
Alexandre
GitHub : https://github.com/Its-Alex/
Site perso : https://itsalex.fr/
LinkedIn : https://www.linkedin.com/in/its-alex/
Journaux liées à cette note :
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
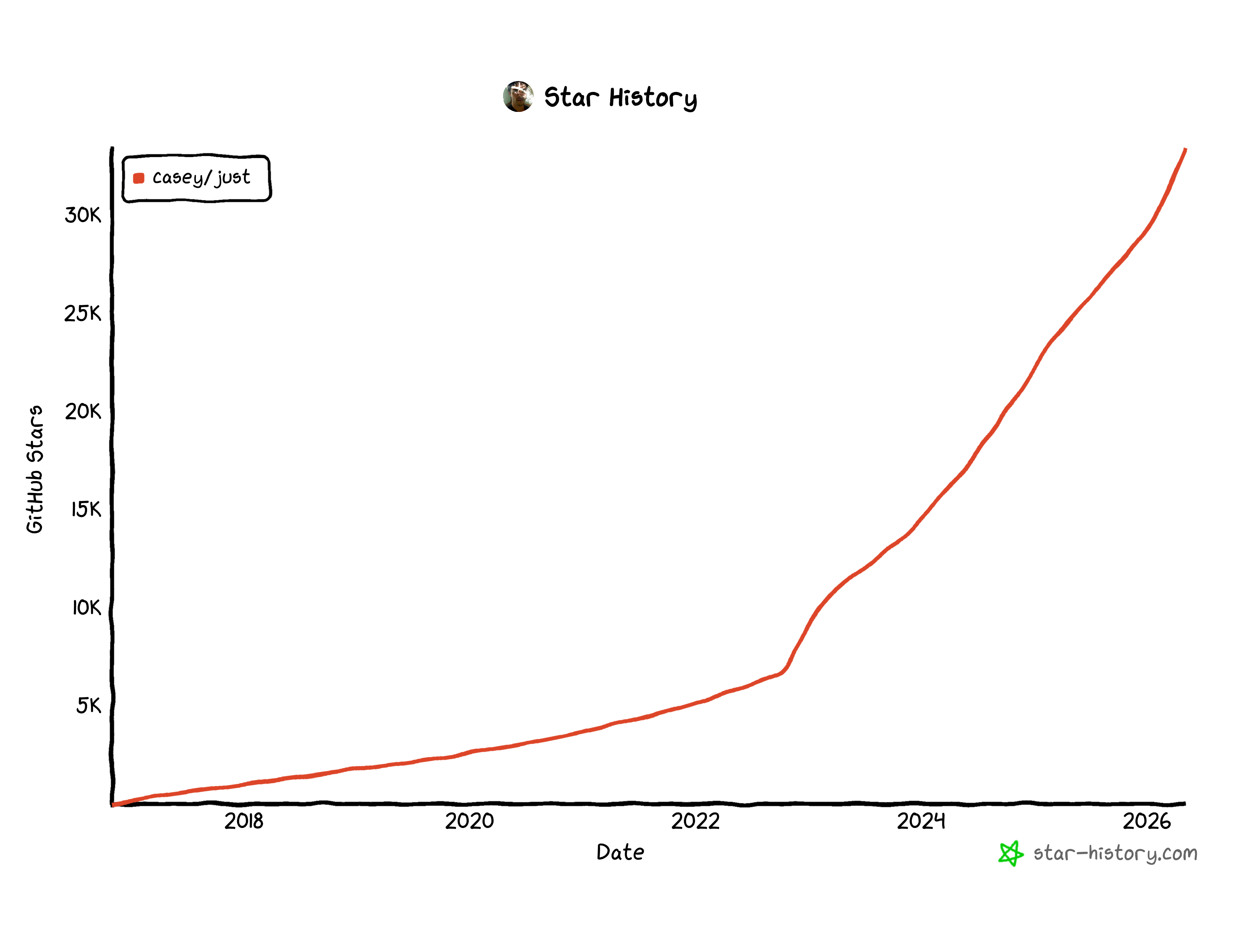
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
J'ai découvert snip et rtk et testé rtk (reduce LLM usage)
Le 13 avril 2026, j'ai découvert le projet snip :
Quelques semaines plus tard, le 29 avril, Alexandre m'a fait découvrir rtk, une alternative à snip.
rtk est un projet Rust dont le développement a commencé le 18 janvier 2026. snip, quant à lui, est un projet Golang initié par un français basé à la Réunion le 15 février 2026, directement inspiré de rtk.
Voici comment le projet snip compare les deux projets :
Design Philosophy
snip chose a fundamentally different approach to LLM token reduction: filters are data, not code. The binary is the engine, filters are YAML data files, and the two evolve independently.
rtk (Rust) snip (Go) Filter authoring Write Rust, recompile, wait for release Write YAML, drop in a folder, done Filter format Compiled into the binary Declarative YAML, engine and filters evolve independently Custom filters Fork the repo, add Rust code Create a .yamlfile in~/.config/snip/filters/Concurrency 2 OS threads Goroutines (lightweight, no thread pool) SQLite Requires CGO + C compiler Pure Go driver, static binary, no dependencies Cross-compilation Per-target C toolchain GOOS=linux GOARCH=arm64 go buildPipeline actions Built-in strategies 19 composable actions (keep, remove, regex, JSON, state machine...) Contributing Rust knowledge required YAML knowledge sufficient Both tools solve the same problem: reducing AI token costs from verbose CLI output. snip's bet is that extensibility wins. When anyone can write a filter in 5 minutes without touching Go or Rust, the filter ecosystem grows faster.
Voici à quoi ressemble un filtre dans rtk : https://github.com/rtk-ai/rtk/blob/master/src/filters/jj.toml.
Et voici l'équivalent pour snip : https://github.com/edouard-claude/snip/blob/master/filters/jj.yaml.
Je trouve la possibilité d'ajouter de nouvelles commandes à snip simplement en créant un fichier YAML intéressante, mais pour le moment je ne sais pas si j'en aurai besoin.
D'autre part, rtk est supporté par Mise : https://mise-versions.jdx.dev/tools/rtk.
Par conséquent, j'ai décidé de tester la configuration de rtk avec OpenCode. Voici le commit d'intégration à sklein-devbox : https://github.com/stephane-klein/sklein-devbox-chezmoi/commit/0fa4917ee2f31605f8d124223ec650961bf057b6.
Voici comment j'ai initialisé le plugin OpenCode pour rtk :
$ rtk init -g --opencode
OpenCode plugin installed (global).
OpenCode: /home/sklein/.config/opencode/plugins/rtk.ts
Restart OpenCode. Test with: git status
--- Telemetry ---
RTK collects anonymous usage metrics once per day to improve filters.
What: command names (not arguments), token savings, OS, version
Why: prioritize filter development for the most-used commands
Who: RTK AI Labs, contact@rtk-ai.app
Rights: disable anytime with `rtk telemetry disable`,
request erasure with `rtk telemetry forget`
Details: https://github.com/rtk-ai/rtk/blob/main/docs/TELEMETRY.md
Enable anonymous telemetry? [y/N] y
Telemetry enabled. Disable anytime: rtk telemetry disable
Et voici un exemple d'utilisation :
$ opencode run "Quels sont les derniers changements de ce projet ?"
> build · minimax-m2.5
$ rtk git log --oneline -10
0fffe04 Remove mode -x dot_config/tmux/scripts/executable_current-path.sh
832f03b Add peeble/ to Chezignore # <m-r> Reset Message
0fa4917 Setup rtk to reduces OpenCode LLM token consumption
983b77d s6-overlay migration to Pebble (#25)
1f7cbcd Start Mise eval before atuin to fix a bug
c8e6194 Remove gopass and GPG agent management since both services start automatically on first use
71e64e1 Enable Mise environment activation so Neovim can access Mise-managed tools
679f53f Purge empty mise installs/ dirs to force reinstall of incomplete tools
4c32db8 Extract init process into standalone script
8258ab9 Add infomation messages in init scripts
...
Je constate que la commande rtk git log est correctement utilisée par OpenCode.
Voici ce que m'affiche la commande rtk gain :
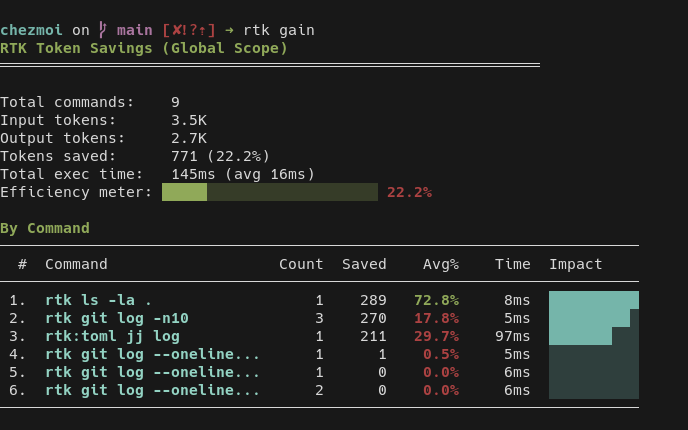
Pour le moment ceci n'est pas représentatif, car je viens de l'installer et j'ai lancé uniquement des tests fictifs.
Je compte publier une note de bilan d'ici quelques semaines pour analyser si c'est vraiment impactant ou non.
J'ai découvert le terme "test sociable"
Alexandre m'a fait découvrir aujourd'hui le terme "test sociable" versus "test solitaire", documenté ici par Martin Fowler.
Je connaissais déjà cette problématique sans en avoir le vocabulaire. Je la décrivais comme du "couplage dans le test" : un test qui couvre plusieurs unités à la fois peut échouer pour une raison indirecte, ce qui rend difficile l'identification de la vraie cause.
Je savais que la solution habituelle est d'utiliser des mocks pour isoler l'unité testée. Cela rend les tests mieux ciblés, mais aussi plus fastidieux à écrire.
Martin Fowler semble préférer les tests sociables par défaut, et ne recourt aux mocks que quand c'est nécessaire (non-déterminisme, lenteur, ressource externe instable). Je partage cette doctrine.
Alexandre m'a partagé le chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp publié en 2019.
Il sait que j'apprécie cette méthode — j'ai lu le livre vers 2021-2022 — et me l'a envoyé parce qu'il ne comprend pas bien comment je peux adhérer à cette méthode alors qu'elle semble aller à l'encontre de ce qu'on a pratiqué ensemble.
Tout d'abord, je commence par préciser que Shape Up semble mélanger les notions de issue tracker et Product Backlog (voir note "Confusion entre issue tracker et backlog, et comment gérer la masse d'issues").
Ensuite, la méthode ne dit pas "no backlog", mais "no backlog commun" :
Des listes décentralisées
On n'a pas à choisir entre un backlog encombrant et ne rien retenir du passé. Chacun peut continuer à suivre pitchs, bugs, demandes ou idées de son côté, sans liste centrale.
Le support peut maintenir une liste des demandes ou problèmes qui reviennent souvent. Le produit suit les idées qu'il espère pouvoir façonner dans un cycle futur. Les développeurs tiennent une liste de bugs qu'ils aimeraient corriger dès qu'ils en ont l'occasion. Il n'y a ni backlog unique ni liste centrale, et aucune de ces listes n'alimente directement le processus des paris.
Shape Up ne m'apparaît pas comme une méthode qui interdit de partager des listes d'issues entre sous-groupes — c'est visible quand le texte dit que « le produit suit les idées qu'il espère pouvoir façonner dans un cycle futur » et que « les développeurs tiennent une liste de bugs qu'ils aimeraient corriger dès qu'ils en ont l'occasion ».
Ce qui me semble central dans Shape Up, ce n'est probablement pas tant le rejet d'un issue tracker commun. À mon sens, le cœur de la méthode réside ici :
Quelques paris potentiels
Que fait-on à la place ? Avant chaque cycle de six semaines, on organise une table des paris (betting table) où les parties prenantes décident ce qu'elles vont faire dans le cycle suivant. À cette table, on examine les pitchs des six dernières semaines — ou ceux que quelqu'un a délibérément ressortis et défendus à nouveau.
Rien d'autre n'est sur la table. Pas de longue liste d'idées à passer en revue. Pas de temps perdu à entretenir un backlog d'anciennes idées.
Cela signifie que si une issue n'a pas de "sponsor", c'est-à-dire, personne qui la met en avant, alors elle ne sera jamais priorisée. Les pitchs sont examinés à la betting table, mais Shape Up n'a pas de process continu de revue des issues en tant que backlog.
C'est pour moi l'idée la plus importante de ce chapitre par rapport à Scrum "mainstream" et cela ne me perturbe pas, car dans ma pratique Scrum, comme je le disais dans une précédente note, une issue sans sponsor n'a pratiquement aucune chance d'être sélectionnée lors d'un Sprint Planning :
Le triage régulier des issues (fermer et prioriser) est un travail laborieux, extrêmement difficile à maintenir dans la durée dès lors qu'un issue tracker contient beaucoup d'issues. Si je peux témoigner d'une chose, c'est que je n'ai probablement jamais réussi à le faire, ni vu quelqu'un y parvenir.
Imaginons un bug remonté il y a 8 mois sur l'export PDF.
- Scénario Scrum classique : le bug traîne dans le backlog, priorité "moyenne". À chaque Sprint Planning, le Product Owner fait défiler la liste, le voit, se dit "pas critique cette fois", et le repousse. Le bug survit parce qu'il est dans le système, pas parce qu'il est défendu.
- Scénario Shape Up : le bug n'existe nulle part dans un backlog central. Si un développeur pense qu'il vaut la peine d'y consacrer un cycle, il doit le re-pitcher activement à la prochaine betting table. Si personne ne le fait, le bug disparaît du radar — pas par décision active de le fermer, mais par absence de sponsor.
Dans ma pratique de Scrum, j'intègre déjà un betting table lors du Sprint Planning, et seules les issues proposées au sprint par un sponsor sont étudiées, par conséquent, cela me semble assez proche de ce que propose Shape Up.
Je préfère Shape Up à Scrum sur ce point précis de la betting table : il me semble que cette approche est plus honnête et reflète probablement mieux ce qui se passe réellement sur le terrain.
J'ai découvert le terme « Architecture à médaillon » — un concept DataOps
Alexandre m'a fait découvrir, via cet article, le terme « Architecture à médaillon » — un concept que je pratiquais déjà sans savoir le nommer.
Journal du vendredi 07 novembre 2025 à 11:59
Alexandre m'a partagé l'article Wikipedia "Lavarand" :
Lavarand est un générateur de nombres aléatoires matériel créé par l'entreprise américaine Silicon Graphics.
Plus concrètement, il s'agit d'un dispositif utilisant des lampes à lave ce qui créé des motifs aléatoires, motifs qui sont photographiés afin d'en extraire des données pour alimenter un générateur de nombres pseudo-aléatoires.
Depuis 2017, l'entreprise américaine cloudflare maintient un système similaire de lampes à lave pour sécuriser le trafic Internet transitant par ses serveurs. Le mur de lampes à lave est accessible au grand public et l'entreprise incite les personnes extérieures à se placer devant pour créer de nouvelles variables alétoires. Les locaux de Londres et de Singapour utilisent des systèmes différents : respectivement des pendules et un compteur Geiger.

Je suis impressionné par cette technique, je la trouve très élégante.
Je me souviens avoir été confronté à ce problème de nombre aléatoire quand j'ai essayé, vers 1995, de programmer un effet Doom Fire en assembleur (époque avant l'accès à Internet).
Je m'étais cassé les dents pour obtenir un effet "aléatoire", c'était un vrai casse-tête !
Je viens de consulter la page "List of random number generators", je suis émerveillé par toutes ces techniques.
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
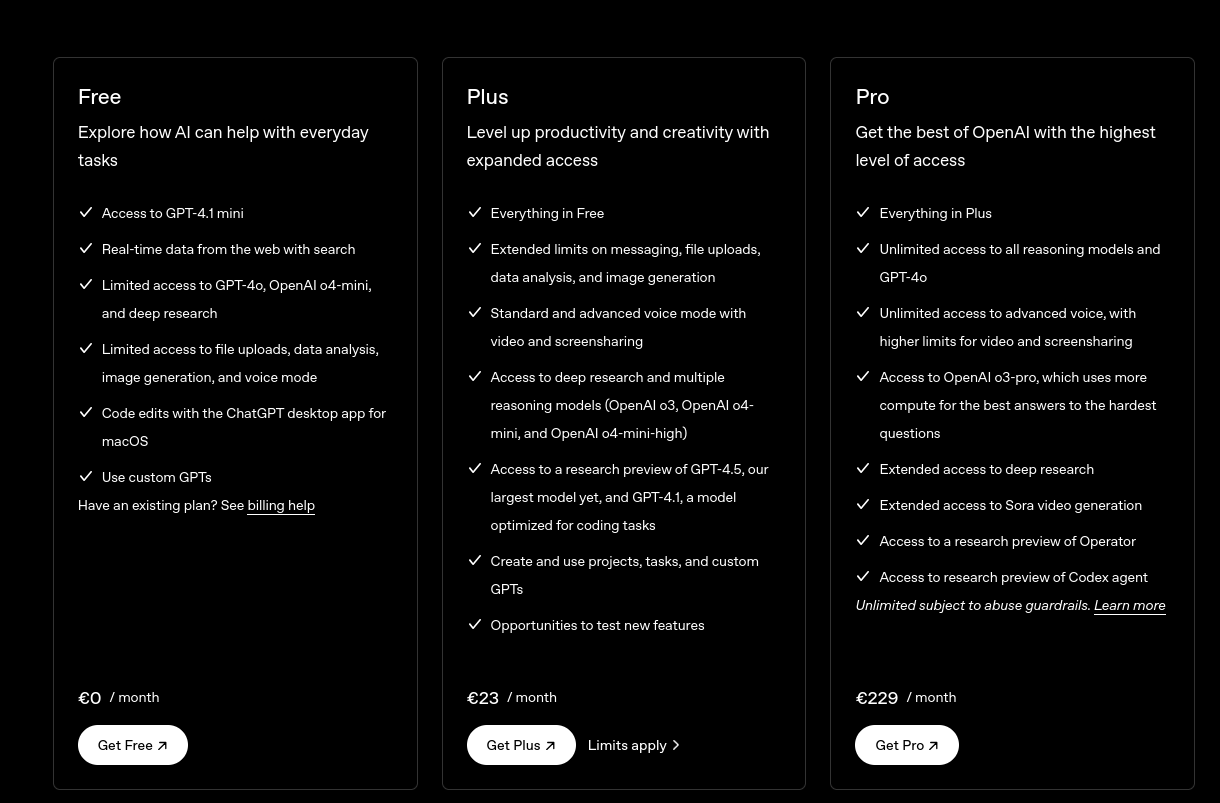
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
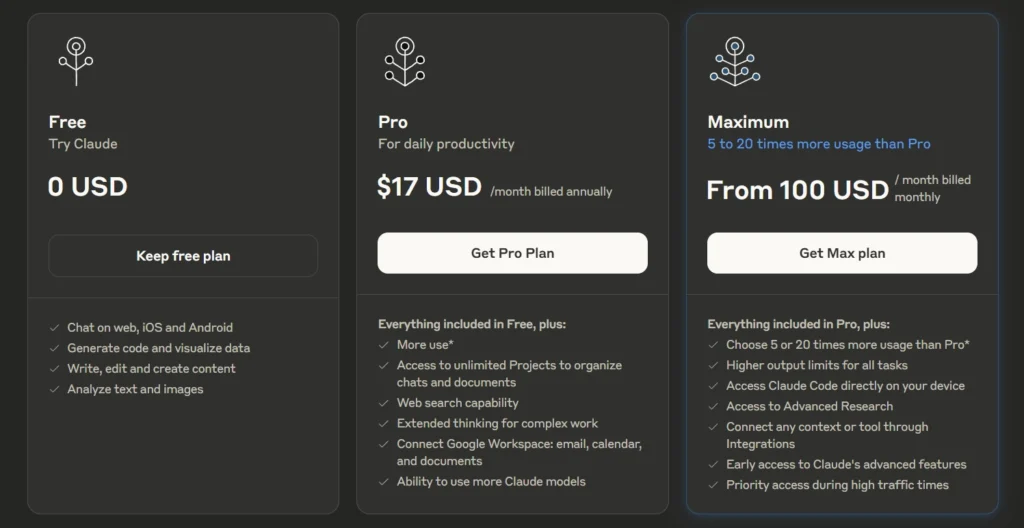
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
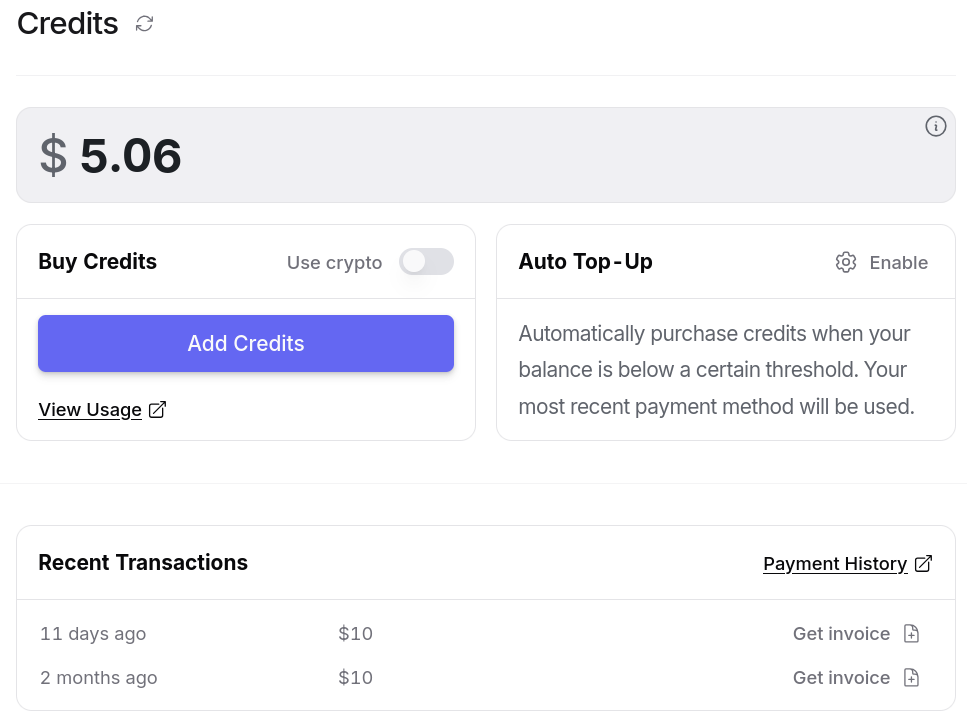
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
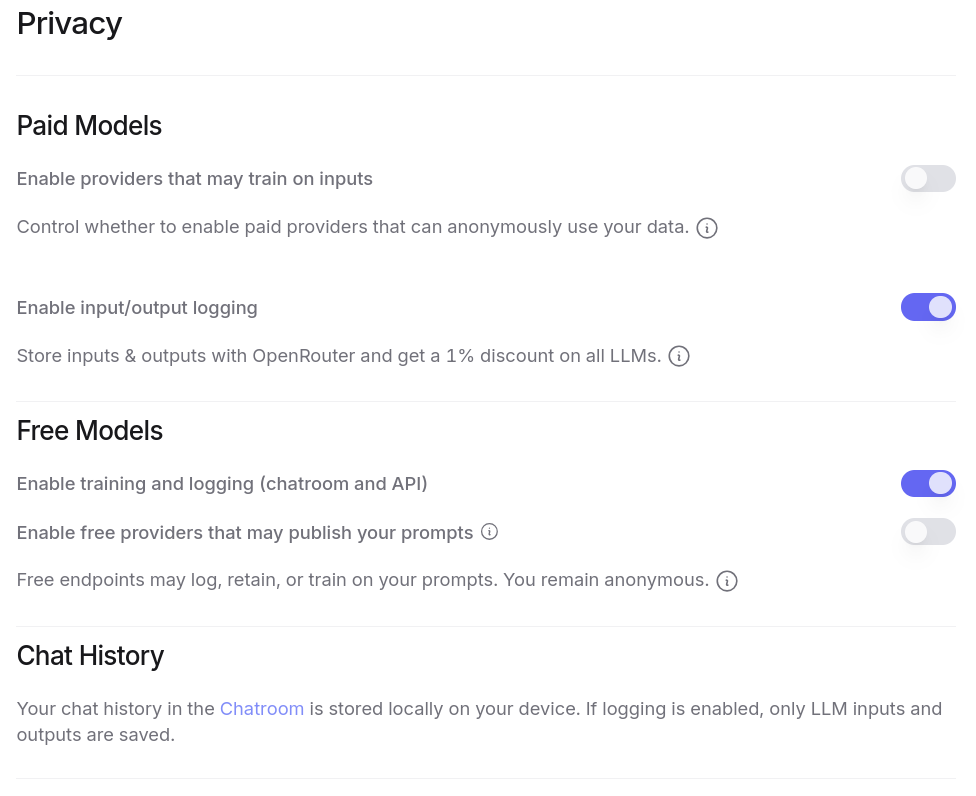
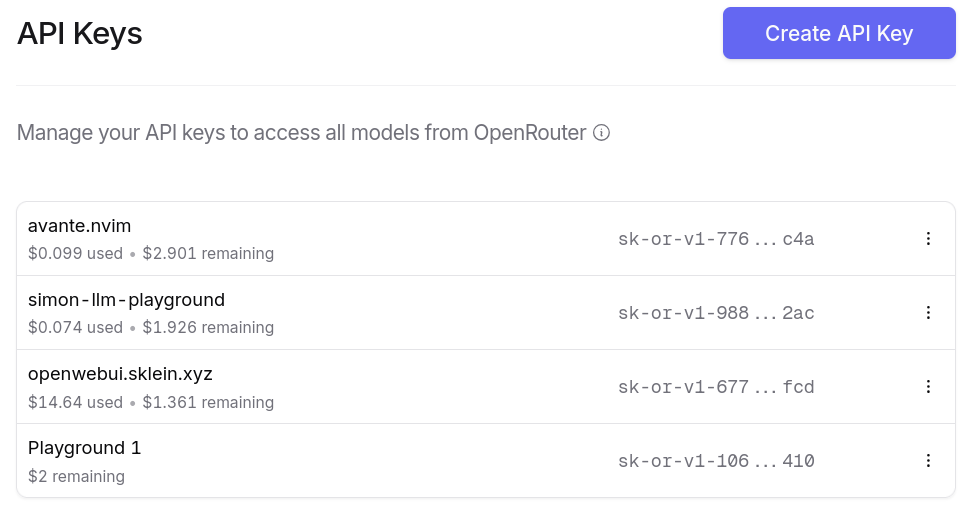
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
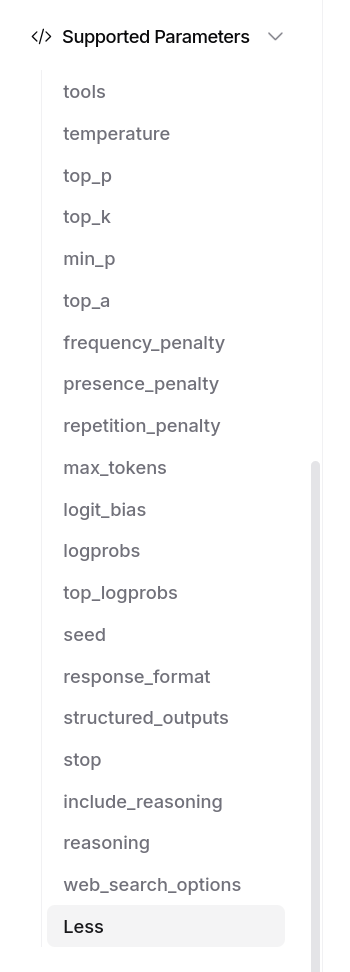
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
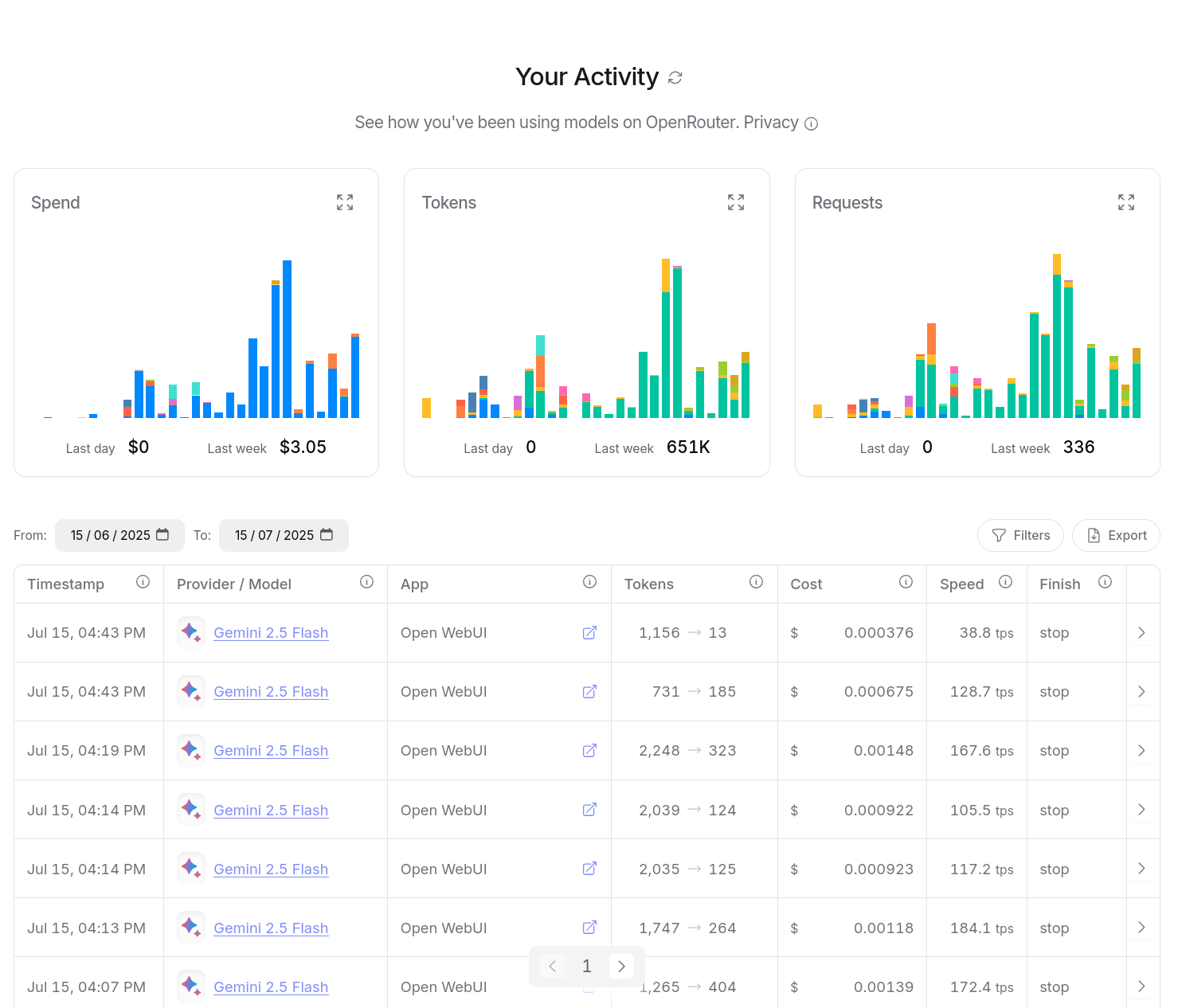
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Journal du mercredi 25 juin 2025 à 12:25
Alexandre m'a partagé le projet de keyboard layout QWERTY-Lafayette (https://qwerty-lafayette.org/).
Je ne connaissais pas ce projet, je découvre que la première version est sortie en 2010, soit 1 an après que j'ai commencé à utiliser le keyboard layout Bépo.
Je crois savoir que le projet de keyboard layout francophone "à la mode" ces dernières années est Ergo L.
J'aimerais bien migrer de Bépo à Ergo L, mais j'ai l'impression qu'à 46 ans, l'effort serait trop important pour moi. Peut-être que je m'amuserai à faire cette transition quand je serai à la retraite, c'est-à-dire vers 2044 😱.
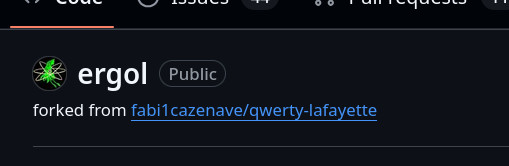
En analysant le dépôt GitHub ErgoL, j'ai découvert qu'Ergo L semble être un fork de QWERTY-Lafayette.
J'ai lu le très bon billet d'Athoune sur Kloset, moteur de stockage de backup de Plakar
Il y a un an, Alexandre m'avait fait découvrir Kopia : Je découvre Kopia, une alternative à Restic.
Ma conclusion était :
Ma doctrine pour le moment : je vais rester sur restic.
En septembre 2024, j'ai découvert rustic, un clone de restic recodé en Rust. Pour le moment, je n'ai aucun avis sur rustic.
Il y a quelques semaines, Athoune m'a fait découvrir Plakar, mais je n'avais pas encore pris le temps d'étudier ce que cet outil de backup apportait de plus que restic que j'ai l'habitude d'utiliser.
Depuis, Athoune a eu la bonne idée d'écrire un article très détaillé sur Plakar, enfin, surtout son moteur de stockage avant-gardiste nommé Kloset : "Kloset sur la table de dissection" (au minimum 30 minutes de lecture).
Ce que je retiens, c'est que Kloset propose un système de déduplication plus performant que par exemple celui de restic qui est basé sur Rabin Fingerprints :
For creating a backup, restic scans the source directory for all files, sub-directories and other entries. The data from each file is split into variable length Blobs cut at offsets defined by a sliding window of 64 bytes. The implementation uses Rabin Fingerprints for implementing this Content Defined Chunking (CDC). An irreducible polynomial is selected at random and saved in the file config when a repository is initialized, so that watermark attacks are much harder.
Files smaller than 512 KiB are not split, Blobs are of 512 KiB to 8 MiB in size. The implementation aims for 1 MiB Blob size on average.
For modified files, only modified Blobs have to be saved in a subsequent backup. This even works if bytes are inserted or removed at arbitrary positions within the file.
Au moment où j'écris ces lignes, je n'ai aucune idée des différences ou des points communs entre l'algorithme Rolling hash dont parle l'article et Rabin Fingerprints qu'utilise restic.
Chose suprernante, je trouve très peu de citations de Plakar ou kloset sur Hacker News ou Lobster :
- Recherche avec "Plakar"
- Hacker News
- dans les stories
- Mars 2021 : March 2021: backups with Plakar – poolp.org : 0 commentaire
- Octobre 2024 : Open source distributed, versioned backups with encryption and deduplication : 0 commentaires
- Mars 2025 : CDC Attack Mitigation in Plakar : 0 commentaires
- dans les commentaires
- dans les stories
- Lobsters => rien
- Hacker News
- Recherche avec "Kloset"
- Hacker News :
- Lobsters => rien
Je tiens à remercier Athoune pour l'écriture, qui m'a permis de découvrir de nombreuses choses 🤗.
Alexandre m'a partagé le projet LocalAI (https://localai.io/).
Ce projet a été mentionné une fois sur Lobster dans un article intitulé Everything I’ve learned so far about running local LLMs, et quatre fois sur Hacker News (recherche pour "localai.io"), mais avec très peu de commentaires.
C’est sans doute pourquoi je n'ai jamais remarqué ce projet auparavant.
Pourtant, il ne s’agit pas d’un projet récent : son développement a débuté en mars 2023.
J'ai l'impression que LocalAI propose à la fois des interfaces web comme Open WebUI, mais qu'il est aussi une sorte de "wrapper" au-dessus de nombreux Inference Engines comme l'illustre cette longue liste.
Pour le moment, j'ai vraiment des difficultés à comprendre son positionnement dans l'écosystème.
LocalAI versus vLLM ou Ollama ? LocalAI versus Open WebUI ?, etc.
Je vais garder ce projet dans mon radar.