
LinuxFr
Journaux liées à cette note :
Mes observations sur la popularité historique des langages de programmation
Un ami m'a partagé la vidéo Most Popular Programming Languages: Data from 1958 to 2025 (Most Popular Programming Languages). Pour quelqu'un comme moi qui a une grande curiosité pour l'histoire de l'informatique, c'est amusant de regarder ça 🙂.
J'ai lu la description de la vidéo pour essayer d'en savoir plus sur la véracité de ce qui est présenté :
Dans cette vidéo, je présente une chronologie détaillée des langages de programmation les plus utilisés de 1958 à 2025, basée sur une analyse approfondie des données. Les classements historiques reposent sur une combinaison d'enquêtes nationales agrégées, du nombre de livres pédagogiques publiés sur chaque langage, et de la fréquence à laquelle ces langages sont mentionnés dans les publications mondiales dédiées aux logiciels et aux technologies. Pour les années récentes, les classements ont été ajustés à partir de données issues de plusieurs indices de popularité des langages de programmation, des tendances d'accès aux dépôts GitHub, et d'enquêtes auprès des développeurs.
La popularité dans ce classement est définie par le nombre de développeurs maîtrisant ou apprenant activement chaque langage. L'échelle est normalisée sur une valeur relative de 100, permettant des comparaisons cohérentes entre les langages et les périodes.
L'emoji flamme représente les langages qui ont atteint la première place au moins une fois. L'emoji tête de mort représente les langages qui ne sont plus officiellement maintenus et ne disposent plus d'une communauté de développeurs active.
Plusieurs erreurs ont été corrigées par rapport à la vidéo précédente. J'ai également étendu la chronologie de près d'une décennie, en remontant à 1958, et ajouté de nouvelles données pour 2023, 2024 et 2025.
Vos retours sont toujours les bienvenus. Une suggestion de sujet ? Envoyez-moi un message !
Quelques observations personnelles sur l'évolution des langages présentés dans la vidéo :
- Fortran et Cobol : Je pensais que Cobol était dominant, mais je découvre que non, je suis surpris, Fortran semble avoir toujours été devant. J'ai toujours beaucoup plus entendu parler de Cobol que Fortran.
- Pascal : L'un de mes premiers amours en programmation, avant Python. Je n'imaginais pas que Pascal avait été numéro 1 à partir de 1980.
J'observe que quand j'ai appris Pascal vers 1991-1992, le langage C l'avait déjà dépassé depuis 1985. - Ada : Je ne m'attendais pas à le voir aussi populaire à la fin des années 1980, et encore moins à le voir passer devant Pascal en 1988. Et au passage, un langage conçu par Jean Ichbiah, un Français, au sein de CII-Honeywell-Bull : une entreprise à capitaux mixtes franco-américains — sur commande du Pentagone.
- C : C'est impressionnant de voir comment C a tout écrasé de 1990 à 1995 !
- Perl : Il a eu sa petite heure de gloire jusqu'en 1997, avant l'arrivée de PHP. C'était juste avant que je commence le développement web. En regardant l'évolution de Perl dans la vidéo, on devine assez bien comment Java et PHP ont ensuite tué Perl sur le web.
- Visual Basic : Curieusement, il n'a jamais vraiment dominé malgré les apparences. À la fin des années 1990, j'avais pourtant l'impression que tout le monde en faisait.
- Java et PHP : C'est au début de ma carrière professionnelle, en 2001, que Java commence à être hégémonique. Mais ce qui est intéressant, c'est de voir PHP se défendre très bien face à lui.
- Python : Il commence à monter en 2006, ce qui correspond exactement à l'année où je commence à me perfectionner sérieusement dans ce langage.
- Javascript : En 2012, j'avais clairement senti une forte montée en puissance de JS avec l'arrivée de NodeJS — j'avais même publié Réflexions à propos de Node.js et de JavaScript plus globalement le 18 avril 2012 sur LinuxFr.
- Python vs Javascript : Je suis vraiment surpris de voir Python doubler JavaScript en 2017, puis Java en 2018. J'imagine que cela doit être l'effet de l'IA — TensorFlow et compagnie. Je suis surpris de constater que Javascript n'a jamais été numéro 1 !
- Golang : J'ai commencé à l'utiliser en 2015, et je suis content de voir qu'il pointe le bout de son nez dans le top 12 en 2019. J'ai une sorte d'affection pour ce langage, j'apprécie beaucoup ses valeurs.
J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes
Un ami m'a posé la question suivante :
J'aimerais ton avis sur l'utilisation des LLM au quotidien (hors code). Les utilises-tu ? En tires-tu quelque chose de positif ? Quelles en sont les limites ?
Je vais tenter de répondre à cette question dans cette note.
Danger des LLMs : le risque de prolétarisation
Mon père et surtout mon grand-père m'ont inculqué par tradition familiale la valeur du savoir-faire. Plus tard, Bernard Stiegler m'a donné les outils théoriques pour comprendre cet enseignement à travers le concept de processus de prolétarisation.
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Ici, j'utilise la définition de prolétaire suivante :
Personne qui ne possède plus ses savoirs, desquels elle a été dépossédée par l’utilisation d’une technique.
En analysant mon parcours, je réalise que ma quête d'autonomie technique et de compréhension — en somme, ma recherche d'émancipation — a systématiquement guidé mes choix, comme le fait d'avoir pris le chemin du logiciel libre en 1997.
Sensibilisé à ces questions, j'ai immédiatement perçu les risques dès que j'ai découvert la puissance des LLM mi 2023 .
J'utilise les LLMs comme des amis expert d'un domaine
Les LLMs sont pour moi des pharmakons : ils sont à la fois un potentiel remède et un poison. J'essaie de rester conscient de leurs toxicités.
J'ai donc décidé d'utiliser les IA générative de texte comme je le ferais avec un ami expert d'un domaine.
Concrètement, je continue d'écrire la première version de mes notes, mails, commentaires, messages de chat ou issues sans l'aide d'IA générative de texte.
C'est seulement dans un second temps que je consulte un LLM, comme je le ferais avec un ami expert : pour lui demander un commentaire, lui poser une question ou lui demander une relecture.
J'utilise les IA générative de texte par exemple pour :
- vérifier si mon texte est explicite et compréhensible
- obtenir des suggestions d'amélioration de ma rédaction
Tout comme avec un ami, je lui partage l'intégralité de mon texte pour donner le contexte, et ensuite je lui pose des questions ciblées sur une phrase ou un paragraphe spécifique. Cette méthode me permet de mieux cadrer ses réponses.
À ce sujet, voir mes notes suivantes :
- Idée d'application de réécriture de texte assistée par IA
- Prompt - Reformulation de paragraphes pour mon notes.sklein.xyz
Par respect pour mes interlocuteurs, je ne demande jamais à un LLM de rédiger un texte à ma place.
 (source)
(source)
Lorsque je trouve pertinent un contenu produit par un LLM, je le partage en tant que citation en indiquant clairement la version du modèle qui l'a généré. Je le cite comme je citerai les propos d'un humain.
En résumé, je ne m'attribue jamais les propos générés par un LLM. Je n'utilise jamais un LLM comme un écrivain fantôme.
Seconde utilisation : exploration de sujets
J'utilise aussi les LLMs pour explorer des sujets.
Je dirais que cela me permet de faire l'expérience de ce que j'appellerais "de la sérendipité dirigée".
Par exemple, je lui expose une idée et comme à un ami, je lui demande si cela a du sens pour lui, qu'est-ce que cela lui évoque et très souvent, je découvre dans ses réponses des auteurs ou des concepts que je n'ai jamais entendus parler.
J'utilise beaucoup les LLMs pour obtenir un "overview" avec une orientation très spécifique, sur des sujets tech, politique, historique…
Je l'utilise aussi souvent pour comprendre l'origine des noms des projets, ce qui me permet de mieux m'en souvenir.
Voir aussi cette note que j'ai publiée en mai 2024 : Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo.
Les limites ?
En matière d'exploration, je pense que les LLMs sont d'une qualité exceptionnelle pour cette tâche. Je n'ai jamais expérimenté quelque chose d'aussi puissant. Peut-être que j'obtiendrais de meilleurs résultats en posant directement des questions à des experts mondiaux dans les domaines concernés, mais la question ne se pose pas puisque je n'ai pas accès à ces personnes.
Pour l'aide à la rédaction, il me semble que c'est nettement plus efficace que ce qu'un ami serait en mesure de proposer. Même si ce n'est pas parfait, je ne pense pas qu'un LLMs soit en mesure de deviner précisément, par lui-même, ce que j'ai l'intention d'exprimer. Il n'y a pas de magie : il faut que mes idées soient suffisamment claires dans mon cerveau pour être formulées de façon explicite. En ce qui concerne ces tâches, je constate d'importantes différences entre les modèles. Actuellement, Claude Sonnet 4 reste mon préféré pour la rédaction En revanche, j'obtiens de moins bons résultats avec les modèles chain-of-thought, ce qui est sans doute visible dans les LLM Benchmark.
Par contre, dès que je m'éloigne des questions générales pour aborder la résolution de problèmes précis, j'obtiens pour le moment des résultats très faibles. Je remarque quotidiennement des erreurs dans le domaine tech, comme :
- des paramètres inexistants
- des parties de code qui ne s'exécutent pas
- ...
Comment a évolué mon utilisation des LLMs depuis 2023 ?
J'ai publié sur https://data.sklein.xyz mes statistiques d'utilisation des LLMs de janvier 2023 à mai 2025.
Ces statistiques ne sont plus représentatives à partir de juin 2025, parce que j'ai commencé à utiliser fortement Open WebUI couplé à OpenRouter et aussi LMArena. J'aimerais prendre le temps d'intégrer les statistiques de ces plateformes prochainement.
Comme on peut le voir sur https://data.sklein.xyz, mon usage de ChatGPT a réellement démarré en avril 2024, pour évoluer vers une consommation mensuelle d'environ 300 threads.
Je suis surpris d'avoir si peu utilisé ChatGPT entre avril 2023 et janvier 2024 🤔. Je l'utilisais peut-être en mode non connecté et dans ce cas, j'ai perdu toute trace de ces interactions.
Voir aussi ma note : Estimation de l'empreinte carbone de mon usage des IA génératives de textes.
Combien je dépense en inférence LLM par mois ?
De mars à septembre 2024, 22 € par mois pour ChatGPT.
De mars à mai 2025, 22 € par mois pour Claude.ai.
Depuis juin 2025, je pense que je consomme moins de 10 € par mois, depuis que je suis passé à OpenRouter. Plus d'informations à ce sujet dans : Quelle est mon utilisation d'OpenRouter.ia ?
J'aurais encore beaucoup à dire sur le sujet des LLMs, mais j'ai décidé de m'arrêter là pour cette note.
Pour aller plus loin sur ce sujet, sous un angle très technique, je conseille cette série d'articles sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
Et toutes mes notes associées au tag : #llm
Journal du dimanche 22 juin 2025 à 15:02
Je viens de découvrir les quatre premiers articles de la série "Nouvelle sur l'IA" sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
L'auteur de ces articles indique en introduction :
Avertissement : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz.
Je viens d'ajouter ces deux feed à ma note "Mes sources de veille en IA".
Prise de note de lecture de : Nouvelles sur l’IA de février 2025
Je découvre la signification de l'acronyme STEM : Science, technology, engineering, and mathematics.
Une procédure standard lors de la divulgation d’un nouveau modèle (chez OpenAI en tout cas) est de présenter une "System Card", aka "à quel point notre modèle est dangereux ou inoffensif".
#JaiDécouvert le concept de System Card, concept qui semble avoir été introduit par Meta en février 2022 : « System Cards, a new resource for understanding how AI systems work » (je n'ai pas lu l'article).
#JaiDécouvert ChatGPT Deep Research.
Je retiens :
Derya Unutmaz, MD: J'ai demandé à Deep Researchh de m'aider sur deux cas de cancer plus tôt aujourd'hui. L'un était dans mon domaine d'expertise et l'autre légèrement en dehors. Les deux rapports étaient tout simplement impeccables, comme quelque chose que seul un médecin spécialiste pourrait écrire ! Il y a une raison pour laquelle j'ai dit que c'est un changement radical ! 🤯
Et
Je suis quelque peu déçu par Deep Research d'@OpenAI. @sama avait promis que c'était une avancée spectaculaire, alors j'y ai entré la plainte pour notre procès guidé par o1 contre @DCGco et d'autres, et lui ai demandé de prendre le rôle de Barry Silbert et de demander le rejet de l'affaire.
Malheureusement, bien que le modèle semble incroyablement intelligent, il a produit des arguments manifestement faibles car il a fini par utiliser des données sources de mauvaise qualité provenant de sites web médiocres. Il s'est appuyé sur des sources comme Reddit et ces articles résumés que les avocats écrivent pour générer du trafic vers leurs sites web et obtenir de nouveaux dossiers.
Les arguments pour le rejet étaient précis dans le contexte des sites web sur lesquels il s'est appuyé, mais après examen, j'ai constaté que ces sites simplifient souvent excessivement la loi et manquent des points essentiels des textes juridiques réels.
#JaiDécouvert qu'il est possible de configurer la durée de raisonnement de Clause Sonnet 3.7 :
Aujourd'hui, nous annonçons Claude Sonnet 3.7, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi instantanées ou une réflexion approfondie, étape par étape, qui est rendue visible à l'utilisateur. Les utilisateurs de l'API ont également un contrôle précis sur la durée de réflexion accordée au modèle.
#JaiDécouvert que l'offre LLM par API de Google se nomme Vertex AI.
#JaiDécouvert que les System Prompt d'Anthropic sont publics : https://docs.anthropic.com/en/release-notes/system-prompts#feb-24th-2025
J'ai trouvé la section "Gradual Disempowerement" très intéressante. #JaimeraisUnJour prendre le temps de faire une lecture active de l'article : Gradual Disempowerment.
Je viens de consacrer 1h30 de lecture active de l'article de février 2025. Je le recommande fortement pour ceux qui s'intéressent au sujet. Merci énormément à son auteur Moonz.
Je vais publier cette note et ensuite commencer la lecture de l'article de mars 2025.
Journal du jeudi 20 mars 2025 à 19:36
Quand j'ai travaillé en décembre 2024 sur mon "Projet 15 - Installation et configuration de OpenWrt sur Xiaomi Mi Router 4A Gigabit", j'avais découvert le projet #hardware OpenWrt One via ces threads Hacker News :
- Janvier 2024 : OpenWrt One/AP-24.XY: new open source router board by OpenWrt and Banana Pi (90 commentaires)
- Novembre 2024 : OpenWrt One (31 commentaires)
- Décembre 2024 : OpenWRT One Released: First Router Designed Specifically for OpenWrt (141 commentaires)
- Décembre 2024 : OpenWrt One router officially launched (43 commentaires)
Today, we at SFC, along with our OpenWrt member project, announce the production release of the OpenWrt One. This is the first wireless Internet router designed and built with your software freedom and right to repair in mind. The OpenWrt One will never be locked down and is forever unbrickable. ...
The OpenWrt One demonstrates what's possible when hardware designers and manufacturers prioritize your software right to repair; OpenWrt One exuberantly follows these requirements of the copyleft licenses of Linux and other GPL'd programs. This device provides the fully copyleft-compliant source code release from the start. Device owners have all the rights as intended on Day 1; device owners are encouraged to take full advantage of these rights to improve and repair the software on their OpenWrt One.
J'ai envie de m'en commander un pour remplacer mon Xiaomi Mi Router 4A Gigabit Edition.

Mais, je viens de lire ce commentaire sur LinuxFr :
- La carte mère et le boîtier sont bien larges et pourtant, ils ne sont pas arrivés à caser un disque dur au format courant 2280.
- La puce WiFi est soudée => impossible à faire évoluer. Il y'a déjà du wifi 7
- Le pilote de cette puce est un vieux blob binaire à mon avis. Il n'y a rien ici en tout cas: https://web.git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/drivers/net/wireless/mediatek?h=for-next
- Si je devais investir dans un équipement de ce genre, j'en prendrai un qui fait aussi le réseau cellulaire.
- Je ne comprends pas trop l'intérêt d'avoir un port Ethernet à 1Gb et l'autre ) 2,5Gb
- Au final, cela fait presque dans les 120€
Je pense que j'irais plutôt vers un truc dans ce genre (plus cher mais plus polyvalent):
https://www.aliexpress.com/item/1005004360072281.html
J'ai lu cet autre commentaire qui préfère le modèle GL.iNet GL-MT6000 (à 146 €) à OpenWrt One 🤔.
Journal du samedi 01 mars 2025 à 17:03
J'ai passé une heure à lire l'article de LinuxFr : « Une intelligence artificielle libre est-elle possible ? ». J'y ai appris de nombreuses choses et je l'ai trouvé plutôt accessible. Merci à l'auteur https://linuxfr.org/users/liorel.
J'ai beaucoup aimé cette manière de présenter ce qu'est l'Intelligence artificielle :
Commençons par définir notre objet d’étude : qu’est-ce qu’une IA ? Par « intelligence artificielle », on pourrait entendre tout dispositif capable de faire réaliser par un ordinateur une opération réputée requérir une tâche cognitive. Dans cette acception, un système expert qui prend des décisions médicales en implémentant les recommandations d’une société savante est une IA. Le pilote automatique d’un avion de ligne est une IA.
Cependant, ce n’est pas la définition la plus couramment employée ces derniers temps. Une IA a battu Lee Sedol au go, mais ça fait des années que des ordinateurs battent les humains aux échecs et personne ne prétend que c’est une IA. Des IA sont employées pour reconnaître des images alors que reconnaître un chien nous semble absolument élémentaire, mais l’algorithme de Youtube qui te suggère des vidéos pouvant te plaire parmi les milliards hébergées fait preuve d’une certaine intelligence et personne ne l’appelle IA. Il semble donc que le terme « IA » s’applique donc à une technique pour effectuer une tâche plus qu’à la tâche en elle-même, ou plutôt à un ensemble de techniques partageant un point commun : le réseau de neurones artificiels.
Dans la suite de cette dépêche, j’utiliserai donc indifféremment les termes d’IA et de réseau de neurones.
J'ai bien aimé la section « Un exemple : la régression linéaire » 👌.
Je n'ai pas compris grand-chose à la section « Le neurone formel ». Elle contient trop d'outils mathématiques qui m'échappent, comme :
- « la fonction f doit être monotone (idéalement strictement monotone) »
- « et non linéaire (sinon mettre les neurones en réseau n’a aucun intérêt, autant faire directement une unique régression linéaire) »
- « La fonction logistique »
- « La fonction Rectified Linear Unit »
On ajoute un ensemble de neurones qu’on pourrait qualifier de « sensitifs », au sens où ils prennent en entrée non pas la sortie d’un neurone antérieur, mais directement l’input de l’utilisateur, ou plutôt une partie de l’input : un pixel, un mot…
#JaiDécouvert les neurones « sensitifs ».
Se pose alors la question : combien de neurones par couche, et combien de couches au total ?
On peut considérer deux types de topologies : soit il y a plus de neurones par couche que de couches : le réseau est plus large que long, on parlera de réseau large. Soit il y a plus de couches que de neurones par couche, auquel cas le réseau est plus long que large, mais on ne va pas parler de réseau long parce que ça pourrait se comprendre « réseau lent ». On parlera de réseau profond. C’est de là que viennent les Deep et les Large qu’on voit un peu partout dans le marketing des IA. Un Large Language Model, c’est un modèle, au sens statistique, de langage large, autrement dit un réseau de neurones avec plus de neurones par couche que de couches, entraîné à traiter du langage naturel.
Je suis très heureux de découvrir cette distinction entre profond et large. Je découvre que ces termes, omniprésents dans le marketing des IA, reflètent en réalité des caractéristiques architecturales précises des réseaux de neurones.
On constate empiriquement que certaines topologies de réseau sont plus efficaces pour certaines tâches. Par exemple, à nombre de neurones constant, un modèle large fera mieux pour du langage. À l’inverse, un modèle profond fera mieux pour de la reconnaissance d’images.
je peux assez facilement ajuster un modèle de régression logistique (qui est une variante de la régression linéaire où on fait prédire non pas une variable quantitative, mais une probabilité)
J'ai une meilleure idée de ce qu'est un modèle de régression logistique.
En définitive, on peut voir le réseau de neurones comme un outil qui résout approximativement un problème mal posé. S’il existe une solution formelle, et qu’on sait la coder en un temps acceptable, il faut le faire. Sinon, le réseau de neurones fera un taf acceptable.
Ok.
Posons-nous un instant la question : qu’est-ce que le code source d’un réseau de neurones ? Est-ce la liste des neurones ? Comme on l’a vu, ils ne permettent ni de comprendre ce que fait le réseau, ni de le modifier. Ce sont donc de mauvais candidats. La GPL fournit une définition : le code source est la forme de l’œuvre privilégiée pour effectuer des modifications. Dans cette acception, le code source d’un réseau de neurones serait l’algorithme d’entraînement, le réseau de neurones de départ et le corpus sur lequel le réseau a été entraîné.
👍️
Journal du mercredi 27 novembre 2024 à 22:56
J'ai apprécié la lecture sur LinuxFr d'un commentaire au sujet de GTK 4 posté par un core développeur de Gimp : https://linuxfr.org/news/gimp-3-0-rc1-est-sorti#comment-1975019.
Journal du mardi 08 octobre 2024 à 00:07
Un ami me dit :
« Tu as mis ton numéro et ton email en clair sur ton site. Tu n’as pas peur de te faire spam ? »
Je viens de vérifier sur Wayback Machine, mon numéro de téléphone est sur mon site personnel depuis octobre 2005.
À ce jour, à ma connaissance, je n'ai pas plus, pas moins de "spam" téléphonique que mes amis.
D'autre part, comme expliqué dans Agir contre les appels commerciaux sur LinuxFr, la législation a évolué dernièrement :
L’ARCEP (Autorité de régulation des communications électroniques et des postes) a publié le 1ᵉʳ septembre 2023 une liste de numéros que les démarcheurs sont obligés d’utiliser pour émettre des appels : si on reçoit un appel depuis un de ces numéros, on peut considérer que c’est du spam. Cela concerne les numéros commençant par 0162, 0163, 0270, 0271, 0377, 0378, 0424, 0425, 0568, 0569, 0948 ou 0949 en zone +33 (France métropolitaine), 09475 en zone +590 (Guadeloupe, Saint-Martin, Saint-Barthélemy ), 09478 ou 09479 en zone +262 (La Réunion, Mayotte et autres territoires de l’Océan Indien), 09476 en zone +594 (Guyane) et 09477 en zone +596 (Martinique).
-- from
Par le passé, j'utilisais DoisJeRépondre et depuis quelque temps, j'utilise SpamBlocker. Je pense que cela fait plus d'un an que je n'ai pas eu un spam sur mon téléphone.
Journal du samedi 24 août 2024 à 21:58
#JaiLu Agir contre les appels commerciaux sur LinuxFr.
#JaiDécouvert EGBG Anti-Telemarketing Contre-scénario et leur super affiche : https://egbg.home.xs4all.nl/EGBGcontrescenario.pdf
J'ai remplacé DoisJeRépondre par SpamBlocker sur mon Android.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

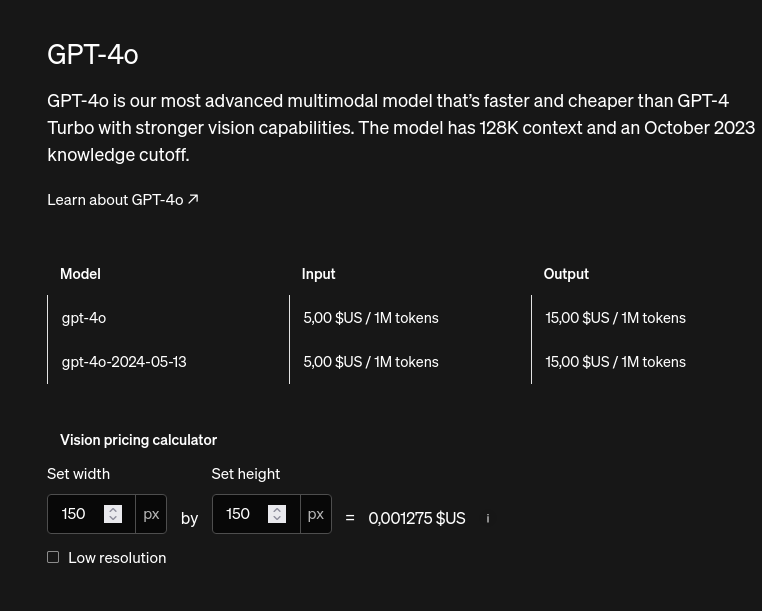
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.
Réflexions à propos de Node.js et de JavaScript plus globalement
Le 18 avril 2012, je publiais sur LinuxFr le journal qui suit — il recueillit 91 commentaire (lien https://linuxfr.org/users/harobed/journaux/reflexions-a-propos-de-nodejs-et-de-javascript-plus-globalement)
Bonjour,
Cela fait quelques jours que je me pose la question suivante : « Est-ce que Node.js ne va pas devenir une technologie incontournable / majeure dans les 2 ans qui viennent ? »
Le contexte
Je suis développeur Python depuis de nombreuses années. J'aime ses librairies, j'aime ses outils, j'aime sa communauté.
J'aime tellement sa syntaxe que quand je vois la syntaxe d'autres langages, j'ai une réaction quelque peu épidermique à la lecture du code.
Avec le temps, l'habitude de la syntaxe Python minimaliste, proche d'un pseudo-code, rend difficile la possibilité d'apprécier un autre langage. Je ne sais pas si c'est positif ou négatif, je me pose simplement la question. Enfin, ceci est un autre sujet.
Cependant, mon regard se tourne de plus en plus vers Node.js… je n'ai pas franchi le pas, je n'ai rien développé en Node.js… mais je me demande si je ne passe pas à côté de quelque chose d'important.
Les forces de Node.js
-
Bien que Node.js date seulement de 2009 :
- il a déjà un bon système de paquets : Node Package Manager, que la grande majorité de la communauté semble utiliser
- il a déjà une très forte communauté, de très nombreuses librairies — exemple : plein de librairies classées, déjà plus de 9 000 paquets sur npm
- de plus en plus de sociétés semblent l'utiliser
-
Tous les développeurs web (front-end) connaissent le langage, il est très populaire. Par conséquent, pour passer à Node.js il n'y a pas le frein d'apprendre un nouveau langage, comme ce serait le cas avec l'utilisation d'un framework web basé sur Ruby ou Python. Je pense que dans les mois qui viennent, de nombreux développeurs PHP vont passer à Node.js… surtout ceux qui regardaient ailleurs mais qui ne souhaitent pas apprendre un nouveau langage.
-
La possibilité de partager du code (librairies communes…) entre la partie client et serveur peut être intéressante. La question se pose de plus en plus, étant donné qu'on est de plus en plus amené à effectuer beaucoup de traitements côté client (exemple avec Backbone.js).
Dernièrement, dans tous mes projets de développement web, j'ai utilisé un moteur de template côté client en plus du moteur de template côté serveur.
Je dois gérer de plus en plus souvent une couche modèle côté client, des vues côté client… Cela fait donc plein d'éléments en double, utilisés une fois sur le serveur, une fois sur le client. Donc deux technologies à maîtriser.
Ces derniers jours, la visualisation du screencast du framework JavaScript Meteor m'a mis la puce à l'oreille.
Autre exemple : il est possible d'utiliser la même API Canvas côté client et côté serveur (avec node-canvas). -
Node.js semble être très rapide et tient très bien la montée en charge.
-
La vitesse de l'interpréteur JavaScript est en constante progression : V8 (JavaScript engine)
Faiblesses de Node.js
Je ne sais pas si mes remarques sont exactes, je n'ai aucune expérience en Node.js.
- Par exemple, dans la partie Bad Use Cases du guide Felix's Node.js Convincing the boss guide, il est indiqué que les frameworks Node.js sont moins matures que ce que l'on peut trouver en Ruby, Python et PHP (bon, pour ce dernier j'ai des doutes — je pense que la communauté Node.js est déjà plus mature, plus structurée que la communauté PHP… enfin bon…).
- Je ne pense pas que Sequelize soit aussi mature que SQLAlchemy.
- Je n'ai pas trouvé d'outil comme Whoosh en JavaScript (c'est un moteur de recherche léger). J'ai tout de même trouvé Node-xapian.
Je ne sais pas s'il est encore tôt pour passer à Node.js, mais si la communauté continue à être aussi dynamique que ces 2 dernières années… alors les pièces manquantes seront bientôt créées.
Est-ce que l'on va retrouver JavaScript partout ?
Voici une petite liste :
- JavaScript dans les navigateurs web
- JavaScript côté serveur (Node.js)
- JavaScript dans Qt : Introduction QML + Qt Quick, qui semble vraiment très puissant
- Les possibilités d'utiliser GTK + JS : gjs and Gtk+
- GNOME Shell est en grande partie développé en JavaScript. Ses extensions sont entièrement développées en JS.
- Sur mobile : WebOS et Boot to Gecko
Quand je vois cette liste, je me pose sérieusement la question : est-ce que JavaScript est le langage incontournable de ces 10 prochaines années ? Certes, il est déjà incontournable dans le navigateur, mais pour le reste ?