
benchmaxxing
Voici plein de commentaires Hacker News qui mentionnent benchmaxxing : https://hn.algolia.com/?dateRange=all&page=0&prefix=false&query=benchmaxxing&sort=byDate&type=comment
Benchmaxxing : Pratique consistant à optimiser un modèle d'IA spécifiquement pour scorer haut sur des benchmarks connus, sans que cela se traduise par une amélioration équivalente en usage réel. L'équivalent du teaching to the test dans l'éducation.
Journaux liées à cette note :
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
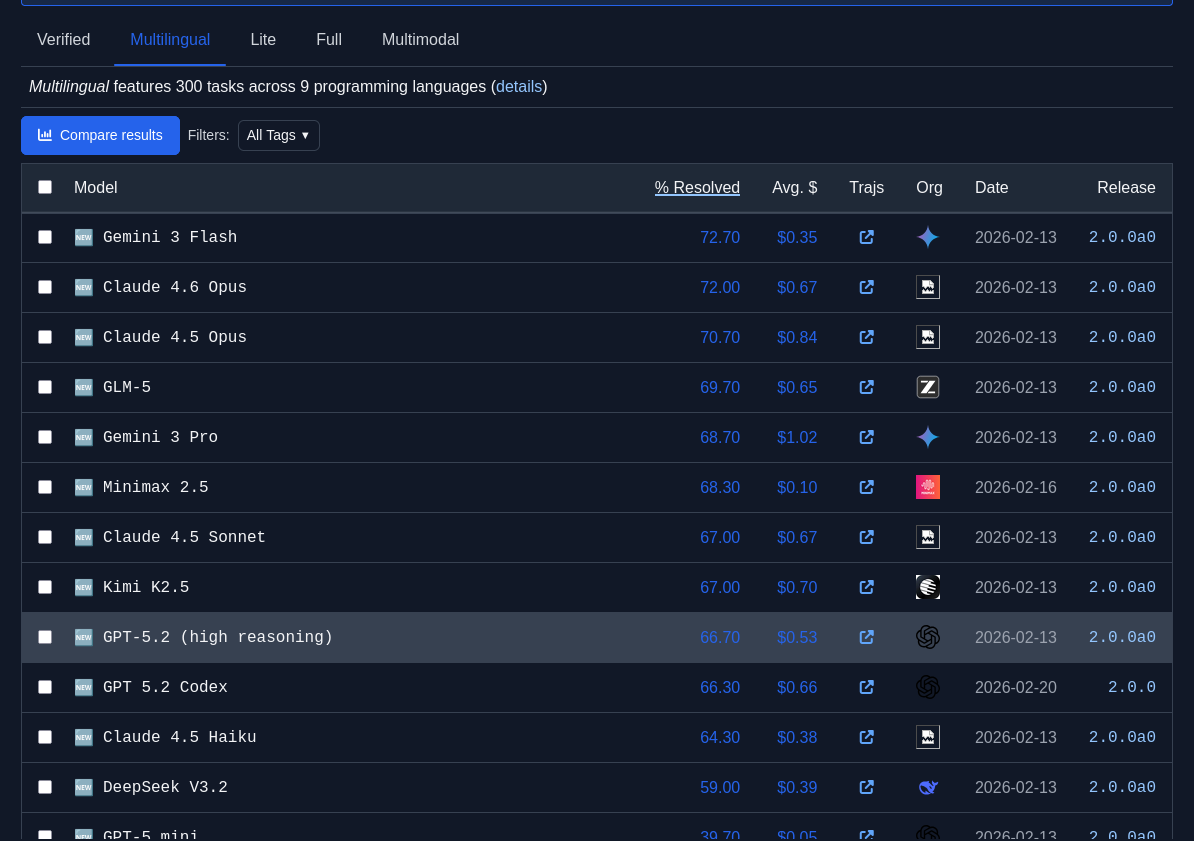
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.