
JSON
Journaux liées à cette note :
J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR
Introduction
Après trois ans à repousser ce projet, je me suis enfin lancé en janvier 2026 dans la création de paquets RPM pour Fedora COPR.
J'ai créé et publié les packages aichat-git (repository) et text-to-audio (repository). L'expérience a été beaucoup plus simple et rapide que je le pensais. Les agents IA simplifient certes ce genre de tâche, mais même sans eux, le code reste plutôt minimaliste.
Pourquoi est-ce que je me suis intéressé à ce sujet ? Au départ, c'était pour distribuer qemu-compose sous forme de package RPM (voir issue).
Pour bien maîtriser ces opérations, la semaine dernière, je suis reparti de zéro et j'ai implémenté et publié le playground : fedora-rpm-copr-playground. Voici les objectifs de ce playground :
- Générer un package pour distribuer un simple script Bash qui affiche un "Hello world" (dans la branche
bash). - Générer un package pour distribuer une application Golang qui affiche un "Hello world" (dans la branche
golang)
Pour chacun de ces packages, j'ai testé trois méthodes de build :
- build du package RPM 100% local
- build du package SRPM en local, puis upload sur Fedora COPR qui génère les RPM pour plusieurs plateformes et architectures (x86_64, aarch64, etc.)
- une méthode basée à 100% sur Fedora COPR à partir des sources d'un dépôt GitHub, déclenchée automatiquement par un script GitHub Actions
Cette note documente ce playground et rassemble les difficultés que j'ai rencontrées. Le README.md reste consultable si vous préférez suivre un exemple pas à pas.
Le fichier .spec
Le point central pour créer un package RPM est le fichier .spec /rpm/hello-bash.spec :
#
Name: hello-bash
Version: 1.0.7
Release: 1%{?dist}
Summary: A simple Hello World bash script
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: hello-bash
BuildArch: noarch
%description
A simple "Hello World" Bash script packaged as an RPM for Fedora COPR.
%prep
# Nothing to prepare, source is ready
%build
# Nothing to build, it's a bash script
%install
mkdir -p %{buildroot}/%{_bindir}
cp %{SOURCE0} %{buildroot}/%{_bindir}/hello-bash
chmod 755 %{buildroot}/%{_bindir}/hello-bash
%files
%{_bindir}/hello-bash
%changelog
* Thu Mar 19 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les lignes importantes dans ce fichier :
BuildArch: noarch, étant donnée que c'est un simple script, ce package n'est pas dépendant de l'architecture (processeur).- La section
%install - La section
%files
La syntaxe du format .spec peut sembler étrange en 2026. Elle date de 1995 — avant même l'existence de YAML (2001) et JSON (1999). Cette ancienneté explique les %... et %{...} qui peuvent paraitre cryptiques aujourd'hui.
Historiquement, le champ Source0 pointe vers une archive (généralement un tar.gz), contenant les sources du projet. Pour des cas simples, comme ici avec le script Bash, Source0 peut directement référencer le fichier source.
J'ai aussi implémenté une variante bash-multifiles dans le playground, pour tester le packaging de plusieurs scripts accompagnés d'un fichier de documentation. J'y indique les fichiers via Source0:, Source1:, Source2:, puis je les copie dans %install avec %{SOURCE0}, %{SOURCE1}, %{SOURCE2}. Cela fonctionne correctement, bien qu'au-delà de trois ou quatre fichiers, je pense qu'il soit probablement plus pratique d'utiliser une archive.
Build local du package RPM
Le script /build.sh suivant permet de générer un package RPM :
#!/bin/bash
set -e
TOPDIR="$(pwd)/rpmbuild"
mkdir -p "$TOPDIR"/{BUILD,RPMS,SRPMS,SOURCES,SPECS}
echo "Copying source to SOURCES..."
cp hello-bash "$TOPDIR/SOURCES/"
echo "Building RPM..."
rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec
echo ""
echo "Build complete!"
echo "RPM: $TOPDIR/RPMS/noarch/"
Il commence par préparer la structure de dossier suivante :
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
├── SPECS
└── SRPMS
Ensuite les fichiers à packager sont copiés dans rpmbuild/SOURCES
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
Pour finir, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec génère à la fois le package SRPM (source RPM) et le RPM binaire. L'option -ba signifie "build all". Pour générer uniquement le SRPM, il faudrait utiliser -bs (build source). Ici, comme le package contient un script Bash, il est de type noarch :
/rpmbuild/
├── BUILD
├── RPMS
│ └── noarch
│ └── hello-bash-1.0.7-1.fc42.noarch.rpm
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
└── hello-bash-1.0.7-1.fc42.src.rpm
Publication sur Fedora COPR
Le playground contient un second script qui permet de publier le package sur Fedora COPR, ce qui permet de rendre accessible publiquement son package.
Voici comment cette méthode fonctionne. Tout d'abord, il faut créer un compte et un projet sur Fedora COPR. Dans le playground, j'ai implémenté le script init-copr-project.sh basé sur copr-cli, qui me permet d'automatiser la création du projet (paradigme GitOps).
$ copr-cli create "hello-bash" \
--description "A simple Hello World Bash script packaged as an RPM (auto-build on tags)" \
--chroot fedora-42-x86_64 \
--chroot fedora-43-x86_64 \
--chroot fedora-44-x86_64
Dans cet exemple, je demande à COPR de builder les packages du projet pour les distributions fedora-42-x86_64, fedora-43-x86_64, fedora-44-x86_64.
Après avoir configuré le projet COPR, je lance le script /build-copr.sh qui exécute :
copr-cli build "hello-bash" /rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
Le premier paramètre "hello-bash" est le nom du projet et le second est le package source SRPM préalablement construit localement par le script /build.sh.
Voici ce que donne l'exécution de ./build-copr.sh côté cli :
$ ./build-copr.sh
...
Build complete!
RPM: /home/stephane/git/github.com/stephane-klein/fedora-rpm-copr-playground/.worktree/bash/rpmbuild/RPMS/noarch/
Uploading package ./rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
|################################| 8.5 kB 47.1 kB/s eta 0:00:00
Build was added to hello-bash:
https://copr.fedorainfracloud.org/coprs/build/10252699
Created builds: 10252699
Watching build(s): (this may be safely interrupted)
08:59:15 Build 10252699: pending
08:59:45 Build 10252699: running
09:00:15 Build 10252699: starting
09:00:46 Build 10252699: running
Voici ce qui est visible sur l'interface web de COPR, https://copr.fedorainfracloud.org/coprs/stephaneklein/hello-bash/builds/ :
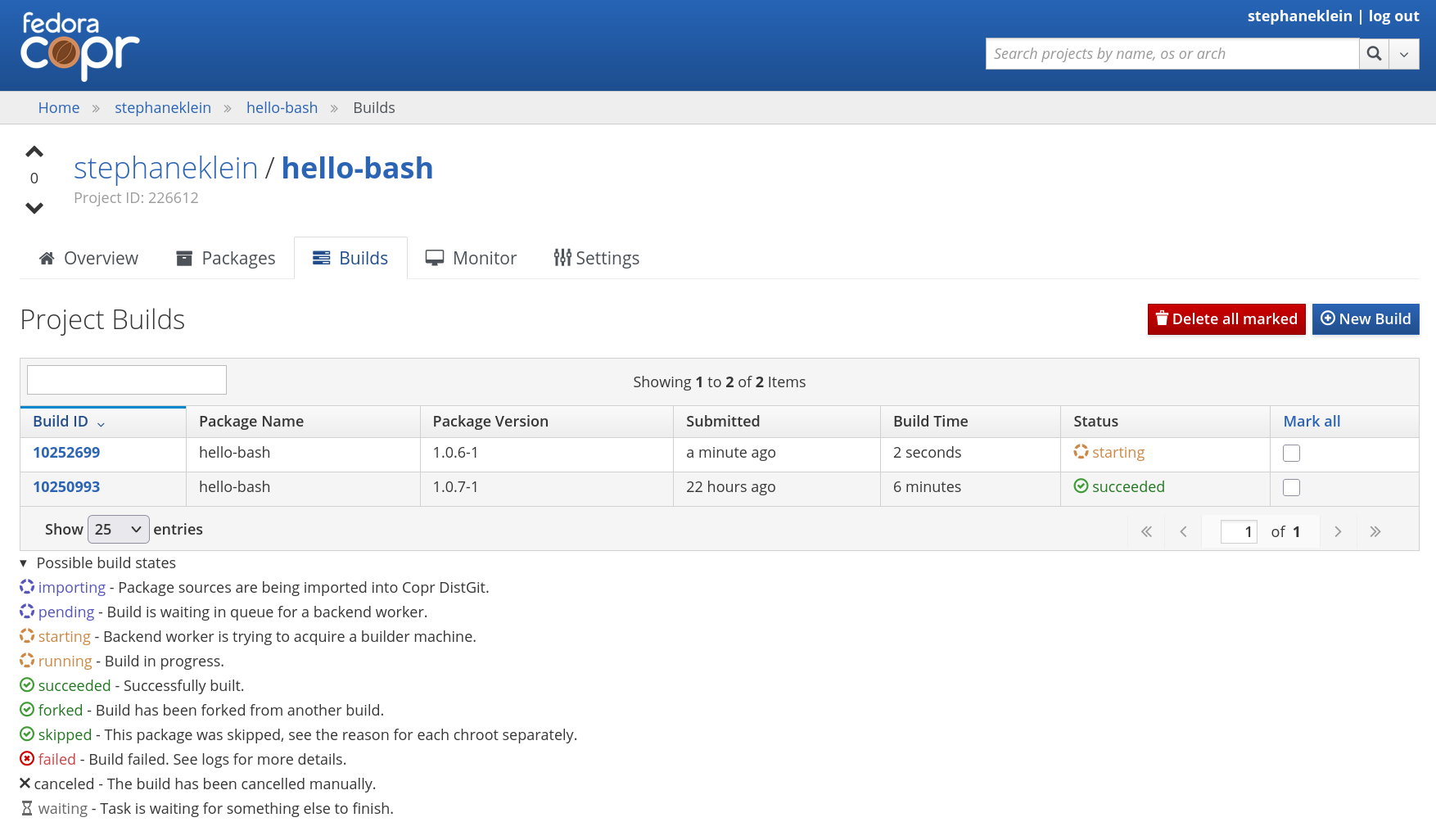
Une fois le build des packages terminé, il est facile d'installer le package avec les commandes suivantes :
$ sudo dnf copr enable -y stephaneklein/hello-bash
$ sudo dnf install -y hello-bash
$ hello-bash
Hello World
Automatisation GitOps avec COPR
Et pour finir, j'ai implémenté dans le playground l'automatisation complète de la compilation et publication des packages sur l'infrastructure COPR.
Pour cela, dans le script init-copr-project.sh j'ai déclaré l'URL du repository qui contient le code source :
...
copr-cli add-package-scm "$COPR_PROJECT" \
--name hello-bash \
--clone-url https://github.com/stephane-klein/fedora-rpm-copr-playground.git \
--commit bash \
--subdir . \
--spec rpm/hello-bash.spec \
--type git \
--method make_srpm \
--webhook-rebuild on
Le paramètre --commit bash permet de définir la branche Git à utiliser comme source.
Le paramètre --method make_srpm, qui permet à l'utilisateur d'utiliser un script personnalisé de génération du SRPM, à placer dans /.copr/Makefile à la racine du dépôt avec une cible srpm, exemple :
specfile = rpm/hello-bash.spec
.PHONY: srpm
srpm: $(specfile)
mkdir -p /tmp/copr-srpm-build
cp rpm/hello-bash.spec /tmp/copr-srpm-build/hello-bash.spec
cp -r . /tmp/copr-srpm-build/source/
cd /tmp/copr-srpm-build && \
rpmbuild -bs hello-bash.spec \
--define "_topdir /tmp/copr-srpm-build/rpmbuild" \
--define "dist .fc42" \
--define "_sourcedir /tmp/copr-srpm-build/source"
cp /tmp/copr-srpm-build/rpmbuild/SRPMS/*.src.rpm $(outdir)
Je ne souhaite pas détailler ici d'autres méthodes comme tito ou Packit, mais la méthode make_srpm est la plus flexible, elle permet de contrôler entièrement comment le SRPM est construit.
Une fois tout ceci configuré, il est possible de rebuild le package directement en cliquant sur le bouton "Rebuild" sur l'interface web de COPR :
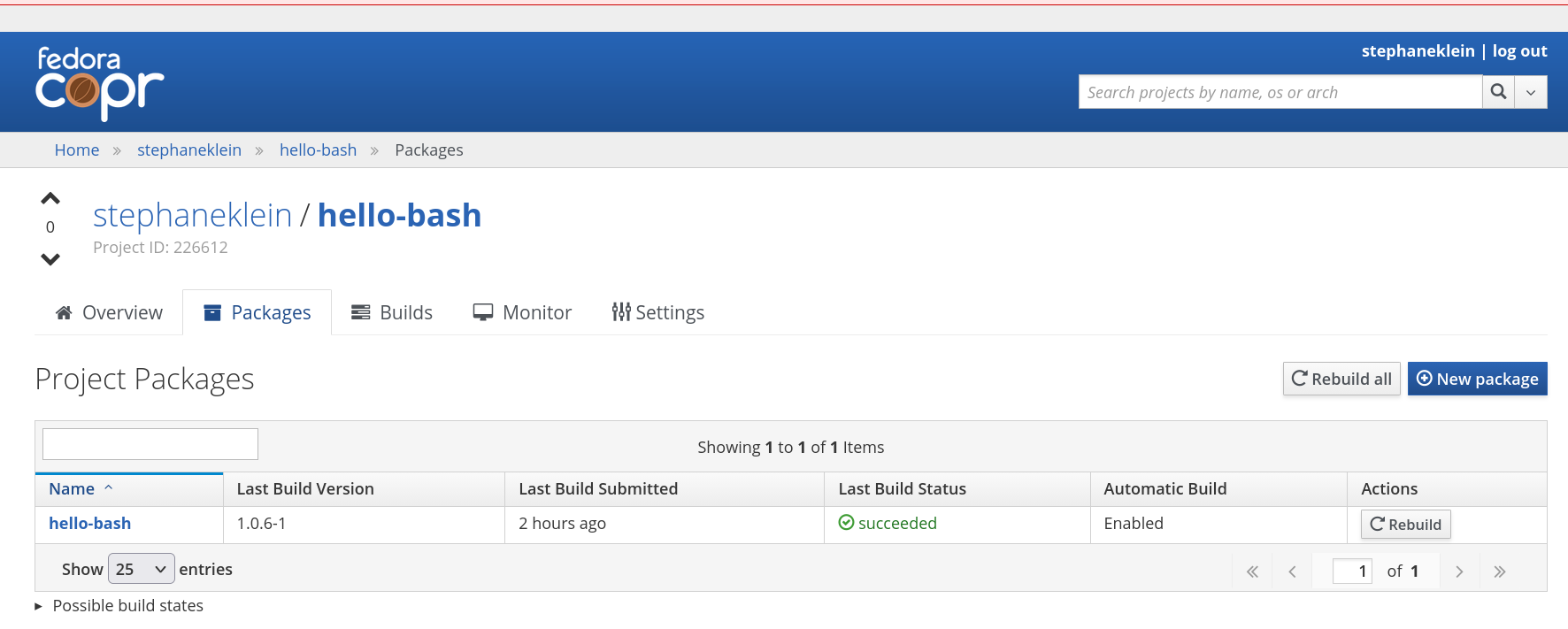
Dernière étape : j'ai implémenté un build automatique qui est déclenchée par un appel curl dans le job GitHub Actions /.github/workflows/trigger-copr-build.yml, dont voici le contenu :
name: Trigger Copr Build
on:
push:
tags:
- '*'
jobs:
trigger-copr-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Verify tag is on bash branch
run: |
if ! git branch -r --contains ${{ github.ref_name }} | grep -q "origin/bash"; then
echo "Tag ${{ github.ref_name }} is not on branch bash"
exit 1
fi
- name: Trigger Copr webhook
run: |
curl -X POST https://copr.fedorainfracloud.org/webhooks/custom/226325/3cf20247-820b-4050-bfb1-593b01a6996f/hello-bash/
Ce job est exécuté à chaque publication d'un nouveau Git tag, suivi d'une vérification que le tag provient bien de la branche bash.
Claude Sonnet 4.6 m'a suggéré l'existence d'une méthode de polling de dépôt Git intégrée à COPR, mais je n'ai trouvé aucune trace de celle-ci dans la documentation.
J'ai aussi essayé d'utiliser la méthode basée sur les webhooks GitHub de COPR, mais je n'ai pas réussi à la faire fonctionner. L'interface de GitHub m'indiquait à chaque fois une erreur dans la réponse des calls HTTP. C'est pour cela que j'ai fini par déclencher le webhook custom via un job GitHub Actions.
Package d'un projet en Golang
Le playground contient aussi le packaging d'une application en Golang, consultable dans la branche golang.
Voici le contenu du fichier /golang/rpm/hello-golang.spec :
Name: hello-golang
Version: 1.0.10
Release: 1%{?dist}
Summary: A simple Hello World Go application
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: %{name}-%{version}.tar.gz
BuildRequires: golang >= 1.21
%description
A simple "Hello World" Go application packaged as an RPM for Fedora COPR.
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
%install
mkdir -p %{buildroot}%{_bindir}
cp %{name} %{buildroot}%{_bindir}/
%files
%{_bindir}/%{name}
%changelog
* Fri Mar 20 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les principales différences avec la version pour Bash :
- Absence de
BuildArch: noarch - Présence de
BuildRequires: golang >= 1.21 - Et l'ajout des instructions suivantes :
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
Peu de changement au niveau du script /build-rpm-locally.sh, qui génère ces fichiers :
rpmbuild
├── BUILD
├── RPMS
│ └── x86_64
│ ├── hello-golang-1.0.10-1.fc42.x86_64.rpm
│ ├── hello-golang-debuginfo-1.0.10-1.fc42.x86_64.rpm
│ └── hello-golang-debugsource-1.0.10-1.fc42.x86_64.rpm
├── SOURCES
│ ├── hello-golang-1.0.10
│ │ ├── go.mod
│ │ └── main.go
│ └── hello-golang-1.0.10.tar.gz
├── SPECS
└── SRPMS
└── hello-golang-1.0.10-1.fc42.src.rpm
Cette fois, plus rien dans le dossier RPMS/noarch/, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-golang.spec build le package pour la distribution de la workstation du développeur.
Pour le reste, je n'ai pas identifié de différence majeure entre la version Bash et la version Golang
La suite… méthode Tito et Packit
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour stephane-klein/fedora-rpm-copr-playground pour les tester et ensuite publier une nouvelle note de compte rendu.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals ou harnais (harness). Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
Journal du mercredi 11 décembre 2024 à 11:22
#JaiDécouvert ArchieML (https://archieml.org/) qui est un markup language créé en 2015 par Michael Strickland qui travaille chez The New York Times.
Mon premier sentiment a été « pourquoi ne pas utiliser du Markdown ».
Ensuite, en lisant la documentation, j'ai compris que ce markup language était utilisé pour renseigner des valeurs dans différents champs. Comme le dit la documentation, ArchieML est une alternative à JSON ou YAML.
En explorant la section « Why not YAML? Or JSON? », j'ai compris la philosophie fondamentale d'ArchieML : offrir un langage de balisage qui soit particulièrement tolérant aux erreurs de syntaxe, notamment concernant l'indentation.
Cette approche répond spécifiquement aux besoins des journalistes qui, contrairement aux développeurs, ne sont généralement pas familiers avec les conventions strictes d'indentation que l'on trouve dans d'autres langages de balisage.
Ensuite, je me suis demandé : « Pourquoi ne pas demander aux journalistes de saisir leur article dans une page d'édition web, qui présente différents champs bien distincts ? ».
Je pense que la réponse se trouve ici :
And finally, because we make extensive use of Google Documents's concurrent-editing features…
Tout comme j'aime travailler avec des documents "plain text", peut-être que les journalistes préfèrent finalement travailler sur de simples documents textes plutôt qu'une page web d'édition, pour des raisons de rapidité d'utilisation : copier-coller rapide, fonctionnalité de commentaire collaboratif de Google Docs…
Je découvre dans la section ressources différentes librairies d'intégration à Google Docs.
Je découvre aussi que ArchieML est utilisé par d'autres journaux :
- Quartz
- The Atlanta Journal-Constitution
- Fusion
- The Wall Street Journal
Au final, je n'ai pas d'opinion définitive au sujet de cette méthode d'édition d'article 🤔.