
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (71 notes) :
Journal du samedi 25 octobre 2025 à 10:37
Mon objectif du weekend est d'avancer sur le Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab".
Je veux apprendre à configurer LUKS encryption sous CoreOS avec un démarrage automatique basé sur TPM2 via clevis.
Je veux aussi m'assurer qu'en cas de problème, je peux toujours monter la partition chiffrée en saisissant manuellement la clé secrète.
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du mardi 26 août 2025 à 21:45
Voici une note pour présenter la seconde #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
J'ai tout d'abord implémenté dans ce commit un mécanisme qui exécute du code JavaScript automatiquement après chaque git push.
Pour cela, j'ai choisi de me baser sur le mécanisme Server-Side Hooks natif de Git : post-receive.
Voici le contenu de ce script hook en Bash :
#!/bin/bash
while read oldrev newrev refname; do
branch=$(git rev-parse --symbolic --abbrev-ref $refname)
curl -X POST \
-H "Content-Type: application/json" \
-d "{
\"oldrev\": \"${oldrev}\",
\"newrev\": \"${newrev}\",
\"refname\": \"${refname}\",
\"branch\": \"${branch}\",
\"repository\": \"$(basename $(pwd))\"
}" \
"${POST_RECIEVE_HOOK_URL}" >> /dev/null
done
Chaque événement git push déclenche un appel HTTP vers le endpoint http://localhost:3334/post_recieve_hook_url/ exposé par le serveur NodeJS. Le payload contient notamment :
oldrev: l'identifiant du dernier commit présent dans le repository avant le pushnewrev: l'identifiant du commit le plus récent envoyé lors du push
L'intervalle entre oldrev et newrev permet d'identifier précisément l'ensemble des commits qui ont été poussés lors de cette opération.
J'ai ensuite implémenté une version SvelteKit iso-fonctionnelle de node-git-http-server. Voici le repository poc-node-git-server-in-sveltekit .
Contrairement à ce que j'avais prévu initialement, pour cette implémentation, je ne me suis pas basé sur SvelteKit Custom Server, mais sur la fonctionnalité Server hooks : src/hooks.server.js#L11.
Journal du dimanche 24 août 2025 à 12:42
Je viens de publier la première #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push" dans le repository node-git-http-server.
L'implémentation d'un serveur Git HTTP via Apache ou nginx, en s'appuyant sur git-http-backend , paraît plutôt simple à réaliser.
Comme mon objectif est d'intégrer cette fonctionnalité dans le projet sklein-pkm-engine et que j'ai une préférence pour les monolith, j'ai exploré les solutions basées sur NodeJS.
J'ai dans un premier temps étudié le projet node-git-http-server et ensuite node-git-server.
Ces deux projets semblent peu actifs.
J'ai échoué à faire fonctionner le projet node-git-server, probablement à cause d'une erreur de ma part — j'ai sans doute oublié d'initialiser au préalable les dépôts Git en mode bare.
Par la suite, en utilisant Claude Sonnet 4, j'ai créé une implémentation basée uniquement sur les modules natifs de NodeJS et l'exécutable git-http-backend , sans recourir à aucun package NodeJS externe.
Voici le résultat : node-git-http-server/server.js.
Prochaines étapes
- Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. - Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server.
Une extension browser pour exporter ses threads Claude.ia et ChatGPT
Actuellement, et à ma connaissance, les APIs de Claude.ai et ChatGPT ne proposent pas de fonctionnalité d'export de l'historique des conversations de leur interface web de chat.
J'imagine deux approches pour réaliser cet export malgré tout : développer un script qui réalise une forme de Web Scraping ou intégrer cette fonctionnalité directement dans une extension navigateur plutôt que dans un script autonome. L'extension browser présente l'avantage de simplifier la gestion de l'authentification.
Après 30 minutes de recherche sur GitHub, du style "export chatgpt", j'ai trouvé claude-chatgpt-backup-extension. Cette extension permet l'export d'une ou plusieurs conversations Claude.ai et une conversation à la fois ChatGPT.
Je l'ai testée, elle fonctionne correctement 🙂.
Je viens de proposer cette Pull Request pour ajouter le support de l'export ChatGPT en mode bulk : Add bulk export feature for ChatGPT conversations.
Cette extension pourrait me servir de base de travail pour l'idée de projet "Aggregator - Backup Numeric Conversation System".
Voici les prochaines issues d'amélioration que j'imagine pour un fork de cette extension :
- Affichage conditionnel des boutons d'export Claude.ai uniquement quand l'utilisateur est connecté sur https://claude.ai/ (même principe pour ChatGPT).
- Afficher une barre de progression lors des bulk exportations.
- Proposer une option d'export au format YAML, sous une forme plus facile à lire pour les humains, avec moins d'informations techniques que le format JSON natif proposé actuellement.
- Tenter un refactoring pour simplifier la base de code actuelle.
- Développer une option permettant l'export vers des services Object Storage qui implémentent l'API S3.
- Créer un mock serveur API REST et permettre l'export des données vers ce serveur.
Liste d'issues pour gibbon-replay de juin 2025
Mon objectif dans cette note est de rassembler une liste d'issues que j'ai à l'esprit pour le projet gibbon-replay.
Dans cette note, les issues sont décrites en moins de 280 caractères, de manière approximative et sans doute un peu idiosyncrasique. Elles sont présentées dans un ordre quelconque.
- Dans le README, expliquer pourquoi j’ai créé ce projet et son ambition. Indiquer clairement que l’objectif est de rester simple à déployer (architecture monolithique) et que les utilisateurs plus ambitieux peuvent se tourner vers des solutions comme Posthog ou OpenReplay.
- Toujours dans le README, indiquer comme dans l'introduction de SilverBullet : « gibbon-replay is optimized for people with a hacker mindset ».
- [x] En tant qu'utilisateur, je peux visualiser l'espace mémoire total utilisé par l'ensemble des sessions. Issue GitHub : #4.
- [x] En tant qu'utilisateur, je peux visualiser l'espace mémoire consommé par chaque session individuellement.
- [x] En tant qu'utilisateur, je peux visualiser la durée de chaque session. Issue Github : #3.
- [x] En tant qu'utilisateur, je peux consulter, session par session, la présence ou non des actions utilisateur. Issue GitHub : #6.
- [ ] Optimiser la densité d'affichage de la liste des sessions en regroupant plusieurs données dans des cellules multilignes.
- En tant qu'utilisateur, dans la page liste des sessions, je peux appliquer un filtre sur les champs suivants : durée, taille mémoire ou mouvement de souris.
- En tant qu'utilisateur, dans la page détail d'une session, je peux visualiser les titres et les URLs des pages décrivant le parcours effectué par l'utilisateur.
- En tant qu'utilisateur, je peux visualiser un résumé textuel, du parcours utilisateur d'une session, rédigé par un agent conversationnel de petite taille.
- En tant qu'utilisateur avancé, je peux effectuer des recherches avancées sur le contenu des URLs présentes dans le parcours utilisateur. Par exemple, l'utilisateur peut saisir du code JavaScript qui permet de tester une condition sur toutes les URLs parcourues lors d'une session. Si la condition est positive, alors le résultat doit être sauvegardé dans un champ json de la session.
- En tant qu'utilisateur avancé, je peux rechercher des informations spécifiques dans le contenu des URLs présentes dans le parcours d'une session. Par exemple, je peux saisir un code JavaScript personnalisé pour tester une condition (comme la présence d'un
utm_sourceoucampaign) sur toutes les URLs parcourues. Si cette condition est vérifiée, les résultats correspondants sont stockés dans un champ json dans la session, permettant d'effectuer par la suite un filtre sur la liste des sessions. - User Story qui ressemble à la précédente : en tant qu'utilisateur avancé, je peux rechercher les balises HTML qui ont déclenché un événement "click" durant un parcours de session. Pour ce faire, il peut saisir du code JavaScript personnalisé pour tester une condition spécifique (comme la présence d'un attribut, d'une classe, etc.) sur ces balises. Les résultats de cette recherche sont enregistrés dans un champ JSON associé à la session, permettant d'effectuer par la suite un filtre sur la liste des sessions.
- En tant qu'utilisateur, je peux activer / désactiver l'envoi de notifications web sur des filtres de session, filtres avancés inclus.
- Permettre à une instance gibbon-replay d'enregistrer et de gérer plusieurs sites en même temps, en single-tenant.
- Ajouter un support multiutilisateurs — toujours en mode single-tenant. Permettre l'authentification par magic link et par username et password.
- Permettre la gestion des utilisateurs par API REST.
- Permettre de supprimer automatiquement des sessions en fonction de critères de filtres.
- En tant qu'utilisateur, je peux supprimer des sessions en mode batch.
Prochaine étape : créer ces issues plus détaillé dans : https://github.com/stephane-klein/gibbon-replay/issues
Journal du samedi 26 avril 2025 à 22:43
J'ai publié une première version du Projet 28 - "Publier un repository playground de déploiement de Open WebUI basé sur docker-compose.yml".
https://github.com/stephane-klein/open-webui-deployment-playground/
Je vais maintenant attaquer le Projet 29 - "Publier un repository playground de déploiement de Open WebUI sur un cluster Kubernetes".
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.
Journal du dimanche 19 janvier 2025 à 11:24
#iteration Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram :
Être capable d'exposer sur Internet un port d'une VM.
Voici comment j'ai atteint cet objectif.
Pour faire ce test, j'ai installé un serveur http nginx sur une VM qui a l'IP 192.168.1.236.
Cette IP est attribuée par le DHCP installé sur mon routeur OpenWrt. Le serveur hôte Proxmox est configuré en mode bridge.
Ma Box Internet Bouygues sur 192.168.1.254 peut accéder directement à cette VM 192.168.1.236.
Pour exposer le serveur Proxmox sur Internet, j'ai configuré mon serveur Serveur NUC i3 gen 5 en tant que DMZ host.
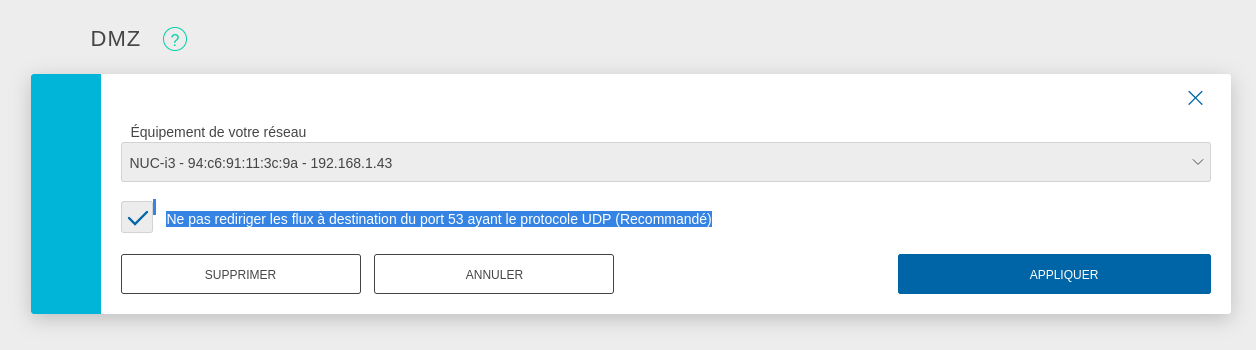
J'ai suivi la recommandation pour éviter une attaque du type : DNS amplification attacks
DNS amplification attacks involves an attacker sending a DNS name lookup request to one or more public DNS servers, spoofing the source IP address of the targeted victim.
Avec cette configuration, je peux accéder en ssh au Serveur NUC i3 gen 5 depuis Internet.
J'ai tout de suite décidé d'augmenter la sécurité du serveur ssh :
# cat <<'EOF' > /etc/ssh/sshd_config.d/sklein.conf
Protocol 2
PasswordAuthentication no
PubkeyAuthentication yes
AuthenticationMethods publickey
KbdInteractiveAuthentication no
X11Forwarding no
# systemctl restart ssh
J'ai ensuite configuré le firewall basé sur nftables pour mettre en place quelques règles de sécurité et mettre en place de redirection de port du serveur hôte Proxmox vers le port 80 de la VM 192.168.1.236.
nftables est installé par défaut sur Proxmox mais n'est pas activé. Je commence par activer nftables :
root@nuci3:~# systemctl enable nftables
root@nuci3:~# systemctl start nftables
Voici ma configuration /etc/nftables.conf, je me suis fortement inspiré des exemples présents dans ArchWiki : https://wiki.archlinux.org/title/Nftables#Server
# cat <<'EOF' > /etc/nftables.conf
flush ruleset;
table inet filter {
# Configuration from https://wiki.archlinux.org/title/Nftables#Server
set LANv4 {
type ipv4_addr
flags interval
elements = { 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 169.254.0.0/16 }
}
set LANv6 {
type ipv6_addr
flags interval
elements = { fd00::/8, fe80::/10 }
}
chain input {
type filter hook input priority filter; policy drop;
iif lo accept comment "Accept any localhost traffic"
ct state invalid drop comment "Drop invalid connections"
ct state established,related accept comment "Accept traffic originated from us"
meta l4proto ipv6-icmp accept comment "Accept ICMPv6"
meta l4proto icmp accept comment "Accept ICMP"
ip protocol igmp accept comment "Accept IGMP"
udp dport mdns ip6 daddr ff02::fb accept comment "Accept mDNS"
udp dport mdns ip daddr 224.0.0.251 accept comment "Accept mDNS"
ip saddr @LANv4 accept comment "Connections from private IP address ranges"
ip6 saddr @LANv6 accept comment "Connections from private IP address ranges"
tcp dport ssh accept comment "Accept SSH on port 22"
tcp dport 8006 accept comment "Accept Proxmox web console"
udp sport bootpc udp dport bootps ip saddr 0.0.0.0 ip daddr 255.255.255.255 accept comment "Accept DHCPDISCOVER (for DHCP-Proxy)"
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table nat {
chain prerouting {
type nat hook prerouting priority dstnat;
tcp dport 80 dnat to 192.168.1.236;
}
chain postrouting {
type nat hook postrouting priority srcnat;
masquerade
}
}
EOF
Pour appliquer en toute sécurité cette configuration, j'ai suivi la méthode indiquée dans : "Appliquer une configuration nftables avec un rollback automatique de sécurité".
Après cela, voici les tests que j'ai effectués :
- Depuis mon réseau local :
- Test d'accès au serveur Proxmox via ssh :
ssh root@192.168.1.43 - Test d'accès au serveur Proxmox via la console web : https://192.168.1.43:8006
- Test d'accès au service http dans la VM :
curl -I http://192.168.1.236
- Test d'accès au serveur Proxmox via ssh :
- Depuis Internet :
Voilà, tout fonctionne correctement 🙂.
Prochaines étapes :
- Être capable d'accéder depuis Internet via IPv6 à une VM
- Je souhaite arrive à effectuer un déploiement d'une Virtual instance via Terraform
J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot
Note d' #iteration du Projet 21 - "Rechercher un AI code assistant qui ressemble à Cursor mais pour Neovim".
J'ai réussi à installer avante.nvim, voici le commit de changement de mon dotfiles : "Add Neovim Avante AI Code assistant".
Suite à la lecture de :
Since auto-suggestions are a high-frequency operation and therefore expensive, it is recommended to specify an inexpensive provider or even a free provider: copilot
et ma note 2025-01-12_2026, #JaiDécidé de connecter avante.nvim à GitHub Copilot.
J'ai suivi les instructions de README.md de avante.nvim et voici les difficultés que j'ai rencontrées.
Contexte : j'utilise lazy.nvim avec la méthode kickstart.nvim.
- Ici j'ai appliqué cette configuration :
opts = {
provider = "copilot",
auto_suggestions_provider = "copilot",
copilot = {
model = "claude-3.5-sonnet"
}
},
- Ce commentaire n'indique pas explicitement que je devais ajouter ici cette initialisation de copilot.lua :
{
"zbirenbaum/copilot.lua",
config = function()
require("copilot").setup({})
end
},
Après installation des plugins (Lazy sync), il faut lancer :Copilot auth pour initialiser l'accès à votre instance de GitHub Copilot. C'est très simple, il suffit de suivre les instructions à l'écran.
Pour le moment, j'ai uniquement fait un test de commentaire d'un script : « Est-ce que ce script contient des erreurs ? » :
J'ai ensuite tenté de consulter mon rapport d'utilisation de GitHub Copilot pour vérifier l'état de mes quotas, mais je n'ai pas réussi à trouver ces informations :
D'ici quelques jours, je prévois de rédiger un bilan d'utilisation de avante.nvim pour faire le point sur mon expérience avec cet outil.
Journal du jeudi 09 janvier 2025 à 13:13
Nouvelle #iteration sur le Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Je viens de push le commit feat(android): implemented webview and configured deeplinks. J'ai passé en tout, 11 heures sur cette itération.
Je souhaite, dans cette note de type DevLog, présenter les difficultés et les erreurs rencontrées dans cette itération.
Étape 1 : mise en place d'un dummy website totalement statique
The Capacitor application in this POC displays the content of a demonstration website, with the HTML content located in the
./dummy-website/folder.
This website is served by an HTTP Nginx server, launched usingdocker-compose.yml.
Pour faire très simple, j'ai choisi de créer un faux site totalement statique, qui sera affiché dans une webview de l'application smartphone.
Ce site contient juste 2 pages HTML ; celui-ci est exposé par un serveur HTTP nginx, lancé via un docker-compose.yml.
Étape 2 : Expose dummy website on Internet
En première étape, j'ai dû mettre en place une méthode pour facilement exposer sur Internet un dummy website lancé localement :
Expose dummy website on Internet
Why?
The Android and iOS emulators do not have direct and easy access to the HTTP service (dummy website) exposed on http://localhost:8080.To overcome this issue, I use "cloudflared tunnel". You can also use other solutions, such as sish or ngrok Developer Preview. For more information, you can refer to the following note (in French): 2025-01-06_2105
Comme expliqué ci-dessus, cette contrainte est nécessaire afin de permettre à l'émulateur Android et à l'émulateur iOS (lancé sur une instance Scaleway Apple Silicon) aussi bien que sur mon smartphone physique personnel, d'accéder aux dummy website avec un support https.
Ceci était d'autant plus nécessaire, pour remplir les contraintes de configuration de la fonctionnalité Deep Linking with Universal and App Links.
C'est pour cela que j'ai dernièrement publié les notes suivantes : 2024-12-28_1621, 2024-12-28_1710, 2024-12-31_1853 et Alternatives managées à ngrok Developer Preview.
Pour simplifier la configuration de ce projet (poc-capacitor), j'ai décidé d'utiliser "cloudflared tunnel" en mode non connecté.
J'ai installé cloudflared avec Mise (voir la configuration ici).
Pour rendre plus pratique le lancement et l'arrêt du tunnel cloudflare, j'ai implémenté deux scripts :
Voici ce que cela donne à l'usage :
$ ./scripts/start-cloudflare-http-tunnel.sh Starting the tunnel... …wait… …wait… …wait… Tunnel started successfully: https://moral-clause-interesting-broadway.trycloudflare.comTo stop the tunnel, you can execute:
$ ./scripts/stop-cloudflare-http-tunnel.sh Stopping the tunnel (PID: 673143)... Tunnel stopped successfully.
Étape 3 : configuration de la webview Capacitor
En réalité, par erreur, j'ai configuré la webview Capacitor après l'implémentation de la partie App links.
Au départ, je pensais qu'un simple window.location.href = process.env.START_URL; était suffisant pour afficher le site web dans l'application. En réalité, cette commande a pour effet d'ouvrir la page HTML dans le browser par défaut du smartphone. Je ne m'en étais pas tout de suite rendu compte.
Dans Capacitor, pour créer une webview dans une application, il est nécessaire l'utiliser la fonction InAppBrowser.openInWebView(... du package @capacitor/inappbrowser.
Voici l'implémentation dans le fichier /src/js/online-webview.js :
window.Capacitor.Plugins.InAppBrowser.openInWebView({ url: startUrl, options: { // See https://github.com/ionic-team/capacitor-os-inappbrowser/blob/e5bee40e9b942da0d4dad872892f5e7007d87e75/src/defaults.ts#L33 // Constant values are in https://github.com/ionic-team/capacitor-os-inappbrowser/blob/e5bee40e9b942da0d4dad872892f5e7007d87e75/src/definitions.ts showToolbar: false, showURL: false, clearCache: true, clearSessionCache: true, mediaPlaybackRequiresUserAction: false, // closeButtonText: 'Close', // toolbarPosition: 'TOP', // ToolbarPosition.TOP // showNavigationButtons: true, // leftToRight: false, customWebViewUserAgent: 'capacitor webview', android: { showTitle: false, hideToolbarOnScroll: false, viewStyle: 'BOTTOM_SHEET', // AndroidViewStyle.BOTTOM_SHEET startAnimation: 'FADE_IN', // AndroidAnimation.FADE_IN exitAnimation: 'FADE_OUT', // AndroidAnimation.FADE_OUT allowZoom: false }, iOS: { closeButtonText: 'DONE', // DismissStyle.DONE viewStyle: 'FULL_SCREEN', // iOSViewStyle.FULL_SCREEN animationEffect: 'COVER_VERTICAL', // iOSAnimation.COVER_VERTICAL enableBarsCollapsing: true, enableReadersMode: false } } });
Les paramètres dans options permettent de configurer la webview. J'ai choisi de désactiver un maximum de fonctionnalités.
En implémentant cette partie, j'ai rencontré trois difficultés :
- Avec la version
1.0.2du packages, j'ai rencontré ce bug "Bug- Android App crashing after adding this plugin, j'ai perdu presque 1 heure avant de le découvrir, pour fixer cela, j'ai choisi le QuickWin d'installer la version1.0.1. - J'ai mis un peu de temps pour trouver les paramètres passés dans
options - J'ai trouvé
allowZoom: falsepour supprimer l'affichage des boutons de zoom dans la webview
Étape 4 : setup de la partie App Links
Après avoir lu la page "Deep Linking with Universal and App Links", c'était la partie que je trouvais la plus difficile, mais en pratique, ce n'est pas très compliqué.
J'ai passé 5h30 sur cette partie, mais j'ai fait plusieurs erreurs.
Cette configuration se passe en 3 étapes.
Génération du fichier .well-known/assetlinks.json
La première consiste à générer le fichier le fichier dummy-website/.well-known/assetlinks.json qui est exposé par le serveur HTTP du dummy website.
Cette opération est documentée dans la partie "Create Site Association File".
Son contenu ressemble à ceci :
[
{
"relation": [
"delegate_permission/common.handle_all_urls"
],
"target": {
"namespace": "android_app",
"package_name": "$PACKAGE_NAME",
"sha256_cert_fingerprints": ["$SHA256_FINGERPRINT"]
}
}
]
Il a une fonction de sécurité, il permet d'éviter de créer des applications malveillantes qui s'ouvriraient automatiquement sur des URLs sans lien avec l'application.
Il permet de dire « l'URL de ce site web peut automatiquement ouvrir l'application $PACKAGE_NAME » qui est signée avec la clé publique $SHA256_FINGERPRINT.
J'ai implémenté le script /scripts/generate-dev-assetlinks.sh qui permet automatiquement de générer ce fichier.
Lorsque j'ai travaillé sur cette partie, j'ai fait l'erreur de générer un certificat (voir le script /scripts/generate-dev-assetlinks.sh). Or, ce n'est pas la bonne méthode en mode développement.
Par défaut, Android met à disposition un certificat de développement dans ${HOME}/.android/debug.keystore.
La commande suivante me permet d'extraire la clé publique :
SHA256_FINGERPRINT=$(keytool -list -v \ -keystore "${HOME}/.android/debug.keystore" \ -alias "androiddebugkey" \ # password par défaut -storepass "android" 2>/dev/null | grep "SHA256:" | awk '{print $2}')
Configuration de AndroidManifest.xml
Comme indiqué ici, voici les lignes que j'ai ajoutées dans /android/app/src/main/AndroidManifest.xml.tmpl :
<intent-filter android:autoVerify="true"> <action android:name="android.intent.action.VIEW" /> <category android:name="android.intent.category.DEFAULT" /> <category android:name="android.intent.category.BROWSABLE" /> <data android:scheme="https" /> <data android:host="{{ .Env.ALLOW_NAVIGATION }}" /> </intent-filter>
Petite digression sur mon usage des templates dans ce projet.
J'utilise gomplate pour générer des fichiers dynamiquement à partir de 4 templates (.tmpl) et des variables d'environnement configurées entre autres dans .envrc.
La génération des fichiers se trouve ici :
gomplate -f capacitor.config.json.tmpl -o capacitor.config.json gomplate -f android/app/build.gradle.tmpl -o android/app/build.gradle gomplate -f android/app/src/main/AndroidManifest.xml.tmpl -o android/app/src/main/AndroidManifest.xml gomplate -f android/app/src/main/strings.xml.tmpl -o android/app/src/main/res/values/strings.xml
Les principaux éléments dynamiques sont :
export APP_NAME=myapp
export PACKAGE_NAME="xyz.sklein.myapp"
export START_URL=$(cat .cloudflared_tunnel_url)
export ALLOW_NAVIGATION=$(echo "$START_URL" | sed -E 's#https://([^/]+).*#\1#')
START_URL contient l'URL publique générée par cloudflared tunnel qui change à chaque lancement du tunnel.
Support deep links via l'interception de l'événement appUrlOpen
Troisième étape de la configuration de App links.
let timeoutId = setTimeout(() => { openInWebView(process.env.START_URL); }, 200); window.Capacitor.Plugins.App.addListener('appUrlOpen', (event) => { clearTimeout(timeoutId); openInWebView(event.url); });
Cela permet d'implémenter la fonction deep links. Exemple : si l'utilisateur du smartphone clique sur l'URL https://dummysite/deep/ alors l'application va directement s'ouvrir sur la page /deep/ du dummy website.
Commandes utiles
La commande suivante permet de demander à l'OS Android de lancer une nouvelle "vérification" du fichier dummy-website/.well-known/assetlinks.json :
$ adb shell pm verify-app-links --re-verify ${PACKAGE_NAME}
Note : le fichier .cloudflared_tunnel_url contient l'URL du tunnel cloudflare qui expose le dummy website.
La commande suivante permet d'afficher la configuration actuelle App Link d'une application :
$ adb shell pm get-app-links ${PACKAGE_NAME} xyz.sklein.myapp: ID: 100ba7e3-b978-49ac-926c-8e6ec6810f5c Signatures: [AF:AE:25:7F:ED:98:49:A3:E0:23:B3:BE:92:08:84:A5:82:D1:80:AA:E0:A4:A3:D3:A0:E2:18:D6:70:05:67:ED] Domain verification state: association-pending-belt-acute.trycloudflare.com: verified
La commande suivante permet de tester le lancement de l'application à partir d'une URL passée en paramètre :
$ adb shell am start -W -a android.intent.action.VIEW -d "$(cat .cloudflared_tunnel_url)" Starting: Intent { act=android.intent.action.VIEW dat=https://sc-lo-welsh-injury.trycloudflare.com/... } Status: ok LaunchState: COLD Activity: xyz.sklein.myapp/.MainActivity TotalTime: 1258 WaitTime: 1266 Complete
Cela fonctionne aussi avec une sous-page, par exemple : "$(cat .cloudflared_tunnel_url)/deep/?query=foobar".
Dans l'émulateur, Chrome ne lance pas les App Link !
Je pense que ce piège m'a fait perdre 2 h (sur les 5 h passées sur cette implémentation) !
Si j'ouvre l'URL du dummy website dans Chrome, l'application n'est pas lancée.
Mais, si j'ouvre l'URL dans l'application qui se nomme "Google", celle accessible via la barre de recherche en bas ce ce screenshot, l'App Link est bien pris en compte.

Problème : je testais mon application seulement dans Chrome. Et la fonctionnalité App Links ne fonctionnait pas. C'est seulement quand j'ai installé l'application sur mon smartphone physique personnel que j'ai constaté que App Links fonctionnait sous "Firefox Android".
J'ai constaté aussi que sur mon smartphone, Chrome n'ouvrait aucune application sur les URLs youtube.com, reddit.com, github.com…
D'après ce que je pense avoir compris, la liste des applications qui peuvent ouvrir les App Links est listée dans la section "Settings => Apps => Default apps" :
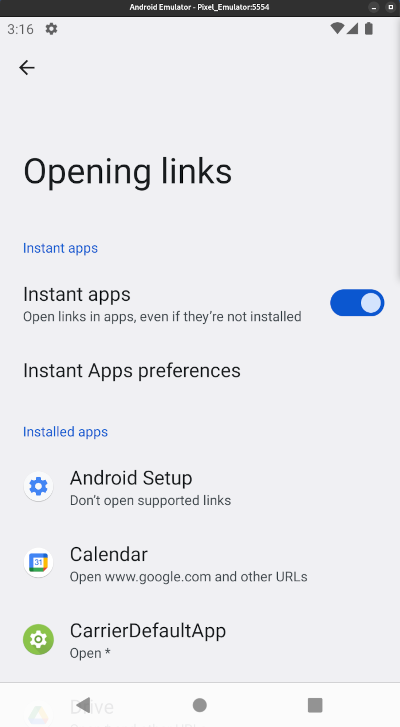
J'ai fait des expériences sur 3 différents smartphones Android d'amis et à ce jour, je n'ai pas encore compris comment cela fonctionne. J'ai l'impression que c'est lié au browser par défaut configuré, mais j'ai trouvé des exceptions.
En tout cas, ce piège m'a fait perdre beaucoup de temps !
Note finale
Pour le moment, je n'ai pas eu besoin de configurer @capacitor/app-launcher, mais je pense que cela sera utile pour permettre à l'application d'ouvrir d'autres applications à partir d'une URL.
J'ai scripté pratiquement toutes les actions de ce projet.
ChatGPT m'a bien servi tout au long de cette implémentation.
Journal du vendredi 27 décembre 2024 à 11:23
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Note de type #mémento à propos de la configuration de l'icône et du splash screen d'une application Capacitor.
J'utilise le plugin @capacitor/splash-screen.
Ce plugin offre de nombreuses options de configuration : https://capacitorjs.com/docs/apis/splash-screen#configuration.
Les paramètres de configuration du splash screen sont définis ici dans mon POC poc-capacitor.
Cela m'a pris du temps pour trouver comment modifier l'icône et le splash screen de l'application.
Cette opération est documentée sur la page suivante : "Splash Screens and Icons".
Dans poc-capacitor, j'ai documenté cette opération ici.
La commande npx capacitor-assets generate prend en entrée mon fichier logo ./assets/logo.png et génère automatiquement de nombreux fichiers assets dans les dossiers suivants :
./android/app/src/main/res/./ios/App/App/Assets.xcassets/./src/assets/
Pour plus d'informations au sujet de cette commande, je vous invite à consulter : https://github.com/ionic-team/capacitor-assets.
Journal du lundi 23 décembre 2024 à 19:39
J'ai commencé le Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram le 9 octobre.
Le 27 octobre, j'ai publié la note 2024-10-27_2109 qui contient une erreur qui m'a fait perdre 14h !
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
[ 0.0] Examining the guest ...
[ 4.5] Setting a random seed
virt-customize: warning: random seed could not be set for this type of
guest
[ 4.5] Setting the machine ID in /etc/machine-id
[ 4.5] Installing packages: qemu-guest-agent
[ 32.1] Running: systemctl enable qemu-guest-agent.service
[ 32.6] Finishing off
Je n'avais pas fait attention au message Setting the machine ID in /etc/machine-id 🙊.
Conséquence : le template Proxmox Ubuntu contenait un fichier /etc/machine-id avec un id.
Conséquence : toutes les Virtual machine que je créais sous Proxmox avaient la même valeur machine-id.
J'ai découvert que l'option 61 "Client identifier" du protocole DHCP permet de passer un client id au serveur DHCP qui sera utilisé à la place de l'adresse MAC.
Conséquence : le serveur DHCP assignait la même IP à ces Virtual machine.
J'ai pensé que le serveur DHCP de mon router BBox avait un problème. J'ai donc décidé d'installer Projet 15 - Installation et configuration de OpenWrt sur Xiaomi Mi Router 4A Gigabit pour avoir une meilleure maitrise du serveur DHCP.
Problème : j'ai fait face au même problème avec le serveur DHCP de OpenWrt.
Après quelques recherches, j'ai découvert que contrairement à virt-customize la commande virt-sysprep permet d'agir sur des images qui ont vocation à être clonées.
"Sysprep" stands for "system preparation" tool. The name comes from the Microsoft program sysprep.exe which is used to unconfigure Windows machines in preparation for cloning them.
Pour corriger le problème, j'ai remplacé cette ligne :
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Par ces deux lignes :
# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
La seconde commande permet de supprimer le fichier /etc/machine-id, ce qui corrige le problème d'attribution d'IP par le serveur DHCP.
À noter que je ne comprends pas pourquoi il est nécessaire de lancer explicitement cette seconde commande, étant donné que la commande virt-sysprep est destinée aux images de type "template". Le fichier /etc/machine-id ne devrait jamais être créé, ou tout du moins, automatiquement supprimé à la fin de chaque utilisation de virt-sysprep.
Maintenant, l'instanciation de Virtual machine fonctionne bien, elles ont des IP différentes 🙂.
Prochaine étape du Projet GH-271 :
Je souhaite arrive à effectuer un déploiement d'une Virtual instance via cli de Terraform.
Journal du samedi 21 décembre 2024 à 16:10
Je viens d'améliorer l'implémentation du moteur de recherche de mon sklein-pkm-engine.
Voici un screencast de présentation du résultat :
Le commit de changement : https://github.com/stephane-klein/sklein-pkm-engine/commit/71210703fe626bd455b2ec7774167d9a637e4972
Je suis passé de :
query_string: {
query: queryString,
default_field: "content_html"
}
à ceci :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Les fonctionnalités de recherche d'Elasticsearch sont nombreuses. Pour les parcourir, je conseille ce point d'entrée de la documentation Search in Depth.
Même après avoir fini mon implémentation de la fonction recherche, je dois avouer que je tâtonne sur le sujet. Je suis loin de maitriser le sujet.
Au départ, après lecture de ce paragraphe :
If you don’t need to support a query syntax, consider using the
matchquery. If you need the features of a query syntax, use thesimple_query_stringquery, which is less strict.
J'ai fait un refactoring de query_string vers simple_query_string (lien vers la documentation).
Mon objectif était d'arriver à implémenter la fonctionnalité Query-Time Search-as-You-Type avec de la recherche floue (fuzzy).
J'ai commencé par essayer la syntax foobar~* mais j'ai appris qu'il n'était pas possible d'utiliser ~ (fuzzy) en couplé avec * 😔 (documentation vers la syntax). Sans doute pour de bonnes raisons, liées à des problèmes de performance.
J'ai ensuite découpé ma requête en 3 conditions :
baseQuery.body.query.bool.must.push({
bool: {
should: [
{
simple_query_string: {
query: queryString,
fields: ["content_html"],
boost: 3
}
},
{
simple_query_string: {
query: queryString.split(' ').map(word => (word.length >= 3) ? `${word}*` : undefined).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
},
{
simple_query_string: {
query: queryString.split(' ').map(
word => {
if (word.length >= 5) { return `${word}~2`; }
else if (word.length >= 3) { return `${word}~1`; }
else return undefined;
}
).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
}
],
minimum_should_match: 1
}
}
Cette implémentation fonctionne, mais je rencontrais des problèmes de performance aléatoires que je n'ai pas pris le temps d'essayer de comprendre la cause.
À force de tâtonnement, j'ai fini par choisir la solution basée sur multi_match (documentation de référence) :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Documentation de référence du paramètre fuzziness : Fuzzy query.
Documentation de la valeur AUTO : Common options - Fuzziness
Malheureusement, ici aussi, je ne peux pas utiliser fuzziness avec phrase_prefix :
The fuzziness parameter cannot be used with the phrase or phrase_prefix type.
En finissant cette note, je viens de découvrir cet exemple dans la documentation.
J'ai l'impression de comprendre qu'en utilisant le tokenizer ngram je pourrais faire des Fuzzy Search sans utiliser l'option fuzziness 🤔.
J'ai commencé l'implémentation dans la branche ngram-tokenizer mais je m'arrête là pour aujourd'hui. En tout, ce weekend, j'ai passé 4h30 sur ce sujet 😮.
J'espère tester cette implémentation d'ici à quelques jours.
Je souhaite aussi essayer prochainement de migrer de Elasticsearch vers OpenSearch.
Journal du samedi 21 décembre 2024 à 14:17
Je viens de corriger dans mon sklein-pkm-engine, un problème d'expérience utilisateur que m'avait remonté Alexandre sur la page détail d'une note.
Par exemple sur la note : https://notes.sklein.xyz/2024-12-19_1709/

Le lien sur le tag dev-kit pointait vers https://notes.sklein.xyz/diaries/?tags=dev-kit. Conséquence : les Evergreen Note n'étaient pas listés dans les résultats. Ce comportement était perturbant pour l'utilisateur.
J'ai modifié l'URL sur les tags pour les faire pointer vers https://notes.sklein.xyz/search/?tags=dev-kit, page qui affiche tous types de notes.
Journal du samedi 07 décembre 2024 à 20:49
Je pense être arrivé à une solution plus ou moins satisfaisante pour le Projet 19 - "Documenter une méthode pour synchroniser un monorepo vers des multirepos qui fonctionne dans les deux sens".
Voici-ci, ci-dessous, les étapes de la démonstration qui sont détaillées dans le README.md du repository poc-git-monorepo-multirepos-sync.
- Je crée deux repositories :
frontendetbackend(multi repositories) ; - J'utilise le script tomono pour les intégrer dans un monorepo nommé
monorepo; - J'ajoute deux fichiers à la racine de
monorepo:README.mdet.mise.toml; - J'effectue des changements dans le repository
frontend, je commit ; - Je pull les changements du repository
frontendversmonorepo; - Dans
monorepo, j'effectue des changements dans le dossierfrontend/, je commit ; - J'utilise
cd frontend/; git format-patch --relative -1 HEADpour générer un patch qui contient les changements que j'ai effectués dans le dossierfrontend/; - Je vais dans le repository
frontendet j'applique les changements contenus dans ce patch avec la commandgit apply monpatch.patchou avecgit am monptach.patch.
Pour le moment, j'ai privilégié l'option git patch, parce que je souhaite suivre la méthode la plus "manuelle" que j'ai pu trouver lorsque je dois intervenir sur les repositories upstream, parce que je ne veux prendre aucun risque de perturber mes collègues avec mon initiative de monorepo.
Le repository GitHub suivant contient le résultat final du monorepo : https://github.com/stephane-klein/poc-git-monorepo-multirepos-sync-result-example/.
Est-ce que je suis satisfait du résultat de cette démo ?
La réponse est oui, bien que je ne sois pas satisfait de quelques éléments.
Par exemple, les fichiers de frontend présents dans ce commit ne sont pas dans le dossier frontend.
J'aimerais que ces titres de commits contiennent un prefix [frontend] ... et [backend].... Je pense que cela doit être possible à implémenter en modifiant le script tomono.
Est-ce que c'est pénible à utiliser ? Pour le moment, ma réponse est « je ne sais pas ».
Je vais tester cette méthode avec deux projets. Je pense écrire une note de bilan de cette expérience d'ici à quelques semaines.
Journal du mardi 03 décembre 2024 à 23:57
Suite de 2024-12-03_2213. J'ai réussi à implémenter le support Pandoc style markdown attributes dans sklein-pkm-engine.
Le package markdown-it-attrs fonctionne parfaitement bien.
Par contre, le plugin markdown-attributes semble ne pas fonctionner sur les dernières versions de Obsidian.
Journal du mardi 03 décembre 2024 à 22:13
Suite à 2024-11-13_2147, j'ai implémenté l'amélioration du rendu des "citations", voici un exemple :
Texte de la citation.
J'ai utilisé la librairie markdown-it-callouts.
Par contre, l'implémentation actuelle contient un bug. Je souhaite appliquer ce style css uniquement au lien de la source de la citation :

Pour cela, j'aimerais pouvoir spécifier en markdown une classe source sur le lien qui pointe vers la source de la citation.
J'ai trouvé markdown-it-attrs qui me permettrait d'implémenter une syntax Pandoc-style markdown attributes :
> [!quote]
>
> Texte de la citation.
>
> [source](http://example.com){.source}
Le plugin Obsidian markdown-attributes semble implémenter cette syntax.
Je souhaite tester si ce plugin fonctionne bien et si oui, je vais essayer d'intégrer markdown-it-attrs dans sklein-pkm-engine.
Journal du jeudi 21 novembre 2024 à 17:36
Dans la note 2024-11-20_1102, je disais :
Prochaine étape du Projet 17 : Setup les iOS Requirements de Capacitor sur ce serveur Apple Silicon.
C'est chose faite 🙂.
Le repository poc-capacitor contient maintenant un script ./scripts/deploy-ios-requirements.sh qui permet d'exécuter ce script de provisioning sur le serveur Scaleway Apple Silicon distant : /provisioning/_ios.sh.
Ensuite, j'ai détaillé les étapes pour :
- Uploader le projet sur le Scaleway Apple Silicon distant
- Démarrer l'émulation d'un iPhone 15
- Compiler et lancer l'application Capacitor dans l'émulateur iPhone 15
- Et visualiser l'émulateur via VNC
Tout cela est détaillé ici : https://github.com/stephane-klein/poc-capacitor/tree/f109fb23dc612f486fad0d55ba939b4679841d06?tab=readme-ov-file#launch-application-on-ios
Je teste l'offre Scaleway Apple Silicon
Dans le projet "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor" je disais :
- Essayer d'utiliser l'offre Apple Mac mini M1 de Scaleway pour builder l'app pour iOS
Voici mon retour d'expérience d'utilisation de l'offre Scaleway Apple Silicon.
Voici la liste des images MacOS disponibles :
$ scw apple-silicon os list
ID NAME LABEL IMAGE URL FAMILY IS BETA VERSION XCODE VERSION
59bf09f1-5584-469d-a0f6-55c8fee1ab81 macos-ventura-13.6 macOS Ventura 13.6 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-ventura.png Ventura false 13.6 14
e08d1e5d-b4b9-402a-9f9a-97732d17e374 macos-sonoma-14.4 macOS Sonoma 14.4 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png Sonoma false 14.4 15
7a8d85fb-781a-4212-8e47-240ec0c3d23f macos-sequoia-15.0 macOS Sequoia 15.0 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sequoia.png Sequoia true 15.0 16
Voici la liste des types de serveurs disponibles dans la zone fr-par-3 :
$ SCW_DEFAULT_ZONE="fr-par-3" scw apple-silicon server-type list
Name CPU Memory Disk Stock Minimum Lease Duration
M1-M Apple M1 (8 cores) 8.0 GB 256 GB high stock 1 days
Et la liste dans la zone fr-par-1 :
$ SCW_DEFAULT_ZONE="fr-par-1" scw apple-silicon server-type list
Name CPU Memory Disk Stock Minimum Lease Duration
M2-M Apple M2 (8 cores) 16 GB 256 GB high stock 1 days
M2-L Apple M2 Pro (10 cores) 16 GB 512 GB high stock 1 days
Je souhaite installer un serveur de type M1-M à 0,11 € HT / heure, soit 2,64 € HT / jour, 80,3 € HT / mois.
Lors de ma première tentative, j'ai essayé de créer un serveur avec la commande suivante :
$ scw apple-silicon server create name=capacitor zone=fr-par-3 "$SCW_PROJECT_ID" M1-M 7a8d85fb-781a-4212-8e47-240ec0c3d23f
Invalid argument '46ad009f-xxxxxx': arg name must only contain lowercase letters, numbers or dashes
Suite à cette erreur, j'ai créé l'issue siuvante : Reduce"scw apple-silicon server create" helper message ambiguity.
$ scw apple-silicon server create name=capacitor project-id=${SCW_PROJECT_ID} type=M1-M os-id=7a8d85fb-781a-4212-8e47-240ec0c3d23f zone=fr-par-3
Mais l'OS n'était pas trouvé, je me suis rendu compte que cette image OS n'était pas disponible dans la zone fr-par-3.
$ SCW_DEFAULT_ZONE="fr-par-3" scw apple-silicon os list
ID NAME LABEL IMAGE URL FAMILY IS BETA VERSION XCODE VERSION
59bf09f1-5584-469d-a0f6-55c8fee1ab81 macos-ventura-13.6 macOS Ventura 13.6 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-ventura.png Ventura false 13.6 14
e08d1e5d-b4b9-402a-9f9a-97732d17e374 macos-sonoma-14.4 macOS Sonoma 14.4 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png Sonoma false 14.4 15
Voici finalement la commande de création de serveur qui a fonctionné avec succès :
$ scw apple-silicon server create name=capacitor project-id=$SCW_PROJECT_ID type=M1-M os-id=e08d1e5d-b4b9-402a-9f9a-97732d17e374 zone=fr-par-3
ID bb34d8ef-6305-4104-801c-1cf1b6b0f99f
Type M1-M
Name capacitor
ProjectID 46ad009f-xxxx
OrganizationID 215d7434-xxxx
IP 51.xxx.xxx.xxx
VncURL vnc://m1:xxxx@51.xxx.xxx.121:5900
SSHUsername m1
SudoPassword xxxxxxx
Os ID e08d1e5d-b4b9-402a-9f9a-97732d17e374
Name macos-sonoma-14.4
Label macOS Sonoma 14.4
ImageURL https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png
Family Sonoma
IsBeta false
Version 14.4
XcodeVersion 15
CompatibleServerTypes:
[M1-M M2-M M2-L]
Status starting
CreatedAt now
UpdatedAt now
DeletableAt 23 hours from now
DeletionScheduled false
Zone fr-par-3
Voici le serveur créé :
$ scw apple-silicon server list
ID TYPE NAME PROJECT ID
bb34d8ef-6305-xxxxx M1-M capacitor 46ad009f-54bc-4125-xxxxxx
Le serveur est passé en ready après environ 1min.
$ scw apple-silicon server get bb34d8ef-6305-xxxxxxx
...
CompatibleServerTypes:
[M1-M M2-M M2-L]
Status ready
...
DeletableAt 23 hours from now
DeletionScheduled false
...
Je peux me connecter directement en ssh au serveur :
$ ssh m1@xxx.xxx.xx.xxx
Last login: Wed Nov 20 16:22:10 2024
m1@bb34d8ef-6305-4104-801c-1cf1b6b0f99f ~ % uname -a
Darwin bb34d8ef-6305-4104-801c-1cf1b6b0f99f 23.4.0 Darwin Kernel Version 23.4.0: Fri Mar 15 00:12:41 PDT 2024; root:xnu-10063.101.17~1/RELEASE_ARM64_T8103 arm64
Je peux aussi me connecter au serveur via VNC (lien vers la documentation à ce sujet).
Installation des dépendances sous Fedora :
$ sudo dnf install -y remmina remmina-plugins-vnc
J'utilise le client VNC nommé Remmina.
$ remmina -c vnc://m1:xxxxx@51.xxxx.xxx.xxxx:5900
Les paramètres vnc et le mot de passe de l'user m1 sont disponibles dans la sortie de :
$ scw apple-silicon server get bb34d8ef-6305-xxxxxxx -o json
{
"id": "bb34d8ef-6305-4104-xxxx-xxxxxxxxx",
...
"vnc_url": "vnc://m1:xxxx@xxx.xxx.xxx.xxx:5900",
"ssh_username": "m1",
"sudo_password": "bTgkdiVUs7yT",
...
}
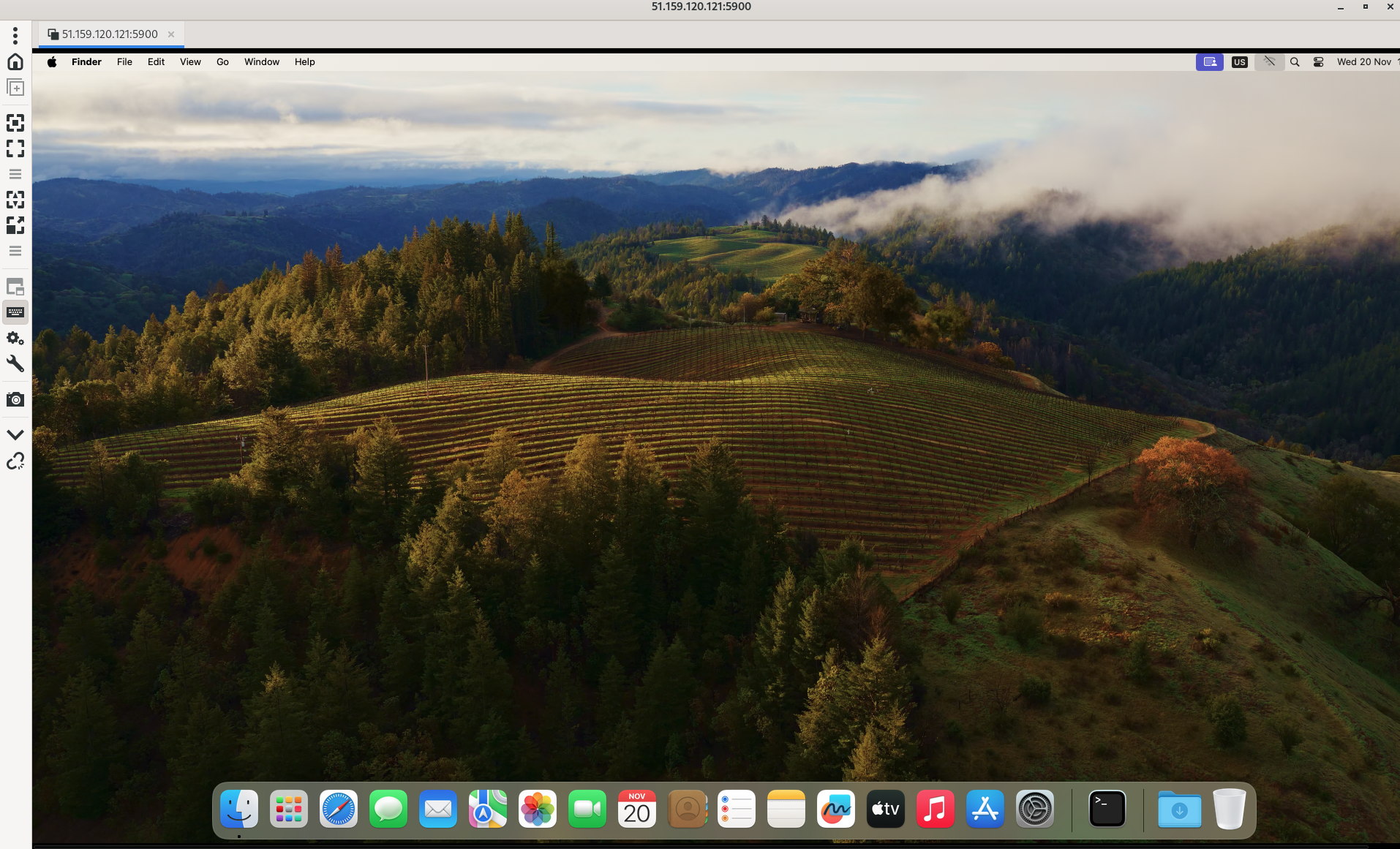
Il est possible de coller le mot de passe via la fonctionnalité « Envoyer le contenu du presse-papiers comme une saisie au clavier » de Remmina :
Attention, la réinstallation d'un serveur Apple Silicon prend au moins 45min.
J'ai implémenté des scritps de déploiement d'un Apple Silicon dans le POC : poc-capacitor.
Prochaine étape du Projet 17 : Setup les iOS Requirements de Capacitor sur ce serveur Apple Silicon.
Journal du mardi 19 novembre 2024 à 23:50
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Dans la note 2024-11-19_1029, je disais :
Pour utiliser Capacitor, j'ai besoin d'installer certains éléments.
In order to develop Android applications using Capacitor, you will need two additional dependencies:
- Android Studio
- An Android SDK installation
Je me demande si Android Studio est optionnel ou non.
La réponse est non, Android Studio n'est pas nécessaire, ni pour compiler l'application, ni pour la lancer dans un émulateur Android. Android SDK est suffisant.
J'ai utilisé le plugin Mise https://github.com/Syquel/mise-android-sdk pour installer les "Android Requirements" de Capacitor. Les instructions détaillées pour Fedora sont listées dans le README.md du repository : https://github.com/stephane-klein/poc-capacitor/tree/4238e80f84a248fdb9e5bb86c10bea8b9f0fdade.
Installation de Android Studio sous Fedora
Dans le Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor, il semble que j'ai besoin d'installer Android Studio.
J'ai exploré la méthode Asdf / Mise, mais j'ai rencontré des difficultés : 2024-11-19_1029 et 2024-11-19_1102.
J'ai ensuite constaté ici que RPM Fusion ne propose pas de package Android Studio. J'ai ensuite cherché sur Fedora COPR, mais j'ai trouvé uniquement de très vieux packages.
J'ai lu ici qu'Android Studio est disponible via Flatpak sur Flathub : https://flathub.org/apps/com.google.AndroidStudio. Je n'avais pas pensé à Flatpak 🙊.
Après réflexion, je trouve cela totalement logique que Android Studio soit distribué via Flatpak.
Voici le repository GitHub de ce package : https://github.com/flathub/com.google.AndroidStudio. Il semble être bien maintenu par Alessandro Scarozza « Senior Android Developer, Android Studio Flatpak Mantainer and old Debian Linux user ».
Le package contient la version 2024.2.1.11 d'Android Studio, j'ai vérifié, elle correspond bien à la dernière version disponible sur https://developer.android.com/studio.
Voici ce que donne l'installation :
$ flatpak install com.google.AndroidStudio
Looking for matches…
Remotes found with refs similar to ‘com.google.AndroidStudio’:
1) ‘flathub’ (system)
2) ‘flathub’ (user)
Which do you want to use (0 to abort)? [0-2]: 1
com.google.AndroidStudio permissions:
ipc network pulseaudio ssh-auth x11 devices multiarch file access [1]
dbus access [2]
[1] home
[2] com.canonical.AppMenu.Registrar, org.freedesktop.Notifications, org.freedesktop.secrets
ID Branch Op Remote Download
1. [✓] com.google.AndroidStudio.Locale stable i flathub 5,6 Ko / 57,2 Ko
2. [✓] com.google.AndroidStudio stable i flathub 1,3 Go / 1,3 Go
Installation complete.
Journal du mardi 19 novembre 2024 à 10:29
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Pour utiliser Capacitor, j'ai besoin d'installer certains éléments.
In order to develop Android applications using Capacitor, you will need two additional dependencies:
- Android Studio
- An Android SDK installation
Je me demande si Android Studio est optionnel ou non.
J'aimerais installer ces deux services avec Mise.
J'ai trouvé des Asdf plugins pour Android SDK :
- https://github.com/Syquel/mise-android-sdk (créé le 2024-03-03)
- https://github.com/huffduff/asdf-android-sdk (créé le 2024-10-10)
- https://github.com/arcticShadow/asdf-android (créé le 2024-11-13)
#JeMeDemande quel plugin utiliser, quelles sont leurs différences.
Pour essayer d'avoir une réponse, j'ai posté les issues suivantes :
- What are the differences with other existing plugins?
- What are the differences with other existing plugins?
Alexandre m'a informé qu'il a utilisé avec succès le plugin https://github.com/Syquel/mise-android-sdk/, il a même créé une issue https://github.com/Syquel/mise-android-sdk/issues/10 qui a été traité 🙂.
La suite : 2024-11-19_1102.
Journal du mercredi 13 novembre 2024 à 21:47
Actuellement, dans sklein-pkm-engine, les "citations" sont affichées comme ceci :
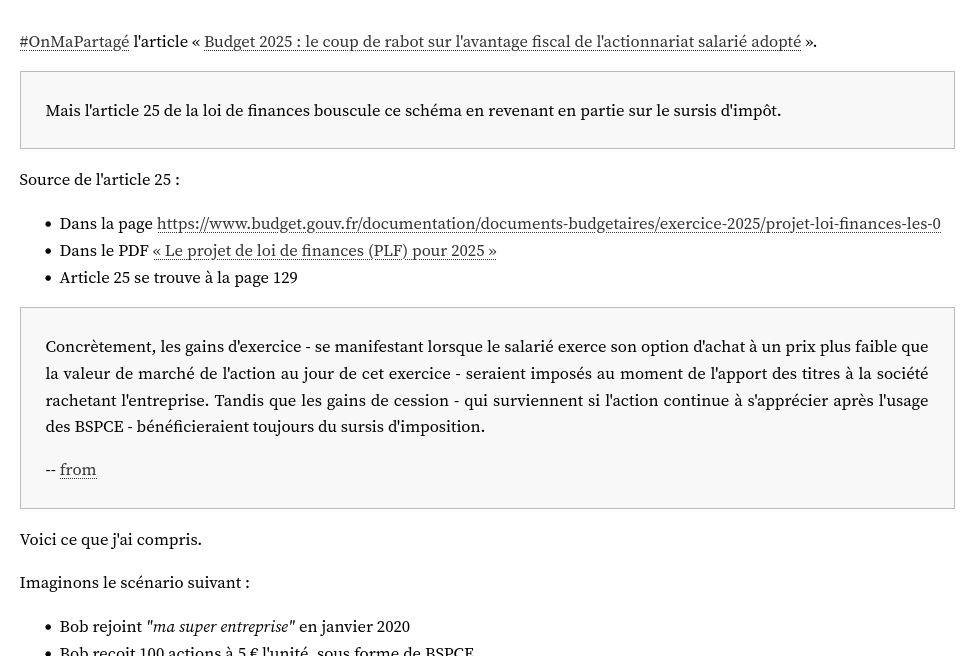
Je souhaite modifier ce rendu pour réaliser quelque chose ressemblant à ceci :

Ma source d'inspiration est le blog de gwern.net.
gwern.net utilise la syntax de quote suivante (exemple) :
<div class="epigraph">
> Beware of bugs in the above code; I have only proved it correct, not tried it.
>
> [Donald Knuth](https://www-cs-faculty.stanford.edu/~knuth/faq.html)
</div>
Étant donné que j'édite notes.sklein.xyz avec Obsidian, je ne peux pas utiliser la même syntax.
En remplacement, je pense utiliser la syntax "Callouts", par exemple :
> [!quote]
>
> Beware of bugs in the above code; I have only proved it correct, not tried it.
>
> [Donald Knuth](https://www-cs-faculty.stanford.edu/~knuth/faq.html)
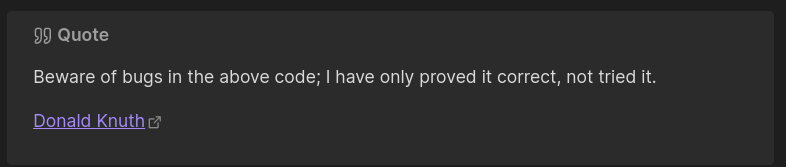
Qui donne le rendu suivant dans Obsidian :
#réflexion : j'ai l'intuition qu'à terme, une utilisation SilverBullet.mb à la place d'Obsidian m'offrirait bien plus de flexibilité.
Journal du dimanche 27 octobre 2024 à 21:09
Nouvelle #iteration du Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram.
J'ai eu des difficultés à trouver comment déployer avec Proxmox des Virtual instance basées sur Ubuntu Cloud Image.
J'ai trouvé réponse à mes questions dans cet article : "Perfect Proxmox Template with Cloud Image and Cloud Init".
Mais depuis, j'ai trouvé un meilleur tutoriel : "Linux VM Templates in Proxmox on EASY MODE using Prebuilt Cloud Init Images!".
Création d'un template Ubuntu LTS
J'ai exécuté les commandes suivantes en SSH sur mon serveur NUC i3 pour créer un template de VM Proxmox.
root@nuci3:~# apt update -y && apt install libguestfs-tools jq -y
root@nuci3:~# wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
Ancienne commande qui contient une erreur à ne pas utilisé, plus d'information dans la note 2024-12-23_1939 :
root@nuci3:~# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
root@nuci3:~# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
root@nuci3:~# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
root@nuci3:~# qm create 8000 --memory 2048 --core 2 --name ubuntu-cloud-template --net0 virtio,bridge=vmbr0
root@nuci3:~# qm disk import 8000 noble-server-cloudimg-amd64.img local-lvm
transferred 3.5 GiB of 3.5 GiB (100.00%)
transferred 3.5 GiB of 3.5 GiB (100.00%)
Successfully imported disk as 'unused0:local-lvm:vm-8000-disk-0'
root@nuci3:~# rm noble-server-cloudimg-amd64.img
root@nuci3:~# qm set 8000 --scsihw virtio-scsi-pci --scsi0 local-lvm:vm-8000-disk-0
update VM 8000: -scsi0 local-lvm:vm-8000-disk-0 -scsihw virtio-scsi-pci
root@nuci3:~# qm set 8000 --ide2 local-lvm:cloudinit
update VM 8000: -ide2 local:cloudinit
Formatting '/var/lib/vz/images/8000/vm-8000-cloudinit.qcow2', fmt=qcow2 cluster_size=65536 extended_l2=off preallocation=metadata compression_type=zlib size=4194304 lazy_refcounts=off refcount_bits=16
ide2: successfully created disk 'local:8000/vm-8000-cloudinit.qcow2,media=cdrom'
generating cloud-init ISO
(liste des paramètres cloud-init)
root@nuci3:~# qm set 8000 --ipconfig0 "ip6=auto,ip=dhcp"
root@nuci3:~# qm set 8000 --sshkeys ~/.ssh/authorized_keys
root@nuci3:~# qm set 8000 --ciuser stephane
root@nuci3:~# qm set 8000 --cipassword password # optionnel, seulement en phase de debug
root@nuci3:~# qm set 8000 --boot c --bootdisk scsi0
update VM 8000: -boot c -bootdisk scsi0
root@nuci3:~# qm set 8000 --serial0 socket --vga serial0
update VM 8000: -serial0 socket -vga serial0
root@nuci3:~# qm set 8000 --agent enabled=1
root@nuci3:~# qm set 8000 --ciupgrade 0
root@nuci3:~# qm template 8000
Renamed "vm-8000-disk-0" to "base-8000-disk-0" in volume group "pve"
Logical volume pve/base-8000-disk-0 changed.
WARNING: Combining activation change with other commands is not advised.
Création d'une Virtual Instance
root@nuci3:~# qm clone 8000 100 --name server1
root@nuci3:~# qm start 100
root@nuci3:~# qm guest cmd 100 network-get-interfaces | jq -r '.[] | select(.name == "eth0") | .["ip-addresses"][0] | .["ip-address"]'
192.168.1.64
$ ssh stephane@192.168.1.64
The authenticity of host '192.168.1.64 (192.168.1.64)' can't be established.
ED25519 key fingerprint is SHA256:OJHcY3GHOsm3I4qcsYFc6V4qePNxVS4iAOBsDjeLM7o.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '192.168.1.64' (ED25519) to the list of known hosts.
Welcome to Ubuntu 24.04.1 LTS (GNU/Linux 6.8.0-45-generic x86_64)
...
Journal du dimanche 20 octobre 2024 à 22:50
Nouvelle #iteration du Projet 14 - Script de base d'installation d'un serveur Ubuntu LTS.
Il y a quelques jours, j'ai migré de vagrant-hostmanger vers vagrant-dns. J'ai ensuite souhaité mettre en œuvre Grizzly, mais j'ai rencontré un problème.
J'ai installé une version binaire statiquement liée de Grizzly à l'aide de Mise. Dans cette version, Go ne fait pas appel à la fonction getaddrinfo pour la résolution des noms d'hôte. Au lieu de cela, Go se limite à lire les informations de configuration DNS dans /etc/resolv.conf (champ nameserver) et les entrées de /etc/hosts.
Cela signifie que les serveurs DNS gérés par systemd-resolved ne sont pas pris en compte 😭.
Pour régler ce problème, j'utilise en même temps vagrant-dns et Vagrant Host Manager : voici le commit.
J'active uniquement ici le paramètre config.hostmanager.manage_host = true et je laisse vagrant-dns résoudre les hostnames à l'intérieur des machines virtuelles et des containers Docker.
Journal du vendredi 18 octobre 2024 à 19:15
Nouvelle #iteration de Projet 14.
Pour traiter ce problème, je souhaite essayer de remplacer Vagrant Host Manager par vagrant-dns.
-- from
Résultat : j'ai migré de Vagrant Host Manager vers vagrant-dns avec succès 🙂.
Voici le commit : lien vers le commit.
Voici quelques explications de la configuration Vagrantfile.
Les lignes suivantes permettent d'utiliser la seconde IP des machines virtuelles pour les identifier (renseignés par le serveur DNS).
config.dns.ip = -> (vm, opts) do
ip = nil
vm.communicate.execute("hostname -I | cut -d ' ' -f 2") do |type, data|
ip = data.strip if type == :stdout
end
ip
end
La commande hostname retourne les deux IP de la machine virtuelle :
vagrant@server1:~$ hostname -I
10.0.2.15 192.168.56.22
La commande hostname -I | cut -d ' ' -f 2 capture la seconde IP, ici 192.168.56.22.
La configuration DNS qui retourne cette IP est consultable via :
$ vagrant dns -l
/server1.vagrant.test/ => 192.168.56.22
/server2.vagrant.test/ => 192.168.56.23
/grafana.vagrant.test/ => 192.168.56.23
/loki.vagrant.test/ => 192.168.56.23
vb.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
Cette ligne configure la machine virtuelle pour qu'elle utilise le serveur DNS de vagrant-dns.
Cela permet de résoudre les noms des autres machines virtuelles. Exemple :
vagrant@server1:~$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23 -- link: eth0
-- Information acquired via protocol DNS in 12.3ms.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
En mettant en place vagrant-dns sur ma workstation qui tourne sous Fedora, j'ai rencontré la difficulté suivante.
J'avais la configuration suivante installée :
$ cat /etc/systemd/resolved.conf.d/csd.conf
[Resolve]
DNS=10.57.40.1
Domains=~csd
Elle me permet de résoudre les hostnames des machines qui appartiennent à un réseau privé exposé via OpenVPN (voir cette note).
Voici ma configuration complète de systemd-resolved :
$ systemd-analyze cat-config systemd/resolved.conf
# /etc/systemd/resolved.conf
...
[Resolve]
...
# /etc/systemd/resolved.conf.d/1-vagrant-dns.conf
# This file is generated by vagrant-dns
[Resolve]
DNS=127.0.0.1:5300
Domains=~test
# /etc/systemd/resolved.conf.d/csd.conf
[Resolve]
DNS=10.57.40.1
Domains=~csd
Quand je lançais resolvectl query server2.vagrant.test pour la première fois après redémarrage de sudo systemctl restart systemd-resolved, tout fonctionnait correctement :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 7.5073s.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
Mais, la seconde fois, j'avais l'erreur suivante :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: Name 'server2.vagrant.test' not found
Ce problème disparait si je supprime /etc/systemd/resolved.conf.d/csd.conf.
Je n'ai pas compris pourquoi. D'après la section "Protocols and routing" de systemd-resolved, le serveur 10.57.40.1 est utilisé seulement pour les hostnames qui se terminent par .csd.
J'ai activé les logs de systemd-resolved au niveau debug avec
$ sudo resolvectl log-level debug
$ journalctl -u systemd-resolved -f
Voici le contenu des logs lors de la première exécution de resolvectl query server2.vagrant.test : https://gist.github.com/stephane-klein/506a9fc7d740dc4892e88bfc590bee98.
Voici le contenu des logs lors de la seconde exécution de resolvectl query server2.vagrant.test : https://gist.github.com/stephane-klein/956befc280ef9738bfe48cdf7f5ef930.
J'ai l'impression que la ligne 13 indique que le cache de systemd-resolved a été utilisé et qu'il n'a pas trouvé de réponse pour server2.vagrant.test. Pourquoi ? Je ne sais pas.
Ligne 13 : NXDOMAIN cache hit for server2.vagrant.test IN A
Ensuite, je supprime /etc/systemd/resolved.conf.d/csd.conf :
$ sudo rm /etc/systemd/resolved.conf.d/csd.conf
Je relance systemd-resolved et voici le contenu des logs lors de la seconde exécution de resolvectl query server2.vagrant.test : https://gist.github.com/stephane-klein/9f87050524048ecf9766f9c97b789123#file-systemd-resolved-log-L11
Je constate que cette fois, la ligne 11 contient : Cache miss for server2.vagrant.test IN A.
Pourquoi avec .csd le cache retourne NXDOMAIN et sans .csd, le cache retourne Cache miss et systemd-resolved continue son algorithme de résosultion du hostname ?
Je soupçonne systemd-resolved de stocker en cache la résolution de server2.vagrant.test par le serveur DNS 10.57.40.1. Si c'est le cas, je me demande pourquoi il fait cela alors qu'il est configuré pour les hostnames qui se terminent par .csd 🤔.
Autre problème rencontré, la latence de réponse :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 7.5073s.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
La réponse est retournée en 7 secondes, ce qui ne me semble pas normal.
J'ai découvert que je n'ai plus aucune latence si je passe le paramètre DNSStubListener à no :
$ sudo cat <<EOF > /etc/systemd/resolved.conf.d/0-vagrant-dns.conf
[Resolve]
DNSStubListener=no
EOF
$ sudo systemctl restart systemd-resolved
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 2.9ms.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
Le temps de réponse passe de 7.5s à 2.9ms. Je n'ai pas compris la signification de ma modification.
Je récapitule, pour faire fonctionner correctement vagrant-dns sur ma workstation Fedora j'ai dû :
- supprimer
/etc/systemd/resolved.conf.d/csd.conf - et paramétrer
DNSStubListeneràno
Journal du lundi 14 octobre 2024 à 11:23
J'ai commencé le projet Projet 14 - Script de base d'installation d'un serveur Ubuntu LTS.
Journal du mercredi 09 octobre 2024 à 23:52
#iteration Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram.
J'ai installé avec succès la version 8.2.2 de Proxmox sur mon Serveur NUC i3 gen 5.
J'ai copié l'image ISO de Proxmox sur une clé USB.
J'ai branché un clavier et un moniteur sur mon Serveur NUC i3 gen 5 et j'ai suivi la procédure d'installation sans rencontrer de difficulté.
Je peux me connecter au serveur via l'interface web de Proxmox ou directement via ssh.
Prochaine étape : déployer une Virtual instance Ubuntu LTS.
Journal du mercredi 02 octobre 2024 à 18:07
Nouvelle #iteration du Projet 11 - "Première version d'un moteur web PKM".
J'ai traité les tâches décrites dans ma dernière note.
- Comme me l'a signalé à plusieurs reprises Alexandre, je dois améliorer le rendu responsive sur smartphone. Jusqu'à présent, je n'ai pas encore consacré de temps à ce sujet.
- Je dois améliorer le script d'import des données dans Elasticsearch. Pour le moment, ici, je commence par supprimer toutes les données avant d'effectuer l'importation des données.
Problème : les pages ne sont plus accessibles pendant l'exécution de ce script.
J'ai enfin publié sklein-pkm-engine sur https://notes.sklein.xyz.
En mars 2024, j'écrivais :
Pour le moment, j'utilise Obsidian Quartz pour déployer https://notes.sklein.xyz.
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Début mai 2024, je suis tombé dans ce Yak!, j'y ai consacré 93 heures en tout, soit l'équivalent d'environ 15 jours de travail étalés sur 8 semaines.
J'ai enfin supprimé Obsidian Quartz
J'ai changé plusieurs fois de direction :
- j'ai exploré une implémentation basée sur Apache Age,
- ensuite pg_search,
- ensuite Typesense
- et pour finir, j'ai opté pour une implémentation basée sur Elasticsearch (voir détail dans Projet 13).
Je viens d'essayer de réaliser un screencast de présentation de la version actuelle de sklein-pkm-engine, mais le résultat de mon discours était vraiment trop déstructuré pour être publié. J'essaierai de publier un screencast prochainement.
Je viens de tenter de réaliser un screencast pour présenter la version actuelle de sklein-pkm-engine, mais mon discours était trop désorganisé pour être publié. Je souhaite enregistrer une nouvelle version prochainement.
Prochains objectifs concernant le projet sklein-pkm-engine :
- Traiter les dernières tâches que j'avais listées dans Projet 11 - "Première version d'un moteur web PKM" ;
- Dresser une liste des corrections de bug et des améliorations que je souhaite apporter à notes.sklein.xyz.
Journal du mardi 01 octobre 2024 à 11:55
Nouvelle #iteration du Projet 11 - "Première version d'un moteur web PKM".
Dans ma dernière itération du 31 août 2024, j'écrivais ceci :
Voici quelque erreur d'User Interface que je souhaite corriger.
Sur ce screenshot, les notes actuellement séparé par des
<hr />ne sont pas facilement identifiable.

Depuis, j'ai travaillé dans la branche experimentation-ui et pour le moment, j'ai le résultat suivant :

Je pense que les délimitations des notes sont maintenant mieux identifiables.
Problème User Interface que j'ai identifié : je pense que la présence d'un lien sur le titre de la note n'est pas facilement "découvrable".
Mon objectif est toujours le suivant :
Maintenant mon objectif est d'apporter le minimum de petite amélioration me permettant de remplacer l'instance notes.sklein.xyz propulsé actuellement par Obsidian Quartz par une version propulsé par
sklein-pkm-engine.-- from
Voici la liste des choses que je dois implémenter pour atteindre cet objectif.
- Comme me l'a signalé à plusieurs reprises Alexandre, je dois améliorer le rendu responsive sur smartphone. Jusqu'à présent, je n'ai pas encore consacré de temps à ce sujet.
- Je dois améliorer le script d'import des données dans Elasticsearch. Pour le moment, ici, je commence par supprimer toutes les données avant d'effectuer l'importation des données.
Problème : les pages ne sont plus accessibles pendant l'exécution de ce script.
Je pense qu'après avoir traité ces deux tâches, je pourrais abandonner Obsidian Quartz et seulement ensuite implémenter toutes les idées pour améliorer mon Personal knowledge management "viewer".
Journal du mardi 24 septembre 2024 à 17:41
gibbon-replay n'enregistre pas les sessions de Safari sous MacOS et iOS.
En analysant le problème, j'ai découvert le message d'erreur suivant :
Beacon API cannot load ... Reached maximum amount of queued data of 64Kb for keepalive requests
Je n'ai trouvé la limitation de 64Kb ni dans https://www.w3.org/TR/beacon/, ni dans https://developer.mozilla.org/en-US/docs/Web/API/Navigator/sendBeacon.
Cela semble être une spécificité de Safari.
#JaiDécouvert que posthog-js utilise fflate pour compresser les données. La compression a été ajoutée en décembre 2020, dans cette Merge Request : Compress events using fflate (gzip-js).
Ce que je compte faire pour corriger le bug que j'ai sous Safari :
- Si les données à envoyer ont une taille supérieure à 50ko, alors utiliser
fetchsinon utilisersendBeacon; - Utiliser fflate pour compresser les données.
Journal du jeudi 29 août 2024 à 13:23
Voici les nouveautés depuis ma dernière itération du Projet 11 - "Première version d'un moteur web PKM".
Ce commit contient le résultat du travail du Projet 13, c'est-à-dire le refactoring de PostgreSQL vers Elasticsearch ainsi que la page /src/routes/search qui permet à la fois d'effectuer une recherche sur le contenu des notes et un filtrage de type and sur les tags.
Une démo est visible ici https://notes.develop.sklein.xyz/

Ma Developer eXperience avec Elasticsearch est excellente. J'ai trouvé toutes les fonctionnalités dont j'avais besoin.
Je pense que mon utilisation des Fleeting Note n'est pas la bonne. Je pense que les notes que je qualifie de Fleeting Note sont en réalité des Diary notes ou Journal notes.
J'ai donc décidé de :
- [x] Renommer partout
fleeting_noteenjournal_notes
Après implémentation, j'ai réalisé que j'ai fait l'erreur de mélanger l'implémentation de le page qui affiche la liste des notes antéchronologiques et la page de recherche.
Pour être efficace, le résultat de la page recherche doit être affiché en fonction du scoring de la recherche, alors que les pages listes de notes par date de publication.
J'ai donc décidé de :
- [x] Implémenter une page
/diaries/(pour la cohérence des path en anglais, je préfère "diaries" à "journaux") qui affiche une liste de notes de type Diary notes ;- [x] Cette page doit permettre un filtrage par tags
- [x] Implémenter une page
/notes/qui affiche une liste des notes qui ne sont pas de type Diary notes, comme des Evergreen Note, Hub note…- [x] Contrairement à la page liste des Diary notes, cette page de liste ne doit pas afficher le contenu des notes, mais seulement le titre des notes ;
- [x] Je propose de classer ces titres de notes par ordre alphabétique ;
- [x] Je propose aussi de séparer ces notes par lettre,
A,B… c'est-à-dire un index alphabétique. - [x] Cette page doit permettre un filtrage par tags
- [x] Refactoring la page
/search/pour ordonner le résultat de la recherche par scoring.- [x] Cette page doit afficher le contenu des notes avec highligthing ;
- [x] Cette page doit permettre un filtrage sur les types de notes, pour le moment Diary notes et Evergreen Note.
- [x] Cette page doit permettre un filtrage par tags
Au moment où j'écris ces lignes, je ne sais pas encore comment je vais gérer les opérateurs or, (.
Pour le moment, le filtrage multi tags est effectué avec des and.
Journal du jeudi 15 août 2024 à 16:00
#iteration Projet 11 - "Première version d'un moteur web PKM".
Le nombre de tags listé sur ce screenshot est limité par un flex-wrap: wrap + height: 2em + overflow: hidden.
Problème : j'aimerais que le bouton "Afficher plus de tags…" soit affiché directement à droite du dernier tag (ici "Svelte").
Je souhaite limiter le nombre de tags affiché non pas via du css (overflow: hidden), mais via une action Svelte.
J'aimerais pouvoir utiliser cette svelte/action comme ceci :
<ul use:ItemOverflowLimiter={{itemClass: "tag"}}>
{#each data.tags as tag}
<li class="tag">
<a
href={`/search/?tags=${tag.name}`}
>{tag.name} ({tag.note_counts})</a>
</li>
{/each}
<li>Afficher plus de tags…</li>
</ul>
1 heure plus tard, j'ai réussi à atteindre mon objectif avec ce commit.
Voici le résulat 🙂 :
Voici le code de la fonction svelte/action ItemOverflowLimiter.js :
export default function ItemOverflowLimiter(node, options) {
let destroyAllNextItems = false;
let itemsToDestroy = [];
// search width of items to keep
let widthItemsToKeep = 0;
for (let item of node.children) {
if (
(options?.itemClass) &&
(!item.classList.contains(options.itemClass))
) {
widthItemsToKeep += item.clientWidth;
}
}
for (let item of node.children) {
if (destroyAllNextItems) {
if (
(!options?.itemClass) ||
(item.classList.contains(options.itemClass))
) {
itemsToDestroy.push(item);
}
} else if (
(item.offsetTop > 0) ||
(item.offsetLeft + item.clientWidth > (node.clientWidth - widthItemsToKeep))
) {
itemsToDestroy.push(item);
destroyAllNextItems = true;
}
}
for (let item of itemsToDestroy) {
item.remove();
}
}
Je trouve les svelte/action très agréable à utiliser.
Journal du jeudi 15 août 2024 à 10:48
Nouvelle #iteration de Projet 11 - "Première version d'un moteur web PKM".
En haut de cette page, j'aimerais afficher quelques tags.
En peu de la même manière que sur ce site :
Dans cette #iteration , j'affiche tous les tags, mais la liste est trop longue.
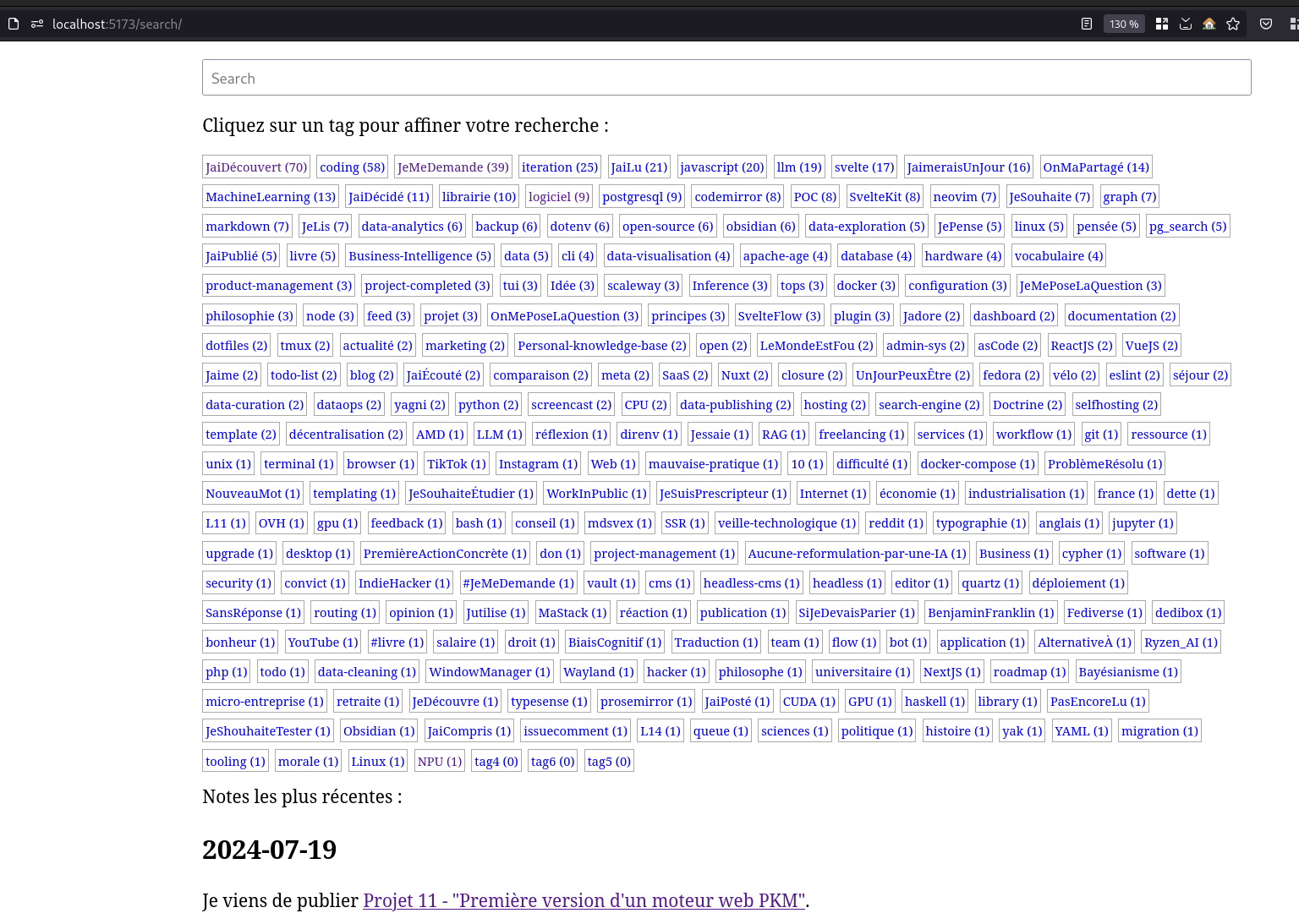
Sur ce screenshot, seules les deux premières lignes de tags sont affichées avec un fondu transparent sur la seconde ligne.
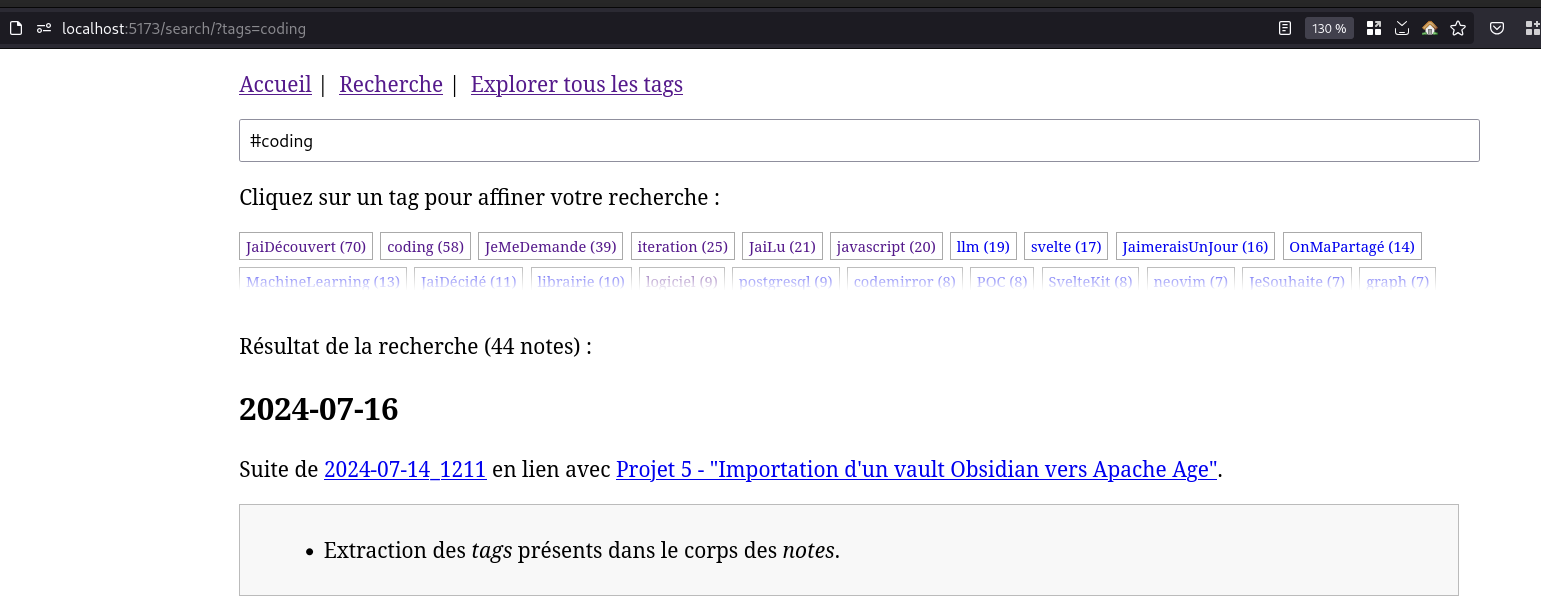
Je ne suis pas convaincu de la pertinence du fondu transparent.
Je pense que cela attire le regard d'une manière excessif sur un élément d'UI secondaire.
Je pense qu'il est préférable d'afficher une seule ligne 🤔.
Je pense ajouter à la fin d'un tags un élément UX inspiré par :

Journal du mardi 13 août 2024 à 21:32
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
J'ai enfin analysé la Merge Request qui m'a été envoyé par un ami 🤗 : https://github.com/stephane-klein/postgres-tags-model-poc/pull/9
6 mois plus tard, j'ai fini l'implémentation de la première version du "Query string javascript parser" : https://github.com/stephane-klein/postgres-tags-model-poc/commit/f0f363b78c136e8e67a38f95b5c627d874537949
Pour la coloration syntaxique des fichiers Peggy sous Neovim, j'utilise avec succès https://github.com/TheGrandmother/peggy-vim : https://github.com/stephane-klein/dotfiles/commit/20cba4ba646a0793f66f9b19788920a4ff1f1838
Journal du jeudi 08 août 2024 à 17:22
Après 11h48 de travail, j'ai enfin réussi à achever mon Projet 8 - "CodeMirror, conceal, Svelte".
Consultez de détailler dans le README du repository : https://github.com/stephane-klein/svelte-codemirror-conceal-poc.
Journal du dimanche 28 juillet 2024 à 11:59
Nouvelle #iteration du Projet 11 - "Première version d'un moteur web PKM".
Voici ce que j'ai implémenté dans la sklein-pkm-engine (lien vers la version du 28 juillet 2024, 12h00) :
- [x] Implémentation d'un script qui injecte des nanoid dans le frontmatter de toutes les notes ;
- [x] Implémentation d'un script qui injecte
type: fleeting_notedans toutes les notes qui se trouvent dans le dossier/Notes éphémères/; - [x] Implémentation d'un script qui injecte
type: evergreen_noteà toutes les notes sanstype; - [x] Implémentation d'un script qui injecte
created_at: ISO 8601sur les Fleeting Note ; - [x]
/{note_filename}/(sans.md) affiche une seule Fleeting Note ; - [x]
/liste de toutes les Fleeting Note de la plus récente à la plus ancienne ; - [x] Afficher les Fleeting Note liées aux Evergreen Note en bas des Evergreen Note ;
- [x] Rendering des
WikiLink; - [x] Rendering des
#tags; - [x] Support des fichiers binaires (image…)
J'ai déployé cette projet sur https://notes.develop.sklein.xyz/.
Voici à quoi cela ressemble :
Prochaines itérations :
- [ ] Activer l'attribue
loading="lazy"sur les images ; - [ ] Ajouter de la pagination sur
/; - [ ] Rendering markdown :
- [ ] Rendering des simples liens;
- [ ] Rendering des codes sources.
- [ ]
/tags/{tag_name}/; - [ ] Affichage des tags derrière l'heure :
 ;
; - [ ] Permettre de remplacer les tages du type
JaiDécouvertparJ'ai découvertpour simplifier la lecture.
Journal du vendredi 19 juillet 2024 à 23:16
Pour la génération de nanoid du Projet 11, j'ai choisi les paramètres suivants :
const nanoid = customAlphabet('0123456789abcdefghijklmnopqrstuvwxyz', 12);
D'après les calculs effectués sur https://zelark.github.io/nano-id-cc/, à raison de 100 nouvelles notes par jour (ce qui est irréaliste), sur 352 années, le risque de doublon d'id est de 1%, ce qui est largement acceptable 😉.
Journal du mardi 16 juillet 2024 à 09:57
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
- Extraction des tags présents dans le corps des notes.
C'est fait 🙂 : Extract tags from note bodies to create and associate them with the note
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
C'est fait 🙂 : Implementation of a markdown-to-html rendering function that takes tags and wikilinks into account
J’ai préparé une première ébauche, mais étant incertain de la manière dont je vais intégrer cette fonctionnalité avec pg_search ou Typesense, j’ai décidé de ne pas continuer à la développer pour le moment : Implementation of a function that transforms markdown content into plain text.
Journal du lundi 15 juillet 2024 à 15:25
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search.- Créer un repository GitHub nommé
obsidian-vault-to-typesense.- Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc
C'est fait 🙂.
Après cela, je souhaite implémenter dans
obsidian-vault-to-apache-age-pocles fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]).
C'est implémenté par ce commit 🙂.
Je ne suis pas satisfait de l'implémentation de cette partie et celle-ci.
Journal du dimanche 14 juillet 2024 à 12:11
Avec l'intégration de pg_search et Typesense, j'ai bien conscience de m'être un peu perdu dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search. - Créer un repository GitHub nommé
obsidian-vault-to-typesense. - Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc.
Après cela, je souhaite implémenter dans obsidian-vault-to-apache-age-poc les fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]). - Extraction des tags présents dans le corps des notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en texte brut, sans lien, destiné à être injecté dans un moteur de recherche comme pg_search ou Typesense.
Après avoir traité ces tâches, je souhaite travailler sur un moteur de rendu HTML basé sur SvelteKit, obsidian-vault-to-apache-age-poc et sans doute obsidian-vault-to-typesense.
Journal du dimanche 14 juillet 2024 à 10:26
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans 2024-07-10_0941 je disais :
je souhaite tester l'intégration de Typesense à
obsidian-vault-to-apache-age-pocen complément de pg_search.
Voici un screencast du résulat de cette implémentation de InstantSearch connecté à Typesense :
Journal du mercredi 10 juillet 2024 à 09:41
Suite à 2024-07-09_0846 (Projet 5) et suite à la publication de poc-meilisearch-blog-sveltekit en 2023, je souhaite tester l'intégration de Typesense à obsidian-vault-to-apache-age-poc en complément de pg_search.
J'ai bien conscience que Typesense fait doublon avec pg_search, mais mon objectif dans ce projet est de comparer les résultats de Typesense avec ceux de pg_search.
J'espère que cet environnement de travail me permettra d'itérer afin de répondre à cette question.
Idéalement, j'aimerais uniquement utiliser pg_search afin de mettre en œuvre un seul serveur de base de données et de bénéficier de la mise à jour automatique de l'index du moteur de recherche :
A BM25 index must be created over a table before it can be searched. This index is strongly consistent, which means that new data is immediately searchable across all connections. Once an index is created, it automatically stays in sync with the underlying table as the data changes. (from)
Journal du mardi 09 juillet 2024 à 08:46
Dans le cadre de mon travail sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément, ma tentative d'utiliser pg_search pour y intégrer un moteur de recherche, j'ai creusé le sujet InstantSearch.
Typesense permet d'utiliser InstantSearch via un adaptateur :
At Typesense, we've built an adapter (opens new window) that lets you use the same Instantsearch widgets as is, but send the queries to Typesense instead. (from)
Ici j'ai découvert des alternatives à InstantSearch :
- typesense-minibar
- autocomplete (aussi créé par Algolia)
- docsearch (aussi créé par Algolia)
#JeMeDemande comment utiliser InstantSearch ou TypeSense-Minibar avec pg_search.
N'ayant pas trouvé de réponse, #JaiPublié How can I implement InstantSearch, Typesense-Minibar or Docsearch with pg_search?.
Journal du lundi 08 juillet 2024 à 09:38
#iteration sur le Projet 10 - "Mettre en oeuvre DotTXT AI".
#JeMeDemande quelles sont les projets alternatif à Outlines 🤔
J'ai trouvé :
- https://github.com/sgl-project/sglang (from)
- https://github.com/guidance-ai/guidance (from)
- https://github.com/eth-sri/lmql (from)
- https://python.langchain.com/v0.1/docs/modules/model_io/output_parsers/types/pydantic/ (from)
- https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md (from)
Journal du dimanche 07 juillet 2024 à 15:59
#iteration sur le Projet 10 - "Mettre en oeuvre DotTXT AI".
16:00
#JeLis Coding For Structured Generation with LLMs
For those new to the blog: structured generation using Outlines (and soon .txt's products!) (from)
Je comprends que https://github.com/outlines-dev/outlines est simplement le repository du futur produit dottxt.
Je pense comprendre que structured generation est le nom officiel de l'objectif de l'outil dottxt.
16:23
#JeMeDemande comment utiliser outlines avec Replicate.com 🤔.
16:31
#JeMeDemande comment utiliser outlines avec Replicate.com 🤔.
Je pense avoir ma réponse ici.
16:47
#JaiPosté How to use outlines with Replicate.com?
J'ai aussi posé la question sur https://replicate.com/support
Journal du samedi 06 juillet 2024 à 15:15
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, 2024-06-23_1057 et 2024-06-23_2222.
Pour le projet obsidian-vault-to-apache-age-poc je souhaite créer une image Docker qui intègre les extensions pg_search et Apache Age à une image PostgreSQL.
Pour réaliser cela, je vais me baser sur ce travail préliminaire https://github.com/stephane-klein/pg_search_docker.
#JaiDécidé de créer un repository GitHub nommé apache-age-docker, qui contiendra un Dockerfile pour builder une image Docker PostgreSQL 16 qui intègre la release "Release v1.5.0 for PG16" de l'extension Postgres Apage Age.
Journal du samedi 06 juillet 2024 à 11:16
Je pense avoir terminé le projet Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Merci à Alexandre pour ses commits de GitHub Actions CI/CD et du support multi architectures publié sur Docker Hub : # stephaneklein/restic-pg_dump.
Je suis assez satisfait du résultat. Le projet a été réalisé avec soin et j'ai tenté de le simplifier au maximum.
Il reste cependant une dernière possibilité de simplification à implémenter : Suggestion : Remplacer Supercronic par Cronie.
Bilan du temps passé sur le Projet 7 :
- 8 sessions de travail entre le 5 juin et le 6 juillet 2024 ;
- Pour un total de 10h16.
Vous êtes sur la première page | [ Page suivante (21) >> ]