
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (119 notes) :
Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code
Cette après-midi, DeepSeek V4 Flash (via OpenCode) a fait une boulette dans mon projet homelab.sklein.xyz !

En voulant corriger le Helmfile de déploiement de Hindsight, il a lancé :
$ mise run destroy-cnpg-hindsight
sans réaliser que cette task Mise allait lancer la commande suivante :
helmfile -f helmfile/helmfile.yaml.gotmpl destroy
sans remarquer que mon fichier helmfile/helmfile.yaml.gotmpl contenait tous mes services et pas seulement cnpg-hindsight !
Ce qui est marrant, c'est qu'après le « Oups », il a tout de suite essayé de se rattraper. Heureusement, je suis au début de l'installation de mon homelab — rien d'important à perdre — et j'ai pu tester que la restauration du backup continu de CloudNativePG basé sur barman fonctionne bien.
DeepSeek V4 Flash n'est pas à blâmer : je ne l'ai pas aidé avec mes instructions, je lui ai tendu un piège.
Suite à cet incident sans gravité, j'ai pris conscience que faire travailler un agent de coding sur un projet d'Infrastructure as code est bien plus risqué que sur un projet de développement cloisonné, sans accès à la production.
J'ai commencé par ajouter ces quelques lignes dans mon fichier AGENTS.md :
## Safety Rules
- **Never run any `destroy-*` script or `helmfile destroy` command without explicit user confirmation** in the same conversation turn. Always ask first.
- If you must run `helmfile destroy`, always use `--selector name=<release>` to target only one release.
- When in doubt about a command's destructiveness, ask before executing.
Ensuite, j'ai remarqué que l'agent plan de OpenCode avait par défaut un accès trop large au tool bash pour un projet d'Infrastructure as code, je me suis lancé dans le renforcement des permissions :
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"plan": {
"permission": {
"bash": {
"*": "ask",
"kubectl get *": "allow",
"kubectl describe *": "allow",
"kubectl logs *": "allow",
"kubectl top *": "allow",
"tofu plan*": "allow",
"tofu show*": "allow",
"tofu output*": "allow",
"tofu state*": "allow",
"helm list*": "allow",
"helm status*": "allow",
"helm diff*": "allow",
"helmfile *list*": "allow",
"helmfile *status*": "allow",
"helmfile *diff*": "allow",
"git log*": "allow",
"git diff*": "allow",
"git status": "allow",
"git show*": "allow",
"jj log*": "allow",
"jj diff*": "allow",
"jj status": "allow",
"ls*": "allow",
"find*": "allow"
}
}
}
}
}
Ensuite, je me suis demandé s'il existait des solutions clé en main de limitation d'accès aux commandes cli, du même style que rtk, pour autoriser seulement des commandes de lecture sans risque.
#JaiDécouvert Prempti et agentsh. Je me suis demandé si l'intégration de l'un de ces outils n'allait pas entrer en conflit avec rtk. En étudiant les issues sur la sécurité de rtk, j'ai découvert que : rtk contourne le système de permissions d'OpenCode.
Journal du samedi 15 novembre 2025 à 14:23
Dans ce commentaire, #JaiDécouvert une alternative à Grafana (partie dashboard) : Perses (https://github.com/perses/perses).
For exclusively dashboards, the CNCF has https://perses.dev/, which supports Prometheus Loki and Pyroscope, and has a Grafana importer but I haven't given it a shot.
Journal du jeudi 06 novembre 2025 à 10:28
Dans mon activité professionnelle, #JaiDécouvert Bicep (https://github.com/Azure/bicep) équivalent pour Microsoft Azure de Terraform et CloudFormation.
Je découvre aussi le format ARM Template JSON :
Bicep code is transpiled to standard ARM Template JSON files, which effectively treats the ARM Template as an Intermediate Language (IL).
Dans ce contexte, j'apprends qu'ARM signifie Azure Resource Manager.
Je comprends que le suffixe "rm" dans le nom du provider Terraform d'Azure terraform-provider-azurerm fait référence à "Resource Manager".
Journal du jeudi 30 octobre 2025 à 09:59
#OnMaPartagé le site https://serverlesshorrors.com à propos des services Serverless computing.
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
Quelques outils CoreOS : coreos-installer, graphe de migration et zincati
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Fusion de CoreOS et Atomic Project en 2018".
coreos-installer
L'outil coreos-installer est un composant essentiel de Fedora CoreOS. Il propose différentes méthodes pour installer Fedora CoreOS.
La commande coreos-installer download permet de télécharger tout type de version de CoreOS, sous différents formats, par exemple iso, raw, qemu, cloud image, etc (toutes celles présentes dans la page download).
Ensuite, la commande coreos-installer install permet d'installer la version téléchargée vers un disque. Cette commande est par exemple disponible à la fin du boot d'une image ISO. Contrairement à Fedora Silverblue qui propose d'installer la distribution avec Anaconda, l'installation de CoreOS s'effectue en cli via coreos-installer install.
Ensuite, la commande coreos-installer install permet d'installer la version téléchargée sur un disque. Cette commande est notamment accessible après le démarrage d'une image ISO. Contrairement à Fedora Silverblue qui utilise l'installateur graphique Anaconda, CoreOS s'installe exclusivement en cli via coreos-installer install.
Toutefois, coreos-installer permet de préparer une installation automatique. La commande coreos-installer iso customize modifie une image ISO existante pour y intégrer directement une configuration ignition, rendant l'installation entièrement automatisée au démarrage.
Voici un exemple dans mon playground : atomic-os-playground/create-coreos-custom-iso.sh.
coreos-installer pxe permet aussi d'effectuer une configuration automatique par réseau, via PXE, mais je ne l'ai pas testé.
Graphe de migration de versions
Lors de mes tests d'upgrade de CoreOS à partir d'une ancienne release (environ n-10), j'ai constaté que la transition vers la dernière version ne se faisait pas directement mais nécessitait le passage par des versions intermédiaires.
J'ai découvert que CoreOS maintient un graphe qui définit le parcours d'upgrade requis. Certaines versions intermédiaires doivent être installées pour gérer des breaking changes, comme la migration de configurations.
zincati
Un autre composant important de Fedora CoreOS est zincati, le service responsable de l'exécution des mises à jour automatiques.
zincati décide d'effectuer les mises à jour en fonction du seuil de prudence de déploiement (rollout_wariness) et de la stratégie de mise à jour : immediate ou periodic (plage horaire définie dans la semaine).
CoreOS utilisant par défaut la stratégie immediate, zincati détecte automatiquement les nouvelles releases dès le premier démarrage et lance immédiatement leur téléchargement, suivi d'un redémarrage.
Le téléchargement par deltas rend l'upgrade vers la dernière release très rapide.
zincati permet également de coordonner les mises à jour de plusieurs serveurs, fonctionnalité particulièrement utile dans le contexte d'un cluster Kubernetes. Je n'ai pas encore testé cette fonctionnalité.
Note suivante : "composefs, un filesystem spécialement créé pour les besoins des distributions atomic".
Ajout de packages dans des distributions atomiques
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Peu à peu depuis 2015, le terme immutable est remplacé par atomic".
Je constate que la plupart des personnes avec qui j'échange pensent qu'une distribution immutable ne permet que d'exécuter des containers Docker ou des applications Flatpak.
En réalité, grâce à la technologie libostree, il est possible d'installer des packages Fedora sur une instance Fedora CoreOS.
Voici un exemple sous Fedora CoreOS que j'ai réalisé avec le playground suivant : https://github.com/stephane-klein/atomic-os-playground.
Je commence par regarder l'état de l'OS avec rpm-ostree status :
stephane@stephane-coreos:~$ rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 12:43:23 UTC)
Deployments:
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Je constate que la version 42.20250901.3.0 identifiée par le commit sha256:d196ab...ae10c1 est installée.
Cette version correspond au moment où j'écris cette note à la dernière release du stream stale listé sur cette page https://fedoraproject.org/coreos/release-notes?arch=x86_64&stream=stable.
Maintenant, j'utilise rpm-ostree install … pour installer neovim.
stephane@stephane-coreos:~$ sudo rpm-ostree install neovim
Checking out tree 1e5b81c... done
Enabled rpm-md repositories: fedora-cisco-openh264 updates fedora updates-archive
Updating metadata for 'fedora-cisco-openh264'... done
Updating metadata for 'updates'... done
Updating metadata for 'fedora'... done
Updating metadata for 'updates-archive'... done
Importing rpm-md... done
rpm-md repo 'fedora-cisco-openh264'; generated: 2025-03-19T16:53:39Z solvables: 6
rpm-md repo 'updates'; generated: 2025-09-27T01:07:36Z solvables: 24410
rpm-md repo 'fedora'; generated: 2025-04-09T11:06:59Z solvables: 76879
rpm-md repo 'updates-archive'; generated: 2025-09-27T01:38:59Z solvables: 44216
Resolving dependencies... done
Will download: 40 packages (121.6 MB)
Downloading from 'updates'... done
Downloading from 'fedora'... done
Importing packages... done
Checking out packages... done
Running systemd-sysusers... done
Running pre scripts... done
Running post scripts... done
Running posttrans scripts... done
Writing rpmdb... done
Writing OSTree commit... done
Staging deployment... done
Added:
binutils-2.44-6.fc42.x86_64
compat-lua-libs-5.1.5-28.fc42.x86_64
...
neovim-0.11.4-1.fc42.x86_64
...
Changes queued for next boot. Run "systemctl reboot" to start a reboot
Neovim a bien été installé, mais je dois reboot pour l'utiliser. Voici ce que me dit rpm-ostree status :
stephane@stephane-coreos:~$ rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 12:48:33 UTC)
Deployments:
ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Diff: 40 added
LayeredPackages: neovim
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
La pastille ● m'indique la version (nommée déploiement) actuellement utilisée par l'instance.
Lors du démarrage du serveur, grub est configuré pour booter sur le premier déploiement de la liste. Exemple :
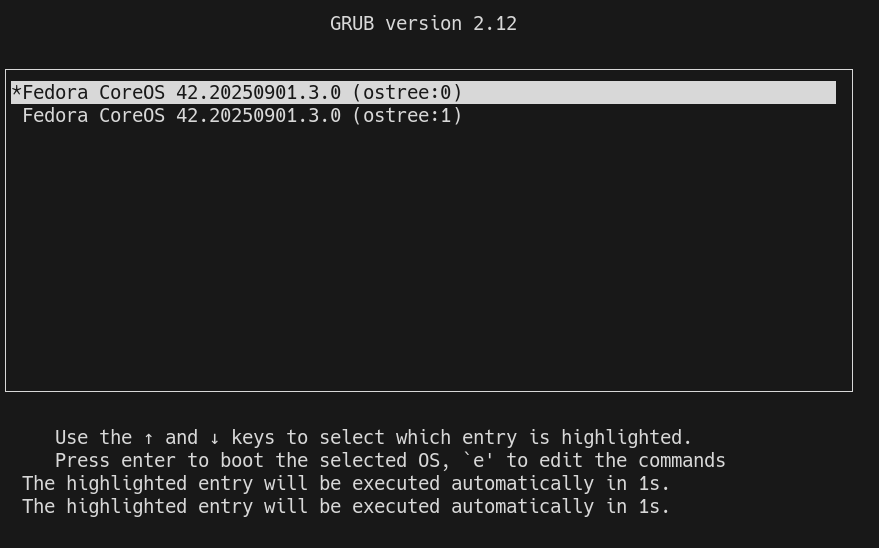
Une fois le serveur démarré, je peux voir que la version 42.20250901.3.0 est toujours utilisée, mais avec en plus un layer qui contient le package neovim :
[stephane@stephane-coreos ~]$ rpm-ostree status
rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 13:04:36 UTC)
Deployments:
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
LayeredPackages: neovim
ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Neovim est bien accessible :
[stephane@stephane-coreos ~]$ nvim --version
nvim --version
NVIM v0.11.4
Build type: RelWithDebInfo
LuaJIT 2.1.1748459687
Run "nvim -V1 -v" for more info
Avec la commande rpm-ostree apply-live il est même possible de commencer à utiliser le package sans avoir à reboot.
Cette fonctionnalité doit se limité à des petits utilitaires. Pour les composants systèmes, il est conseillé d'effectuer un reboot.
Note suivante : "Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows".
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Journal du lundi 22 septembre 2025 à 17:30
Je viens de publier le "Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab"".
J'ai découvert Kiln, un outil de gestion de secret basé sur Age
#JaiDécouvert dans ce thread Hacker News le projet kiln (https://kiln.sh/).
kiln is a secure environment variable management tool that encrypts your sensitive configuration data using age encryption. It provides a simple, offline-first alternative to centralized secret management services, with role-based access control and support for both age and SSH keys, making it perfect for team collaboration and enterprise environments.
Je n'ai pas encore testé kiln mais j'ai l'intuition qu'il pourrait remplacer le workflow que j'ai présenté il y a quelque mois dans cette note : "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh".
Voici les informations que j'ai identifiées au sujet de kiln :
- Ce projet est très jeune
- Écrit en Golang
- Supporte des clés age ou des clés ssh.
- « Team Collaboration: Fine-grained role-based access control for team members and groups »
- What happens if someone leaves the team?
La lecture de la faq m'a fait penser que je n'ai toujours pas pris le temps d'étudier SOPS 🫣.
J'ai hâte de tester kiln qui grâce à Age me semble plus simple que le workflow basé sur pass, que j'ai utilisé professionnellement de 2019 à 2023.
J'ai découvert la méthode officielle de SvelteKit pour accéder aux variables d'environnement
Voici une nouvelle fonctionnalité qui illustre pourquoi j'apprécie l'expérience développeur (DX) de SvelteKit : la simplicité d'accès aux variables d'environnement !
Je commence avec un peu de contexte.
Comme je l'ai déjà dit dans une précédente note, je suis depuis 2015 les principes de The Twelve-Factors App.
Concrètement, quand je déploie un frontend web qui a besoin de paramètres de configuration, par exemple une URL pour accéder à une API, je déploie quelque chose qui ressemble à ceci :
# docker-compose.yml
services:
webapp:
image: ...
environment:
GRAPHQL_API: https://example.com/
De 2012 à 2022, quand ma doctrine était de produire des frontend web en SPA, j'avais recours à du boilerplate code à base de commande sed dans un entrypoint.sh, qui avait pour fonction d'attribuer des valeurs aux variables de configuration — comme dans cet exemple GRAPHQL_API — au moment du lancement du container Docker, exemple : entreypoint.sh.
Ce système était peu élégant, difficile à expliquer et à maintenir.
Ce soir, j'ai découvert les fonctionnalités suivantes de SvelteKit :
J'ai publié ce playground sveltekit-environment-variable-playground qui m'a permis de tester ces fonctionnalités dans un projet SSR avec hydration.
J'ai testé comment accéder à trois variables dans trois contextes différents (.envrc) :
# Set at application build time
export PUBLIC_VERSION="0.1.0"
# Set at application startup time and accessible only on server side
export POSTGRESQL_URL="postgresql://myuser:mypassword123@localhost:5432/mydatabase"
# Set at application startup time and accessible on frontend side
export PUBLIC_GOATCOUNTER_ENDPOINT=https://example.com/count
Cela fonctionne parfaitement bien, c'est simple, pratique, un pur bonheur.
Pour plus de détails, je vous invite à regarder le playground et à tester par vous-même.
Merci aux développeurs de SvelteKit ❤️.
J'ai regardé ce que propose NextJS et je constate qu'il propose moins de fonctionnalités.
D'après ce que j'ai compris, NextJS propose l'équivalent de $env/dynamic/private et $env/static/public mais j'ai l'impression qu'il ne propose rien d'équivalent à $env/dynamic/public.
Journal du mardi 20 mai 2025 à 17:03
#JaiLu la discussion GitHub du projet nginx-proxy : "How can we scapre metrics from nginx-proxy container".
J'y ai découvert le Prometheus exporter : nginx-prometheus-exporter (https://github.com/nginx/nginx-prometheus-exporter). Il semble être l'exporter officiel de nginx pour Prometheus.
Je pense tester son installation et sa configuration d'ici à quelques jours.
Liste des éléments que je souhaite étudier :
- Est-ce qu'il existe un dashboard Grafana qui permet de consulter par domaine et peut-être par URLs :
- le temps moyen de réponse
- la mediane de temps de réponse
- le temps de réponse au 90ème percentile (p90)
- le temps de réponse au 95ème percentile (p95)
Je pense que la metric nginxplus_upstream_server_response_time me permettra peut-être d'obtenir cette information.
J'ai identifié ce dashboard Grafana mais il ne semble pas afficher les informations dont j'ai besoin.
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Journal du jeudi 01 mai 2025 à 16:22
Je continue mon travail de mise à niveau en Kubernetes.
Je viens de réaliser que Helmfile ne fait pas directement partie du projet Helm. Je trouve cela surprenant. Ces deux projets sont réalisés par deux equipes différentes :
- Dépôt GitHub de Helm : https://github.com/helm/helm/
- Développeurs principaux :
- Matt Butcher basé aux États-Unis
- Adam Reese basé aux États-Unis
- Développeurs principaux :
- Dépôt GitHub de Helmfile : https://github.com/helmfile/helmfile/
- Développeurs principaux :
- Yusuke Kuoka basé au Japon
- yxxhero basé en Chine
- Développeurs principaux :
D'après ce que je comprends, si je simplifie, Helmfile est pour Helm l'équivalent de ce qu'est docker-compose.yml pour Docker.
Je m'intéresse aujourd'hui à Helmfile parce que je souhaite effectuer une tâche qui correspond au use-case numéro 2 décrit dans la documentation :
ArgoCD has support for kustomize/manifests/helm chart by itself. Why bother with Helmfile?
The reasons may vary:
1.You do want to manage applications with ArgoCD, while letting Helmfile manage infrastructure-related components like Calico/Cilium/WeaveNet, Linkerd/Istio, and ArgoCD itself.2.You want to review the exact K8s manifests being applied on pull-request time, before ArgoCD syncs.3.This is often better than using a kind of HelmRelease custom resources that obfuscates exactly what manifests are being applied, which makes reviewing harder.
Suite à cette lecture, voici comment j'ai mis en application une partie du use-case 2.
J'ai ce helmfile.yaml :
environments:
dev:
values:
- version: 6.1.0
production:
values:
- version: 6.1.0
---
repositories:
- name: open-webui
url: https://helm.openwebui.com/
---
releases:
- name: openwebui
namespace: {{ .Namespace }}
chart: open-webui/open-webui
values:
- ./env.d/{{ .Environment.Name }}/values.yaml
version: {{ .Values.version }}
Et ensuite, j'ai exécuté :
$ helmfile template -e dev --output-dir-template $(pwd)/gitops/{{.Release.Name}}
Adding repo open-webui https://helm.openwebui.com/
"open-webui" has been added to your repositories
Templating release=openwebui, chart=open-webui/open-webui
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service.yaml
wrote .../gitops/openwebui/open-webui/templates/service.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/deployment.yaml
wrote .../gitops/openwebui/open-webui/templates/workload-manager.yaml
wrote .../gitops/openwebui/open-webui/templates/ingress.yaml
Cela me permet ensuite de pouvoir observer avec précision ce qui va être déployé par ArgoCD.
Journal du mardi 29 avril 2025 à 15:30
Depuis quelques semaines, je vois de plus en plus de sites web qui intègrent Anubis. Par exemple sur https://gitlab.gnome.org/, https://priv.au/ et à l'instant sur https://forge.libre.sh/indiehosters.
Voici ce qu'Anubis affiche à la première connexion au site web :
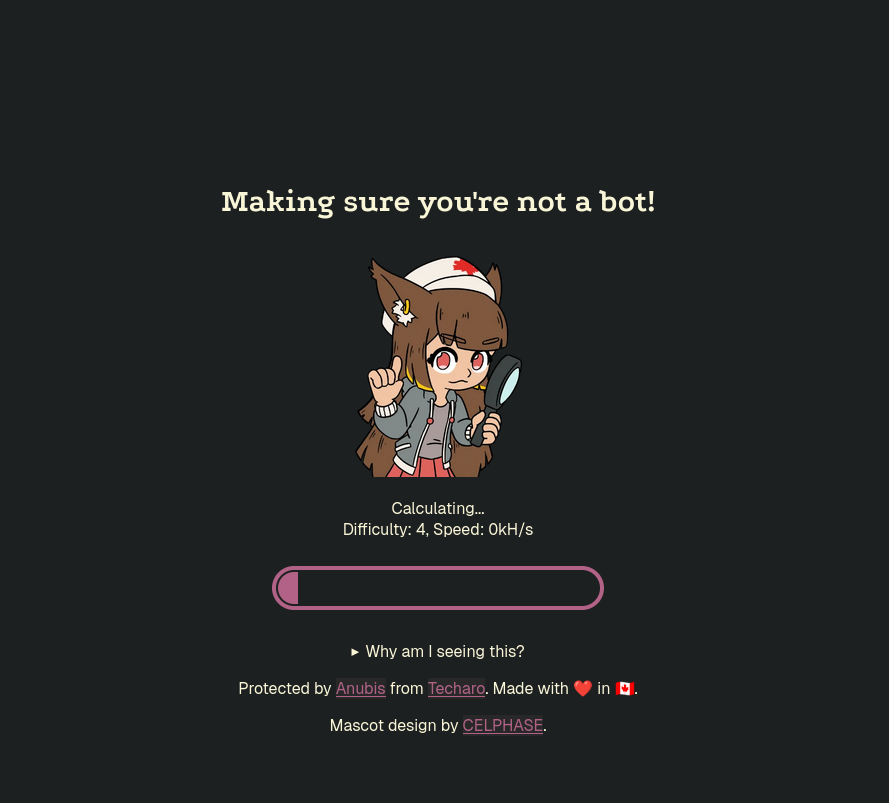
Journal du lundi 28 avril 2025 à 23:34
#JaiDécouvert Krew (https://github.com/kubernetes-sigs/krew) :
#JaiDécouvert MetalLB (https://metallb.io/) :
#JaiDécouvert cert-manager (https://github.com/cert-manager/cert-manager)
cert-manager adds certificates and certificate issuers as resource types in Kubernetes clusters, and simplifies the process of obtaining, renewing and using those certificates.
It supports issuing certificates from a variety of sources, including Let's Encrypt (ACME), HashiCorp Vault, and Venafi TPP / TLS Protect Cloud, as well as local in-cluster issuance.
Journal du mardi 22 avril 2025 à 17:57
J'ai un collègue qui utilise Terragrunt (https://terragrunt.gruntwork.io/).
Je pense que j'ai déjà croisé cet outil mais sans trop y prêter attention.
Pour le moment, je ne comprends pas très bien l'intérêt de Terragrunt, j'ai l'impression que c'est un wrapper au-dessus de Terraform ou OpenTofu.
#JaimeraisUnJour prendre le temps de faire un POC de Terragrunt.
Journal du jeudi 10 avril 2025 à 22:48
Dans la documentation de restic, #JaiDécouvert resticprofile :
Scheduling backups
Restic does not have a built-in way of scheduling backups, as it’s a tool that runs when executed rather than a daemon. There are plenty of different ways to schedule backup runs on various different platforms, e.g. systemd and cron on Linux/BSD and Task Scheduler in Windows, depending on one’s needs and requirements. If you don’t want to implement your own scheduling, you can use resticprofile.
Le projet resticprofile a commencé en 2019, tout comme restic, il est écrit en Golang.
resticprofile permet de lancer restic à partir d'un fichier de configuration. D'après l'extrait ci-dessous, l'équipe de restic ne semble pas vouloir intégrer un système de fichiers de configuration.
Configuration profiles manager for restic backup
resticprofile is the missing link between a configuration file and restic backup. Creating a configuration file for restic has been discussed before, but seems to be a very low priority right now.
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.
Journal du mercredi 02 avril 2025 à 16:48
J'ai souvent besoin d'exécuter l'équivalent de :
$ scp -r root@myserver:/foo/bar/ ./tmp/
ou l'inverse :
$ scp -r ./tmp/ root@myserver:/foo/bar/
sur des serveurs sur lesquels je n'ai pas directement accès à l'utilisateur root par ssh.
J'accède, par exemple, à ce serveur via l'utilisateur ubuntu.
L'utilisateur ubuntu n'a pas accès aux fichiers que je souhaite download ou upload.
Sur le serveur, j'ai accès aux fichiers de l'utilisateur root via sudo.
Voici une astuce pour download des fichiers via ssh et sudo :
$ ssh ubuntu@myserver "sudo tar cf - -C /foo/bar/ ." | tar xf - -C ./tmp/
Et, voici une méthode pour upload :
$ tar cf - -C ./tmp/ . | ssh ubuntu@myserver "sudo tar xf - -C /foo/bar/"
Object Storage append-only backup playground
Pour un projet, je dois mettre en place un système de sauvegarde sécurisé (WORM).
Ici, "sécurisé" signifie :
- qui empêche la suppression accidentelle ou intentionnelle des données ;
- une protection contre les ransomwares.
Pour cela, j'ai décidé de sauvegarder ces données chez deux fournisseurs d'Object Storage :
Je viens de publier le playground append-only-backup-playground qui m'a permis de tester la configuration de bucket Backblaze et Scaleway.
Object Storage append-only backup playground
In this "playground" repository, I explore different methods to configure object storage services in append-only or write-once-read-many (WORM) mode.
J'ai testé deux méthodes qui interdisent la suppression des données :
1.La première, basée sur une clé d'accès avec des droits limités : l'interdiction de supprimer des fichiers. Si un attaquant parvient à s'infiltrer sur un serveur qui effectue des sauvegardes, la clé ne lui permettra pas d'effacer les anciennes sauvegardes.2.La seconde méthode plus stricte utilise la fonctionnalité object lock en modeGOVERNANCEouCOMPLIANCE.
Je vous recommande d'être vigilant avec le mode COMPLIANCE, car il vous sera impossible de supprimer les fichiers avant leur date de rétention, sauf si vous décidez de supprimer entièrement votre compte client !
Personnellement, je recommande d'utiliser la méthode 1 pour tous les environnements de développement.
En général, je pense que la méthode 1 est suffisante, même pour les environnements de production. Mais si les données sont vraiment critiques, alors je conseille le mode GOVERNANCE ou COMPLIANCE.
Le repository append-only-backup-playground contient 4 playgrounds :
- Pour tester la méthode
1:/scaleway/: configuration d'un bucket Scaleway Object Storage et une clé qui ne peut pas supprimer de fichier. L'option de versionning est activée./backblaze/: configuration d'un bucket Backblaze et une clé qui ne peut pas supprimer de fichier. L'option de versionning est activée.
- Pour tester la méthode
2:/scaleway-object-lock/: la même chose que/scaleway/avec en plus la configuration de object lock en modeGOVERNANCEavec une durée de rétention définie à 1 jour./backblaze-object-lock/: la même chose que/backblaze/avec en plus la configuration de object lock en modeGOVERNANCEavec une durée de rétention définie à 1 jour.
Journal du jeudi 27 février 2025 à 11:02
Au mois d'août 2024, je disais :
Je cherche depuis plusieurs années une solution pour surveiller la date d'expiration des noms de domaine en analysant le contenu de Whois.
#JaiDécouvert cet exporter Prometheus qui correspond exactement à mon besoin : https://github.com/shift/domain_exporter
Ce matin, en travaillant sur la note "Je découvre Beszel", #JaiDécouvert que Gatus permet de monitorer l'expiration d'un domaine :
You can monitor the expiration of a domain with all endpoint types except for DNS by using the
[DOMAIN_EXPIRATION]placeholder.The aforementioned placeholder resolves to a duration (e.g. 734h22m5s), as such, the value you should compare it to should also be a duration (e.g. 720h, 1h30m). Here's an example of what a condition may look like:
[DOMAIN_EXPIRATION] > 720hThe condition above will fail if the domain expires in less than 720 hours (30 days).
Journal du jeudi 27 février 2025 à 10:41
En travaillant sur la note "Je découvre Beszel", #JaiDécouvert ici un autre projet de monitoring intéressant : Dozzle (https://dozzle.dev/).
Dozzle is a small lightweight application with a web based interface to monitor Docker logs. It doesn’t store any log files. It is for live monitoring of your container logs only.
Là aussi, Dozzle est un projet en Golang, commencé fin 2018.
Dozzle est une alternative à Loki + Grafana.
#JaimeraisUnJour déployer Dozzle pour le tester et si ce test est concluant, je l'intégrerai peut-être à ma stack minimaliste de monitoring en complément de Beszel et Gatus.
Un ami m'a partagé le projet Beszel (https://beszel.dev/).
Beszel is a lightweight server monitoring platform that includes Docker statistics, historical data, and alert functions.
It has a friendly web interface, simple configuration, and is ready to use out of the box. It supports automatic backup, multi-user, OAuth authentication, and API access.
Beszel est codé en Golang, il est très récent, il a commencé en été 2024, c'est sans doute pour cela que je ne l'avais jamais croisé.
De prime abord, j'ai pensé que Beszel était un outil de Status / Uptime pages comme Uptime Kuma ou Gatus, mais ce n'est pas le cas.
Je qualifierai plutôt Beszel d'alternative "plug and play" de Prometheus + Grafana + node_exporter + cAdvisor.
Alors que l'annonce de Beszel a fait "choux blanc" sur Hacker News « Beszel: Lightweight server resource monitoring with history, Docker stats,alerts », le projet a suscité plus de réaction — 270 commentaires — sur Subreddit SelfHosted : « I just released Beszel, a server monitoring hub with historical data, docker stats, and alerts. It's a lighter and simpler alternative to Grafana + Prometheus or Checkmk. Any feedback is appreciated! ».
Les retours sont très positifs 🙂 :
« There is beauty in simplicity. Very nice little application! »
« Kiss »
« Just installed on all of my servers, gorgeous project, simple but also not simple. »
« Awesome work. I think you identified a good use case for the self hosting community, a simple server monitor running as a simple service. I will give it a go soon! »
« I never installed Grafana and Prometheus because it’s overkill for my little server.. but this looks really good! I’ll give it a go »
Prometheus propose bien plus d'exporter que Beszel, mais je pense que Beszel est un bon point de départ pour une stack de monitoring minimaliste.
À l'avenir, mon choix par défaut en matière monitoring sera probablement un couple Beszel + Gatus. Si des besoins plus avancés émergent, comme du monitoring poussé de PostgreSQL, Redis ou d'autres services, j'envisagerai alors de commencer la mise en place du couple Prometheus + Grafana.
Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh
Cette note est aussi disponible au format vidéo : https://www.youtube.com/watch?v=J9jsd4m9YkQ.
De 2018 à 2023, j'utilisais l'outil "pass" (https://www.passwordstore.org/) couplé avec GNU Privacy Guard pour chiffrer et déchiffrer les secrets dans mes projets professionnels.
Bien que cette méthode fonctionnait, elle s'avérait laborieuse.
La procédure documentant l'installation, la création des clés et la configuration de gnupg était l'étape posant le plus de difficultés d'onboarding des développeurs sur ces projets.
Au feeling, je dirais que trois développeurs sur quatre bloquaient à cette étape.
En parallèle à cette méthode, j'ai essayé d'utiliser la cli de Bitwarden, mais l'expérience n'a pas été très concluante, principalement à cause de problèmes de latence lors de son exécution.
Aujourd'hui, j'ai exploré une nouvelle méthode basée sur age et son support natif des clés ssh.
Voici le repository Git du résultat de cette exploration : age-secret-skeleton.
Le résultat est très positif et je pense avoir trouvé ma nouvelle méthode de chiffrement des secrets dans mes projets 🙂.
Pour en savoir plus, vous pouvez à la fois suivre le README.md du repository et continuer la lecture de cette note.
Détail des fichiers du repository
.
├── .envrc
├── .gitignore
├── .mise.toml
├── README.md
├── scripts
│ ├── decrypt_secrets.sh
│ └── encrypt_secrets.sh
├── .secret
├── .secret.age
├── .secret.skel
└── ssh-keys
├── john-doe.pub
└── stephane-klein.pub
/.secret: fichier qui contient les secrets en clair. Ce fichier est ignoré par.gitignoreafin qu'il ne soit pas présent dans le repository git/.secret.age: fichier qui contient le contenu du fichier.secretchiffré avec age. Ce fichier est ajouté au repository git./ssh-keys/: ce dossier contient les clés publiques ssh des personnes qui ont accès au contenu de.secret.age/scripts/decrypt_secrets.sh: permet de déchiffrer avec age le contenu de.secret.ageet écrit le résultat en clair dans.secret/scripts/encrypt_secrets.sh: permet de chiffrer avec age le contenu de.secretvers.secret.age. Ce script doit être exécuté quand le contenu de.secretest modifié ou quand une nouvelle clé est ajoutée dans/ssh-keys//.envrc: Dans ce skeleton, ce fichier charge uniquement les variables d'environnement présentes dans.secretmais dans un vrai projet, il permet de charger automatiquement des variables d'environnement qui ne sont pas des secrets./.secret.skel: ce fichier contient l'exemple de contenu du fichier.secret, sans les secrets. Par exemple :
# You can either request these secrets from Stéphane Klein (contact@stephane-klein.info)
# or, if your public ssh key is present in `./ssh-keys/` use the ./scripts/decrypt_secrets.sh command
# which will automatically decrypt the .secret.age file to .secret
export POSTGRES_PASSWORD="..."
export SCW_SECRET_KEY="..."
Ce fichier n'est pas nécessaire au bon fonctionnement du workflow mais je le trouve utile pour :
- documenter le contenu de
.secretaux personnes qui ont juste accès au dépôt Git - permettre de review les modifications de
.secret.skeldans des Merge Request.
Utilisation des clés ssh
L'un des avantages majeurs de age par rapport à pass + gnupg est son support natif des clés SSH pour chiffrer et déchiffrer les secrets.
Ainsi, je n'ai plus besoin de demander aux développeurs deux types de clés (SSH et gnupg) : une seule clé SSH suffit.
De plus, il me semble qu'un grand nombre de développeurs possèdent déjà une clé SSH, alors que je pense que gnupg reste une technologie bien moins répandue.
Détail d'implémentation des scripts
Vvoici le contenu de /scripts/encrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare recipient arguments for age
recipient_args=()
for pubkey in ./ssh-keys/*.pub; do
if [ -f "$pubkey" ]; then
recipient_args+=("-R" "$pubkey")
fi
done
# Execute age with all public keys
age "${recipient_args[@]}" -o .secret.age .secret
La boucle permet de passer toutes les clés ssh du dossier /ssh-keys/* en paramètre d' age.
Voici le contenu de /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
La boucle permet de passer en paramètre toutes les clés privées ssh du dossier ~/.ssh/ en espérant en trouver une qui correspond à une clé publique du dossier /ssh-keys/.
Plusieurs niveaux de sécurisation
Si je veux cloisonner les secrets en limitant leur accès à des groupes d'utilisateurs distincts, je peux utiliser des secrets différents selon l'environnement.
Par exemple :
.
├── production
│ ├── .secret.age
│ └── ssh-keys
└── sandbox
├── .secret.age
└── ssh-keys
Cette structure me permet de donner à certains utilisateurs accès aux secrets de l'environnement sandbox, sans leur donner accès à ceux de production.
Aller plus loin avec par exemple Vault ?
Je pense qu'il est possible d'aller plus loin en matière de sécurité avec des solutions comme Vault, mais trouve que la méthode basée sur age reste plus simple à déployer dans une petite équipe.
Journal du vendredi 07 février 2025 à 16:12
Exemples d'outils qui suivent de modèle Orchestration Push Mode :
Exemples d'outils qui suivent le modèle Orchestration Pull Mode :
Journal du vendredi 07 février 2025 à 14:03
Pendant l'année 2014, Athoune m'a fait découvrir les concepts DevOps "Baking" et "Frying".
Je le remercie, car ce sont des concepts que je considère très importants pour comprendre les différents paradigmes de déploiement.
Je n'ai aucune idée dans quelles conditions il avait découvert ces concepts. J'ai essayé de faire des recherches limitées à l'année 2014 et je suis tombé sur cette photo :
J'en déduis que cela devait être un sujet à la méthode dans l'écosystème DevOps de 2014.
Cet ami me l'avait très bien expliqué avec une analogie du type :
« Le baking en DevOps, c’est comme dans un restaurant où les plats sont préparés en cuisine et ensuite apportés tout prêt salle à la table du client. Le frying, c’est comme si le plat était préparé directement en salle sur la table du client. »
Bien que cette analogie ne soit pas totalement rigoureuse, elle m'a bien permis de saisir, en 2014, le paradigme Docker qui consiste à préparer des images de container en amont. Ce paradigme permet d'installer, de configurer ces images "en cuisine", donc pas sur les serveurs de production, "de goûter les plats" et de les envoyer ensuite de manière prédictible sur le serveur de production.
Ces images peuvent être construites soit sur la workstation du développeur ou mieux, sur des serveurs dédiés à cette fonction, comme Gitlab-Runner…
Définitions proposées par LLaMa :
Baking (ou "Image Baking") : Il s'agit de créer une image de serveur prête à l'emploi, avec tous les logiciels et les configurations nécessaires déjà installés et configurés. Cette image est ensuite utilisée pour déployer de nouveaux serveurs, qui seront ainsi identiques et prêts à fonctionner immédiatement. L'avantage de cette approche est qu'elle permet de réduire le temps de déploiement et d'assurer la cohérence des environnements.
Frying (ou "Server Frying") : Il s'agit de déployer un serveur "nu" et de le configurer et de l'installer à la volée, en utilisant des outils d'automatisation tels que Ansible, Puppet ou Chef. Cette approche permet de personnaliser la configuration de chaque serveur en fonction des besoins spécifiques de l'application ou du service.
Exemple :
Cas d'usage Baking Frying Docker Construire une image complète ( docker build) et la stocker dans un registreLancer un conteneur minimal et installer les dépendances au démarrage. Machines virtuelles (VMs) Créer une image VM avec Packer et la déployer telle quelle Démarrer une VM de base et appliquer un script d’installation à la volée CI/CD Compiler et packager une application en image prête à être déployée Construire l’application à chaque déploiement sur la machine cible
En 2014, lorsque le concept de baking m’a été présenté, j’ai immédiatement été enthousiasmé, car il répondait à trois problèmes que je cherchais à résoudre :
- Réduire les risques d’échec d’une installation sur le serveur de production
- Limiter la durée de l’indisponibilité (pendant la phase d’installation)
- Éviter d'augmenter la charge du serveur durant les opérations de build lors de l’installation
Depuis, j'évite au maximum le frying et j'ai intégré le baking dans ma doctrine d'artisan développeur.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Journal du vendredi 07 février 2025 à 10:48
Note de type #mémento pour ajouter le support healthcheck à nginx-proxy et nginx-proxy acme-companion.
J'ai effectué des recherches dans les dépôts GitHub des projets :
- nginx-proxy « health », j'ai trouvé :
- acme-companion « health », j'ai trouvé :
J'ai aussi trouvé « Adding health check support to nginx-proxy nginx.tmpl file · nginx-proxy/nginx-proxy » qui est un sujet qui m'intéresse, mais pas en lien avec le sujet de cette note.
N'ayant rien trouvé de clés en main, voici ci-dessous mon implémentation.
Je ne suis pas certain qu'elle soit très robuste 🤔.
Elle a tout de même l'avantage de me permettre d'utiliser l'option --wait dans docker-compose up -d --remove-orphans --wait.
J'ai partagé aussi posté un commentaire à l'issue pour partager mon implémentation.
# docker-compose.yml
services:
nginx-proxy:
image: nginxproxy/nginx-proxy:1.6.4
container_name: nginx-proxy
restart: unless-stopped
network_mode: "host"
volumes:
- ./vhost.d/:/etc/nginx/vhost.d:rw
- ./htpasswd:/etc/nginx/htpasswd:ro
- html:/usr/share/nginx/html
- certs:/etc/nginx/certs:ro
- /var/run/docker.sock:/tmp/docker.sock:ro
healthcheck:
test: ["CMD-SHELL", "nginx -t && kill -0 $$(cat /var/run/nginx.pid)"]
interval: 10s
timeout: 2s
retries: 3
acme-companion:
image: nginxproxy/acme-companion:2.5.1
restart: unless-stopped
volumes_from:
- nginx-proxy
depends_on:
- "nginx-proxy"
environment:
DEFAULT_EMAIL: contact@stephane-klein.info
volumes:
- certs:/etc/nginx/certs:rw
- acme:/etc/acme.sh
- /var/run/docker.sock:/var/run/docker.sock:ro
healthcheck:
test: ["CMD-SHELL", "ps aux | grep -v grep | grep -q '/bin/bash /app/start.sh'"]
interval: 30s
timeout: 3s
retries: 3
start_period: 10s
volumes:
html:
certs:
acme:
Journal du jeudi 30 janvier 2025 à 12:02
Note de type #aide-mémoire : contrairement à ~/.zprofile, .zshenv est chargé même lors de l'exécution d'une session ssh en mode non interactif, par exemple :
$ ssh user@host 'echo "Hello, world!"'
Je me suis intéressé à ce sujet parce que mes scripts exécutés par ssh dans le cadre du projet /poc-capacitor/ n'avaient pas accès aux outils mis à disposition par Homebrew et Mise.
J'ai creusé le sujet et j'ai découvert que .zprofile était chargé seulement dans les cas suivants :
- « login shell »
- « interactive shell »
Un login shell est un shell qui est lancé lors d'une connexion utilisateur. C'est le type de shell qui exécute des fichiers de configuration spécifiques pour préparer l'environnement utilisateur. Un login shell se comporte comme si tu te connectais physiquement à une machine ou à un serveur.
Un shell interactif est un shell dans lequel tu peux entrer des commandes de manière active, et il attend des entrées de ta part. Un shell interactif est conçu pour interagir avec l'utilisateur et permet de saisir des commandes, d'exécuter des programmes, de lancer des scripts, etc.
Suite à cela, dans ce commit "Move zsh config from .zprofile to .zshenv", j'ai déplacé la configuration de Homebrew et Mise de ~/.zprofile vers .zshenv.
Cela donne ceci une fois configuré :
$ cat .zshenv
eval "$(/opt/homebrew/bin/brew shellenv)"
eval "$(mise activate zsh)"
Mais, attention, « As /etc/zshenv is run for all instances of zsh ». Je pense que ce n'est pas forcément une bonne idée d'appliquer cette configuration sur une workstation, parce que cela peut "ralentir" légèrement le système en lançant inutilement ces commandes.
ChatGPT me conseille cette configuration pour éviter cela :
# Ne charge Brew et Mise que si on est dans un shell interactif ou SSH
if [[ -t 1 || -n "$SSH_CONNECTION" ]]; then
eval "$(/opt/homebrew/bin/brew shellenv)"
eval "$(mise activate zsh)"
fi
Journal du mardi 21 janvier 2025 à 10:45
Alexandre m'a fait découvrir testssl.sh (https://github.com/testssl/testssl.sh) :
testssl.shis a free command line tool which checks a server's service on any port for the support of TLS/SSL ciphers, protocols as well as some cryptographic flaws.
Voici ci-dessous le résultat pour mon domaine sklein.xyz.
Je lis : Overall Grade: A+
Quelques précisions concernant la configuration derrière sklein.xyz :
- J'utilise un certificat Let's Encrypt, validé par la méthode challenge HTTP-01
- Ce certificat est généré par nginx-proxy acme-companion et utilisé par nginx-proxy (la configuration)
$ docker run --rm -ti drwetter/testssl.sh sklein.xyz
#####################################################################
testssl.sh version 3.2rc3 from https://testssl.sh/dev/
This program is free software. Distribution and modification under
GPLv2 permitted. USAGE w/o ANY WARRANTY. USE IT AT YOUR OWN RISK!
Please file bugs @ https://testssl.sh/bugs/
#####################################################################
Using OpenSSL 1.0.2-bad [~183 ciphers]
on 43cf528ca9c5:/home/testssl/bin/openssl.Linux.x86_64
Start 2025-01-21 09:45:05 -->> 51.159.34.231:443 (sklein.xyz) <<--
rDNS (51.159.34.231): 51-159-34-231.rev.poneytelecom.eu.
Service detected: HTTP
Testing protocols via sockets except NPN+ALPN
SSLv2 not offered (OK)
SSLv3 not offered (OK)
TLS 1 not offered
TLS 1.1 not offered
TLS 1.2 offered (OK)
TLS 1.3 offered (OK): final
NPN/SPDY not offered
ALPN/HTTP2 h2, http/1.1 (offered)
Testing cipher categories
NULL ciphers (no encryption) not offered (OK)
Anonymous NULL Ciphers (no authentication) not offered (OK)
Export ciphers (w/o ADH+NULL) not offered (OK)
LOW: 64 Bit + DES, RC[2,4], MD5 (w/o export) not offered (OK)
Triple DES Ciphers / IDEA not offered
Obsoleted CBC ciphers (AES, ARIA etc.) not offered
Strong encryption (AEAD ciphers) with no FS not offered
Forward Secrecy strong encryption (AEAD ciphers) offered (OK)
Testing server's cipher preferences
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
-
SSLv3
-
TLSv1
-
TLSv1.1
-
TLSv1.2 (no server order, thus listed by strength)
xc030 ECDHE-RSA-AES256-GCM-SHA384 ECDH 521 AESGCM 256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
x9f DHE-RSA-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
xcca8 ECDHE-RSA-CHACHA20-POLY1305 ECDH 521 ChaCha20 256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xccaa DHE-RSA-CHACHA20-POLY1305 DH 2048 ChaCha20 256 TLS_DHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xc02f ECDHE-RSA-AES128-GCM-SHA256 ECDH 521 AESGCM 128 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
x9e DHE-RSA-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
TLSv1.3 (no server order, thus listed by strength)
x1302 TLS_AES_256_GCM_SHA384 ECDH 253 AESGCM 256 TLS_AES_256_GCM_SHA384
x1303 TLS_CHACHA20_POLY1305_SHA256 ECDH 253 ChaCha20 256 TLS_CHACHA20_POLY1305_SHA256
x1301 TLS_AES_128_GCM_SHA256 ECDH 253 AESGCM 128 TLS_AES_128_GCM_SHA256
Has server cipher order? no
(limited sense as client will pick)
Testing robust forward secrecy (FS) -- omitting Null Authentication/Encryption, 3DES, RC4
FS is offered (OK) TLS_AES_256_GCM_SHA384 TLS_CHACHA20_POLY1305_SHA256 ECDHE-RSA-AES256-GCM-SHA384 DHE-RSA-AES256-GCM-SHA384
ECDHE-RSA-CHACHA20-POLY1305 DHE-RSA-CHACHA20-POLY1305 TLS_AES_128_GCM_SHA256 ECDHE-RSA-AES128-GCM-SHA256
DHE-RSA-AES128-GCM-SHA256
Elliptic curves offered: prime256v1 secp384r1 secp521r1 X25519 X448
Finite field group: ffdhe2048 ffdhe3072 ffdhe4096 ffdhe6144 ffdhe8192
TLS 1.2 sig_algs offered: RSA+SHA224 RSA+SHA256 RSA+SHA384 RSA+SHA512 RSA-PSS-RSAE+SHA256 RSA-PSS-RSAE+SHA384 RSA-PSS-RSAE+SHA512
TLS 1.3 sig_algs offered: RSA-PSS-RSAE+SHA256 RSA-PSS-RSAE+SHA384 RSA-PSS-RSAE+SHA512
Testing server defaults (Server Hello)
TLS extensions (standard) "renegotiation info/#65281" "server name/#0" "EC point formats/#11" "status request/#5" "supported versions/#43"
"key share/#51" "supported_groups/#10" "max fragment length/#1" "application layer protocol negotiation/#16"
"extended master secret/#23"
Session Ticket RFC 5077 hint no -- no lifetime advertised
SSL Session ID support yes
Session Resumption Tickets no, ID: yes
TLS clock skew Random values, no fingerprinting possible
Certificate Compression none
Client Authentication none
Signature Algorithm SHA256 with RSA
Server key size RSA 4096 bits (exponent is 65537)
Server key usage Digital Signature, Key Encipherment
Server extended key usage TLS Web Server Authentication, TLS Web Client Authentication
Serial 048539E72F864A52E28F6CBEFF15527F75C5 (OK: length 18)
Fingerprints SHA1 5B966867DF42BC654DA90FADFDB93B6C77DD7053
SHA256 E79D3ACF988370EF01620C00F003E92B137FFB4EE992A5B1CE3755931561629D
Common Name (CN) sklein.xyz (CN in response to request w/o SNI: letsencrypt-nginx-proxy-companion )
subjectAltName (SAN) cv.stephane-klein.info garden.stephane-klein.info sklein.xyz stephane-klein.info
Trust (hostname) Ok via SAN and CN (SNI mandatory)
Chain of trust Ok
EV cert (experimental) no
Certificate Validity (UTC) 63 >= 30 days (2024-12-26 08:40 --> 2025-03-26 08:40)
ETS/"eTLS", visibility info not present
Certificate Revocation List --
OCSP URI http://r11.o.lencr.org
OCSP stapling offered, not revoked
OCSP must staple extension --
DNS CAA RR (experimental) not offered
Certificate Transparency yes (certificate extension)
Certificates provided 2
Issuer R11 (Let's Encrypt from US)
Intermediate cert validity #1: ok > 40 days (2027-03-12 23:59). R11 <-- ISRG Root X1
Intermediate Bad OCSP (exp.) Ok
Testing HTTP header response @ "/"
HTTP Status Code 302 Moved Temporarily, redirecting to "https://sklein.xyz/fr/"
HTTP clock skew 0 sec from localtime
Strict Transport Security 365 days=31536000 s, just this domain
Public Key Pinning --
Server banner nginx/1.27.1
Application banner --
Cookie(s) (none issued at "/") -- maybe better try target URL of 30x
Security headers --
Reverse Proxy banner --
Testing vulnerabilities
Heartbleed (CVE-2014-0160) not vulnerable (OK), no heartbeat extension
CCS (CVE-2014-0224) not vulnerable (OK)
Ticketbleed (CVE-2016-9244), experiment. not vulnerable (OK), no session ticket extension
ROBOT Server does not support any cipher suites that use RSA key transport
Secure Renegotiation (RFC 5746) supported (OK)
Secure Client-Initiated Renegotiation not vulnerable (OK)
CRIME, TLS (CVE-2012-4929) not vulnerable (OK)
BREACH (CVE-2013-3587) no gzip/deflate/compress/br HTTP compression (OK) - only supplied "/" tested
POODLE, SSL (CVE-2014-3566) not vulnerable (OK), no SSLv3 support
TLS_FALLBACK_SCSV (RFC 7507) No fallback possible (OK), no protocol below TLS 1.2 offered
SWEET32 (CVE-2016-2183, CVE-2016-6329) not vulnerable (OK)
FREAK (CVE-2015-0204) not vulnerable (OK)
DROWN (CVE-2016-0800, CVE-2016-0703) not vulnerable on this host and port (OK)
make sure you don't use this certificate elsewhere with SSLv2 enabled services, see
https://search.censys.io/search?resource=hosts&virtual_hosts=INCLUDE&q=E79D3ACF988370EF01620C00F003E92B137FFB4EE992A5B1CE3755931561629D
LOGJAM (CVE-2015-4000), experimental not vulnerable (OK): no DH EXPORT ciphers, no common prime detected
BEAST (CVE-2011-3389) not vulnerable (OK), no SSL3 or TLS1
LUCKY13 (CVE-2013-0169), experimental not vulnerable (OK)
Winshock (CVE-2014-6321), experimental not vulnerable (OK)
RC4 (CVE-2013-2566, CVE-2015-2808) no RC4 ciphers detected (OK)
Running client simulations (HTTP) via sockets
Browser Protocol Cipher Suite Name (OpenSSL) Forward Secrecy
------------------------------------------------------------------------------------------------
Android 6.0 TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 256 bit ECDH (P-256)
Android 7.0 (native) TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 256 bit ECDH (P-256)
Android 8.1 (native) TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 253 bit ECDH (X25519)
Android 9.0 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 10.0 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 11 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 12 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Chrome 79 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Chrome 101 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Firefox 66 (Win 8.1/10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Firefox 100 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
IE 6 XP No connection
IE 8 Win 7 No connection
IE 8 XP No connection
IE 11 Win 7 TLSv1.2 DHE-RSA-AES256-GCM-SHA384 2048 bit DH
IE 11 Win 8.1 TLSv1.2 DHE-RSA-AES256-GCM-SHA384 2048 bit DH
IE 11 Win Phone 8.1 No connection
IE 11 Win 10 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Edge 15 Win 10 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 253 bit ECDH (X25519)
Edge 101 Win 10 21H2 TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Safari 12.1 (iOS 12.2) TLSv1.3 TLS_CHACHA20_POLY1305_SHA256 253 bit ECDH (X25519)
Safari 13.0 (macOS 10.14.6) TLSv1.3 TLS_CHACHA20_POLY1305_SHA256 253 bit ECDH (X25519)
Safari 15.4 (macOS 12.3.1) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Java 7u25 No connection
Java 8u161 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Java 11.0.2 (OpenJDK) TLSv1.3 TLS_AES_128_GCM_SHA256 256 bit ECDH (P-256)
Java 17.0.3 (OpenJDK) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
go 1.17.8 TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
LibreSSL 2.8.3 (Apple) TLSv1.2 ECDHE-RSA-CHACHA20-POLY1305 253 bit ECDH (X25519)
OpenSSL 1.0.2e TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
OpenSSL 1.1.0l (Debian) TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 253 bit ECDH (X25519)
OpenSSL 1.1.1d (Debian) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
OpenSSL 3.0.3 (git) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
Apple Mail (16.0) TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Thunderbird (91.9) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Rating (experimental)
Rating specs (not complete) SSL Labs's 'SSL Server Rating Guide' (version 2009q from 2020-01-30)
Specification documentation https://github.com/ssllabs/research/wiki/SSL-Server-Rating-Guide
Protocol Support (weighted) 100 (30)
Key Exchange (weighted) 90 (27)
Cipher Strength (weighted) 90 (36)
Final Score 93
Overall Grade A+
Done 2025-01-21 09:46:08 [ 66s] -->> 51.159.34.231:443 (sklein.xyz) <<--
Journal du dimanche 19 janvier 2025 à 11:24
#iteration Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram :
Être capable d'exposer sur Internet un port d'une VM.
Voici comment j'ai atteint cet objectif.
Pour faire ce test, j'ai installé un serveur http nginx sur une VM qui a l'IP 192.168.1.236.
Cette IP est attribuée par le DHCP installé sur mon routeur OpenWrt. Le serveur hôte Proxmox est configuré en mode bridge.
Ma Box Internet Bouygues sur 192.168.1.254 peut accéder directement à cette VM 192.168.1.236.
Pour exposer le serveur Proxmox sur Internet, j'ai configuré mon serveur Serveur NUC i3 gen 5 en tant que DMZ host.
J'ai suivi la recommandation pour éviter une attaque du type : DNS amplification attacks
DNS amplification attacks involves an attacker sending a DNS name lookup request to one or more public DNS servers, spoofing the source IP address of the targeted victim.
Avec cette configuration, je peux accéder en ssh au Serveur NUC i3 gen 5 depuis Internet.
J'ai tout de suite décidé d'augmenter la sécurité du serveur ssh :
# cat <<'EOF' > /etc/ssh/sshd_config.d/sklein.conf
Protocol 2
PasswordAuthentication no
PubkeyAuthentication yes
AuthenticationMethods publickey
KbdInteractiveAuthentication no
X11Forwarding no
# systemctl restart ssh
J'ai ensuite configuré le firewall basé sur nftables pour mettre en place quelques règles de sécurité et mettre en place de redirection de port du serveur hôte Proxmox vers le port 80 de la VM 192.168.1.236.
nftables est installé par défaut sur Proxmox mais n'est pas activé. Je commence par activer nftables :
root@nuci3:~# systemctl enable nftables
root@nuci3:~# systemctl start nftables
Voici ma configuration /etc/nftables.conf, je me suis fortement inspiré des exemples présents dans ArchWiki : https://wiki.archlinux.org/title/Nftables#Server
# cat <<'EOF' > /etc/nftables.conf
flush ruleset;
table inet filter {
# Configuration from https://wiki.archlinux.org/title/Nftables#Server
set LANv4 {
type ipv4_addr
flags interval
elements = { 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 169.254.0.0/16 }
}
set LANv6 {
type ipv6_addr
flags interval
elements = { fd00::/8, fe80::/10 }
}
chain input {
type filter hook input priority filter; policy drop;
iif lo accept comment "Accept any localhost traffic"
ct state invalid drop comment "Drop invalid connections"
ct state established,related accept comment "Accept traffic originated from us"
meta l4proto ipv6-icmp accept comment "Accept ICMPv6"
meta l4proto icmp accept comment "Accept ICMP"
ip protocol igmp accept comment "Accept IGMP"
udp dport mdns ip6 daddr ff02::fb accept comment "Accept mDNS"
udp dport mdns ip daddr 224.0.0.251 accept comment "Accept mDNS"
ip saddr @LANv4 accept comment "Connections from private IP address ranges"
ip6 saddr @LANv6 accept comment "Connections from private IP address ranges"
tcp dport ssh accept comment "Accept SSH on port 22"
tcp dport 8006 accept comment "Accept Proxmox web console"
udp sport bootpc udp dport bootps ip saddr 0.0.0.0 ip daddr 255.255.255.255 accept comment "Accept DHCPDISCOVER (for DHCP-Proxy)"
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table nat {
chain prerouting {
type nat hook prerouting priority dstnat;
tcp dport 80 dnat to 192.168.1.236;
}
chain postrouting {
type nat hook postrouting priority srcnat;
masquerade
}
}
EOF
Pour appliquer en toute sécurité cette configuration, j'ai suivi la méthode indiquée dans : "Appliquer une configuration nftables avec un rollback automatique de sécurité".
Après cela, voici les tests que j'ai effectués :
- Depuis mon réseau local :
- Test d'accès au serveur Proxmox via ssh :
ssh root@192.168.1.43 - Test d'accès au serveur Proxmox via la console web : https://192.168.1.43:8006
- Test d'accès au service http dans la VM :
curl -I http://192.168.1.236
- Test d'accès au serveur Proxmox via ssh :
- Depuis Internet :
Voilà, tout fonctionne correctement 🙂.
Prochaines étapes :
- Être capable d'accéder depuis Internet via IPv6 à une VM
- Je souhaite arrive à effectuer un déploiement d'une Virtual instance via Terraform
Journal du vendredi 17 janvier 2025 à 12:03
Suite de ma note 2025-01-15_1350.
Voici la réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Journal du vendredi 17 janvier 2025 à 11:58
#JeMeDemande s'il est possible d'installer des serveurs Scaleway Elastic Metal avec des images d'OS préalablement construites avec Packer 🤔.
Je viens de poser la question suivante : Is it possible to create Elastic Metal OS images with Packer and use it to create a Elastic Metal serveurs?
En français :
Bonjour,
Je sais qu'il est possible de créer des images d'OS avec Packer utilisables lors de la création d'instance Scaleway (voir https://www.scaleway.com/en/docs/tutorials/deploy-instances-packer-terraform/).
De la même manière, je me demande s'il est possible de créer des images d'OS avec Packer pour installer des serveurs Elastic Metal .
Question : est-il possible de créer des images Elastic Metal avec Packer et d'utiliser celle-ci pour créer des serveurs Elastic Metal ?
Si c'est impossible actuellement, pensez-vous qu'il soit possible de l'implémenter ? Ou alors, est-ce que des limitations techniques de Elastic Metal rendent impossible cette fonctionnalité ?
Bonne journée, Stéphane
Je viens d'envoyer cette demande au support de Scaleway.
Journal du mercredi 15 janvier 2025 à 13:50
Suite de la note 2025-01-14_2152 au sujet de Scaleway Domains and DNS.
Dans l'e-mail « External domain name validation » que j'ai reçu, je lis :
Alternative validation process (if your current registrar doesn't offer basic DNS service):
Please set your nameservers at your registrar to:
9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud
J'ai essayé cette méthode alternative pour le sous-domaine scw.stephane-klein.info :
Voici les DNS Records correspondants :
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
J'ai vérifié ma configuration :
$ dig NS scw.stephane-klein.info @ali.ns.cloudflare.com
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
J'ai attendu plus d'une heure et cette méthode de validation n'a toujours pas fonctionné.
Je pense que cela ne fonctionne pas 🤔.
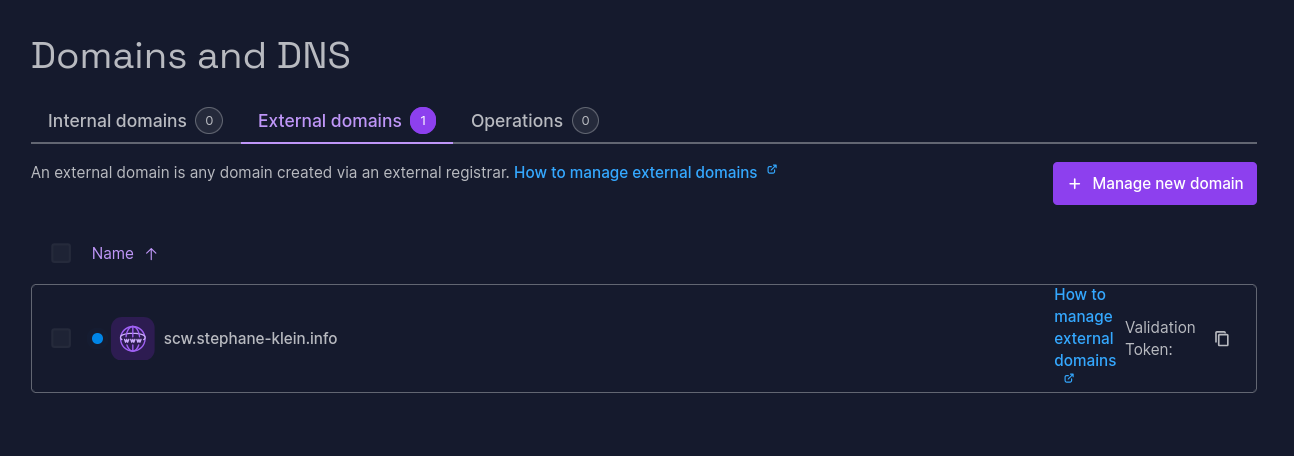
Je vais créer un ticket de support Scaleway pour savoir si c'est un bug ou si j'ai mal compris comment cela fonctionne.
2025-01-17 : réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Conclusion : la documentation était imprécise, ce que j'ai essayé de réaliser ne peut pas fonctionner.
Journal du mardi 14 janvier 2025 à 21:52
J'ai réalisé un test pour vérifier que la délégation DNS par le managed service de Scaleway nommé Domains and DNS (lien direct) fonctionne correctement pour un sous-domaine tel que testscaleway.stephane-klein.info.
Je commence par suivre les instructions du how to : How to add an external domain to Domains and DNS.
Sur la page https://console.scaleway.com/domains/internal/create :
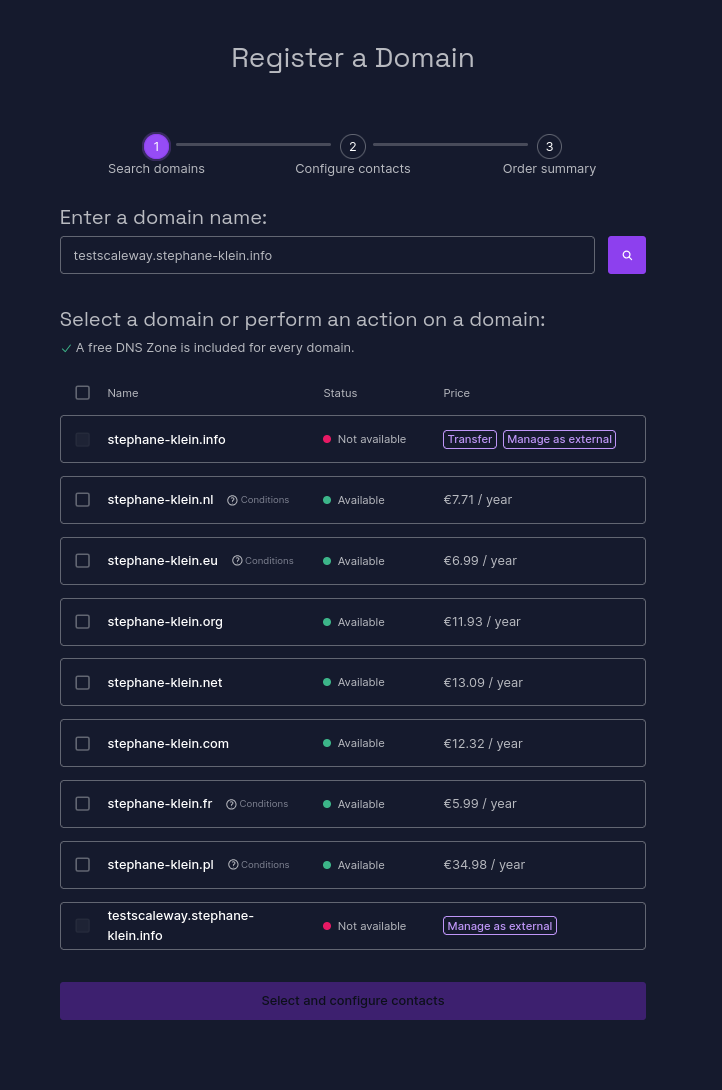
Je sélectionne la dernière entrée « Manage as external ».
Ensuite :
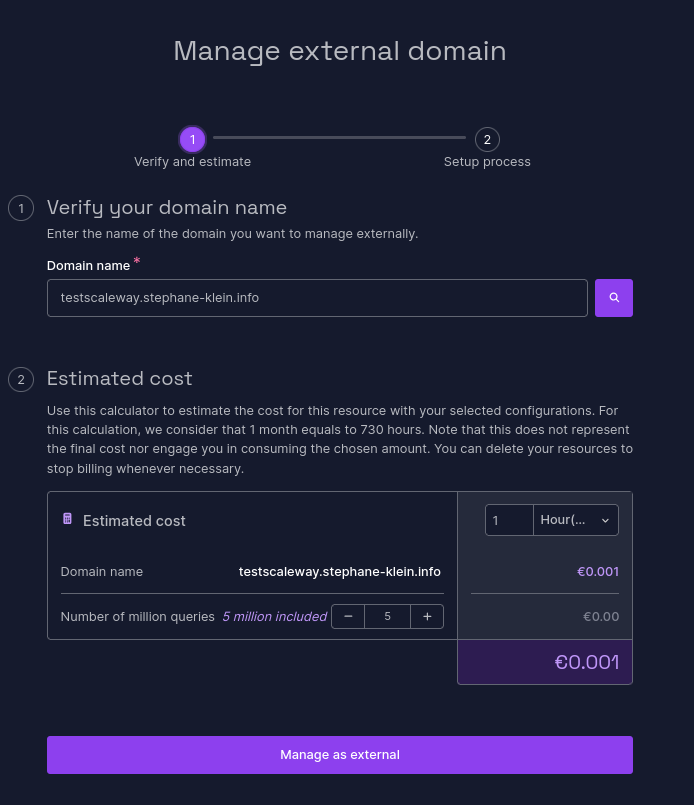

J'ai ajouté le DNS Record suivant à mon serveur DNS géré par cloudflare :
_scaleway-challenge.testscaleway.stephane-klein.info. 1 IN TXT "dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Vérification :
$ dig TXT _scaleway-challenge.testscaleway.stephane-klein.info +short
"dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Je n'ai aucune idée de la fréquencede passage du job Scaleway qui effectue la vérification de l'entrée TXT :
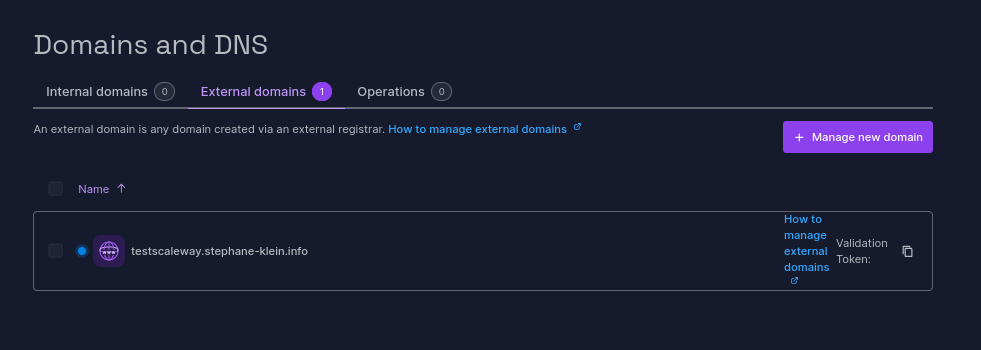
J'ai ajouté mon domaine à 22h22 et il a été validé à 22h54 :
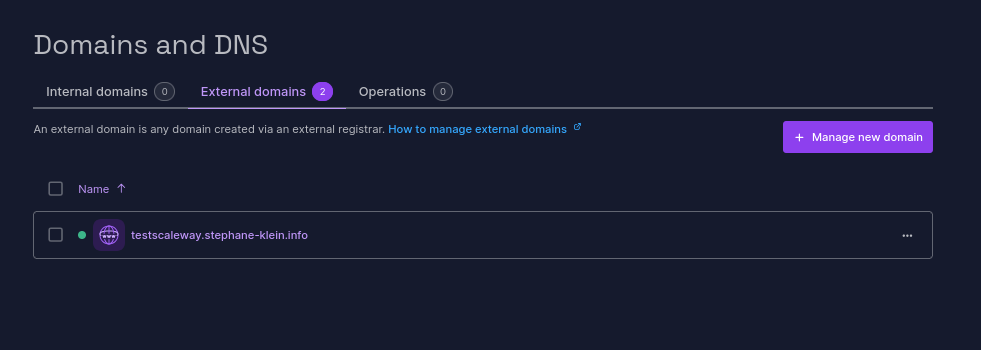
Ensuite, j'ai ajouté les DNS Records suivants :
testscaleway.stephane-klein.info. 1 IN NS ns1.dom.scw.cloud.
testscaleway.stephane-klein.info. 1 IN NS ns0.dom.scw.cloud.
Vérification :
$ dig NS testscaleway.stephane-klein.info +short
ns0.dom.scw.cloud.
ns1.dom.scw.cloud.
Ensuite, j'ai configuré dans la console Scaleway, le DNS Record :
test1 3600 IN A 8.8.8.8
Vérification :
$ dig test1.testscaleway.stephane-klein.info +short
8.8.8.8
Conclusion : la réponse est oui, le managed service Scaleway Domains and DNS permet la délégation de sous-domaines 🙂.
Quelle est la fonction de "/deployment-playground/" dans mes projets ?
L'objectif de cette note est d'expliquer ce que sont les dossiers /deployment-playground/ et ma pratique consistant à les intégrer dans la plupart de mes projets de développement web.
Je pense me souvenir que j'ai commencé à intégrer ce type de dossier vers 2018.
Au départ, je nommais ce dossier /demo/ dont l'objectif était le suivant : permettre à un développeur de lancer localement le plus rapidement possible une instance de démo complète de l'application.
Pour cela, ce dossier contenait généralement :
- Un
docker-compose.ymlqui permettait le lancer tous les services à partir des dernières images Docker déjà buildé. Soit les images de la version de l'environnement de développement, staging ou production. - Un script d'injection de données de fixtures ou de données spécifiques de démonstration.
- Mise à disposition des logins / password d'un ou plusieurs comptes utilisateurs.
Cet environnement était configuré au plus proche de la configuration de production.
Avec le temps, j'ai constaté que mon utilisation de ce dossier a évolué. Petit à petit, je m'en servais pour :
- Aider les développeurs à comprendre le processus de déploiement de l'application en production, en fournissant une représentation concrète des résultats des scripts de déploiement.
- Permettre aux développeurs de tester localement la bonne installation de l'application, afin de reproduire les conditions de production en cas de problème.
- Faciliter l'itération locale sur l'amélioration ou le refactoring de la méthode de déploiement.
- Et bien d'autres usages.
J'ai finalement décidé de renommer ce dossier deployment-playground, un bac à sable pour "jouer" localement avec la configuration de production de l'application.
Je ne peux pas vous partager mes exemples beaucoup plus complets qui sont hébergés sur des dépôts privés, mais voici quelques exemples minimalistes dans mes dépôts publics :
- https://github.com/stephane-klein/sveltekit-user-auth-postgres-rls-skeleton/tree/main/deployment-playground
- https://github.com/stephane-klein/sveltekit-ssr-skeleton/tree/main/deployment-playground
- https://github.com/stephane-klein/gibbon-replay/tree/main/deployment-playground
- https://github.com/stephane-klein/sveltekit-tendaro-webshell-skeleton/tree/main/deployment-playground
Je découvre la compression Zstandard
Un ami m'a partagé Zstandard (zstd), un algorithme de compression.
Il y a 2 ans, j'ai étudié et activé Brotli dans mes containers nginx, voir la note : Mise en œuvre du module Nginx Brotli.
Je viens de trouver un module zstd pour nginx : https://github.com/tokers/zstd-nginx-module
Mon ami m'a partagé cet excellent article : Choosing Between gzip, Brotli and zStandard Compression. Très complet, il explique tout, contient des benchmarks…
Voici ce que je retiens.
Brotli a été créé par Google, Zstandard par Facebook :
Je lis sur canIuse, le support Zstandard a été ajouté à Chrome en mars 2024 et à Firefox en mai 2024, c'est donc une technologie très jeune coté browser.
Benchmark sur le dépôt officiel de Zstandard :
J'ai trouvé ces threads Hacker News :
- 2020-05-07 : Introduce ZSTD compression to ZFS
- 2022-08-20 : AWS switch from gzip to zstd – about 30% reduction in compressed S3 storage
Zstandard semble être fortement adopté au niveau de l'écosystème des OS Linux :
In March 2018, Canonical tested the use of zstd as a deb package compression method by default for the Ubuntu Linux distribution. Compared with xz compression of deb packages, zstd at level 19 decompresses significantly faster, but at the cost of 6% larger package files. Support was added to Debian in April 2018
Packages Fedora :
#JeMeDemande si dans mes projets de doit utiliser Zstandard plutôt que Brotli 🤔.
Je pense avoir trouver une réponse ici :
The research I’ve shared in this article also shows that for many sites Brotli will provide better compression for static content. Zstandard could potentially provide some benefits for dynamic content due to its faster compression speeds. Additionally:
- ...
- For dynamic content
- Brotli level 5 usually result in smaller payloads, at similar or slightly slower compression times.
- zStandard level 12 often produces similar payloads to Brotli level 5, with compression times faster than gzip and Brotli.
- For static content
- Brotli level 11 produces the smallest payloads
- zStandard is able to apply their highest compression levels much faster than Brotli, but the payloads are still smaller with Brotli.
#JaimeraisUnJour prendre le temps d'installer zstd-nginx-module à mon image Docker nginx-brotli-docker (ou alors d'en trouver une déjà existante).
Alternatives managées à ngrok Developer Preview
Dans la note 2024-12-31_1853, j'ai présenté sish-playground qui permet de self host sish.
Je souhaite maintenant lister des alternatives à ngrok qui proposent des services gérés.
Quand je parle d'alternative à ngrok, il est question uniquement de la fonctionnalité d'origine de ngrok en 2013 : exposer des serveurs web locaux (localhost) sur Internet via une URL publique. ngrok nomme désormais ce service "Developer Preview".
Offre managée de sish
Les développeurs de sish proposent un service managé à 2 € par mois.
Ce service permet l'utilisation de noms de domaine personnalisés : https://pico.sh/custom-domains#tunssh.
Test de la fonctionnalité "Developer Preview" de ngrok
J'ai commencé par créer un compte sur https://ngrok.com.
Ensuite, une fois connecté, la console web de ngrok m'invite à installer le client ngrok. Voici la méthode que j'ai suivie sur ma Fedora :
$ wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz -O ~/Downloads/ngrok-v3-stable-linux-amd64.tgz
$ sudo tar -xvzf ~/Downloads/ngrok-v3-stable-linux-amd64.tgz -C /usr/local/bin
$ ngrok --help
ngrok version 3.19.0
$ ngrok config add-authtoken 2r....RN
$ ngrok http http://localhost:8080
ngrok (Ctrl+C to quit)
👋 Goodbye tunnels, hello Agent Endpoints: https://ngrok.com/r/aep
Session Status online
Account Stéphane Klein (Plan: Free)
Version 3.19.0
Region Europe (eu)
Web Interface http://127.0.0.1:4040
Forwarding https://2990-2a04-cec0-107a-ea02-74d7-2487-cc11-f4d2.ngrok-free.app -> http://localhost:8080
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00
Cette fonctionnalité de ngrok est gratuite.
Toutefois, pour pouvoir utiliser un nom de domaine personnalisé, il est nécessaire de souscrire à l'offre "personal" à $8 par mois.
Test de la fonctionnalité Tunnel de Cloudflare
Pour exposer un service local sur Internet via une URL publique avec cloudflared, je pense qu'il faut suivre la documentation suivante : Create a locally-managed tunnel (CLI).
J'ai trouvé sur cette page, le package RPM pour installer cloudflared sous Fedora :
$ wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-x86_64.rpm -O /tmp/cloudflared-linux-x86_64.rpm
$ sudo rpm -i /tmp/cloudflared-linux-x86_64.rpm
$ cloudflared --version
cloudflared version 2024.12.2 (built 2024-12-19-1724 UTC)
Voici comment exposer un service local sur Internet via une URL publique avec cloudflared sans même créer un compte :
$ cloudflared tunnel --url http://localhost:8080
...
Requesting new quick Tunnel on trycloudflare.com...
Your quick Tunnel has been created! Visit it at (it may take some time to be reachable):
https://manufacturer-addressing-surgeon-tried.trycloudflare.com
Après cela, le service est exposé sur Internet sur l'URL suivante : https://manufacturer-addressing-surgeon-tried.trycloudflare.com.
Voici maintenant la méthode pour exposer un service sur un domaine spécifique.
Pour cela, il faut que le nom de domaine soit géré pour les serveurs DNS de cloudflare.
Au moment où j'écris cette note, c'est le cas pour mon domaine stephane-klein.info :
$ dig NS stephane-klein.info +short
ali.ns.cloudflare.com.
sri.ns.cloudflare.com.
Ensuite, il faut lancer :
$ cloudflared tunnel login
Cette commande ouvre un navigateur, ensuite il faut se connecter à cloudflare et sélectionner le nom de domaine à utiliser, dans mon cas j'ai sélectionné stephane-klein.info.
Ensuite, il faut créer un tunnel :
$ cloudflared tunnel create mytunnel
Tunnel credentials written to /home/stephane/.cloudflared/61b0e52f-13e3-4d57-b8da-6c28ff4e810b.json. …
La commande suivante, connecte le tunnel mytunnel au hostname mytunnel.stephane-klein.info :
$ cloudflared tunnel route dns mytunnel mytunnel.stephane-klein.info
2025-01-06T17:52:10Z INF Added CNAME mytunnel.stephane-klein.info which will route to this tunnel tunnelID=67db5943-1f16-4b4a-a307-e8ceeb01296c
Et, voici la commande pour exposer un service sur ce tunnel :
$ cloudflared tunnel --url http://localhost:8080 run mytunnel
Après cela, le service est exposé sur Internet sur l'URL suivante : https://mytunnel.stephane-klein.info.
Pour finir, voici comment détruire ce tunnel :
$ cloudflared tunnel delete mytunnel
J'ai essayé de trouver le prix de ce service, mais je n'ai pas trouvé. Je pense que ce service est gratuit, tout du moins jusqu'à un certain volume de transfert de données.
Journal du samedi 28 décembre 2024 à 17:10
Comme mentionné dans la note 2024-12-28_1621, j'ai implémenté un playground nommé powerdns-playground.
J'ai fait le triste constat de découvrir encore un projet (PowerDNS-Admin) qui ne supporte pas une "automated and unattended installation" 🫤.
PowerDNS-Admin ne permet pas de créer automatiquement un utilisateur admin.
Pour contourner cette limitation, j'ai implémenté un script configure_powerdns_admin.py qui permet de créer un utilisateur basé sur les variables d'environnement POWERDNS_ADMIN_USERNAME, POWERDNS_ADMIN_PASSWORD, POWERDNS_ADMIN_EMAIL.
Le script ./scripts/setup-powerdns-admin.sh se charge de copier le script Python dans le container powerdns-admin et de l'exécuter.
J'ai partagé ce script sur :
- le SubReddit self hosted : https://old.reddit.com/r/selfhosted/comments/1hocrjm/powerdnsadmin_a_python_script_for_automating_the/?
- et le Discord de PowerDNS-Admin : https://discord.com/channels/1088963190693576784/1088963191574376601/1322661412882874418
Journal du samedi 28 décembre 2024 à 16:21
Je viens de tomber dans un Yak! 🙂.
Je cherchais des alternatives Open source à ngrok et j'ai trouvé sish (https://docs.ssi.sh/).
Côté client, sish utilise exclusivement ssh pour exposer des services (lien la documentation).
Voici comment exposer sur l'URL http://hereiam.tuns.sh le service HTTP exposé localement sur le port 8080 :
$ ssh -R hereiam:80:localhost:8080 tuns.sh
Je trouve cela très astucieux 👍️.
Après cela, j'ai commencé à étudier comment déployer sish et j'ai lu cette partie :
This includes taking care of SSL via Let's Encrypt for you. This uses the adferrand/dnsrobocert container to handle issuing wildcard certifications over DNS.
Après cela, j'ai étudié dnsrobocert qui permet de générer des certificats SSL Let's Encrypt avec la méthode DNS challenges, mais pour cela, il a besoin d'insérer et de modifier des DNS Record sur un serveur DNS.
Je n'ai pas envie de donner accès à l'intégralité de mes zones DNS à un script.
Pour éviter cela, j'ai dans un premier temps envisagé d'utiliser un serveur DNS managé de Scaleway, mais j'ai constaté que le provider Scaleway n'est pas supporté par Lexicon (qui est utilisé par dnsrobocert).
Après cela, j'ai décidé d'utiliser PowerDNS et je viens de publier ce playground : powerdns-playground.
Journal du lundi 23 décembre 2024 à 19:39
J'ai commencé le Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram le 9 octobre.
Le 27 octobre, j'ai publié la note 2024-10-27_2109 qui contient une erreur qui m'a fait perdre 14h !
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
[ 0.0] Examining the guest ...
[ 4.5] Setting a random seed
virt-customize: warning: random seed could not be set for this type of
guest
[ 4.5] Setting the machine ID in /etc/machine-id
[ 4.5] Installing packages: qemu-guest-agent
[ 32.1] Running: systemctl enable qemu-guest-agent.service
[ 32.6] Finishing off
Je n'avais pas fait attention au message Setting the machine ID in /etc/machine-id 🙊.
Conséquence : le template Proxmox Ubuntu contenait un fichier /etc/machine-id avec un id.
Conséquence : toutes les Virtual machine que je créais sous Proxmox avaient la même valeur machine-id.
J'ai découvert que l'option 61 "Client identifier" du protocole DHCP permet de passer un client id au serveur DHCP qui sera utilisé à la place de l'adresse MAC.
Conséquence : le serveur DHCP assignait la même IP à ces Virtual machine.
J'ai pensé que le serveur DHCP de mon router BBox avait un problème. J'ai donc décidé d'installer Projet 15 - Installation et configuration de OpenWrt sur Xiaomi Mi Router 4A Gigabit pour avoir une meilleure maitrise du serveur DHCP.
Problème : j'ai fait face au même problème avec le serveur DHCP de OpenWrt.
Après quelques recherches, j'ai découvert que contrairement à virt-customize la commande virt-sysprep permet d'agir sur des images qui ont vocation à être clonées.
"Sysprep" stands for "system preparation" tool. The name comes from the Microsoft program sysprep.exe which is used to unconfigure Windows machines in preparation for cloning them.
Pour corriger le problème, j'ai remplacé cette ligne :
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Par ces deux lignes :
# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
La seconde commande permet de supprimer le fichier /etc/machine-id, ce qui corrige le problème d'attribution d'IP par le serveur DHCP.
À noter que je ne comprends pas pourquoi il est nécessaire de lancer explicitement cette seconde commande, étant donné que la commande virt-sysprep est destinée aux images de type "template". Le fichier /etc/machine-id ne devrait jamais être créé, ou tout du moins, automatiquement supprimé à la fin de chaque utilisation de virt-sysprep.
Maintenant, l'instanciation de Virtual machine fonctionne bien, elles ont des IP différentes 🙂.
Prochaine étape du Projet GH-271 :
Je souhaite arrive à effectuer un déploiement d'une Virtual instance via cli de Terraform.
Journal du dimanche 22 décembre 2024 à 18:11
Alexandre m'a partagé l'article "Proxmox - Activer les mises à jour sans abonnement (no-subscription)".
Élément que je retiens :
Le processus de validation des paquets chez Proxmox est le suivant : Test -> No-Subscription -> Enterprise. Le dépôt No-Suscription est donc suffisamment stable. L'avertissement est à mon avis pour mettre hors cause l'équipe de Proxmox en cas de trou dans la raquette lors des tests de validation.
$ ssh root@192.168.1.43
# cat <<EOF > /etc/apt/sources.list.d/proxmox.list
deb http://download.proxmox.com/debian/pve bookworm pve-no-subscription
EOF
# rm /etc/apt/sources.list.d/pve-enterprise.list
# rm /etc/apt/sources.list.d/ceph.list
# apt update -y
# apt upgrade -y
...
# reboot
Pour supprimer le message de warning au login, sur la version 8.3.2, j'ai appliqué le patch suivant :
# patch /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js <<EOF
--- /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js.old 2024-12-22 18:23:48.951557867 +0100
+++ /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js 2024-12-22 18:18:50.509376748 +0100
@@ -563,6 +563,7 @@
let res = response.result;
if (res === null || res === undefined || !res || res
.data.status.toLowerCase() !== 'active') {
+ /*
Ext.Msg.show({
title: gettext('No valid subscription'),
icon: Ext.Msg.WARNING,
@@ -575,6 +576,7 @@
orig_cmd();
},
});
+ */
} else {
orig_cmd();
}
EOF
# systemctl restart pveproxy
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞
Le 6 novembre 2024, j'ai publié la note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
L'issue indiquée dans cette note a été cloturée il y a 3 jours : Use mise tools in env template · Issue #1982.
Voici le contenu de changement de la documentation : https://github.com/jdx/mise/pull/3598/files#diff-e8cfa8083d0343d5a04e010a9348083f7b64035c407faa971074c6f0e8d0d940
Ce qui signifie que je vais pouvoir maintenant utiliser terraform installé via Mise dans le fichier .envrc :
[env]
_.source = { value = "./.envrc.sh", tools = true }
[tools]
terraform="1.9.8"
Après avoir installé la dernière version de Mise, j'ai testé cette configuration dans repository suivant : install-and-configure-mise-skeleton.
Le fichier .envrc suivant a fonctionné :
export HELLO_WORLD=foo3
export NOW=$(date)
export TERRAFORM_VERSION=$(terraform --version | head -n1)
Exemple :
$ mise trust
$ echo $TERRAFORM_VERSION
Terraform v1.9.8
Je n'ai pas trouvé de commande Mise pour recharger les variables d'environnement du dossier courant, sans quitter le dossier. Avec direnv, pour effectuer un rechargement je lançais : direnv allow.
À la place, j'ai trouvé la méthode suivante :
$ source .envrc
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Journal du jeudi 19 décembre 2024 à 16:40
#JaiDécouvert le format de fichier Bake de Docker : https://docs.docker.com/build/bake/introduction/.
Je ne comprends pas bien son utilité 🤔.
La commande suivante me convient parfaitement :
$ docker build \
-f Dockerfile \
-t myapp:latest \
--build-arg foo=bar \
--no-cache \
--platform linux/amd64,linux/arm64 \
.
J'ai essayé de trouver l'issue d'origine du projet Bake, pour connaitre ses motivations, mais je n'ai pas trouvé.
Comment lancer une image Docker de l'architecture "arm64" sous Intel ?
#JeMeDemande comment lancer une image Docker pour l'architecture arm64 sur une architecture Intel sous Fedora ?
Par défaut, l'exécution de cette image Docker sous Intel avec l'option --platform linux/arm64 ne fonctionne pas :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
exec /usr/bin/bash: exec format error
J'ai consulté et suivi la documentation Docker officielle suivante : Install QEMU manually.
$ docker run --privileged --rm tonistiigi/binfmt --install all
installing: arm64 OK
installing: arm OK
installing: ppc64le OK
installing: riscv64 OK
installing: mips64le OK
installing: s390x OK
installing: mips64 OK
{
"supported": [
"linux/amd64",
"linux/arm64",
"linux/riscv64",
"linux/ppc64le",
"linux/s390x",
"linux/386",
"linux/mips64le",
"linux/mips64",
"linux/arm/v7",
"linux/arm/v6"
],
"emulators": [
"qemu-aarch64",
"qemu-arm",
"qemu-mips64",
"qemu-mips64el",
"qemu-ppc64le",
"qemu-riscv64",
"qemu-s390x"
]
}
Après cela, je constate que j'arrive à lancer avec succès une image arm64 sous processeur Intel :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
root@bf74bfb8bc35:/# graphql-engine version
Hasura GraphQL Engine (Pro Edition): v2.43.0
J'ai pris un peu de temps pour explorer le repository tonistiigi/binfmt.
Je n'ai pas compris quelle est l'interaction entre les éléments installés par cette image et docker-engine.
Je constate que cette image a été créée en 2019 par deux développeurs de Docker : CrazyMax (un Français) et Tõnis Tiigi.
Journal du dimanche 08 décembre 2024 à 22:19
Je viens de rencontrer l'outil envdir (à ne pas confondre avec direnv) et son modèle de stockage de variables d'environnement, que je trouve très surprenant !
direnv ou dotenv utilisent de simples fichiers texte pour stocker les variables d'environnements, par exemple :
export POSTGRES_URL="postgres://postgres:password@localhost:5432/postgres"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export MAIL_FROM="noreply@example.com"
Contrairement à ces deux outils, pour définir ces quatre variables, le modèle de stockage de envdir nécessite la création de 4 fichiers :
$ tree .
.
├── MAIL_FROM
├── POSTGRES_URL
├── SMTP_HOST
└── SMTP_PORT
1 directory, 4 files
$ cat POSTGRES_URL
postgres://postgres:password@localhost:5432/postgres
$ cat SMTP_HOST
127.0.0.1
$ cat SMTP_PORT
1025
$ cat MAIL_FROM
127.0.0.1
Je trouve ce modèle fort peu pratique. Contrairement à un simple fichier unique, le modèle de envdir présente certaines limitations :
- Organisation : il ne permet pas de structurer librement l'ordre ou de regrouper visuellement les variables.
- Lisibilité : l'ensemble de la configuration est plus difficile à visualiser d'un seul coup d'œil.
- Manipulation : copier ou coller son contenu n'est pas aussi direct qu'avec un fichier texte.
- Documentation : les commentaires ne peuvent pas être inclus pour expliquer les variables.
- Rapidité : la saisie ou la modification de plusieurs variables demande plus de temps, chaque variable étant dans un fichier distinct.
J'ai été particulièrement intrigué par le choix fait par l'auteur de envdir. Sa décision semble vraiment surprenante.
envdir fait partie du projet daemontools, créé en 1990. Ainsi, il est bien plus ancien que dotenv, qui a été lancé autour de 2010, et direnv, qui date de 2014.
Si je me remets dans le contexte des années 1990, je pense que le modèle de envdir a été avant tout motivé par une simplicité d'implémentation plutôt que d'utilisation. En effet, il est plus facile de lister les fichiers d'un répertoire et de charger leur contenu que de développer un parser de fichiers.
Je pense qu'en 2024, envdir n'a plus sa place dans un environnement informatique moderne. Je recommande vivement de le remplacer par des solutions plus récentes, comme devenv ou direnv.
Personnellement, j'utilise direnv dans tous mes projets.
Journal du dimanche 03 novembre 2024 à 18:35
Dans le tutoriel "Proxmox Template with Cloud Image and Cloud Init", #JaiDécouvert un usage de la commande virt-customize :
# wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Je trouve cela extrêmement pratique, cela évite de devoir utiliser Packer pour personnaliser une image disque.
J'ai fait quelques recherches et j'ai appris que la fonctionnalité d'installation de package est ancienne, elle a été implémentée dans libguestfs en 2014 par Richard Jones, employé de chez Red Hat (auteur de libguestfs).
Journal du mercredi 30 octobre 2024 à 10:21
Je garde trace dans cette notes de deux plugins Asdf / Mise que j'ai utilisé avec succès ces deux derniers jours.
Le premier, pour installer la cli de Hasura : asdf-hasura
$ mise plugin add hasura-cli https://github.com/gurukulkarni/asdf-hasura.git
Contenu de .mise.toml :
[tools]
hasura-cli = "2.43.0"
$ mise install
$ hasura version
INFO hasura cli version=v2.43.0
Le second, pour installer Gitleaks : asdf-gitleaks
$ mise plugin add gitleaks https://github.com/jmcvetta/asdf-gitleaks.git
Contenu de .mise.toml :
[tools]
gitleaks = "8.21.2"
$ mise install
$ gitleaks --version
gitleaks version 8.21.2
Vous êtes sur la première page | [ Page suivante (69) >> ]