
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (29 notes) :
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Journal du lundi 22 septembre 2025 à 21:26
Dans le cadre du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab", j'étudie CoreOS.
Dans la page "Fedora CoreOS Release Notes stable" je vois quelques packages mis en avant :
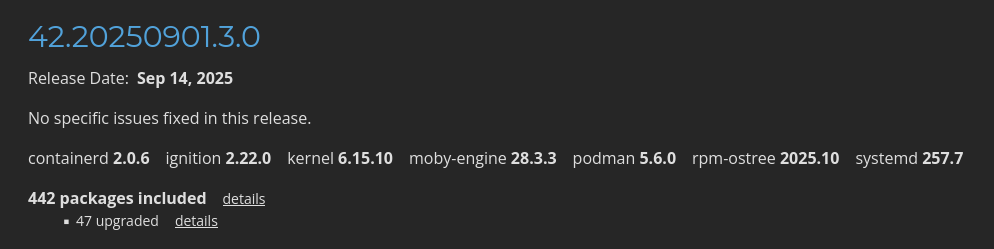
Je constate que CoreOS installe par défaut containerd, moby-engine et podman.
Information de type #mémento #mémo au sujet de containerd, moby-engine et podman.
- Kubernetes intéragie directement avec containerd.
- Depuis 2017, Docker est basé sur containerd + moby-engine. Sous Fedora, la commande
dockerest installée par le packagedocker-cli. - podman est une alternative rootless à Docker. podman n'est pas basé sur containerd, ni moby-engine.
Journal du mercredi 12 février 2025 à 15:53
Jusqu'à aujourd'hui, j'utilise la commande sleep infinity pour garder en "vie" un container Docker qui n'exécute aucun service.
Exemple de docker-compose.yml :
services:
ubuntu:
image: ubuntu
command: sleep infinity
Ce qui me permet d'entrer dans le container après son lancement en background :
$ docker compose up -d ubuntu
$ docker compose exec ubuntu bash
root@357466c4b52c:/# ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Aujourd'hui, j'ai découvert via Copilot une alternative préférable à sleep infinity :
services:
ubuntu:
image: ubuntu
command: tail -f /dev/null
Cela fonctionne de la même manière, mais semble avoir l'avantage de ne pas dépendre de la dépendance sleep 🤔.
Journal du mercredi 12 février 2025 à 15:11
Je pense comprendre que pgBackRest ne permet pas d'utiliser des INET sockets pour communiquer avec PostgreSQL.
Toutefois, je me dis que je pourrais partager le volume
PGDATAavec le sidecar pgBackRest pour lui donner accès à l'Unix Socket du Streaming Replication Protocol 🤔.
Je viens de me rappeler que pgBackRest a une seconde contrainte qui semble l'empêcher de fonctionner en Docker sidecar :
Backing up a running PostgreSQL cluster requires WAL archiving to be enabled. Note that at least one WAL segment will be created during the backup process even if no explicit writes are made to the cluster.
pg-primary:/etc/postgresql/15/demo/postgresql.conf⇒ Configure archive settings :archive_command = 'pgbackrest --stanza=demo archive-push %p' archive_mode = on max_wal_senders = 3 wal_level = replica
Cela signifie que l'exécutable pgbackrest doit être installé dans l'image Docker PostgreSQL.
Cela me pose un problème parce que mon objectif est de pouvoir utiliser un système de sauvegarde en Docker sidecar sans avoir à utiliser une image Docker PostgreSQL modifiée.
Cette contrainte ne semble pas présente avec barman qui propose 3 méthodes de backup :
La méthode postgres utilise pg_basebackup et je pense qu'elle peut fonctionner en Docker sidecar.
#JaiDécidé d'explorer cette piste.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Je découvre Colima, installation minimaliste de Docker sous MacOS
#JaiDécouvert le projet Colima : https://github.com/abiosoft/colima
Colima - container runtimes on macOS (and Linux) with minimal setup.
Support for Intel and Apple Silicon Macs, and Linux
- Simple CLI interface with sensible defaults
- Automatic Port Forwarding
- Volume mounts
- Multiple instances
- Support for multiple container runtimes
- Docker (with optional Kubernetes)
- Containerd (with optional Kubernetes)
- Incus (containers and virtual machines)
Colima est une solution minimaliste qui permet d'installer sous MacOS docker-engine sans Docker Desktop.
Thread Hacker News à ce sujet de 2023 : Colima: Container runtimes on macOS (and Linux) with minimal setup.
Méthode d'installation que je suis sous MacOS avec Brew :
$ brew install colima docker docker-compose
$ cat << EOF > ~/.docker/config.json
{
"auths": {},
"currentContext": "colima",
"cliPluginsExtraDirs": [
"/opt/homebrew/lib/docker/cli-plugins"
]
}
EOF
$ brew services start colima
Comme indiqué ici, la modification du fichier ~/.docker/config.json permet d'activer de plugin docker compose, ce qui permet d'utiliser, par exemple :
$ docker compose ps
Qui est, depuis 2020, la méthode recommandée d'utiliser docker compose sans -.
Vérification, que tout est bien installé et lancé :
$ colima status
INFO[0000] colima is running using macOS Virtualization.Framework
INFO[0000] arch: aarch64
INFO[0000] runtime: docker
INFO[0000] mountType: sshfs
INFO[0000] socket: unix:///Users/m1/.colima/default/docker.sock
$ docker info
Client: Docker Engine - Community
Version: 27.5.1
Context: colima
Debug Mode: false
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 1
Server Version: 27.4.0
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 88bf19b2105c8b17560993bee28a01ddc2f97182
runc version: v1.2.2-0-g7cb3632
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: builtin
cgroupns
Kernel Version: 6.8.0-50-generic
Operating System: Ubuntu 24.04.1 LTS
OSType: linux
Architecture: aarch64
CPUs: 2
Total Memory: 1.914GiB
Name: colima
ID: 7fd5e4bd-6430-4724-8238-e420b3f23609
Docker Root Dir: /var/lib/docker
Debug Mode: false
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
J'ai suivi de loin l'histoire de Docker Desktop qui est devenu "propriétaire". Je viens prendre le temps d'étudier un peu le sujet, et voici ce que j'ai trouvé :
August 2021: Docker Desktop for Windows and MacOS was no longer available free of charge for enterprise users. Docker ended free Docker Desktop use for larger business customers and replaced its Free Plan with a Personal Plan. Docker on Linux distributions remained unaffected.
Sur le site officiel, sur la page "docker.desktop", quand je clique sur « Choose plan » je tombe sur ceci :

Je n'ai pas tout compris, j'ai l'impression qu'il est tout de même possible d'installer et d'utiliser gratuitement Docker Desktop.
Au final, tout cela n'a pas beaucoup d'importance pour moi, je ne trouve aucune utilité à Docker Desktop, par conséquent, sous MacOS j'utilise Colima.
J'ai vu qu'il est possible d'installer Colima sous Linux, mais je ne l'utilise pas, car je n'y vois aucun intérêt pour le moment.
Journal du jeudi 19 décembre 2024 à 16:40
#JaiDécouvert le format de fichier Bake de Docker : https://docs.docker.com/build/bake/introduction/.
Je ne comprends pas bien son utilité 🤔.
La commande suivante me convient parfaitement :
$ docker build \
-f Dockerfile \
-t myapp:latest \
--build-arg foo=bar \
--no-cache \
--platform linux/amd64,linux/arm64 \
.
J'ai essayé de trouver l'issue d'origine du projet Bake, pour connaitre ses motivations, mais je n'ai pas trouvé.
Comment lancer une image Docker de l'architecture "arm64" sous Intel ?
#JeMeDemande comment lancer une image Docker pour l'architecture arm64 sur une architecture Intel sous Fedora ?
Par défaut, l'exécution de cette image Docker sous Intel avec l'option --platform linux/arm64 ne fonctionne pas :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
exec /usr/bin/bash: exec format error
J'ai consulté et suivi la documentation Docker officielle suivante : Install QEMU manually.
$ docker run --privileged --rm tonistiigi/binfmt --install all
installing: arm64 OK
installing: arm OK
installing: ppc64le OK
installing: riscv64 OK
installing: mips64le OK
installing: s390x OK
installing: mips64 OK
{
"supported": [
"linux/amd64",
"linux/arm64",
"linux/riscv64",
"linux/ppc64le",
"linux/s390x",
"linux/386",
"linux/mips64le",
"linux/mips64",
"linux/arm/v7",
"linux/arm/v6"
],
"emulators": [
"qemu-aarch64",
"qemu-arm",
"qemu-mips64",
"qemu-mips64el",
"qemu-ppc64le",
"qemu-riscv64",
"qemu-s390x"
]
}
Après cela, je constate que j'arrive à lancer avec succès une image arm64 sous processeur Intel :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
root@bf74bfb8bc35:/# graphql-engine version
Hasura GraphQL Engine (Pro Edition): v2.43.0
J'ai pris un peu de temps pour explorer le repository tonistiigi/binfmt.
Je n'ai pas compris quelle est l'interaction entre les éléments installés par cette image et docker-engine.
Je constate que cette image a été créée en 2019 par deux développeurs de Docker : CrazyMax (un Français) et Tõnis Tiigi.
Journal du lundi 09 décembre 2024 à 15:50
J'utilise la fonctionnalité Docker volume mounts dans tous mes projets depuis septembre 2015.
Généralement, sous la forme suivante :
services:
postgres:
image: postgres:17
...
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
D'après mes recherches, la fonctionnalité volumes mounts a été introduite dans la version 0.5.0 en juillet 2013.
À cette époque, je crois me souvenir que Docker permettait aussi de créer des volumes anonymes.
Je n'ai jamais apprécié les volumes anonymes, car lorsqu'un conteneur était supprimé, il devenait compliqué de retrouver le volume associé.
À cette époque, Docker était nouveau et j'avais très peur de perdre des données, par exemple, les volumes d'une instance PostgreSQL.
J'ai donc décidé qu'il était préférable de renoncer aux volumes anonymes et d'opter systématiquement pour des volume mounts.
Ensuite, peut-être en janvier 2016, Docker a introduit les named volumes, qui permettent de créer des volumes avec des noms précis, par exemple :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
name: postgres
$ docker volume ls
DRIVER VOLUME NAME
local postgres
Ce volume est physiquement stocké dans le dossier /var/lib/docker/volumes/postgres/_data.
Depuis, j'ai toujours préféré les volumes mounts aux named volumes pour les raisons pratiques suivantes :
- Travaillant souvent sur plusieurs projets, j'utilise les volume mounts pour éviter les collisions. Lorsque j'ai essayé les named volumes, une question s'est posée : quel nom attribuer aux volumes PostgreSQL ? «
postgres» ? Mais alors, quel nom donner au volume PostgreSQL dans le projet B ? Avec les volume mounts, ce problème ne se pose pas. - J'apprécie de savoir qu'en supprimant un projet avec
rm -rf ~/git/github.com/stephan-klein/foobar/, cette commande effacera non seulement l'intégralité du projet, mais également ses volumes Docker. - Avec les mounted volume, je peux facilement consulter le contenu des volumes. Je n'ai pas besoin d'utiliser
docker volume inspectpour trouver le chemin du volume.
La stratégie que j'ai choisie basée sur volumes mounts a quelques inconvénients :
- Le owner du dossier
volumes/, situé dans le répertoire du projet, estroot. Cela entraîne fréquemment des problèmes de permissions, par exemple lors de l'exécution des scripts de linter dans le dossier du projet. Pour supprimer le projet, je dois donc utilisersudo. Je précise que ce problème n'existe pas sous MacOS. Je pense que ce problème pourrait être contourné sous Linux en utilisant podman. - La commande
docker compose down -vne détruit pas les volumes.
Je suis pleinement conscient que ma méthode basée sur les volume mounts est minoritaire. En revanche, j'observe qu'une grande majorité des développeurs privilégie l'utilisation des named volumes.
Par exemple, cet été, un collègue a repris l'un de mes projets, et l'une des premières choses qu'il a faites a été de migrer ma configuration de volume mounts vers des named volumes pour résoudre un problème de permissions lié à Prettier, eslint ou Jest. En effet, la fonctionnalité ignore de ces outils ne fonctionne pas si NodeJS n'a pas les droits d'accès à un dossier du projet 😔.
Aujourd'hui, je me suis lancé dans la recherche d'une solution me permettant d'utiliser des named volumes tout en évitant les problèmes de collision entre projets.
Je pense que j'ai trouvé une solution satisfaisante 🙂.
Je l'ai décrite et testée dans le repository docker-named-volume-playground.
Ce repository d'exemple contient 2 projets distincts, nommés project_a et project_b.
J'ai instancié deux fois chacun de ces projets. Voici la liste des dossiers :
$ tree
.
├── project_a_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_a_instance_2
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_2
│ ├── docker-compose.yml
│ └── .envrc
└── README.md
Ce repository illustre l'organisation de plusieurs instances de différents projets sur la workstation du développeur.
Il ne doit pas être utilisé tel quel comme base pour un projet.
Par exemple, le "vrai" repository du projet projet_a se limiterait aux fichiers suivants : docker-compose.yml et .envrc.
Voici le contenu d'un de ces fichiers .envrc :
export PROJECT_NAME="project_a"
export INSTANCE_ID=$(pwd | shasum -a 1 | awk '{print $1}' | cut -c 1-12) # Used to define docker volume path
export COMPOSE_PROJECT_NAME=${PROJECT_NAME}_${INSTANCE_ID}
L'astuce que j'utilise est au niveau de INSTANCE_ID. Cet identifiant est généré de telle manière qu'il soit unique pour chaque instance de projet installée sur la workstation du développeur.
J'ai choisi de générer cet identifiant à partir du chemin complet vers le dossier de l'instance, je le passe dans la commande shasum et je garde les 12 premiers caractères.
J'utilise ensuite la valeur de COMPOSE_PROJECT_NAME dans le docker-compose.yml pour nommer le named volume :
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- 5432
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
volumes:
postgres:
name: ${COMPOSE_PROJECT_NAME}_postgres
Exemples de valeurs générées pour l'instance installée dans /home/stephane/git/github.com/stephane-klein/docker-named-volume-playground/project_a_instance_1 :
INSTANCE_ID=d4cfab7403e2COMPOSE_PROJECT_NAME=project_a_d4cfab7403e2- Nom du container postgresql :
project_a_d4cfab7403e2-postgres-1 - Nom du volume postgresql :
project_a_a04e7305aa09_postgres
Conclusion
Cette méthode me permet de suivre une pratique plus mainstream — utiliser les named volumes Docker — tout en évitant la collision des noms de volumes.
Je suis conscient que ce billet est un peu long pour expliquer quelque chose de simple, mais je tenais à partager l'historique de ma démarche.
Je pense que je vais dorénavant utiliser cette méthode pour tous mes nouveaux projets.
20224-12-10 11h27 : Je tiens à préciser qu'avec la configuration suivante :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
Quand le nom du volume postgres n'est pas défini, docker-compose le nomme sous la forme ${COMPOSE_PROJECT_NAME}_postgres. Si le projet est stocké dans le dossier foobar, alors le volume sera nommé foobar_postgres.
$ docker volume ls
DRIVER VOLUME NAME
local foobar_postgres
Journal du vendredi 13 septembre 2024 à 10:23
Après une mise en pratique plus approfondie, la technique présentée dans pnpm workspace et Docker build n'a pas fonctionné comme je l'attendais.
À cause de cette ligne du /demosite/pnpm-lock.yaml :
dependencies:
gibbon-replay-js:
specifier: 0.2.0
version: link:../packages/gibbon-replay-js
Pour générer un fichier pnpm-lock.yaml qui contient :
gibbon-replay-js:
specifier: 0.2.0
version: 0.2.0
j'ai créé un script nommé demosite/scripts/generate-local-pnpm-lock-file.sh qui contient :
#!/usr/bin/env bash
# This script generates a pnpm-lock.yaml file in the local directory,
# without including dependencies from workspace projects.
# For example, the version of gibbon-replay-js installed is the version
# published on npmjs.
# This point is crucial to ensure the correct operation of the docker build
# command when creating the Docker image of the demo-site project.
set -e
cd "$(dirname "$0")/../"
export npm_config_link_workspace_packages=false
export npm_config_prefer_workspace_packages=false
export npm_config_shared_workspace_lockfile=false
pnpm install --lockfile-only
Cela me permet de générer un fichier pnpm-lock.yaml qui sera présent dans le dossier /demosite/ et utilisé lors de l'exécution de Docker build.
En complément de cela, j'utilise les paramètres suivants dans /demosite/.npmrc :
link-workspace-packages=true
prefer-workspace-packages=true
shared-workspace-lockfile=true
cela permet en phase de "développement", c'est-à-dire en dehors du build Docker, d'utiliser le fichier pnpm-lock.yaml à la racine et la version locale du package packages/gibbon-replay-js.
Tout cela me paraît un peu complexe, mais pour l'instant, je n'ai pas trouvé de méthode alternative permettant de configurer un environnement de développement répondant à ces deux exigences :
- En mode développement, utiliser directement le code du
packages/gibbon-replay-jssans qu'aucune action ne soit requise de la part du développeur. - Pouvoir générer l'image Docker en une seule commande.
Je suis ouvert à toute suggestion 🙂 (contact@stephane-klein.info).
pnpm workspace et Docker build
J'écris cette note pour me souvenir pourquoi j'ai paramétré .npmrc avec les options suivantes :
link-workspace-packages=true
prefer-workspace-packages=true
shared-workspace-lockfile=false
Sans l'option link-workspace-packages=true, je devais configurer package.json comme ceci
"gibbon-replay-js": "workspace:*"
pour que /demosite utilise le package local /packages/gibbon-replay-js.
Cette contrainte me posait un problème, parce que /demosite/Dockerfile ne pouvait pas être buildé.
L'option link-workspace-packages=true permet de configurer la dépendance suivante
"gibbon-replay-js": "0.2.0"
qui pourra être installé correctement lors du build de l'image Docker.
Attention, cette version de gibbon-replay-js doit avoir préalablement été publiée sur npm registry.
Seconde option qui m'a été utile : shared-workspace-lockfile=false.
Avec cette option, pnpm install génère les fichiers /demosite/pnpm-lock.yaml et /app/pnpm-lock.yaml, fichiers indispensables pour build les images Docker.
Journal du jeudi 12 septembre 2024 à 19:14
#JaiDécouvert cet article pnpm "Working with Docker".
J'y ai découvert corepack.
Pour le moment, je ne comprends pas l'avantage d'utiliser :
FROM node:20-slim AS base
ENV PNPM_HOME="/pnpm"
ENV PATH="$PNPM_HOME:$PATH"
RUN corepack enable
plutôt que :
FROM node:20-slim AS base
RUN npm install -g pnpm@9.10
🤔
Dans ce Dockerfile j'ai tout de même utilisé cette technique pour tester.
J'ai utilisé le système de cache store de pnpm :
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-lockfile
Je me suis posé la question de partage le cache de ma workstation :
$ pnpm store path
/home/stephane/.local/share/pnpm/store/v3
Mais je ne pense pas que cela soit une bonne idée dans le cas où cette image est buildé par une CI.
Journal du dimanche 25 août 2024 à 12:44
En cherchant des informations au sujet de l'origine de la fonctionnalité compose watch, #JaiDécouvert Tilt (from).
Journal du mercredi 21 août 2024 à 10:37
Note de type snippets concernant docker compose et l'utilisation de la fonctionnalité healthcheck et depends_on.
Cette méthode évite que le service webapp démarre avant que les services postgres et redis soient prêts.
# Fichier docker-composexyml
services:
postgres:
image: postgres:16
...
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
redis:
image: redis:7
...
healthcheck:
test: ["CMD", "redis-cli", "ping"]
timeout: 10s
retries: 3
start_period: 10s
webapp:
image: ...
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
Ici la commande :
$ docker compose up -d webapp
s'assure du lancement de ses dépendances, les services postgres et redis.
De plus, si le Dockerfile du service webapp contient par exemple :
# Fichier Dockerfile
...
RUN apt update -y; apt install -y curl
...
HEALTHCHECK --interval=30s --timeout=10s --retries=3 CMD curl --fail http://localhost:3000 || exit 1
Alors, je peux lancer webapp avec :
$ docker compose up -d webapp --wait
Avec l'option --wait docker compose "rend la main" lorsque le service webapp est prêt à recevoir des requêtes.
Ressources :
Journal du samedi 17 août 2024 à 15:21
Je repository GitHub officiel des images Docker de Elasticsearch se trouve ici : https://github.com/elastic/elasticsearch/tree/main/distribution/docker.
Journal du dimanche 23 juin 2024 à 10:57
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, #JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
Je lis ici :
#JePense que c'est un synonyme de pg_search mais je n'en suis pas du tout certain.
En regardant la documetation de ParadeDB, je lis :
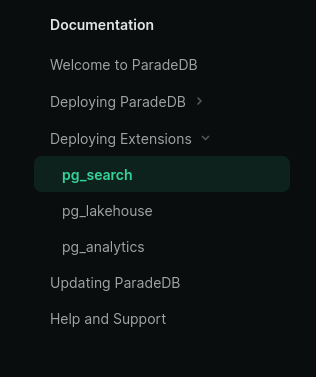
J'en conclu que ParadeDB est un projet qui regroupe plusieurs extensions PostgreSQL : pg_search, pg_lakehouse et pg_analytics.
Pour le Projet 5, je suis intéressé seulement par pg_search.
#JeMeDemande si pg_search dépend de pg_vector mais je pense que ce n'est pas le cas.
#JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
J'ai commencé par essayer de créer cette image Docker en me basant sur ce Dockerfile mais j'ai trouvé cela pas pratique. Je constaté que j'avais trop de chose à modifier.
Suite à cela, je pense que je vais essayer d'installer pg_search avec PGXN.
Lien vers l'extension pg_search sur PGXN : https://pgxn.org/dist/pg_bm25/
Sur GitHub, je n'ai trouvé aucun exemple de Dockerfile qui inclue pgxn install pg_bm25.
J'ai posté https://github.com/paradedb/paradedb/issues/1019#issuecomment-2184933674.
I've seen this PGXN extension https://pgxn.org/dist/pg_bm25/
But for the moment I can't install it:
root@631f852e2bfa:/# pgxn install pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: unpacking: /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: building extension ERROR: no Makefile found in the extension root
J'ai posté pgxn install pg_bm25 => ERROR: no Makefile found in the extension root #1287.
I think I may have found my mistake.
Should I not use
pgxn installbut should I usepgxn download:root@28769237c982:~# pgxn download pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /root/pg_bm25-9.9.9.zip@philippemnoel Can you confirm my hypothesis?
J'ai l'impression que https://pgxn.org/dist/pg_bm25/ n'est buildé que pour PostgreSQL 15.
root@4c6674286839:/# unzip pg_bm25-9.9.9.zip
Archive: pg_bm25-9.9.9.zip
creating: pg_bm25-9.9.9/
creating: pg_bm25-9.9.9/usr/
creating: pg_bm25-9.9.9/usr/lib/
creating: pg_bm25-9.9.9/usr/lib/postgresql/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/
inflating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/pg_bm25.so
creating: pg_bm25-9.9.9/usr/share/
creating: pg_bm25-9.9.9/usr/share/postgresql/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25.control
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25--9.9.9.sql
inflating: pg_bm25-9.9.9/META.json
Je pense que je dois changer de stratégie 🤔.
Je ne pensais pas rencontrer autant de difficultés pour installer cette extension 🤷♂️.
Ce matin, j'ai passé 1h30 sur ce sujet.
J'ai trouvé ce Dockerfile https://github.com/kevinhu/pgsearch/blob/48c4fee0b645fddeb7825802e5d1a4a2beb9a99b/Dockerfile#L14
Je pense pouvoir installer un package Debian présent dans la page release : https://github.com/paradedb/paradedb/releases
Le paramétrage de `search_path` PostgreSQL dans docker-compose ne fonctionne pas 🤨
Je suis en train de travailler sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et je rencontre une difficulté.
J'utilise cette configuration docker-compose.yml :
services:
postgres:
image: apache/age:PG16_latest
restart: unless-stopped
ports:
- 5432:5432
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
PGOPTIONS: "--search_path='ag_catalog,public'"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Je ne comprends pas pourquoi, j'ai l'impression que le paramètre PGOPTIONS: "--search_path=''" ne fonctionne plus.
$ ./scripts/enter-in-pg.sh
postgres=# SHOW search_path ;
search_path
-----------------
"$user", public
(1 ligne)
postgres=#
La valeur de search_path devrait être ag_catalog,public.
J'ai testé avec l'image Docker image: postgres:16, j'observe le même problème.
Je suis surpris parce que je pense me souvenir que cette syntaxe fonctionnait ici en septembre 2023 🤔.
#JeMeDemande comment corriger ce problème 🤔.
#JaiLu docker - Can't set schema_name in dockerized PostgreSQL database - Stack Overflow
09:07 : #ProblèmeRésolu par https://github.com/stephane-klein/obsidian-vault-to-apache-age-poc/commit/0b1cef3a725550269583ddb514fa3fff1932e89d
Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker"
Date de la création de cette note : 2024-06-05.
Ce projet est terminé : voir 2024-07-06_1116.
Quel est l'objectif de ce projet ?
Bien que j'aie beaucoup travaillé de décembre 2023 janvier 2024 sur le projet Implémenter un POC de pgBackRest, je souhaite mettre à jour et améliorer le repository restic-pg_dump-docker.
Quelques tâches à réaliser :
- [x] Mettre à jour tous les composants ;
- [x] Publier le
Dockerfiledestephaneklein/restic-backup-docker; - [ ] Réaliser et publier un screencast ;
- [x] Améliorer le
README.md.
Pourquoi je souhaite réaliser ce projet ?
Pourquoi continuer ce projet alors que j'ai travaillé sur pgBackRest qui semble bien mieux ?
Pour plusieurs raisons :
- Je ne peux pas installer pgBackRest dans un « sidecar container Docker » — en tout cas, je n'ai pas trouvé comment réaliser cela 🤷♂️. Je dois utiliser un container Docker PostgreSQL qui intègre pgBackRest.
- Pour le moment, je ne comprends pas très bien la taille consommée par les "WAL segments" sauvegardés dans les buckets.
- Pour le moment, je ne sais pas combien de temps prend la restauration d'un backup d'une base de données d'une taille supérieure à un test. Par exemple, combien de temps prend la restauration d'une base de données de 100 Mo 🤔.
- Je ne suis pas rassuré de devoir lancer un cron —
supercronic— lancé partini
Bien que pgBackRest permette un backup en temps "réel" et est sans doute plus rapide que "ma" méthode "restic-pg_dump", pour toutes les raisons listée ci-dessus, je pense que la méthode "restic-pg_dump" est moins complexe à mettre en place et à utiliser.
#JeMeDemande si la fonctionnalité "incremental backups" la version 17 de PostgreSQL sera une solution plus pratique que pgBackRest et la méthode "restic-pg_dump" 🤔.
Repository de ce projet :
https://github.com/stephane-klein/restic-pg_dump-docker
Je vais travailler dans la branche nommée june-2024-working-session
Define your dev environment as code. For microservice apps on Kubernetes.
Dépôt GitHub : https://github.com/abiosoft/colima
Dépôt GitHub : https://github.com/louislam/dockge
Sidecar containers are the secondary containers that run along with the main application container within the same Pod. These containers are used to enhance or to extend the functionality of the primary app container by providing additional services, or functionality such as logging, monitoring, security, or data synchronization, without directly altering the primary application code.
Site officiel : https://mobyproject.org
Site officiel : https://containerd.io
Registry Docker de Red Hat, une alternative à Docker Hub.
Voir aussi quay.
Dernière page.