
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
Résultat de la recherche (1946 notes) :
Dimanche 29 juin 2025
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
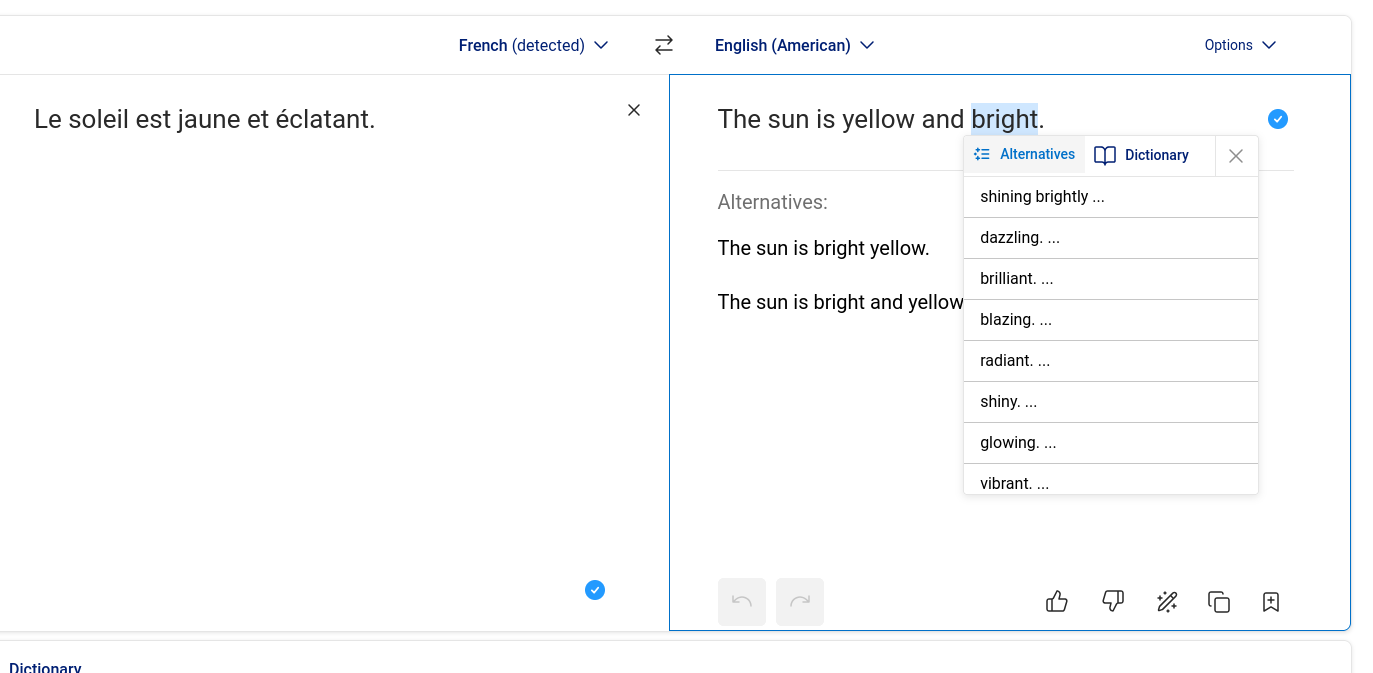
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité OpenAI - Stractured Outputs (https://platform.openai.com/docs/guides/structured-outputs)
Journal du dimanche 29 juin 2025 à 17:08
Ma première rencontre avec Hegel et sa dialectique date probablement de 2005, quand j'ai lu "Karl Mark ou l'esprit du monde " de Jacques Attali.
Hier, je suis tombé sur une vidéo qui mentionnait encore ce concept, et je dois avouer que j'étais incapable de décrire ce qu'il représente. J'ai donc décidé de prendre du temps pour mieux le comprendre.
L'épisode Hegel - La dialectique de juin 2020 de la chaîne Le Précepteur me semble être une excellente ressource. L'audio fait 50 minutes, mais j'ai trouvé l'ensemble très accessible.
Jeudi 26 juin 2025
Journal du jeudi 26 juin 2025 à 12:07
J'ai appris un #NouveauMot : flagorneur qui signifie « Bassement, outrageusement flatteur. »
Le mois dernier, nous avions brièvement mentionné que OpenAI 4o était flagorneur, au point d’opiner sur des prompts relevant manifestement de l’épisode psychotique. Un utilisateur anonyme explore la même tendance à un moindre niveau Opus 4, et travaille à mesurer ça plus précisément. Il mentionne que ses résultats préliminaires montrent que les modèles plus avancés ont plus tendance à exhiber ce comportement.
Mercredi 25 juin 2025
Est-ce qu'une fonction Open WebUI peut importer une autre fonction Open WebUI ?
J'ai essayé de comprendre si une fonction Open WebUI pouvait importer le code d'une autre fonction Open WebUI.
La réponse est non. Je vais tenter dans cette note d'expliquer pourquoi.
(j'ai aussi publié une version de cette note en anglais dans la section "discussions" de Open WebUI)
Open WebUI propose de méthode pour créer ou mettre à jour une fonction Open WebUI sur une instance en production : via l'interface web d'administration, ou via l'API REST.
Une instance production fait référence à Open WebUI hébergé sur une Virtual machine ou un Cluster Kubernetes, par opposition à une instance locale lancée en mode développement.
Dans un premier temps, j'ai essayé d'importer dans Open WebUI les deux fichiers suivants :
# utils.py
def add(a, b):
return a + b
# hello_world.py
from pydantic import BaseModel, Field
from .utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le fichier hello_world.py contient un import de utils.add implémenté dans le premier fichier.
L'importation du premier fichier est refusée par Open WebUI parce que class Pipe: est absent de utils.py.
J'ai ensuite trompé Open WebUI en ajoutant une classe Pipe fictive das le fichier utils.py et l'importation a réussi.
Ensuite l'import de hello_world.py a échoué parce que Open WebUI n'arrive pas a effectué l'import from .utils import add. J'ai ensuite effectué plusieurs tentatives d'import absolut, par exemple from open_webui.utils import add… mais sans succès.
J'ai pris un peu de temps pour étudier l'implémentation d'Open WebUI et j'ai identifié cette section de code :
module_name = f"tool_{tool_id}"
module = types.ModuleType(module_name)
sys.modules[module_name] = module
Ce code permet à Open WebUI de charger dynamiquement le code source des modules qui sont stockés dans la base de données.
Un esprit tordu pourrait en pratique importer une fonction chargé dynamiquement dans un autre module dynamique, par exemple :
from tool_utils import add
Mais cette méthode ne correspond pas à l'usage normal d'Open WebUI.
Pour implémenter des fonctions "modulaires", Open WebUI conseille d'utiliser la fonctionnalité "Pipelines" :
Welcome to Pipelines, an Open WebUI initiative. Pipelines bring modular, customizable workflows to any UI client supporting OpenAI API specs – and much more! Easily extend functionalities, integrate unique logic, and create dynamic workflows with just a few lines of code.
Pour les personnes qui souhaitent vraiment effectuer des imports dans des fonctions Open WebUI sans utiliser la fonction Pipelines, il existe tout de même une solution que j'ai implémentée dans la branche test-if-openwebui-function-support-import.
Voici le contenu de /functions/hello_world.py :
from pydantic import BaseModel, Field
from open_webui.shared.utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le contenu de /shared/utils.py
def add(a, b):
return a + b
Pour rendre accessible /shared/utils.py dans l'instance d'Open WebUI lancé loculement, j'ai configuré de volume mounts suivante dans mon /docker-compose.yml :
openwebui:
image: ghcr.io/open-webui/open-webui:0.6.15
restart: unless-stopped
volumes:
- ./shared/:/app/backend/open_webui/shared/
ports:
- "3000:8080"
Ensuite, si je souhaite pouvoir déployer en production cette fonction Open WebUI et le module utils.py, il sera nécessaire de build une image Docker customisé d'Open WebUI pour y inclure le fichier /shared/utils.py.
Cette méthode peut fonctionner, mais cela reste un "hack" non conseillé. Il est préférable d'utiliser la méthode "Pipelines".
Journal du mercredi 25 juin 2025 à 12:25
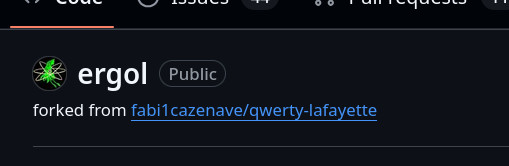
Alexandre m'a partagé le projet de keyboard layout QWERTY-Lafayette (https://qwerty-lafayette.org/).
Je ne connaissais pas ce projet, je découvre que la première version est sortie en 2010, soit 1 an après que j'ai commencé à utiliser le keyboard layout Bépo.
Je crois savoir que le projet de keyboard layout francophone "à la mode" ces dernières années est Ergo L.
J'aimerais bien migrer de Bépo à Ergo L, mais j'ai l'impression qu'à 46 ans, l'effort serait trop important pour moi. Peut-être que je m'amuserai à faire cette transition quand je serai à la retraite, c'est-à-dire vers 2044 😱.
En analysant le dépôt GitHub ErgoL, j'ai découvert qu'Ergo L semble être un fork de QWERTY-Lafayette.
Mardi 24 juin 2025
J'ai découvert la méthode officielle de SvelteKit pour accéder aux variables d'environnement
Voici une nouvelle fonctionnalité qui illustre pourquoi j'apprécie l'expérience développeur (DX) de SvelteKit : la simplicité d'accès aux variables d'environnement !
Je commence avec un peu de contexte.
Comme je l'ai déjà dit dans une précédente note, je suis depuis 2015 les principes de The Twelve-Factors App.
Concrètement, quand je déploie un frontend web qui a besoin de paramètres de configuration, par exemple une URL pour accéder à une API, je déploie quelque chose qui ressemble à ceci :
# docker-compose.yml
services:
webapp:
image: ...
environment:
GRAPHQL_API: https://example.com/
De 2012 à 2022, quand ma doctrine était de produire des frontend web en SPA, j'avais recours à du boilerplate code à base de commande sed dans un entrypoint.sh, qui avait pour fonction d'attribuer des valeurs aux variables de configuration — comme dans cet exemple GRAPHQL_API — au moment du lancement du container Docker, exemple : entreypoint.sh.
Ce système était peu élégant, difficile à expliquer et à maintenir.
Ce soir, j'ai découvert les fonctionnalités suivantes de SvelteKit :
J'ai publié ce playground sveltekit-environment-variable-playground qui m'a permis de tester ces fonctionnalités dans un projet SSR avec hydration.
J'ai testé comment accéder à trois variables dans trois contextes différents (.envrc) :
# Set at application build time
export PUBLIC_VERSION="0.1.0"
# Set at application startup time and accessible only on server side
export POSTGRESQL_URL="postgresql://myuser:mypassword123@localhost:5432/mydatabase"
# Set at application startup time and accessible on frontend side
export PUBLIC_GOATCOUNTER_ENDPOINT=https://example.com/count
Cela fonctionne parfaitement bien, c'est simple, pratique, un pur bonheur.
Pour plus de détails, je vous invite à regarder le playground et à tester par vous-même.
Merci aux développeurs de SvelteKit ❤️.
J'ai regardé ce que propose NextJS et je constate qu'il propose moins de fonctionnalités.
D'après ce que j'ai compris, NextJS propose l'équivalent de $env/dynamic/private et $env/static/public mais j'ai l'impression qu'il ne propose rien d'équivalent à $env/dynamic/public.
Lundi 23 juin 2025
Journal du lundi 23 juin 2025 à 13:34
#JaiDécouvert de nombreuses informations intéressantes au sujet de Cloud Nubo dans les slides Nubo - A French government sovereign cloud du FOSDEM 2025.
#JaiDécouvert la fondation OpenInfra qui gouverne, entre autres, le projet OpenStack.
#JaiDécouvert l'existance des projets : Airship, Starlingx, Zuul. Je ne les ai pas étudiés.
Journal du lundi 23 juin 2025 à 11:49
Dans la slide 18 de la conférence "Nubo: the French government sovereign cloud" du FOSDEM 2025, j'ai découvert l'article "Un logiciel libre est un produit et un projet" (https://bzg.fr/fr/logiciel-produit-projet/).
Je viens de réaliser une lecture active de cet article. Je l'ai trouvé très intéressant. Je vais garder à l'esprit cette distinction "produit / projet".
Voici quelques extraits de cet article.
La popularité de GitHub crée des attentes sur ce qu'est un logiciel « open source » (comme disent les jeunes) ou « libre » (comme disent les vrais). Il s'agit d'un dépôt de code avec une licence, une page de présentation (souvent nommée README), un endroit où remonter des problèmes (les issues), un autre où proposer corrections et évolutions (les pull requests) et, parfois, d'autres aspects : un espace de discussion, des actions lancées à chaque changement, un lien vers le site web officiel, etc.
Je trouve que ce paragraphe décrit très bien les fonctions remplies par un dépôt GitHub :
Pourquoi distinguer produit et projet ?
Cette distinction permet d'abord de décrire une tension inhérente à tout logiciel libre : d'un côté les coûts de distribution du produit sont quasi-nuls, mais de l'autre, l'énergie à dépenser pour maintenir le projet est élevée. Lorsque le nombre d'utilisateurs augmente, la valeur du produit augmente aussi, de même que la charge qui pèse sur le projet. C'est un peu comme l'amour et l'attention : le premier se multiplie facilement, mais le deuxième ne peut que se diviser.
Je partage cet avis 👍️.
C'est d'ailleurs cette tension qu'on trouve illustrée dans l'opposition entre les deux sens de fork. Dans le sens technique, forker un code source ne coûte rien. Dans le sens humain, forker un projet demande beaucoup d'effort : il faut recréer la structure porteuse, à la fois techniquement (hébergement du code, site web, etc.), juridiquement (éventuelle structure pour les droits, etc.) et humainement (attirer les utilisateurs et les contributeurs vers le projet forké.)
J'approuve 👍️.
Côté morale, il y a les principes et les valeurs. Les principes sont des règles que nous nous donnons pour les suivre ; les valeurs expriment ce qui nous tient à coeur. Les deux guident notre action.
Intéressant 🤔
Un logiciel libre est un produit qui suit un principe, celui d'octroyer aux utilisateurs les quatre libertés. Il est porté par un projet ayant des valeurs, dont voici des exemples : l'importance de ne pas utiliser des plateformes dont le code source n'est pas libre pour publier un code source libre, celle d'utiliser des outils libres pour communiquer, de produire un logiciel accessible et bien documenté, d'être à l'état de l'art technique, d'être inclusif dans les contributions recherchées, d'avoir des règles pour prendre des décisions collectivement, de contribuer à la paix dans le monde, etc.
Je trouve cela très bien exprimé 👍️.
Dimanche 22 juin 2025
Journal du dimanche 22 juin 2025 à 23:34
Un collègue m'a fait découvrir Vercel Chat SDK (https://github.com/vercel/ai-chatbot) :
Chat SDK is a free, open-source template built with NextJS and the AI SDK that helps you quickly build powerful chatbot applications.
#JaimeraisUnJour prendre le temps de le décliner vers SvelteKit.
Journal du dimanche 22 juin 2025 à 15:02
Je viens de découvrir les quatre premiers articles de la série "Nouvelle sur l'IA" sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
L'auteur de ces articles indique en introduction :
Avertissement : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz.
Je viens d'ajouter ces deux feed à ma note "Mes sources de veille en IA".
Prise de note de lecture de : Nouvelles sur l’IA de février 2025
Je découvre la signification de l'acronyme STEM : Science, technology, engineering, and mathematics.
Une procédure standard lors de la divulgation d’un nouveau modèle (chez OpenAI en tout cas) est de présenter une "System Card", aka "à quel point notre modèle est dangereux ou inoffensif".
#JaiDécouvert le concept de System Card, concept qui semble avoir été introduit par Meta en février 2022 : « System Cards, a new resource for understanding how AI systems work » (je n'ai pas lu l'article).
#JaiDécouvert ChatGPT Deep Research.
Je retiens :
Derya Unutmaz, MD: J'ai demandé à Deep Researchh de m'aider sur deux cas de cancer plus tôt aujourd'hui. L'un était dans mon domaine d'expertise et l'autre légèrement en dehors. Les deux rapports étaient tout simplement impeccables, comme quelque chose que seul un médecin spécialiste pourrait écrire ! Il y a une raison pour laquelle j'ai dit que c'est un changement radical ! 🤯
Et
Je suis quelque peu déçu par Deep Research d'@OpenAI. @sama avait promis que c'était une avancée spectaculaire, alors j'y ai entré la plainte pour notre procès guidé par o1 contre @DCGco et d'autres, et lui ai demandé de prendre le rôle de Barry Silbert et de demander le rejet de l'affaire.
Malheureusement, bien que le modèle semble incroyablement intelligent, il a produit des arguments manifestement faibles car il a fini par utiliser des données sources de mauvaise qualité provenant de sites web médiocres. Il s'est appuyé sur des sources comme Reddit et ces articles résumés que les avocats écrivent pour générer du trafic vers leurs sites web et obtenir de nouveaux dossiers.
Les arguments pour le rejet étaient précis dans le contexte des sites web sur lesquels il s'est appuyé, mais après examen, j'ai constaté que ces sites simplifient souvent excessivement la loi et manquent des points essentiels des textes juridiques réels.
#JaiDécouvert qu'il est possible de configurer la durée de raisonnement de Clause Sonnet 3.7 :
Aujourd'hui, nous annonçons Claude Sonnet 3.7, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi instantanées ou une réflexion approfondie, étape par étape, qui est rendue visible à l'utilisateur. Les utilisateurs de l'API ont également un contrôle précis sur la durée de réflexion accordée au modèle.
#JaiDécouvert que l'offre LLM par API de Google se nomme Vertex AI.
#JaiDécouvert que les System Prompt d'Anthropic sont publics : https://docs.anthropic.com/en/release-notes/system-prompts#feb-24th-2025
J'ai trouvé la section "Gradual Disempowerement" très intéressante. #JaimeraisUnJour prendre le temps de faire une lecture active de l'article : Gradual Disempowerment.
Je viens de consacrer 1h30 de lecture active de l'article de février 2025. Je le recommande fortement pour ceux qui s'intéressent au sujet. Merci énormément à son auteur Moonz.
Je vais publier cette note et ensuite commencer la lecture de l'article de mars 2025.
Journal du dimanche 22 juin 2025 à 12:43
Je viens de découvrir sur LMArena un nouveau LLM développé par Google : flamesong.
Pour le moment, ce thread est la seule information que j'ai trouvé à ce sujet : https://old.reddit.com/r/Bard/comments/1lg48l9/new_model_flaamesong/.
Toujours via LMArena, j'ai découvert le modèle MinMax-M1 développé par une équipe basé à Singapore.
Dans le cadre de ma mission à la DINUM, #JaiDécouvert les clouds internes dédiés aux services sensibles de l'État : π (Pi), Cloud Nubo.
Ce cloud interne se décline en deux offres :
- Nubo, opérée par la Direction générale des Finances publiques (DGFiP), adaptée à l’hébergement de données sensibles,
- π (Pi), opérée par le Ministère de l'Intérieur, adaptée à l’hébergement de données sensibles jusqu’au niveau Diffusion restreinte.
"Nubo" signifie "Nuage" en esperanto.
Cloud Nubo ne doit pas être confondu avec la coopérative Nubo qui propose, elle aussi, des offres de services "cloud".
En consultant le profil LinkedIn de Renaud Chaillat, je découvre que le projet Cloud Nubo a été lancé en 2015 et s'appuie sur une expérience de 14 ans dans ce domaine, débutée en 2001.
 (source)
(source)
Ressources que j'ai trouvées intéressantes sur ce sujet :
Samedi 21 juin 2025
#JaiDécouvert le référentiel SecNumCloud de l'ANSSI, qui définit les règles de sécurité que doivent respecter les Cloud providers pour obtenir le Visa de sécurité ANSSI.
Élaboré par l’Agence nationale de la sécurité des systèmes d’information (ANSSI), le référentiel SecNumCloud propose un ensemble de règles de sécurité à suivre garantissant un haut niveau d’exigence tant du point de vue technique, qu’opérationnel ou juridique.
... en conformité avec le droit européen.
Les solutions ayant passé avec succès la qualification obtiennent le Visa de sécurité ANSSI.
... L’obtention du Visa permet … de répondre aux exigences de la doctrine « cloud au centre » de l’État imposant aux administrations le recours à des solutions SecNumCloud pour l’hébergement de données qualifiées de sensibles.
Voici la documentation de ce référentiel : https://cyber.gouv.fr/sites/default/files/document/secnumcloud-referentiel-exigences-v3.2.pdf
J'ai consulté la liste des 8 prestataires SecNumCloud qualifiés. J'ai identifié Outscale, OVH (les offres OVH WMWare et OVH Bare Metal Pod), mais les 6 autres me sont totalement inconnues.
J'ai appris que le 8 janvier 2025, Scaleway a annoncé son entrée dans le processus de qualification SecNumCloud.
Voici la liste officielle des prestataires en cours de qualification.
Journal du samedi 21 juin 2025 à 13:21
Dans la page Models Overview de Mistral AI, j'ai été surpris de ne pas trouver de Mistral Large dans la liste des "Premier models" 🤔.
Tous les modèles "Large" sont dans la liste des modèles dépréciés :
| Model | Deprecation on date | Retirement date | Alternative model |
|---|---|---|---|
| Mistral Large 24.02 | 2024/11/30 | 2025/06/16 | mistral-medium-latest |
| Mistral Large 24.07 | 2024/11/30 | 2025/03/30 | mistral-medium-latest |
| Mistral Large 24.11 | 2025/06/10 | 2025/11/30 | mistral-medium-latest |
Je me demande pourquoi il est remplacé par le modèle Mistral Medium 🤔.
Je découvre dans la note de release de Mistral Medium 3 :
Medium is the new large
Mistral Medium 3 delivers state-of-the-art performance at 8X lower cost with radically simplified enterprise deployments.
...
All the way from Mistral 7B, our models have consistently demonstrated performance of significantly higher-weight and more expensive models. And today, we are excited to announce Mistral Medium 3, pushing efficiency and usability of language models even further.
Je pense que Mistral Large sortie en juillet 2024 suis l'ancien paradigme « entraîner de plus gros modèle sur plus de données », alors que Mistral Medium sorti en mai 2025 suis le nouveau paradigme chain-of-thought (CoT) et que c'est pour cela que pour le moment Mistral AI ne propose plus de modèles très larges.
À titre de comparaison, j'ai lu que Mistral Large 2 avait une taille de 123 milliards de paramètres, alors que Mistral Medium 3 a une taille estimée de 50 milliards de paramètres.
Journal du samedi 21 juin 2025 à 12:45
Dans ce commentaire, #JaiDécouvert la page Models Table de LifeArchitect.ai d'Alan D. Thompson.
La page contient énormément d'information à propos des LLM !
Bien que je ne sois pas sûr de moi, pour le moment, je classe cette page dans la catégorie des leaderboard.
Journal du samedi 21 juin 2025 à 11:10
J'ai downgradé libinput de la version 1.18.1 version la version 1.17.1 (contexte : thread 1, thread 2).
Voici la méthode pour lock une version de package avec dnf version 5 :
$ sudo dnf versionlock add libinput
Ajout d'un versionlock "libinput = 1.27.1-1.fc42".
$ dnf versionlock list
# Ajouté par la commande 'versionlock add' 2025-06-21 11:22:11
Package name: libinput
evr = 1.27.1-1.fc42
Documentation officielle : Versionlock Command.
Aggregator - Backup Numeric Conversation System
Ce matin, j'ai eu l' #Idée et l’envie de créer une appli d'archivage et de centralisation de toutes mes conversations numériques.
L'objectif ? Rassembler en un seul endroit, dans une interface web minimaliste, toutes mes discussions provenant de :
- ChatGPT
- Claude.ia
- Open WebUI
- Mes threads Mattermost
- Mes Mail
Le support des threads serait utile pour Mattermost et les mails. J'aimerais pouvoir sauvegarder tous ces messages au format brut original et en Markdown. Une fonction pour partager un message ou un thread serait aussi sympa.
Pour la persistance des données, je pense utiliser ElasticSearch avec son moteur vectoriel. Un LLM pourrait assigner automatiquement des tags à chaque conversation. J'aimerais que l'interface web soit minimaliste, orientée vitesse et exploration.
Pour la postérité, toutes ces données devraient être exportées en continu dans un Object Storage, sous un format YAML facilement compréhensible.
Je me demande si ce type d’application existe en Open source ou closed-source 🤔.
Vendredi 20 juin 2025
Journal du vendredi 20 juin 2025 à 17:28
#JaiDécouvert un autre leaderboard : Political Email Extraction Leaderboard (from).
Journal du vendredi 20 juin 2025 à 16:46
#JaiDécouvert le projet communautaire LLM-Stats.com (https://llm-stats.com/)
A comprehensive set of LLM benchmark scores and provider prices.
J'observe que LLM-Stats.com se base principalement sur le benchmark : A Graduate-Level Google-Proof Q&A Benchmark (GPQA).
En creusant le sujet, j'ai découvert cette page Wikipédia qui liste les principaux outils de LLM Benchmark : Language model benchmark.
Je pense avoir compris que le benchmark MMLU était populaire, utilisé par pratiquement tous les développeurs de LLM jusqu'en 2024, mais peu à peu remplacé par GPQA, qui est plus récent et plus compliqué.
Par exemple, GPQA est "Google-proof", ce qui signifie que les questions de GPQA sont difficiles à trouver en ligne, ce qui réduit le risque de contamination des données d'entraînement.
Journal du vendredi 20 juin 2025 à 16:37
#JaiDécouvert "Leaderboard des modèles de langage pour le français" : https://fr-gouv-coordination-ia-llm-leaderboard-fr.hf.space
C’est dans cette dynamique que la Coordination Nationale pour l’IA, le Ministère de l’Éducation nationale, Inria, le LNE et GENCI ont collaboré avec Hugging Face pour créer un leaderboard de référence dédié aux modèles de langage en français. Cet outil offre une évaluation de leurs performances, de leurs capacités et aussi de leurs limites.
Journal du vendredi 20 juin 2025 à 15:49
Il y a quelques mois, j'ai publié la note : J'ai découvert « Timeline of AI model releases in 2024 ».
Aujourd'hui, #JaiDécouvert le site The Road To AGI 2015 - 2025 (https://ai-timeline.org/).
Ce projet est Open source, voici son repository : jam3scampbell/ai-timeline.

Il me permet d'avoir une d'ensemble des publications des 6 premiers mois de l'année 2025 :
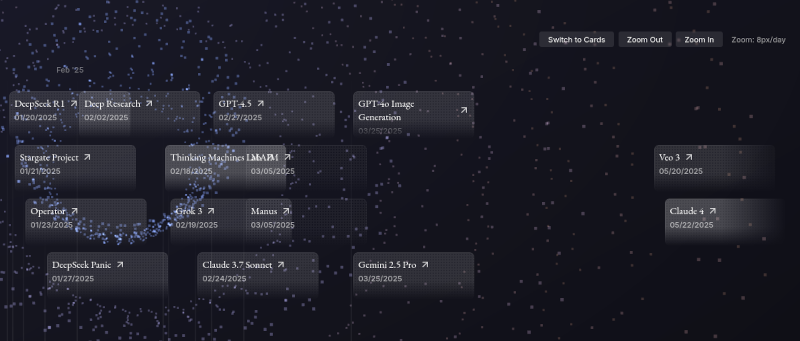
Bien que la réalisation de ce site soit techniquement réussie, après utilisation, je trouve qu'une simple liste Wikipedia répond mieux à mes besoins : https://en.wikipedia.org/wiki/List_of_large_language_models
Jeudi 19 juin 2025
Journal du jeudi 19 juin 2025 à 12:25
J'ai découvert la semaine dernière, le concept de "Brouillard de la guerre" de Carl von Clausewitz. Depuis, je n'arrive plus à quitter ce concept de mon esprit.
Je vois dans ce concept énormément de points communs avec ce qu'il se passe dans les organisations de travail.
Je pense qu'à l'avenir je vais utiliser les termes "brouillard organisationnel" ou "brouillard corporate" pour décrire ces concepts.
Voici quelques éléments qui caractérisent de "Brouillard organisationnel" :
- L'opacité informationnelle - Les informations cruciales circulent de manière fragmentée, déformée ou retardée entre les différents niveaux hiérarchiques et départements.
- L'ambiguïté stratégique - Les objectifs réels de l'organisation, les priorités changeantes et les non-dits politiques créent une vision floue de la direction à prendre.
- La complexité relationnelle - Les jeux de pouvoir, les alliances informelles et les agendas cachés rendent difficile la compréhension des véritables enjeux et motivations.
- L'incertitude décisionnelle - Les processus de prise de décision opaques, les responsabilités diluées et les changements fréquents de cap génèrent confusion et stress.
Autres réflexions qui me viennent à l'esprit.
Pour les concepts de "brouillard de la guerre" et de "brouillard organisationnel", je vois des liens avec :
- avec les concepts décrients dans le livre Systemantics.
- le féodalisme managérial de David Graeber
Je me suis aidé de Claude Sonnet 4 pour la rédaction de cette note.
Mercredi 18 juin 2025
Journal du mercredi 18 juin 2025 à 17:23
Je viens de créer : Projet 31 - "Réaliser un POC d'une integration ProConnect dans un projet SvelteKit".
Journal du mercredi 18 juin 2025 à 08:34
Actuellement, un freelance qui fait plus de 34 000 € de chiffre d'affaires annuel est assujetti à la TVA (note en lien) et doit donc ajouter 20% de TVA à toutes ses factures.
Généralement, le montant de la TVA facturé par le freelance est transparent pour son client. Ce montant entre dans la catégorie de la TVA "déductible".
Si l'entreprise cliente du freelance est au régime réel normal de TVA, alors elle peut soustraire du montant de TVA encaissé auprès de ses propres clients (TVA collectée), la TVA qu'elle a payée sur ses achats professionnels (TVA déductible) — dont les factures freelances — pendant cette même période. Cela permet de ne verser à l'État que la différence entre ces deux montants.
Exemple : en janvier 2025, le client a collecté 20 000 € de TVA, le même mois, le client a payé une facture de prestation freelance de 1000 €, dont 200 € de TVA, le client devra verser 19 800 € (20 000 - 200 = 19 800) de TVA aux impôts.
Mi-avril 2025, j'ai pris conscience que la TVA n'était pas "transparente" pour tous les types de clients.
Les associations ou la plupart des structures étatiques ne collectent pas de TVA. En conséquence, si je propose des prestations freelances à une association ou à beta.gouv.fr, la TVA représente un surcoût direct de 20% supplémentaire par rapport à une personne employée.
Ensuite, j'ai pensé que la TVA représente aussi un surcoût par rapport à des salariés pour les entreprises de type "startup", qui dépensent beaucoup d'argent alors qu'elles n'ont pas ou peu de revenu et donc peu de TVA collectée.
Mais j'étais dans l'erreur, car j'ai découvert qu'une entreprise peut bénéficier d'un crédit de TVA qu'elle pourra déduire à l'avenir, quand elle pourra collecter de la TVA et même dans certains cas se la faire rembourser.
Toutefois, même avec un crédit de TVA, je pense que les 20% de surcoût de TVA des freelances peuvent avoir un impact sur la trésorerie de l'entreprise.
Je ne suis pas du tout expert dans ce domaine, si vous rencontrez des erreurs dans mon analyse, n'hésitez pas à m'en informer en m'écrivant à «contact@stephane-klein.info>.
Lundi 16 juin 2025
J'ai lu le très bon billet d'Athoune sur Kloset, moteur de stockage de backup de Plakar
Il y a un an, Alexandre m'avait fait découvrir Kopia : Je découvre Kopia, une alternative à Restic.
Ma conclusion était :
Ma doctrine pour le moment : je vais rester sur restic.
En septembre 2024, j'ai découvert rustic, un clone de restic recodé en Rust. Pour le moment, je n'ai aucun avis sur rustic.
Il y a quelques semaines, Athoune m'a fait découvrir Plakar, mais je n'avais pas encore pris le temps d'étudier ce que cet outil de backup apportait de plus que restic que j'ai l'habitude d'utiliser.
Depuis, Athoune a eu la bonne idée d'écrire un article très détaillé sur Plakar, enfin, surtout son moteur de stockage avant-gardiste nommé Kloset : "Kloset sur la table de dissection" (au minimum 30 minutes de lecture).
Ce que je retiens, c'est que Kloset propose un système de déduplication plus performant que par exemple celui de restic qui est basé sur Rabin Fingerprints :
For creating a backup, restic scans the source directory for all files, sub-directories and other entries. The data from each file is split into variable length Blobs cut at offsets defined by a sliding window of 64 bytes. The implementation uses Rabin Fingerprints for implementing this Content Defined Chunking (CDC). An irreducible polynomial is selected at random and saved in the file config when a repository is initialized, so that watermark attacks are much harder.
Files smaller than 512 KiB are not split, Blobs are of 512 KiB to 8 MiB in size. The implementation aims for 1 MiB Blob size on average.
For modified files, only modified Blobs have to be saved in a subsequent backup. This even works if bytes are inserted or removed at arbitrary positions within the file.
Au moment où j'écris ces lignes, je n'ai aucune idée des différences ou des points communs entre l'algorithme Rolling hash dont parle l'article et Rabin Fingerprints qu'utilise restic.
Chose suprernante, je trouve très peu de citations de Plakar ou kloset sur Hacker News ou Lobster :
- Recherche avec "Plakar"
- Hacker News
- dans les stories
- Mars 2021 : March 2021: backups with Plakar – poolp.org : 0 commentaire
- Octobre 2024 : Open source distributed, versioned backups with encryption and deduplication : 0 commentaires
- Mars 2025 : CDC Attack Mitigation in Plakar : 0 commentaires
- dans les commentaires
- dans les stories
- Lobsters => rien
- Hacker News
- Recherche avec "Kloset"
- Hacker News :
- Lobsters => rien
Je tiens à remercier Athoune pour l'écriture, qui m'a permis de découvrir de nombreuses choses 🤗.
Dimanche 15 juin 2025
Journal du dimanche 15 juin 2025 à 11:02
En étudiant l'article Wikipedia "Base de données vectorielle", je découvre la liste de différents algorithmes Approximate Nearest Neighbor.
#JaiDécouvert feature extraction algorithms.
These feature vectors may be computed from the raw data using machine learning methods such as feature extraction algorithms, word embeddings or deep learning networks. The goal is that semantically similar data items receive feature vectors close to each other.
J'apprends :
Je lis :
Databases that use HNSW as search index include:
En interrogeant Claude Sonnet 4, j'apprends :
Benchmark indicatif (1M vecteurs 768D) :
Métrique Qdrant pgvector Elasticsearch Temps indexation 15 min 45 min 25 min Requête/sec 2000+ 500-800 800-1200 RAM utilisée 4 GB 6 GB 8 GB+ Précision @10 0.95 0.92 0.94 Date création 2021 2021 2022 (support HNSW) Langage Rust C Java Open Source Open Source Open Source
Journal du dimanche 15 juin 2025 à 09:43
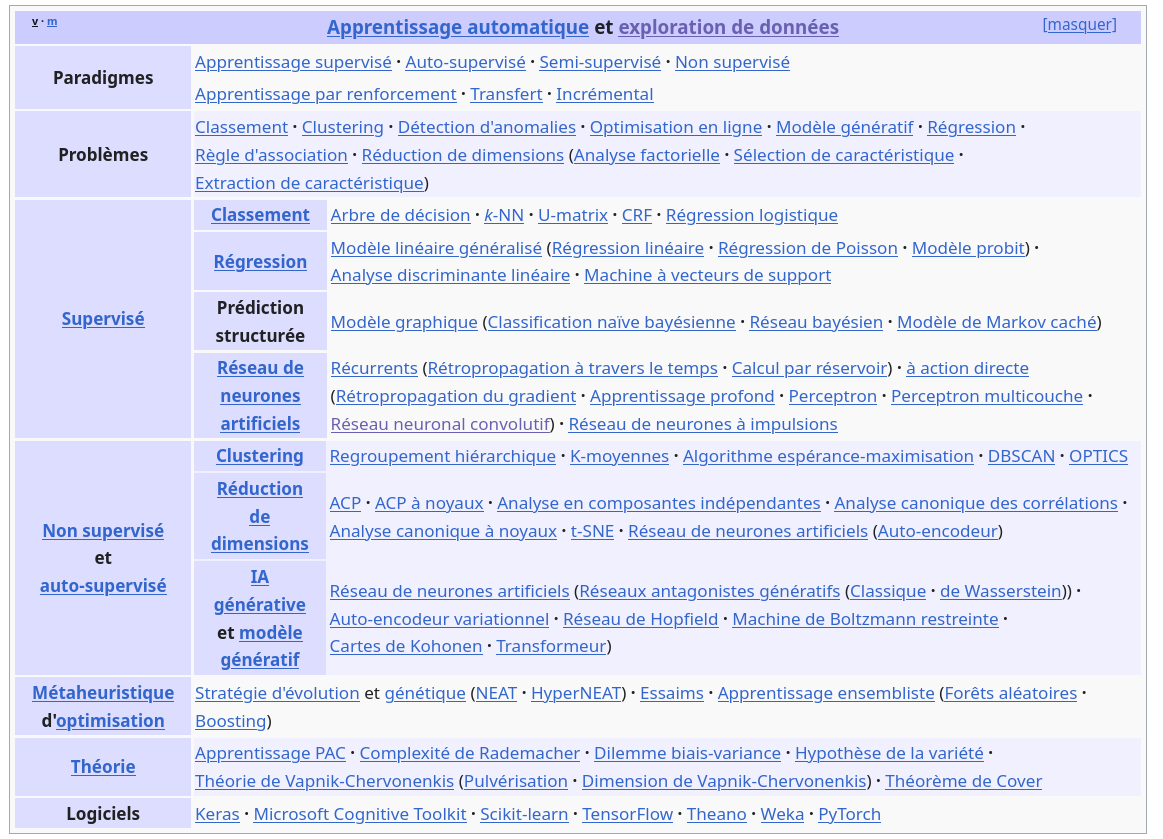
Par sérendipité, je suis tombé sur la palette Wikipedia nommée "Apprentissage automatique et exploration de données".
Je pense que cette liste d'articles est une bonne porte d'entrée d'exploration de ces sujets. Elle me permet d'avoir une vue d'ensemble du domaine.
Quand j'aborde un nouveau domaine, j'aime recevoir ce type de présentation. C'est par exemple pour cela que j'aime beaucoup les "Developer Roadmaps" (https://roadmap.sh/).
Samedi 14 juin 2025
Journal du samedi 14 juin 2025 à 00:06
#JaiDécouvert OmniPoly (https://github.com/kWeglinski/OmniPoly)
Welcome to a solution for translation and language enhancement tool. This project integrates LibreTranslate for accurate translations, LanguageTool for grammar and style checks, and AI Translation for modern touch of sentiment analysis and interesting sentences extraction.
Je souhaite intégrer cet outil au dépôt sklein-open-webui-instance.
Comme ce projet ne sera plus exclusivement dédié à Open WebUI, il me semble qu'un changement de nom s'impose.
Vendredi 13 juin 2025
Journal du vendredi 13 juin 2025 à 22:32
Dans cette fonction filtre Open WebUI, #JaiDécouvert Detoxify (https://github.com/unitaryai/detoxify).
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
#JaimeraisUnJour prendre le temps de le tester.
Journal du vendredi 13 juin 2025 à 14:37
Je viens de découvrir la fonction inspect.cleandoc de la librairie standard de Python.
Exemple :
# foobar.py
from inspect import cleandoc
def foobar(body):
print(body)
foobar(
body=cleandoc("""
My text, with indentation
- item 1
- item 1.1
- item 2
Last line
""")
)
$ python foobar.py
My text, with indentation
- item 1
- item 1.1
- item 2
Last line
Je trouve cela très pratique pour améliorer la lisibilité du code source sans générer des indentations qui ne devraient pas être présentes dans les données.
Jeudi 12 juin 2025
Journal du jeudi 12 juin 2025 à 23:56
La semaine dernière, j'ai fait des étapes de randonnée entre 15 et 21 km par jours.
Mon record de distance en randonnée, date du 11 avril 2024, 33 km avec 1075m de dénivelé positif cumulé, en 9h, soit 3,6 km/h de moyenne.
En ce moment, je m'intéresse au concept de brouillard de la guerre de Carl von Clausewitz et dans l'émission Radio France "Épisode 3/4 : Clausewitz a-t-il inventé la guerre absolue ?" j'ai appris (à partir de 17min) :
- Le régime de mobilité (capacité de déplacement quotidienne d'une armée) pendant la guerre de Sept Ans, 1756-1763 était de 25 km par jour
- Le régime de mobilité des armées napoléoniennes pouvait être de 40 km par jour !
40 km par jour avec l'équipement — chaussure, etc — du 19ᵉ siècle, je trouve cela énorme !
Un ami m'a partagé : La vitesse de César et de ses troupes durant les campagnes militaires en Occident
Journal du jeudi 12 juin 2025 à 21:38
Je me pose souvent des questions sur l'histoire des notations mathématiques. Quelle est l'origine d'une notation, pourquoi avoir fait ce choix, etc.
Comprendre comment une notation a émergé m'aide à la retenir.
Au cours de mes recherches par sérendipité sur ce sujet, #JaiDécouvert Florian Cajori :
Florian Cajori est un historien des mathématiques, véritable fondateur de cette discipline aux États-Unis, et auteur dans ce domaine d'ouvrages qui ont fait date.
Il a, entre autres, écrit le livre : "A History of Mathematical Notations".
Je suis ensuite tombé sur cette excellente page Wikipedia nommée "Table de symboles mathématiques", (et surtout sa version anglaise) que j'aurais adoré avoir quand je faisais mes études.
Autres ressources que j'ai croisées :
Alexandre m'a partagé le projet LocalAI (https://localai.io/).
Ce projet a été mentionné une fois sur Lobster dans un article intitulé Everything I’ve learned so far about running local LLMs, et quatre fois sur Hacker News (recherche pour "localai.io"), mais avec très peu de commentaires.
C’est sans doute pourquoi je n'ai jamais remarqué ce projet auparavant.
Pourtant, il ne s’agit pas d’un projet récent : son développement a débuté en mars 2023.
J'ai l'impression que LocalAI propose à la fois des interfaces web comme Open WebUI, mais qu'il est aussi une sorte de "wrapper" au-dessus de nombreux Inference Engines comme l'illustre cette longue liste.
Pour le moment, j'ai vraiment des difficultés à comprendre son positionnement dans l'écosystème.
LocalAI versus vLLM ou Ollama ? LocalAI versus Open WebUI ?, etc.
Je vais garder ce projet dans mon radar.
Journal du jeudi 12 juin 2025 à 15:51
Je viens de publier : Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter".
Mardi 10 juin 2025
J'ai découvert le support SSH agent de Bitwarden et ses conséquences sur l'utilisation de Age
J'ai utilisé le "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh" dans un projet professionnel et un collègue a rencontré un problème au niveau du script /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
Sa clé privée ssh n'était pas présente dans ~./ssh/ parce qu'il utilise "1Password SSH agent" (disponible depuis mars 2022).
Je ne connaissais pas cette fonctionnalité (merci).
#JaiDécouvert que cette fonctionnalité existe aussi dans Bitwarden depuis février 2025 : "SSH Agent".
#JaiDécouvert qu'une solution alternative pour Bitwarden existait depuis 2020 : bitwarden-ssh-agent. Mais beaucoup moins bien intégré à Bitwarden.
Au cours des 15 dernières années, j'ai régulièrement reçu des demandes de redéploiement de clés SSH de la part des développeurs, parfois plusieurs mois après leur onboarding. La cause principale : la plupart des développeurs ne pensent pas à sauvegarder leurs clés SSH dans leur gestionnaire de password et les perdent inévitablement lors du changement de workstation ou de réinstallation de leur système.
Face à ce constat récurrent, j'envisageais depuis plusieurs années de créer une issue chez Bitwarden pour leur proposer d'implémenter un système de sauvegarde automatique des clés SSH.
L'approche basée sur un ssh-agent ne m'avait jamais traversé l'esprit.
À l'avenir, j'envisage d'intégrer l'usage de Bitwarden SSH Agent (ou équivalent) dans les processus d'onboarding dont j'ai la responsabilité.
J'ai tenté d'ajouter le support de ssh-agent au script /scripts/decrypt_secrets.sh, mais d'après le thread "ssh-agent support", age ne semble pas supporter ssh-agent.
Conséquence : en attendant, j'ai demandé à mon collègue de placer sa clé privée ssh dans ~/.ssh/.
Jeudi 5 juin 2025
Liste d'issues pour gibbon-replay de juin 2025
Mon objectif dans cette note est de rassembler une liste d'issues que j'ai à l'esprit pour le projet gibbon-replay.
Dans cette note, les issues sont décrites en moins de 280 caractères, de manière approximative et sans doute un peu idiosyncrasique. Elles sont présentées dans un ordre quelconque.
- Dans le README, expliquer pourquoi j’ai créé ce projet et son ambition. Indiquer clairement que l’objectif est de rester simple à déployer (architecture monolithique) et que les utilisateurs plus ambitieux peuvent se tourner vers des solutions comme Posthog ou OpenReplay.
- Toujours dans le README, indiquer comme dans l'introduction de SilverBullet : « gibbon-replay is optimized for people with a hacker mindset ».
- [x] En tant qu'utilisateur, je peux visualiser l'espace mémoire total utilisé par l'ensemble des sessions. Issue GitHub : #4.
- [x] En tant qu'utilisateur, je peux visualiser l'espace mémoire consommé par chaque session individuellement.
- [x] En tant qu'utilisateur, je peux visualiser la durée de chaque session. Issue Github : #3.
- [x] En tant qu'utilisateur, je peux consulter, session par session, la présence ou non des actions utilisateur. Issue GitHub : #6.
- [ ] Optimiser la densité d'affichage de la liste des sessions en regroupant plusieurs données dans des cellules multilignes.
- En tant qu'utilisateur, dans la page liste des sessions, je peux appliquer un filtre sur les champs suivants : durée, taille mémoire ou mouvement de souris.
- En tant qu'utilisateur, dans la page détail d'une session, je peux visualiser les titres et les URLs des pages décrivant le parcours effectué par l'utilisateur.
- En tant qu'utilisateur, je peux visualiser un résumé textuel, du parcours utilisateur d'une session, rédigé par un agent conversationnel de petite taille.
- En tant qu'utilisateur avancé, je peux effectuer des recherches avancées sur le contenu des URLs présentes dans le parcours utilisateur. Par exemple, l'utilisateur peut saisir du code JavaScript qui permet de tester une condition sur toutes les URLs parcourues lors d'une session. Si la condition est positive, alors le résultat doit être sauvegardé dans un champ json de la session.
- En tant qu'utilisateur avancé, je peux rechercher des informations spécifiques dans le contenu des URLs présentes dans le parcours d'une session. Par exemple, je peux saisir un code JavaScript personnalisé pour tester une condition (comme la présence d'un
utm_sourceoucampaign) sur toutes les URLs parcourues. Si cette condition est vérifiée, les résultats correspondants sont stockés dans un champ json dans la session, permettant d'effectuer par la suite un filtre sur la liste des sessions. - User Story qui ressemble à la précédente : en tant qu'utilisateur avancé, je peux rechercher les balises HTML qui ont déclenché un événement "click" durant un parcours de session. Pour ce faire, il peut saisir du code JavaScript personnalisé pour tester une condition spécifique (comme la présence d'un attribut, d'une classe, etc.) sur ces balises. Les résultats de cette recherche sont enregistrés dans un champ JSON associé à la session, permettant d'effectuer par la suite un filtre sur la liste des sessions.
- En tant qu'utilisateur, je peux activer / désactiver l'envoi de notifications web sur des filtres de session, filtres avancés inclus.
- Permettre à une instance gibbon-replay d'enregistrer et de gérer plusieurs sites en même temps, en single-tenant.
- Ajouter un support multiutilisateurs — toujours en mode single-tenant. Permettre l'authentification par magic link et par username et password.
- Permettre la gestion des utilisateurs par API REST.
- Permettre de supprimer automatiquement des sessions en fonction de critères de filtres.
- En tant qu'utilisateur, je peux supprimer des sessions en mode batch.
Prochaine étape : créer ces issues plus détaillé dans : https://github.com/stephane-klein/gibbon-replay/issues
Mardi 3 juin 2025
J'ai terminé poc-svelteki-web-notification
Je viens de terminer un POC nommé poc-sveltekit-web-notification , qui m'a permis d'apprendre à implémenter la fonctionnalité Push API dans une PWA.
Quelques ressources qui m'ont été utiles :
- Push API
- Web Workers API
- Using VAPID with WebPush
- Cet exemple de MDN Web Docs :
push-subscription-management.
Je n'ai aucune idée de pourquoi ce repository est archivé et par quoi il a été remplacé. - J'ai lu en partie Voluntary Application Server Identification (VAPID) for Web Push - RFC 8292
- SvelteKit - Service workers
Ma prochaine étape : intégrer cette fonctionnalité dans gibbon-replay.
Lundi 2 juin 2025
Journal du lundi 02 juin 2025 à 08:00
#JaiDécouvert Datatracker de IETF. Voici un exemple d'utilisation : https://datatracker.ietf.org/doc/rfc8292/
Vendredi 30 mai 2025
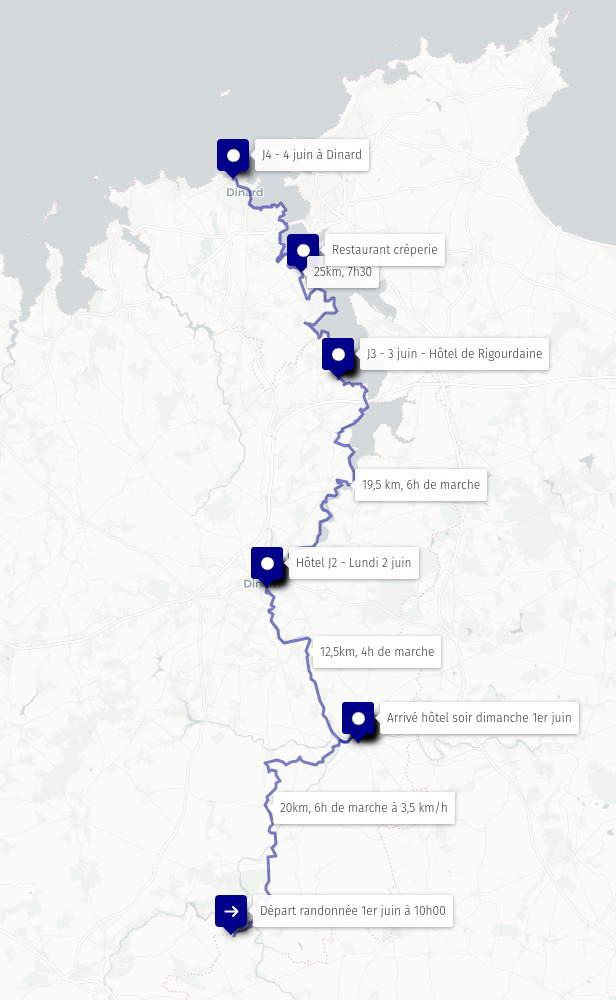
Randonnée des mégalithes de Lampouy à Dinard en 4 jours
J'ai fini le tracé d'une randonnée de 4 jours, que j'ai prévu du dimanche 1ᵉʳ juin au mercredi 4.
- Jour 1 : 20 km
- Nous sommes déposés en voiture à L'Espace naturel départemental des mégalithes de Lampouy
- Destination un hôtel à Évran
- Jour 2 : 12,5 km
- Départ Évran
- Destination un hôtel à Dinan
- Visite de la ville fortifiée
- Jour 3 : 19,5 km
- Départ de Dinan
- Destination un hôtel à la Rigourdaine
- Jour 4 : 25 km
- Départ la Rigourdaine
- Destination une location à Dinard
- Ensuite, 3 jours en thalassothérapie 🙂.
Lien vers le tracé : http://u.osmfr.org/m/1209152/
Jeudi 29 mai 2025
J'ai découvert la fonctionnalité SvelteKit Shared hooks init
J'ai bien fait de partager poc-sveltekit-custom-server dans la section discussion GitHb de Sveltekit car cela m'a permis de découvrir via ce commentaire l'existence de la fonctionnalité native SvelteKit nommée Shared hooks init.
This function runs once, when the server is created or the app starts in the browser, and is a useful place to do asynchronous work such as initializing a database connection.
Cette fonctionnalité a été introduite dans la version 2.10.0 de SvelteKit publiée le 10 décembre 2024.
C'est particulièrement frustrant car j'ai cherché cette fonctionnalité à plusieurs reprises entre mi-2022 et mi-2024, sans la trouver. Je me souviens même avoir lu une issue de Rich Harris expliquant que cette fonctionnalité était complexe à implémenter.
Il y a quelques semaines, lors du développement de poc-sveltekit-custom-server, j'ai refait une recherche de fonctionnalité "init", mais en me limitant à la documentation "Node servers". La présence de "Graceful shutdown" m'a paradoxalement induit en erreur : j'en ai déduit que s'il n'y avait pas d'équivalent pour l'initialisation sur cette page, c'est que la fonctionnalité n'existait toujours pas 😔.
Conséquence de tout cela :
- Je vais utiliser Shared hooks init dans gibbon-replay ;
- J'ai indiqué dans
poc-sveltekit-custom-serverque je recommande d'utiliser "Shared hooks init"
Journal du jeudi 29 mai 2025 à 00:04
Dans ma note Bilan de poc-sveltekit-custom-server je finis par ceci :
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Voici ce que je viens de publier :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Mercredi 28 mai 2025
Bilan de poc-sveltekit-custom-server
Contexte et objectifs
Dans le projet gibbon-replay, j'ai besoin d'exécuter une tâche une fois par jour pour supprimer des anciennes sessions.
gibbon-replay utilise une base de données SQLite qui ne dispose pas nativement de fonctionnalité de type Time To Live, comme on peut trouver dans Clickhouse.
SQLite ne propose pas non plus d'équivalent à pg_cron — ce qui est tout à fait normal étant donnée que SQLite est une librairie et non pas un service à part entière.
Le projet gibbon-replay est un monolith (j'aime les monoliths !) et je souhaite conserver ce choix.
Face à ces contraintes, une solution consiste à intégrer une solution comme Cron for Node.js directement dans l'application gibbon-replay.
Je pense que je dois implémenter cela dans un SvelteKit Custom Server, ce qui me permettrait d'exécuter cette tâche de purge à intervalles réguliers tout en conservant l'architecture monolithique.
Il y a quelques jours, j'ai décidé de tester cette idée dans un POC nommé : poc-sveltekit-custom-server.
J'ai aussi décidé d'expérimenter un objectif supplémentaire dans ce POC : lancer la migration du modèle de données dès le lancement du monolith et non plus lors de la première requête HTTP reçue par le service.
Enfin, je souhaitais ne pas dégrader l'expérience développeur (DX), c'est à dire, je souhaitais pouvoir continuer à simplement utiliser :
$ pnpm run dev
ou
$ pnpm run build
$ pnpm run preview
sans différence avec un projet SvelteKit "vanilla".
Résultats du POC et enseignements
Tout d'abord, le POC fonctionne parfaitement 🙂, sans dégrader l'expérience développeur (DX), qui ressemble à ceci :
$ mise install
$ pnpm install
$ pnpm run load-seed-data
Start data model migration…
Data model migration completed
Start load seed data...
seed data loaded
Lancement du projet en mode développement :
$ pnpm run dev
Start data model migration…
Data model migration completed
Server started on http://localhost:5173 in development mode
Lancement du projet "buildé" :
$ pnpm run build
$ pnpm run preview
Start data model migration…
Data model migration completed
Server started on http://localhost:3000 in production mode
Les migrations et les données "seed.sql" se trouvent dans le dossier /sqls/.
Le SvelteKit Custom Server est implémenté dans le fichier src/server.js et il ressemble à ceci :
import express from 'express';
import cron from 'node-cron';
import db, { migrate } from '@lib/server/db.js';
const isDev = process.env.ENV !== 'production';
migrate(); // Lancement de la migration du modèle de donnée dès de lancement du serveur
// Configuration d'une tâche exécuté toutes les heures
cron.schedule(
'0 * * * *',
async () => {
console.log('Start task...');
console.log(db().query('SELECT * FROM posts'));
console.log('Task executed');
}
);
async function createServer() {
const app = express();
...
Personnellement, je trouve cela simple et minimaliste.
Point de difficulté
SvelteKit utilise des "module alias", comme par exemple $lib.
Problème, par défaut, ces "module alias" ne sont pas configurés lors de l'exécution de node src/server.js.
Pour me permettre d'importer dans src/server.js des modules de src/lib/server/* comme :
import db, { migrate } from '@lib/server/db.js';
j'ai utilisé la librairie esm-module-alias.
Ceci complexifie un peu le projet, j'ai dû configurer ceci dans /package.json :
{
"scripts": {
"dev": "ENV=development node --loader esm-module-alias/loader --no-warnings src/server.js",
"preview": "ENV=production node --loader esm-module-alias/loader --no-warnings build/server.js",
...
"aliases": {
"@lib": "src/lib/"
}
}
- ajout de
--loader esm-module-alias/loader --no-warnings - et la section
aliases
Et dans /vite.config.js :
export default defineConfig({
plugins: [sveltekit()],
resolve: {
alias: {
'@lib': path.resolve('./src/lib')
}
}
});
- ajout de
alias
Le fichier src/server.js contient du code spécifique en fonction de son contexte d'exécution ("dev" ou "buildé") :
if (isDev) {
const { createServer: createViteServer } = await import('vite');
const vite = await createViteServer({
server: { middlewareMode: true },
appType: 'custom'
});
app.use(vite.middlewares);
} else {
const { handler } = await import('./handler.js');
app.use(handler);
}
En mode "dev" il utilise Vite et en "buildé" il utilise le fichier build/handler.js généré par SvelteKit build en mode SSR.
Le fichier src/server.js est copié vers le dossier /build/ lors de l'exécution de pnpm run build.
J'ai testé le bon fonctionnement du POC dans un container Docker.
J'ai intégré au projet un deployment-playground : https://github.com/stephane-klein/poc-sveltekit-custom-server/tree/main/deployment-playground.
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Update du 2025-05-29 à 00:07 - Je viens de publier ceci :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/?
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Vendredi 23 mai 2025
Journal du vendredi 23 mai 2025 à 21:14
#JaiLu cet excellent article "The future of Flatpak".
J'y ai appris énormément de choses au sujet de Flatpak. Le sujet est bien plus complexe que je l'imaginais. Je découvre aussi que les axes d'amélioration du projet sont nombreux.
Journal du vendredi 23 mai 2025 à 18:22
#JaiDécouvert l'origine du nom du projet Flatpak :
Flatpak was originally developed by Alexander Larsson, who had been working on similar projects stretching back to 2007. The first release was as XDG-App in 2015. It was renamed to Flatpak in 2016, a nod to IKEA's "flatpacks" for delivering furniture.
J'adore l'idée derrière ce nom !
Mercredi 21 mai 2025
Journal du mercredi 21 mai 2025 à 14:25
#JaiDécouvert le concept de LLM-as-a-Judge.
#JaiLu l'article Wikipédia à ce sujet "LLM-as-a-Judge".
"Abstract" du papier de recherche Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena datant du 24 décembre 2023 :
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, including position, verbosity, and self-enhancement biases, as well as limited reasoning ability, and propose solutions to mitigate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and [[Chatbot Arena]], a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA and Vicuna. The MT-bench questions, 3K expert votes, and 30K conversations with human preferences are publicly available at https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge.
J'ai parcouru rapidement l'article "Evaluating RAG with LLM as a Judge" du blog de Mistral AI. Je n'ai pas pris le temps d'étudier les concepts que je ne connaissais pas dans cet article, par exemple RAG Triad.
J'ai effectué une recherche sur « LLM as Judge » sur le blog de Simon Willison.
Mardi 20 mai 2025
Journal du mardi 20 mai 2025 à 17:03
#JaiLu la discussion GitHub du projet nginx-proxy : "How can we scapre metrics from nginx-proxy container".
J'y ai découvert le Prometheus exporter : nginx-prometheus-exporter (https://github.com/nginx/nginx-prometheus-exporter). Il semble être l'exporter officiel de nginx pour Prometheus.
Je pense tester son installation et sa configuration d'ici à quelques jours.
Liste des éléments que je souhaite étudier :
- Est-ce qu'il existe un dashboard Grafana qui permet de consulter par domaine et peut-être par URLs :
- le temps moyen de réponse
- la mediane de temps de réponse
- le temps de réponse au 90ème percentile (p90)
- le temps de réponse au 95ème percentile (p95)
Je pense que la metric nginxplus_upstream_server_response_time me permettra peut-être d'obtenir cette information.
J'ai identifié ce dashboard Grafana mais il ne semble pas afficher les informations dont j'ai besoin.
Lundi 19 mai 2025
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Journal du lundi 19 mai 2025 à 15:38
#JaiDécouvert la définition du mot "Bastide" :
Une bastide peut être aussi bien la maison d'habitation des maitres d'une exploitation agricole que l'ensemble d'une exploitation agricole, puis plus tardivement, une maison rurale bourgeoise provençale.
Le terme bastide désigne aussi un type de villes, créées au Moyen Âge, dans l'objectif de constituer de nouveaux foyers de population. Les bastides, nombreuses dans le Sud-Ouest de la France, étaient le plus souvent fondées sur initiative seigneuriale, royale ou ecclésiastique (parfois conjointement). Des privilèges fiscaux furent généralement octroyés aux personnes qui acceptaient de peupler les bastides nouvellement construites.
Vendredi 16 mai 2025
Journal du vendredi 16 mai 2025 à 13:31
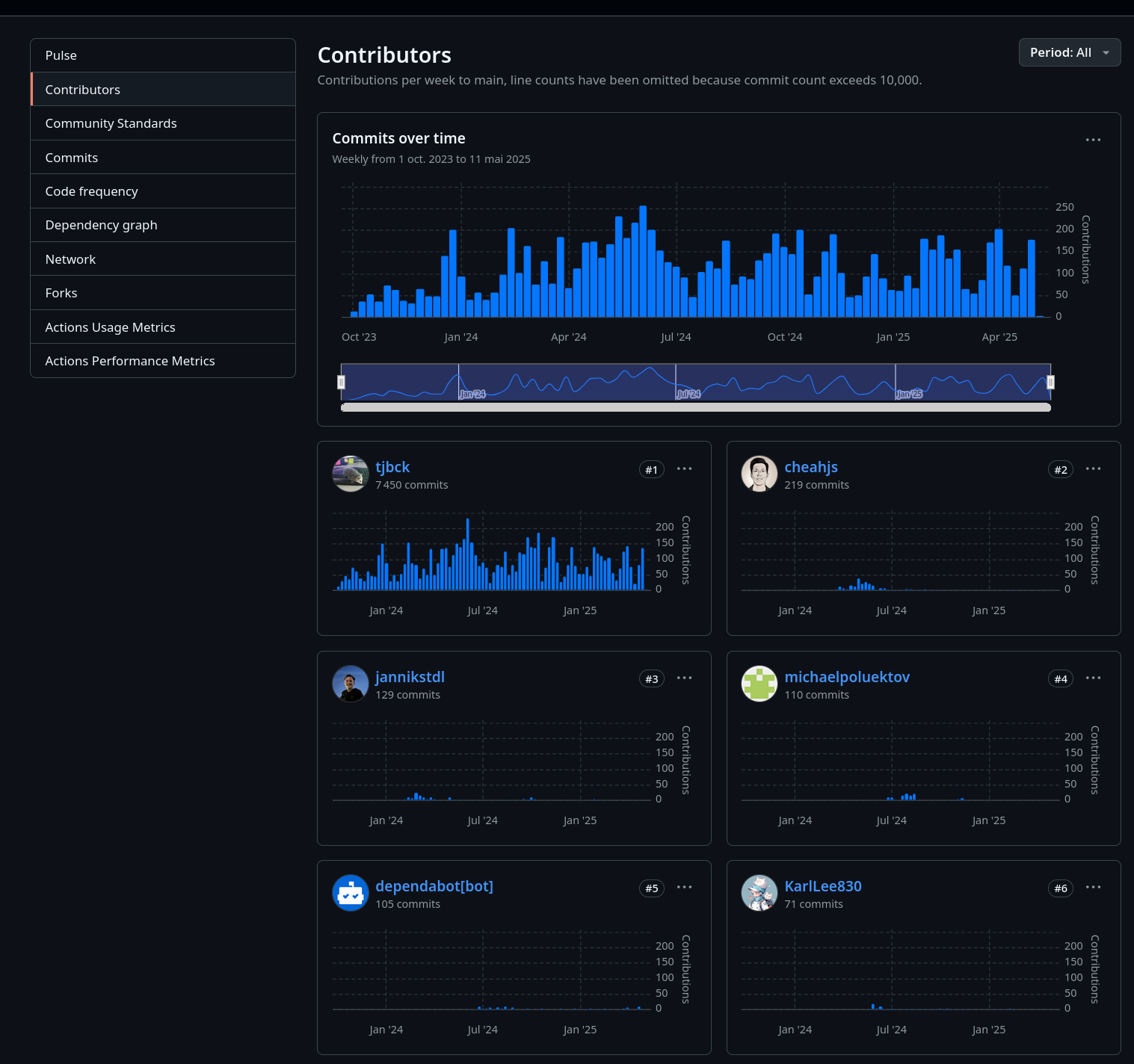
Je me suis posé la question suivante : « Qui contribue au projet Open WebUI ? »
Si je regarde les contributions au projet, je constate que, à la louche, 95% du repository /open-webui/open-webui/ et /pipelines/graphs/ est réalisé par Tim Jaeryang Baek.
Contributions au dépôt /open-webui/open-webui/ :
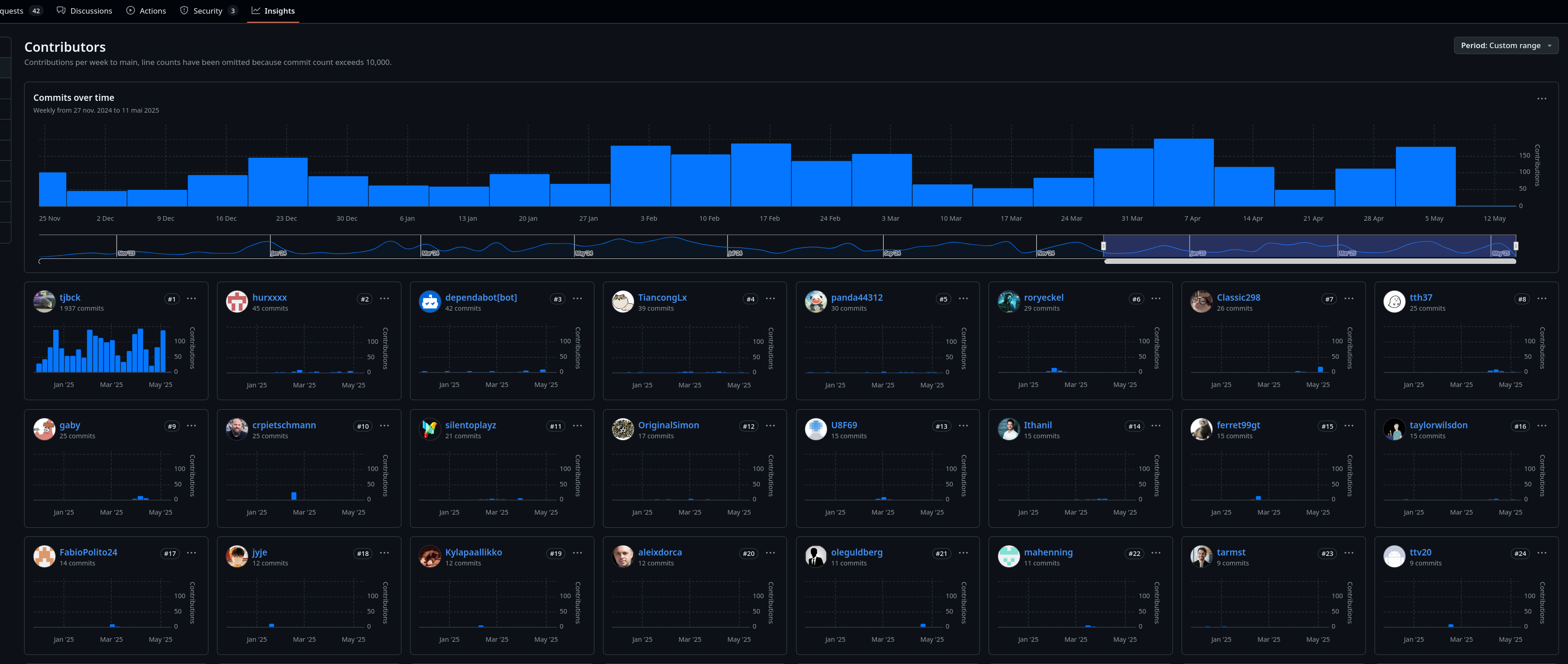
Contributions au dépôt /open-webui/open-webui/ sur les 6 derniers mois :
D'après la section "People" de la page LinkedIn "Open WebUI", James W. semble être dédié et peut-être rémunéré pour travailler sur /open-webui/helm-charts/.
Voici mon estimation de Fermi de calcul du coût de développement d'Open WebUI (seulement ce composant) :
- Estimation du taux journalier de Tim Jaeryang Baek : bien que Tim a commencé depuis peu sa carrière professionnelle, je pense qu'il n'aurait pas de difficulté à trouver des missions entre 500 et 1000 € HT la journée.
- Le dépôt Open WebUI a reçu ses premiers commits le 1ᵉʳ octobre 2023. Cela fait 20 mois de travail.
- Si j'estime, 20 jours de travail par mois sans vacances, j'obtiens 400 jours de travail
- J'obtiens un coût total entre :
- 500 x 400 = 200 000 €
- 1000 x 400 = 400 000 €
Je tiens à préciser que ce montant n'a pas de lien avec une valeur économique d'usage, ni une valeur d'échange.
Comme on a pu le voir au début de cette note, ce projet a été développé par une seule personne, réduisant considérablement les "frais de couplage" (coûts liés à la coordination, communication et synchronisation entre développeurs, management, recrutement…). Si ce même projet avait été réalisé au sein d'une startup, son coût aurait été d'un ordre de grandeur nettement supérieur. Selon mon estimation, il aurait été multiplié par 50, voire davantage.
Pas de notes plus récentes | [ Notes plus anciennes (948) >> ]