
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
Journal du vendredi 31 mai 2024 à 17:46
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

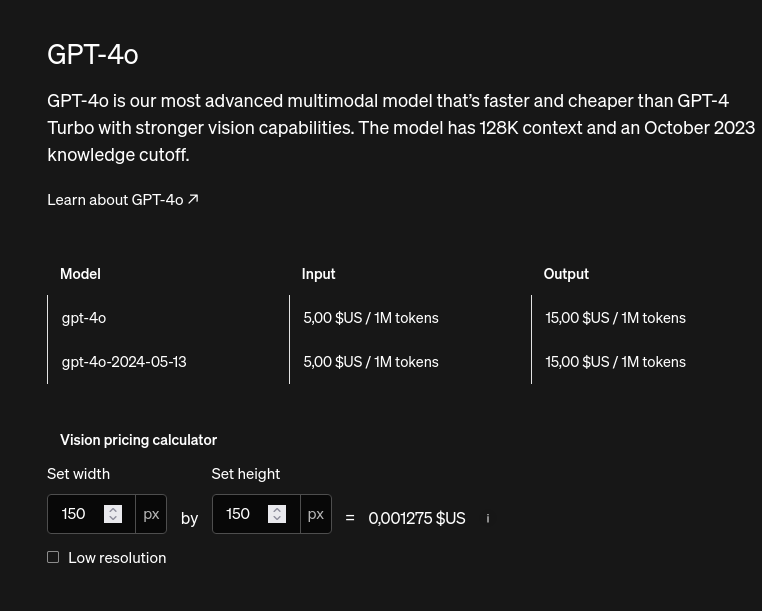
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.