
Artificial Analysis
Site officiel : https://artificialanalysis.ai
Journaux liées à cette note :
Comment je me renseigne sur un nouveau modèle LLM en 4 étapes
Voici le process que je suis lorsque je découvre un nouveau modèle LLM et que je souhaite en savoir plus à son propos.
Étape 1 : blog de Simon Willison
Je commence par jeter un œil rapide sur le blog de Simon Willison, car cela fait plusieurs années que je le suis et j'apprécie son expertise et ses analyses de modèles.
Étape 2 : les articles de Artificial Analysis
Ensuite je regarde les articles (https://artificialanalysis.ai/articles) d'Artificial Analysis, pour voir s'ils ont publié un nouvel article sur ce modèle. Généralement, ils sont très réactifs. Voici un exemple concernant Kimi K2.6 : Kimi K2.6: The new leading open weights model.
J'aime beaucoup la structure de leurs articles.
Tout d'abord, une section synthétique avec des informations majeures du modèle :

Ensuite, la position du nouveau modèle pour différents leaderboards :
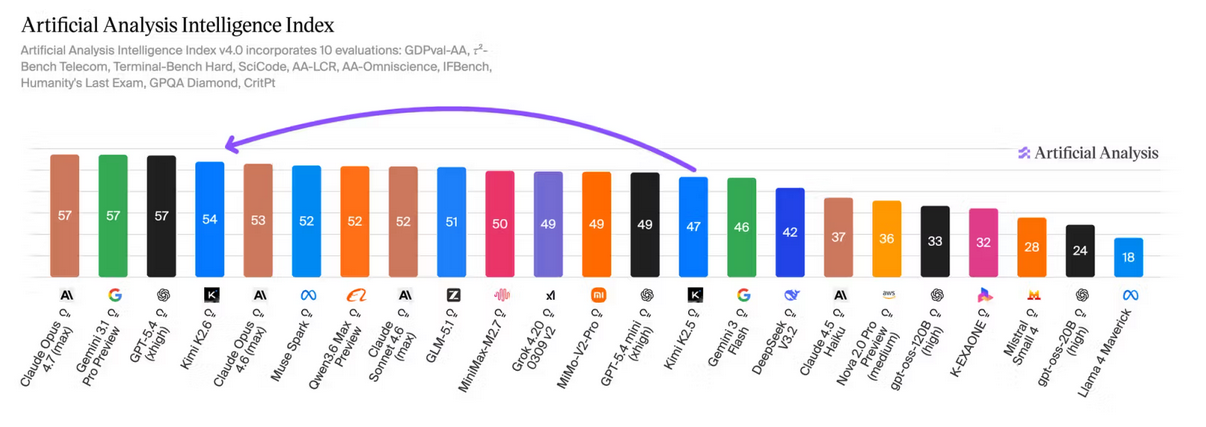
Étape 3 : Analyse des commentaires HackerNews
En troisième étape, j'utilise le moteur de recherche de Hacker News pour identifier le thread qui traite du modèle. Voici par exemple celui à propos de Kimi K2.6: Advancing open-source coding et ses 371 commentaires.
À partir de l'url de ce thread, je lance le prompt suivant dans Claude Desktop connecté au serveur MCP fetch lancé localement :
Utilise `fetch_html` pour récupérer https://news.ycombinator.com/item?id=47835735
**Étape 1 — Récupération complète**
- Récupère la première page avec `fetch_html` et lis le nombre total de commentaires indiqué en début de page — ce nombre est ta cible obligatoire
- Le contenu étant probablement tronqué (limite 200 000 caractères), enchaîne les appels successifs en incrémentant `start_index` de 200 000 à chaque fois :
- `fetch_html(url, start_index=0, max_length=200000)`
- `fetch_html(url, start_index=200000, max_length=200000)`
- `fetch_html(url, start_index=400000, max_length=200000)`
- … jusqu'à ce que la réponse soit vide
- **Tu dois avoir récupéré 100% des commentaires avant de passer à l'étape suivante.** Vérifie que le nombre de commentaires extraits correspond au compteur initial — si ce n'est pas le cas, continue à paginer.
**Étape 2 — Analyse exhaustive**
Analyse **chacun des commentaires sans exception** exclusivement sous l'angle des **modèles LLM** mentionnés. Aucun commentaire ne doit être ignoré ou échantillonné.
Pour chaque modèle cité, synthétise :
- **Points forts** relevés par les commentateurs
- **Points faibles** ou limitations mentionnées
- **Cas d'usage Coding** : performance en génération de code, débogage, complétion, etc.
- **Cas d'usage Intelligence générale** : raisonnement, compréhension, tâches polyvalentes, etc.
- **Benchmarks mentionnés** : scores, classements ou comparaisons chiffrées associés à ce modèle
**Étape 3 — Synthèse**
Présente le résultat sous forme de **deux tableaux comparatifs markdown** :
1. **Tableau Coding** — colonnes : Modèle | Points forts | Points faibles | Benchmarks coding
2. **Tableau Intelligence générale** — colonnes : Modèle | Points forts | Points faibles | Benchmarks généralistes
Puis ajoute :
1. Une section **"Comparaison directe entre modèles"** synthétisant les confrontations explicites faites par les commentateurs (quel modèle bat quel autre, sur quoi, dans quel contexte), en distinguant coding vs intelligence générale
2. Une section **"Benchmarks en discussion"** listant les benchmarks cités, leur crédibilité perçue par la communauté, et les modèles qu'ils avantagent ou désavantagent — en précisant s'il s'agit de benchmarks coding (HumanEval, SWE-bench…) ou généralistes (MMLU, GPQA…)
Seuls les commentaires sans aucune mention de modèle spécifique sont à ignorer.
Ce qui m'a donné le résultat suivant : Analyse par Sonnet 4.6 des commentaires Hacker News à propos de Kimi K2.6.
Étape 4 : quelques semaines plus tard
Quelques semaines plus tard, je consulte toutes les sorties de modèle du mois dans l'article Nouvelles sur l'IA du site LinuxFR pour avoir une revue complète de l'écosystème.
J'ai découvert MimiMax M2.7, qui semble équivalent à GLM-5 pour un tiers du prix
#JaiDécouvert la sortie de MiniMax M2.7 le 18 mars 2026 : https://www.minimax.io/news/minimax-m27-en.
Pour donner du contexte, j'utilise depuis le 12 mars 2026 les modèles GLM-5, Kimi K2.5 et MiniMax M2.5 via l'offre OpenCode Go. Je n'ai pas comparé rigoureusement ces modèles avec Sonnet 4.6 et Opus 4.6, mais pour le moment, je suis satisfait de ces modèles. J'ai même l'impression que MiniMax M2.5, le moins cher, suffit pour la majorité de mes besoins.
J'ai lu l'article "MiniMax M2.7 Review: Is It Worth the Hype?", mais c'est finalement MiniMax M2.7: Everything you need to know qui m'a été le plus utile, voici sa traduction :
MiniMax a publié MiniMax-M2.7, offrant une intelligence de niveau GLM-5 pour moins d'un tiers du coût
MiniMax-M2.7 de @MiniMax_AI obtient un score de 50 sur l'Artificial Analysis Intelligence Index, une amélioration de 8 points par rapport à MiniMax-M2.5, publié il y a un mois. Cette amélioration est portée par une performance améliorée sur les tâches agentiques du monde réel et une réduction des hallucinations. MiniMax-M2.7 est désormais devant MiMo-V2-Pro (Reasoning, 49) et Kimi K2.5 (Reasoning, 47), et équivalent à GLM-5 (Reasoning, 50) tout en utilisant 20% de tokens de sortie en moins et coûtant moins d'un tiers du prix pour fonctionner. MiniMax-M2.7 est un modèle uniquement raisonnement et maintient le même prix par token que MiniMax-M2.5.
Points clés :
➤ Performance solide sur les tâches agentiques du monde réel : MiniMax-M2.7 atteint un Elo GDPval-AA de 1494, une amélioration significative par rapport à MiniMax-M2.5 (1203) et devant MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406) et Kimi K2.5 (Reasoning, 1283). Il reste derrière les modèles de pointe tels que GPT-5.4 (xhigh, 1667) et Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606).
- Réduction des hallucinations : MiniMax-M2.7 obtient un score de +1 sur l'AA-Omniscience Index, contre -40 pour MiniMax-M2.5. Cela le place en compétition avec GPT-5.2 (xhigh, -1) et GLM-5 (Reasoning, +2), et bien devant Kimi K2.5 (Reasoning, -8). L'amélioration par rapport à M2.5 est entièrement due à la réduction des hallucinations, ce qui signifie que le modèle est plus susceptible de s'abstenir de répondre lorsqu'il ne connaît pas la réponse, plutôt que de deviner. M2.7 atteint un taux d'hallucination de 34%, inférieur à Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) et Gemini 3.1 Pro Preview (50%).
- Gains sur la plupart des évaluations par rapport à MiniMax-M2.5 : En dehors des améliorations du GDPval-AA et de l'AA-Omniscience notées ci-dessus, MiniMax-M2.7 progresse en HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.) et LCR (+3 p.p.). Nous avons constaté une régression notable en τ²-Bench (-11 p.p.).>
- Utilisation accrue de tokens : MiniMax-M2.7 a utilisé environ 87M tokens de sortie pour exécuter l'Artificial Analysis Intelligence Index, en hausse de 55% par rapport à MiniMax-M2.5 (environ 56M). Il reste plus efficace en tokens que d'autres modèles tels que GLM-5 (Reasoning, 110M) et Kimi K2.5 (Reasoning, environ 89M).
- Rentabilité de pointe : MiniMax-M2.7 a coûté 176 $ pour exécuter l'Artificial Analysis Intelligence Index, maintenant le même prix de 0,30 $/1,20 $ par million de tokens d'entrée/sortie que M2.5. Cela le place sur la frontière de Pareto de notre graphique Intelligence vs. Coût. À titre de référence, GLM-5 (Reasoning) a coûté 547 $ à intelligence équivalente, Kimi K2.5 (Reasoning) 371 $, et Gemini 3 Flash Preview (Reasoning) 278 $.
Détails clés du modèle :
- Fenêtre de contexte : 200K tokens (équivalent à MiniMax-M2.5).
- Tarification : 0,30 $/1,20 $ par million de tokens d'entrée/sortie (inchangé par rapport à MiniMax-M2.5).
- Disponibilité : API propriétaire MiniMax uniquement.
- Modalité : Entrée et sortie de texte uniquement (pas de multimodalité).
- Licence : MiniMax n'a pas annoncé si MiniMax-M2.7 sera en open weights. MiniMax-M2.5 est disponible sous licence MIT.
MiniMax M2.7 a été intégré dans l'offre OpenCode Go, par conséquent, je vais tester ce modèle dans mes projets OpenCode.