
Comment je me renseigne sur un nouveau modèle LLM en 4 étapes
Journal du dimanche 26 avril 2026 à 22:56
Voici le process que je suis lorsque je découvre un nouveau modèle LLM et que je souhaite en savoir plus à son propos.
Étape 1 : blog de Simon Willison
Je commence par jeter un œil rapide sur le blog de Simon Willison, car cela fait plusieurs années que je le suis et j'apprécie son expertise et ses analyses de modèles.
Étape 2 : les articles de Artificial Analysis
Ensuite je regarde les articles (https://artificialanalysis.ai/articles) d'Artificial Analysis, pour voir s'ils ont publié un nouvel article sur ce modèle. Généralement, ils sont très réactifs. Voici un exemple concernant Kimi K2.6 : Kimi K2.6: The new leading open weights model.
J'aime beaucoup la structure de leurs articles.
Tout d'abord, une section synthétique avec des informations majeures du modèle :

Ensuite, la position du nouveau modèle pour différents leaderboards :
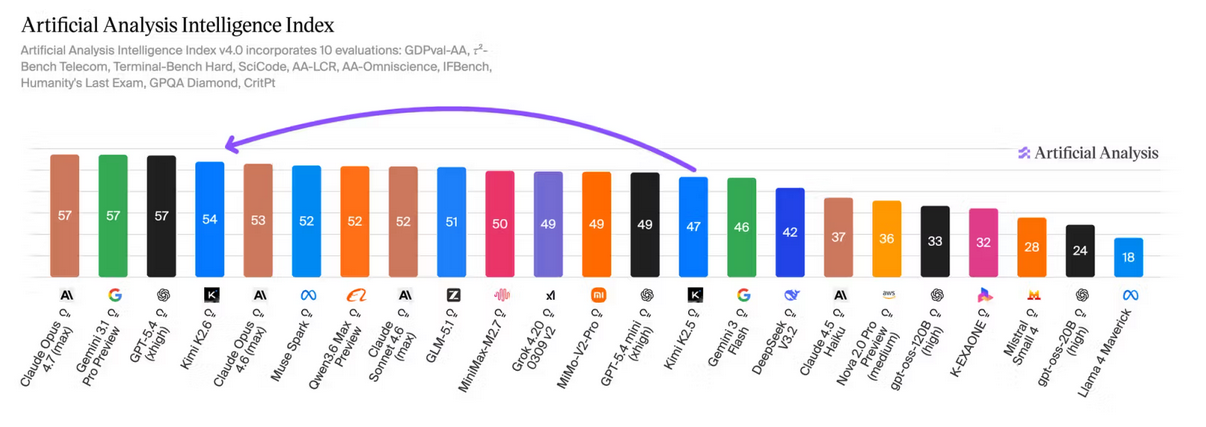
Étape 3 : Analyse des commentaires HackerNews
En troisième étape, j'utilise le moteur de recherche de Hacker News pour identifier le thread qui traite du modèle. Voici par exemple celui à propos de Kimi K2.6: Advancing open-source coding et ses 371 commentaires.
À partir de l'url de ce thread, je lance le prompt suivant dans Claude Desktop connecté au serveur MCP fetch lancé localement :
Utilise `fetch_html` pour récupérer https://news.ycombinator.com/item?id=47835735
**Étape 1 — Récupération complète**
- Récupère la première page avec `fetch_html` et lis le nombre total de commentaires indiqué en début de page — ce nombre est ta cible obligatoire
- Le contenu étant probablement tronqué (limite 200 000 caractères), enchaîne les appels successifs en incrémentant `start_index` de 200 000 à chaque fois :
- `fetch_html(url, start_index=0, max_length=200000)`
- `fetch_html(url, start_index=200000, max_length=200000)`
- `fetch_html(url, start_index=400000, max_length=200000)`
- … jusqu'à ce que la réponse soit vide
- **Tu dois avoir récupéré 100% des commentaires avant de passer à l'étape suivante.** Vérifie que le nombre de commentaires extraits correspond au compteur initial — si ce n'est pas le cas, continue à paginer.
**Étape 2 — Analyse exhaustive**
Analyse **chacun des commentaires sans exception** exclusivement sous l'angle des **modèles LLM** mentionnés. Aucun commentaire ne doit être ignoré ou échantillonné.
Pour chaque modèle cité, synthétise :
- **Points forts** relevés par les commentateurs
- **Points faibles** ou limitations mentionnées
- **Cas d'usage Coding** : performance en génération de code, débogage, complétion, etc.
- **Cas d'usage Intelligence générale** : raisonnement, compréhension, tâches polyvalentes, etc.
- **Benchmarks mentionnés** : scores, classements ou comparaisons chiffrées associés à ce modèle
**Étape 3 — Synthèse**
Présente le résultat sous forme de **deux tableaux comparatifs markdown** :
1. **Tableau Coding** — colonnes : Modèle | Points forts | Points faibles | Benchmarks coding
2. **Tableau Intelligence générale** — colonnes : Modèle | Points forts | Points faibles | Benchmarks généralistes
Puis ajoute :
1. Une section **"Comparaison directe entre modèles"** synthétisant les confrontations explicites faites par les commentateurs (quel modèle bat quel autre, sur quoi, dans quel contexte), en distinguant coding vs intelligence générale
2. Une section **"Benchmarks en discussion"** listant les benchmarks cités, leur crédibilité perçue par la communauté, et les modèles qu'ils avantagent ou désavantagent — en précisant s'il s'agit de benchmarks coding (HumanEval, SWE-bench…) ou généralistes (MMLU, GPQA…)
Seuls les commentaires sans aucune mention de modèle spécifique sont à ignorer.
Ce qui m'a donné le résultat suivant : Analyse par Sonnet 4.6 des commentaires Hacker News à propos de Kimi K2.6.
Étape 4 : quelques semaines plus tard
Quelques semaines plus tard, je consulte toutes les sorties de modèle du mois dans l'article Nouvelles sur l'IA du site LinuxFR pour avoir une revue complète de l'écosystème.