
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (79 notes) :
Journal du dimanche 21 septembre 2025 à 12:50
Après un an d'utilisation de mon Shokz OpenMove, j'ai enfin pris le temps de mettre en place l'appairage multipoint . Cela marche impeccablement, et je trouve cette fonctionnalité vraiment pratique, voire même indispensable 🙂 !
#JeMeDemande pourquoi le mode multipoint n'est pas activé pas défaut 🤔.
Journal du lundi 10 mars 2025 à 18:02
Après ruff il y a 1 mois, on m'a encore partagé un nouveau formatter, bien entendu en Rust : Biome (https://github.com/biomejs/biome).
Biome is a performant toolchain for web projects, it aims to provide developer tools to maintain the health of said projects.
Biome is a fast formatter for JavaScript, TypeScript, JSX, JSON, CSS and GraphQL that scores 97% compatibility with Prettier.
Biome is a performant linter for JavaScript, TypeScript, JSX, CSS and GraphQL that features more than 270 rules from ESLint, typescript-eslint, and other sources. It outputs detailed and contextualized diagnostics that help you to improve your code and become a better programmer!
Le projet Biome a commencé en été 2023, mais en réalité, le projet est plus ancien. Biome est un fork du projet Rome de Meta, qui a commencé en 2020.
Ce billet explique la raison du fork, pour faire simple, un problème de propriété du nom.
Thread Hacker News de l'annonce du fork : Biome.
J'ai lu le billet Biome v1.7 qui explique comment migrer d'eslint ou Prettier en une commande :
biome migrate eslint- ou
biome migrate prettier
Je pense que je vais attendre encore un peu avant de migrer parce que le support Svelte est partiel :
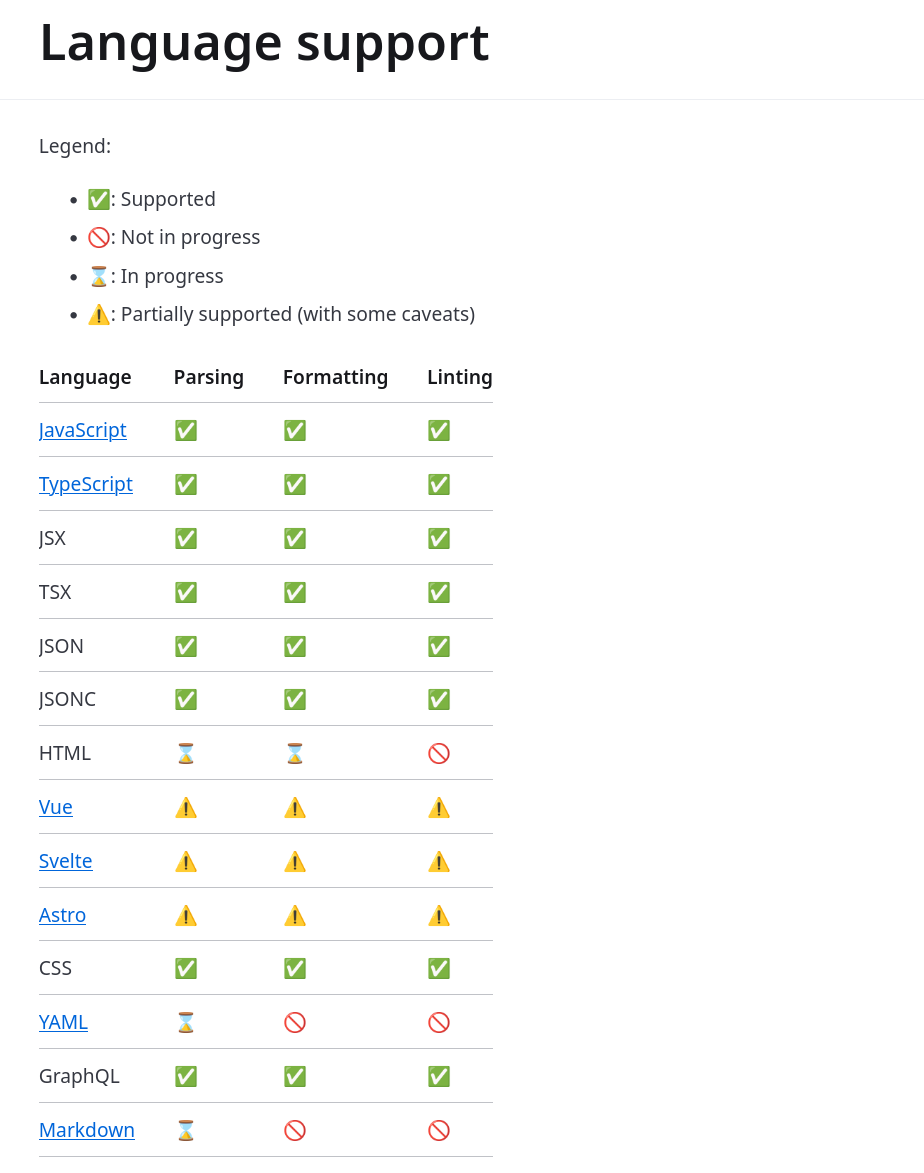
#JeMeDemande quelles sont les différences entre le linter de Oxc https://oxc.rs/docs/guide/usage/linter et Biome 🤔.
Je viens de vérifier, le projet Oxc est toujours très actif : https://github.com/oxc-project/oxc/graphs/contributors.
Journal du mardi 04 février 2025 à 11:36
Suite de ma note 2025-02-03_1718.
Suite à la réponse de l'agent des impôts qui ne m'a pas beaucoup aidé :
Bonjour,
C’est juste une attestation sur l’honneur.
En vous remerciant de votre attention. Cette demande est terminée, si vous souhaitez y répondre ou apporter des remarques ou aborder d’autres sujets, vous devez déposer une autre demande.
J'ai effectué la recherche suivante : Demande d'option pour un régime de TVA modèle de lettre
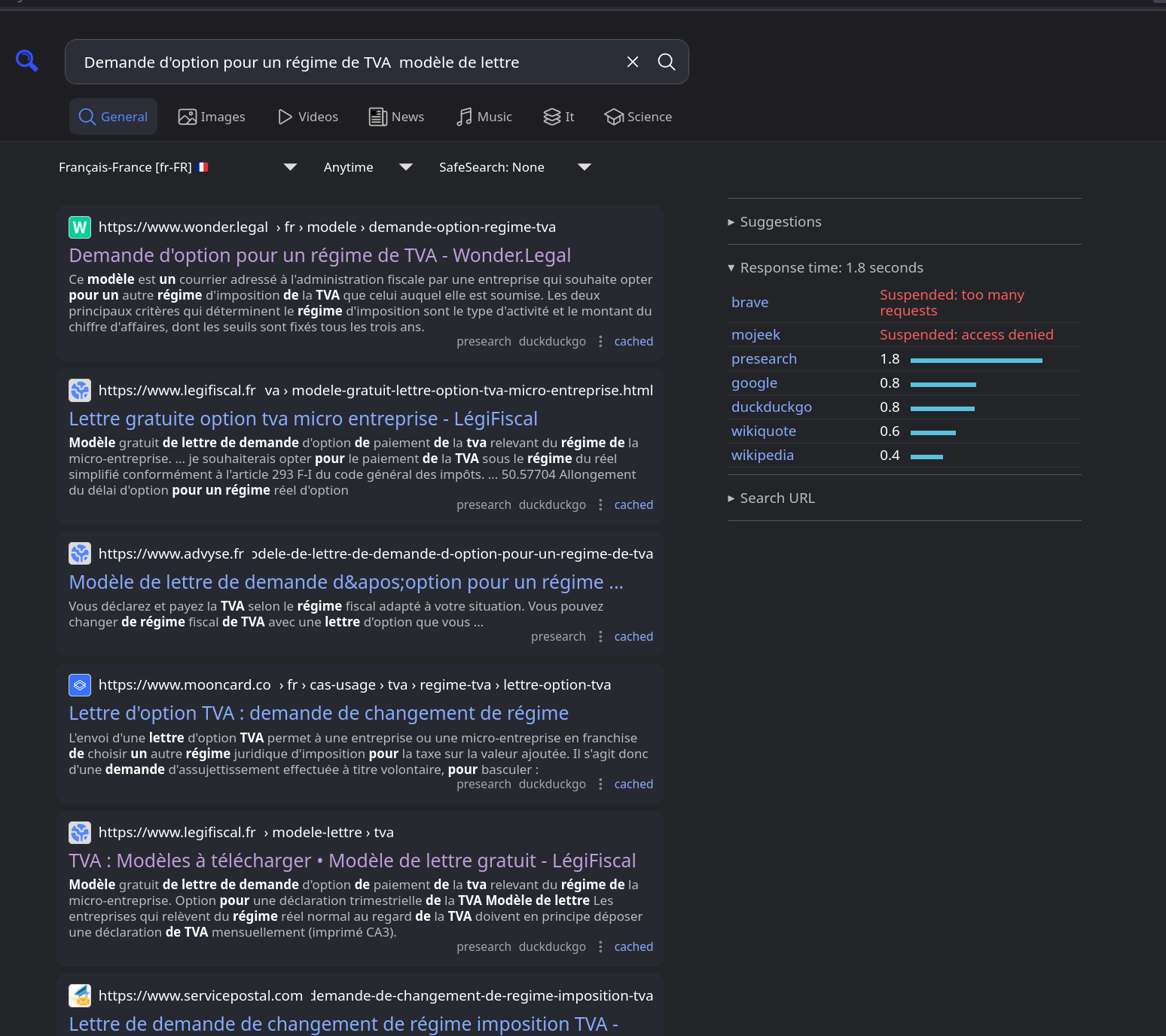
J'ai parcouru les dix premières pages de résultats sans trouver le moindre modèle de lettre sur un site officiel de l'État. C'est désolant de devoir dépendre de sites privés qui exploitent les lacunes d'un service public pour en tirer profit.
Voici un modèle de lettre que j'ai trouvé :
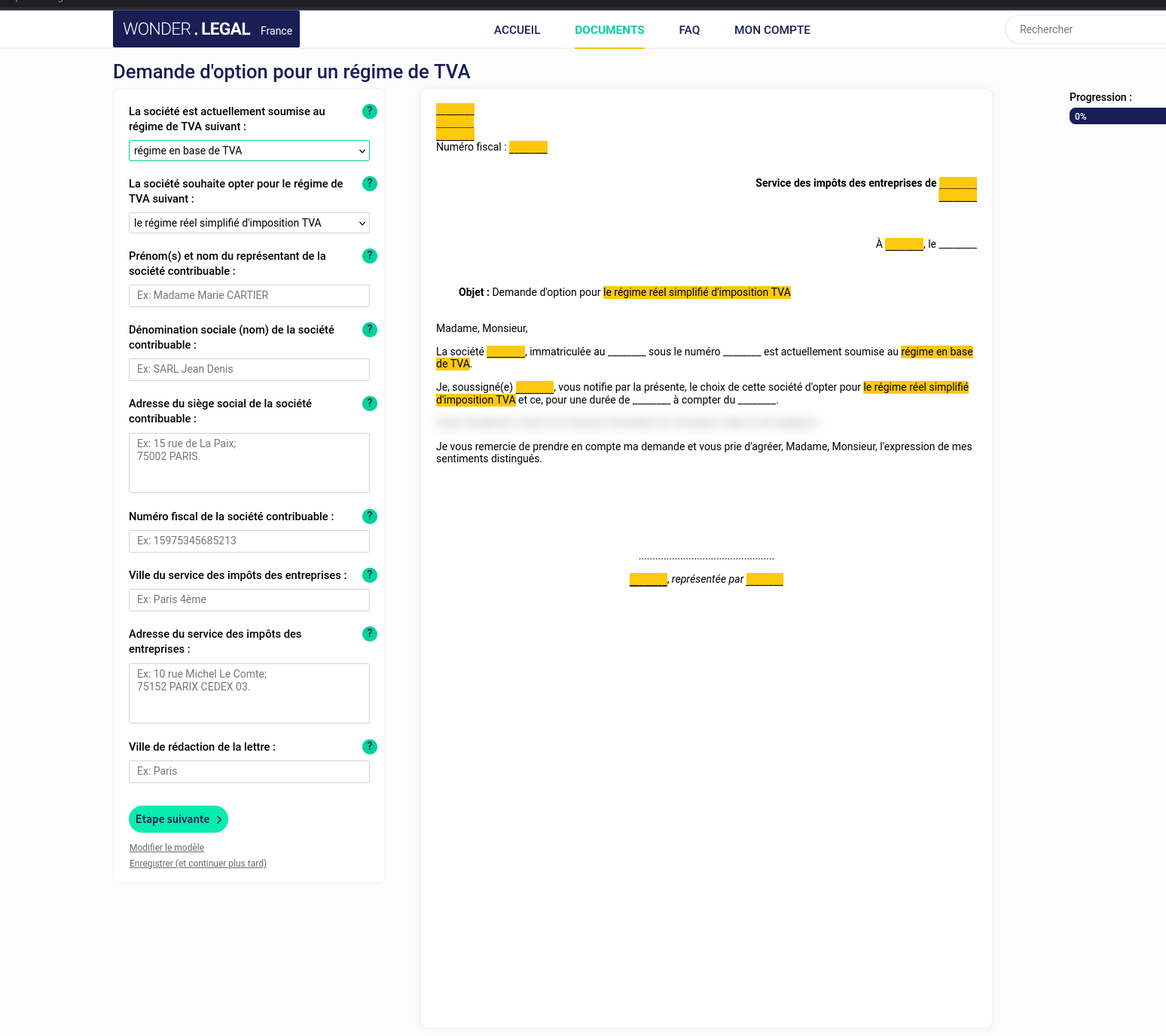
Je pense que c'est ce type de lettre que me demande l'agence des impôts.
Le formulaire me propose 3 options :
- "Le régime réel simplifié d'imposition TVA"
- "Le régime normal d'imposition TVA"
- "Le régime alternatif du mini-réel"
D'après mes recherches, je comprends qu'il y a en réalité 4 options :
- Régime en base de TVA
- Régime réel simplifié d'imposition à la TVA
- Régime mini-réel d'imposition à la TVA
- Régime réel normal d'imposition à la TVA
(Lien vers une version Google Spreadshet du tableau)
| Critères | Régime en base de TVA | Régime réel simplifié de TVA | Régime mini-réel de TVA | Régime réel normal de TVA |
|---|---|---|---|---|
| Facturation de la TVA | ❌ Non | ✅ Oui | ✅ Oui | ✅ Oui |
| Déclarations de TVA | ❌ Aucune | ✅ Annuelle (CA12) + acomptes | ✅ Mensuelle/trimestrielle (CA3) | ✅ Mensuelle/trimestrielle (CA3) |
| Paiement de la TVA | ❌ Non | ✅ 2 acomptes + régularisation annuelle | ✅ Régulier, au fil des déclarations | ✅ Régulier, au fil des déclarations |
| Récupération de la TVA | ❌ Non | ✅ Oui | ✅ Oui | ✅ Oui |
| Obligations comptables | 📌 Ultra simplifiée | 📌 Allégée | 📌 Comptabilité complète | 📌 Comptabilité complète |
| Charge administrative | ✅ Très faible | ⚠️ Moyenne | ❌ Plus lourde | ❌ Lourde |
| Seuil de chiffre d’affaires | -91 900 € (commerce) / 36 800 € (services) | < 840 000 € (commerce) / < 254 000 € (services) | < 840 000 € (commerce) / < 254 000 € (services) | > 840 000 € (commerce) / > 254 000 € (services) |
| Public concerné | Micro-entreprises, indépendants | Petites entreprises | Entreprises voulant mensualiser la TVA | Entreprises à forte activité |
| Flexibilité de trésorerie | ✅ Maximum | ⚠️ Moins flexible | ✅ Bonne gestion | ❌ Contraignant |
J'ai réalisé ce modèle de lettre Google Docs :
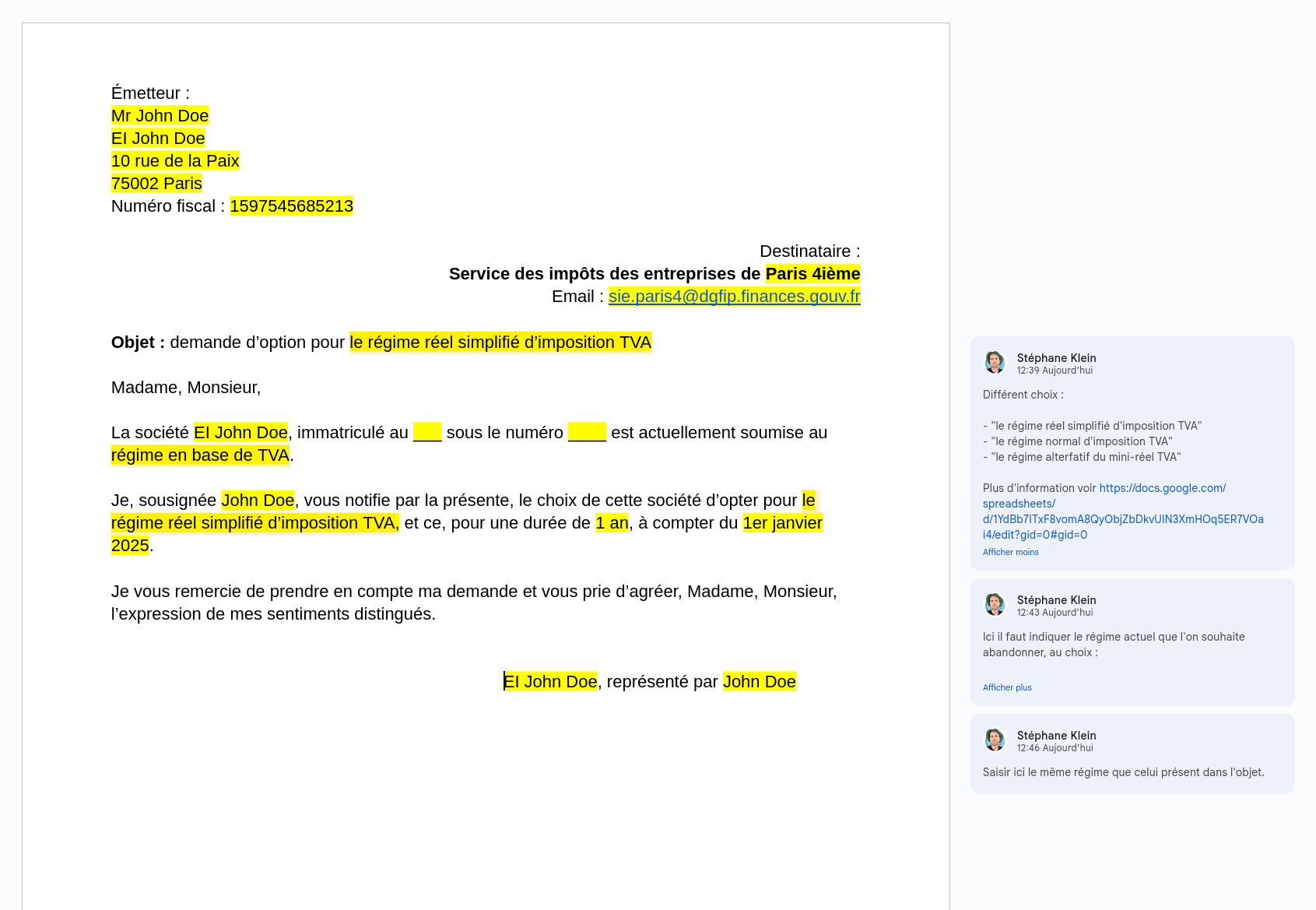
#JeMeDemande si je préfère choisir l'option "Régime réel simplifié d'imposition à la TVA" ou "Régime mini-réel d'imposition à la TVA".
Le "Régime réel simplifié d'imposition à la TVA" fonctionne avec un système d'acomptes semestriels qui est calculé à partir de la TVA collectée par l'entreprise durant l'année précédente. #JeMeDemande comment le montant de cet acompte est calculé la première année.
À ce jour, j'ignore encore si je vais continuer ou non une activité de Freelance sur le long terme.
Avec le système d'acompte, j'ai peur de devoir continuer à payer des acomptes pendant un an sur un chiffre d'affaires qui sera nul et de voir faire des démarches pour me faire rembourser 🤔.
Pour le moment, je n'ai pas encore trouvé réponse à ces deux questions :
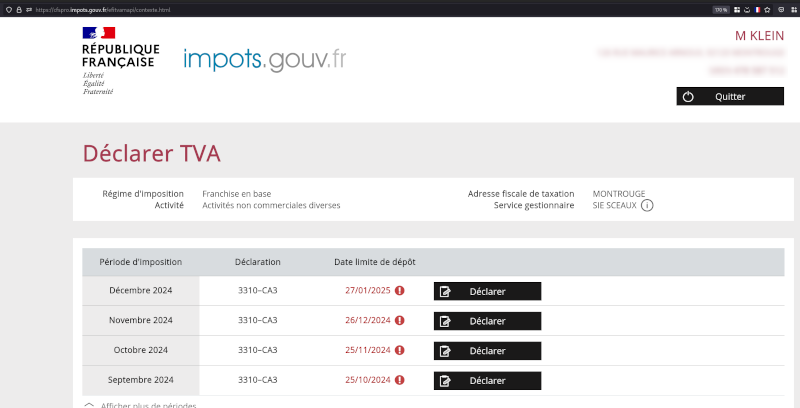
- c. Pouvez-vous me confirmer que ma déclaration devrait se faire sur la page web indiquée dans le screenshot en pièce jointe ?
- d. Est-ce que la déclaration doit s'effectuer en fonction de la date d'émission de la facture ou alors sa date d'encaissement ?
Journal du mercredi 29 janvier 2025 à 11:55
#JaiDécouvert Nitro (https://nitro.build/)
Next Generation Server Toolkit.
Create web servers with everything you need and deploy them wherever you prefer.
D'après ce que j'ai compris, Nitro est un serveur http en NodeJS qui a été spécialement conçu pour Nuxt.js.
Nitro a été introduit fin 2021 dans la version 3 de Nuxt.
Nitro fait partie de l'écosystème UnJS.
Je découvre l'existence de UnJS Ecosystem. #JeMeDemande si ce projet a un lien avec VoidZero 🤔.
Je viens de vérifier, SvelteKit ne semble pas utiliser Nitro. Nitro semble être utilisé uniquement par Nuxt.js.
Journal du vendredi 17 janvier 2025 à 11:58
#JeMeDemande s'il est possible d'installer des serveurs Scaleway Elastic Metal avec des images d'OS préalablement construites avec Packer 🤔.
Je viens de poser la question suivante : Is it possible to create Elastic Metal OS images with Packer and use it to create a Elastic Metal serveurs?
En français :
Bonjour,
Je sais qu'il est possible de créer des images d'OS avec Packer utilisables lors de la création d'instance Scaleway (voir https://www.scaleway.com/en/docs/tutorials/deploy-instances-packer-terraform/).
De la même manière, je me demande s'il est possible de créer des images d'OS avec Packer pour installer des serveurs Elastic Metal .
Question : est-il possible de créer des images Elastic Metal avec Packer et d'utiliser celle-ci pour créer des serveurs Elastic Metal ?
Si c'est impossible actuellement, pensez-vous qu'il soit possible de l'implémenter ? Ou alors, est-ce que des limitations techniques de Elastic Metal rendent impossible cette fonctionnalité ?
Bonne journée, Stéphane
Je viens d'envoyer cette demande au support de Scaleway.
Journal du dimanche 12 janvier 2025 à 16:38
J'ai résolu mon problème d'hier : « Panne clavier : soudainement, la touche "v" de mon Thinkpad affiche "m" » 🙂.
En moins de 24h, j'ai reçu une réponse d'un employé de Lenovo à mon message (posté un weekend) :
2. Perform a Power Drain:
- Shut down your laptop.
- Disconnect the power adapter and any external devices.
- Press and hold the power button for about 30 seconds to drain any residual power.
- Reconnect the power adapter and turn on your laptop to see if the issue persists.
J'ai suivi ces instructions et la panne est corrigée, le clavier de mon Thinkpad T14s fonctionne parfaitement 🙂.
Ce n'est pas la première fois que je trouve des réponses très précises sur le Forum officiel Lenovo :
- Random screen flickering on T14s Gen 3 AMD in Fedora 37
- T14 Gen1 AMD with kernel 6.1.12 thermal: Invalid critical threshold (0) & No valid trip found
- No external USB-C monitor detection on my Thinkpad T14s AMD Gen3 powered by Fedora 38
Des ingénieurs de chez Lenovo répondent très régulièrement sur ce forum, par exemple :
It seems like you have the same panel as some of the other users who have reported this issue. Disabling PSR is currently the recommended workaround until a proper fix is available. AMD is actively working on this issue and we are hoping to have a solution soon. I will keep you updated on any progress.
C'est quelque chose que j'apprécie.
Je pense que je pourrais retrouver la même expérience sur le forum de Framework (laptop) : https://community.frame.work/.
#JeMeDemande si je pourrais échanger avec des techniciens de chez Apple, DELL…
Journal du dimanche 12 janvier 2025 à 00:14
Voici mes prochaines #intentions d'amélioration de ma workstation :
- Après avoir observé l'environement desktop d'Alexandre, cela m'a donné envie de tester Zen Browser.
- Installer, configurer et tester Ghostty.
- Étudier, installer, configurer un AI code assistant qui ressemble à Cursor mais pour Neovim, voici-ci les plugins que j'aimerais tester :
- Peut-être apprendre à utiliser Jujutsu - A Git-compatible VCS that is both simple and powerful.
- J'aimerais trouver un équivalent à rofi ou fuzzel pour GNOME Shell.
#JeMeDemande si la fonctionnalité "GNOME Shell Search Provider" me permettrait de réaliser cet objectif 🤔.
Ou alors, est-ce que GNOME Shell permet nativement de lancer des scripts shells 🤔. - Essayer de remplacer les services ChatGPT ou Claude.ai par Open WebUI.
- Peut-être remplacer zsh par fish shell.
Je découvre la compression Zstandard
Un ami m'a partagé Zstandard (zstd), un algorithme de compression.
Il y a 2 ans, j'ai étudié et activé Brotli dans mes containers nginx, voir la note : Mise en œuvre du module Nginx Brotli.
Je viens de trouver un module zstd pour nginx : https://github.com/tokers/zstd-nginx-module
Mon ami m'a partagé cet excellent article : Choosing Between gzip, Brotli and zStandard Compression. Très complet, il explique tout, contient des benchmarks…
Voici ce que je retiens.
Brotli a été créé par Google, Zstandard par Facebook :
Je lis sur canIuse, le support Zstandard a été ajouté à Chrome en mars 2024 et à Firefox en mai 2024, c'est donc une technologie très jeune coté browser.
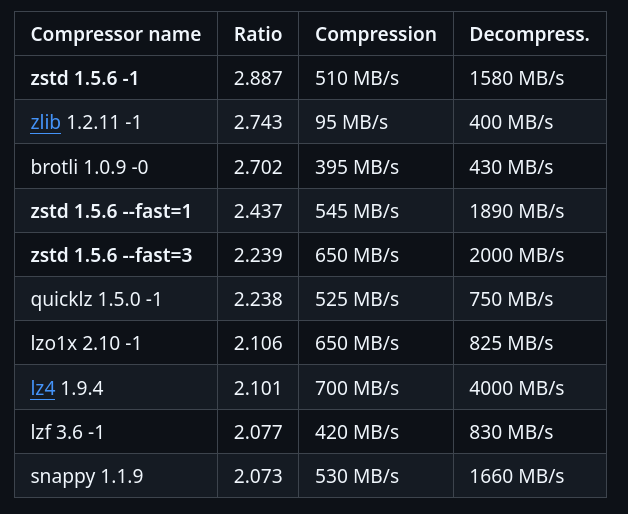
Benchmark sur le dépôt officiel de Zstandard :
J'ai trouvé ces threads Hacker News :
- 2020-05-07 : Introduce ZSTD compression to ZFS
- 2022-08-20 : AWS switch from gzip to zstd – about 30% reduction in compressed S3 storage
Zstandard semble être fortement adopté au niveau de l'écosystème des OS Linux :
In March 2018, Canonical tested the use of zstd as a deb package compression method by default for the Ubuntu Linux distribution. Compared with xz compression of deb packages, zstd at level 19 decompresses significantly faster, but at the cost of 6% larger package files. Support was added to Debian in April 2018
Packages Fedora :
#JeMeDemande si dans mes projets de doit utiliser Zstandard plutôt que Brotli 🤔.
Je pense avoir trouver une réponse ici :
The research I’ve shared in this article also shows that for many sites Brotli will provide better compression for static content. Zstandard could potentially provide some benefits for dynamic content due to its faster compression speeds. Additionally:
- ...
- For dynamic content
- Brotli level 5 usually result in smaller payloads, at similar or slightly slower compression times.
- zStandard level 12 often produces similar payloads to Brotli level 5, with compression times faster than gzip and Brotli.
- For static content
- Brotli level 11 produces the smallest payloads
- zStandard is able to apply their highest compression levels much faster than Brotli, but the payloads are still smaller with Brotli.
#JaimeraisUnJour prendre le temps d'installer zstd-nginx-module à mon image Docker nginx-brotli-docker (ou alors d'en trouver une déjà existante).
Je me demande si Obsidian ou SilverBullet pourraient tirer parti de la norme "URL text fragment" 🤔
#JeMeDemande si Obsidian ou SilverBullet.mb supportent la syntax URL text fragment 🤔.
Claude.ai m'a appris que les URL text fragment se nomment aussi des "deep linking to text".
J'ai effectué les recherches suivantes sur GitHub :
- « obsidian deep linking » et j'ai trouvé :
deep-notesmais le README "vide" ne m'a pas donné envie de le tester
- « obsidian fragment » mais je n'ai rien trouvé de pertinent
J'ai effectué les recherches suivantes sur https://forum.obsidian.md :
- « deep link » et j'ai trouvé :
- En lisant "Link to Block does not work with non-default themes" #JaiDécouvert la fonctionnalité d'Obsidian nommée "Link to a block in a note" qui est à l'usage très pratique.
- « fragment » et j'ai trouvé :
- "I think text fragment could be very useful in Obsidian" qui correspond à la question que je me pose.
Pour le moment, je pense qu'avec Obsidian la seule solution est d'utiliser la fonctionnalité "Link to a block in a note".
Voici mes recherches concernant SilverBullet.mb.
Dans la page "Links" j'ai trouvé la fonctionnalité "Anchors."
J'ai effectué les recherches suivantes sur https://community.silverbullet.md:
et je n'ai rien trouvé d'intéressant.
J'ai ensuite effectué des recherches sur GitHub :
je n'ai rien trouvé d'intéressant non plus.
J'ai posté le message suivant sur « I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔 ».
Version française :
Il y a quelques jours, j'ai découvert la fonctionnalité URL text fragment (ma note à ce sujet en français). Depuis, j'utilise l'extension Firefox "Link to Text Fragment" pour partager des liens précis et je trouve cela très simple d'usage.
J'ai bien identifié la fonctionnalité Anchors de Silverbullet pour créer un lien vers une position précise dans une page interne à SilverBullet.
Je me demande si SilverBullet pourrait tirer parti de la norme "URL text fragment" 🤔.
J'imagine une syntaxe du type
[[MyPage#:~:text=foobar]].Pour le moment, j'ai du mal à imaginer les avantages /inconvénients de cette idée de fonctionnalité par rapport à l'utilisation de "Anchors".
J'ai cherché si Obsidian supportait les URL text fragment, je constate que non.
Chez Obsidian l'équivalent de Anchors semble être Link to a block in a note.Quelle est votre intuition à ce sujet ?
Version anglaise :
A few days ago, I discovered the URL text fragment feature (my note about this in french). Since then, I've been using the Firefox extension “Link to Text Fragment” to share specific links, and I find it very easy to use.
I did identify Silverbullet's Anchors feature for linking to a specific position on a SilverBullet internal page.
I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔.
I can imagine a syntax like
[[MyPage#:~:text=foobar]].For now, I'm struggling to imagine the advantages/disadvantages of this feature idea compared to using “Anchors”.
I've looked to see if Obsidian supports URL text fragments, and find that it doesn't.
Obsidian's equivalent of Anchors seems to be Link to a block in a note.What's your feeling about this?
Journal du vendredi 03 janvier 2025 à 12:59
Dans ce thread du forum de SilverBullet.mb #JaiDécouvert l'outil Nutshell (https://ncase.me/nutshell/) :

Je trouve cela très ingénieux.
#JeMeDemande comment je pourrais tirer parti de cette fonctionnalité dans notes.sklein.xyz 🤔.
Comment lancer une image Docker de l'architecture "arm64" sous Intel ?
#JeMeDemande comment lancer une image Docker pour l'architecture arm64 sur une architecture Intel sous Fedora ?
Par défaut, l'exécution de cette image Docker sous Intel avec l'option --platform linux/arm64 ne fonctionne pas :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
exec /usr/bin/bash: exec format error
J'ai consulté et suivi la documentation Docker officielle suivante : Install QEMU manually.
$ docker run --privileged --rm tonistiigi/binfmt --install all
installing: arm64 OK
installing: arm OK
installing: ppc64le OK
installing: riscv64 OK
installing: mips64le OK
installing: s390x OK
installing: mips64 OK
{
"supported": [
"linux/amd64",
"linux/arm64",
"linux/riscv64",
"linux/ppc64le",
"linux/s390x",
"linux/386",
"linux/mips64le",
"linux/mips64",
"linux/arm/v7",
"linux/arm/v6"
],
"emulators": [
"qemu-aarch64",
"qemu-arm",
"qemu-mips64",
"qemu-mips64el",
"qemu-ppc64le",
"qemu-riscv64",
"qemu-s390x"
]
}
Après cela, je constate que j'arrive à lancer avec succès une image arm64 sous processeur Intel :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
root@bf74bfb8bc35:/# graphql-engine version
Hasura GraphQL Engine (Pro Edition): v2.43.0
J'ai pris un peu de temps pour explorer le repository tonistiigi/binfmt.
Je n'ai pas compris quelle est l'interaction entre les éléments installés par cette image et docker-engine.
Je constate que cette image a été créée en 2019 par deux développeurs de Docker : CrazyMax (un Français) et Tõnis Tiigi.
Journal du mercredi 27 novembre 2024 à 10:52
Depuis des années, j'hésite toujours entre get et fetch lors du naming de fonctions.
Je viens de demander à ChatGPT la différence entre ces deux verbes et quand est-ce qu'il est préférable d'utiliser l'un ou l'autre.
Voici sa réponse :
Pour
get:
- Signification : Indique une opération simple pour récupérer ou accéder à des données.
- Contexte d'utilisation :
- Utilisé pour des accès rapides et directs à des données qui sont déjà disponibles localement (en mémoire, en cache, etc.).
- Souvent employé dans des fonctions "getter" ou des méthodes utilitaires simples.
Pour
fetch:
- Signification : Suggère une opération potentiellement asynchrone ou coûteuse, comme récupérer des données d'une source externe.
- Contexte d'utilisation :
- Lorsqu'une action supplémentaire est requise pour obtenir les données, comme un appel réseau ou une requête vers une API.
- Implique souvent un effort ou une complexité plus grande que
get.
J'ai essayé d'obtenir plus de ressources concernant cette déclaration.
J'ai trouvé ceci :
Example: fetch implies that some entity needs to go and get something that is remote and bring it back. Dogs fetch a stick, and retrieve is a synonym for fetch with the added semantic that you may have had possession of the thing prior as well. get is a synonym for obtain as well which implies that you have sole possession of something and no one else can acquire it simultaneously.
-
Ma recherche "
fetch get" sur English Language and Usage Stack Exchange : -
Sur MDN Web Docs, j'ai effectué des recherches de fonctions qui commencent par
getoufetch. Je constate que le verbefetchest utilisé lorsque la fonction va chercher des données sur le réseau.
Suite à cette étude, j'ai décidé d'utiliser fetch plutôt que get pour toutes les fonctions allant chercher des données en dehors du "processus local". Quelques exemples :
- Utilisation de
fetchpour nommer une fonction javascript frontend ou backend, qui effectue des requêtes REST ou GraphQL. - Utilisation de
getpour nommer une fonction PL/pgSQL qui effectue uniquement des requêtes SQL sur la base de données locale (pas de requêtes vers des Foreign Data (PostgreSQL)). Ici "locale" signifie que l'instance qui exécute la fonction PL/pgSQL est la même que celle qui contient les tables requêtées (voir cet échange).
Journal du mardi 19 novembre 2024 à 11:02
Suite de 2024-11-19_1029.
J'ai testé https://github.com/Syquel/mise-android-sdk. Il dépend de yq. Cela m'embête un peu d'ajouter cette dépendance dans les "Prerequisite" de mon projet.
À la suite de cela, j'ai testé https://github.com/huffduff/asdf-android-sdk, mais je suis tombé sur le problème suivant, ce qui ne m'a pas donné confiance : "Bad URL in "asdf plugin add android-sdk https://github.com/tommyo/asdf-android-sdk.git" instruction".
Échec avec arcticShadow/asdf-android
Ensuite, j'ai testé https://github.com/arcticShadow/asdf-android.
$ mise plugins install https://github.com/arcticShadow/asdf-android.git
$ mise ls-remote android
1
#JeMeDemande pourquoi version 1 ? 🤔
$ mise install android latest
mise ERROR latest not found in mise tool registry
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
$ mise install android 1
curl: (22) The requested URL returned error: 404
mise ERROR ~/.local/share/mise/plugins/android/bin/download failed
* Downloading android release 1...
curl: (22) The requested URL returned error: 404
asdf-android: Could not download https://dl.google.com/android/repository/commandlinetools-linux-1_latest.zip
mise ERROR failed to install android@1
mise ERROR ~/.local/share/mise/plugins/android/bin/download exited with non-zero status: exit code 1
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
Suite à cela, j'ai posté cette issue : "mise ERROR latest not found in mise tool registry · Issue #6 · arcticShadow/asdf-android · GitHub".
À ce moment précis, je me suis dit que je suis en train de tomber dans un Yak!.
Échec avec huffduff/asdf-android-sdk
Je retourne au projet https://github.com/huffduff/asdf-android-sdk.
$ mise plugin add android-sdk https://github.com/huffduff/asdf-android-sdk
$ mise ls-remote android-sdk
2.1
J'ai consulté la page https://github.com/AndroidSDKSources/android-sdk-sources-list et je ne comprends pas à quoi correspond la version 2.1 🤔.
Ensuite, j'ai rencontré ces erreurs :
$ mise install android-sdk latest
mise ERROR latest not found in mise tool registry
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
$ mise install android-sdk 2.1
Warning: Errors during XML parse:
Warning: Additionally, the fallback loader failed to parse the XML.
cp: impossible d'évaluer '/home/stephane/.local/share/mise/downloads/android-sdk/2.1/*': Aucun fichier ou dossier de ce nom
mise ERROR ~/.local/share/mise/plugins/android-sdk/bin/install failed
cp: impossible d'évaluer '/home/stephane/.local/share/mise/downloads/android-sdk/2.1/*': Aucun fichier ou dossier de ce nom
asdf-android-sdk: Expected /home/stephane/.local/share/mise/installs/android-sdk/2.1/cmdline-tools/2.1/bin/sdkmanager to be executable.
asdf-android-sdk: An error occurred while installing android-sdk 2.1.
mise ERROR failed to install android-sdk@2.1
mise ERROR ~/.local/share/mise/plugins/android-sdk/bin/install exited with non-zero status: exit code 1
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
Suite à cela, j'ai posté cette issue : "Add mise support? « mise ERROR latest not found in mise tool registry »"
Succès avec Syquel/mise-android-sdk
Je retourne sur le premier projet https://github.com/Syquel/mise-android-sdk et j'installe yq :
$ sudo dnf install yq
$ mise plugins install android-sdk https://github.com/Syquel/mise-android-sdk.git
mise plugin:android-sdk ✓ https://github.com/Syquel/mise-android-sdk.git#a44eb2b
$ mise ls-remote android-sdk
1.0
2.0
2.1
3.0
4.0
5.0
6.0
7.0
8.0
9.0
10.0
11.0
12.0
13.0-rc01
13.0
14.0-alpha01
16.0-alpha01
16.0
Je pense que ces versions correspondent à https://github.com/AndroidSDKSources/android-sdk-sources-list, mais #JeMeDemande pourquoi la version 15 est absente de cette liste.
J'ai configuré mon fichier .mise.toml
$ cat .mise.toml
[tools]
android-sdk = "13.0"
Et ensuite :
$ mise install
$ rehash
$ sdkmanager --version
13.0
Ensuite je ne sais pas trop quoi faire avec sdkmanager mais c'est une autre histoire 🙂.
Journal du mardi 19 novembre 2024 à 10:29
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Pour utiliser Capacitor, j'ai besoin d'installer certains éléments.
In order to develop Android applications using Capacitor, you will need two additional dependencies:
- Android Studio
- An Android SDK installation
Je me demande si Android Studio est optionnel ou non.
J'aimerais installer ces deux services avec Mise.
J'ai trouvé des Asdf plugins pour Android SDK :
- https://github.com/Syquel/mise-android-sdk (créé le 2024-03-03)
- https://github.com/huffduff/asdf-android-sdk (créé le 2024-10-10)
- https://github.com/arcticShadow/asdf-android (créé le 2024-11-13)
#JeMeDemande quel plugin utiliser, quelles sont leurs différences.
Pour essayer d'avoir une réponse, j'ai posté les issues suivantes :
- What are the differences with other existing plugins?
- What are the differences with other existing plugins?
Alexandre m'a informé qu'il a utilisé avec succès le plugin https://github.com/Syquel/mise-android-sdk/, il a même créé une issue https://github.com/Syquel/mise-android-sdk/issues/10 qui a été traité 🙂.
La suite : 2024-11-19_1102.
Je remplace direnv par la fonctionnalité env._source proposée Mise
Depuis avril 2019, j'utilise direnv dans pratiquement tous mes projets de développement informatique.
Ce matin je me suis demandé si avec les nouvelles fonctionnalités de gestion des variables d'environnement de Mise, je pouvais simplifier mes development kit 🤔.
Comme vous pouvez le voir dans install-and-configure-direnv-with-mise-skeleton, actuellement mes development kit contiennent deux étapes de modifications de .bash_profile ou .zshrc. Exemple avec Zsh :
- Une étape pour configurer Mise :
$ echo 'eval "$(~/.local/bin/mise activate zsh)"' >> ~/.zshrc
$ source ~/.zsrhrc
- Seconde étape pour configurer direnv :
$ echo -e "\neval \"\$(direnv hook zsh)\"" >> ~/.zshrc
$ source ~/.zsrhrc
Voici la version simplifiée de ce skeleton basé sur "mise env._source", avec une étape de configuration en moins :
https://github.com/stephane-klein/install-and-configure-mise-skeleton
Voici le contenu du fichier .mise.toml :
[env]
_.source = "./.envrc.sh"
et le contenu de .envrc.sh :
export HELLO_WORLD=foo
J'ai fait le choix de nommer ce fichier .envrc.sh plutôt que .envrc afin d'éviter des problèmes de compatibilité pour les utilisateurs qui ont direnv installé.
J'ai vérifié que les variables d'environnements "parents" sont bien conservées en cas de changement de variable d'environnement par Mise dans un sous dossier.
#JeMeDemande si je vais rencontrer des régressions par rapport à direnv 🤔.
J'ai décidé d'utiliser la fonctionnalité "mise env._source" pendant quelques semaines pour me faire une opinion.
Update : voir 2024-11-06_2109.
Journal du lundi 28 octobre 2024 à 18:30
Été 2021, j'ai essayé d'utiliser PostgREST dans un projet professionnel, mais j'ai abandonné cette option en raison de trop nombreuses limitations rencontrées.
Depuis, je constate que PostgREST a beaucoup évolué : CHANGELOG.md.
Cela pourrait valoir la peine que je redonne une chance à ce projet lors de ma prochaine réalisation d'une API REST.
#JeMeDemande si la bonne santé du projet est liée au sponsoring de Supabase.
Sur la page Patreon du projet, je constate qu'il reçoit 1375 € de don récurrent par mois.
Journal du dimanche 20 octobre 2024 à 10:04
La version 5 de Svelte vient de sortir : 5.0.0.
Il y a un an, j'avais lu le billet Introducing runes. Depuis, j'ai suivi ce sujet de loin.
J'aimerais tester et apprendre à utiliser la fonctionnalité rune.
#JeMeDemande dans quel projet 🤔. Est-ce que je préfère refactorer vers rune le projet sklein-pkm-engine ou gibbon-replay 🤔. Je pense que ces deux projets utilisent trop peu de "reactive state".
Je souhaite prochainement débuter le projet que j'ai présenté dans 2023-10-28_2008. Je pense que ça serait une bonne occasion pour créer mon premier projet 100% TypeScript avec Svelte 5 avec Rune.
Journal du mardi 15 octobre 2024 à 10:48
Un ami m'a fait découvrir le journal Politico et Politico Europe qui ressemble à Contexte en bien plus "gros".
Politico traite de l'actualité politique de la Maison-Blanche, du Congrès, et des différents États américains. Depuis 2014, il dispose d'une édition européenne intitulée Politico Europe.
Le groupe dispose d'une édition payante, Politico Pro, qui diffuse des informations de haute valeur ajoutée, et est utilisée par les cabinets de lobbying et journalistes spécialisés. Politico est considéré comme une source d’information influente dans les milieux politiques.
-- from
J'avais déjà entendu parler de ce média, mais c'est la première fois que je me penche réellement sur sa ligne éditoriale.
Je lis que ce média est influent, #JeMeDemande s'il parvient à maintenir un niveau d'objectivité satisfaisant 🤔.
Depuis l'été 2021, Politico est détenu par le géant allemand Axel Springer (Entreprise).
-- from
Sur la page Wikipédia de Axel Springer (Entreprise), je lis :
Axel Springer a été impliqué dans de nombreuses controverses. Ses médias sont parfois accusés de populisme ou non-respect de l'éthique journalistique.
Le groupe est principalement détenu par le fonds d'investissement américain KKR (42%) et par Friede Springer, la veuve du fondateur. Son dirigeant est le milliardaire Mathias Döpfner depuis 2002.
-- from
Journal du dimanche 06 octobre 2024 à 19:26
#JeMeDemande s'il existe une communauté identique à social.coop, mais 100% francophone 🤔.
J'ai posté le message suivant :
Connaissez-vous une instance Mastodon gérée par des membres francophones ou des personnes localisées en France, dont le financement et la gouvernance s'inspirent de celle de "social.coop" ? Autrement dit, une instance financée par ses utilisateurs, avec un financement transparent via Open Collective et des décisions prises collectivement sur Loomio.
Traduction :
Do you know a Mastodon instance managed by French members whose financing and governance are inspired by that of “social.coop”? In other words, an instance funded by its users, with transparent financing via Open Collective and decisions taken collectively on Loomio.
Sur :
- Le Subreddit Fediverse : https://old.reddit.com/r/Mastodon/comments/1fxottc/do_you_know_a_mastodon_instance_managed_by_french/
- Message adressé à Nathan Schneider, un administrateur de social.coop : https://mamot.fr/@stephane_klein/113262176462779173
- Message adressé au compte administrateur de l'instance Piaille : https://mamot.fr/@stephane_klein/113262221066589302
Première itération de mon aventure Malt
Il y a quelques mois, j'ai envisagé de créer plusieurs profils sur Malt pour me présenter sous différentes "casquettes". Par exemple :
- CTO as a Service
- CPTO
- DevOps
- Expert en Web Scraping
- Développeur Frontend
- Développeur Backend
- Développeur Fullstack
- …
Cette idée m'est venue en 2022, lorsque j'étais CTO chez Spacefill et que je recrutais des freelances pour des missions très spécifiques.
Je m'étais alors rendu compte que la sélection des profils était fastidieuse et que je passais à côté de candidats intéressants simplement à cause de problèmes liés aux mots-clés.
C'est à ce moment-là que je me suis dit que si un jour je m'inscrivais sur une place de marché de freelances, il serait judicieux de créer plusieurs types de profils pour contourner ces limitations de filtres.
En août dernier, j'ai fait quelques recherches sur la possibilité de créer plusieurs profils sur Malt et je suis tombé sur cette page (webarchive):
Créer plusieurs profils dans Malt ?
Vous pouvez créer plusieurs profils dans Malt. Chaque compte doit être associé à une adresse e-mail différente.
Chez Malt, nous déconseillons de créer deux profils différents sur la marketplace sauf si vous avez deux activités très différentes, par exemple si vous êtes développeur et graphiste.
Vos filleuls et gains cumulés seront alors répartis entre plusieurs profils.
Si vous exercez deux activités indépendantes très différentes, nous vous conseillons de créer deux comptes distincts en prenant soin de télécharger les documents liés à votre(vos) activité(s).
Nous ne pourrons pas fusionner vos notes et projets entre vos deux profils.
Création de mon compte Malt
Je me suis ensuite dit qu'avant de mettre en place une stratégie complexe, qu'il serait plus judicieux de commencer par créer et publier un simple profil.
En remplissant ce profil, j'ai constaté que je pouvais renseigner une longue liste de compétences. J'ai alors pensé que l'idée de créer plusieurs profils n'était finalement plus nécessaire.
Premier point de difficulté, le choix de la catégorie :
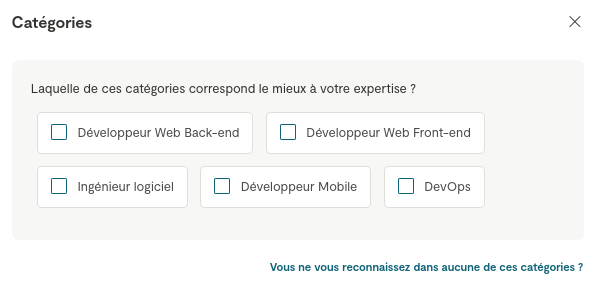
J'ai opté pour une catégorie générique, celle de "Ingénieur logiciel".
Cependant, je doute fortement que ce soit le premier choix d'une personne que utilise le recherche de Malt 🤔 :
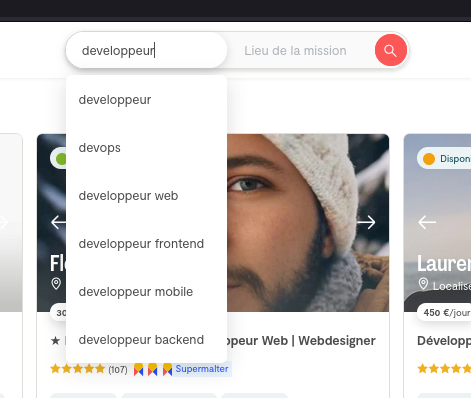
'ai fait un test en choisissant l'intitulé "Développeur". Après avoir filtré par mon tarif journalier exact et mon niveau d'expérience, je suis présent en page 6 des résultats.
Si je sélectionne la catégorie "Développeur Web Back-end" ou "Développeur Web Front-end" je ne suis plus présente dans la liste des résultats 😟.
Bilan Malt après 25 jours
Mon bilan Malt après 25 jours ? Pour le moment, personne ne m'a contacté. J'observe que mes statistiques sont plutôt mauvaises. De plus, je pense que les 3 personnes qui ont vu mon profil sont des amis.
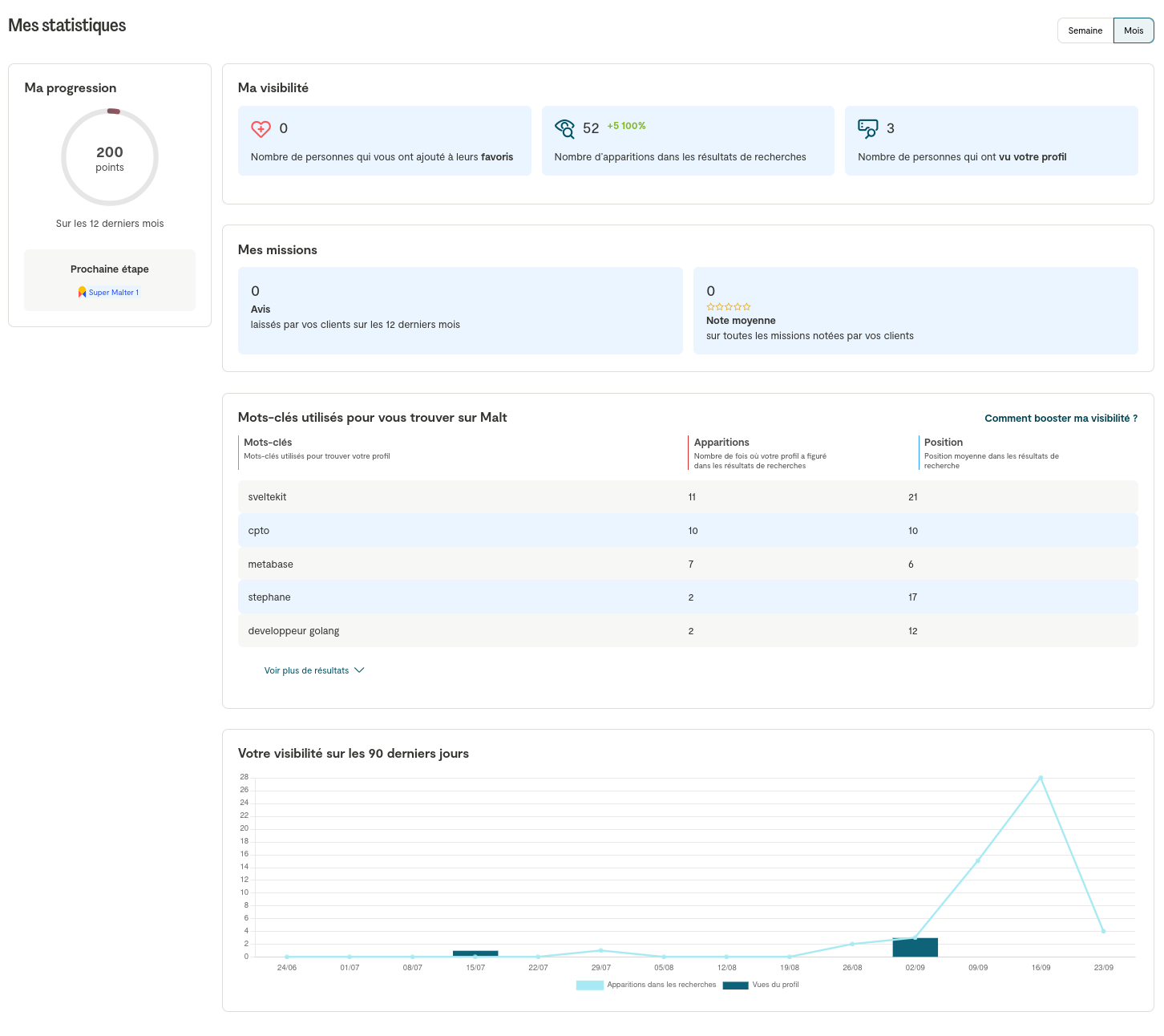
Un ami freelance m'a confié qu'il n'avait reçu qu'une seule proposition de mission sur Malt en plus de trois ans.
Un autre ami freelance m'a confié avoir eu, sur un an, sur Malt, environ 40 propositions de mission, 5 échanges constructifs et signé deux missions.
Suite de stratégie Malt ?
Il est clair que mon profil Malt n'est pas optimisé.
J'ai visé trop large en listant mes compétences, et je pense que ce n'est pas la meilleure stratégie.
Le problème, c'est que si je veux rendre mon profil plus spécialisé, je vais devoir faire des choix et retirer des compétences que je ne souhaite pas supprimer 😞.
Pour éviter cela, je vois deux stratégies :
- Modifier mon profil chaque semaine, en ajustant les technologies, les catégories et le tarif journalier ;
- Créer plusieurs profils.
#JeMeDemande si l'étape de vérification des documents d'entreprise va m'empêcher de créer plusieurs profils 🤔.
#JeMeDemande s'il est préférable que je consacre prioritairement du temps à l'optimisation de mon profil Malt ou alors de travailler sur ma Stratégie de promotion de mon activité freelance sur LinkedIn 🤔.
#JaiDécidé de reporter l'optimisation de mon profil Malt.
Journal du lundi 23 septembre 2024 à 17:12
PostgreSQL zero-downtime migrations made easy.
#JaiLu en partie ce thread Hacker News de 2023.
Après avoir lu partiellement la documentation, j'ai l'impression que pgroll est simple à utiliser pour des migrations qui restent simples.
J'ai lu la section Raw SQL et #JeMeDemande si pgroll reste pratique à utiliser pour des migrations complexes, par exemple, split d'une table en plusieurs tables, merge de tables…
Je ne suis pas très motivé pour apprendre un nouveau DSL, c'est-à-dire, le format de migrations de pgroll à la place des instructions DDL (Data Definition Language) SQL (create, alter…).
Pour le moment, j'ai réussi à réaliser "à la main" des migrations en douceur : mise en place de view, de triggers… qui sont par la suite supprimés.
Je pense que pgroll serait très pratique avec une fonctionnalité Skew Protection pour un projet où les déploiements en production en journée sont fréquents et qui ne souhaite pas imposer aux utilisateurs de rafraîchir leurs pages.
Journal du vendredi 20 septembre 2024 à 10:25
#JaiDécouvert et un peu étudié Temporal (workflow management).
D'après ce que j'ai compris, Temporal a été initialement développé par les auteurs (Maxim Fateev et Samar Abbas) de Cadence.
Je me souviens d'avoir étudié Cadence vers 2019. J'ai l'impression que ce projet est encore très actif. #JeMeDemande quelles sont les réelles différences entre Temporal et Cadence 🤔.
Une première réponse à ma question :
- Temporal supporte les langages Go, Java, PHP, Python, TypeScript, dotNET alors que Cadence est limitée aux langages Go et Java.
- Cadence propose une UI nommée
cadence-webqui semble plus minimaliste quetemporalio/ui.
D'après ce que j'ai lu, Temporal est totalement open-source, sous licence MIT. L'entreprise Temporal propose une version hébergée (managée) nommée Temporal Cloud.
#JaiDécouvert un exemple de projet d'Order Management System codé en Go et basé sur Temporal : https://github.com/temporalio/reference-app-orders-go.
Je n'ai pas étudié le code source, mais c'est un sujet qui m'intéresse, étant donné que j'ai travaillé par le passé sur le développement d'un Order Management System 😉.
Journal du mercredi 11 septembre 2024 à 11:14
Dans la branche gibbon-replay-js du projet Idée d'un outil de session recoding web minimaliste basé sur rrweb, j'ai essayé sans succès d'extraire du code dans un package Javascript.
Pour le moment l'import suivant ne fonctionne pas :
import gibbonReplayJs from 'gibbon-replay-js';
Quand je lance pnpm run build, j'ai l'erreur suivante :
$ pnpm run build
...
x Build failed in 336ms
error during build:
src/routes/(record)/+layout.svelte (2:11): "default" is not exported by "packages/gibbon-replay-js/dist/index.js", imported by "src/routes/(record)/+layout.svelte".
file: /home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/src/routes/(record)/+layout.svelte:2:11
1: <script>
2: import gibbonReplayJs from 'gibbon-replay-js';
Et quand je lance pnpm run dev, j'ai l'erreur suivante :
$ pnpm run dev
...
11:21:21 [vite] Error when evaluating SSR module /packages/gibbon-replay-js/dist/index.js:
|- ReferenceError: exports is not defined
at eval (/home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/packages/gibbon-replay-js/dist/index.js:5:23)
at instantiateModule (file:///home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/node_modules/.pnpm/vite@5.4.3/node_modules/vite/dist/node/chunks/dep-BaOMuo4I.js:52904:11)
11:21:21 [vite] Error when evaluating SSR module /src/routes/(record)/+layout.svelte:
|- ReferenceError: exports is not defined
at eval (/home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/packages/gibbon-replay-js/dist/index.js:5:23)
at instantiateModule (file:///home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/node_modules/.pnpm/vite@5.4.3/node_modules/vite/dist/node/chunks/dep-BaOMuo4I.js:52904:11)
Suite à cette frustration, j'ai envie de créer un projet, sans doute nommé javascript-package-playground dans lequel je souhaite étudier les sujets suivants :
- mise en place d'une librairie
/packages/lib1/qui contient une librairie javascript, qui peut être importé avec la méthode ECMAScript Modules ; - mise en place d'une app NodeJS dans
/services/app1_nodejs/qui utiliselib1; - mise en place d'une app SvelteKit dans
/services/app2_sveltekit/qui utiliselib1dans un fichier coté server et dans une page web coté browser ; - mise en place d'une librairie
/packages/lib2qui utiliselib1
Je souhaite décliner ces 2 libs et 2 apps sous plusieurs déclinaisons d'implémentation :
- avec le build basé sur tsc
- avec le build basé sur esbuild
- avec le build basé sur Babel (Javascript)
- et sans build
Et le tout encore dans deux déclinaisons : Javascript et TypeScript.
Je ne souhaite pas supporter CommonJS qui est sur le déclin, remplacé par ECMAScript Modules.
Dans ce playground, je souhaite aussi me perfectionner dans l'usage de pnpm link et pnpm workspace.
#JeMeDemande si ces connaissances sont totalement maitrisées et évidentes chez mes amis développeurs Javascript 🤔 et s'ils les considèrent comme "basiques".
Journal du samedi 07 septembre 2024 à 19:32
#JeMeDemande souvent comment nommer la méthode permettant d'installer des applications de manière scriptée.
Lorsque je recherche cette fonctionnalité, j'utilise généralement les mots-clés : "headless", "script", "cli".
Je constate que la roadmap de Proxmox utilise le terme « automated and unattended installation » :
Support for automated and unattended installation of Proxmox VE.
-- from
#JaiPublié cette question dans la section discussion du projet Plausible : Plausible automated and unattended installation support (create user and web site by script) · plausible/analytics.
Journal du mardi 27 août 2024 à 15:02
Au cours des 12 derniers mois, j'ai été confronté à la nécessité de compléter de nombreux dossiers administratifs complexes, chacun comprenant un grand nombre de documents. Voici quelques exemples concrets :
- J'ai dû rassembler et transmettre à mon courtier immobilier un dossier complet de 70 fichiers pour l'achat de mon logement, une opération impliquant quatre acteurs : le courtier, la banque, ma compagne et moi-même.
- J'ai constitué et envoyé un dossier à un diagnosticien pour obtenir un certificat de Diagnostic de performance énergétique
- J'ai préparé et soumis un dossier pour une assurance de prêt immobilier.
- Dans le cadre de mes fonctions de président d'association :
- J'ai demandé à des futurs employés de compléter un dossier d'embauche.
- J'ai rédigé trois dossiers distincts pour effectuer trois demandes de subventions différentes.
- J'ai constitué et transmis un dossier destiné au Commissaire aux comptes.
- Demande de dossier pour l'entrée d'un locataire de logement.
Méthodes utilisées pour constituer et transmettre ces dossiers :
- Partage via Google Drive ;
- Envoi par email ;
- Utilisation de plateformes en ligne proposées par certaines structures, comme la mairie ou le conseil départemental, pour l'upload des documents.
Difficultés rencontrées :
- Identifier précisément les documents à fournir, avec un manque d'exemples ou de spécimens pour référence.
- Gestion du workflow de validation des pièces.
- Difficultés de nommage et d'identification des documents.
- Problèmes de versionning des documents.
- Difficile d'avoir une vue d'ensemble des documents manquants.
- Suivi de la progression difficile.
- Pas de statut clair si un document est validé ou non.
- Méthode de notification de mise à jour de document imprécis.
- Complexité accrue lorsque plusieurs personnes participent à la constitution d'un dossier.
- Limites de taille pour certains documents.
- Choix de la plateforme d'échange : certaines personnes refusent d'utiliser certains outils.
- Conformité avec le RGPD.
- …
Fort de cette expérience et des difficultés rencontrées, je m'interroge sur la possibilité de créer une application web capable de simplifier la constitution de dossiers.
Voici l'idée que j'envisage.
Souvent, un email ou un fichier PDF détaille les pièces nécessaires à la constitution d'un dossier.
Je propose de remplacer ou de compléter ces documents par une page web interactive.
.png) Cette page web intégrerait la documentation nécessaire ainsi que les emplacements pour uploader les documents requis.
Cette page web intégrerait la documentation nécessaire ainsi que les emplacements pour uploader les documents requis.
L'objectif pour l'utilisateur chargé de rassembler les documents est de combler les "trous" : si un trou est visible, cela signifie qu'un document est manquant.
Les PDF seraient transformés en images miniatures, cliquables pour un aperçu en zoom, ce qui est bien plus pratique que d'ouvrir un PDF entier pour le consulter.
Dans ce croquis, j'ai tenté de représenter en bas à droite un composant d'interface permettant de savoir si une pièce est validée ou refusée (ce n'est qu'une première ébauche de cette fonctionnalité).
J'imagine également un espace dédié à la consultation des dernières activités effectuées sur le dossier.
L'interface utilisateur varierait légèrement en fonction du type d'utilisateur et de son rôle dans le processus. Par exemple, un courtier pourrait rapidement voir les pièces qu'il doit valider.
Je prévois aussi la possibilité de visualiser un spécimen du document, ainsi qu'un système de commentaires attachés à un document ou à un groupe de documents, permettant de comprendre facilement à quel document une remarque fait référence.
Je pense que tant la personne qui constitue le dossier que celle qui en demande la complétion pourraient devenir prescripteurs du service. Idéalement, c'est le demandeur des documents qui devrait être le prescripteur, car cela lui permettrait de configurer et documenter en amont un template de dossier. Ce template pourrait ensuite être réutilisé à volonté.
J'imagine également que le service pourrait envoyer un SMS contenant un message tel que « John Doe vous demande les documents suivants …url… » ou « Alice vous a envoyé les documents suivants …url… ».
Cela pourrait remplacer des solutions comme WeTransfer, Dropbox ou Google Drive.
Cette grande page web permettrait d'organiser et d'identifier clairement tous les documents, évitant ainsi de devoir gérer un amas de fichiers aux noms pas toujours explicites.
Si un utilisateur a un compte sur la plateforme, il pourrait très bien garder de coté des pièces très souvent demandé, comme sa carte d'identité par exemple.
Il serait également possible d'intégrer une fonctionnalité de chiffrement symétrique côté browser, pour assurer la confidentialité des documents (voir [référence 2024-08-27_1406]).
Une autre idée serait de proposer des templates préconfigurés :
- Template standard pour une demande de location ;
- Template standard pour une demande de prêt ;
- Template standard pour un Diagnostic de Performance Énergétique (DPE).
De plus, si un utilisateur dispose d'un compte sur la plateforme, il pourrait conserver des documents fréquemment demandés, comme sa carte d'identité, pour les réutiliser facilement.
Idéalement, ce service serait distribué sous une licence de type fair source.
Pour l’implémentation, la première étape consisterait à configurer un template initial codé en dur, par exemple, un dossier de demande de location.
Ensuite, implémenter le système de gestion des documents manquants ("trous") avec un rendu des PDF sous forme d’images.
Ah… j'ai oublié quelque chose d'important ! #JeMeDemande si ce type de produit existe déjà !
Deux options s'offrent à moi : soit je me lance pour le plaisir et développe une première version de cette application, soit je prends les choses plus au sérieux et réalise une étude de marché 🤔.
Mon premier beta testeur pourrait être mon ami courtier en prêt immobilier.
Journal du mardi 27 août 2024 à 14:23
#JaiLu en partie le thread Hacker News Dokku: My favorite personal serverless platform.
- https://github.com/skateco/skate
- dokploy
- kamal
- ptah.sh (sous licence fair source)
J'ai apprécié ce tableau de comparaison de fonctionnalités entre dokploy, CapRover, Dokku et Coolify.
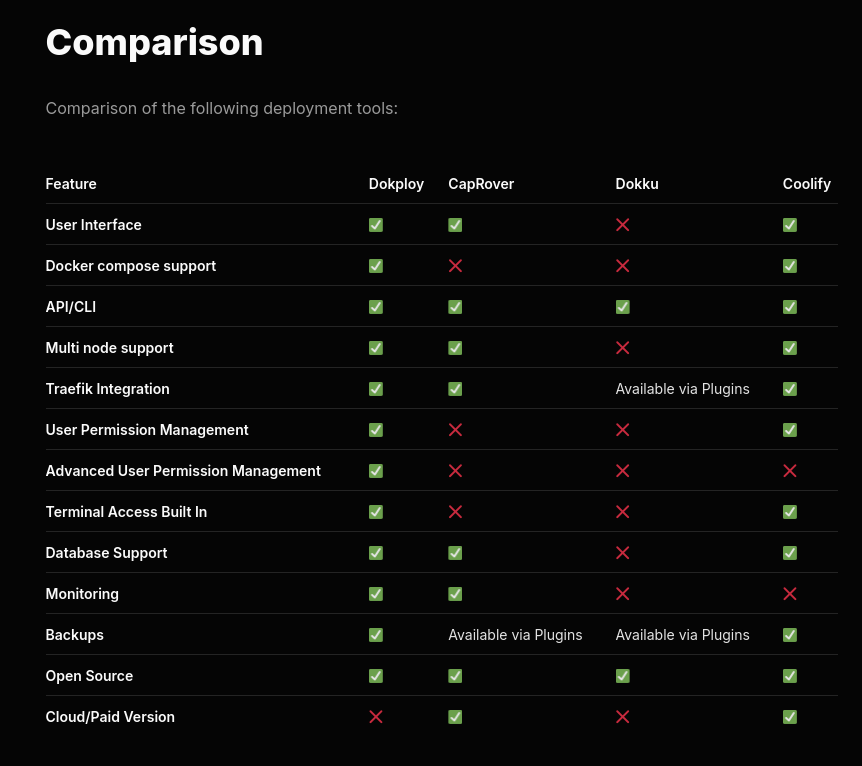
C'est la ligne "Docker compose support" qui a attiré mon attention.
Je reste très attaché au support de docker compose qui je trouve est une spécification en même temps simple, complète et flexible qui ne m'a jamais déçu ces 9 dernières années.
Attention, je n'ai pas bien compris si Dokku est réellement open source ou non 🤔.
Je constate que Dokploy est basé sur Docker Swarm.
Dokploy leverages Docker Swarm to orchestrate and manage container deployments for your applications, providing an intuitive interface for monitoring and control.
-- from
Choix qui me paraît surprenant puisque Docker Swarm est officieusement déprécié.
Je me suis demandé si K3s pourrait être une alternative à Docker Swarm 🤔.
Journal du samedi 17 août 2024 à 15:00
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
-- from
#JeMeDemande également si pg_search, Typesense et Meilisearch peuvent réaliser la même chose que ce qui est décrit dans Elastic Search: Highlighting Text That Contains HTML Tags.
En ce qui concerne Typesense, j'ai consulté l'issue Feature Request - Ignore any HTML tags when searching but still return response with HTML included, ce qui me laisse penser que cette fonctionnalité n'est pas prise en charge.
Pour Meilisearch, la discussion Ignore HTML tags at search m'a également conduit à la conclusion que cette fonctionnalité n'est pas encore implémentée. J'ai aussi appris qu'Algolia permet d'ignorer les balises HTML lors de la recherche : Algolia ignores HTML tags during search.
Quant à pg_search, mes recherches sur les mots-clés HTML dans les dépôts pg_search et Tantivy (Tantivy) n'ont rien donné. Il semble donc que la fonctionnalité de surlignage du texte contenant des balises HTML ne soit pas prise en charge par pg_search.
Contenu de ce constat, je vais peut-être redonner une chance à Elasticsearch malgré mon aversion pour la JVM 🤔.
Journal du samedi 17 août 2024 à 12:53
Ce matin, j'ai enfin pris le temps de parcourir attentivement la documentation d'Elasticsearch pour comparer ses fonctionnalités à celles de Meilisearch, Typesense et pg_search.
J'ai lu Text analysis overview de Elasticsearch.
Je note ici les étapes de l'Text analysis que j'ai des difficultés à retenir :
- Tokenization
- Token filtering (voir dans Anatomy of an analyzer)
- Normalization (search engine)
- Stemmer token filter (search engine)
- Character filters reference
- Customize text analysis
J'ai parcouru la liste des différents types des Built-in analyzer reference de Elasticsearch.
Je retiens le concept de stop analyzer.
#JeMeDemande l'usage du Keyword analyzer 🤔.
Je trouve le Pattern analyzer intéressant.
En lisant Fingerprint analyzer je découvre l'algorithme fingerprinting décrit dans la documentation de OpenRefine : https://openrefine.org/docs/technical-reference/clustering-in-depth#fingerprint. Je garde cela dans un coin de mon esprit, il se peut que cela me soit utile à l'avenir 🤔.
Je découvre que Elasticsearch (sans doute Lucene 🤔) propose beauoup de token filtering différent qui peuvent être combinés : Apostrophe, ASCII folding, CJK bigram, CJK width, Classic, Common grams, Conditional, Decimal digit, Delimited payload, Dictionary decompounder, Edge n-gram, Elision, Fingerprint, Flatten graph, Hunspell, Hyphenation decompounder, Keep types, Keep words, Keyword marker, Keyword repeat, KStem, Length, Limit token count, Lowercase, MinHash, Multiplexer, N-gram, Normalization, Pattern capture, Pattern replace, Phonetic, Porter stem, Predicate script, Remove duplicates, Reverse, Shingle, Snowball, Stemmer, Stemmer override, Stop, Synonym, Synonym graph, Trim, Truncate, Unique, Uppercase, Word delimiter, Word delimiter graph.
J'ai lu Stemmer token filter que je considère comme très important pour un moteur de recherche efficace.
#JaiDécouvert le support de Synonym graph token filter.
Je lis HTML strip character filter, fonctionnalité que je juge très utile.
Je lis qu'Elasticsearch propose de nombreuses méthodes de query, entre autres :
- Query DSL
- EQL search
- ES QL
- et même SQL
- Scripting
Tout cela est très riche !
J'ai lu Highlighting
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
Journal du mardi 13 août 2024 à 10:41
Deux amis m'ont partagé un thread Hacker News : Postgres.new: In-browser Postgres with an AI interface.
Je viens de prendre le temps de tester postgres.new.
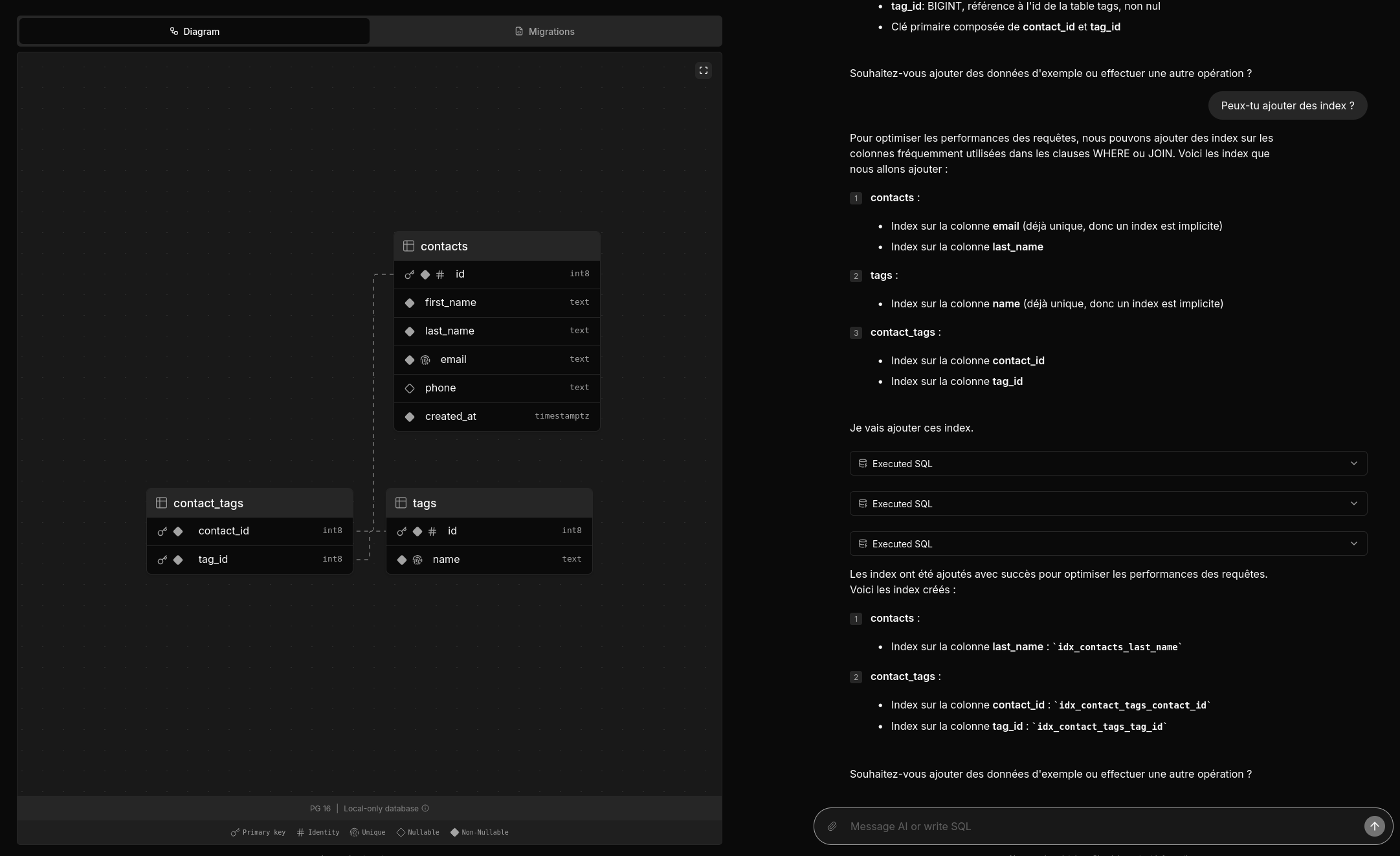
Voici une vidéo officielle : https://www.youtube.com/watch?v=ooWaPVvljlU
#Jadore ! Je trouve l'UX très bonne, j'aime l'onglet "Migrations", les explications données dans la colonne de droite.
Le projet est 100% Open source, voici le dépôt GitHub : https://github.com/supabase-community/postgres-new
Très beau travail !
Je me demande combien de temps ce projet a été implémenté 🤔.
1 mois et demi d'après la page contributors.
Mais je constate que le premier commit est plutôt conséquent, je pense que le projet était initialement intégré dans un mono repository.
Concernant l'implémentation, je lis :
All queries in postgres.new run directly in your browser. There’s no remote Postgres container or WebSocket proxy.
👍️
How is this possible? PGlite, a WASM version of PostgreSQL that can run directly in your browser. Every database that you create spins up a new instance of PGlite that exposes a fully-functional Postgres database. Data is stored in IndexedDB so that changes persist after refresh.
La partie LLM n'est pas mentionnée, #JeMeDemande comment elle est implémentée 🤔.
Je pense avoir trouvé ma réponse ici :
We pair PGlite with an LLM (currently GPT-4o) and give it full reign over the database with unrestricted permissions. (from)
Je lis :
RAG / pgvector: PGLite supports pgvector, so you can ask the LLM to create embeddings for RAG. The site uses transformers.js to create embeddings inside the browser.
Je n'ai pas tout compris 🤔.
#JaiDécouvert transformers.js.
J'ai lu ce commentaire :
It is a neat tech demo but it clearly shows the limits of AI:
- I got it to generate invalid SQL resulting in errors - it merely generates reasonable SQL, but in my case it generated to disjoint set of tables…. - In practice you have tot review all code - It can point you into the wrong direction. Novel systems often have something smart/abstract in there. This system creates mostly Straightforward simple systems. That’s not where the value is
All in all, it’s not worth it to me. Writing code myself is easier than having to review LLM code
Within our organization we have forbidden full LLM merge request because more often than not the code was suboptimal. And had sneaky bugs/mistakes.
I’m not saying these can’t be overcome. But not with current LLM design. They mostly generate stuff they have seen and are bad as truly new stuff.
Personnellement, cela ne me surprend pas et cela ne remet pas en question, à mes yeux, l'intérêt de cet outil.
Je pense l'utiliser pour concevoir une ébauche de base de données.
Je pense qu'il pourra me fournir de bonnes suggestions pour les noms de tables et de champs, et même inclure des champs auxquels je n'aurais peut-être pas pensé.
Journal du samedi 10 août 2024 à 17:26
Dans mon PKM notes.sklein.xyz, #JeMeDemande quels sont les différences entre les tags et Wikilinks 🤔.
Les tags et les wikilinks me permettent tous les deux de retrouver une note à partir d'un ou plusieurs mots :
Contrairement aux tags, les wikilinks permettent :
- D'être documenté ;
- De proposer les alias.
Pour le moment, je ne vois pas d'avantage à utiliser des tags 🤔.
#JaiLu les threads suivants du forum Obsidian :
Links auto-refactor by default, and tags do not
This is a big one!
When you change the name of a file within Obsidian, all links to that folder will automatically change to be pointing to the right place. -- from
Je trouve que cette différence n'est pas négligeable 🤔.
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
People often debate the merits of using tags vs. page links to organize your notes. With tag pages, you can combine the best of both worlds: the visibility and fluid entry of tags, plus the centralized content and outbound linking of a page. -- from
Je trouve cette fonctionnalité intéressante, mais #JeMeDemande si l'utilisation de wikilinks ne serait pas une option plus simple 🤔.
Journal du mardi 06 août 2024 à 14:27
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
#JaiDécouvert lezer-markdown-obsidian qui correspond à ce que j'ai besoin pour 2024-08-06_1140.
Je viens de voir ici une propriété complete :
class FootnoteReferenceParser implements LeafBlockParser {
...
complete(cx: BlockContext, leaf: LeafBlock) {
cx.addLeafElement(
leaf,
cx.elt(
"FootnoteReference",
leaf.start,
leaf.start + leaf.content.length,
[
cx.elt("FootnoteMark", leaf.start, leaf.start + 2),
cx.elt("FootnoteLabel", leaf.start + 2, this.labelEnd - 2),
cx.elt("FootnoteMark", this.labelEnd - 2, this.labelEnd),
...cx.parser.parseInline(
leaf.content.slice(this.labelEnd - leaf.start),
this.labelEnd
),
]
)
);
return true;
}
}
Dans le Projet 1 - "CodeMirror, autocomplétion, Svelte", #JeMeDemande si je ne suis pas passé à coté d'une meilleur méthode pour implémenter de l'auto complétiion dans CodeMirror 🤔.
Journal du lundi 05 août 2024 à 22:57
« #JeMeDemande si lezer sera un jour remplacé par tree-sitter compilé en WASM 🤔. » -- from
Je viens de lire le thread suivant : [Question: difference between Lezer and tree-sitter](# Question: difference between Lezer and tree-sitter).
This system's approach is heavily influenced by tree-sitter, a similar system written in C and Rust, and several papers by Tim Wagner and Susan Graham on incremental parsing (1, 2). It exists as a different system because it has different priorities than tree-sitter—as part of a JavaScript system, it is written in JavaScript, with relatively small library and parser table size. It also generates more compact in-memory trees, to avoid putting too much pressure on the user's machine. -- from
Journal du lundi 05 août 2024 à 15:20
Je regarde le site web de lezer https://lezer.codemirror.net/ et je constate qu'il a le même look que CodeMirror.
J'en déduis qu'il est sans doute développé par les mêmes développeur que CodeMirror.
#JeMeDemande si lezer sera un jour remplacé par tree-sitter compilé en WASM 🤔.
Journal du lundi 05 août 2024 à 14:52
Dans le cadre du Projet 8 - "CodeMirror, conceal, Svelte", j'essaie de m'inspirer du code source de SilverBullet.mb.
#JeMeDemande si l'implémentation de la fonctionnalité conceal sur les wikilink se trouve ici 🤔.
Je constate ici que l'implémentation ne prend pas en charge directement la recherche des de la syntax [[wikilink]] via, par exemple, une regex, mais l'implémentation semble utiliser un parser Markdown.
Je constate ici que SilverBullet.mb est basé sur la lib lezer. Ce qui me semble normal, parce que le plugin lang-markdown utilise aussi lezer.
Je ne trouve aucune mention de wikilink dans le code source de /lezer-parser/markdown/, par conséquent, je pense que ce type d'élément a été implémenté dans le code source de SilverBullet.mb.
Journal du mercredi 31 juillet 2024 à 17:33
#JeMeDemande comment définir la largeur d'une image dans Obsidian.
J'ai commencé par faire une recheche sur le forum d'Obsidian : image size.
Et j'ai trouvé ma réponse. La syntax Markdown suivante fonctionne :

🙂
Journal du mardi 30 juillet 2024 à 16:33
Free and Open Source Machine Translation API. Self hosted, offline capable and easy to setup.
Qui utilise Argos Translate :
Open Source offline translation library written in Python.
Qui utilise OpenNMT.
Open source ecosystem for neural machine translation and neural sequence learning.
#JeMeDemande quelle est la différence en termes de qualité de traduction et de consommation d'énergie entre la technologie OpenNMT et les modèles de langage classiques tels que Llama 🤔.
Un ami m'a dit que DeepL utilise un Neural Machine Translation. Ce que semble confirmer cette source.
Journal du mardi 16 juillet 2024 à 13:44
#JaiLu Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret publié sur HAL.
La documentation personnelle peut être définie comme la documentation élaborée par un individu pour lui-même, de manière idiosyncrasique.
#JaiDécouvert le mot Idiosyncrasique.
#JeMeDemande si la condition « pour lui-même » est dépassable ou non 🤔.
(Psychologie) Caractères propres au comportement d’un individu particulier. (from).
Élaborer une documentation personnelle permet d’organiser le processus de « signifiance » (Leleu-Merviel, 2010) pour construire des connaissances (voir figure 1).
#JaiDécouvert la chercheuse Sylvie Leleu-Merviel.
#JeSouhaite lire Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
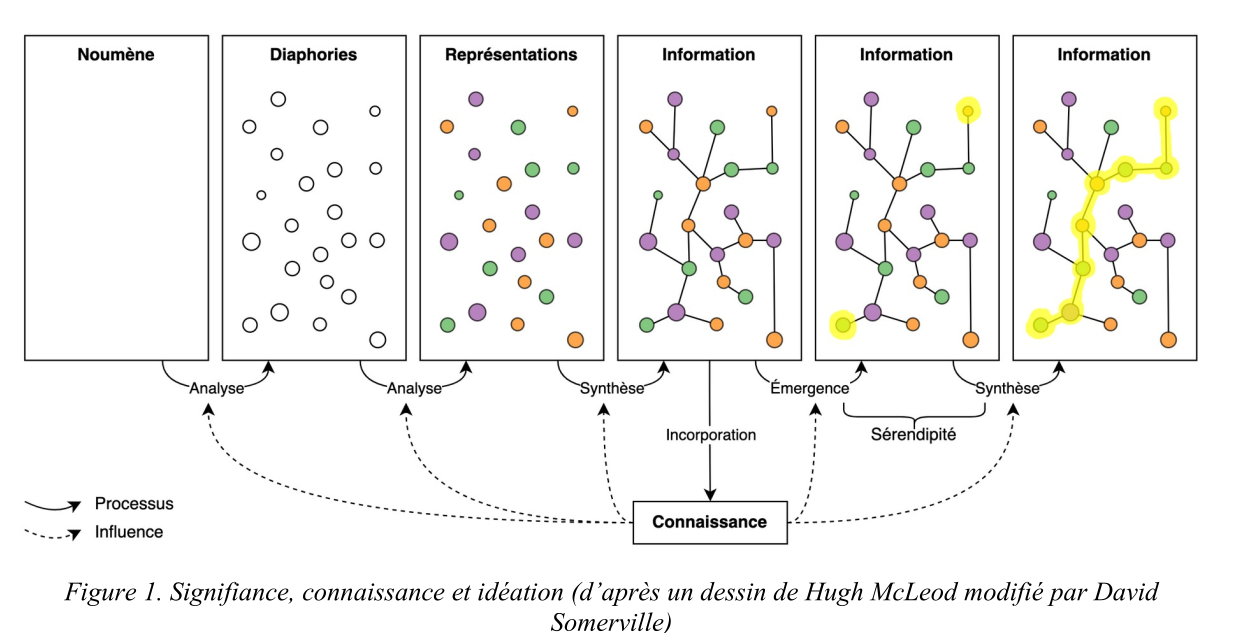 #JaiDécouvert les mots Noumène, Noème et Diaphories.
#JaiDécouvert les mots Noumène, Noème et Diaphories.
Comme l’écrit Latour (dans « Pensée retenue, pensée distribuée »), la pensée n’est pas « retenue » dans l’unique cerveau du penseur, mais « distribuée » dans un ensemble d’acteurs et d’actants – un « milieu de savoir » selon l’expression de Le Deuff : données et documents, individus et collectifs, lieux, évènements et dispositifs divers.
#JaiDécouvert Traité de documentation de Paul Otlet.
#JaiDécouvert Robert Estivals et Communicology.
L’approche hypertextuelle présente plusieurs avantages par rapport aux graphes de connaissance, notamment une mise en œuvre plus simple et une plus grande expressivité. Cette méthode produit ce que Stiegler (Le concept d’ « Idiotexte » : esquisses - 2010) appelle un idiotexte, c’est-à-dire la textualisation d’une mémoire personnelle. L’utilité primaire de cette méthode, pour l’individu qui crée sa documentation personnelle, est de multiplier les chemins vers une même information, via des connexions riches en signification et facilement réactivées.
#JaiDécouvert idiotexte, j'ai lu l'article mentionné et je ne l'ai pas compris 🙅♀️.
Cette méthode présente également un intérêt pour les recherches sur les systèmes d’organisation des connaissances (SOC). Mazzocchi (2018) définit les SOC comme des ensembles de termes ou concepts interreliés, outils intermédiaires entre des humains et des collections de données et documents. Dans la méthode que nous avons décrite, la création d’un graphe documentaire correspond à la fois à la création d’une collection de documents – les fiches – et d’un SOC – les catégories de fiches et de liens utilisées dans le graphe.
#JaiDécouvert Systèmes d’organisation des connaissances (SOC).
D’abord, cette méthode est orientée par la subjectivité : les choix qui guident l’élaboration du graphe sont basés sur la mémorabilité, critère hautement subjectif.
Ok, j'ai bien compris 👌.
Par exemple, des catégories de fiches peuvent être modifiées, supprimées ou ajoutées progressivement pour orienter la manière dont fonctionne la remémoration.
Ok, j'ai bien compris 👌.
#JaiDécouvert L’épistémologie sociale (from)
J'ai pris le temps de regarder https://www.arthurperret.fr/glossaire-indexation.html, j'ai trouvé des choses intéressantes, du vocabulaire pour nommer des éléments techniques des CMS.
Ces configurations affectent la manière dont nous remémorons les choses : nous nous disons par exemple « J’ai mentionné ce concept dans telle publication » ou bien « C’est untel qui m’a recommandé cette méthode ». Ces connexions idiosyncrasiques sont facilement réactivées car elles reposent sur des éléments ayant une grande « mémorabilité » – terme qui renvoie aux arts de la mémoire et que nous entendons ici comme une qualité déterminée subjectivement, de manière réflexive, à partir de situations essentiellement contingentes, qui modifient notre « comportement informationnel ».
Je comprends très bien ce qui est exprimé et cela correspond à mon expérience vécu.
Journal du dimanche 14 juillet 2024 à 10:08
#JeMeDemande comment Typesense gère le contenu HTML présent dans les champs textes. Ignore-t-il ou non les balises HTML ?
Ici dans la documentation, j'ai trouvé un lien vers l'issue intitulée Feature Request - Ignore any HTML tags when searching but still return response with HTML included.
La solution proposée ne me satisfait pas à 100% :
For a simple solution you could introduce an artificial field where all html tags are removed.
Idéalement, j'aimerais que cette fonctionnalité soit directement prise en charge par Typesense.
Journal du mardi 09 juillet 2024 à 08:46
Dans le cadre de mon travail sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément, ma tentative d'utiliser pg_search pour y intégrer un moteur de recherche, j'ai creusé le sujet InstantSearch.
Typesense permet d'utiliser InstantSearch via un adaptateur :
At Typesense, we've built an adapter (opens new window) that lets you use the same Instantsearch widgets as is, but send the queries to Typesense instead. (from)
Ici j'ai découvert des alternatives à InstantSearch :
- typesense-minibar
- autocomplete (aussi créé par Algolia)
- docsearch (aussi créé par Algolia)
#JeMeDemande comment utiliser InstantSearch ou TypeSense-Minibar avec pg_search.
N'ayant pas trouvé de réponse, #JaiPublié How can I implement InstantSearch, Typesense-Minibar or Docsearch with pg_search?.
Journal du lundi 08 juillet 2024 à 09:38
#iteration sur le Projet 10 - "Mettre en oeuvre DotTXT AI".
#JeMeDemande quelles sont les projets alternatif à Outlines 🤔
J'ai trouvé :
- https://github.com/sgl-project/sglang (from)
- https://github.com/guidance-ai/guidance (from)
- https://github.com/eth-sri/lmql (from)
- https://python.langchain.com/v0.1/docs/modules/model_io/output_parsers/types/pydantic/ (from)
- https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md (from)
Journal du dimanche 07 juillet 2024 à 15:59
#iteration sur le Projet 10 - "Mettre en oeuvre DotTXT AI".
16:00
#JeLis Coding For Structured Generation with LLMs
For those new to the blog: structured generation using Outlines (and soon .txt's products!) (from)
Je comprends que https://github.com/outlines-dev/outlines est simplement le repository du futur produit dottxt.
Je pense comprendre que structured generation est le nom officiel de l'objectif de l'outil dottxt.
16:23
#JeMeDemande comment utiliser outlines avec Replicate.com 🤔.
16:31
#JeMeDemande comment utiliser outlines avec Replicate.com 🤔.
Je pense avoir ma réponse ici.
16:47
#JaiPosté How to use outlines with Replicate.com?
J'ai aussi posé la question sur https://replicate.com/support
Journal du dimanche 23 juin 2024 à 10:57
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, #JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
Je lis ici :
#JePense que c'est un synonyme de pg_search mais je n'en suis pas du tout certain.
En regardant la documetation de ParadeDB, je lis :
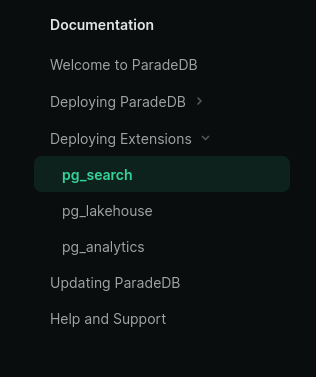
J'en conclu que ParadeDB est un projet qui regroupe plusieurs extensions PostgreSQL : pg_search, pg_lakehouse et pg_analytics.
Pour le Projet 5, je suis intéressé seulement par pg_search.
#JeMeDemande si pg_search dépend de pg_vector mais je pense que ce n'est pas le cas.
#JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
J'ai commencé par essayer de créer cette image Docker en me basant sur ce Dockerfile mais j'ai trouvé cela pas pratique. Je constaté que j'avais trop de chose à modifier.
Suite à cela, je pense que je vais essayer d'installer pg_search avec PGXN.
Lien vers l'extension pg_search sur PGXN : https://pgxn.org/dist/pg_bm25/
Sur GitHub, je n'ai trouvé aucun exemple de Dockerfile qui inclue pgxn install pg_bm25.
J'ai posté https://github.com/paradedb/paradedb/issues/1019#issuecomment-2184933674.
I've seen this PGXN extension https://pgxn.org/dist/pg_bm25/
But for the moment I can't install it:
root@631f852e2bfa:/# pgxn install pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: unpacking: /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: building extension ERROR: no Makefile found in the extension root
J'ai posté pgxn install pg_bm25 => ERROR: no Makefile found in the extension root #1287.
I think I may have found my mistake.
Should I not use
pgxn installbut should I usepgxn download:root@28769237c982:~# pgxn download pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /root/pg_bm25-9.9.9.zip@philippemnoel Can you confirm my hypothesis?
J'ai l'impression que https://pgxn.org/dist/pg_bm25/ n'est buildé que pour PostgreSQL 15.
root@4c6674286839:/# unzip pg_bm25-9.9.9.zip
Archive: pg_bm25-9.9.9.zip
creating: pg_bm25-9.9.9/
creating: pg_bm25-9.9.9/usr/
creating: pg_bm25-9.9.9/usr/lib/
creating: pg_bm25-9.9.9/usr/lib/postgresql/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/
inflating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/pg_bm25.so
creating: pg_bm25-9.9.9/usr/share/
creating: pg_bm25-9.9.9/usr/share/postgresql/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25.control
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25--9.9.9.sql
inflating: pg_bm25-9.9.9/META.json
Je pense que je dois changer de stratégie 🤔.
Je ne pensais pas rencontrer autant de difficultés pour installer cette extension 🤷♂️.
Ce matin, j'ai passé 1h30 sur ce sujet.
J'ai trouvé ce Dockerfile https://github.com/kevinhu/pgsearch/blob/48c4fee0b645fddeb7825802e5d1a4a2beb9a99b/Dockerfile#L14
Je pense pouvoir installer un package Debian présent dans la page release : https://github.com/paradedb/paradedb/releases
Journal du dimanche 16 juin 2024 à 17:08
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
#JeMeDemande si la convention est de nommer les nodes au singulier ou au pluriel, par exemple Note ou Notes 🤔.
D'après cette documentation, je comprends que la convention semble être le singulier.
Journal du samedi 08 juin 2024 à 17:08
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Alors que je travaille sur cette partie du projet, je relis la documentation de pg_dumpall et je constate à nouveau que cette commande ne supporte pas les différents formats de sortie que propose pg_dump 😡.
C'est pénible… du coup, j'ai enfin pris le temps de chercher si il existe une solution alternative et #JaiDécouvert pg_back :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
C'est parfait, c'est exactement ce que je cherche 👌.
Mais je découvre aussi les fonctionnalités suivantes :
- Pre-backup and post-backup hooks
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure or a remote host with SFTP
Conséquence : #JeMeDemande si j'ai encore besoin de restic dans Projet 7 🤔.
Je viens de lire ici :
In addition to the N previous backups, it would be nice to keep N' weekly backups and N'' monthly backups, to be able to look back into the far past.
C'est une fonctionnalité supporté par restic, donc pour le moment, je choisis de continuer à utiliser restic.
Pour le moment, #JaiDécidé d'intégrer simplement pg_back dans restic-pg_dump-docker en remplacement de pg_dumpall et de voir par la suite si je simplifie ce projet ou non.
Journal du jeudi 06 juin 2024 à 22:57
#JeMeDemande quelles sont les différences entre les modèles qui terminent par "rien", par -instruct et par -chat.
This brings us to the heart of the innovation behind the wildly popular ChatGPT: it uses an enhancement of GPT3 that (besides having a lot more parameters), was explicitly fine-tuned on instructions (and dialogs more generally) -- this is referred to as instruction-fine-tuning or IFT for short. In addition to fine-tuning instructions/dialogs, the models behind ChatGPT (i.e., GPT-3.5-Turbo and GPT-4) are further tuned to produce responses that align with human preferences (i.e. produce responses that are more helpful and safe), using a procedure called Reinforcement Learning with Human Feedback (RLHF). (from)
Journal du mercredi 05 juin 2024 à 11:29
#JeMeDemande s'il existe un meilleur moteur de recherche que https://www.postgresql.org/search/?u=%2Fdocs%2F16%2F&q=on+conflict 🤔.
J'ai fait quelques recherches, pour le moment, je n'ai rien trouvé 😟.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

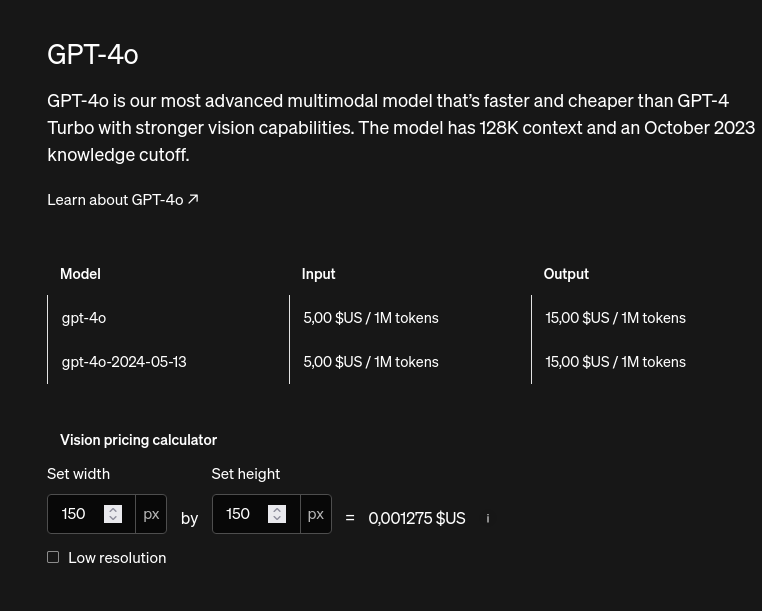
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.
Journal du mardi 28 mai 2024 à 12:29
Sur gwern.net #JaiDécouvert :
- Tests de lisibilité Flesch-Kincaid (from) ( #PasEncoreLu ).
- proselint, je l'avais déjà croisé mais je l'avais oublié. #JeMeDemande si il est possible de supporter le français 🤔 (from).
- Loi de Benford (from) ( #PasEncoreLu )
Journal du jeudi 23 mai 2024 à 21:49
#JeMeDemande comment sous Neovim, je peux lister avec telescope l'historique de mes recherches live_grep_args.live_grep_args 🤔.
22:10 : J'ai trouvé ceci https://github.com/nvim-telescope/telescope.nvim/blob/5665d93988acfbb0747bdbf4f4cb583bcebc8930/lua/telescope/actions/history.lua#L11 mais je ne sais pas encore comment l'utiliser.
22:12 : Je vais essayer https://github.com/nvim-telescope/telescope-live-grep-args.nvim/issues/33
Commit : https://github.com/stephane-klein/dotfiles/commit/c36515c5055a31ecc51e9f08ab02cdb8acdaac69
Journal du jeudi 23 mai 2024 à 10:08
#idée de Projets : #JeMeDemande quelles méthodes utiliser pour implémenter un éditeur web de type texte à trous basé sur les librairies CodeMirror et ProseMirror.
Voici les premiers résultats de recherche que j'ai trouvés.
Pour ProseMirror, j'ai trouvé ceci :
Pour CodeMirror, j'ai trouvé ceci :
#JeMeDemande quelles sont les forces et faiblesses des deux idées d'implémentations suivantes :
a.Texte à trous implémenté par une seule instance d'éditeur CodeMirror/ProseMirror.b.Plusieurs instances d'éditeur CodeMirror/ProseMirror dans une page HTML. Dans cette implémentation les éléments en readonly ne seraient pas présents dans l'éditeur, mais seraientt de simples composants HTML de la page.
Vous êtes sur la première page | [ Page suivante (29) >> ]