
Journaux liées à cette note :
Premier test minimaliste de Promptfoo avec le provider OpenCode SDK
Depuis au moins novembre 2025, je cherche à rédiger mes prompts, mes fichiers AGENTS.md, mes fichiers SKILLS.md — et plus largement mon harness OpenCode — avec une méthode rigoureuse et contrôlée. J'ai découvert dans cette issue le nom du mécanisme que j'essaie de mettre en place : agent-eval-harness, terme plutôt simple et explicite.
En février, je disais :
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Quelques mois plus tard, j'ai enfin implémenté un premier POC utilisant Promptfoo couplé avec le provider OpenCode SDK : https://github.com/stephane-klein/opencode-promptfoo-poc.
Cette première itération est volontairement minimaliste. J'ai testé :
- 3 LLMs (dans 2 configurations chacune)
- 3 cas de test
L'intégralité de mon évaluation tient dans un seul fichier promptfooconfig.yaml :
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: "Hello World - minimal test"
providers:
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
prompts:
- "Translate the following English text to {{language}}: {{input}}"
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-all
value:
- "Bonjour"
- "monde"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: contains-any
value:
- "Donde esta la biblioteca"
providers:
- "with-agent*"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: not-contains-any
value:
- "Donde esta la biblioteca"
providers:
- "without-agent*"
L'exécution de promptfoo eval donne ceci :
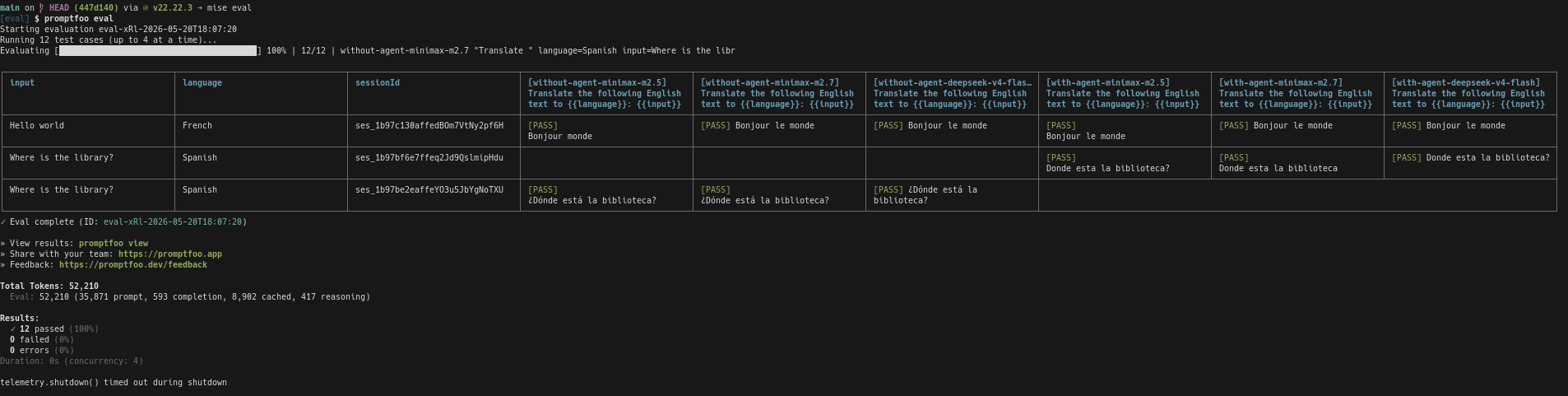
Et voici ce qu'affiche promptfoo viewer dans un browser :
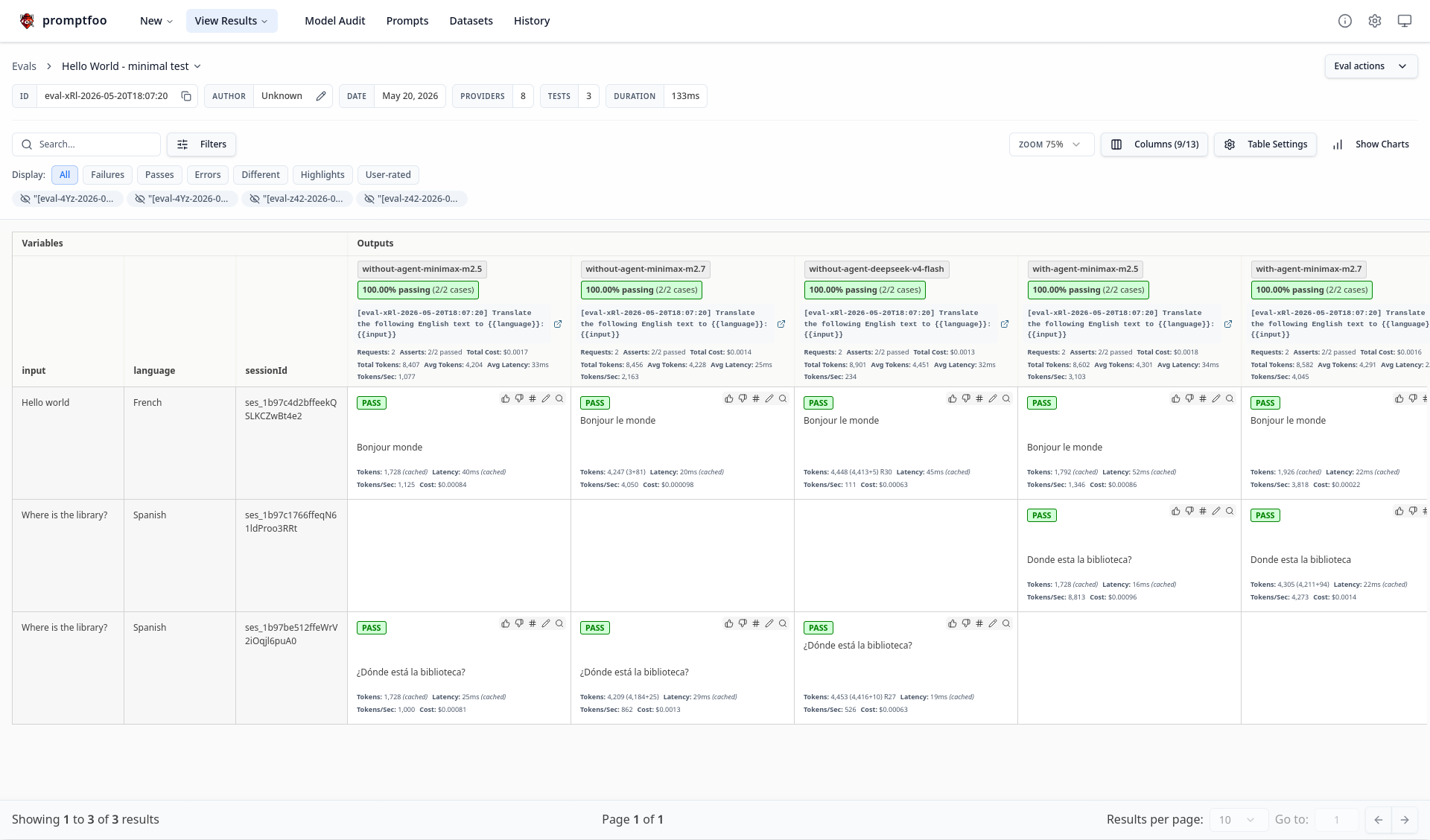
Dans mes tests, j'ai mis en œuvre uniquement contains-all et contains-any, mais Promptfoo propose beaucoup d'autres « Deterministic metrics ».
Promptfoo propose aussi de nombreuses assertions effectuées par des modèles de langage, les « Model-graded metrics », dont la plupart peuvent être qualifiées de LLM-as-a-Judge. Je ne les ai pas encore testées.
Je n'ai pas non plus exploré l'évaluation de « Chat conversations / threads ». Par ailleurs, en examinant la documentation du provider OpenCode SDK, j'ai constaté ce qui me semble être une limitation : il n'est probablement pas possible de changer d'agent dans un thread, c'est-à-dire d'alterner entre le mode plan et le mode build, comme on le ferait dans un usage normal de OpenCode.
Mais après réflexion, il me semble que cette limitation n'est pas importante. Dans un test d'évaluation, chaque cas est un appel unique à l'agent, avec l'historique complet de la conversation fourni en contexte — il n'est pas nécessaire de simuler un flux interactif multi-tours avec alternance d'agents.
Dans ce POC, je configure le provider OpenCode SDK pour qu'il utilise le dossier de configuration ./config/opencode du repository, afin que le harness évalué soit précisément celui qui est versionné, et afin de ne pas subir de perturbation par la configuration OpenCode globale.
Quand j'ai démarré ce POC, j'ai essayé d'indiquer différentes configurations OpenCode au niveau des tests, pour tester différents fichiers AGENTS.md. Mais j'ai constaté que la configuration OpenCode ne peut être définie qu'une seule fois, ici, via une variable d'environnement XDG_CONFIG_HOME.
J'ai mis un certain temps à réaliser que je pouvais procéder autrement, en plaçant les fichiers AGENTS.md dans différents working_dir. Les working_dir se configurent au niveau des providers, voici deux exemples :
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
Cela permet de charger et de tester ./workdir1/AGENTS.md ou ./workdir2/AGENTS.md. Il est possible d'utiliser la même méthode pour évaluer différents SKILLS.md.
Pour le moment, je ne sais pas encore si Promptfoo est un bon outil pour mettre au point mon harness.
Avant de poursuivre mes tests de harness engineering avec Promptfoo, j'aimerais tester agent-catalog-eval pour voir si cet outil serait plus simple à mettre en œuvre.
J'ai testé des services de inbox placement
Toujours dans le contexte d'une mission freelance d'audit de délivrabilité d'e-mail (voir notes : 2025-08-04_1449 et 2025-08-08_2222), j'ai creusé le sujet de inbox placement.
À l'origine, je croyais qu'un test d'inbox placement permettait de simuler l'envoi d'emails vers différents providers de messagerie pour déterminer leur destination finale, par exemple :
- Boîte de réception principale
- Dossier spam/indésirables
- Dossier "Promotions"
- Dossier "Social"
- Dossier "Notifications"
Après avoir testé GlockApps, MailReach et MailerCheck, j'ai l'impression que leurs fonctionnalités d'inbox placement se limitent à vérifier si l'email atterrit en "spam" ou en "inbox", sans distinguer entre "Boite de réception principale", "Promotions" ou "Social". Cependant, j'ai un doute pour GlockApps, car j'ai aperçu "Other" sur un screenshot .
Cette fonctionnalité inbox placement est parfois appelée "spam checker" ou "Inbox insight".
Mes recherches sur le Subreddit EmailMarketing m'ont également permis d'identifier plusieurs autres services : Gwarm, Folderly, Warmup Inbox, MailGenius et Mail-Tester. Je n'ai pas pris le temps de les tester.
Comment les services d'inbox placement fonctionnent techniquement ?
Mon hypothèse sur le fonctionnement de ces services :
- Ces services créent d'abord des boîtes mail chez un maximum de email service providers (Gmail, Yahoo (Mail), Fastmail, La Poste (mail)…).
- Ils mettent en place un système de surveillance IMAP pour monitorer les mails reçus sur chacune de ces boîtes.
- Ils demandent à leurs utilisateurs d'envoyer un mail sur ces boîtes avec un code d'identification dans le corps pour faire le lien entre l'utilisateur et le mail reçu dans les mailbox.
- Ils communiquent ensuite à l'utilisateur les résultats observés : placement dans le dossier principal ou dans le spam pour chaque boîte.
Voici quelques exemples de résultats de mes tests d'inbox placement.
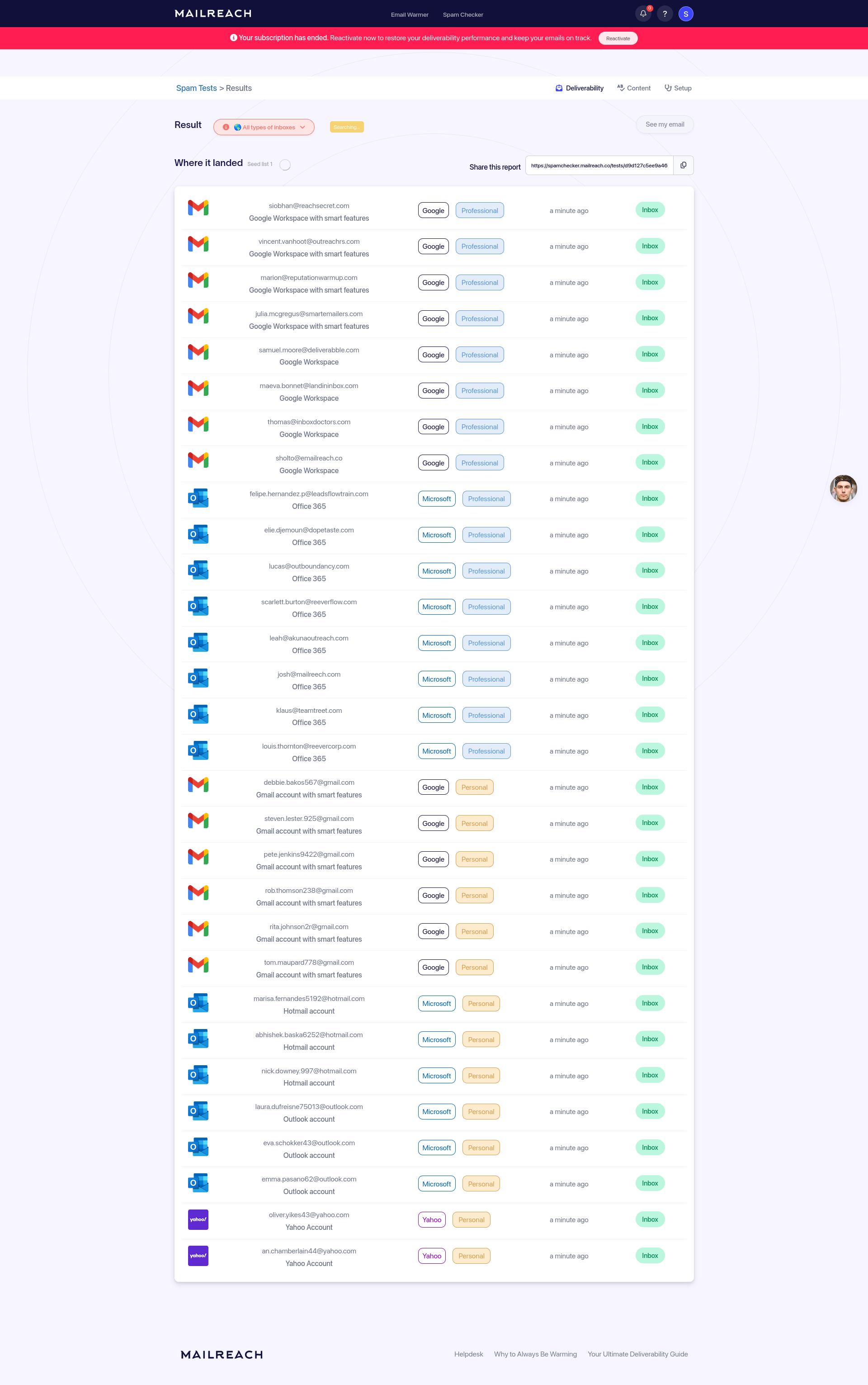
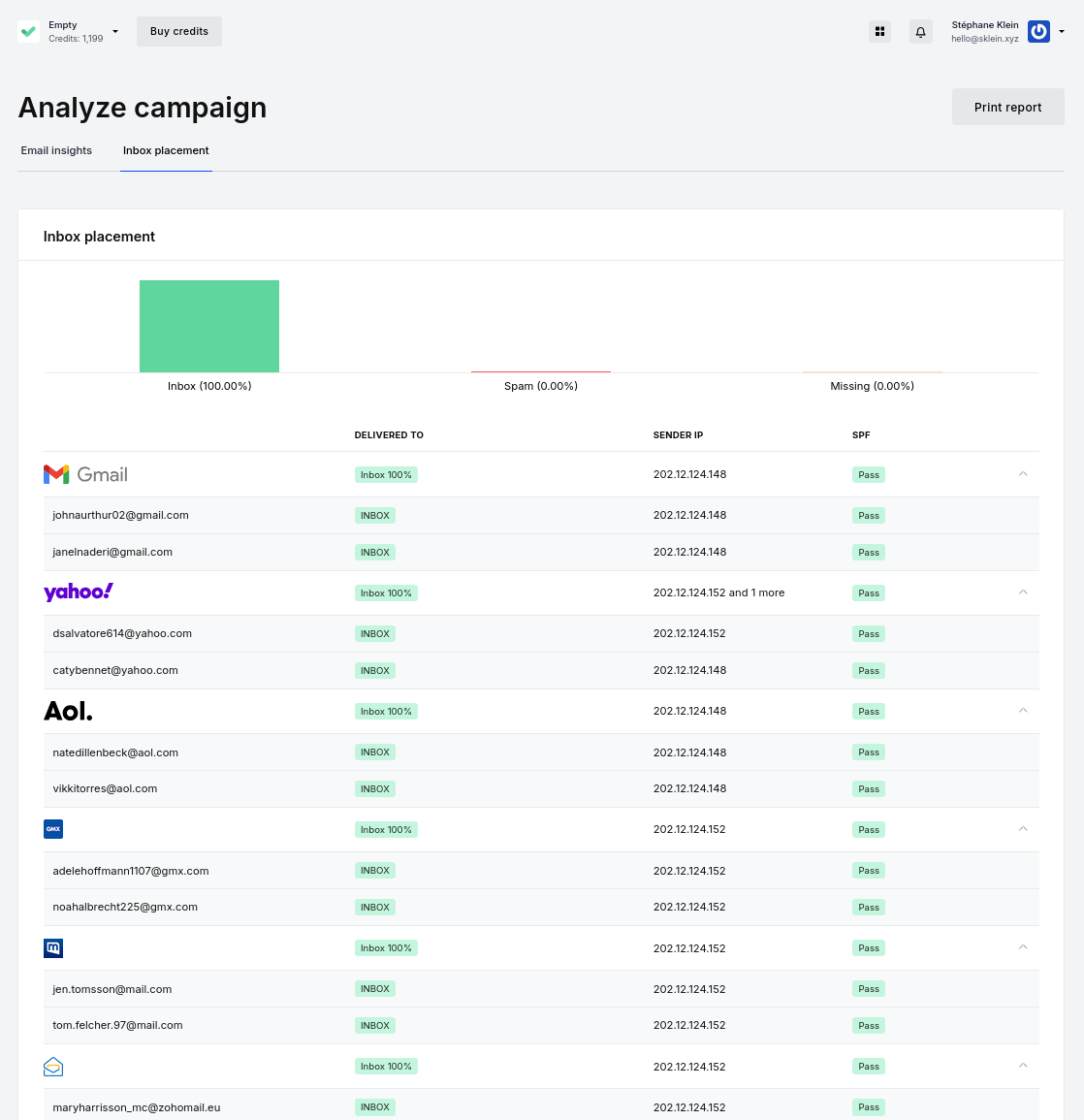
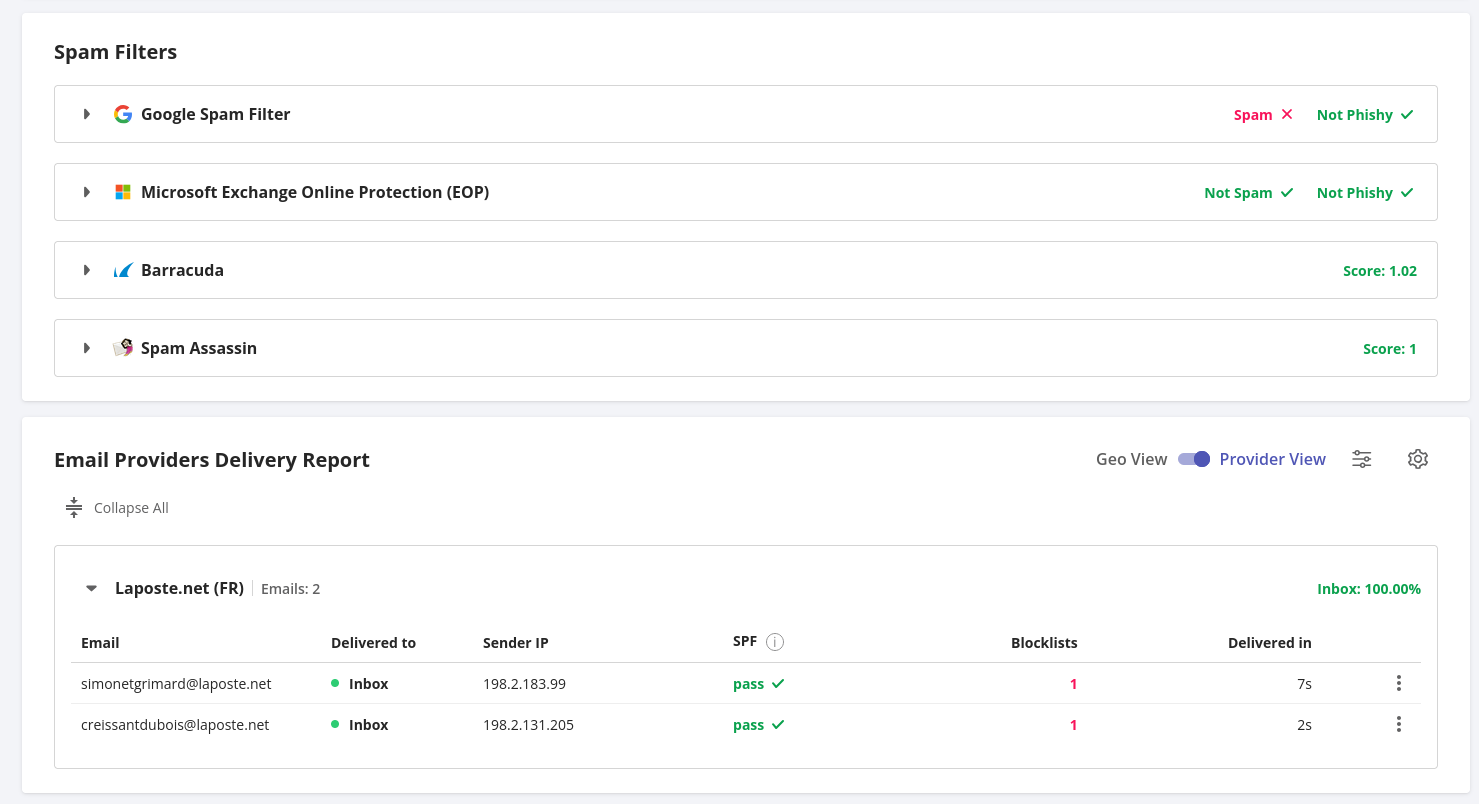
Pour l'instant, GlockApps semble être le service qui teste le plus grand nombre de types de boîtes e-mail différentes.
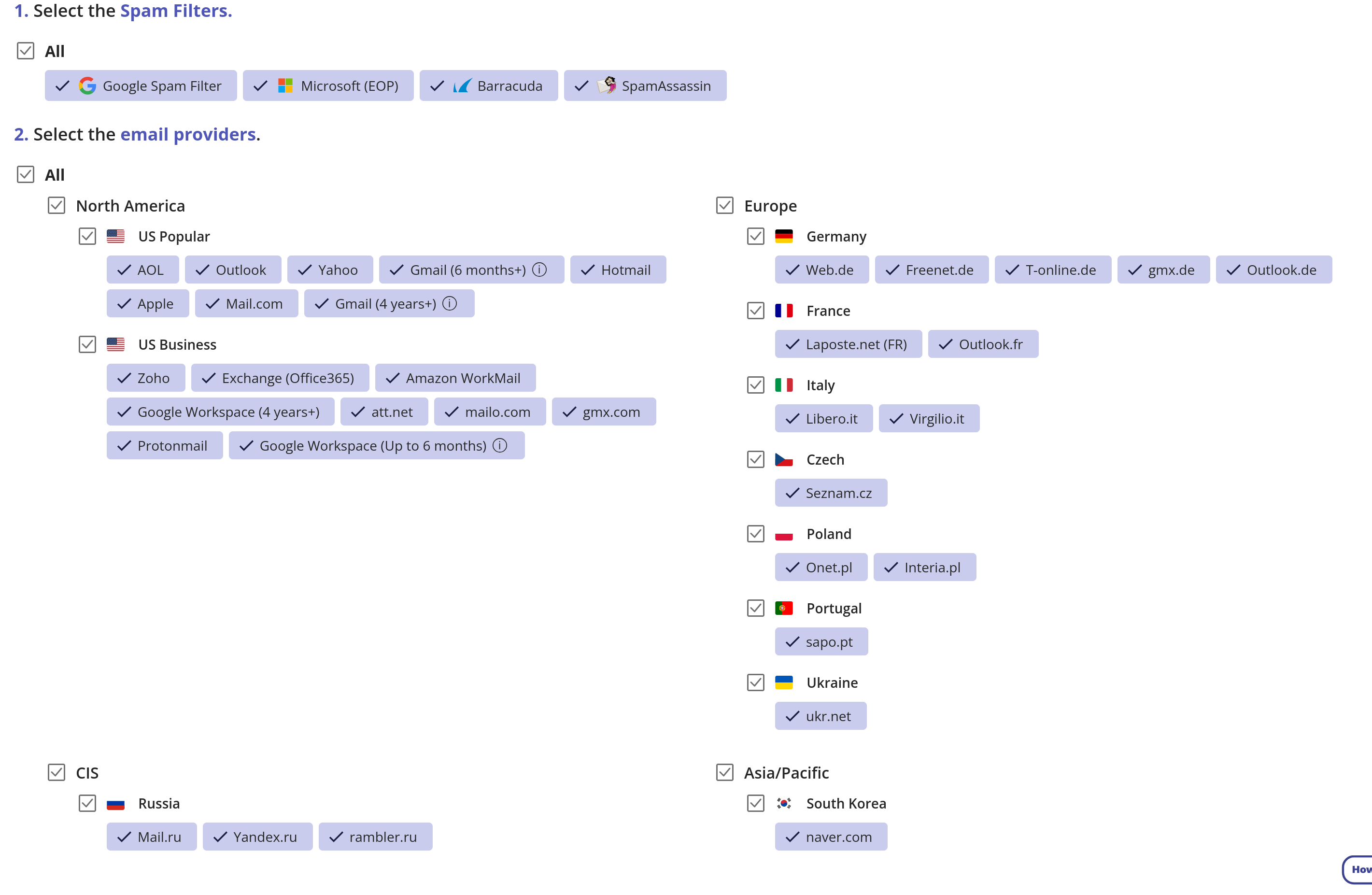
J'ai observé quelque chose de surprenant lors de mon premier test de MailReach avec mon adresse mail contact@stephane-klein.info.
J'ai envoyé un mail avec ce contenu et il a atterri dans le dossier spam des boîtes Microsoft Office 365 Mail, des boîtes qui appartiennent à la catégorie Professionnal.
J'ai écrit au support technique de MailReach car je n'arrivais pas à bien saisir le sens du message de tooltip qui s'affiche au survol des pastilles "spam" :
« Not good BUT the question is : do you really target professional inboxes? Because if not, it's not relevant to take it into account. Spam filters work differently between Professional and Personal inboxes. »
J'ai demandé si le style du contenu du message envoyé pouvait être pris en compte par les règles de spam et j'ai eu comme réponse :
Ca peut tre lié a ton contenu ou la réputation de ta boite mail.
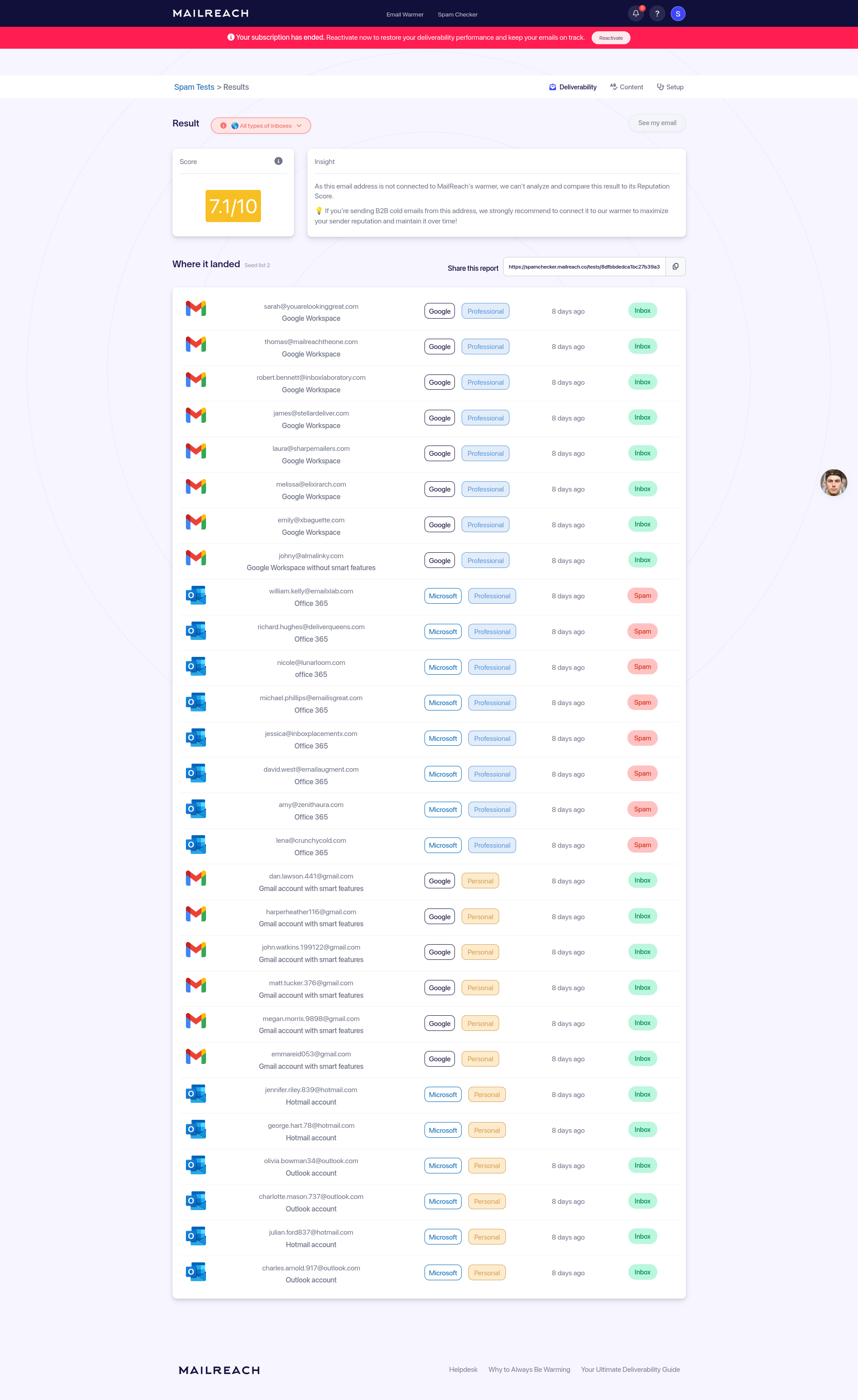
Suite à cela, un jour après, j'ai fait un nouveau test, avec ce contenu plus professionnel et cette fois, tous les mails ont été placés dans le dossier principal, aucun spam :
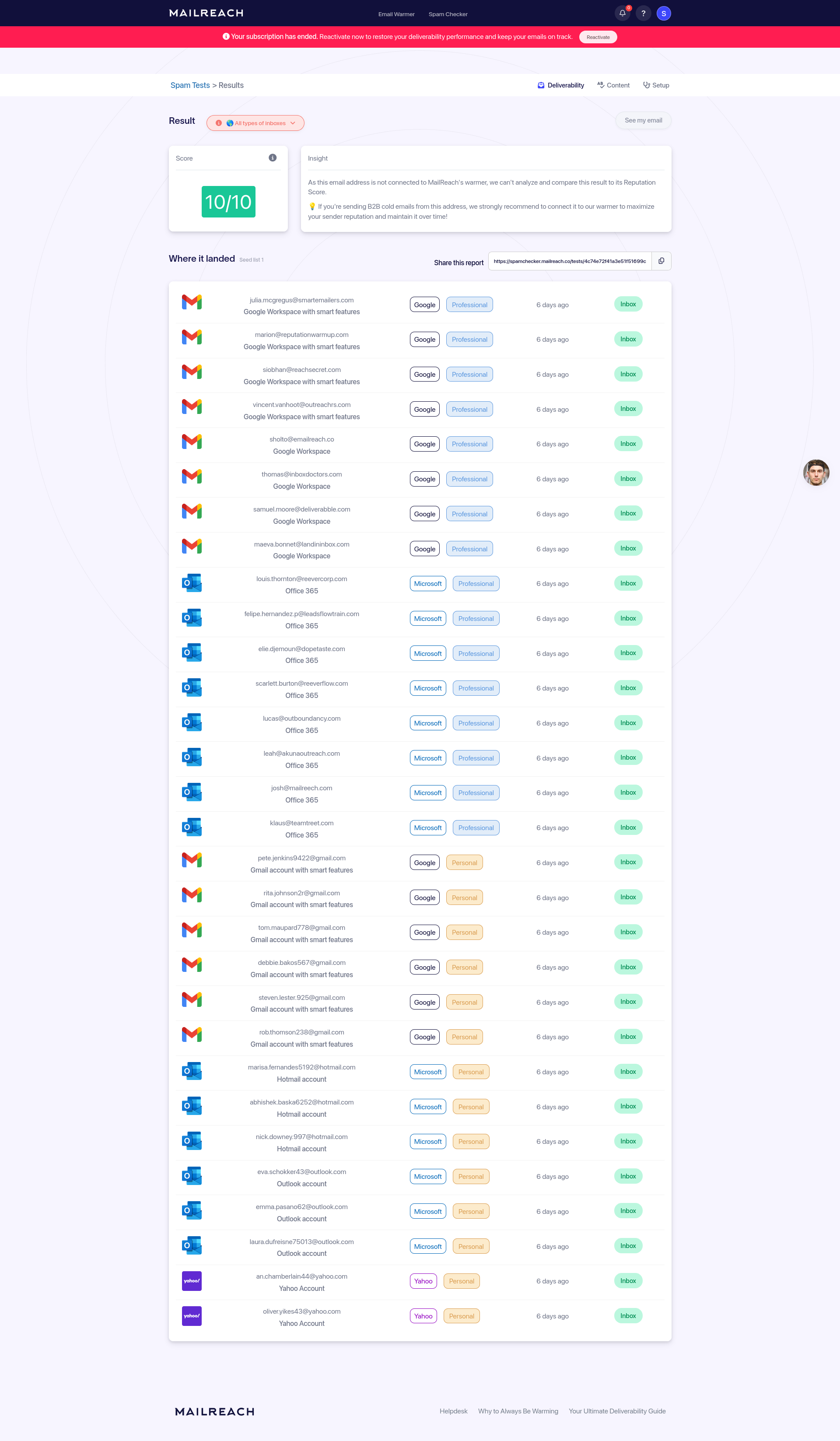
3 jours plus tard, j'ai fait un test en envoyant à nouveau le premier contenu mail dans un style plus personnel et cette fois le mail a été placé dans inbox dans toutes les boites mails.
Pour le moment, je n'ai pas d'explication. Est-ce une illustration de l'intérêt de la fonctionnalité email warming 🤔 ?
J'ai également testé le service MailTester, mais je n'ai pas réussi à le faire fonctionner. Tous les mails que j'ai envoyés m'ont été renvoyés avec un message d'erreur indiquant que les boîtes mail n'existaient pas :
Voici quelques informations concernant les tarifs de ces services d'inbox placement.
- $9,6 pour 25 tests
- $28 pour 100 tests
La tarification de MailerCheck est un peu compliquée :
- $10 pour 1000 crédits, un test d'inbox placement coûte 200 crédits, cela fait donc $2 par test.
GlockApps paraît être l'outil qui teste la plus large gamme de email service providers et qui détecte le classement des e-mails dans les dossiers "Promotions", "Social"… mais c'est probablement aussi la solution la plus coûteuse :
- $16.99 pour 3 tests
- $47,99 pour 10 tests
- $75,99 pour 20 tests
GlockApps offre 2 tests gratuits à la création du compte, mais j'ai mal utilisé les miens.
J'ai contacté leur service commercial pour demander des crédits gratuits supplémentaires, en leur expliquant que je voulais uniquement tester mon adresse personnelle sans visée commerciale, peut-être avant de suggérer leur outil à un client. Ils ont décliné ma demande 😔.
Je n'ai donc pas pu explorer davantage cette solution.
Dans un premier temps, je vais probablement proposer à mon client la solution MailReach et éventuellement GlockApps par la suite s'il souhaite des tests plus approfondis.
Pour effectuer mes tests, j'ai utilisé ce script d'envoi d'e-mail : https://github.com/stephane-klein/send-mail-to-test-inbox-placement.
Pour l'instant, je ne sais pas encore quelle approche je suggérerai à mon client pour qu'il puisse réaliser des tests d'inbox placement de façon autonome, par exemple mensuellement.
#UnJourPeuxÊtre je développerai un POC de fonctionnalité d'inbox placement. Il me semble qu'en dehors de la création de nombreuses adresses mail, les vérifications basées sur l'imap ne doivent pas être très compliquées à implémenter.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
2026-04-02 : étudier Beads comme source d'inspiration ou outil à intégrer.
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
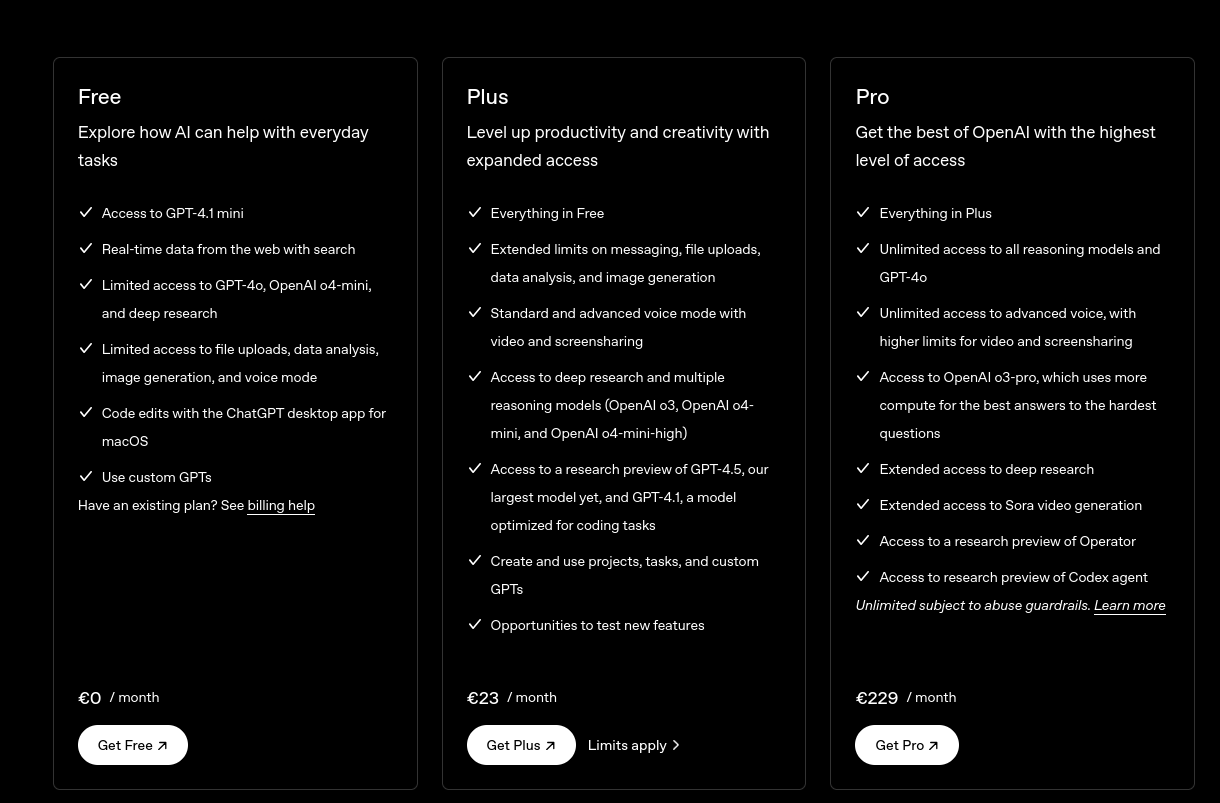
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
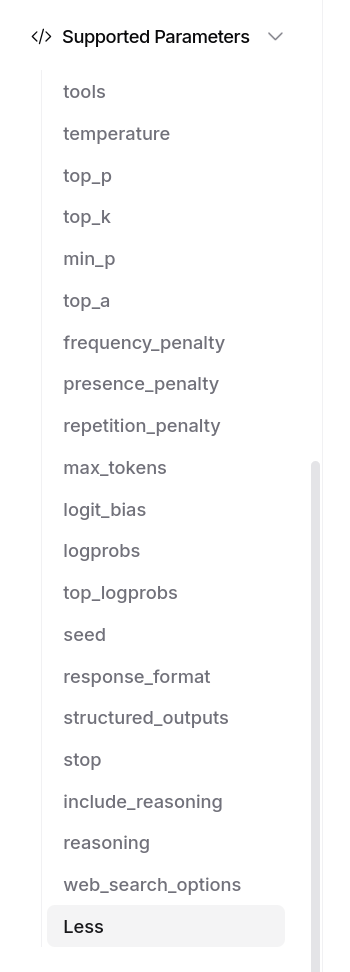
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
J'ai terminé poc-svelteki-web-notification
Je viens de terminer un POC nommé poc-sveltekit-web-notification , qui m'a permis d'apprendre à implémenter la fonctionnalité Push API dans une PWA.
Quelques ressources qui m'ont été utiles :
- Push API
- Web Workers API
- Using VAPID with WebPush
- Cet exemple de MDN Web Docs :
push-subscription-management.
Je n'ai aucune idée de pourquoi ce repository est archivé et par quoi il a été remplacé. - J'ai lu en partie Voluntary Application Server Identification (VAPID) for Web Push - RFC 8292
- SvelteKit - Service workers
Ma prochaine étape : intégrer cette fonctionnalité dans gibbon-replay.
Bilan de poc-sveltekit-custom-server
Contexte et objectifs
Dans le projet gibbon-replay, j'ai besoin d'exécuter une tâche une fois par jour pour supprimer des anciennes sessions.
gibbon-replay utilise une base de données SQLite qui ne dispose pas nativement de fonctionnalité de type Time To Live, comme on peut trouver dans Clickhouse.
SQLite ne propose pas non plus d'équivalent à pg_cron — ce qui est tout à fait normal étant donnée que SQLite est une librairie et non pas un service à part entière.
Le projet gibbon-replay est un monolith (j'aime les monoliths !) et je souhaite conserver ce choix.
Face à ces contraintes, une solution consiste à intégrer une solution comme Cron for Node.js directement dans l'application gibbon-replay.
Je pense que je dois implémenter cela dans un SvelteKit Custom Server, ce qui me permettrait d'exécuter cette tâche de purge à intervalles réguliers tout en conservant l'architecture monolithique.
Il y a quelques jours, j'ai décidé de tester cette idée dans un POC nommé : poc-sveltekit-custom-server.
J'ai aussi décidé d'expérimenter un objectif supplémentaire dans ce POC : lancer la migration du modèle de données dès le lancement du monolith et non plus lors de la première requête HTTP reçue par le service.
Enfin, je souhaitais ne pas dégrader l'expérience développeur (DX), c'est à dire, je souhaitais pouvoir continuer à simplement utiliser :
$ pnpm run dev
ou
$ pnpm run build
$ pnpm run preview
sans différence avec un projet SvelteKit "vanilla".
Résultats du POC et enseignements
Tout d'abord, le POC fonctionne parfaitement 🙂, sans dégrader l'expérience développeur (DX), qui ressemble à ceci :
$ mise install
$ pnpm install
$ pnpm run load-seed-data
Start data model migration…
Data model migration completed
Start load seed data...
seed data loaded
Lancement du projet en mode développement :
$ pnpm run dev
Start data model migration…
Data model migration completed
Server started on http://localhost:5173 in development mode
Lancement du projet "buildé" :
$ pnpm run build
$ pnpm run preview
Start data model migration…
Data model migration completed
Server started on http://localhost:3000 in production mode
Les migrations et les données "seed.sql" se trouvent dans le dossier /sqls/.
Le SvelteKit Custom Server est implémenté dans le fichier src/server.js et il ressemble à ceci :
import express from 'express';
import cron from 'node-cron';
import db, { migrate } from '@lib/server/db.js';
const isDev = process.env.ENV !== 'production';
migrate(); // Lancement de la migration du modèle de donnée dès de lancement du serveur
// Configuration d'une tâche exécuté toutes les heures
cron.schedule(
'0 * * * *',
async () => {
console.log('Start task...');
console.log(db().query('SELECT * FROM posts'));
console.log('Task executed');
}
);
async function createServer() {
const app = express();
...
Personnellement, je trouve cela simple et minimaliste.
Point de difficulté
SvelteKit utilise des "module alias", comme par exemple $lib.
Problème, par défaut, ces "module alias" ne sont pas configurés lors de l'exécution de node src/server.js.
Pour me permettre d'importer dans src/server.js des modules de src/lib/server/* comme :
import db, { migrate } from '@lib/server/db.js';
j'ai utilisé la librairie esm-module-alias.
Ceci complexifie un peu le projet, j'ai dû configurer ceci dans /package.json :
{
"scripts": {
"dev": "ENV=development node --loader esm-module-alias/loader --no-warnings src/server.js",
"preview": "ENV=production node --loader esm-module-alias/loader --no-warnings build/server.js",
...
"aliases": {
"@lib": "src/lib/"
}
}
- ajout de
--loader esm-module-alias/loader --no-warnings - et la section
aliases
Et dans /vite.config.js :
export default defineConfig({
plugins: [sveltekit()],
resolve: {
alias: {
'@lib': path.resolve('./src/lib')
}
}
});
- ajout de
alias
Le fichier src/server.js contient du code spécifique en fonction de son contexte d'exécution ("dev" ou "buildé") :
if (isDev) {
const { createServer: createViteServer } = await import('vite');
const vite = await createViteServer({
server: { middlewareMode: true },
appType: 'custom'
});
app.use(vite.middlewares);
} else {
const { handler } = await import('./handler.js');
app.use(handler);
}
En mode "dev" il utilise Vite et en "buildé" il utilise le fichier build/handler.js généré par SvelteKit build en mode SSR.
Le fichier src/server.js est copié vers le dossier /build/ lors de l'exécution de pnpm run build.
J'ai testé le bon fonctionnement du POC dans un container Docker.
J'ai intégré au projet un deployment-playground : https://github.com/stephane-klein/poc-sveltekit-custom-server/tree/main/deployment-playground.
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Update du 2025-05-29 à 00:07 - Je viens de publier ceci :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/?
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Journal du mardi 22 avril 2025 à 17:57
J'ai un collègue qui utilise Terragrunt (https://terragrunt.gruntwork.io/).
Je pense que j'ai déjà croisé cet outil mais sans trop y prêter attention.
Pour le moment, je ne comprends pas très bien l'intérêt de Terragrunt, j'ai l'impression que c'est un wrapper au-dessus de Terraform ou OpenTofu.
#JaimeraisUnJour prendre le temps de faire un POC de Terragrunt.
Journal du vendredi 18 avril 2025 à 11:40
Cela fait des années que je m'intéresse au sujet des solutions de sauvegarde en continu de bases de données PostgreSQL.
Dans cette note, le terme "sauvegarde en continu" ne signifie pas Point In Time Recovery.
Jusqu'à présent, je me suis toujours concentré sur la méthode "mainstream", qui consiste principalement à effectuer un backup binaire couplé avec une sauvegarde continue du WAL. Par exemple des solutions basées sur pg_basebackup, pgBackRest ou barman.
Une autre solution consiste à déployer une seconde instance PostgreSQL en mode streaming replication.
Une troisième solution que #JaimeraisUnJour tester : mettre en place une sauvegarde incrémentale basée sur le filesystème btrfs.
Plus précisément, la commande btrfs-send. La documentation de Dalibo mentionne cette méthode de sauvegarde.
Samedi dernier, j'ai imaginé une autre méthode qui me plait beaucoup par sa relative flexibilité et sa simplicité.
Elle consisterait à sauvegarder des tables de manière granulaire à intervalle de temps régulier vers un Object Storage à l'aide d'un Foreign Data Wrapper.
Pour cela, j'ai identifié parquet_s3_fdw, basé sur le format Apache Parquet qui permet de lire et d'écrire des données sur un bucket Object Storage.
Features
- Support SELECT of parquet file on local file system or Amazon S3.
- Support INSERT, DELETE, UPDATE (Foreign modification).
- Support MinIO access instead of Amazon S3.
J'ai utilisé de nombreuses fois Foreign Data Wrapper pour copier de manière granulaire des données entre deux bases de données PostgreSQL.
J'ai trouvé cette méthode très pratique, en particulier la possibilité de pouvoir utiliser un "pattern" SQL de copie du type :
INSERT INTO clients_local (id, nom, email, date_derniere_maj)
SELECT
d.client_id,
d.nom_client,
d.email_client,
CURRENT_TIMESTAMP
FROM
distant.clients_distant d
WHERE
d.date_modification > (SELECT MAX(date_derniere_maj) FROM clients_local)
ON CONFLICT (id) DO UPDATE
SET
nom = EXCLUDED.nom,
email = EXCLUDED.email,
date_derniere_maj = EXCLUDED.date_derniere_maj;
#JaimeraisUnJour réaliser un POC de cette idée basée sur parquet_s3_fdw.
Journal du vendredi 18 avril 2025 à 10:31
Il existe deux familles de méthodes de backup d'une base de données PostgreSQL :
- Backup logique
- Backup binaire à "chaud et à froid"
Voici une présentation simplifiée des différences entre ces deux modes de sauvegarde, qui peut comporter certaines imprécisions dues à cette vulgarisation.
Un backup logique est effectué par pg_dump sur une instance PostgreSQL en cours d'exécution (nommée "à chaud"). pg_dump supporte plusieurs formats d'archivage dont plain et custom.
Le format plain génère un fichier SQL classique, lisible "humainement".
Le format custom génère un fichier binaire, qui est plus flexible et a une taille bien plus réduite que le format plain. Il est toujours possible de générer un fichier SQL comme plain à partir d'un fichier custom : avec la commande pg_restore -f output.sql fichier_custom.
Il est possible de réaliser des sauvegardes et restaurations à "distance", via le protocole classique PostgreSQL Frontend Backend Protocol.
Il est possible d'importer un backup logique vers une instance PostgreSQL de version différente, en général plus récente.
Un backup binaire peut être effectué à "chaud" ou à "froid". En simplifiant, cela consiste à sauvegarder les fichiers PostgreSQL du filesystem et optionnellement sauvegarder aussi les journaux (WAL) de PostgreSQL. Pour effectuer un backup binaire, il existe la commande officielle pg_basebackup, mais aussi d'autres solutions plus complètes, comme pgBackRest ou barman.
Les systèmes de backup binaire de PostgreSQL ont l'avantage de pouvoir restaurer une sauvegarde à un point précis dans le temps (fonctionnalité PITR).
Je constate que la mise en place d'un backup binaire est plus complexe à mettre en place qu'un backup logique.
Voici mon POC le plus avancé concernant les backup binaire : poc-pg_basebackup_incremental.
Actuellement, pour sauvegarder des instances PostgreSQL, j'utilise pg_back-docker-sidecar qui est une solution de backup logique, basé sur pg_back, déployé sous la forme d'un Docker sidecar.
J'envisage aussi d'expérimenter une méthode basée sur parquet_s3_fdw que j'ai décrite dans 2025-04-18_1140.
Pour des informations plus approfondies à propos de ces sujets, je vous conseille la documentation de ces formations de Dalibo :
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.