
GitLab
Journaux liées à cette note :
gh-issue-sync: sync GitHub issues locally and back
gh-issue-sync is a command line tool that syncs GitHub issues to local Markdown files for offline editing, batch updates, and integration with coding agents.
Pull issues locally, refine them until you are satisfied, and sync changes back. Also useful for offline access to your issues.
C'est un outil qui répond à un besoin que j'ai depuis 2018 : préparer avec un process précis des issues GitLab ou GitHub en draft, dans un format texte versionnable, particulièrement utile pendant la phase de meta-spec-writing.
C'est pour répondre à ce besoin que j'avais spécifié les fonctionnalités suivantes dans Projet 24 - Prototyper le gestionnaire de projet de mes rêves :
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
Je trouve curieux de voir émerger des projets comme Beads en octobre 2025 ou gh-issue-sync en décembre 2025, portés par la mouvance Specs Driven Development des agents IA, alors que j'explore ce formalisme depuis environ 2010. Ce qui m'intrigue surtout : pourquoi les développeurs s'intéressent à la spécification maintenant, et pas avant ? J'ai commencé à rédiger des choses à ce sujet, que je souhaite publier.
Le 15 mars dernier, j'ai créé des commandes OpenCode issue-create.md, issue-pull.md, issue-push.md, issue-update.md dont l'objectif était plus ou moins identique à gh-issue-sync : rédiger une issue dans un fichier local, la raffiner, puis l'envoyer vers GitHub. J'ai utilisé ces commandes pour créer les issues du projet sklein-devbox : https://github.com/stephane-klein/sklein-devbox/issues.
En l'état, je ne suis pas satisfait de mon expérience de développeur (DX). Il me semble que la fonctionnalité SKILL.md de gh-issue-sync offre probablement une meilleure architecture que l'utilisation des commandes OpenCode.
Ces prochains jours, je compte tester gh-issue-sync pour un éventuel remplacement. À plus long terme, j'aimerais pousser plus loin le sujet en testant Beads.
Confusion entre issue tracker et backlog, et comment gérer la masse d'issues
À la fin de la note "Collecter les sujets dans un issue tracker pour ne pas se répéter", je disais :
Un backlog est une liste d'items souvent extraits de l'ensemble des issues de l'issue tracker — un sous-ensemble volontairement restreint et de meilleure qualité. Priorisée, maintenue à jour et régulièrement affiné, cette liste représente le travail potentiel sérieusement envisagé pour le produit. Lors du Sprint Planning, les parties prenantes — développeurs, produit et autres contributeurs concernés — discutent et arbitrent ensemble les priorités pour décider quels items intégreront le Sprint Backlog.
Est-ce que toutes les issues ouvertes du issue tracker sont un backlog ? La réponse est non.
J'ai vu plusieurs fois des Product Managers arriver dans une organisation et être effrayés par la quantité d'issues présentes dans l'issue tracker — ils essayaient de passer en revue toutes les issues, pensant qu'il s'agissait du backlog.
Il me semble que cette confusion entre issue tracker et backlog est très classique — j'ai moi-même probablement entretenu cette confusion.
Les personnes issues de la culture open source sont habituées aux issue tracker, tandis que les Product Managers sont généralement plus familiers avec les Product Backlog.
Face à toutes ces issues, certains Product Managers font des choix radicaux pour garder la maîtrise :
- fermer très rapidement toutes les issues non prioritaires
- interdire l'utilisation d'un issue tracker
- ignorer l'issue tracker et travailler dans un autre outil
Je ne conseille pas ces approches : elles suppriment d'un bloc ce qui fait la valeur d'un issue tracker (voir "Collecter les sujets dans un issue tracker pour ne pas se répéter").
À la place, je conseille dans un premier temps de ne pas se préoccuper de l'intégralité des issues, et de se concentrer uniquement sur les issues indiquées par ses collègues ainsi que sur celles que l'on a soi-même créées.
Pour suivre ces issues et constituer son backlog, je conseille d'utiliser des labels — sur GitLab, j'utilise par exemple backlog, backlog-stephane, next-sprint, next-next-sprint. Ces labels, combinés à des vues kanban, permettent à chaque membre de créer un backlog à partir d'un sous-ensemble restreint d'issues.
Cette approche par labels fonctionne, mais le problème est que ce workflow exige une rigueur importante et un protocole commun d'équipe — difficile à mettre en place sans un leadership fort qui l'impulse et le maintient.
C'est pour améliorer cette expérience utilisateur, que j'ai intégré les fonctionnalités suivantes dans la description du gestionnaire de projet de mes rêves :
- Permettre de créer des portfolios d'issue par utilisateurs.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
De plus, j'imagine aussi une fonctionnalité permettant de « cacher » les issues, ou du moins de les rendre moins facilement accessibles aux nouveaux arrivants — non pas pour en interdire l'accès, mais pour réduire le bruit visuel et éviter qu'ils ne soient effrayés au point, après ce traumatisme, de les ignorer totalement.
Le triage régulier des issues (fermer et prioriser) est un travail laborieux, extrêmement difficile à maintenir dans la durée dès lors qu'un issue tracker contient beaucoup d'issues. Si je peux témoigner d'une chose, c'est que je n'ai probablement jamais réussi à le faire, ni vu quelqu'un y parvenir.
Concernant la fermeture des issues, certains projets configurent un système qui ferme automatiquement les issues après un certain temps sans activité. Personnellement, à la place de cela, je préfère un système qui poste un commentaire dans l'issue qui notifie et demande au créateur s'il juge qu'elle est toujours pertinente. En cas de non réponse après un temps imparti, l'issue peut être clôturée automatiquement.
Pour la priorisation des issues, toujours dans la description du gestionnaire de projet de mes rêves, j'ai imaginé la fonctionnalité suivante :
Collecter les sujets dans un issue tracker pour ne pas se répéter
En essayant de répondre à une question d'un ami au sujet du chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp, j'ai cherché à mettre des mots sur les raisons qui me poussent à utiliser un issue tracker, une pratique que j'expérimente depuis plus de 15 ans. Cette note est le résultat de cette réflexion.
Pendant 5 ans, de 2018 à 2023, j'ai utilisé GitLab comme outil de issue tracker, en équipe, dans deux organisations différentes.
Avant d'aller plus loin, il me semble utile de montrer concrètement les types d'issue présentes dans ces trackers (voir aussi ces labels) :
- Bug — corriger un comportement qui ne correspond pas à ce qui est attendu
- Feature — implémenter une nouvelle fonctionnalité
- Enhancement — améliorer une capacité existante ; DoD : le comportement amélioré est mesurable ou observable
- Knowledge Gap — répondre à une question sans réponse accessible ; DoD : répondre à la question, indiquer comment trouver la réponse à cette question, si l'information n'était pas documentée, alors la documenter ou améliorer la documentation existante
- Spike — explorer une question technique ou une hypothèse incertaine dans un temps imparti ; DoD : du code est livré, une décision binaire est posée (concluante / non concluante) et documentée dans l'issue
- Enabler — préparer le terrain technique pour qu'une ou plusieurs issues futures soient implémentables en moins de 10h ; DoD : mergé sur main sans régression, les issues qu'il débloque sont identifiées
- User story développeur — exprimer un besoin d'infrastructure ou d'outillage interne sous forme de user story dont le "user" est un développeur ; DoD : code produit, environnement de développement amélioré, documentation ajoutée, etc.
- meta-spec-writing — décomposer un périmètre flou en issues actionnables ; DoD : les issues enfants sont créées, estimées et prêtes pour le sprint planning
- Sprint planning — préparer et documenter une session de sprint planning ; DoD : date, participants et issues candidates documentés avant la réunion, décisions prises et issues assignées documentées après
- Sprint retrospective — préparer et documenter une session de rétrospective ; DoD : date et sujets à aborder documentés avant la réunion, décisions et actions correctives documentées après, chaque action corrective génère une issue de suivi
Pourquoi je crée systématiquement une issue ?
Mon approche consiste à créer une issue dès qu'une idée, un bug ou un sujet émerge — même sans intention de le traiter immédiatement.
C'est un point qui me tient à cœur, parce qu'il m'agace profondément de voir les mêmes sujets resurgir sans cesse sans jamais être vraiment travaillés.
J'ai souvent observé dans les open spaces des conversations de 10-20 minutes autour d'un sujet où chacun y va de son opinion, de son intuition, de ses mises en garde et de ses objections, puis retourne à ses activités… pour recommencer le même débat deux jours plus tard. Tout ce qui a été dit est perdu et rarement approfondi.
Ces "conversations de couloir" récurrentes sont un symptôme classique de non-décision : personne ne bloque explicitement, personne n'avance vraiment — la discussion tourne en boucle, invisible et non tracée. Dans certains cas, elles dégénèrent en Stop Energy : les mêmes objections ressurgissent à chaque fois, épuisant le porteur de l'idée sans jamais produire de résolution.
Je préfère de loin créer l'issue avant toute conversation. À défaut, quand j'assiste à une discussion informelle qui tourne en rond, je la crée à chaud, y dépose les idées échangées, et la partage aux participants pour vérifier que j'ai bien retranscrit. La prochaine fois que le sujet resurgit, j'invite chacun à la lire et ajouter son commentaire ou voter "+1".
L'issue devient un espace formel où chacun peut argumenter et enrichir le fil à son rythme ; le Sprint Planning devient le moment de délibération légitime où l'équipe arbitre collectivement si l'issue doit être traitée dans le nouveau sprint ou non.
Cette rigueur n'est pas simple à tenir : quand l'équipe a l'habitude de tout régler à l'oral, créer une issue peut passer pour de la lourdeur bureaucratique. Je la tiens malgré tout, parce que le coût de la répétition me paraît plus élevé que celui du traçage. Surtout, à long terme, cela évite le brouillard organisationnel.
Cette utilisation d'un issue tracker s'inspire du monde du logiciel libre, où des issues peuvent rester ouvertes des années, voire des décennies, et servent de mémoire collective pour comprendre la complexité d'une demande, les trade-offs, les ressources disponibles.
Quand cette méthode est appliquée pendant plusieurs années dans une organisation, un issue tracker peut contenir des centaines voire des milliers d'issues ouvertes, mais ceci ne pose pas de problème car ces issues ne constituent pas un backlog.
Un backlog est une liste d'items extraits et sélectionnés de l'ensemble des issues de l'issue tracker — un sous-ensemble volontairement restreint et de meilleure qualité. Priorisée, maintenue à jour et régulièrement affiné, cette liste représente le travail potentiel sérieusement envisagé pour le produit. Lors du Sprint Planning, les parties prenantes — développeurs, produit et autres contributeurs concernés — discutent et arbitrent ensemble les priorités pour décider quels items intégreront le Sprint Backlog.
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
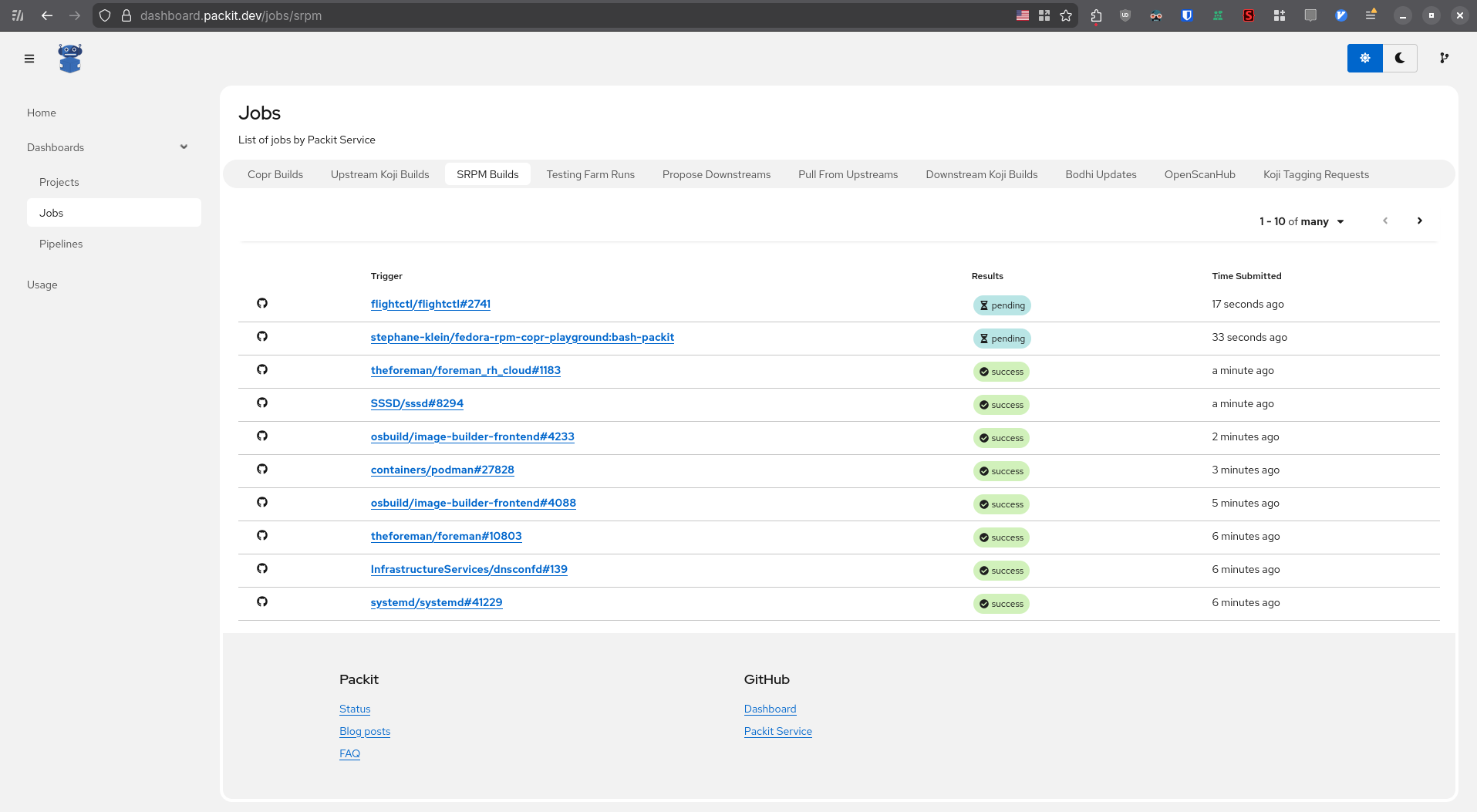
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
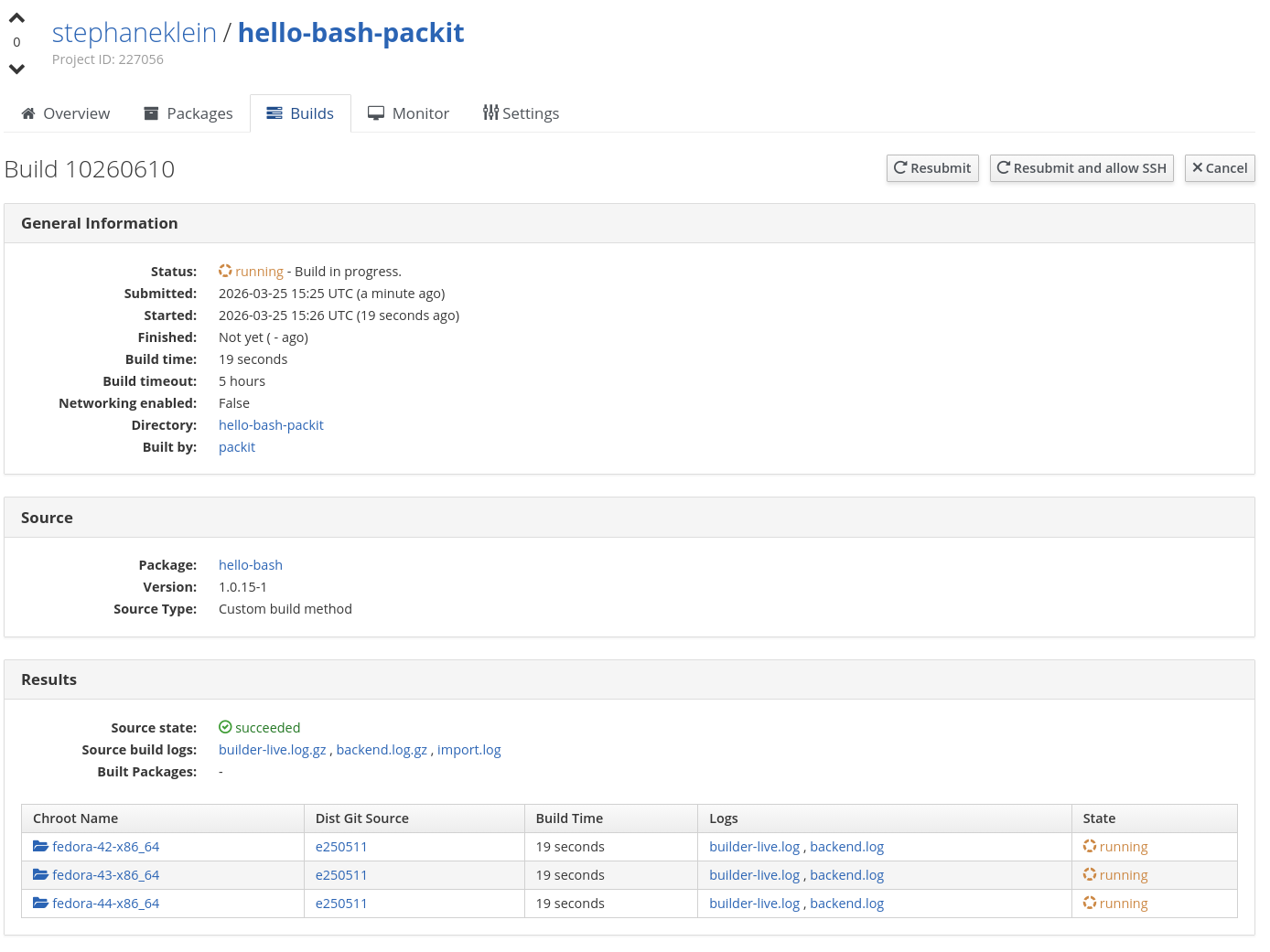
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
2026-04-02 : étudier Beads comme source d'inspiration ou outil à intégrer.
Exemples de labels de gestion de projet
Voici-ci dessous, une partie de la liste de labels d'Issues que l'équipe tech de Spacefill utlisait sous GitLab. Cette liste de labels est le fruit d'un travail itératif d'environ 15 personnes, sur une période de 4 ans.
Voici comment cette liste a été élaborée :
- Au départ, quelques labels ont été créés de manière organique par 3 développeurs et un product manager.
- Après 3 mois d'usage, une page de documentation nommée "GitLab Spacefill labels" a été ajoutée au handbook de l'équipe.
- Ensuite, au fur et à mesure des nouvelles problématiques rencontrées et de l'évolution des workflows, ce fichier de documentation a été amendé plus de 70 fois en 3 ans, par 11 contributeurs différents.
- Ce document était modifié suivant le même processus que le reste du handbook et le code :
- Une personne commençait par créer une issue pour décrire une problématique
- Ensuite, cette même personne ou une autre faisait une proposition d'évolution du processus par la rédaction d'une Merge Request qui modifiait cette page de documentation
- Puis cette Merge Request entrait dans une phase de review par l'équipe, était corrigée, amendée...
- Et finalement, quand cette Merge Request était approuvée par toute l'équipe, elle était mergée et ensuite respectée par tous
J'ai conservé cette liste afin de pouvoir l'utiliser comme source d'inspiration ou de fondation pour mes prochains projets en équipe.
Pour ceux qui souhaitent s'en inspirer, je recommande de ne pas adopter cette liste intégralement d'emblée. Privilégiez plutôt une sélection ciblée des labels qui correspondent à vos processus actuels, puis incorporez progressivement de nouveaux labels selon l'évolution de vos besoins.
Mon expérience m'a démontré que la mise en place de processus dans une organisation humaine fonctionne mieux par petites étapes successives. Cette approche incrémentale s'avère bien plus efficace que de tenter d'imposer en bloc un processus complet qui risquerait d'être inadapté à votre contexte spécifique.
Voici cette liste.
Labels pour indiquer les types d'issue
Une issue doit avoir dans tous les cas un seul type.
type::user-story: une issue qui apporte une fonctionnalité à l'applicationtype::improve: une issue qui apporte une amélioration mineure à une fonctionnalité existante, qui est plus simple de ne pas exprimer sous forme d'une user story, et qui bien sûr n'est pas un bug.type::documentation-and-process: problème ou amélioration d'un process ou d'une documentation interne (les deux sujets documentation et processus sont liés parce que les processus sont documentés). La documentation du logiciel à destination des usagers de l'application n'entre pas dans cette catégorie, elles sont du typeuser-story,improveoubug.type::enabler: un changement qui n'apporte pas directement de valeur aux utilisateurs de l'application. Ce type est utilisé pour des issues dont le but est d'améliorer l'expérience des développeurs (voir définitions : SAFe Enablers,Les enablers en agile)type::technical-debt: definition, label à utiliser, par exemple pour des issues dont le bug est d'upgrader une librairie, d'améliorer une implémentation, ou une proposition de refactoring… Ce label ne doit pas être utilisé pour des issues "produit".type::support-ops: pour les tâches de support qui ne nécessitent généralement pas de merge request, par exemple : des migrations de données, des corrections de données, des extractions de données…type::spike: voir la definitiontype::meta: pour des issues de type "meta", par exemple, des issues dont le but est de créer d'autres issues, de faire de l'affinage d'issues, ou organiser des rituels…- `type::meta-spec-writing` : pour des issues dont l'objectif est de créer des issues ou des Epic, dont le but est de rédiger des spécifications techniques, ce sont des sortes d'issues de type "meta", mais plus spécifiques.
type::bug: pour des issues qui décrivent des dysfonctionnements de l'applicationtype::bug-job-CI: pour des issues qui décrivent des bugs de CI
Labels pour indiquer la priorité des issues
priority::critical: une issue qui doit obligatoirement être traitée tout de suite par un développeurpriority::24h: une issue qui doit être traitée d'ici 24hpriority::7days: une issue qui doit être traitée d'ici à 1 semaine
Labels de workflow
Une issue doit avoir un et seulement un label de type workflow, un et un seul label de type product-review.
- Draft
workflow::need-product-specs: l'issue doit être spécifiée par un membre de l'équipe produitworkflow::need-design: l'issue a besoin de wireframe, design, …workflow::need-tech-specs: l'issue doit être affiner par un membre de l'équipe tech
- To do
workflow::ready-for-development: l'issue est prête à être implémentéeworkflow::to-be-continued: l'issue a été commencée, mais mise en pause parce que le développeur est assigné sur une autre issue.workflow::doing: un développeur est en train de travailler sur cette issueworkflow::ready-for-first-review: l'issue est prête à être review par un développeurworkflow::ready-for-maintainer-review: l'issue est prête à être review par un maintainersworkflow::blocked: l'issue est bloquée Par exemple :- l'issue est commencée, elle peut avoir une merge request de prête, mais le développeur ne peut pas la terminer, car elle dépend d'une autre Merge Request en cours d'élaboration ;
- l'auteur de l'issue attend une réponse d'une personne externe de l'équipe produit ou tech, par exemple un client.
workflow::ready-for-merge: l'issue a été review et est prête à être mergéneed-cto: l'issue est bloquée parce qu'elle est en attente d'une validation par le CTO
- Product review
product-review::needed: indique que l'issue doit être review par un membre de l'équipe produitproduct-review::not-needed: indique que l'issue n'a pas besoin d'être review par l'équipe produitproduct-review::pending: issue en attente de review par un membre de l'équipe produitproduct-review::feedback: une demande de correction a été émise par un membre de l'équipe produitproduct-review::approved: la Merge Request a été review et validée par un membre de l'équipe produit avec plus aucune demande de correction
Labels d'intégration dans des boards
board-product-refinement: pour intégrer des issues dans un Kanban board qui contient une liste d'issues que l'équipe produit doit affinerboard-tech-refinement: pour intégrer des issues dans un Kanban board qui contient une liste d'issues que l'équipe tech doit affinerboard-support: pour intégrer des issues dans un Kanban board qui contient une liste d'issues de support qui traitent des demandes externes à l'équipe tech ou produit.board-cto: utilisé par le CTO pour suivre des issues "cross team"
Labels divers
first-contribution: pour identifier des issues en théorie facilement réalisables par un nouveau développeur en phase d'onboarding.sprint-planning: pour les issues de typemeta, dont l'objectif est d'organiser le rituel Sprint Planning.sprint-retrospective: pour les issues de typemeta, dont l'objectif est d'organiser le rituel Sprint Retrospective.sprint-retro-follow-up: pour identifier les sujets qui ont été remontés lors d'une session de Sprint Retrospective.triage: pour identifier les issues qui doivent être triées, c'est-à-dire, décider si l'issue doit être abandonnée pour être placée dans un backlog.need-to-be-planned: pour identifier des issues validées, mais qui doivent être planifiées, c'est-à-dire, être ajoutées dans un sprintdanger: pour identifier des issues qui doivent être traitées avec prudence, qui par exemple risquent de détruire des données.tech-refinement: pour identifier une issue qui doit être affiner par l'équipe tech, mais qui n'a pas encore été ajoutée dans leboard-tech-refinement.tech-refinement-removed: pour identifier des issues qui étaient dans unboard-tech-refinementmais qui n'ont pas été affiné par manque de temps et donc repoussées à une future session.security: pour identifier des issues en lien avec la sécurité informatique, par exemple, un risque de fuite de données, de perte de données, d'intrusion…version-outdated: pour identifier les issues dont l'objectif est la mise à jour de librairies ou de services.
Label de compétences nécessaires
Liste de labels peu utilisés, ils permettaient d'identifier les compétences techniques nécessaires pour pouvoir traiter l'issue.
skills:ansibleskills:terraformskills:nodejsskills:postgraphileskills:html/cssskills:dockerskills:gitlab-ciskills:dockerskills:dev-opsskills:postgresskills:postgres-rlsskills:postgres-rbacskills:postgresql-plsqlskills:postgresql-policyskills:reactjsskills:shellscriptskills:sql
Depuis un an, j'ai pris conscience d'une difficulté inhérente aux organisations qui suivent le paradigme Multirepos, difficulté dont je ne m'étais pas rendu compte auparavant : décider où publier ses issues !
J'ai observé que dès qu'une organisation commence à utiliser plusieurs repositories, la question de l'endroit où créer de nouvelles issues se pose. Par exemple :
- Où poster une issue d'amélioration qui nécessite des changements dans le repository A et B ?
- Où créer une issue d'une proposition d'un process qui ne concerne pas spécifiquement le code source d'un projet hébergé dans un repository ?
- Où créer une issue dont le but est de créer un nouveau service ?
Quand une organisation suit le paradigme Monorepo avec issues colocalisées et utilise, comme je l'explique dans la note "Nom et arborescence de Monorepo" un nom non spécifique, alors la question de l'endroit où publier ses issues ne se pose pas ! Il suffit de publier l'issue dans le Monorepo (par exemple sur GitHub, GitLab ou Forgejo).
Le gestionnaire d'issue du Monorepo est un point de schelling, c'est-à-dire un endroit où tous les développeurs convergent naturellement en l'absence de communication explicite pour trouver et créer des issues.
Ce paradigme évite des débats à propos de l'endroit où publier les issues.
Nom et arborescence de Monorepo
Je suis un adepe du paradigme Monorepo, de la documentation colocalisée et des issues colocalisées.
Je conseille de nommer le repository avec le nom de l'organisation.
Par exemple, si mon organisation se nomme « Dummy Tech » et si elle utilise GitLab, alors je conseille d'utiliser le slug dummy-tech, ce qui donne gitlab.com/dummy-tech/dummy-tech/ et « Dummy Tech Monorepo » comme titre de repository.
La neutralité de ce nom facilite les décisions concernant ce qui peut ou non être inclus dans le repository, sans être limité par un nom trop restrictif. Il est flexible face à l'évolution du projet. Il permet d'éviter bien des débats à propos du nommage.
En 2018, sur GitHub, j'ai découvert un exemple de monorepo d'une organisation. Cet exemple m'a servi de base et je l'ai fait évoluer quand je travaillais chez Spacefill.
Voici un exemple d'arborescence de monorepo que j'aime utiliser :
dummy-tech
├── deployments
│ ├── prod
│ └── sandbox
├── ci
├── docs
├── playgrounds
│ ├── playground_a
│ └── playground_b
├── services
│ ├── service_a
│ ├── service_b
│ └── service_c
└── tools
├── tool_a
├── tool_b
└── tool_c
En 2016, Philippe Lafoucrière m'a appris que contrairement aux règles de typographie française, en typographie anglaise, il ne faut pas placer d'espace avant le caractère deux points :.
Je pense d'ailleurs que cette différence est peu connue par les Français et inversement.
Une des conséquences malheureuses de cette différence est la présence généralisée d'une popup de suggestion automatique d'émojis après la séquence <espace>: dans les éditeurs de texte Markdown. Cette fonctionnalité est activée par défaut, sans option pour la désactiver, par exemple, dans GitHub, GitLab ou Discourse.
Exemple :
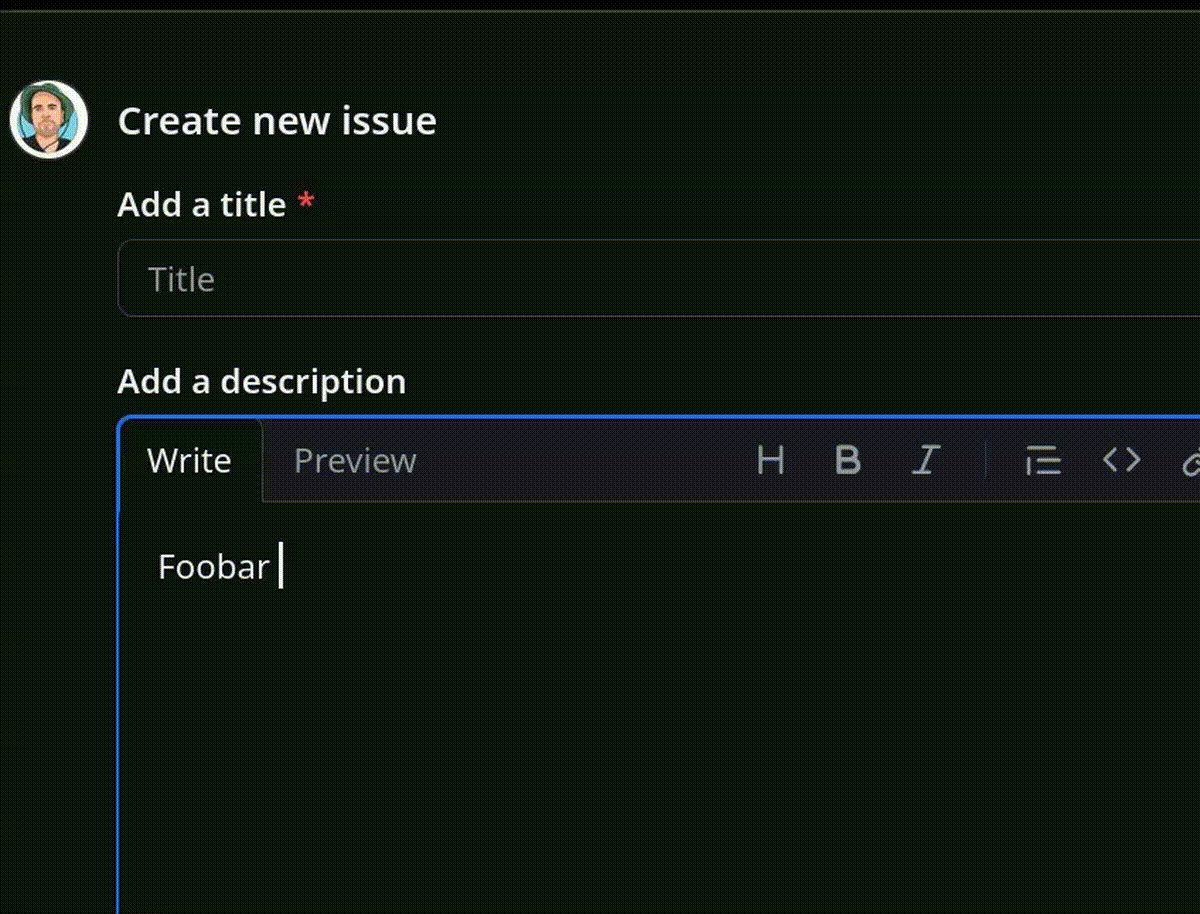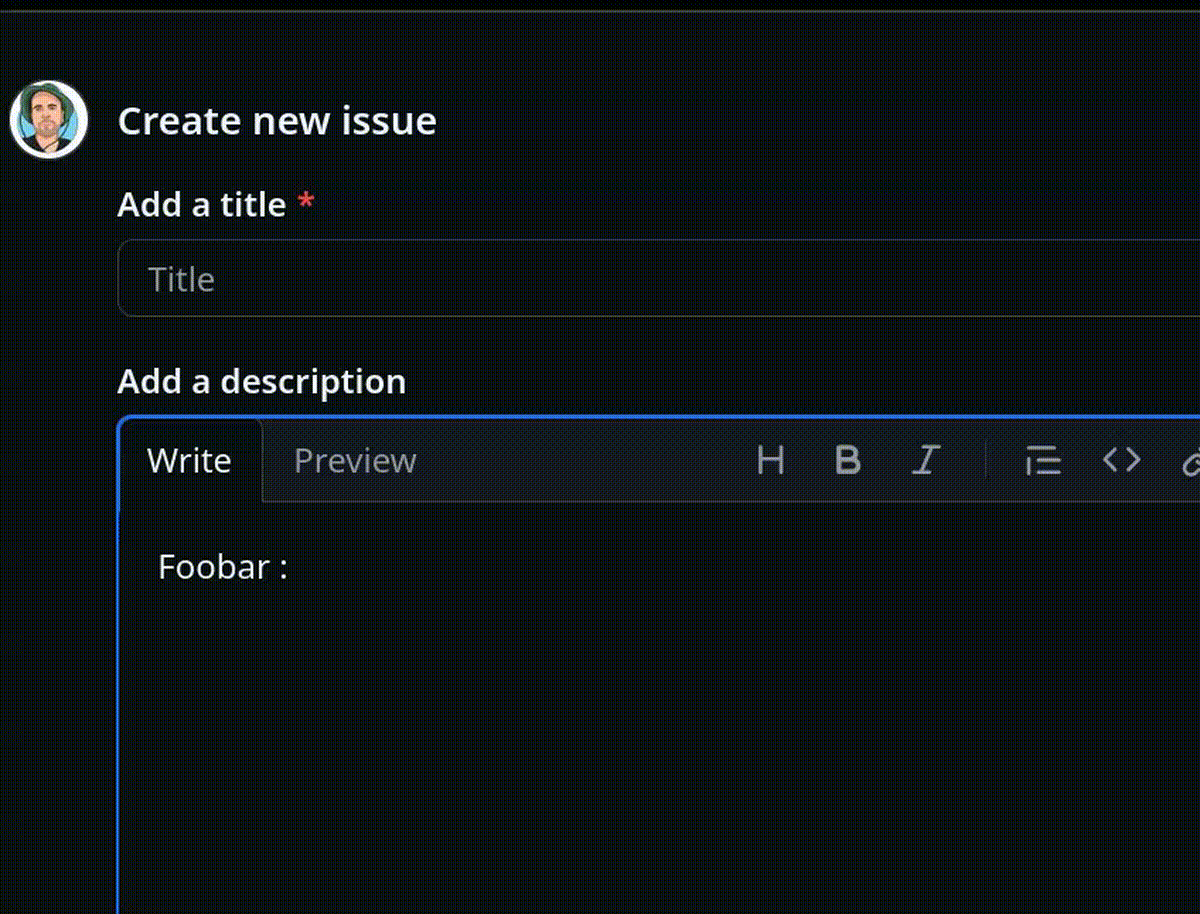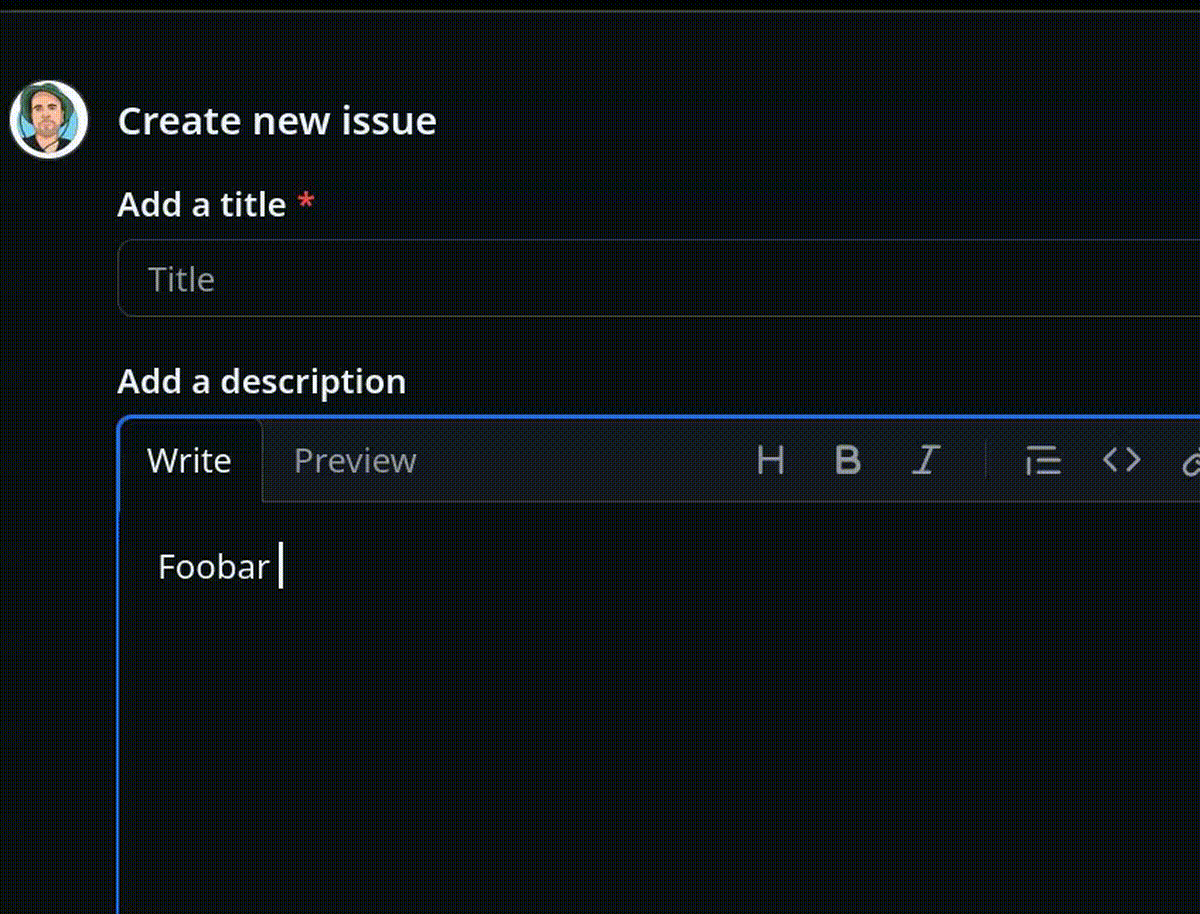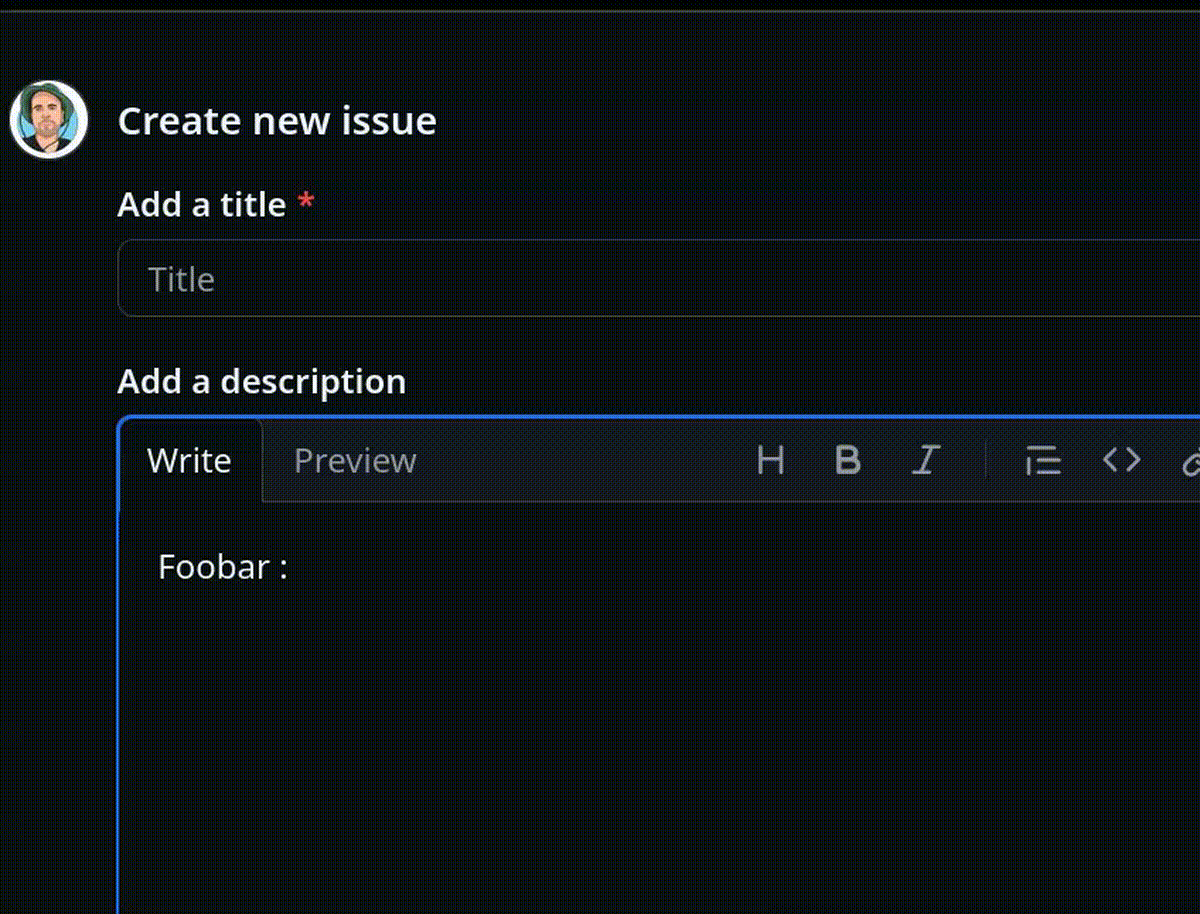
En 2022, j'ai implémenté et publié un User Styles pour Firefox (maintenant LibreWolf) basé sur Stylus pour désactiver cette autosuggestion automatique d'émojis sur GitHub, GitLab.
Je viens d'ajouter une règle pour Discourse.
Voici ces règles exécutées par Stylus (le fichier) :
@-moz-document regexp("http.*gitlab.*") {
.atwho-container #at-view-58 {
display: none !important;
}
}
@-moz-document domain("github.com") {
[class^="AutocompleteSuggestions"] {
display: none !important;
visibility: hidden !important;
}
}
@-moz-document regexp(".*discourse.*"), regexp(".*discussion.*") {
.autocomplete.ac-emoji {
display: none !important;
}
}
Comment l'installer ?
- Installer l'extension Firefox : https://add0n.com/stylus.html
- Et ensuite, cliquer sur le lien suivant pour installer mon fichier User Styles : https://github.com/stephane-klein/dotfiles/raw/refs/heads/main/userstyles/disable-gitlab-github-discourse-emoji-picker.user.css
Je vais essayer de rassembler mes User Styles dans ce dossier : https://github.com/stephane-klein/dotfiles/tree/main/userstyles.
Journal du mercredi 29 janvier 2025 à 16:29
Alexandre m'a fait remarquer que GitLab a activé par défaut une extension Markdown de génération automatique de TOC :
A table of contents is an unordered list that links to subheadings in the document. You can add a table of contents to issues, merge requests, and epics, but you can’t add one to notes or comments.
Add one of these tags on their own line to the description field of any of the supported content types:
[[_TOC_]] or [TOC]
- Markdown files.
- Wiki pages.
- Issues.
- Merge requests.
- Epics.
Je trouve cela excellent que cette extension Markdown soit supportée un peu partout, en particulier les issues, Merge Request… 👍️.
Cette fonctionnalité a été ajoutée en mars 2020 🫢 ! Comment j'ai pu passer à côté ?
GitHub permet d'afficher un TOC au niveau des README, mais je viens de vérifier, GitHub ne semble pas supporter cette extension TOC Markdown au niveau des issues… Pull Request…