
CI_CD
Journaux liées à cette note :
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
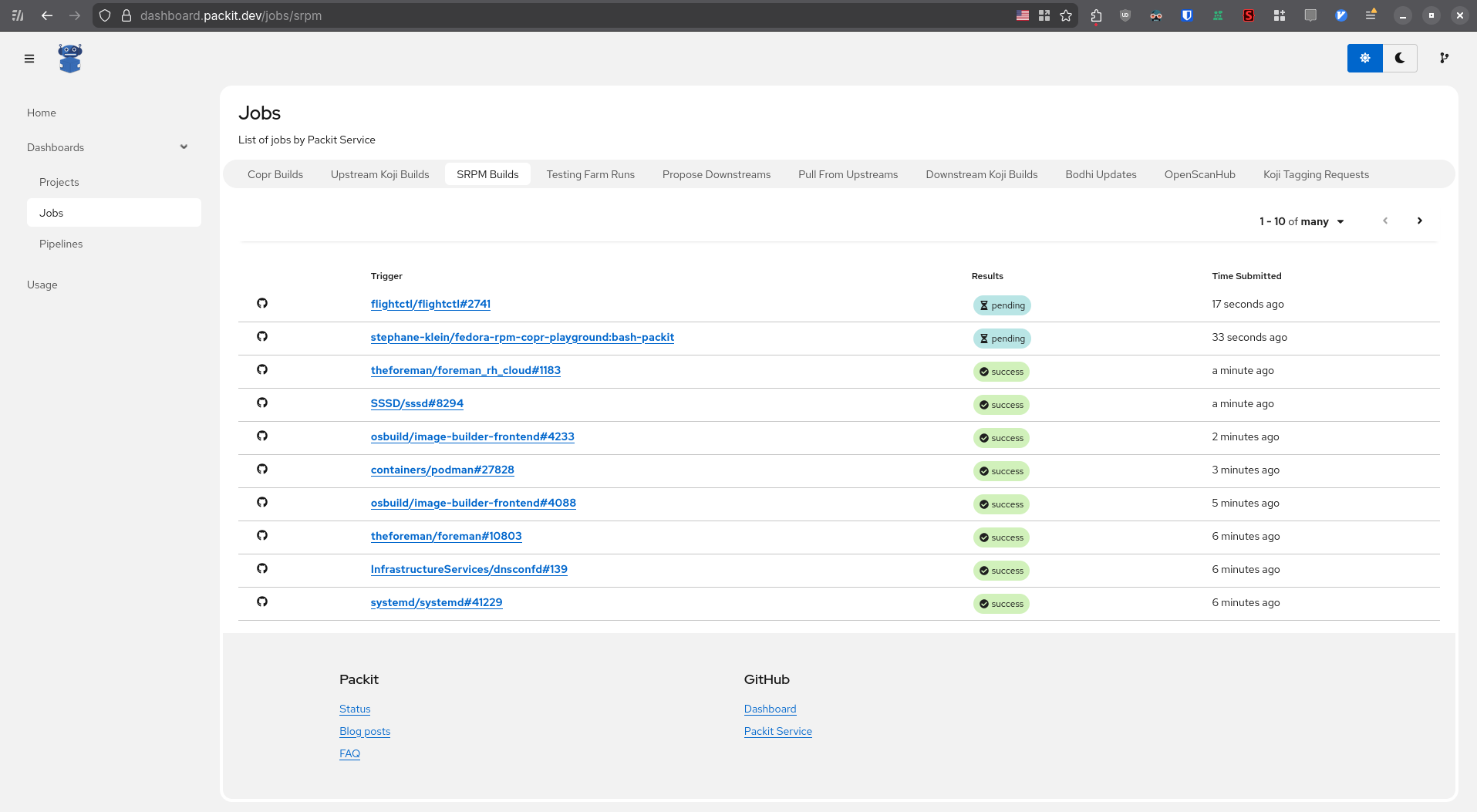
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
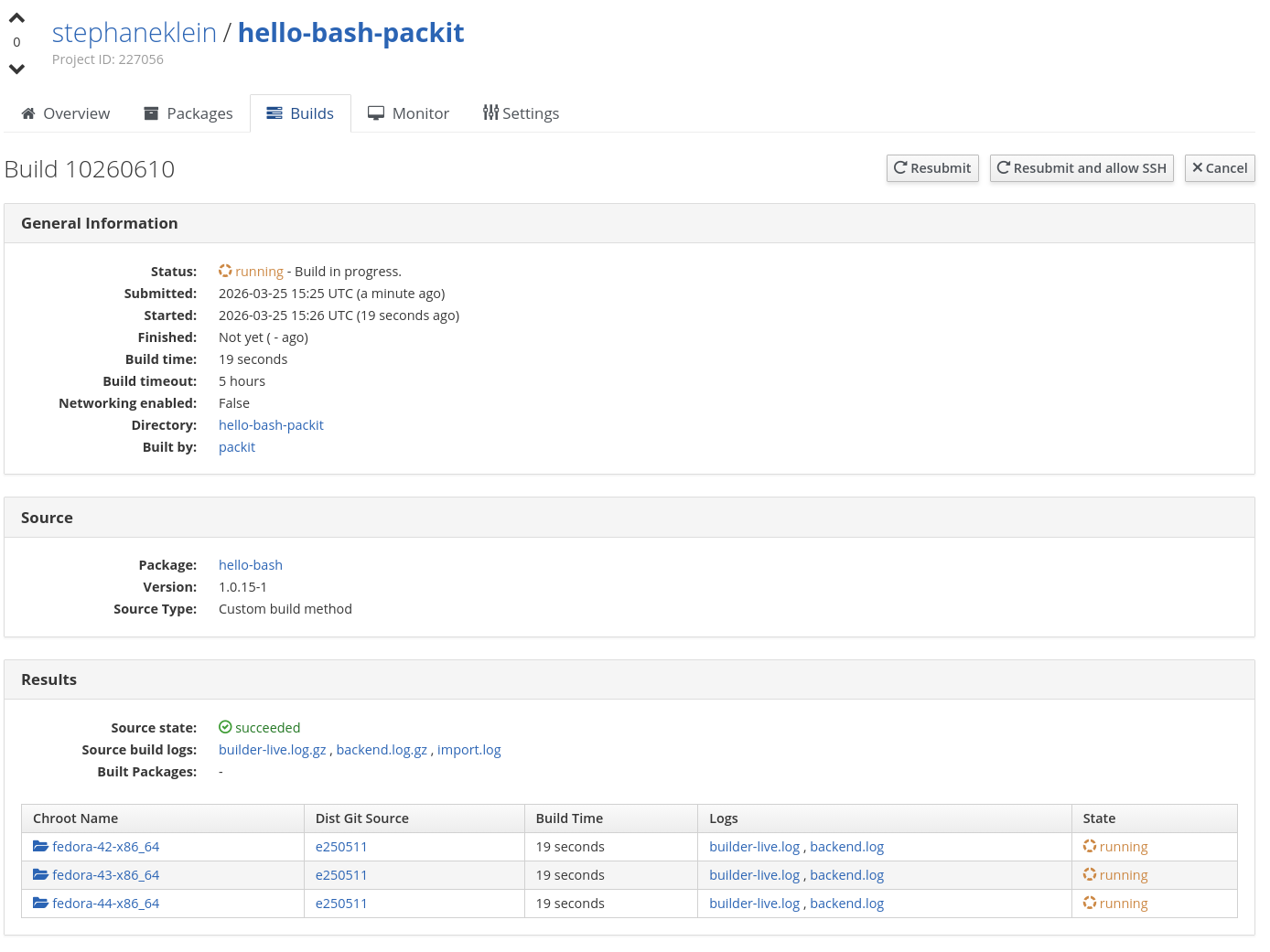
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
Exemples de labels de gestion de projet
Voici-ci dessous, une partie de la liste de labels d'Issues que l'équipe tech de Spacefill utlisait sous GitLab. Cette liste de labels est le fruit d'un travail itératif d'environ 15 personnes, sur une période de 4 ans.
Voici comment cette liste a été élaborée :
- Au départ, quelques labels ont été créés de manière organique par 3 développeurs et un product manager.
- Après 3 mois d'usage, une page de documentation nommée "GitLab Spacefill labels" a été ajoutée au handbook de l'équipe.
- Ensuite, au fur et à mesure des nouvelles problématiques rencontrées et de l'évolution des workflows, ce fichier de documentation a été amendé plus de 70 fois en 3 ans, par 11 contributeurs différents.
- Ce document était modifié suivant le même processus que le reste du handbook et le code :
- Une personne commençait par créer une issue pour décrire une problématique
- Ensuite, cette même personne ou une autre faisait une proposition d'évolution du processus par la rédaction d'une Merge Request qui modifiait cette page de documentation
- Puis cette Merge Request entrait dans une phase de review par l'équipe, était corrigée, amendée...
- Et finalement, quand cette Merge Request était approuvée par toute l'équipe, elle était mergée et ensuite respectée par tous
J'ai conservé cette liste afin de pouvoir l'utiliser comme source d'inspiration ou de fondation pour mes prochains projets en équipe.
Pour ceux qui souhaitent s'en inspirer, je recommande de ne pas adopter cette liste intégralement d'emblée. Privilégiez plutôt une sélection ciblée des labels qui correspondent à vos processus actuels, puis incorporez progressivement de nouveaux labels selon l'évolution de vos besoins.
Mon expérience m'a démontré que la mise en place de processus dans une organisation humaine fonctionne mieux par petites étapes successives. Cette approche incrémentale s'avère bien plus efficace que de tenter d'imposer en bloc un processus complet qui risquerait d'être inadapté à votre contexte spécifique.
Voici cette liste.
Labels pour indiquer les types d'issue
Une issue doit avoir dans tous les cas un seul type.
type::user-story: une issue qui apporte une fonctionnalité à l'applicationtype::improve: une issue qui apporte une amélioration mineure à une fonctionnalité existante, qui est plus simple de ne pas exprimer sous forme d'une user story, et qui bien sûr n'est pas un bug.type::documentation-and-process: problème ou amélioration d'un process ou d'une documentation interne (les deux sujets documentation et processus sont liés parce que les processus sont documentés). La documentation du logiciel à destination des usagers de l'application n'entre pas dans cette catégorie, elles sont du typeuser-story,improveoubug.type::enabler: un changement qui n'apporte pas directement de valeur aux utilisateurs de l'application. Ce type est utilisé pour des issues dont le but est d'améliorer l'expérience des développeurs (voir définitions : SAFe Enablers,Les enablers en agile)type::technical-debt: definition, label à utiliser, par exemple pour des issues dont le bug est d'upgrader une librairie, d'améliorer une implémentation, ou une proposition de refactoring… Ce label ne doit pas être utilisé pour des issues "produit".type::support-ops: pour les tâches de support qui ne nécessitent généralement pas de merge request, par exemple : des migrations de données, des corrections de données, des extractions de données…type::spike: voir la definitiontype::meta: pour des issues de type "meta", par exemple, des issues dont le but est de créer d'autres issues, de faire de l'affinage d'issues, ou organiser des rituels…- `type::meta-spec-writing` : pour des issues dont l'objectif est de créer des issues ou des Epic, dont le but est de rédiger des spécifications techniques, ce sont des sortes d'issues de type "meta", mais plus spécifiques.
type::bug: pour des issues qui décrivent des dysfonctionnements de l'applicationtype::bug-job-CI: pour des issues qui décrivent des bugs de CI
Labels pour indiquer la priorité des issues
priority::critical: une issue qui doit obligatoirement être traitée tout de suite par un développeurpriority::24h: une issue qui doit être traitée d'ici 24hpriority::7days: une issue qui doit être traitée d'ici à 1 semaine
Labels de workflow
Une issue doit avoir un et seulement un label de type workflow, un et un seul label de type product-review.
- Draft
workflow::need-product-specs: l'issue doit être spécifiée par un membre de l'équipe produitworkflow::need-design: l'issue a besoin de wireframe, design, …workflow::need-tech-specs: l'issue doit être affiner par un membre de l'équipe tech
- To do
workflow::ready-for-development: l'issue est prête à être implémentéeworkflow::to-be-continued: l'issue a été commencée, mais mise en pause parce que le développeur est assigné sur une autre issue.workflow::doing: un développeur est en train de travailler sur cette issueworkflow::ready-for-first-review: l'issue est prête à être review par un développeurworkflow::ready-for-maintainer-review: l'issue est prête à être review par un maintainersworkflow::blocked: l'issue est bloquée Par exemple :- l'issue est commencée, elle peut avoir une merge request de prête, mais le développeur ne peut pas la terminer, car elle dépend d'une autre Merge Request en cours d'élaboration ;
- l'auteur de l'issue attend une réponse d'une personne externe de l'équipe produit ou tech, par exemple un client.
workflow::ready-for-merge: l'issue a été review et est prête à être mergéneed-cto: l'issue est bloquée parce qu'elle est en attente d'une validation par le CTO
- Product review
product-review::needed: indique que l'issue doit être review par un membre de l'équipe produitproduct-review::not-needed: indique que l'issue n'a pas besoin d'être review par l'équipe produitproduct-review::pending: issue en attente de review par un membre de l'équipe produitproduct-review::feedback: une demande de correction a été émise par un membre de l'équipe produitproduct-review::approved: la Merge Request a été review et validée par un membre de l'équipe produit avec plus aucune demande de correction
Labels d'intégration dans des boards
board-product-refinement: pour intégrer des issues dans un Kanban board qui contient une liste d'issues que l'équipe produit doit affinerboard-tech-refinement: pour intégrer des issues dans un Kanban board qui contient une liste d'issues que l'équipe tech doit affinerboard-support: pour intégrer des issues dans un Kanban board qui contient une liste d'issues de support qui traitent des demandes externes à l'équipe tech ou produit.board-cto: utilisé par le CTO pour suivre des issues "cross team"
Labels divers
first-contribution: pour identifier des issues en théorie facilement réalisables par un nouveau développeur en phase d'onboarding.sprint-planning: pour les issues de typemeta, dont l'objectif est d'organiser le rituel Sprint Planning.sprint-retrospective: pour les issues de typemeta, dont l'objectif est d'organiser le rituel Sprint Retrospective.sprint-retro-follow-up: pour identifier les sujets qui ont été remontés lors d'une session de Sprint Retrospective.triage: pour identifier les issues qui doivent être triées, c'est-à-dire, décider si l'issue doit être abandonnée pour être placée dans un backlog.need-to-be-planned: pour identifier des issues validées, mais qui doivent être planifiées, c'est-à-dire, être ajoutées dans un sprintdanger: pour identifier des issues qui doivent être traitées avec prudence, qui par exemple risquent de détruire des données.tech-refinement: pour identifier une issue qui doit être affiner par l'équipe tech, mais qui n'a pas encore été ajoutée dans leboard-tech-refinement.tech-refinement-removed: pour identifier des issues qui étaient dans unboard-tech-refinementmais qui n'ont pas été affiné par manque de temps et donc repoussées à une future session.security: pour identifier des issues en lien avec la sécurité informatique, par exemple, un risque de fuite de données, de perte de données, d'intrusion…version-outdated: pour identifier les issues dont l'objectif est la mise à jour de librairies ou de services.
Label de compétences nécessaires
Liste de labels peu utilisés, ils permettaient d'identifier les compétences techniques nécessaires pour pouvoir traiter l'issue.
skills:ansibleskills:terraformskills:nodejsskills:postgraphileskills:html/cssskills:dockerskills:gitlab-ciskills:dockerskills:dev-opsskills:postgresskills:postgres-rlsskills:postgres-rbacskills:postgresql-plsqlskills:postgresql-policyskills:reactjsskills:shellscriptskills:sql
Journal du jeudi 12 septembre 2024 à 19:14
#JaiDécouvert cet article pnpm "Working with Docker".
J'y ai découvert corepack.
Pour le moment, je ne comprends pas l'avantage d'utiliser :
FROM node:20-slim AS base
ENV PNPM_HOME="/pnpm"
ENV PATH="$PNPM_HOME:$PATH"
RUN corepack enable
plutôt que :
FROM node:20-slim AS base
RUN npm install -g pnpm@9.10
🤔
Dans ce Dockerfile j'ai tout de même utilisé cette technique pour tester.
J'ai utilisé le système de cache store de pnpm :
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-lockfile
Je me suis posé la question de partage le cache de ma workstation :
$ pnpm store path
/home/stephane/.local/share/pnpm/store/v3
Mais je ne pense pas que cela soit une bonne idée dans le cas où cette image est buildé par une CI.
Journal du samedi 06 juillet 2024 à 11:16
Je pense avoir terminé le projet Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Merci à Alexandre pour ses commits de GitHub Actions CI/CD et du support multi architectures publié sur Docker Hub : # stephaneklein/restic-pg_dump.
Je suis assez satisfait du résultat. Le projet a été réalisé avec soin et j'ai tenté de le simplifier au maximum.
Il reste cependant une dernière possibilité de simplification à implémenter : Suggestion : Remplacer Supercronic par Cronie.
Bilan du temps passé sur le Projet 7 :
- 8 sessions de travail entre le 5 juin et le 6 juillet 2024 ;
- Pour un total de 10h16.