
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (118 notes) :
Premier test minimaliste de Promptfoo avec le provider OpenCode SDK
Depuis au moins novembre 2025, je cherche à rédiger mes prompts, mes fichiers AGENTS.md, mes fichiers SKILLS.md — et plus largement mon harness OpenCode — avec une méthode rigoureuse et contrôlée. J'ai découvert dans cette issue le nom du mécanisme que j'essaie de mettre en place : agent-eval-harness, terme plutôt simple et explicite.
En février, je disais :
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Quelques mois plus tard, j'ai enfin implémenté un premier POC utilisant Promptfoo couplé avec le provider OpenCode SDK : https://github.com/stephane-klein/opencode-promptfoo-poc.
Cette première itération est volontairement minimaliste. J'ai testé :
- 3 LLMs (dans 2 configurations chacune)
- 3 cas de test
L'intégralité de mon évaluation tient dans un seul fichier promptfooconfig.yaml :
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: "Hello World - minimal test"
providers:
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
prompts:
- "Translate the following English text to {{language}}: {{input}}"
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-all
value:
- "Bonjour"
- "monde"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: contains-any
value:
- "Donde esta la biblioteca"
providers:
- "with-agent*"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: not-contains-any
value:
- "Donde esta la biblioteca"
providers:
- "without-agent*"
L'exécution de promptfoo eval donne ceci :
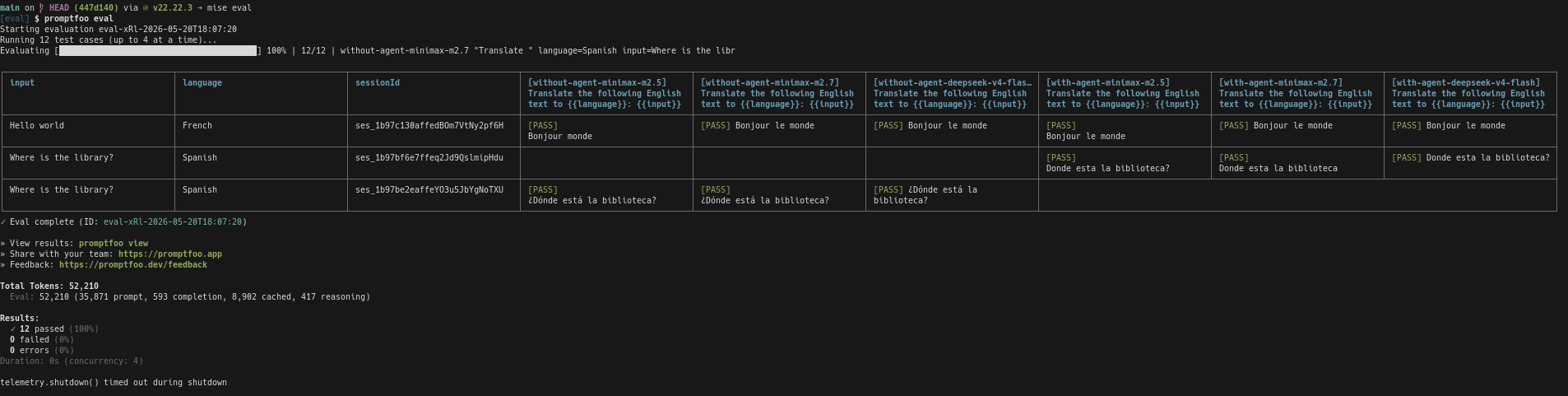
Et voici ce qu'affiche promptfoo viewer dans un browser :
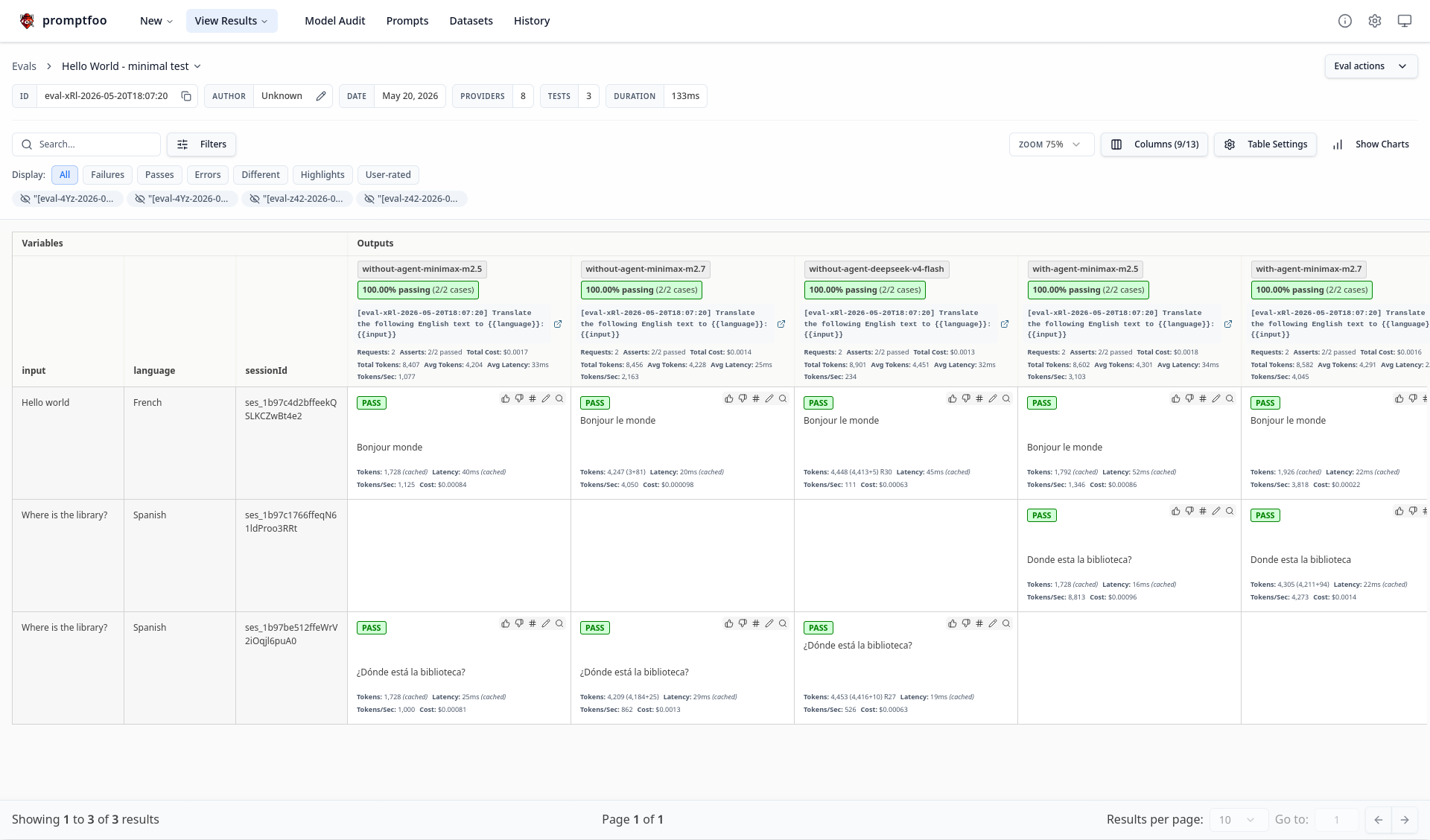
Dans mes tests, j'ai mis en œuvre uniquement contains-all et contains-any, mais Promptfoo propose beaucoup d'autres « Deterministic metrics ».
Promptfoo propose aussi de nombreuses assertions effectuées par des modèles de langage, les « Model-graded metrics », dont la plupart peuvent être qualifiées de LLM-as-a-Judge. Je ne les ai pas encore testées.
Je n'ai pas non plus exploré l'évaluation de « Chat conversations / threads ». Par ailleurs, en examinant la documentation du provider OpenCode SDK, j'ai constaté ce qui me semble être une limitation : il n'est probablement pas possible de changer d'agent dans un thread, c'est-à-dire d'alterner entre le mode plan et le mode build, comme on le ferait dans un usage normal de OpenCode.
Mais après réflexion, il me semble que cette limitation n'est pas importante. Dans un test d'évaluation, chaque cas est un appel unique à l'agent, avec l'historique complet de la conversation fourni en contexte — il n'est pas nécessaire de simuler un flux interactif multi-tours avec alternance d'agents.
Dans ce POC, je configure le provider OpenCode SDK pour qu'il utilise le dossier de configuration ./config/opencode du repository, afin que le harness évalué soit précisément celui qui est versionné, et afin de ne pas subir de perturbation par la configuration OpenCode globale.
Quand j'ai démarré ce POC, j'ai essayé d'indiquer différentes configurations OpenCode au niveau des tests, pour tester différents fichiers AGENTS.md. Mais j'ai constaté que la configuration OpenCode ne peut être définie qu'une seule fois, ici, via une variable d'environnement XDG_CONFIG_HOME.
J'ai mis un certain temps à réaliser que je pouvais procéder autrement, en plaçant les fichiers AGENTS.md dans différents working_dir. Les working_dir se configurent au niveau des providers, voici deux exemples :
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
Cela permet de charger et de tester ./workdir1/AGENTS.md ou ./workdir2/AGENTS.md. Il est possible d'utiliser la même méthode pour évaluer différents SKILLS.md.
Pour le moment, je ne sais pas encore si Promptfoo est un bon outil pour mettre au point mon harness.
Avant de poursuivre mes tests de harness engineering avec Promptfoo, j'aimerais tester agent-catalog-eval pour voir si cet outil serait plus simple à mettre en œuvre.
Comment "harness" s'est répandu en IA et pourquoi ce terme a été choisi
Le week-end dernier, j'ai commencé à chercher d'où venait le terme harness et pourquoi il a été choisi pour désigner ce concept dans les AI agents comme OpenCode ou Claude Code.
Cette note est le résultat de ce travail de recherche, basé sur des échanges avec Sonnet 4.6, des lectures de commentaires Hacker News et divers articles sur le sujet.
En novembre 2025, Anthropic a publié l'article « Effective Harnesses for Long-Running Agents », qui utilise explicitement « agent harness » dans le sens moderne.
Le terme « harness engineering » semble avoir été popularisé par Mitchell Hashimoto dans la section 5 de son billet publié le 5 février 2026. Il y décrit une pratique qu'il a développée au fil de son usage des agents IA :
Je ne sais pas s'il existe un terme largement accepté par l'industrie pour cela, mais j'en suis venu à appeler cela « harness engineering ». C'est l'idée que chaque fois qu'on constate qu'un agent commet une erreur, on prend le temps de concevoir une solution pour que l'agent ne commette plus jamais cette erreur. Je n'ai pas besoin d'inventer de nouveaux termes ici ; s'il en existe un autre, je m'y joindrai.
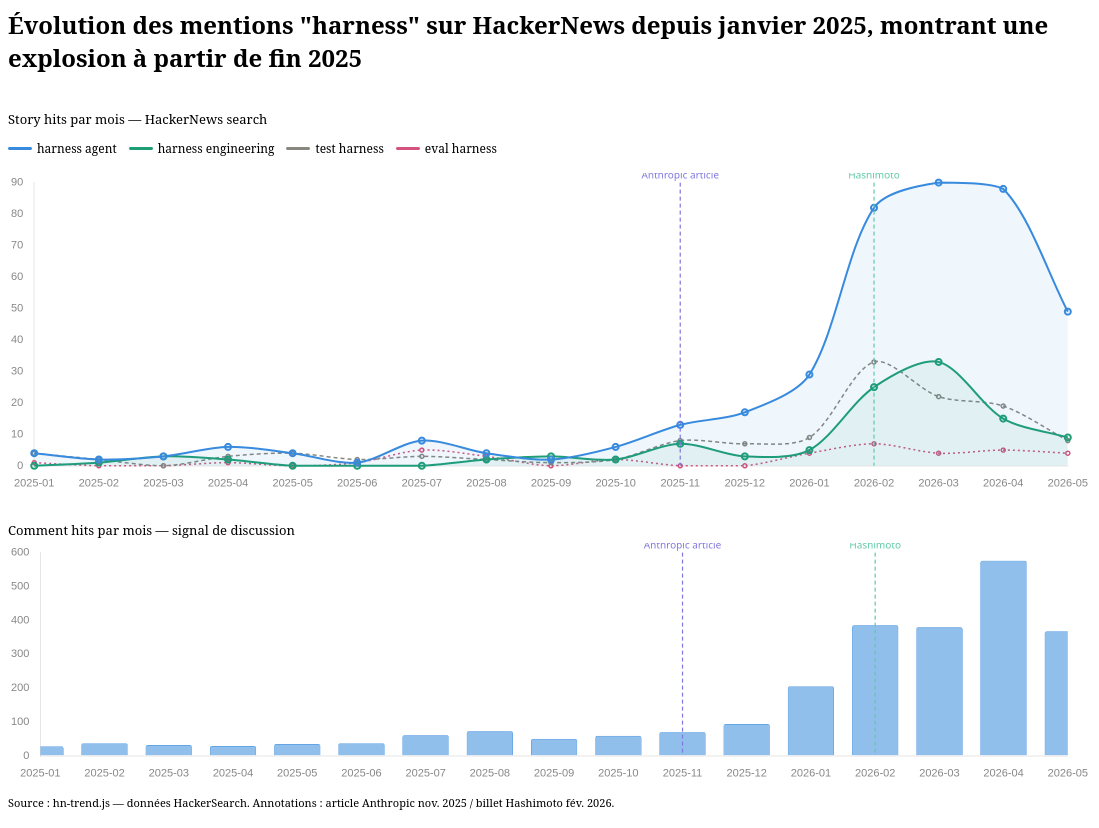 Données extraites avec hackernews-trends-poc.
Données extraites avec hackernews-trends-poc.
Jusqu'à présent, je pensais à tort que l'analogie du harnais correspondait simplement à l'équipement qu'on pose sur un cheval, sans saisir la pertinence de ce terme, par manque de culture de cette langue. En anglais, on trouve les expressions « harness the sun » ou « harness the wind ». Voici la définition du verbe harness :
Verb
harness (third-person singular simple present harnesses, present participle harnessing, simple past and past participle harnessed)
- (transitive) To place a harness on something; to tie up or restrain. Synonym: tackle
« They harnessed the horse to the post. »- (transitive) To capture, control or put to use. « Imagine what might happen if it were possible to harness solar energy fully. »
- (transitive) To equip with armour.
Le terme français qui me semble le plus proche du verbe harness serait « canaliser » ou « dompter ».
Le terme harness désigne donc l'action de canaliser et d'orienter la puissance d'un LLM vers un objectif souhaité.
Avant l'usage du terme harness dans le domaine de l'AI — que ce soit pour agent harness, harness engineering ou LM Evaluation Harness — j'ai découvert en travaillant sur cette note qu'il était déjà utilisé en software engineering, principalement dans l'expression test harness. Il me semble que c'était d'ailleurs l'usage principal du mot dans notre domaine, bien avant qu'il ne soit repris pour les agents IA.
Les concepts que je pense avoir identifiés et que je retiens
- Le harness est un artefact à installer et configurer dans OpenCode. Il est composé de :
- Le harness engineering est le processus humain d'amélioration itérative du harness. Quand l'utilisateur observe une erreur de l'agent, il modifie ou ajoute des fichiers
AGENTS.md,SKILLS.md, des outils MCP ou des configurations pour qu'elle ne se reproduise plus. Ce terme désigne le processus, par opposition au harness qui est l'artefact. - Agent-eval-harness est un outil externe au harness permettant de lancer des sortes de tests unitaires. Il est utilisé pendant les phases de harness engineering pour valider les modifications de façon contrôlée et reproductible.
Cette note ne traite pas de la boucle agent en elle-même — j'ai documenté ce concept séparément ici :
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise.
Le concept de harness vient encadrer cette boucle pour la configurer et la contraindre, mais il ne la définit pas. Comprendre la boucle aide à saisir ce qu'orchestre le harness.
Extrait d'un article de Sebastian Raschka :
Pour clarifier les concepts :
- LLM : le modèle brut de prédiction du prochain token
- Modèle de raisonnement : un LLM optimisé pour produire des traces de raisonnement intermédiaires et se vérifier davantage
- Agent : une boucle qui combine un modèle avec des outils, de la mémoire et des retours d'environnement
- Agent harness : le scaffold logiciel autour d'un agent qui gère le contexte, l'utilisation des outils, les prompts, l'état et le flux de contrôle
- Coding harness : un cas particulier d'agent harness ; un harness spécifique au génie logiciel qui gère le contexte du code, les outils, l'exécution et les retours itératifs
Quelques articles que j'ai lus avec attention :
- Effective harnesses for long-running agents — Anthropic, nov. 2025
- My AI Adoption Journey — Mitchell Hashimoto, fév. 2026
- Components of a Coding Agent — Sebastian Raschka, avr. 2026
En explorant le sujet de harness, je constate que, comme beaucoup de concepts, sa définition peut varier selon les sources et les communautés. Par exemple, l'article Components of a Coding Agent de Sebastian Raschka semble en proposer une définition plus large que Mitchell Hashimoto.
Pour le moment, je souhaite adopter la version de Mitchell Hashimoto, que j'arrive mieux à appréhender et dont je parviens mieux à délimiter le périmètre : un dispositif qui canalise la fougue du LLM, comme le harnais canalise le cheval sauvage.
Comment je me renseigne sur un nouveau modèle LLM en 4 étapes
Voici le process que je suis lorsque je découvre un nouveau modèle LLM et que je souhaite en savoir plus à son propos.
Étape 1 : blog de Simon Willison
Je commence par jeter un œil rapide sur le blog de Simon Willison, car cela fait plusieurs années que je le suis et j'apprécie son expertise et ses analyses de modèles.
Étape 2 : les articles de Artificial Analysis
Ensuite je regarde les articles (https://artificialanalysis.ai/articles) d'Artificial Analysis, pour voir s'ils ont publié un nouvel article sur ce modèle. Généralement, ils sont très réactifs. Voici un exemple concernant Kimi K2.6 : Kimi K2.6: The new leading open weights model.
J'aime beaucoup la structure de leurs articles.
Tout d'abord, une section synthétique avec des informations majeures du modèle :

Ensuite, la position du nouveau modèle pour différents leaderboards :
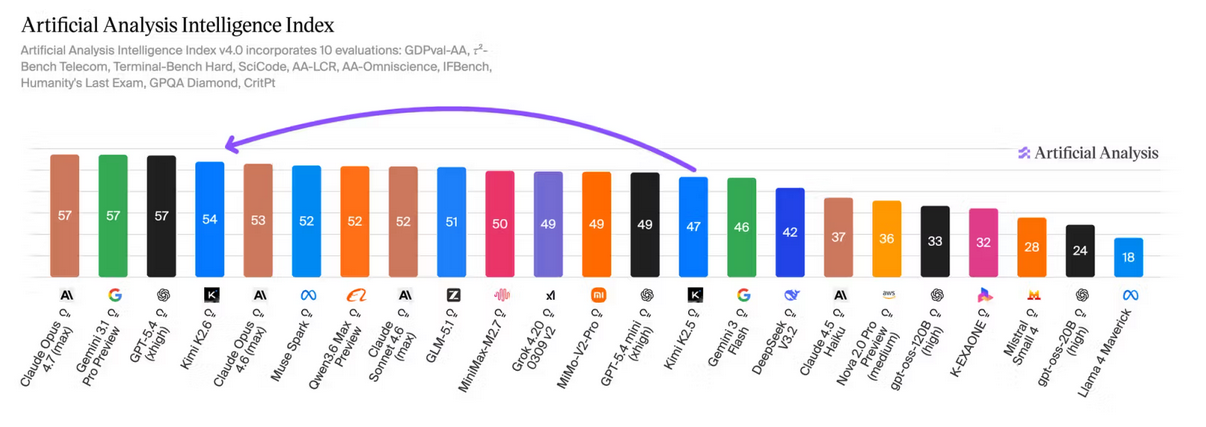
Étape 3 : Analyse des commentaires HackerNews
En troisième étape, j'utilise le moteur de recherche de Hacker News pour identifier le thread qui traite du modèle. Voici par exemple celui à propos de Kimi K2.6: Advancing open-source coding et ses 371 commentaires.
À partir de l'url de ce thread, je lance le prompt suivant dans Claude Desktop connecté au serveur MCP fetch lancé localement :
Utilise `fetch_html` pour récupérer https://news.ycombinator.com/item?id=47835735
**Étape 1 — Récupération complète**
- Récupère la première page avec `fetch_html` et lis le nombre total de commentaires indiqué en début de page — ce nombre est ta cible obligatoire
- Le contenu étant probablement tronqué (limite 200 000 caractères), enchaîne les appels successifs en incrémentant `start_index` de 200 000 à chaque fois :
- `fetch_html(url, start_index=0, max_length=200000)`
- `fetch_html(url, start_index=200000, max_length=200000)`
- `fetch_html(url, start_index=400000, max_length=200000)`
- … jusqu'à ce que la réponse soit vide
- **Tu dois avoir récupéré 100% des commentaires avant de passer à l'étape suivante.** Vérifie que le nombre de commentaires extraits correspond au compteur initial — si ce n'est pas le cas, continue à paginer.
**Étape 2 — Analyse exhaustive**
Analyse **chacun des commentaires sans exception** exclusivement sous l'angle des **modèles LLM** mentionnés. Aucun commentaire ne doit être ignoré ou échantillonné.
Pour chaque modèle cité, synthétise :
- **Points forts** relevés par les commentateurs
- **Points faibles** ou limitations mentionnées
- **Cas d'usage Coding** : performance en génération de code, débogage, complétion, etc.
- **Cas d'usage Intelligence générale** : raisonnement, compréhension, tâches polyvalentes, etc.
- **Benchmarks mentionnés** : scores, classements ou comparaisons chiffrées associés à ce modèle
**Étape 3 — Synthèse**
Présente le résultat sous forme de **deux tableaux comparatifs markdown** :
1. **Tableau Coding** — colonnes : Modèle | Points forts | Points faibles | Benchmarks coding
2. **Tableau Intelligence générale** — colonnes : Modèle | Points forts | Points faibles | Benchmarks généralistes
Puis ajoute :
1. Une section **"Comparaison directe entre modèles"** synthétisant les confrontations explicites faites par les commentateurs (quel modèle bat quel autre, sur quoi, dans quel contexte), en distinguant coding vs intelligence générale
2. Une section **"Benchmarks en discussion"** listant les benchmarks cités, leur crédibilité perçue par la communauté, et les modèles qu'ils avantagent ou désavantagent — en précisant s'il s'agit de benchmarks coding (HumanEval, SWE-bench…) ou généralistes (MMLU, GPQA…)
Seuls les commentaires sans aucune mention de modèle spécifique sont à ignorer.
Ce qui m'a donné le résultat suivant : Analyse par Sonnet 4.6 des commentaires Hacker News à propos de Kimi K2.6.
Étape 4 : quelques semaines plus tard
Quelques semaines plus tard, je consulte toutes les sorties de modèle du mois dans l'article Nouvelles sur l'IA du site LinuxFR pour avoir une revue complète de l'écosystème.
Je suis ravi de voir l'offre de modèles OpenCode Go s'enrichir semaine après semaine
Le 12 mars 2026, quand j'ai commencé à utiliser OpenCode Go, seuls 3 modèles étaient disponibles : MiniMax M2.5, Kimi K2.5 et GLM-5. J'ai depuis eu l'agréable surprise de voir arriver de nouveaux modèles Open Weights, souvent dès le lendemain de leur publication.
Aujourd'hui, l'offre est bien plus vaste :
- 18 mars, ajout de MiniMax M2.7
- 19 mars OpenCode supprime le support d'accès à l'offre Claude Pro
- 2 avril, ajout de MiMo-V2-Pro et MiMo-V2-Omni de Xiaomi
- 7 avril, ajout de GLM-5.1
- 15 avril, ajout de Qwen 3.5 Plus et Qwen3.6 Plus
- 20 avril, ajout de Kimi K2.6
- 22 avril, ajout de MiMo v2.5 et MiMo v2.5 Pro de Xiaomi
- 24 avril, ajout de DeepSeek V4 Pro et DeepSeek V4 Flash
Et depuis, j'ai pris la fâcheuse habitude — un peu par FoMo, je l'avoue — de consulter presque une fois par jour le compte Twitter de OpenCode (https://xcancel.com/opencode/) pour voir si un nouveau modèle est sorti.
Après 45 jours d'utilisation de OpenCode Go à 10$ par mois, je n'ai jamais été limité par les quotas
Comme je l'avais décidé dans ma note de découverte de OpenCode Go, j'utilise OpenCode Go depuis le 12 mars 2026.
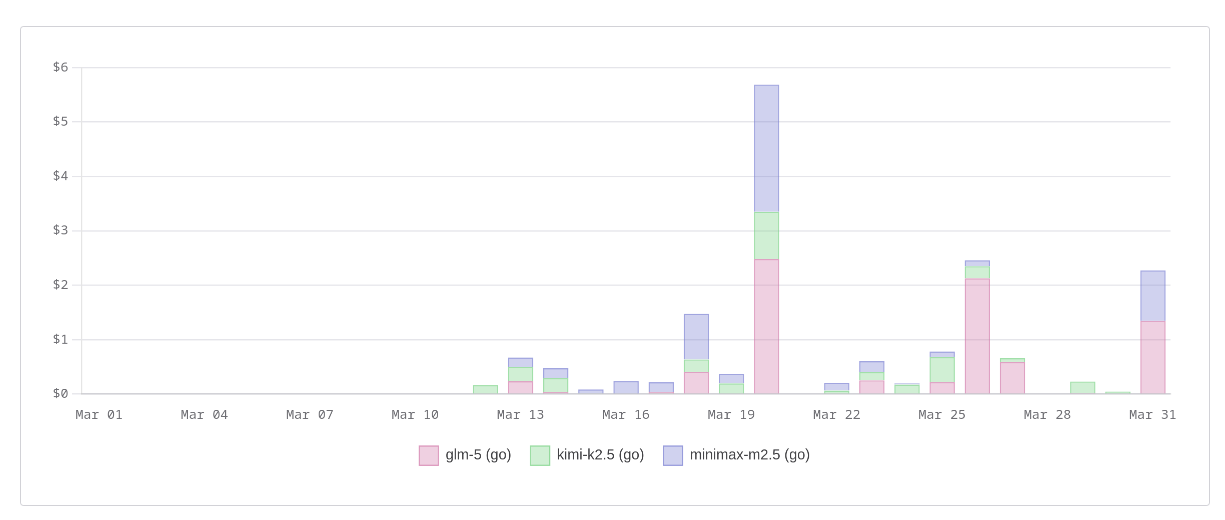
Voici mes coûts d'utilisation par jour du mois de mars :
Et ceux du mois d'avril :
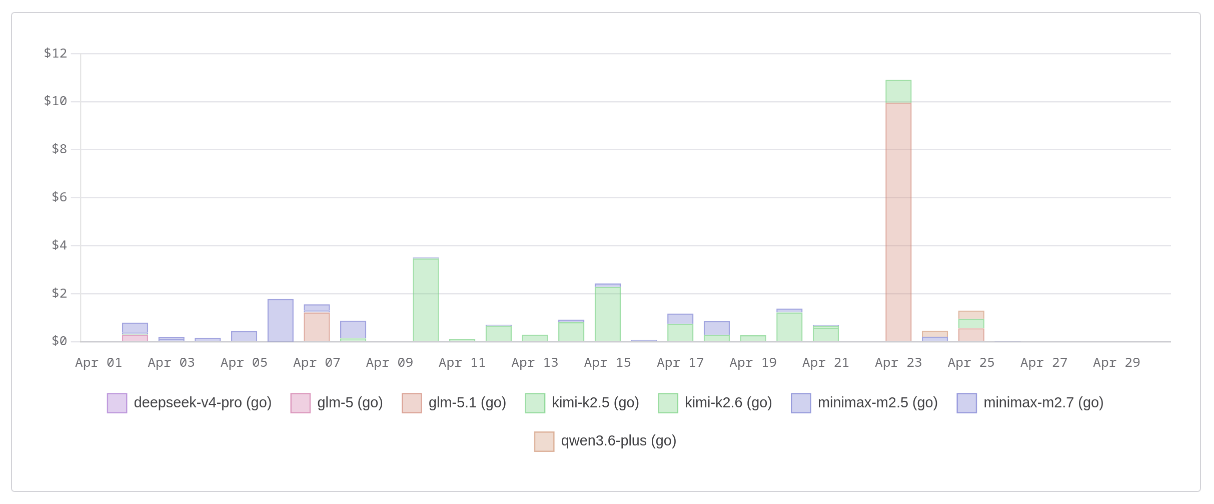
Mais attention, la lecture de ce graphe peut être trompeuse : ces montants correspondent au coût réel de l'offre OpenCode Zen, de type Pay-As-You-Go. Concrètement, je paie 10 $/mois avec l'offre OpenCode Go, qui me donne l'équivalent d'environ 60 $ de crédits Zen.
Après environ 14 jours sur mon abonnement d'avril — soit près de la moitié du mois —, j'ai consommé 35 % de mon quota. Pour le mois de mars, je n'ai pas de chiffre précis en tête, mais il me semble que j'avais atteint environ 60 %.
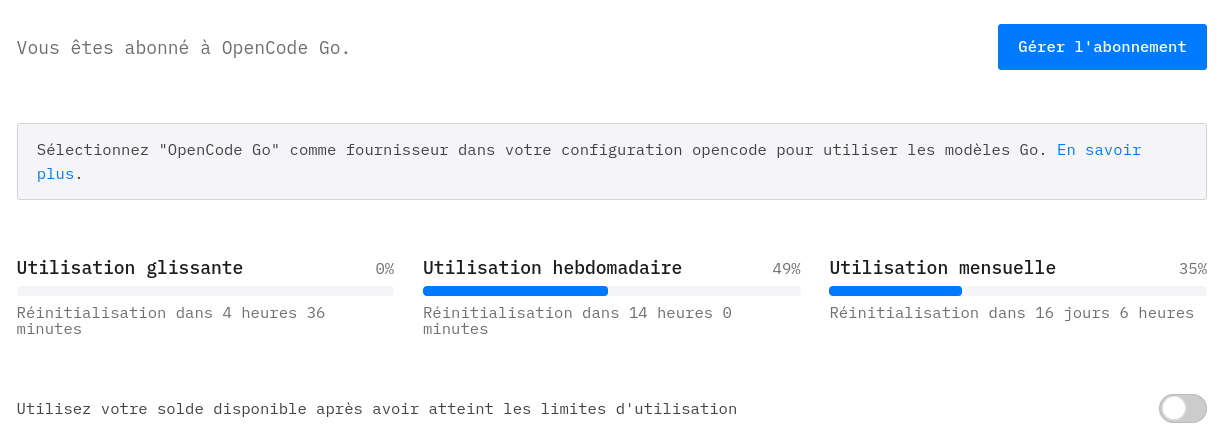
En 45 jours d'utilisation, je n'ai jamais atteint les limitations des fenêtres de 5 h, ni les limites hebdomadaires.
J'ai découvert MimiMax M2.7, qui semble équivalent à GLM-5 pour un tiers du prix
#JaiDécouvert la sortie de MiniMax M2.7 le 18 mars 2026 : https://www.minimax.io/news/minimax-m27-en.
Pour donner du contexte, j'utilise depuis le 12 mars 2026 les modèles GLM-5, Kimi K2.5 et MiniMax M2.5 via l'offre OpenCode Go. Je n'ai pas comparé rigoureusement ces modèles avec Sonnet 4.6 et Opus 4.6, mais pour le moment, je suis satisfait de ces modèles. J'ai même l'impression que MiniMax M2.5, le moins cher, suffit pour la majorité de mes besoins.
J'ai lu l'article "MiniMax M2.7 Review: Is It Worth the Hype?", mais c'est finalement MiniMax M2.7: Everything you need to know qui m'a été le plus utile, voici sa traduction :
MiniMax a publié MiniMax-M2.7, offrant une intelligence de niveau GLM-5 pour moins d'un tiers du coût
MiniMax-M2.7 de @MiniMax_AI obtient un score de 50 sur l'Artificial Analysis Intelligence Index, une amélioration de 8 points par rapport à MiniMax-M2.5, publié il y a un mois. Cette amélioration est portée par une performance améliorée sur les tâches agentiques du monde réel et une réduction des hallucinations. MiniMax-M2.7 est désormais devant MiMo-V2-Pro (Reasoning, 49) et Kimi K2.5 (Reasoning, 47), et équivalent à GLM-5 (Reasoning, 50) tout en utilisant 20% de tokens de sortie en moins et coûtant moins d'un tiers du prix pour fonctionner. MiniMax-M2.7 est un modèle uniquement raisonnement et maintient le même prix par token que MiniMax-M2.5.
Points clés :
➤ Performance solide sur les tâches agentiques du monde réel : MiniMax-M2.7 atteint un Elo GDPval-AA de 1494, une amélioration significative par rapport à MiniMax-M2.5 (1203) et devant MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406) et Kimi K2.5 (Reasoning, 1283). Il reste derrière les modèles de pointe tels que GPT-5.4 (xhigh, 1667) et Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606).
- Réduction des hallucinations : MiniMax-M2.7 obtient un score de +1 sur l'AA-Omniscience Index, contre -40 pour MiniMax-M2.5. Cela le place en compétition avec GPT-5.2 (xhigh, -1) et GLM-5 (Reasoning, +2), et bien devant Kimi K2.5 (Reasoning, -8). L'amélioration par rapport à M2.5 est entièrement due à la réduction des hallucinations, ce qui signifie que le modèle est plus susceptible de s'abstenir de répondre lorsqu'il ne connaît pas la réponse, plutôt que de deviner. M2.7 atteint un taux d'hallucination de 34%, inférieur à Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) et Gemini 3.1 Pro Preview (50%).
- Gains sur la plupart des évaluations par rapport à MiniMax-M2.5 : En dehors des améliorations du GDPval-AA et de l'AA-Omniscience notées ci-dessus, MiniMax-M2.7 progresse en HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.) et LCR (+3 p.p.). Nous avons constaté une régression notable en τ²-Bench (-11 p.p.).>
- Utilisation accrue de tokens : MiniMax-M2.7 a utilisé environ 87M tokens de sortie pour exécuter l'Artificial Analysis Intelligence Index, en hausse de 55% par rapport à MiniMax-M2.5 (environ 56M). Il reste plus efficace en tokens que d'autres modèles tels que GLM-5 (Reasoning, 110M) et Kimi K2.5 (Reasoning, environ 89M).
- Rentabilité de pointe : MiniMax-M2.7 a coûté 176 $ pour exécuter l'Artificial Analysis Intelligence Index, maintenant le même prix de 0,30 $/1,20 $ par million de tokens d'entrée/sortie que M2.5. Cela le place sur la frontière de Pareto de notre graphique Intelligence vs. Coût. À titre de référence, GLM-5 (Reasoning) a coûté 547 $ à intelligence équivalente, Kimi K2.5 (Reasoning) 371 $, et Gemini 3 Flash Preview (Reasoning) 278 $.
Détails clés du modèle :
- Fenêtre de contexte : 200K tokens (équivalent à MiniMax-M2.5).
- Tarification : 0,30 $/1,20 $ par million de tokens d'entrée/sortie (inchangé par rapport à MiniMax-M2.5).
- Disponibilité : API propriétaire MiniMax uniquement.
- Modalité : Entrée et sortie de texte uniquement (pas de multimodalité).
- Licence : MiniMax n'a pas annoncé si MiniMax-M2.7 sera en open weights. MiniMax-M2.5 est disponible sous licence MIT.
MiniMax M2.7 a été intégré dans l'offre OpenCode Go, par conséquent, je vais tester ce modèle dans mes projets OpenCode.
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Journal du jeudi 12 mars 2026 à 11:18
En étudiant l'offre OpenCode Go, je suis tombé sur une page marketing du service ApiYi : « Is the OpenCode GO Plan Worth Buying? $10/Month 3 Model Tests + 5 Major Alternative Solutions Compared ».
En analysant le contenu avec Sonnet 4.6, j'ai compris qu'ApiYi fonctionne vraisemblablement comme une solution de contournement à destination du marché chinois : les utilisateurs qui ne peuvent pas acheter directement auprès d'Anthropic — en raison des risques de bannissement liés aux adresses IP et aux moyens de paiement chinois — y trouvent un accès indirect aux modèles.
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
J'ai installé Claude Desktop sous Fedora
Anthropic ne propose pas de version GNU Linux de Claude Desktop.
#JaiDécouvert le projet Claude Desktop for Linux qui a repackagé la version de Claude Desktop Windows pour GNU Linux. Ce projet propose des packages pour Debian, Fedora, ArchLinux et NixOS.
Je l'ai installé avec succès sous Fedora avec les commandes suivantes trouvé ici :
$ sudo curl -fsSL https://aaddrick.github.io/claude-desktop-debian/rpm/claude-desktop.repo -o /etc/yum.repos.d/claude-desktop.repo
$ sudo dnf install claude-desktop
J'ai ensuite testé la connexion de Claude Desktop au Filesystem MCP Server lancé en local :
Seul élément négatif pour l'instant : la version Desktop ne permet pas d'utiliser l'extension Claude Counter (extension), contrairement à la version web.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals. Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
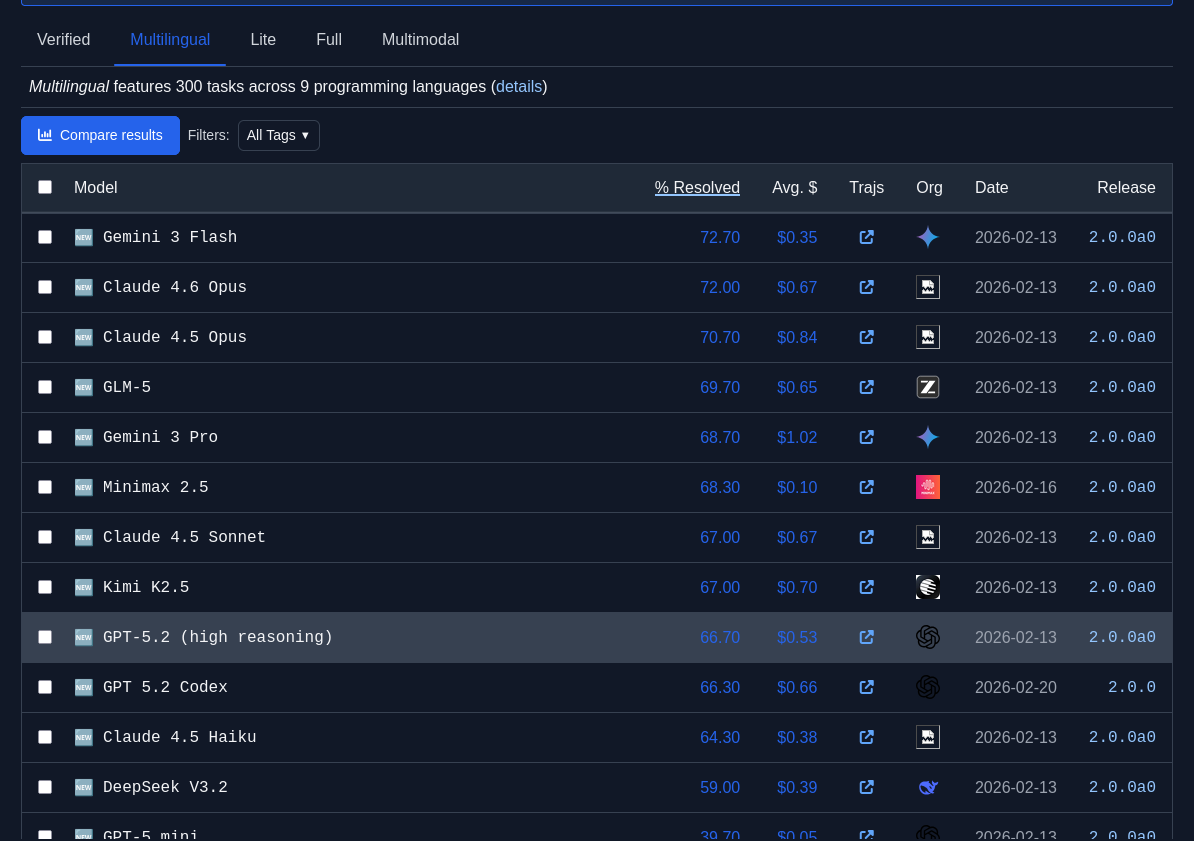
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.
J'ai découvert Promptfoo qui permet de faire du LLM Eval
Cette note a été partiellement écrite fin novembre 2025 et publiée 3 mois plus tard, fin février 2026.
Souhaitant améliorer mes prompts et combler mes lacunes en prompt engineering, je me suis mis à chercher des outils permettant de pratiquer quelque chose qui ressemblerait au Test driven development appliqué à la conception de prompts.
Via Claude Sonnet 4.5, #JaiDécouvert Promptfoo (https://github.com/promptfoo/promptfoo), un framework Javascript permettant notamment de faire du LLM Eval.
Cela fait plusieurs mois que je croise l'expression LLM Eval, sans avoir jamais pris le temps de comprendre ce que ce concept signifie précisément.
D'après ce que j'ai compris, la différence essentielle entre Unit testing et LLM Eval, c'est que les tests unitaires sont déterministes, alors que la qualité des réponses des LLM est évaluée de manière probabiliste.
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?
Dans une note de juillet 2025, j'évoquais ne pas avoir trouvé d'information sur les limites de consommation de tokens de l'offre "Pro" de Claude.
J'avais observé empiriquement qu'avec mon usage de Claude Sonnet à l'époque, l'API directe était plus avantageuse qu'un abonnement Pro :
Entre le 30 mai et le 15 juillet 2025, j'ai consommé
$14,94de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
En 2026, avec la forte augmentation de l'usage des AI code assistant de type Claude Code ou OpenCode, la consommation de tokens a explosé, ce qui change la donne.
Je me pose à nouveau la question suivante : « Est-ce que les abonnements sont maintenant réellement plus économiques que l'utilisation directe de l'API ? ».
Cette semaine, j'ai effectué de nouvelles recherches pour en savoir plus sur les limites des abonnements Claude et cette fois, j'ai trouvé dans ce thread Reddit des informations.
Dans cette article, l'auteur explique les résultats qu'il a trouvé par reverse engineering.
Attention, l'unité "credits" est différente de "tokens". La définition de crédit est donné un peu plus loin dans cette note.
Le plan 20× n'est pas aussi avantageux qu'on pourrait le croire. Sur le site d'Anthropic, toutes les mentions « 20× plus d'utilisation* » comportent cet astérisque gênant. Les limites de session de cinq heures sont bien 20× plus élevées qu'en Pro, mais la vraie question est : quelle quantité de travail peut-on en tirer ? La réponse est : seulement deux fois plus par semaine que le plan 5×.
En revanche, le plan 5× offre un excellent rapport qualité-prix. Il tient largement ses promesses. C'est le point idéal du tableau tarifaire. Vous obtenez une limite de session six fois plus élevée que Pro (et non cinq), et plus de huit fois la limite hebdomadaire (davantage que l'éponyme cinq).
Tier Credits/5h Credits/week Pro 550,000 (1×) 5,000,000 (1×) Max 5× 3,300,000 (6×) 41,666,700 (8.33×) Max 20× 11,000,000 (20×) 83,333,300 (16.67×) Comparés aux tarifs de l'API, tous les abonnements semblent fantastiques. Les estimations de valeur dans le tableau sont des bornes inférieures, car la mise en cache rend l'équivalent API effectif encore plus favorable (je l'expliquerai dans un moment). Dans tous les cas, si vous pouvez utiliser un abonnement plutôt que l'API, foncez.
Tier Price Credits/month Opus-rate tokens Equivalent API cost Pro $20 21.7M 32.5M in or 6.5M out $163 (8.1×) Max 5× $100 180.6M 270.9M in or 54.2M out $1,354 (13.5×) Max 20× $200 361.1M 541.7M in or 108.3M out $2,708 (13.5×)
Voici un autre avantage de l'abonnement versus l'API :
Les lectures de cache. Elles sont entièrement gratuites.
Cela rend la balance encore plus favorable aux abonnements. Dans une boucle agentique (par exemple Claude Code), le modèle effectue des dizaines d'appels d'outils par tour. Après chaque appel d'outil, le modèle est invoqué à nouveau. Lecture du cache sur l'intégralité du contexte. L'API facture 10% pour chaque lecture ; les abonnements ne facturent rien. Ça s'accumule vite, comme nous allons le voir dans un instant.
Les écritures de cache sont également moins chères : elles coûtent 1,25×/2× le prix d'entrée sur l'API, tandis que sur l'abonnement elles sont facturées au prix d'entrée normal. Chaque tour de conversation est écrit dans le cache avant de pouvoir être lu, ce qui a donc aussi son importance.
Voici le lien entre credit et tokens :
Ce sont les unités utilisées en interne pour suivre la consommation de votre abonnement. « Crédits » est mon nom arbitraire pour ça — ces valeurs n'apparaissent pas directement dans un champ de l'API, donc il n'y a pas de mot évident pour les désigner. Je trouve que « crédits » sonne bien.
Comment passe-t-on des crédits aux tokens ? Voici la formule :
credits_used = ceil(input_tokens × input_rate + output_tokens × output_rate)...et les valeurs à y insérer :
Modèle Crédits/token en entrée Crédits/token en sortie Haiku 2/15 = 0,133... 10/15 = 2/3 = 0,666... Sonnet 6/15 = 2/5 = 0,4 30/15 = 2 Opus 10/15 = 2/3 = 0,666... 50/15 = 10/3 = 3,333... Les valeurs spécifiques semblent assez arbitraires, mais les ratios entre elles reflètent la tarification de l'API : la sortie coûte 5× l'entrée, vous paierez 5× plus pour Opus que pour Haiku, etc.
Après la lecture de cet article, il est clair que je vais utiliser principalement un abonnement Claude plutôt que des tokens d'API. Cependant, l'accès à un LLM par abonnement est moins flexible qu'une OpenAI Chat Completions compatible API.
Par exemple, je ne peux pas connecter Open WebUI, LibreChat ou toute autre application qui nécessite un accès direct à un LLM.
Mi-janvier 2026, j'ai lu ce thread à propos d'un "hack" utilisé par OpenCode pour accéder directement à l'API Anthropic avec un abonnement Claude. Ça m'a donné l'idée de chercher des outils de type "proxy" capables d'exposer une OpenAI Chat Completions compatible API à partir d'un abonnement Claude.
En fouillant sur Reddit, dans ce thread, j'ai trouvé les projets suivants :
Je compte tester ces deux projets dans les semaines à venir.
Journal du lundi 12 janvier 2026 à 09:36
Il y a exactement 1 an, j'ai publié cette note pour citer ce message de Salvatore Sanfilippo, créateur de Redis :
About "people still thinking LLMs are quite useless", I still believe that the problem is that most people are exposed to ChatGPT 4o that at this point for my use case (programming / design partner) is basically a useless toy. And I guess that in tech many folks try LLMs for the same use cases. Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
Aujourd'hui, je viens de lire son nouveau billet : Don't fall into the anti-AI hype (1106 commentaires sur HackerNews, 217 commentaires sur Lobsters).
Ces observations rejoignent ce que je constate avec OpenCode et les modèles Claude Sonnet 4.5 ou Claude Opus 4.5. Il me semble que "coder à la main" pourrait devenir un jeu, comme faire des sudoku ou jouer à des jeux vidéo. Pour le moment, je n'ai aucune idée de l'impact que cela aura sur mes capacités cognitives. J'ai l'impression que mes compétences pourraient décliner.
En fait, j'ai très peur de ne plus faire d'efforts de compréhension et qu'après quelques mois ou années, je devienne de plus en plus bête en déléguant systématiquement la réflexion à l'IA.
Voici cet article, traduit en français avec Claude Sonnet 4.5 :
Ne tombez pas dans le battage anti-IA
J'adore écrire du logiciel, ligne par ligne. On pourrait dire que ma carrière a été un effort continu pour créer des logiciels bien écrits, minimaux, où la touche humaine était la caractéristique fondamentale. J'espère également une société où les derniers ne sont pas oubliés. De plus, je ne souhaite pas que l'IA réussisse économiquement, je me fiche que le système économique actuel soit subverti (je pourrais être très heureux, honnêtement, si cela va dans la direction d'une redistribution massive de la richesse). Mais, je ne me respecterais pas moi-même et mon intelligence si mon idée du logiciel et de la société devait altérer ma vision : les faits sont les faits, et l'IA va changer la programmation pour toujours.
En 2020, j'ai quitté mon emploi pour écrire un roman sur l'IA, le revenu de base universel, une société qui s'adaptait à l'automatisation du travail en faisant face à de nombreux défis. À la toute fin de 2024, j'ai ouvert une chaîne YouTube axée sur l'IA, son utilisation dans les tâches de codage, ses effets sociaux et économiques potentiels. Mais bien que j'aie reconnu très tôt ce qui allait se passer, je pensais que nous avions plus de temps avant que la programmation ne soit complètement remodelée, au moins quelques années. Je ne crois plus que ce soit le cas. Récemment, les LLM de pointe sont capables de compléter de grandes sous-tâches ou des projets de taille moyenne seuls, presque sans assistance, avec un bon ensemble d'indices sur ce que devrait être le résultat final. Le degré de succès que vous obtiendrez est lié au type de programmation que vous faites (plus c'est isolé et textuellement représentable, mieux c'est : la programmation système est particulièrement adaptée), et à votre capacité à créer une représentation mentale du problème à communiquer au LLM. Mais, en général, il est maintenant clair que pour la plupart des projets, écrire le code soi-même n'a plus de sens, si ce n'est pour s'amuser.
Au cours de la semaine dernière, simplement en promptant, et en inspectant le code pour fournir des conseils de temps en temps, en quelques heures j'ai accompli les quatre tâches suivantes, en heures au lieu de semaines :
J'ai modifié ma bibliothèque linenoise pour supporter l'UTF-8, et créé un framework pour tester l'édition de ligne qui utilise un terminal émulé capable de rapporter ce qui est affiché dans chaque cellule de caractère. Quelque chose que j'ai toujours voulu faire, mais il était difficile de justifier le travail nécessaire juste pour tester un projet personnel. Mais si vous pouvez simplement décrire votre idée, et qu'elle se matérialise dans le code, les choses sont très différentes.
J'ai corrigé des échecs transitoires dans le test de Redis. C'est un travail très ennuyeux, des problèmes liés au timing, des conditions de deadlock TCP, etc. Claude Code a itéré pendant tout le temps nécessaire pour le reproduire, a inspecté l'état des processus pour comprendre ce qui se passait, et a corrigé les bugs.
Hier, je voulais une bibliothèque C pure capable de faire l'inférence de modèles d'embedding de type BERT. Claude Code l'a créée en 5 minutes. Même sortie et même vitesse (15% plus lent) que PyTorch. 700 lignes de code. Un outil Python pour convertir le modèle GTE-small.
Au cours des dernières semaines, j'ai effectué des modifications des mécanismes internes de Redis Streams. J'avais un document de conception pour le travail que j'ai fait. J'ai essayé de le donner à Claude Code et il a reproduit mon travail en, genre, 20 minutes ou moins (principalement parce que je suis lent à vérifier et à autoriser l'exécution des commandes nécessaires).
Il est tout simplement impossible de ne pas voir la réalité de ce qui se passe. Écrire du code n'est plus nécessaire pour la plupart. Il est maintenant beaucoup plus intéressant de comprendre quoi faire, et comment le faire (et, à propos de cette deuxième partie, les LLM sont aussi d'excellents partenaires). Peu importe si les entreprises d'IA ne pourront pas récupérer leur argent et que le marché boursier s'effondrera. Tout cela est sans importance, à long terme. Peu importe si tel ou tel PDG d'une licorne vous dit quelque chose de rebutant, ou d'absurde. La programmation a changé pour toujours, de toute façon.
Comment je me sens, à propos de tout le code que j'ai écrit qui a été ingéré par les LLM ? Je suis ravi d'en faire partie, parce que je vois cela comme une continuation de ce que j'ai essayé de faire toute ma vie : démocratiser le code, les systèmes, la connaissance. Les LLM vont nous aider à écrire de meilleurs logiciels, plus rapidement, et permettront aux petites équipes d'avoir une chance de rivaliser avec les plus grandes entreprises. La même chose que les logiciels open source ont fait dans les années 90.
Cependant, cette technologie est beaucoup trop importante pour être entre les mains de quelques entreprises. Pour l'instant, vous pouvez faire le pré-entraînement mieux ou pas, vous pouvez faire l'apprentissage par renforcement de manière beaucoup plus efficace que d'autres, mais les modèles ouverts, en particulier ceux produits en Chine, continuent de rivaliser (même s'ils sont en retard) avec les modèles de pointe des laboratoires fermés. Il y a une démocratisation suffisante de l'IA, jusqu'à présent, même si elle est imparfaite. Mais : il n'est absolument pas évident qu'il en sera ainsi pour toujours. J'ai peur de la centralisation. En même temps, je crois que les réseaux de neurones, à l'échelle, sont simplement capables de faire des choses incroyables, et qu'il n'y a pas assez de "magie" dans l'IA de pointe actuelle pour que les autres laboratoires et équipes ne rattrapent pas leur retard (sinon il serait très difficile d'expliquer, par exemple, pourquoi OpenAI, Anthropic et Google sont si proches dans leurs résultats, depuis des années maintenant).
En tant que programmeur, je veux écrire plus d'open source que jamais, maintenant. Je veux améliorer certains de mes dépôts abandonnés pour des raisons de temps. Je veux appliquer l'IA à mon workflow Redis. Améliorer l'implémentation des Vector Sets et ensuite d'autres structures de données, comme je le fais avec Streams maintenant.
Mais je m'inquiète pour les gens qui vont être licenciés. Il n'est pas clair quelle sera la dynamique en jeu : les entreprises vont-elles essayer d'avoir plus de personnes, et de construire plus ? Ou vont-elles essayer de réduire les coûts salariaux, en ayant moins de programmeurs qui sont meilleurs au prompting ? Et, il y a d'autres secteurs où les humains deviendront complètement remplaçables, je le crains.
Quelle est la solution sociale, alors ? L'innovation ne peut pas être annulée après tout. Je crois que nous devrions voter pour des gouvernements qui reconnaissent ce qui se passe, et qui sont prêts à soutenir ceux qui resteront sans emploi. Et, plus les gens seront licenciés, plus il y aura de pression politique pour voter pour ceux qui garantiront un certain degré de protection. Mais j'attends également avec impatience le bien que l'IA pourrait apporter : de nouveaux progrès en science, qui pourraient aider à réduire la souffrance de la condition humaine, qui n'est pas toujours heureuse.
Quoi qu'il en soit, revenons à la programmation. J'ai une seule suggestion pour vous, mon ami. Quoi que vous croyiez sur ce qui devrait être la Bonne Chose, vous ne pouvez pas la contrôler en refusant ce qui se passe actuellement. Éviter l'IA ne va pas vous aider, vous ou votre carrière. Pensez-y. Testez ces nouveaux outils, avec soin, avec des semaines de travail, pas dans un test de cinq minutes où vous ne pouvez que renforcer vos propres convictions. Trouvez un moyen de vous multiplier, et si cela ne fonctionne pas pour vous, réessayez tous les quelques mois.
Oui, peut-être pensez-vous que vous avez travaillé si dur pour apprendre à coder, et maintenant les machines le font pour vous. Mais quel était le feu en vous, quand vous codiez jusqu'à la nuit pour voir votre projet fonctionner ? C'était construire. Et maintenant vous pouvez construire plus et mieux, si vous trouvez votre façon d'utiliser l'IA efficacement. Le plaisir est toujours là, intact.
Journal du vendredi 09 janvier 2026 à 10:11
Dans Nouvelles sur l’IA de décembre 2025 #JaiDécouvert METR - Model Evaluation & Threat Research :
Claude Opus 4.5 rejoint la maintenant célèbre évaluation du METR. Il prend largement la tête (sachant que ni Gemini 3 Pro, ni ChatGPT 5.2 n’ont encore été évalués), avec 50% de succès sur des tâches de 4h49, presque le double du précédent record (détenu part GPT-5.1-Codex-Max, avec 50% de succès sur des tâches de 2h53). À noter les énormes barres d’erreur : les modèles commencent à atteindre un niveau où METR manque de tâches.
Journal du mercredi 24 décembre 2025 à 14:59
Un ami vient de me poser cette question :
tu es content de Mammouth ? ça s'intègre bien à Zed, VSCode ?
Il fait probablement référence à ma note du 2025-11-16_1325.
Comme je l'indiquais à l'époque :
J'ai pris un abonnement d'un mois à 12 € TTC pour tester le service. Pour l'instant, je pense continuer avec le couple Open WebUI et OpenRouter qui me donne accès à plus de modèles et plus de flexibilité.
Finalement, je n'ai pas utilisé Mammouth et je suis resté sur le couple Open WebUI et OpenRouter.
Par ailleurs, je n'ai jamais essayé Zed editor et je n'utilise plus VS Code depuis mi-2022 (voir Historique des éditeurs texte que j'ai utilisés).
Voici ce que j'utilise depuis début 2025 pour les LLM :
Au quotidien, j'utilise Open WebUI connecté à OpenRouter pour accéder à différents modèles LLM (voir Quelle est mon utilisation d'OpenRouter.ia ?).
Pour les AI code assistant, j'ai d'abord utilisé avante.nvim, puis depuis quelques mois j'utilise principalement Aider.
Par exemple, j'ai implémenté 90% du projet qemu-compose avec Aider (voir section Development approach).
J'utilise aussi llm (cli), mais sans doute pas encore assez.
Ce que j'envisage de tester :
- AIChat pour remplacer llm (cli) et potentiellement Open WebUI
- Claude Code pour le comparer à Aider
- Avante Zen Mode pour éventuellement remplacer Aider
- LibreChat pour potentiellement remplacer Open WebUI
Avec AIChat et LibreChat, je souhaite commencer à utiliser sérieusement les tools (LLM) et des services MCP.
Ce que je compte conserver : OpenRouter.
J'ai découvert AIChat, alternative à llm cli
Dans ce thread, #JaiDécouvert AIChat (https://github.com/sigoden/aichat), une alternative à llm (cli) codée en Rust.
AIChat is an all-in-one LLM CLI tool featuring Shell Assistant, CMD & REPL Mode, RAG, AI Tools & Agents, and More.
En parcourant le README.md, j'ai l'impression que AIChat propose une meilleure UX que llm (cli).
Je constate aussi que AIChat offre plus de fonctionnalités que llm (cli) :
- AI Tools & MCP
- AI Agents
- LLM Arena
- La partie RAG semble plus avancée
Ce qui attire le plus mon attention, c'est le sous-projet llm-functions qui, d'après ce que j'ai lu, permet de créer très facilement des tools en Bash, Python ou Javascript. Exemples :
J'ai hâte de tester ça 🙂 ( #JaimeraisUnJour ).
Par contre, llm-functions ne semble pas encore permettre la configuration de Remote MCP server.
Je suis aussi intéressé par cette issue : TUI for managing, searching, and switching between chat sessions.
Un point qui m'inquiète un peu : le projet semble peu actif ces derniers mois.
Journal du lundi 01 décembre 2025 à 08:02
Dans le livre "La parole aux machines", j'ai appris beaucoup de choses au sujet de la technique Reinforcement Learning from Human Feedback (RLHF).
Journal du vendredi 21 novembre 2025 à 14:32
Via Claude Sonnet 4.5, #JaiDécouvert le projet Massive Text Embedding Benchmark qui compare les embeddings Models.
Voici le site de documentation, son dépôt GitHub, et son leaderboard qui liste actuellement 319 models, dont 180 supportant le français.
Journal du vendredi 21 novembre 2025 à 13:56
Dans ce commentaire, #JaiDécouvert le site models.dev (https://models.dev) qui est entre autres une alternative à llm-prices.
OpenRouter.ai propose maintenant des embeddings models
Il y a quelques mois, j'ai posté le message suivant sur Reddit et je l'ai aussi envoyé par mail au support OpenRouter :
Bonjour,
Sauf erreur de ma part, openrouter.ai ne semble pas proposer d'API de Vector embeddings, comme
text-embedding-3-smalloutext-embedding-3-larged'OpenAI. Nivoyage-3-large,voyage-3.5, etc d'Anthropic.Quelques questions :
- Y a-t-il une raison technique particulière à cette absence ?
- S'agit-il d'un choix stratégique produit ?
- Cette fonctionnalité est-elle prévue dans votre roadmap ?
Merci pour votre produit, félicitations !
Stéphane
Deux jours plus tard, j'ai eu la réponse mail suivante :
Hi Stéphane,
Thanks for the thoughtful note and for sharing your observations. You're right — embeddings aren’t currently available via OpenRouter.
While I can’t share exact timelines, I can say it's something we’re actively thinking about. We appreciate the interest and are keeping a close eye on demand and technical feasibility.
Thanks again for the kind words and for using OpenRouter.
Le 5 novembre 2025, j'ai eu la bonne surprise de découvrir par mail qu'OpenRouter supporte maintenant des modèles d'embedding :
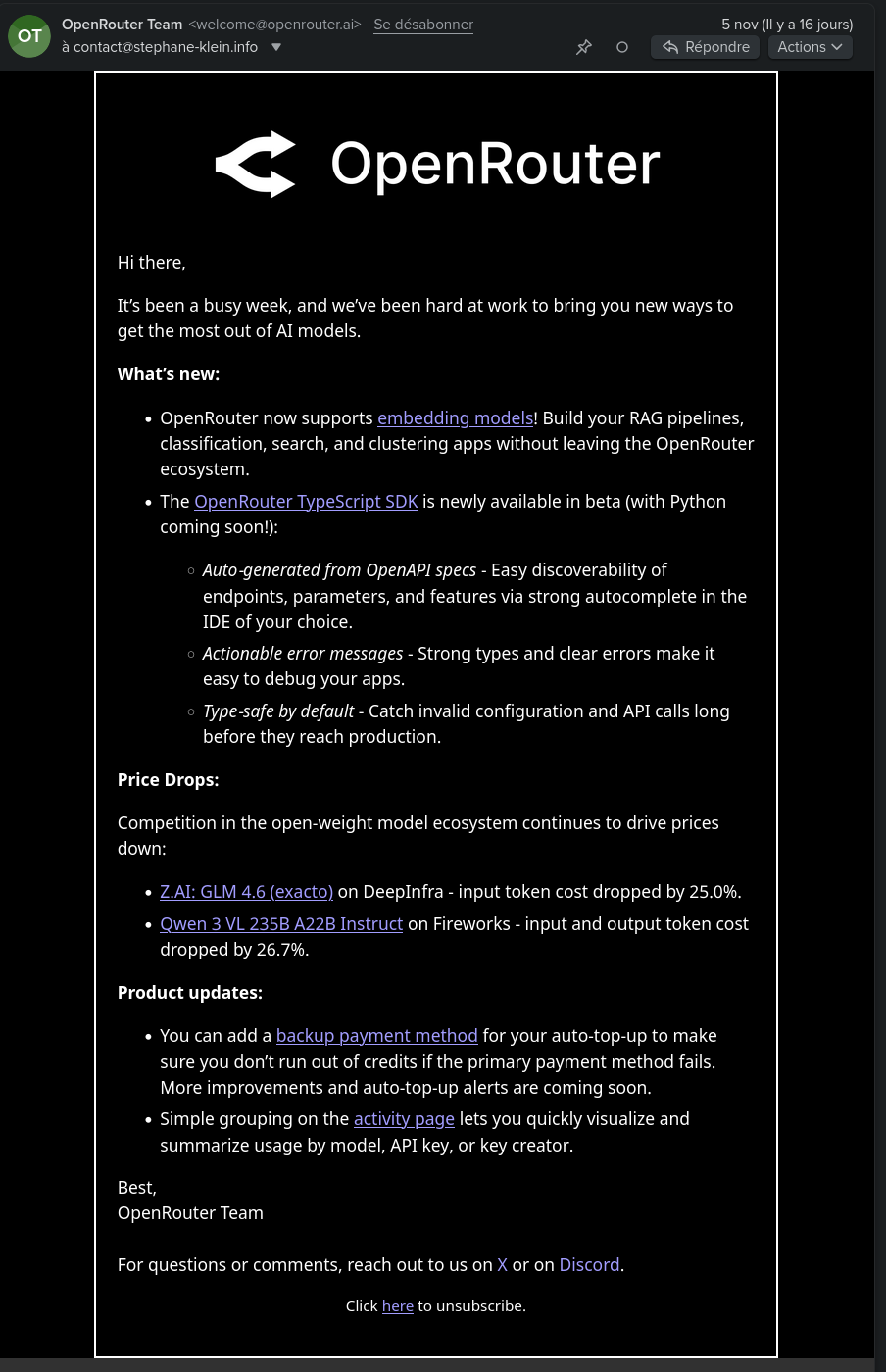
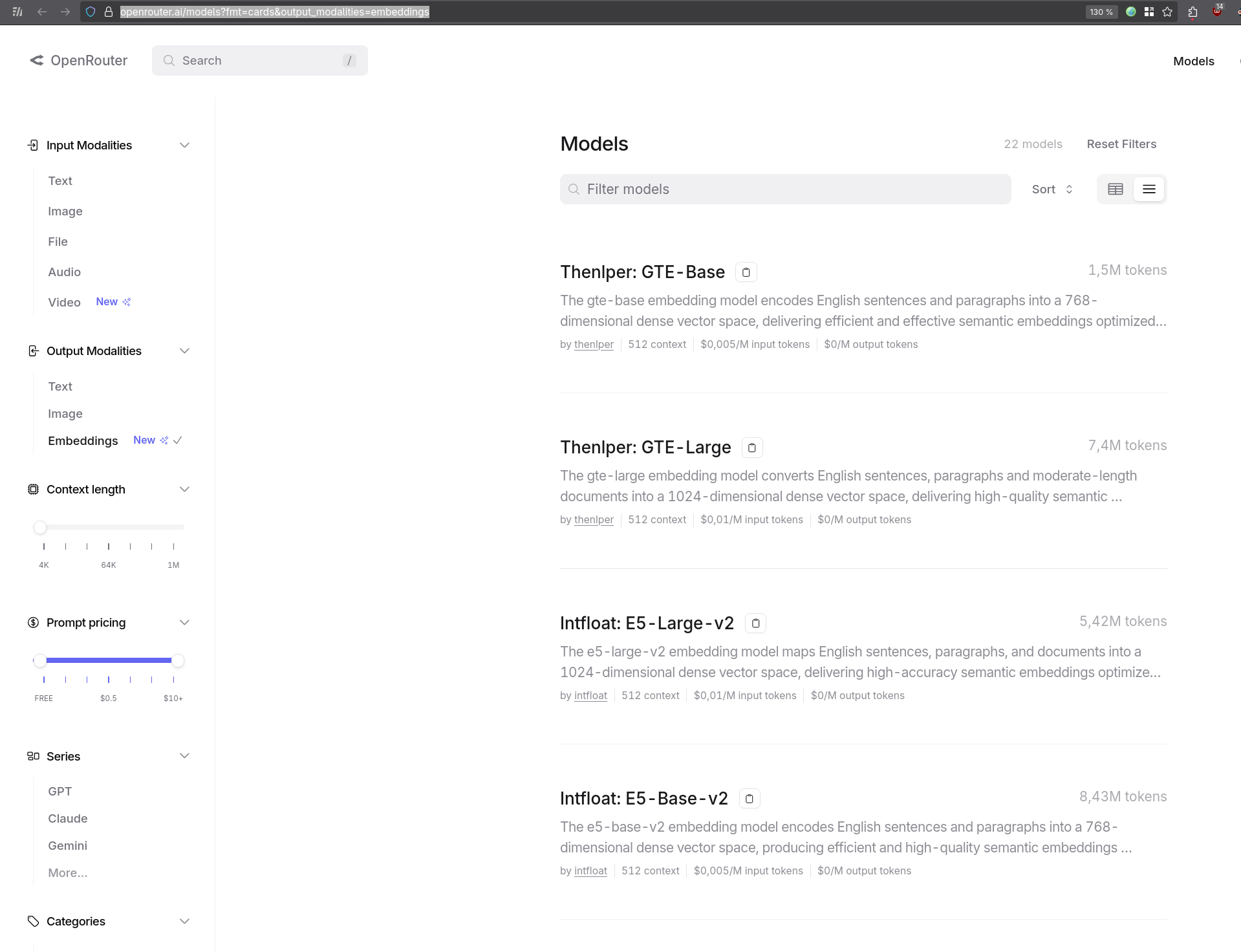
La pages OpenRouter Embeddings Models contient une liste de 22 models :
J'ai posté le message suivant sur Reddit :
OpenRouter a annoncé par mail le 5 novembre 2025 qu'ils supportent maintenant les Embedding models. Leur catalogue compte actuellement 22 modèles, provenant entre autres d'OpenAI, Qwen, Mistral et Google.
Au moment où j'écris ces lignes, cette information ne figure pas encore sur https://openrouter.ai/announcements.
Journal du vendredi 21 novembre 2025 à 12:03
Dans ce thread, #JaiDécouvert OpenCode (https://github.com/sst/opencode) qui semble être une alternative à Aider et Claude Code.
Après avoir parcouru la documentation, j'ai l'impression qu'OpenCode propose des fonctionnalités et une User experience plus avancées qu'Aider.
Le projet est récent (démarré en mars 2025) et publié sous licence MIT.
D'après le footer du site de documentation, je comprends qu'OpenCode est développé par l'entreprise Anomaly, financée par du Venture capital.
#JaiLu ce commentaire à propos d'OpenCode dans les issues d'Aider.
En cherchant sur Hacker News, je suis tombé sur ce thread de juillet 2025.
J'ai retenu ce commentaire :
Two big differences:
opencode is much more "agentic": It will just take off and do loads of stuff without asking, whereas aider normally asks permission to do everything. It will make a change, the language server tells it the build is broken, it goes and searches for the file and line in the error message, reads it, and tries to fix it; rinse repeat, running (say) "go vet" and "go test" until it doesn't see anything else to do. You can interrupt it, of course, but it won't wait for you otherwise.
aider has much more specific control over the context window. You say exactly what files you want the LLM to be able to see and/or edit; and you can clear the context window when you're ready to move on to the next task. The current version of opencode has a way to "compact" the context window, where it summarizes for itself what's been done and then (it seems) drops everything else. But it's not clear exactly what's in and out, and you can't simply clear the chat history without exiting the program. (Or if you can, I couldn't find it documented anywhere.)
Je retiens donc qu'Aider offre un contrôle plus précis qu'OpenCode. OpenCode fonctionne de manière plus autonome.
Pour ma part, je préfère contrôler finement les actions d'un AI code assistant sur mon code, à la fois pour comprendre ses interventions et pour gérer ma consommation de tokens.
Je n'ai pas envie de tester OpenCode pour le moment, je vais continuer avec Aider.
Journal du dimanche 16 novembre 2025 à 13:25
Dans la vidéo de Monsieur Phi "L'autonomie des IA expliquée aux humains", #JaiDécouvert le service Mammouth, qui me rappelle un peu OpenRouter.
J'ai pris un abonnement d'un mois à 12 € TTC pour tester le service. Pour l'instant, je pense continuer avec le couple Open WebUI et OpenRouter qui me donne accès à plus de modèles et plus de flexibilité.
L'objectif produit de Mammouth ressemble pas mal au projet Albert Conversation sur lequel j'ai travaillé à la DINUM entre avril et août 2025.
Journal du dimanche 16 novembre 2025 à 11:06
Je viens d'écouter une nouvelle vidéo de Monsieur Phi au sujet des LLM : "L'autonomie des IA expliquée aux humains". Je l'ai trouvée excellente, tout comme celle que j'avais mentionnée dans la note de décembre 2024.
J'ai apprécié tout particulièrement :
- L'analogie du « Le paradigme du micro-trottoir », que je trouve frapante.
- La présentation de l'étude de METR sur la progression exponentielle de la capacité à résoudre des tâches longues.
- La présentation des résultats du concours AtCoder, expliquée par Passe-Science.
- La présentation de l'article sur l'émergence de désalignement quand on entraîne un modèle sur du code vulnérable : https://www.emergent-misalignment.com.
- La présentation de l'article sur la falsification d'alignement et Claude soucieux du bien-être animal : https://www.anthropic.com/research/alignment-faking.
J'ai découvert que le livre de Monsieur Phi, "La parole aux machines - Philosophie des grands modèles de langage" est enfin sorti ! Je viens de l'acheter 🙂.
Équivalence de l'empreinte carbone de l'entrainement de Mistral Large 2
#JaiLu cet article à propos de l'impact environnemental de Mistral Large 2 : « Notre contribution pour la création d'un standard environnemental mondial pour l'IA ».
Bien que cet article ne propose aucun lien vers le rapport complet, le fait que l'étude ait été menée en collaboration avec Carbon 4 me donne confiance. D'autant que Carbon 4 a publié un article dédié sur leur site : « Nouveau jalon dans la transparence environnementale de l'IA générative ».
Dans une note du 14 juillet 2025, j'ai écrit :
Pour Claude Sonnet 3.7 que j'ai fréquemment utilisé, je lis ceci :
- 100 in => 100 out : 0.4g
- 1k in => 1k out : 1g
- 10k in => 10k out : 2g
L'étude de Mistral AI indique un peu plus du double d'émission de CO2 pour l'inférence :
Les impacts marginaux de l'inférence, plus précisément l'utilisation de notre assistant IA Le Chat pour une réponse de 400 tokens:
- 1,14 gCO₂e
- 45 mL d'eau
- 0,16 mg de Sb eq.
1 g pour 1000 tokens versus 1,14g pour 400 tokens.
Concernant l'entrainement de Mistral Large 2, je retiens ceci :
L'empreinte environnementale de l'entraînement de Mistral Large 2 : en janvier 2025, et après 18 mois d'utilisation, Large 2 a généré les impacts suivants :
- 20,4 ktCO₂e,
- 281 000 m3 d'eau consommée, et
- 660 kg Sb eq (unité standard pour l'épuisement des ressources).
Si j'applique le référentiel de ma note du 14 juillet 2025, cette émission de CO2 lors de l'entraînement représente 115 606 trajets aller-retour Paris - Crest-Voland (Savoie) effectués avec ma voiture.
Détail du calcul : 20×1000×1000 / 173 = 115 606.
Voici une estimation grossière pour établir une comparaison.
D'après ce rapport , 8% des Français partent au ski chaque année, soit environ 5 millions de personnes (68 000 000 * 0,08 = 5 440 000).
Selon cet article BFMTV , 90% d'entre elles s'y rendent en voiture.
En supposant 4 personnes par véhicule, cela représente 1,2 million de voitures (5 440 000 * 0,9 / 4 = 1224000).
Si la moitié effectue un trajet de 500 km x 2 (aller-retour), j'obtiens 600 000 trajets.
En reprenant l'estimation d'émission de ma voiture pour cette distance, le calcul donne 600 000 * 172 kg = 103 200 000 kg, soit 130 kt de CO2, ce qui représente plus de 6 fois l'entraînement de Mistral Large 2.
Pour résumer cette Estimation de Fermi : les déplacements des parisiens vers les Alpes pour une saison de ski émettent probablement 6 fois plus de CO2 que l'entraînement de Mistral Large 2.
Dans cette note, mon but n'est pas de justifier l'intérêt de cet entraînement. Je cherchais plutôt à avoir des points de repère et des comparaisons pour mieux évaluer cet impact.
J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes
Un ami m'a posé la question suivante :
J'aimerais ton avis sur l'utilisation des LLM au quotidien (hors code). Les utilises-tu ? En tires-tu quelque chose de positif ? Quelles en sont les limites ?
Je vais tenter de répondre à cette question dans cette note.
Danger des LLMs : le risque de prolétarisation
Mon père et surtout mon grand-père m'ont inculqué par tradition familiale la valeur du savoir-faire. Plus tard, Bernard Stiegler m'a donné les outils théoriques pour comprendre cet enseignement à travers le concept de processus de prolétarisation.
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Ici, j'utilise la définition de prolétaire suivante :
Personne qui ne possède plus ses savoirs, desquels elle a été dépossédée par l’utilisation d’une technique.
En analysant mon parcours, je réalise que ma quête d'autonomie technique et de compréhension — en somme, ma recherche d'émancipation — a systématiquement guidé mes choix, comme le fait d'avoir pris le chemin du logiciel libre en 1997.
Sensibilisé à ces questions, j'ai immédiatement perçu les risques dès que j'ai découvert la puissance des LLM mi 2023 .
J'utilise les LLMs comme des amis expert d'un domaine
Les LLMs sont pour moi des pharmakons : ils sont à la fois un potentiel remède et un poison. J'essaie de rester conscient de leurs toxicités.
J'ai donc décidé d'utiliser les IA générative de texte comme je le ferais avec un ami expert d'un domaine.
Concrètement, je continue d'écrire la première version de mes notes, mails, commentaires, messages de chat ou issues sans l'aide d'IA générative de texte.
C'est seulement dans un second temps que je consulte un LLM, comme je le ferais avec un ami expert : pour lui demander un commentaire, lui poser une question ou lui demander une relecture.
J'utilise les IA générative de texte par exemple pour :
- vérifier si mon texte est explicite et compréhensible
- obtenir des suggestions d'amélioration de ma rédaction
Tout comme avec un ami, je lui partage l'intégralité de mon texte pour donner le contexte, et ensuite je lui pose des questions ciblées sur une phrase ou un paragraphe spécifique. Cette méthode me permet de mieux cadrer ses réponses.
À ce sujet, voir mes notes suivantes :
- Idée d'application de réécriture de texte assistée par IA
- Prompt - Reformulation de paragraphes pour mon notes.sklein.xyz
Par respect pour mes interlocuteurs, je ne demande jamais à un LLM de rédiger un texte à ma place.
 (source)
(source)
Lorsque je trouve pertinent un contenu produit par un LLM, je le partage en tant que citation en indiquant clairement la version du modèle qui l'a généré. Je le cite comme je citerai les propos d'un humain.
En résumé, je ne m'attribue jamais les propos générés par un LLM. Je n'utilise jamais un LLM comme un écrivain fantôme.
Seconde utilisation : exploration de sujets
J'utilise aussi les LLMs pour explorer des sujets.
Je dirais que cela me permet de faire l'expérience de ce que j'appellerais "de la sérendipité dirigée".
Par exemple, je lui expose une idée et comme à un ami, je lui demande si cela a du sens pour lui, qu'est-ce que cela lui évoque et très souvent, je découvre dans ses réponses des auteurs ou des concepts que je n'ai jamais entendus parler.
J'utilise beaucoup les LLMs pour obtenir un "overview" avec une orientation très spécifique, sur des sujets tech, politique, historique…
Je l'utilise aussi souvent pour comprendre l'origine des noms des projets, ce qui me permet de mieux m'en souvenir.
Voir aussi cette note que j'ai publiée en mai 2024 : Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo.
Les limites ?
En matière d'exploration, je pense que les LLMs sont d'une qualité exceptionnelle pour cette tâche. Je n'ai jamais expérimenté quelque chose d'aussi puissant. Peut-être que j'obtiendrais de meilleurs résultats en posant directement des questions à des experts mondiaux dans les domaines concernés, mais la question ne se pose pas puisque je n'ai pas accès à ces personnes.
Pour l'aide à la rédaction, il me semble que c'est nettement plus efficace que ce qu'un ami serait en mesure de proposer. Même si ce n'est pas parfait, je ne pense pas qu'un LLMs soit en mesure de deviner précisément, par lui-même, ce que j'ai l'intention d'exprimer. Il n'y a pas de magie : il faut que mes idées soient suffisamment claires dans mon cerveau pour être formulées de façon explicite. En ce qui concerne ces tâches, je constate d'importantes différences entre les modèles. Actuellement, Claude Sonnet 4 reste mon préféré pour la rédaction En revanche, j'obtiens de moins bons résultats avec les modèles chain-of-thought, ce qui est sans doute visible dans les LLM Benchmark.
Par contre, dès que je m'éloigne des questions générales pour aborder la résolution de problèmes précis, j'obtiens pour le moment des résultats très faibles. Je remarque quotidiennement des erreurs dans le domaine tech, comme :
- des paramètres inexistants
- des parties de code qui ne s'exécutent pas
- ...
Comment a évolué mon utilisation des LLMs depuis 2023 ?
J'ai publié sur https://data.sklein.xyz mes statistiques d'utilisation des LLMs de janvier 2023 à mai 2025.
Ces statistiques ne sont plus représentatives à partir de juin 2025, parce que j'ai commencé à utiliser fortement Open WebUI couplé à OpenRouter et aussi LMArena. J'aimerais prendre le temps d'intégrer les statistiques de ces plateformes prochainement.
Comme on peut le voir sur https://data.sklein.xyz, mon usage de ChatGPT a réellement démarré en avril 2024, pour évoluer vers une consommation mensuelle d'environ 300 threads.
Je suis surpris d'avoir si peu utilisé ChatGPT entre avril 2023 et janvier 2024 🤔. Je l'utilisais peut-être en mode non connecté et dans ce cas, j'ai perdu toute trace de ces interactions.
Voir aussi ma note : Estimation de l'empreinte carbone de mon usage des IA génératives de textes.
Combien je dépense en inférence LLM par mois ?
De mars à septembre 2024, 22 € par mois pour ChatGPT.
De mars à mai 2025, 22 € par mois pour Claude.ai.
Depuis juin 2025, je pense que je consomme moins de 10 € par mois, depuis que je suis passé à OpenRouter. Plus d'informations à ce sujet dans : Quelle est mon utilisation d'OpenRouter.ia ?
J'aurais encore beaucoup à dire sur le sujet des LLMs, mais j'ai décidé de m'arrêter là pour cette note.
Pour aller plus loin sur ce sujet, sous un angle très technique, je conseille cette série d'articles sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
Et toutes mes notes associées au tag : #llm
Journal du mardi 15 juillet 2025 à 22:53
Je viens de poser la question suivante ici sur Reddit et aussi par e-mail à support@openrouter.ai
Bonjour,
Sauf erreur de ma part, openrouter.ai ne semble pas proposer d'API de Vector embeddings, comme
text-embedding-3-smalloutext-embedding-3-larged'OpenAI. Nivoyage-3-large,voyage-3.5, etc d'Anthropic.Quelques questions :
- Y a-t-il une raison technique particulière à cette absence ?
- S'agit-il d'un choix stratégique produit ?
- Cette fonctionnalité est-elle prévue dans votre roadmap ?
Merci pour votre produit, félicitations !
Stéphane
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
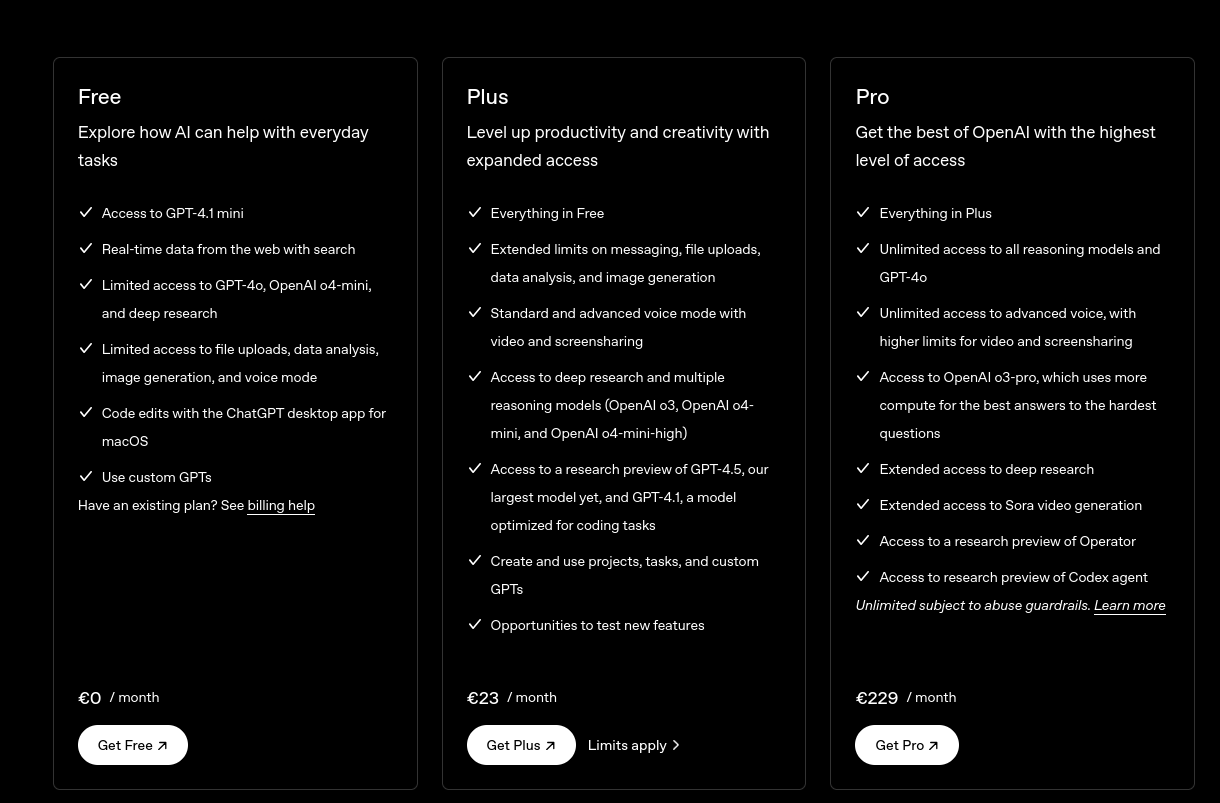
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
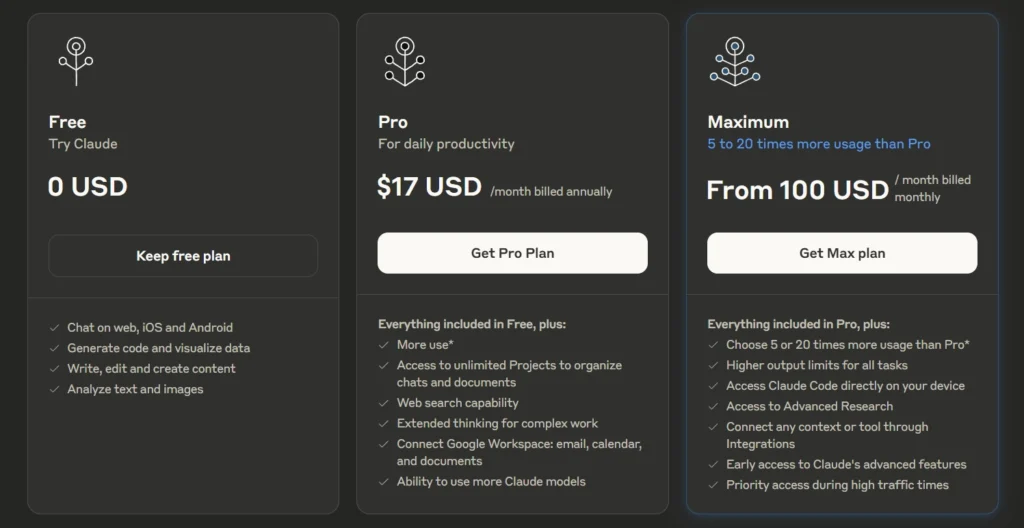
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Estimation de l'empreinte carbone de mon usage des IA génératives de textes
Je pense avoir entendu : « Une requête ChatGPT consomme l'équivalent de 10 recherches conventionnelles Google ! ».
Problème : je ne retrouve plus la source et cette comparaison me paraît manquer de rigueur. Par exemple, elle ne prend pas en compte le volume de tokens traités en entrée et en sortie.
Aujourd'hui, j'ai cherché à en savoir plus sur ce sujet et à vérifier cette déclaration.
J'ai d'abord cherché des informations sur l'émission de CO2 d'une recherche conventionnelle Google et j'ai trouvé ceci :
In 2009, The Guardian published an article about the carbon cost of Google search. Google had posted a rebuttal to the claim that every search emits 7 g of CO2 on their blog. What they claimed was that, in 2009, the energy cost was 0.0003 kWh per search, or 1 kJ. That corresponded to 0.2 g CO2, and I think that was indeed a closer estimate.
Si ma déclaration précédente est valide et qu'une recherche conventionnelle Google génère 0,2 g de CO2, alors une requête sur une IA générative de texte devrait sans doute produire environ 2g de CO2.
Attention, ces chiffres datent de 2009 : Google a probablement gagné en efficacité énergétique, mais a probablement aussi complexifié son algorithme.
En attendant de trouver des données plus récentes, j'ai choisi de partir de cette estimation pour cette note.
Ensuite, je me suis lancé dans des recherches sur l'estimation de la consommation CO2 des IA génératives de texte. J'ai effectué des recherches sur arXiv et je suis tombé sur cet article "How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference" qui date de mai 2025.
J'y ai trouvé ces graphes d'émission de CO2 par modèle en fonction du nombre de tokens en entrée et en sortie :

Pour Claude Sonnet 3.7 que j'ai fréquemment utilisé, je lis ceci :
- 100 in => 100 out : 0.4g
- 1k in => 1k out : 1g
- 10k in => 10k out : 2g
J'en conclus que l'ordre de grandeur de la déclaration que j'ai entendu semble réaliste.
(Mise à jour du 31 juillet : Mistral IA indique 1,14g pour 400 tokens pour Mistral Large 2)
En mai 2025, mes 299 threads ont consommé 19 129 tokens en entrée, soit 63 tokens par thread en moyenne. Mon usage d'IA générative de texte ce mois-là aurait généré approximativement 299 x 0,4g = 119g de CO2.
Pour mettre cela en perspective, j'ai estimé les émissions d'un trajet aller-retour Paris - Crest-Voland (Savoie) avec ma voiture :
- Trajet total :
620 km x 2=1240 km - Émissions constructeur (Dacia Sandero Stepway) : 140g CO2/km en WLTP en cycle mixte
Résultat : 1240km x 140g = 173 kg de CO2 pour mes déplacements hivernaux en Savoie.
Un seul voyage correspond à 121 ans de mon utilisation mensuelle actuelle d'IA générative de texte.
Mise à jour de 31 juillet, voir aussi : Équivalence de l'empreinte carbone de l'entrainement de Mistral Large 2.
Journal du samedi 05 juillet 2025 à 15:38
Je viens d'écouter la dernière vidéo de Monsieur Phi : Comment parler intelligemment d'intelligence ?.
Comme toujours avec Thibaut Giraud, une vidéo qui donne matière à pensée.
Ce qui m'a particulièrement intéressé, c'est d'en savoir plus au sujet de ARC-AGI et ARC-AGI-2. Benchmark que j'avais découvert en décembre 2024.
J'ai passé un peu de temps à analyser le leaderboard de ARC-AGI : https://arcprize.org/leaderboard.
Voici le sommaire de cette vidéo :
- 0:00 - Intro
- 0:50 - Sponso NordVPN
- 2:16 - Des étincelles d'intelligence générale dans GPT-4
- 6:40 - Nous sommes médiocres en tout (et c'est très fort)
- 9:21 - L'intelligence selon François Chollet
- 11:52 - Les benchmarks usuels ne testent que la mémorisation 14:51 - ARC-AGI : un test de QI pour IA
- 17:36 - Les LLM échouent lamentablement
- 20:04 - Les modèles de raisonnement font une percée
- 23:53 - Détour par d'autres benchmarks (Codeforces et Humanity's Last Exam)
- 27:29 - Des progrès en maths : FrontierMaths et AlphaEvolve
- 30:16 - Des CoT à n'en plus finir
- 32:55 - ARC-AGI-2 le retour
- 35:09 - Leaderboard actuel
- 37:55 - Conclusion + outro
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité Structured Outputs (LLM) (https://platform.openai.com/docs/guides/structured-outputs)
Journal du dimanche 22 juin 2025 à 15:02
Je viens de découvrir les quatre premiers articles de la série "Nouvelle sur l'IA" sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
L'auteur de ces articles indique en introduction :
Avertissement : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz.
Je viens d'ajouter ces deux feed à ma note "Mes sources de veille en IA".
Prise de note de lecture de : Nouvelles sur l’IA de février 2025
Je découvre la signification de l'acronyme STEM : Science, technology, engineering, and mathematics.
Une procédure standard lors de la divulgation d’un nouveau modèle (chez OpenAI en tout cas) est de présenter une "System Card", aka "à quel point notre modèle est dangereux ou inoffensif".
#JaiDécouvert le concept de System Card, concept qui semble avoir été introduit par Meta en février 2022 : « System Cards, a new resource for understanding how AI systems work » (je n'ai pas lu l'article).
#JaiDécouvert ChatGPT Deep Research.
Je retiens :
Derya Unutmaz, MD: J'ai demandé à Deep Researchh de m'aider sur deux cas de cancer plus tôt aujourd'hui. L'un était dans mon domaine d'expertise et l'autre légèrement en dehors. Les deux rapports étaient tout simplement impeccables, comme quelque chose que seul un médecin spécialiste pourrait écrire ! Il y a une raison pour laquelle j'ai dit que c'est un changement radical ! 🤯
Et
Je suis quelque peu déçu par Deep Research d'@OpenAI. @sama avait promis que c'était une avancée spectaculaire, alors j'y ai entré la plainte pour notre procès guidé par o1 contre @DCGco et d'autres, et lui ai demandé de prendre le rôle de Barry Silbert et de demander le rejet de l'affaire.
Malheureusement, bien que le modèle semble incroyablement intelligent, il a produit des arguments manifestement faibles car il a fini par utiliser des données sources de mauvaise qualité provenant de sites web médiocres. Il s'est appuyé sur des sources comme Reddit et ces articles résumés que les avocats écrivent pour générer du trafic vers leurs sites web et obtenir de nouveaux dossiers.
Les arguments pour le rejet étaient précis dans le contexte des sites web sur lesquels il s'est appuyé, mais après examen, j'ai constaté que ces sites simplifient souvent excessivement la loi et manquent des points essentiels des textes juridiques réels.
#JaiDécouvert qu'il est possible de configurer la durée de raisonnement de Clause Sonnet 3.7 :
Aujourd'hui, nous annonçons Claude Sonnet 3.7, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi instantanées ou une réflexion approfondie, étape par étape, qui est rendue visible à l'utilisateur. Les utilisateurs de l'API ont également un contrôle précis sur la durée de réflexion accordée au modèle.
#JaiDécouvert que l'offre LLM par API de Google se nomme Vertex AI.
#JaiDécouvert que les System Prompt d'Anthropic sont publics : https://docs.anthropic.com/en/release-notes/system-prompts#feb-24th-2025
J'ai trouvé la section "Gradual Disempowerement" très intéressante. #JaimeraisUnJour prendre le temps de faire une lecture active de l'article : Gradual Disempowerment.
Je viens de consacrer 1h30 de lecture active de l'article de février 2025. Je le recommande fortement pour ceux qui s'intéressent au sujet. Merci énormément à son auteur Moonz.
Je vais publier cette note et ensuite commencer la lecture de l'article de mars 2025.
Journal du dimanche 22 juin 2025 à 12:43
Je viens de découvrir sur LMArena un nouveau LLM développé par Google : flamesong.
Pour le moment, ce thread est la seule information que j'ai trouvé à ce sujet : https://old.reddit.com/r/Bard/comments/1lg48l9/new_model_flaamesong/.
Toujours via LMArena, j'ai découvert le modèle MinMax-M1 développé par une équipe basé à Singapore.
Journal du samedi 21 juin 2025 à 13:21
Dans la page Models Overview de Mistral AI, j'ai été surpris de ne pas trouver de Mistral Large dans la liste des "Premier models" 🤔.
Tous les modèles "Large" sont dans la liste des modèles dépréciés :
| Model | Deprecation on date | Retirement date | Alternative model |
|---|---|---|---|
| Mistral Large 24.02 | 2024/11/30 | 2025/06/16 | mistral-medium-latest |
| Mistral Large 24.07 | 2024/11/30 | 2025/03/30 | mistral-medium-latest |
| Mistral Large 24.11 | 2025/06/10 | 2025/11/30 | mistral-medium-latest |
Je me demande pourquoi il est remplacé par le modèle Mistral Medium 🤔.
Je découvre dans la note de release de Mistral Medium 3 :
Medium is the new large
Mistral Medium 3 delivers state-of-the-art performance at 8X lower cost with radically simplified enterprise deployments.
...
All the way from Mistral 7B, our models have consistently demonstrated performance of significantly higher-weight and more expensive models. And today, we are excited to announce Mistral Medium 3, pushing efficiency and usability of language models even further.
Je pense que Mistral Large sortie en juillet 2024 suis l'ancien paradigme « entraîner de plus gros modèle sur plus de données », alors que Mistral Medium sorti en mai 2025 suis le nouveau paradigme chain-of-thought (CoT) et que c'est pour cela que pour le moment Mistral AI ne propose plus de modèles très larges.
À titre de comparaison, j'ai lu que Mistral Large 2 avait une taille de 123 milliards de paramètres, alors que Mistral Medium 3 a une taille estimée de 50 milliards de paramètres.
Journal du samedi 21 juin 2025 à 12:45
Dans ce commentaire, #JaiDécouvert la page Models Table de LifeArchitect.ai d'Alan D. Thompson.
La page contient énormément d'information à propos des LLM !
Bien que je ne sois pas sûr de moi, pour le moment, je classe cette page dans la catégorie des leaderboard.
Journal du vendredi 20 juin 2025 à 17:28
#JaiDécouvert un autre leaderboard : Political Email Extraction Leaderboard (from).
Journal du vendredi 20 juin 2025 à 16:37
#JaiDécouvert "Leaderboard des modèles de langage pour le français" : https://fr-gouv-coordination-ia-llm-leaderboard-fr.hf.space
C’est dans cette dynamique que la Coordination Nationale pour l’IA, le Ministère de l’Éducation nationale, Inria, le LNE et GENCI ont collaboré avec Hugging Face pour créer un leaderboard de référence dédié aux modèles de langage en français. Cet outil offre une évaluation de leurs performances, de leurs capacités et aussi de leurs limites.
Journal du vendredi 20 juin 2025 à 15:49
Il y a quelques mois, j'ai publié la note : J'ai découvert « Timeline of AI model releases in 2024 ».
Aujourd'hui, #JaiDécouvert le site The Road To AGI 2015 - 2025 (https://ai-timeline.org/).
Ce projet est Open source, voici son repository : jam3scampbell/ai-timeline.

Il me permet d'avoir une d'ensemble des publications des 6 premiers mois de l'année 2025 :
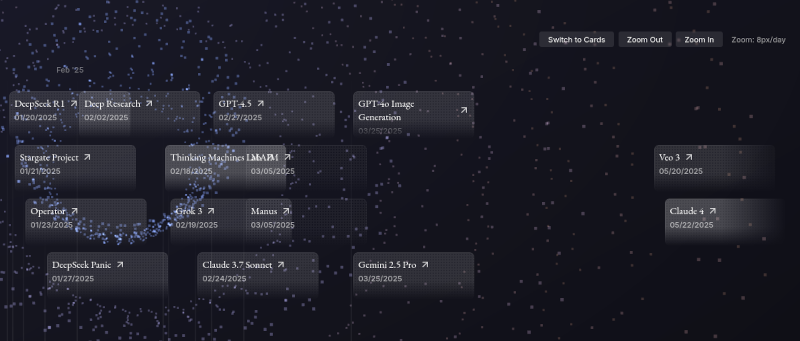
Bien que la réalisation de ce site soit techniquement réussie, après utilisation, je trouve qu'une simple liste Wikipedia répond mieux à mes besoins : https://en.wikipedia.org/wiki/List_of_large_language_models
Alexandre m'a partagé le projet LocalAI (https://localai.io/).
Ce projet a été mentionné une fois sur Lobster dans un article intitulé Everything I’ve learned so far about running local LLMs, et quatre fois sur Hacker News (recherche pour "localai.io"), mais avec très peu de commentaires.
C’est sans doute pourquoi je n'ai jamais remarqué ce projet auparavant.
Pourtant, il ne s’agit pas d’un projet récent : son développement a débuté en mars 2023.
J'ai l'impression que LocalAI propose à la fois des interfaces web comme Open WebUI, mais qu'il est aussi une sorte de "wrapper" au-dessus de nombreux Inference Engines comme l'illustre cette longue liste.
Pour le moment, j'ai vraiment des difficultés à comprendre son positionnement dans l'écosystème.
LocalAI versus vLLM ou Ollama ? LocalAI versus Open WebUI ?, etc.
Je vais garder ce projet dans mon radar.
Journal du jeudi 12 juin 2025 à 15:51
Je viens de publier : Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter".
Journal du mercredi 21 mai 2025 à 14:25
#JaiDécouvert le concept de LLM-as-a-Judge.
#JaiLu l'article Wikipédia à ce sujet "LLM-as-a-Judge".
"Abstract" du papier de recherche Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena datant du 24 décembre 2023 :
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, including position, verbosity, and self-enhancement biases, as well as limited reasoning ability, and propose solutions to mitigate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and [[Chatbot Arena]], a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA and Vicuna. The MT-bench questions, 3K expert votes, and 30K conversations with human preferences are publicly available at https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge.
J'ai parcouru rapidement l'article "Evaluating RAG with LLM as a Judge" du blog de Mistral AI. Je n'ai pas pris le temps d'étudier les concepts que je ne connaissais pas dans cet article, par exemple RAG Triad.
J'ai effectué une recherche sur « LLM as Judge » sur le blog de Simon Willison.
Journal du jeudi 15 mai 2025 à 11:59
Un ami m'a partagé la chaine YouTube "Le lab du vieux geek" :
Chaine YouTube consacrée à l'IA l'IT la culture Geek et de nombreux autres sujets autour de l'IA. Je m'appelle Jerome Fortias, je suis français vivant en Belgique, et j'ai utilisé mon premier robot en 1986, depuis je travaille dans le monde de l'IT et de l'IA. Cette chaine c'est un peu une expérimentation d'un youtuber amateur.
J'ai écouté "La fin des LLM (Yann LeCun a raison)" et ensuite "Comment les machines pourraient-elles atteindre l'intelligence humaine ? Conférence de Yann LeCun".
Énormément de contenu, j'en ai saisi qu'une petite partie.
#JaimeraisUnJour prendre le temps de lire les 509 commentaires sous la vidéo "La fin des LLM (Yann LeCun a raison)".
L'écoute de ces vidéos m'a fait penser aux vidéos suivantes de Thibault Neveu que j'ai écoutées il y a un an :
Journal du mardi 25 février 2025 à 23:29
#JaiDécouvert cette page web qui permet de savoir quel LLM peut être exécuté sur une machine en particuler : https://canirunthisllm.com/ll
Vous êtes sur la première page | [ Page suivante (68) >> ]