
Journaux
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
Résultat de la recherche (4 notes) :
Vendredi 16 mai 2025
Journal du vendredi 16 mai 2025 à 13:31
Je me suis posé la question suivante : « Qui contribue au projet Open WebUI ? »
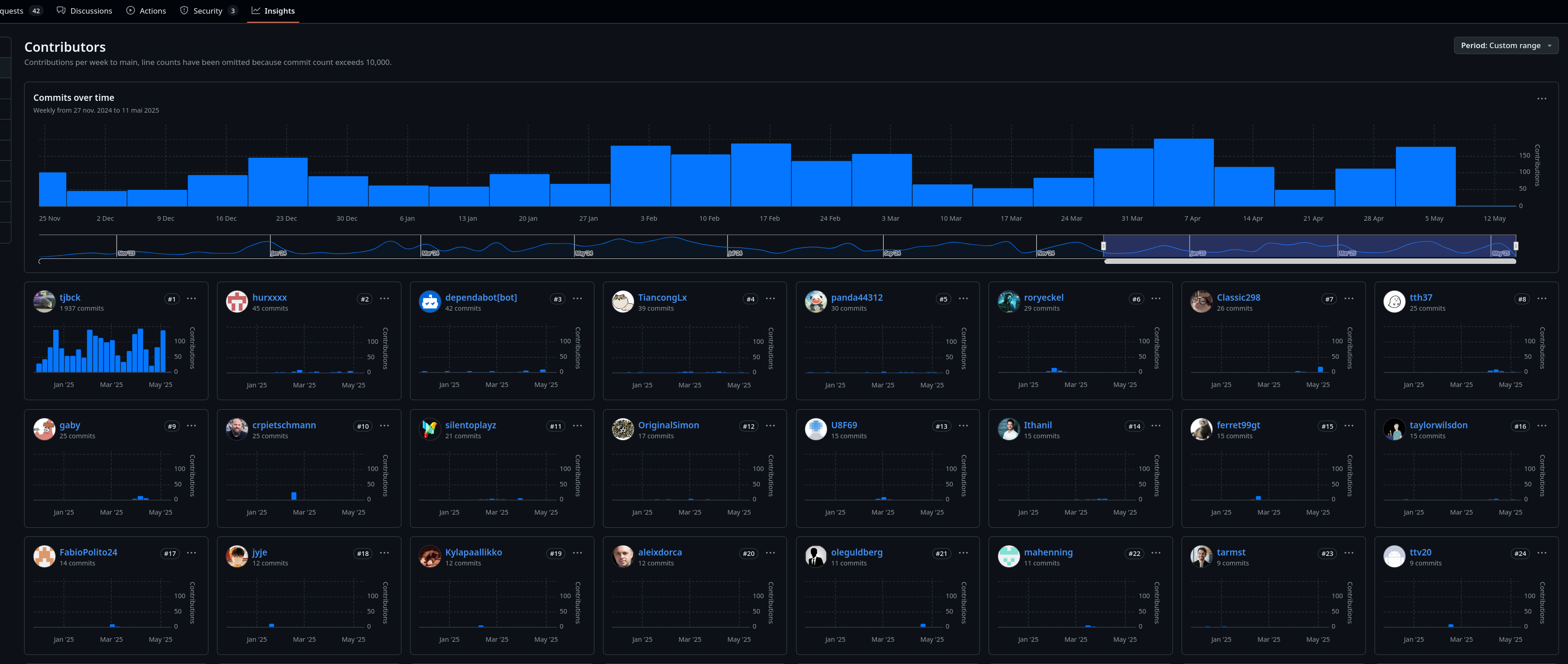
Si je regarde les contributions au projet, je constate que, à la louche, 95% du repository /open-webui/open-webui/ et /pipelines/graphs/ est réalisé par Tim Jaeryang Baek.
Contributions au dépôt /open-webui/open-webui/ :
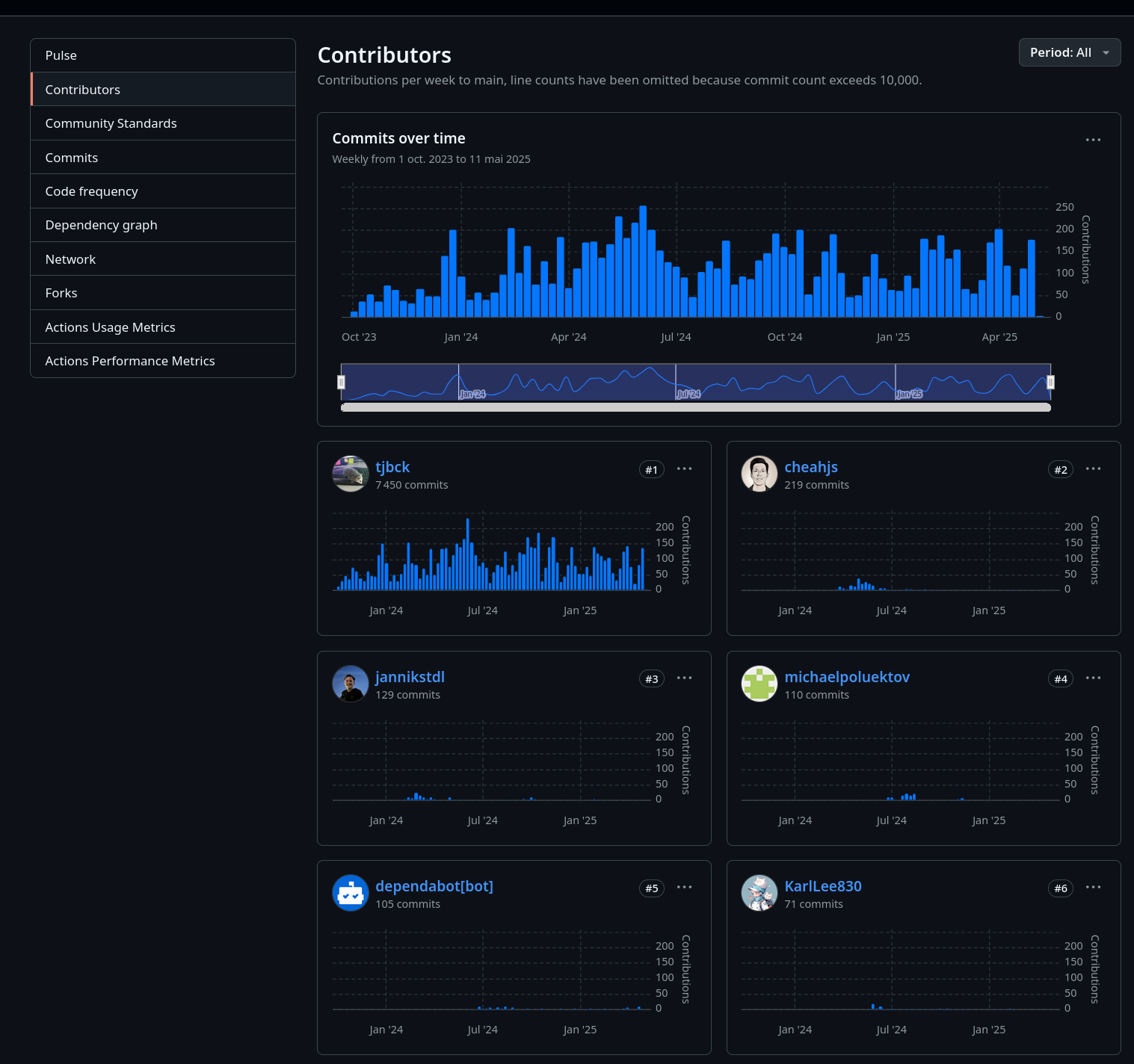
Contributions au dépôt /open-webui/open-webui/ sur les 6 derniers mois :
D'après la section "People" de la page LinkedIn "Open WebUI", James W. semble être dédié et peut-être rémunéré pour travailler sur /open-webui/helm-charts/.
Voici mon estimation de Fermi de calcul du coût de développement d'Open WebUI (seulement ce composant) :
- Estimation du taux journalier de Tim Jaeryang Baek : bien que Tim a commencé depuis peu sa carrière professionnelle, je pense qu'il n'aurait pas de difficulté à trouver des missions entre 500 et 1000 € HT la journée.
- Le dépôt Open WebUI a reçu ses premiers commits le 1ᵉʳ octobre 2023. Cela fait 20 mois de travail.
- Si j'estime, 20 jours de travail par mois sans vacances, j'obtiens 400 jours de travail
- J'obtiens un coût total entre :
- 500 x 400 = 200 000 €
- 1000 x 400 = 400 000 €
Je tiens à préciser que ce montant n'a pas de lien avec une valeur économique d'usage, ni une valeur d'échange.
Comme on a pu le voir au début de cette note, ce projet a été développé par une seule personne, réduisant considérablement les "frais de couplage" (coûts liés à la coordination, communication et synchronisation entre développeurs, management, recrutement…). Si ce même projet avait été réalisé au sein d'une startup, son coût aurait été d'un ordre de grandeur nettement supérieur. Selon mon estimation, il aurait été multiplié par 50, voire davantage.
Mardi 12 novembre 2024
Journal du mardi 12 novembre 2024 à 23:35
#OnMaPartagé l'article « Budget 2025 : le coup de rabot sur l'avantage fiscal de l'actionnariat salarié adopté » (BSPCE).
Mais l'article 25 de la loi de finances bouscule ce schéma en revenant en partie sur le sursis d'impôt.
Source de l'article 25 :
- Dans la page https://www.budget.gouv.fr/documentation/documents-budgetaires/exercice-2025/projet-loi-finances-les-0
- Dans le PDF « Le projet de loi de finances (PLF) pour 2025 »
- Article 25 se trouve à la page 129
Concrètement, les gains d'exercice - se manifestant lorsque le salarié exerce son option d'achat à un prix plus faible que la valeur de marché de l'action au jour de cet exercice - seraient imposés au moment de l'apport des titres à la société rachetant l'entreprise. Tandis que les gains de cession - qui surviennent si l'action continue à s'apprécier après l'usage des BSPCE - bénéficieraient toujours du sursis d'imposition.
-- from
Voici ce que j'ai compris.
Imaginons le scénario suivant :
- Bob rejoint "ma super entreprise" en janvier 2020
- Bob reçoit 100 actions à 5 € l'unité, sous forme de BSPCE
- Janvier 2024, Bob a "vesté" à 100% ses BSPCE
- Février 2024, une action de "ma super entreprise" a pour valeur 100 €. Bob décide d'exercer son option d'achat de ses 100 actions. Bob doit débourser 500 € pour (prix de départ) acheter ses 100 actions. Valeur de gain d'exercice : (100 actions * 100 €) - 500 € = 9500 €
- À ce moment-là, ces 9500 € de gains ne sont pas imposables.
- Septembre 2025, "ma super entreprise" est rachetée par "la grosse enterprise", au prix de 200 € l'action. Voici comment calculer les gains de session : 100 actions * (prix de l'action lors du rachat par l'entreprise - prix de l'action au moment de l'achat des actions) ce qui donne : 100 actions * (200 € - 100 €) = 10 000 €
- Mai 2026, Bob doit déclarer aux impôts ses gains d'exercice, qui correspondent à 9500 €, Bob sera imposé sur cette somme. Par contre, Bob ne devra pas déclarer son gain de session, dont le montant est de 10 000 €.
- Juin 2028, Bob vend toutes ses actions "la grosse entreprise". Le prix de l'action est de 400 €. Bob reçoit 100 actions * 400 € = 40 000 €
- Mai 2029, Bob doit déclarer aux impôts ses gains de session, dont le montant est 40 000 € - 9 500 € = 30 500 € Bob sera imposé sur ce gain de 30 500 €.
Voici ce qui aurait changé dans ce scénario avant l'application de l'article 25 du projet de loi de finance 2025 :
- En mai 2026, Bob n'aurait pas eu besoin de déclarer ses gains d'exercice de 9 500 €
- En mai 2029, Bob aurait dû déclarer aux impôts non pas 30 500 €, mais 40 000 €.
Lorsque mon ami m'a parlé de ce changement de loi, je pensais que Bob devait payer des impôts sur les 9 500 € de gains dès février 2024. Cependant, il s'avère que ce n'est pas le cas. Les impôts ne sont dus qu'au moment où les titres sont apportés à la société qui rachète l'entreprise, c'est-à-dire lorsque "la grosse entreprise" acquiert les actions de Bob. À ce moment-là, Bob a la possibilité de choisir de ne pas réinvestir la totalité de la valeur de ses actions dans "la grosse entreprise".
Finalement, je trouve cette modification de la règle fiscale moins illogique que ce que j'avais initialement pensé.
Mercredi 31 juillet 2024
Journal du mercredi 31 juillet 2024 à 11:11
Une amie m'a demandé ce que je pense de cette déclaration :
« Selon moi, la résolution de problème se déroule en deux étapes : d'abord, on traite les symptômes. Si le problème persiste, on prend plus de temps pour en identifier et résoudre la cause profonde.
Cette doctrine est particulièrement adapté aux Startup ».
Cette question de fait penser à la citation du chapitre "Quick Fixes Become Quicksand" du livre Practices of an Agile Developer :
« You don't need to really understand that piece of code; it seems, to work OK as is. Oh, but it just needs one small tweak. Just add one to the result, and it works. Go ahead and put that in; it's probably fine. »
De mon expérience — dans le domaine du software engineering —, le bon dosage de l'usage des Quick Fixes, QuickWin est une source de désacord classique au sein d'une organisation.
Et ceci arrive d'autant plus lorsqu'une équipe est dans sa période de storming.
La lecture du chapitre Quick Fixes Become Quicksand en 2007 m'a beaucoup marqué et ne m'a jamais quitté depuis, je peux dire qu'il fait parti de ma doctrine d'artisan développeur.
Voici-ci dessous les screenshot et la version texte de ce chapiter.
(cliquer ici pour voir ces screenshots en grand)

Voici la version texte de ce chapitre.
Quick Fixes Become Quicksand
You don't need to really understand that piece of code; it seems, to work OK as is. Oh, but it just needs one small tweak. Just add one to the result, and it works. Go ahead and put that in; it's probably fine.”
We've all been there. There's a bug, and there's time pressure. The quick fix seems to work— just add one or ignore that last entry in the list, and it works OK for now. But what happens next distinguishes good programmers from crude hackers.
The crude hacker leaves the code as is and quickly moves on to the next problem.
The good programmer will go to the next step and try to understand why that +1 is necessary, and—more important—what else is affected.
Now this might sound like a contrived, even silly, example, except that it really happened — on a large scale. A former client of Andy's had this very problem. None of the developers or architects understood the underlying data model of their domain, and over the course of several years the code base became littered with thousands of +1 and -1 corrections. Trying to add features or fix bugs in that mess was a hair-pulling nightmare (and indeed, many of the developers had gone bald by then).
But like most catastrophes, it didn't get like that all at once. Instead, it happened one quick fix at a time. Each quick fix — which ignored the pervasive, underlying problem — added up to a swamp-like morass of quicksand that eventually sucked the life out of the project.
« Beware of land mines »
Shallow hacks are the problem — those quick changes that you make under pressure without a deep understanding of the true problem and any possible consequences. It's easy to fall prey to this temptation: the quick fix is a very seductive proposition. With a short enough lens, it looks like it works. But in any longer view, you may as well be walking across a field strewn with land mines. You might make it halfway across — or even more — and everything seems fine. But sooner or later...
As soon as that quick hack goes in, the clarity of the code goes down. Once a number of those pile up, clarity is out the window, and opacity takes over. You've probably worked places where they say, “Whatever you do, don’t touch that module of code. The guy who wrote it is no longer here, and no one knows how it works.” There's no clarity. The code is opaque, and no one can understand it.
You can't possibly be agile with that kind of baggage. But some agile techniques can help prevent this from happening. We'll look at these in more depth in later chapters, but here's a preview.
Isolation is dangerous; don’t let your developers write code in complete isolation (see Practice 40, Practice Collective Ownership, on page 155). If team members take the time to read the code that their colleagues write, they can ensure that it's readable and understandable—and isn’t laced with arbitrary “+1s and -1s”. The more frequently you read the code, the better. These ongoing code reviews not only help make the code understandable but they are also one of the most effective ways of spotting bugs (see Practice 44, Review Code, on page 165).
The other major technique that can help prevent opaque code is unit testing. Unit testing helps you naturally layer the code into manageable pieces, which results in better designed, clearer code. Further into the project, you can go back and read the unit tests — they're a kind of executable documentation (see Practice 19, Put Angels on Your Shoulders, on page 78). Unit tests allow you to look at smaller, more comprehensible modules of code and help you get a thorough understanding by running and working with the code.
Conseil de petit ange : A Don't fall for the quick hack. Invest the energy to keep code clean and out in the open.
What It Feels Like
It feels like the code is well lit; there are no dark corners in the project. You may not know every detail of every piece of code or every step of every algorithm, but you have a good general working knowledge. No code is cordoned off with police tape or “Keep Out” signs.
Keeping Your Balance
- You need to understand how a piece of code works, but you don't necessarily have to become an expert at it. Know enough to work with it effectively, but don't make a career of it.
- If a team member proclaims that a piece of code is too hard for anyone else to understand, then it will be too hard for anyone (including the original author) to maintain. Simplify it.
- Never kludge in a fix without understanding. The +1/-1 syndrome starts innocently enough but rapidly escalates into an opaque mess. Fix the problem, not the symptom.
- Most nontrivial systems are too complex for any one person to understand entirely. You need to have a high-level understanding of most of the parts in order to understand what pieces of the system interact with each other, in addition to a deeper understanding of the particular parts on which you're working.
- If the system has already become an opaque mess, follow the advice given in Practice 4, Damn the Torpedoes, Go Ahead, on page 23.
Andy Says : Understand Process. Too
Although we're talking about understanding code, and especially understanding code well before you make changes to it, the same argument holds for your team’s methodology or development process.
You have to understand the development methodology in use on your team. You have to understand how the methodology in place is supposed to work, why things are the way they are, and how they got that way.
Only with that understanding can you begin to make changes effectively.
Mon point de vue plus détaillé
Voici une version plus personnelle de ma philosophie — ma doctrine d'artisan développeur — à ce sujet. Je précise qu'elle est bien plus longue que ce que j'avais prévu et qu'elle dépasse la question de départ de mon ami… oui, je suis tombé dans un Yak! 🙂.
J'accepte d'utiliser des Quick Fixes — même sans bien comprendre le problème — dans les situations suivantes :
- Dans un Proof of Concept ou un code exploratoire ;
- Dans une application ou un composant d'application destiné à être rapidement abandonné ;
- En cas d'urgence, si le bug impacte les clients. Dans ce cas, j'applique un Quick Fixes en production, puis, je m'efforce, dans un second temps, de comprendre et de corriger correctement le problème par la suite ;
- Si je suis solo développeur sur l'application et que celle-ci n'est pas critique pour le client.
D'après mon expérience, lorsque le développement d'une application est fait en équipe, l'accumulation de Quick Fixes entraîne rapidement :
-
Une perte de contrôle — analogie "des sables mouvants" dans l'article.
-
Un risque de perte de confiance de l'équipe, surtout des nouveaux venus en période de storming : voir le concept sociologique de l'hypothèse de la vitre brisée.
-
Risque de "game over de la partie de Tetris", voir l'article La dette technique est comme une partie de Tetris.
Je tiens à préciser que la solution « On le fera plus tard quand on aura le temps » n'arrive jamais.
En 20 ans d'expérience, j'ai toujours travaillé dans des organisations où l'urgence était la norme. L'urgence permanente est tout ce que j'ai connu. Je pense que cela reflète la nature humaine.
Ainsi, la déclaration « Oui, mais nous, c'est différent, tu comprends, on n'a pas le temps » n'a pas de sens à mes yeux, car c'est le cas pour tout le monde.
Avec le temps, j'ai construit la doctrine suivante pour gérer les Quick Fixes et donc la dette technique en équipes :
- a. Durant toute la vie du projet, accorder entre 20 et 40% du temps — "de l'énergie" — au traitement de la dette technique.
- b. Si une dette jugée critique ne peut pas être traitée durant ce temps imparti, je propose de l'expliquer au Product Management et éventuellement à la direction afin qu'un choix stratégique soit fait pour lui allouer plus de temps en la priorisant comme objectif de Sprint (scrum).
Par expérience, j'observe que si la règle a est appliquée, alors la situation b se produit exceptionnellement.
L'itération pour éviter de tomber dans l'overthinking et l'overengineering !
Je pense qu'un certain nombre de leaders de startup créent un climat d'urgence pour éviter que les développeurs tombent dans de l'overthinking et de l'overengineering.
Bien que cette approche soit compréhensible, j'ai personnellement une autre méthode pour éviter ces écueils sans recourir à l'urgence.
Ma solution pour éviter de tomber dans ces travers sont :
- l'itération ;
- le time boxing, autrement dit l'utilisation de spikes ou la définition de l'appétit d'un sprint ;
- sensibiliser les développeurs aux Yak!.
Par itération, j'entends la livraison du plus petit Incrément (Scrum) possible et sa mise en production dès que possible.
Le choix du plus petit incrément possible doit être associé aux principes Keep it simple, stupid! (KISS) et You aren't gonna need it (YAGNI).
L'esprit marathon en meuthe plutôt que des courses de 100m !
Comme le dit la Loi de Gall, je pense que :
Un système complexe qui fonctionne se trouve invariablement avoir évolué depuis un système simple qui fonctionnait. La proposition inverse se révèle également exacte : Un système complexe développé de A à Z ne fonctionne jamais et vous n'arriverez jamais à le faire fonctionner. Vous devez recommencer depuis le début, en commençant par un système simple.
Ici j'entends par "système complexe" à la fois le logiciel et l'organisation humaine.
Je crois également à « New systems mean new problems ».
Depuis des années, j'observe de nombreuses startups en situation d'urgence vivre des cycles sans fin de reboot — une fois par an ou tous les deux ans —, accompagnés d'un turnover élevé.
Les projets sont constamment recommencés à zéro, avec de nouvelles équipes.
Je doute fortement que le pari de la vitesse — la course de 100m — soit plus efficace que celui du marathon.
Attention à bien identifier les projets et phases d'explorations !
Il m'est arrivé à plusieurs reprises de ne pas identifier correctement les signaux faibles indiquant qu'un projet dont j'avais la responsabilité devait en réalité être traité comme un projet d'exploration..
Je pense que les projets d'exploration ne doivent pas être traités comme des courses de 100 mètres, mais plutôt comme des spikes — prototypes.
J'insiste sur l'utilisation du terme Spike pour bien communiquer :
- Aux décideurs — stakeholder — que l'implémentation de ce projet n'est pas destinée à être conservée sur le long terme. Si l'exploration est concluante, le projet sera recommencé à zéro et attribué à une équipe dédiée.
- Aux développeurs qu'ils peuvent échouer, que le code peut contenir des bugs et être développé avec une grande dette technique.
- Aux utilisateurs qu'il est fort probable que l'application contienne des bugs ou que l'User experience ne soit pas optimale.
Ces messages sont souvent difficiles à faire passer, et c'est sans doute pour se protéger que les développeurs choisissent souvent de traiter le projet comme un projet pérenne de long terme plutôt que comme un spike.
De plus, je constate que les décideurs pensent souvent que leur idée est valide et ne jugent pas utile de réaliser des prototypes. Ce n'est souvent qu'après 1 ou 2 ans de vie de la startup que les décideurs considèrent rétrospectivement que les premières versions étaient des prototypes. Problème : ces premières versions n'ont pas été développées comme des prototypes.
Jeudi 15 juin 2023
Journal du jeudi 15 juin 2023 à 17:34
J'ai lu cet article de Ploum : De la merdification des choses.
Je fais le même constat que Ploum 👌.
Fin de la liste des notes.