
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (16 notes) :
Journal du mardi 25 février 2025 à 09:35
Dans cette note, je souhaite décrire et expliquer comment j'intègre des sessions de terminal dans des documentations.
Convention mainstream que j'ai adoptée
Je suis la convention mainstream suivante pour représenter des sessions terminal (de type bash, zsh…) au format Markdown :
Première partie :
$ echo "Hello, world!" Hello, world! $ ls -l total 0 -rw-r--r-- 1 user user 0 Feb 25 10:00 file.txtSeconde partie :
$ sudo su # systemctl restart nginx $ exit $ uptime # Affiche l'uptime uptime 10:00:00 up 1 day, 2:45, 1 user, load average: 0.15, 0.10, 0.05
Les lignes commençant par $ ou # indiquent les commandes saisies par l'utilisateur, tandis que les autres correspondent aux sorties du terminal.
Il m'arrive également d'ajouter des commentaires en fin de ligne à l'aide de # ….
Origine de cette convention ?
J'ai cherché à retracer l'origine de cette pratique et elle semble très ancienne, probablement adoptée dès les débuts d'Unix en 1971.
On retrouve cette syntaxe notamment dans le livre The Unix Programming Environment (pdf), publié en 1984.
Ne pas inclure de $ si un bloc ne contient aucune sortie de commande
La règle MD014 de Markdownlint aborde ce sujet :
MD014 - Dollar signs used before commands without showing output
Tags: code
Aliases: commands-show-output
This rule is triggered when there are code blocks showing shell commands to be typed, and the shell commands are preceded by dollar signs ($):
$ ls $ cat foo $ less barThe dollar signs are unnecessary in the above situation, and should not be included:
ls cat foo less barHowever, an exception is made when there is a need to distinguish between typed commands and command output, as in the following example:
$ ls foo bar $ cat foo Hello world $ cat bar bazRationale: it is easier to copy and paste and less noisy if the dollar signs are omitted when they are not needed. See https://cirosantilli.com/markdown-style-guide#dollar-signs-in-shell-code for more information.
Pendant un certain temps, j’ai suivi la recommandation de ne pas inclure de $ dans un bloc de commande lorsqu’il n’affiche aucune sortie.
Après quelques années, j’ai décidé de ne plus appliquer cette règle pour la raison suivante :
- Lorsque la documentation mélange des fichiers de configuration et des commandes sans
$, j’ai du mal à distinguer ce qui doit être exécuté dans un terminal et ce qui relève de la configuration.
Pour éviter toute ambiguïté, j’ai adopté une approche radicale : toujours utiliser $ pour indiquer une commande à exécuter, même si le bloc ne contient pas de sortie.
Je n'aime pas les $ dans les blocs de commande, car que je ne peux pas copier / coller facilement !
Je comprends tout à fait cette remarque. Cependant, ces "screenshots" de session de terminal n'ont pas vocation à être copiées / collées en masse.
Ils ont avant tout une fonction explicative.
Ce sont des sortes de "screenshot".
Si j'éprouve le besoin de faire souvent des "copier / coller" d'exemples de session terminal, alors je considère que c'est le signe qu'un script "helper" serait plus approprié pour exécuter ce groupe de commandes d’un seul coup.
Par exemple, je peux remplacer ce contenu :
Ensure that the following prerequisites have been installed: mise and direnv, see instruction in ../README.md.
$ mise trust $ mise install $ scw version Version 2.34.0
Par celui-ci (qui indique l'existence du script ./scripts/mise-install.sh) :
Ensure that the following prerequisites have been installed: mise and direnv, see instruction in ../README.md (or execute
./scripts/mise-install.sh).$ mise trust $ mise install $ scw version Version 2.34.0
Cela évite les copier-coller répétitifs tout en conservant la clarté de l’explication.
Journal du mercredi 29 janvier 2025 à 16:29
Alexandre m'a fait remarquer que GitLab a activé par défaut une extension Markdown de génération automatique de TOC :
A table of contents is an unordered list that links to subheadings in the document. You can add a table of contents to issues, merge requests, and epics, but you can’t add one to notes or comments.
Add one of these tags on their own line to the description field of any of the supported content types:
[[_TOC_]] or [TOC]
- Markdown files.
- Wiki pages.
- Issues.
- Merge requests.
- Epics.
Je trouve cela excellent que cette extension Markdown soit supportée un peu partout, en particulier les issues, Merge Request… 👍️.
Cette fonctionnalité a été ajoutée en mars 2020 🫢 ! Comment j'ai pu passer à côté ?
GitHub permet d'afficher un TOC au niveau des README, mais je viens de vérifier, GitHub ne semble pas supporter cette extension TOC Markdown au niveau des issues… Pull Request…
Journal du mercredi 11 décembre 2024 à 11:22
#JaiDécouvert ArchieML (https://archieml.org/) qui est un markup language créé en 2015 par Michael Strickland qui travaille chez The New York Times.
Mon premier sentiment a été « pourquoi ne pas utiliser du Markdown ».
Ensuite, en lisant la documentation, j'ai compris que ce markup language était utilisé pour renseigner des valeurs dans différents champs. Comme le dit la documentation, ArchieML est une alternative à JSON ou YAML.
En explorant la section « Why not YAML? Or JSON? », j'ai compris la philosophie fondamentale d'ArchieML : offrir un langage de balisage qui soit particulièrement tolérant aux erreurs de syntaxe, notamment concernant l'indentation.
Cette approche répond spécifiquement aux besoins des journalistes qui, contrairement aux développeurs, ne sont généralement pas familiers avec les conventions strictes d'indentation que l'on trouve dans d'autres langages de balisage.
Ensuite, je me suis demandé : « Pourquoi ne pas demander aux journalistes de saisir leur article dans une page d'édition web, qui présente différents champs bien distincts ? ».
Je pense que la réponse se trouve ici :
And finally, because we make extensive use of Google Documents's concurrent-editing features…
Tout comme j'aime travailler avec des documents "plain text", peut-être que les journalistes préfèrent finalement travailler sur de simples documents textes plutôt qu'une page web d'édition, pour des raisons de rapidité d'utilisation : copier-coller rapide, fonctionnalité de commentaire collaboratif de Google Docs…
Je découvre dans la section ressources différentes librairies d'intégration à Google Docs.
Je découvre aussi que ArchieML est utilisé par d'autres journaux :
- Quartz
- The Atlanta Journal-Constitution
- Fusion
- The Wall Street Journal
Au final, je n'ai pas d'opinion définitive au sujet de cette méthode d'édition d'article 🤔.
Journal du mercredi 11 septembre 2024 à 09:28
#JaiDécouvert NestedText (from).
Même en lisant la section Alternatives - YAML, je ne comprends pas encore précisément l'intérêt du projet. Je ne trouve pas YAML plus simple que NestedText.
Journal du lundi 26 août 2024 à 22:10
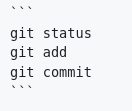
Lorsque vous collaborez avec moi et partagez du code source ou des extraits de terminal dans un logiciel compatible avec le format Markdown, tel que GitHub, GitLab, Mattermost, Zulip, etc., je vous encourage à entourer vos extraits avec des balises ```. Par exemple :
De même, pour les citations de texte en prose, utilisez les caractères > au début de chaque ligne, comme illustré ci-dessous :
> Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse justo neque, facilisis ut commodo in, auctor at tellus. Morbi non mattis risus. In vehicula risus felis, ac ullamcorper magna consequat et.
> Sed finibus, lorem a rutrum pulvinar, magna urna rutrum tortor, eget faucibus dolor enim sit amet lacus. Nulla pulvinar ligula eu leo rhoncus faucibus.
Ce qui produira :
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse justo neque, facilisis ut commodo in, auctor at tellus. Morbi non mattis risus. In vehicula risus felis, ac ullamcorper magna consequat et. Sed finibus, lorem a rutrum pulvinar, magna urna rutrum tortor, eget faucibus dolor enim sit amet lacus. Nulla pulvinar ligula eu leo rhoncus faucibus.
Ces deux recommandations permettent d'améliorer le confort de lecture de vos messages.
Voir aussi je préfère recevoir les extraits de vos textes au format texte plutôt que sous forme de captures d'écran.
Journal du lundi 05 août 2024 à 14:58
Le projet SilverBullet.mb utilise le terme Transclusion : https://silverbullet.md/Transclusions
Transclusions are an extension of the Markdown syntax enabling inline embedding of content.
The general syntax is
![[path]].
Journal du mercredi 31 juillet 2024 à 17:33
#JeMeDemande comment définir la largeur d'une image dans Obsidian.
J'ai commencé par faire une recheche sur le forum d'Obsidian : image size.
Et j'ai trouvé ma réponse. La syntax Markdown suivante fonctionne :

🙂
Dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age", j'utilise les librairies remark mais pour le moment, je les trouve bien plus difficiles à utiliser que gray-matter couplé avec markdown-it.
Par exemple, je souhaite extraire dans un dict le contenu frontmatter de fichiers markdown, ainsi que la partie body.
Avec remark j'ai écrit avec difficulté le code suivant :
#!/usr/bin/env node
import { glob } from "glob";
import fs from 'fs';
import { unified } from 'unified';
import markdown from 'remark-parse';
import frontmatter from 'remark-frontmatter';
import extract from 'remark-extract-frontmatter';
import { parse } from 'yaml';
import stringify from 'remark-stringify';
const processor = unified()
.use(markdown)
.use(frontmatter, ['yaml'])
.use(extract, { yaml: parse })
.use(stringify);
const processMarkdown = async (filename) => {
const fileContent = fs.readFileSync(filename);
const result = await processor.process(fileContent);
const body = result.toString().split(/---\s*$/m)[2] || '';
return {
frontmatter: result.data,
body: body.trim()
};
};
for (const filename of (await glob("content/**/*.md"))) {
processMarkdown(filename).then(data => {
console.log('Frontmatter:', data.frontmatter);
console.log('Body:', data.body);
});
}
Et voici mon implémentation avec gray-matter :
#!/usr/bin/env node
import { glob } from "glob";
import matter from "gray-matter";
import yaml from "js-yaml";
for (const filename of (await glob("content/**/*.md"))) {
console.log(matter.read(filename, {
engines: {
yaml: (s) => yaml.load(s, { schema: yaml.JSON_SCHEMA })
}
}));
}
Je préfère sans hésitation cette seconde implémentation.
#JaiDécidé d'utiliser gray-matter.
#JeMeDemande quels seraient les avantages que j'aurai à utiliser remark 🤔.
Journal du mercredi 01 mai 2024 à 12:05
#JeMeDemande si la librairie mdsvex me permet d'implémenter de manière agréable des nouveaux components qui ont la capacité d'aller chercher des données en backend, typiquement une base de données PostgreSQL.
J'aimerais que la requête soit décrite directement dans le markdown.
Je souhaite aussi que le composant soit rendu seulement côté serveur (SSR).
J'aimerais pouvoir implémenter quelque chose comme :
# Mon titre
Mon paragraphe
``sql posts
SELECT title FROM posts ORDER BY created_at LIMIT 10
``
<ul>
{#each posts as post}
<li>{post}</li>
{/each}
</ul>
(inspiration de https://evidence.dev/).
#JeMeDemande si mdsvex serait adapté pour cet objectif.
Je viens de voir ce thread Thoughts on Mdsvex moving away from Unified : sveltejs. Il contient un lien vers Penguin-flavoured markdown · pngwn/MDsveX · Discussion #293 · GitHub qui me semble intéressant #JaimeraisUnJour prendre le temps de le lire.
Autre thread What remark and rehype plugins are people using? · pngwn/MDsveX · Discussion #354 · GitHub.
#JeMeDemande si remark ou markdown-it serait mieux adapté pour atteindre mon objectif 🤔.
#JaiDécouvert (ou plutôt redécouvert) https://github.com/unifiedjs.
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Evidence semble implémenter un mécanisme qui ressemble à mon objectif et est codé en Svelte.
Je découvre "Carta" (Svelte Markdown editor)
En faisant la recheche suivant sur le subreddit Svelte : "markdown" #JaiDécouvert ici la librairie carta :
A lightweight, fast and extensible Svelte Markdown editor and viewer.
La démo se trouve ici : https://beartocode.github.io/carta/
#JeMeDemande si je dois tester cette librairie pour réaliser l'objectif du projet Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai regardé le code source de l'extension Slash et j'ai l'impression que je pourrais m'inspirer de cette implémentation pour créer une extension permettant d'implémenter un "sélécteur de ressource", "à la" Obsidian pour le projet Value Props 🤔.
Dépôt GitHub : https://github.com/VikParuchuri/marker
Dernière page.