
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (95 notes) :
Mes observations sur la popularité historique des langages de programmation
Un ami m'a partagé la vidéo Most Popular Programming Languages: Data from 1958 to 2025 (Most Popular Programming Languages). Pour quelqu'un comme moi qui a une grande curiosité pour l'histoire de l'informatique, c'est amusant de regarder ça 🙂.
J'ai lu la description de la vidéo pour essayer d'en savoir plus sur la véracité de ce qui est présenté :
Dans cette vidéo, je présente une chronologie détaillée des langages de programmation les plus utilisés de 1958 à 2025, basée sur une analyse approfondie des données. Les classements historiques reposent sur une combinaison d'enquêtes nationales agrégées, du nombre de livres pédagogiques publiés sur chaque langage, et de la fréquence à laquelle ces langages sont mentionnés dans les publications mondiales dédiées aux logiciels et aux technologies. Pour les années récentes, les classements ont été ajustés à partir de données issues de plusieurs indices de popularité des langages de programmation, des tendances d'accès aux dépôts GitHub, et d'enquêtes auprès des développeurs.
La popularité dans ce classement est définie par le nombre de développeurs maîtrisant ou apprenant activement chaque langage. L'échelle est normalisée sur une valeur relative de 100, permettant des comparaisons cohérentes entre les langages et les périodes.
L'emoji flamme représente les langages qui ont atteint la première place au moins une fois. L'emoji tête de mort représente les langages qui ne sont plus officiellement maintenus et ne disposent plus d'une communauté de développeurs active.
Plusieurs erreurs ont été corrigées par rapport à la vidéo précédente. J'ai également étendu la chronologie de près d'une décennie, en remontant à 1958, et ajouté de nouvelles données pour 2023, 2024 et 2025.
Vos retours sont toujours les bienvenus. Une suggestion de sujet ? Envoyez-moi un message !
Quelques observations personnelles sur l'évolution des langages présentés dans la vidéo :
- Fortran et Cobol : Je pensais que Cobol était dominant, mais je découvre que non, je suis surpris, Fortran semble avoir toujours été devant. J'ai toujours beaucoup plus entendu parler de Cobol que Fortran.
- Pascal : L'un de mes premiers amours en programmation, avant Python. Je n'imaginais pas que Pascal avait été numéro 1 à partir de 1980.
J'observe que quand j'ai appris Pascal vers 1991-1992, le langage C l'avait déjà dépassé depuis 1985. - Ada : Je ne m'attendais pas à le voir aussi populaire à la fin des années 1980, et encore moins à le voir passer devant Pascal en 1988. Et au passage, un langage conçu par Jean Ichbiah, un Français, au sein de CII-Honeywell-Bull : une entreprise à capitaux mixtes franco-américains — sur commande du Pentagone.
- C : C'est impressionnant de voir comment C a tout écrasé de 1990 à 1995 !
- Perl : Il a eu sa petite heure de gloire jusqu'en 1997, avant l'arrivée de PHP. C'était juste avant que je commence le développement web. En regardant l'évolution de Perl dans la vidéo, on devine assez bien comment Java et PHP ont ensuite tué Perl sur le web.
- Visual Basic : Curieusement, il n'a jamais vraiment dominé malgré les apparences. À la fin des années 1990, j'avais pourtant l'impression que tout le monde en faisait.
- Java et PHP : C'est au début de ma carrière professionnelle, en 2001, que Java commence à être hégémonique. Mais ce qui est intéressant, c'est de voir PHP se défendre très bien face à lui.
- Python : Il commence à monter en 2006, ce qui correspond exactement à l'année où je commence à me perfectionner sérieusement dans ce langage.
- Javascript : En 2012, j'avais clairement senti une forte montée en puissance de JS avec l'arrivée de NodeJS — j'avais même publié Réflexions à propos de Node.js et de JavaScript plus globalement le 18 avril 2012 sur LinuxFr.
- Python vs Javascript : Je suis vraiment surpris de voir Python doubler JavaScript en 2017, puis Java en 2018. J'imagine que cela doit être l'effet de l'IA — TensorFlow et compagnie. Je suis surpris de constater que Javascript n'a jamais été numéro 1 !
- Golang : J'ai commencé à l'utiliser en 2015, et je suis content de voir qu'il pointe le bout de son nez dans le top 12 en 2019. J'ai une sorte d'affection pour ce langage, j'apprécie beaucoup ses valeurs.
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
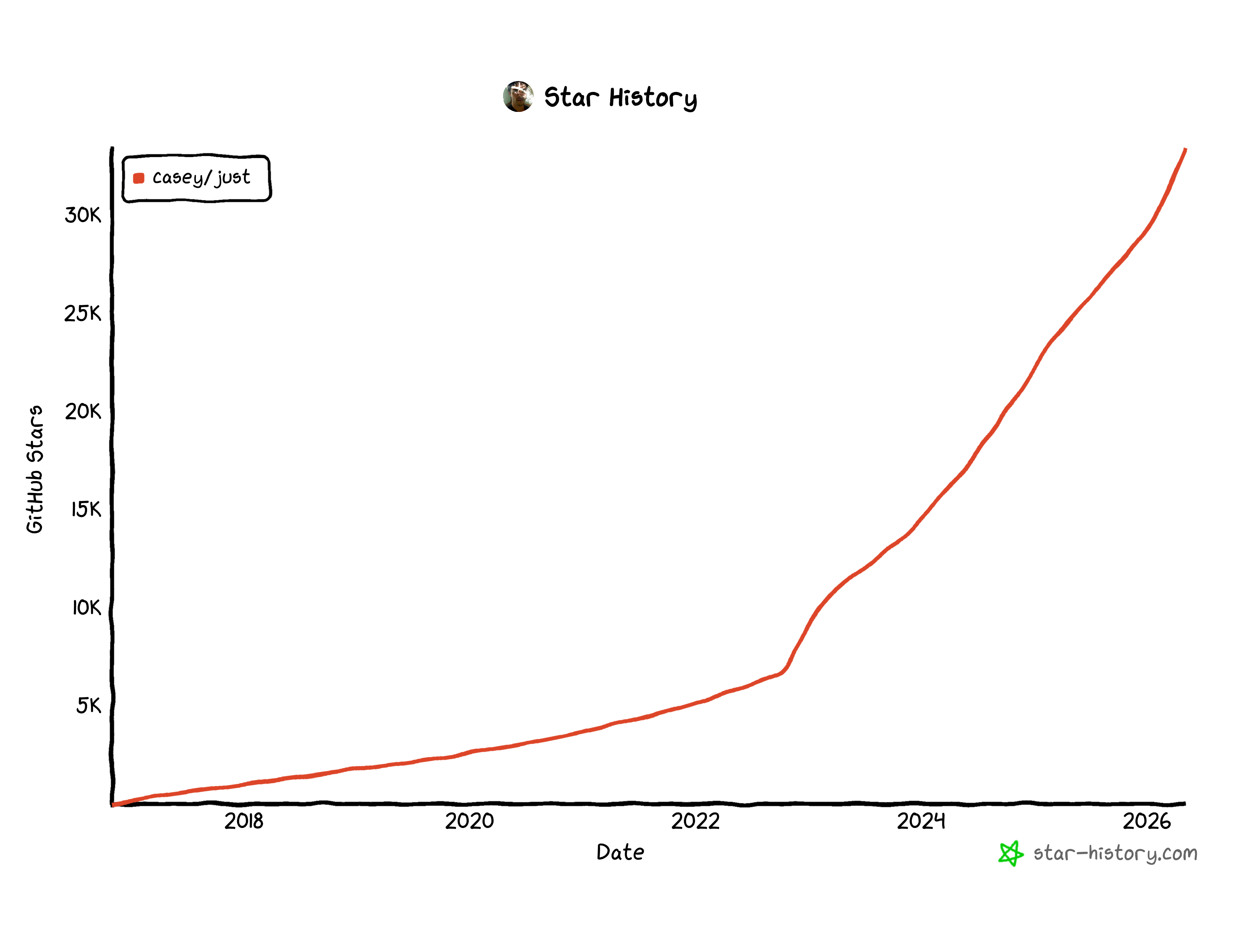
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
J'ai découvert le terme "test sociable"
Alexandre m'a fait découvrir aujourd'hui le terme "test sociable" versus "test solitaire", documenté ici par Martin Fowler.
Je connaissais déjà cette problématique sans en avoir le vocabulaire. Je la décrivais comme du "couplage dans le test" : un test qui couvre plusieurs unités à la fois peut échouer pour une raison indirecte, ce qui rend difficile l'identification de la vraie cause.
Je savais que la solution habituelle est d'utiliser des mocks pour isoler l'unité testée. Cela rend les tests mieux ciblés, mais aussi plus fastidieux à écrire.
Martin Fowler semble préférer les tests sociables par défaut, et ne recourt aux mocks que quand c'est nécessaire (non-déterminisme, lenteur, ressource externe instable). Je partage cette doctrine.
Journal du jeudi 26 mars 2026 à 14:47
#JaiDécouvert https://keepachangelog.com, un guide pour maintenir les changelog de ses projets.
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals. Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
J'ai découvert Promptfoo qui permet de faire du LLM Eval
Cette note a été partiellement écrite fin novembre 2025 et publiée 3 mois plus tard, fin février 2026.
Souhaitant améliorer mes prompts et combler mes lacunes en prompt engineering, je me suis mis à chercher des outils permettant de pratiquer quelque chose qui ressemblerait au Test driven development appliqué à la conception de prompts.
Via Claude Sonnet 4.5, #JaiDécouvert Promptfoo (https://github.com/promptfoo/promptfoo), un framework Javascript permettant notamment de faire du LLM Eval.
Cela fait plusieurs mois que je croise l'expression LLM Eval, sans avoir jamais pris le temps de comprendre ce que ce concept signifie précisément.
D'après ce que j'ai compris, la différence essentielle entre Unit testing et LLM Eval, c'est que les tests unitaires sont déterministes, alors que la qualité des réponses des LLM est évaluée de manière probabiliste.
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Journal du lundi 12 janvier 2026 à 09:36
Il y a exactement 1 an, j'ai publié cette note pour citer ce message de Salvatore Sanfilippo, créateur de Redis :
About "people still thinking LLMs are quite useless", I still believe that the problem is that most people are exposed to ChatGPT 4o that at this point for my use case (programming / design partner) is basically a useless toy. And I guess that in tech many folks try LLMs for the same use cases. Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
Aujourd'hui, je viens de lire son nouveau billet : Don't fall into the anti-AI hype (1106 commentaires sur HackerNews, 217 commentaires sur Lobsters).
Ces observations rejoignent ce que je constate avec OpenCode et les modèles Claude Sonnet 4.5 ou Claude Opus 4.5. Il me semble que "coder à la main" pourrait devenir un jeu, comme faire des sudoku ou jouer à des jeux vidéo. Pour le moment, je n'ai aucune idée de l'impact que cela aura sur mes capacités cognitives. J'ai l'impression que mes compétences pourraient décliner.
En fait, j'ai très peur de ne plus faire d'efforts de compréhension et qu'après quelques mois ou années, je devienne de plus en plus bête en déléguant systématiquement la réflexion à l'IA.
Voici cet article, traduit en français avec Claude Sonnet 4.5 :
Ne tombez pas dans le battage anti-IA
J'adore écrire du logiciel, ligne par ligne. On pourrait dire que ma carrière a été un effort continu pour créer des logiciels bien écrits, minimaux, où la touche humaine était la caractéristique fondamentale. J'espère également une société où les derniers ne sont pas oubliés. De plus, je ne souhaite pas que l'IA réussisse économiquement, je me fiche que le système économique actuel soit subverti (je pourrais être très heureux, honnêtement, si cela va dans la direction d'une redistribution massive de la richesse). Mais, je ne me respecterais pas moi-même et mon intelligence si mon idée du logiciel et de la société devait altérer ma vision : les faits sont les faits, et l'IA va changer la programmation pour toujours.
En 2020, j'ai quitté mon emploi pour écrire un roman sur l'IA, le revenu de base universel, une société qui s'adaptait à l'automatisation du travail en faisant face à de nombreux défis. À la toute fin de 2024, j'ai ouvert une chaîne YouTube axée sur l'IA, son utilisation dans les tâches de codage, ses effets sociaux et économiques potentiels. Mais bien que j'aie reconnu très tôt ce qui allait se passer, je pensais que nous avions plus de temps avant que la programmation ne soit complètement remodelée, au moins quelques années. Je ne crois plus que ce soit le cas. Récemment, les LLM de pointe sont capables de compléter de grandes sous-tâches ou des projets de taille moyenne seuls, presque sans assistance, avec un bon ensemble d'indices sur ce que devrait être le résultat final. Le degré de succès que vous obtiendrez est lié au type de programmation que vous faites (plus c'est isolé et textuellement représentable, mieux c'est : la programmation système est particulièrement adaptée), et à votre capacité à créer une représentation mentale du problème à communiquer au LLM. Mais, en général, il est maintenant clair que pour la plupart des projets, écrire le code soi-même n'a plus de sens, si ce n'est pour s'amuser.
Au cours de la semaine dernière, simplement en promptant, et en inspectant le code pour fournir des conseils de temps en temps, en quelques heures j'ai accompli les quatre tâches suivantes, en heures au lieu de semaines :
J'ai modifié ma bibliothèque linenoise pour supporter l'UTF-8, et créé un framework pour tester l'édition de ligne qui utilise un terminal émulé capable de rapporter ce qui est affiché dans chaque cellule de caractère. Quelque chose que j'ai toujours voulu faire, mais il était difficile de justifier le travail nécessaire juste pour tester un projet personnel. Mais si vous pouvez simplement décrire votre idée, et qu'elle se matérialise dans le code, les choses sont très différentes.
J'ai corrigé des échecs transitoires dans le test de Redis. C'est un travail très ennuyeux, des problèmes liés au timing, des conditions de deadlock TCP, etc. Claude Code a itéré pendant tout le temps nécessaire pour le reproduire, a inspecté l'état des processus pour comprendre ce qui se passait, et a corrigé les bugs.
Hier, je voulais une bibliothèque C pure capable de faire l'inférence de modèles d'embedding de type BERT. Claude Code l'a créée en 5 minutes. Même sortie et même vitesse (15% plus lent) que PyTorch. 700 lignes de code. Un outil Python pour convertir le modèle GTE-small.
Au cours des dernières semaines, j'ai effectué des modifications des mécanismes internes de Redis Streams. J'avais un document de conception pour le travail que j'ai fait. J'ai essayé de le donner à Claude Code et il a reproduit mon travail en, genre, 20 minutes ou moins (principalement parce que je suis lent à vérifier et à autoriser l'exécution des commandes nécessaires).
Il est tout simplement impossible de ne pas voir la réalité de ce qui se passe. Écrire du code n'est plus nécessaire pour la plupart. Il est maintenant beaucoup plus intéressant de comprendre quoi faire, et comment le faire (et, à propos de cette deuxième partie, les LLM sont aussi d'excellents partenaires). Peu importe si les entreprises d'IA ne pourront pas récupérer leur argent et que le marché boursier s'effondrera. Tout cela est sans importance, à long terme. Peu importe si tel ou tel PDG d'une licorne vous dit quelque chose de rebutant, ou d'absurde. La programmation a changé pour toujours, de toute façon.
Comment je me sens, à propos de tout le code que j'ai écrit qui a été ingéré par les LLM ? Je suis ravi d'en faire partie, parce que je vois cela comme une continuation de ce que j'ai essayé de faire toute ma vie : démocratiser le code, les systèmes, la connaissance. Les LLM vont nous aider à écrire de meilleurs logiciels, plus rapidement, et permettront aux petites équipes d'avoir une chance de rivaliser avec les plus grandes entreprises. La même chose que les logiciels open source ont fait dans les années 90.
Cependant, cette technologie est beaucoup trop importante pour être entre les mains de quelques entreprises. Pour l'instant, vous pouvez faire le pré-entraînement mieux ou pas, vous pouvez faire l'apprentissage par renforcement de manière beaucoup plus efficace que d'autres, mais les modèles ouverts, en particulier ceux produits en Chine, continuent de rivaliser (même s'ils sont en retard) avec les modèles de pointe des laboratoires fermés. Il y a une démocratisation suffisante de l'IA, jusqu'à présent, même si elle est imparfaite. Mais : il n'est absolument pas évident qu'il en sera ainsi pour toujours. J'ai peur de la centralisation. En même temps, je crois que les réseaux de neurones, à l'échelle, sont simplement capables de faire des choses incroyables, et qu'il n'y a pas assez de "magie" dans l'IA de pointe actuelle pour que les autres laboratoires et équipes ne rattrapent pas leur retard (sinon il serait très difficile d'expliquer, par exemple, pourquoi OpenAI, Anthropic et Google sont si proches dans leurs résultats, depuis des années maintenant).
En tant que programmeur, je veux écrire plus d'open source que jamais, maintenant. Je veux améliorer certains de mes dépôts abandonnés pour des raisons de temps. Je veux appliquer l'IA à mon workflow Redis. Améliorer l'implémentation des Vector Sets et ensuite d'autres structures de données, comme je le fais avec Streams maintenant.
Mais je m'inquiète pour les gens qui vont être licenciés. Il n'est pas clair quelle sera la dynamique en jeu : les entreprises vont-elles essayer d'avoir plus de personnes, et de construire plus ? Ou vont-elles essayer de réduire les coûts salariaux, en ayant moins de programmeurs qui sont meilleurs au prompting ? Et, il y a d'autres secteurs où les humains deviendront complètement remplaçables, je le crains.
Quelle est la solution sociale, alors ? L'innovation ne peut pas être annulée après tout. Je crois que nous devrions voter pour des gouvernements qui reconnaissent ce qui se passe, et qui sont prêts à soutenir ceux qui resteront sans emploi. Et, plus les gens seront licenciés, plus il y aura de pression politique pour voter pour ceux qui garantiront un certain degré de protection. Mais j'attends également avec impatience le bien que l'IA pourrait apporter : de nouveaux progrès en science, qui pourraient aider à réduire la souffrance de la condition humaine, qui n'est pas toujours heureuse.
Quoi qu'il en soit, revenons à la programmation. J'ai une seule suggestion pour vous, mon ami. Quoi que vous croyiez sur ce qui devrait être la Bonne Chose, vous ne pouvez pas la contrôler en refusant ce qui se passe actuellement. Éviter l'IA ne va pas vous aider, vous ou votre carrière. Pensez-y. Testez ces nouveaux outils, avec soin, avec des semaines de travail, pas dans un test de cinq minutes où vous ne pouvez que renforcer vos propres convictions. Trouvez un moyen de vous multiplier, et si cela ne fonctionne pas pour vous, réessayez tous les quelques mois.
Oui, peut-être pensez-vous que vous avez travaillé si dur pour apprendre à coder, et maintenant les machines le font pour vous. Mais quel était le feu en vous, quand vous codiez jusqu'à la nuit pour voir votre projet fonctionner ? C'était construire. Et maintenant vous pouvez construire plus et mieux, si vous trouvez votre façon d'utiliser l'IA efficacement. Le plaisir est toujours là, intact.
Journal du dimanche 06 juillet 2025 à 10:14
Il m'arrive régulièrement de perdre du temps en tentant d'insérer des lignes de commentaires dans des commandes Bash multiline, par exemple comme ceci :
sudo qemu-system-x86_64 \
-m 8G \
-smp 4 \
-enable-kvm \
-drive file=ubuntu-working-layer.qcow2,format=qcow2 \
-drive file=cloud-init.img,format=raw \
-nographic \
\ # Folder sharing between the host system and the virtual machine:
-fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share \
\ # Allows virtual machine to access the Internet
\ # and port forwarding to access virtual machine via ssh:
-nic user,ipv6-net=fd00::/64,hostfwd=tcp::2222-:22
Malheureusement, cette syntaxe n'est pas supportée par Bash et à ma connaissance, il n'existe aucune solution en Bash pour atteindre mon objectif.
Je suis ainsi contraint de diviser la documentation en deux parties : l'une pour l'exécution de la commande, l'autre pour expliquer les paramètres. Voici ce que cela donne :
sudo qemu-system-x86_64 \
-m 8G \
-smp 4 \
-enable-kvm \
-drive file=ubuntu-working-layer.qcow2,format=qcow2 \
-drive file=cloud-init.img,format=raw \
-nographic \
-fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share \
-nic user,ipv6-net=fd00::/64,hostfwd=tcp::2222-:22
# Here are some explanations of the parameters used in this command
#
# Folder sharing between the host system and the virtual machine:
#
# ```
# -fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file
# -device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share
# ```
#
# Allows virtual machine to access the Internet
# and port forwarding to access virtual machine via ssh:
#
# ```
# -nic user,ipv6-net=fd00::/64,hostfwd=tcp::2222-:22
# ```
Je me souviens d'avoir étudié Oils shell en octobre dernier et je me suis demandé si ce shell supporte ou non les commentaires sur des commandes multiline.
La réponse est oui : "multiline-command".
Exemple dans ce playground :
#!/usr/bin/env osh
... ls
-l
# comment 1
--all
# comment 2
--human-readable;
Chaque fois que je me plonge dans Oils, je trouve ce projet intéressant.
J'aimerais l'utiliser, mais je sais que c'est un projet de niche et qu'en contexte d'équipe, je rencontrerais sans doute des difficultés d'adoption. Je pense que je ferais face à des oppositions.
Je pense tout de même à l'utiliser dans mes projets personnels, mais j'ai peur de trop l'apprécier et d'être frustré ensuite si je ne peux pas l'utiliser en équipe 🤔.
J'ai découvert la méthode officielle de SvelteKit pour accéder aux variables d'environnement
Voici une nouvelle fonctionnalité qui illustre pourquoi j'apprécie l'expérience développeur (DX) de SvelteKit : la simplicité d'accès aux variables d'environnement !
Je commence avec un peu de contexte.
Comme je l'ai déjà dit dans une précédente note, je suis depuis 2015 les principes de The Twelve-Factors App.
Concrètement, quand je déploie un frontend web qui a besoin de paramètres de configuration, par exemple une URL pour accéder à une API, je déploie quelque chose qui ressemble à ceci :
# docker-compose.yml
services:
webapp:
image: ...
environment:
GRAPHQL_API: https://example.com/
De 2012 à 2022, quand ma doctrine était de produire des frontend web en SPA, j'avais recours à du boilerplate code à base de commande sed dans un entrypoint.sh, qui avait pour fonction d'attribuer des valeurs aux variables de configuration — comme dans cet exemple GRAPHQL_API — au moment du lancement du container Docker, exemple : entreypoint.sh.
Ce système était peu élégant, difficile à expliquer et à maintenir.
Ce soir, j'ai découvert les fonctionnalités suivantes de SvelteKit :
J'ai publié ce playground sveltekit-environment-variable-playground qui m'a permis de tester ces fonctionnalités dans un projet SSR avec hydration.
J'ai testé comment accéder à trois variables dans trois contextes différents (.envrc) :
# Set at application build time
export PUBLIC_VERSION="0.1.0"
# Set at application startup time and accessible only on server side
export POSTGRESQL_URL="postgresql://myuser:mypassword123@localhost:5432/mydatabase"
# Set at application startup time and accessible on frontend side
export PUBLIC_GOATCOUNTER_ENDPOINT=https://example.com/count
Cela fonctionne parfaitement bien, c'est simple, pratique, un pur bonheur.
Pour plus de détails, je vous invite à regarder le playground et à tester par vous-même.
Merci aux développeurs de SvelteKit ❤️.
J'ai regardé ce que propose NextJS et je constate qu'il propose moins de fonctionnalités.
D'après ce que j'ai compris, NextJS propose l'équivalent de $env/dynamic/private et $env/static/public mais j'ai l'impression qu'il ne propose rien d'équivalent à $env/dynamic/public.
Depuis un an, j'ai pris conscience d'une difficulté inhérente aux organisations qui suivent le paradigme Multirepos, difficulté dont je ne m'étais pas rendu compte auparavant : décider où publier ses issues !
J'ai observé que dès qu'une organisation commence à utiliser plusieurs repositories, la question de l'endroit où créer de nouvelles issues se pose. Par exemple :
- Où poster une issue d'amélioration qui nécessite des changements dans le repository A et B ?
- Où créer une issue d'une proposition d'un process qui ne concerne pas spécifiquement le code source d'un projet hébergé dans un repository ?
- Où créer une issue dont le but est de créer un nouveau service ?
Quand une organisation suit le paradigme Monorepo avec issues colocalisées et utilise, comme je l'explique dans la note "Nom et arborescence de Monorepo" un nom non spécifique, alors la question de l'endroit où publier ses issues ne se pose pas ! Il suffit de publier l'issue dans le Monorepo (par exemple sur GitHub, GitLab ou Forgejo).
Le gestionnaire d'issue du Monorepo est un point de schelling, c'est-à-dire un endroit où tous les développeurs convergent naturellement en l'absence de communication explicite pour trouver et créer des issues.
Ce paradigme évite des débats à propos de l'endroit où publier les issues.
Nom et arborescence de Monorepo
Je suis un adepe du paradigme Monorepo, de la documentation colocalisée et des issues colocalisées.
Je conseille de nommer le repository avec le nom de l'organisation.
Par exemple, si mon organisation se nomme « Dummy Tech » et si elle utilise GitLab, alors je conseille d'utiliser le slug dummy-tech, ce qui donne gitlab.com/dummy-tech/dummy-tech/ et « Dummy Tech Monorepo » comme titre de repository.
La neutralité de ce nom facilite les décisions concernant ce qui peut ou non être inclus dans le repository, sans être limité par un nom trop restrictif. Il est flexible face à l'évolution du projet. Il permet d'éviter bien des débats à propos du nommage.
En 2018, sur GitHub, j'ai découvert un exemple de monorepo d'une organisation. Cet exemple m'a servi de base et je l'ai fait évoluer quand je travaillais chez Spacefill.
Voici un exemple d'arborescence de monorepo que j'aime utiliser :
dummy-tech
├── deployments
│ ├── prod
│ └── sandbox
├── ci
├── docs
├── playgrounds
│ ├── playground_a
│ └── playground_b
├── services
│ ├── service_a
│ ├── service_b
│ └── service_c
└── tools
├── tool_a
├── tool_b
└── tool_c
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Journal du samedi 22 mars 2025 à 10:58
Voici quelques principes qui me guident. Je pense qu'ils contribuent à rendre une organisation efficace et efficiente.
1. La loi empirique de Gall :
« Un système complexe qui fonctionne se trouve invariablement avoir évolué depuis un système simple qui fonctionnait.
La proposition inverse se révèle également exacte : Un système complexe développé de A à Z ne fonctionne jamais et vous n'arriverez jamais à le faire fonctionner. Vous devez recommencer depuis le début, en commençant par un système simple. »
2. Je suis convaincu de la pertinence du modèle de Tuckman pour comprendre comment les équipes se construisent et évoluent au fil du temps.
En conséquence, je crois qu'une organisation doit accorder suffisamment de temps aux équipes pour qu'elles atteignent leur phase de performance, puis veiller à maintenir la composition de l'équipe sur la durée.
3. Le modèle du triangle de gestion de projet qui je trouve est très bien expliqué dans le livre Getting Real :
Voici un moyen simple de lancer le projet dans les délais et le budget impartis : ne pas les modifier. Il ne faut jamais consacrer plus de temps ou d'argent à un problème, mais simplement en réduire la taille (le périmètre).
Il existe un mythe qui dit que l'on peut lancer un projet dans les délais, en respectant le budget et le champ d'application. Cela n'arrive presque jamais et, lorsque c'est le cas, la qualité s'en ressent souvent.
Si vous ne pouvez pas tout faire tenir dans le temps et le budget impartis, n'augmentez pas le temps et le budget. Au contraire, réduisez le champ d'application. Il sera toujours temps d'ajouter des choses plus tard - plus tard est éternel, maintenant est éphémère.
Il vaut mieux lancer quelque chose d'excellent dont la portée est un peu plus réduite que prévu que de lancer quelque chose de médiocre et plein de trous parce qu'il fallait respecter une fenêtre magique de temps, de budget et de portée. Laissez la magie à Houdini. Vous avez une véritable entreprise à gérer et un véritable produit à livrer.
Journal du mercredi 05 mars 2025 à 16:02
J'ai lu le billet de Mitchell Hashimoto « As code ».
Voir aussi configuration as code.
En gestion de projet logiciel, quelle est la définition de "Theme" ?
J'ai du mal à bien définir le terme thème en gestion de projet logiciel.
Dans cette note, je vais décrire les deux définitions que je connais.
Voici une définition de Ken Rubin, auteur du livre Essential Scrum :
A collection of related user stories. A theme provides a convenient way to indicate that a set of stories have something in common, such as being in the same functional area.
Un Theme peut-être assigné à tout type d'issue, par exemple Epic ou User Story.
Les auteurs du livre Product Roadmaps Relaunched ont une autre définition de Theme :
As we’ve touched on, in the relaunched roadmapping process we use themes and subthemes to express customer needs. This is probably a new concept for many of you, so let’s define what we mean by these terms.
Themes are an organizational construct for defining what’s important to your customers at the present time.
...
So, again, themes and subthemes represent the needs and problems your product will solve for. A need is generally something the customer doesn’t have yet, whereas a problem is something that’s not working right (with the existing product, or whatever substitute they might currently be using). Even though these two terms suggest subtle differences, the important point is that both refer to a gap or pain in the customer’s experience. When identifying the themes and subthemes for your roadmap, remember to consider both needs and problems from all angles.
Jared Spool, paraphrasing our very own Bruce McCarthy, says, “Themes help teams stay focused without prematurely committing to a solution that may not be the best idea later on.” As Spool points out, it is important to focus most of the roadmapping effort on customer needs and problems because “the viability of a feature may shift dramatically, while the nature of an important customer problem will likely remain the same.”
Dans ce livre, un Theme représente un besoin client important à un instant donné.
D'après ce que j'ai compris, Product Roadmaps Relaunched adopte une définition plus restrictive du concept de thème que Essential Scrum. Dans Product Roadmaps Relaunched, un thème sert uniquement à décrire des fonctionnalités de façon imprécise.
Exemple tiré du livre Product Roadmaps Relaunched :
- Theme: Billing & payments
- Subtheme: Billing & payments API integration
- Subtheme: API integration testing
Pour résumer :
- Essential Scrum inclut des thèmes qui ne sont pas seulement liés aux fonctionnalités, mais aussi à la stratégie globale, à l’organisation, voire aux aspects techniques et processus internes.
- Product Roadmaps Relaunched reste focalisé sur l'expérience utilisateur et les besoins clients, avec des thèmes qui expriment des fonctionnalités sans trop rentrer dans les considérations techniques ou organisationnelles.
#JaiDécidé d'adopter la définition de "Theme" donnée dans Essential Scrum.
Journal du vendredi 07 février 2025 à 14:03
Pendant l'année 2014, Athoune m'a fait découvrir les concepts DevOps "Baking" et "Frying".
Je le remercie, car ce sont des concepts que je considère très importants pour comprendre les différents paradigmes de déploiement.
Je n'ai aucune idée dans quelles conditions il avait découvert ces concepts. J'ai essayé de faire des recherches limitées à l'année 2014 et je suis tombé sur cette photo :
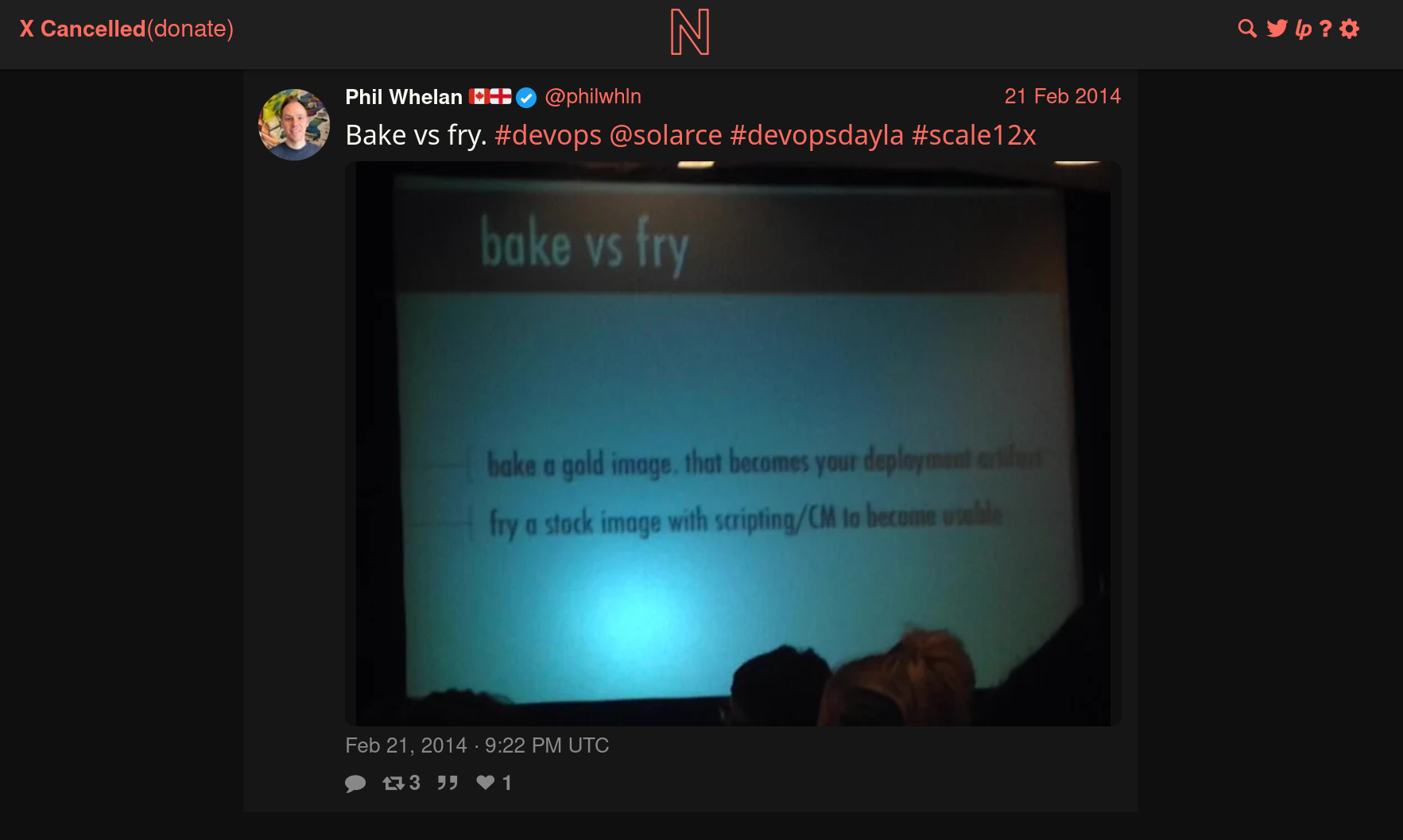
J'en déduis que cela devait être un sujet à la méthode dans l'écosystème DevOps de 2014.
Cet ami me l'avait très bien expliqué avec une analogie du type :
« Le baking en DevOps, c’est comme dans un restaurant où les plats sont préparés en cuisine et ensuite apportés tout prêt salle à la table du client. Le frying, c’est comme si le plat était préparé directement en salle sur la table du client. »
Bien que cette analogie ne soit pas totalement rigoureuse, elle m'a bien permis de saisir, en 2014, le paradigme Docker qui consiste à préparer des images de container en amont. Ce paradigme permet d'installer, de configurer ces images "en cuisine", donc pas sur les serveurs de production, "de goûter les plats" et de les envoyer ensuite de manière prédictible sur le serveur de production.
Ces images peuvent être construites soit sur la workstation du développeur ou mieux, sur des serveurs dédiés à cette fonction, comme Gitlab-Runner…
Définitions proposées par LLaMa :
Baking (ou "Image Baking") : Il s'agit de créer une image de serveur prête à l'emploi, avec tous les logiciels et les configurations nécessaires déjà installés et configurés. Cette image est ensuite utilisée pour déployer de nouveaux serveurs, qui seront ainsi identiques et prêts à fonctionner immédiatement. L'avantage de cette approche est qu'elle permet de réduire le temps de déploiement et d'assurer la cohérence des environnements.
Frying (ou "Server Frying") : Il s'agit de déployer un serveur "nu" et de le configurer et de l'installer à la volée, en utilisant des outils d'automatisation tels que Ansible, Puppet ou Chef. Cette approche permet de personnaliser la configuration de chaque serveur en fonction des besoins spécifiques de l'application ou du service.
Exemple :
Cas d'usage Baking Frying Docker Construire une image complète ( docker build) et la stocker dans un registreLancer un conteneur minimal et installer les dépendances au démarrage. Machines virtuelles (VMs) Créer une image VM avec Packer et la déployer telle quelle Démarrer une VM de base et appliquer un script d’installation à la volée CI/CD Compiler et packager une application en image prête à être déployée Construire l’application à chaque déploiement sur la machine cible
En 2014, lorsque le concept de baking m’a été présenté, j’ai immédiatement été enthousiasmé, car il répondait à trois problèmes que je cherchais à résoudre :
- Réduire les risques d’échec d’une installation sur le serveur de production
- Limiter la durée de l’indisponibilité (pendant la phase d’installation)
- Éviter d'augmenter la charge du serveur durant les opérations de build lors de l’installation
Depuis, j'évite au maximum le frying et j'ai intégré le baking dans ma doctrine d'artisan développeur.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Journal du mardi 28 janvier 2025 à 13:49
Alexandre me dit : « Le contenu de Speed of Code Reviews (https://google.github.io/eng-practices/review/reviewer/speed.html) ressemble à ce dont tu faisais la promotion dans notre précédente équipe ».
En effet, après lecture, les recommandations de cette documentation font partie de ma doctrine d'artisan développeur.
Note: j'ai remplacé CL qui signifie Changelist par Merge Request.
When code reviews are slow, several things happen:
- The velocity of the team as a whole is decreased. Yes, the individual who doesn’t respond quickly to the review gets other work done. However, new features and bug fixes for the rest of the team are delayed by days, weeks, or months as each Merge Request waits for review and re-review.
- Developers start to protest the code review process. If a reviewer only responds every few days, but requests major changes to the Merge Request each time, that can be frustrating and difficult for developers. Often, this is expressed as complaints about how “strict” the reviewer is being. If the reviewer requests the same substantial changes (changes which really do improve code health), but responds quickly every time the developer makes an update, the complaints tend to disappear. Most complaints about the code review process are actually resolved by making the process faster.
- Code health can be impacted. When reviews are slow, there is increased pressure to allow developers to submit Merge Request that are not as good as they could be. Slow reviews also discourage code cleanups, refactorings, and further improvements to existing Merge Request.
J'ai fait le même constat et je trouve que cette section explique très bien les conséquences 👍️.
How Fast Should Code Reviews Be?
If you are not in the middle of a focused task, you should do a code review shortly after it comes in.
One business day is the maximum time it should take to respond to a code review request (i.e., first thing the next morning).
Following these guidelines means that a typical Merge Request should get multiple rounds of review (if needed) within a single day.
Je partage et recommande cette pratique 👍️.
If you are too busy to do a full review on a Merge Request when it comes in, you can still send a quick response that lets the developer know when you will get to it, suggest other reviewers who might be able to respond more quickly.
👍️
Large Merge Request
If somebody sends you a code review that is so large you’re not sure when you will be able to have time to review it, your typical response should be to ask the developer to split the Merge Request into several smaller Merge Requests that build on each other, instead of one huge Merge Request that has to be reviewed all at once. This is usually possible and very helpful to reviewers, even if it takes additional work from the developer.
Je partage très fortement cette recommandation et je pense que c'est celle que j'avais le plus de difficulté à faire accepter par les nouveaux développeurs.
Quand je code, j'essaie de garder à l'esprit que mon objectif est de faciliter au maximum le travail du reviewer plutôt que de chercher à minimiser mes propres efforts.
J'ai sans doute acquis cet état d'esprit du monde open source. En effet, l'un des principaux défis lors d'une contribution à un projet open source est de faire accepter son patch par le mainteneur. On comprend rapidement qu'un patch doit être simple à comprendre et rapide à intégrer pour maximiser ses chances d'acceptation.
Un bon patch doit remplir un objectif unique et ne contenir que les modifications strictement nécessaires pour l'atteindre.
Je suis convaincu que si une équipe de développeurs applique ces principes issus de l'open source dans leur contexte professionnel, leur efficacité collective s'en trouvera grandement améliorée.
Par ailleurs, une Merge Request de taille réduite présente plusieurs avantages concrets :
- elle est non seulement plus simple à rebase,
- mais elle a aussi plus de chances d'être mergée rapidement.
Cela permet à l'équipe de bénéficier plus rapidement des améliorations apportées, qu'il s'agisse de corrections de bugs ou de nouvelles fonctionnalités.
Quelle est la fonction de "/deployment-playground/" dans mes projets ?
L'objectif de cette note est d'expliquer ce que sont les dossiers /deployment-playground/ et ma pratique consistant à les intégrer dans la plupart de mes projets de développement web.
Je pense me souvenir que j'ai commencé à intégrer ce type de dossier vers 2018.
Au départ, je nommais ce dossier /demo/ dont l'objectif était le suivant : permettre à un développeur de lancer localement le plus rapidement possible une instance de démo complète de l'application.
Pour cela, ce dossier contenait généralement :
- Un
docker-compose.ymlqui permettait le lancer tous les services à partir des dernières images Docker déjà buildé. Soit les images de la version de l'environnement de développement, staging ou production. - Un script d'injection de données de fixtures ou de données spécifiques de démonstration.
- Mise à disposition des logins / password d'un ou plusieurs comptes utilisateurs.
Cet environnement était configuré au plus proche de la configuration de production.
Avec le temps, j'ai constaté que mon utilisation de ce dossier a évolué. Petit à petit, je m'en servais pour :
- Aider les développeurs à comprendre le processus de déploiement de l'application en production, en fournissant une représentation concrète des résultats des scripts de déploiement.
- Permettre aux développeurs de tester localement la bonne installation de l'application, afin de reproduire les conditions de production en cas de problème.
- Faciliter l'itération locale sur l'amélioration ou le refactoring de la méthode de déploiement.
- Et bien d'autres usages.
J'ai finalement décidé de renommer ce dossier deployment-playground, un bac à sable pour "jouer" localement avec la configuration de production de l'application.
Je ne peux pas vous partager mes exemples beaucoup plus complets qui sont hébergés sur des dépôts privés, mais voici quelques exemples minimalistes dans mes dépôts publics :
- https://github.com/stephane-klein/sveltekit-user-auth-postgres-rls-skeleton/tree/main/deployment-playground
- https://github.com/stephane-klein/sveltekit-ssr-skeleton/tree/main/deployment-playground
- https://github.com/stephane-klein/gibbon-replay/tree/main/deployment-playground
- https://github.com/stephane-klein/sveltekit-tendaro-webshell-skeleton/tree/main/deployment-playground
Journal du mardi 31 décembre 2024 à 17:12
Dans le billet de blog d'Emmanuele Bassi "The Mirror", j'ai découvert l'expression informatique "Flag day".
Releasing GLib 3.0 today would necessitate breaking API in the entirety of the GNOME stack and further beyond; it would require either a hard to execute “flag day”, or an impossibly long transition, reverberating across downstreams for years to come.
L'article Wikipédia donne la définition suivante :
A flag day, as used in system administration, is a change which requires a complete restart or conversion of a sizable body of software or data. The change is large and expensive, and—in the event of failure—similarly difficult and expensive to reverse.
D'après ce que j'ai compris, un "Flag day" désigne un déploiement complexe où plusieurs systèmes doivent être mis à jour simultanément, sans possibilité de retour en arrière. C'est une approche risquée, car elle implique une transition brutale entre l'ancien et le nouveau système, souvent difficile à gérer dans des environnements interdépendants.
Un "Flag day" s'oppose à une migration en douceur.
C'est une situation que j'essaie d'éviter autant que possible. Des méthodes comme les Feature toggle ou l'introduction d'un système de versionnement permettent d'effectuer des migrations douces, par petites itérations, testables et sans interruption de service.
Concernant l'origine de cette expression, je lis :
This systems terminology originates from a major change in the Multics operating system's definition of ASCII, which was scheduled for the United States holiday, Flag Day, on June 14, 1966.
Je pense qu'à l'avenir, je vais utiliser cette expression.
Qu'est-ce qu'un "Script Helper" ?
J'utilise souvent le terme "Script Helper". Dans cette note, je vais tenter de le définir.
Un script dit « helper » est un script qui n'est pas essentiel au cœur du projet et qui ne contient pas de code métier. Son rôle est d’automatiser des tâches courantes et réutilisables pour le développeur.
L’écriture de ces scripts permet de centraliser et de versionner leur contenu, tout en réduisant les risques d’erreurs d’exécution.
Ma définition et objectif d'un "Workspace" dans un "environnement de développement" ?
Dans une note précédente, j'ai donné ma définition et les objectifs d'un "Development kit".
Dans cette note, je souhaite donner ma définition et les objectifs d'un workspace dans un "environnements de développement".
Un workspace est un dossier, qui contient des paramètres de configuration spécifiques — généralement sous la forme de variables d'environnements — qui permettent d'interagir sur une ou plusieurs instances de services, d'un environnement précis.
Généralement ce dossier contient des guides d'instructions pour réaliser des actions spécifiques sur le workspace et des scripts de type "helpers".
Exemple de workspaces :
staging/remote-workspace/: un workspace utilisé pour effectuer des actions sur les services déployés en staging sur des serveurs distants ;staging/local-workspace/: un workspace d'installer localement des services dans les mêmes conditions que sur l'environnement staging ;development/local-workspace/: un dossier workspace, qui permet de travailler — contribuer — localement sur le ou les services.
Voir aussi :
Journal du samedi 07 décembre 2024 à 20:49
Je pense être arrivé à une solution plus ou moins satisfaisante pour le Projet 19 - "Documenter une méthode pour synchroniser un monorepo vers des multirepos qui fonctionne dans les deux sens".
Voici-ci, ci-dessous, les étapes de la démonstration qui sont détaillées dans le README.md du repository poc-git-monorepo-multirepos-sync.
- Je crée deux repositories :
frontendetbackend(multi repositories) ; - J'utilise le script tomono pour les intégrer dans un monorepo nommé
monorepo; - J'ajoute deux fichiers à la racine de
monorepo:README.mdet.mise.toml; - J'effectue des changements dans le repository
frontend, je commit ; - Je pull les changements du repository
frontendversmonorepo; - Dans
monorepo, j'effectue des changements dans le dossierfrontend/, je commit ; - J'utilise
cd frontend/; git format-patch --relative -1 HEADpour générer un patch qui contient les changements que j'ai effectués dans le dossierfrontend/; - Je vais dans le repository
frontendet j'applique les changements contenus dans ce patch avec la commandgit apply monpatch.patchou avecgit am monptach.patch.
Pour le moment, j'ai privilégié l'option git patch, parce que je souhaite suivre la méthode la plus "manuelle" que j'ai pu trouver lorsque je dois intervenir sur les repositories upstream, parce que je ne veux prendre aucun risque de perturber mes collègues avec mon initiative de monorepo.
Le repository GitHub suivant contient le résultat final du monorepo : https://github.com/stephane-klein/poc-git-monorepo-multirepos-sync-result-example/.
Est-ce que je suis satisfait du résultat de cette démo ?
La réponse est oui, bien que je ne sois pas satisfait de quelques éléments.
Par exemple, les fichiers de frontend présents dans ce commit ne sont pas dans le dossier frontend.
J'aimerais que ces titres de commits contiennent un prefix [frontend] ... et [backend].... Je pense que cela doit être possible à implémenter en modifiant le script tomono.
Est-ce que c'est pénible à utiliser ? Pour le moment, ma réponse est « je ne sais pas ».
Je vais tester cette méthode avec deux projets. Je pense écrire une note de bilan de cette expérience d'ici à quelques semaines.
Journal du mercredi 04 décembre 2024 à 14:56
Alexandre a eu un breaking change avec Mise : https://github.com/jdx/mise/issues/3338.
Suite à cela, j'ai découvert que Mise va prévilégier l'utilisation du backend aqua plutôt que Asdf :
we are actively moving tools in the registry away from asdf where possible to backends like aqua and ubi which don't require plugins.
J'ai découvert au passage que Mise supporte de plus en plus de backend, par exemple Ubi et vfox.
Je constate qu'il commence à y avoir une profusion de "tooling version management" : Asdf,Mise, aqua, Ubi, vfox !
Je pense bien qu'ils ont chacun leurs histoires, leurs forces, leurs faiblesses… mais j'ai peur que cela me complique mon affaire : comment arriver à un consensus de choix de l'un de ces outils dans une équipe 🫣 ! Chaque développeur aura de bons arguments pour utiliser l'un ou l'autre de ces outils.
Constatant plusieurs fois que le développeur de Mise a fait des breaking changes qui font perdre du temps aux équipes, mon ami et moi nous sommes posés la question si, au final, il ne serait pas judicieux de revenir à Asdf.
D'autre part, au départ, Mise était une simple alternative plus rapide à Asdf, mais avec le temps, Mise prend en charge de plus en plus de fonctionnalités, comme une alternative à direnv , un système d'exécution de tâches, ou mise watch.
Souvent, avec des petits défauts très pénibles, voir par exemple, ma note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
Alexandre s'est ensuite posé la question d'utiliser un jour le projet devenv, un outil qui va encore plus loin, basé sur le système de package Nix.
Le projet devenv me fait un peu peur au premier abord, il gère "tout" :
- Comme Asdf et Mise : l'installation des outils, packages et langages
- Support de scripts "helper"
- Intégration de Docker
- Support de process
- Support du SDK Android
Il fait énormément de choses et je crains que la barrière à l'entrée soit trop haute et fasse fuir beaucoup de développeurs 🤔.
Tout cela me fait un peu penser à Bazel (utilisé par Google), Pants (utilisé par Twitter), Buck (utilisé par Facebook) et Please.
Tous ces outils sont puissants, je les ai étudiés en 2018 sans arrivée à les adopter.
Pour le moment, mes development kit nécessitent les compétences suivantes :
- Comprendre les rudiments d'un terminal Bash ;
- Arriver à installer et à utiliser Mise et direnv ;
- Maitriser Docker ;
- Savoir lire et écrire des scripts Bash de niveau débutant.
Déjà, ces quatre prérequis posent quelques fois des difficultés d'adoption.
Journal du mercredi 27 novembre 2024 à 11:29
Il y a quelques jours, j'ai écrit une note au sujet des stratégies de versionning et aujourd'hui, #JaiDécouvert le site TrunkVer (https://trunkver.org/) (from).
We have identified a frequent source of avoidable confusion, conflict and cost in the software delivery process caused by versioning software that should not be versioned - or rather, the versioning should be automated.
👍️
However, we keep encountering teams and organizations that apply semantic versioning or a custom versioning scheme to software that does not need any of that - and through this, they create an astonishing amount of unnecessary work such as arguing whether or not a certain piece of software should be called “alpha”, “beta”, “rho”, “really final v4” etc, manually creating tickets listing the changes or even specialized gatekeeper roles such as “release engineer” - in the worst case a single person in the whole organization. Because this makes it harder, boring and costly to deploy, it systematically reduces the number of deployments, and through this the delivery performance of the organization.
👍️
Depuis 20 ans, j'ai rarement développé des librairies ou des API REST utilisées par des tiers.
Par conséquent, je n'ai pratiquement jamais eu besoin d'utiliser Semantic Versioning dans mes projets.
La plupart des projets sur lesquels je travaille suivent le modèle "Rolling release".
Je croise trop souvent des développeurs utilisant la spécification Semantic Versioning alors que leur projet suit le modèle Rolling release et je pense que TrunkVer serait bien plus adapté à leur contexte.
Cela fait plusieurs années maintenant que j'utilise la méthode suivante pour identifier "la version" de ce que je déploie.
Dans mes scripts de déploiement, je génère un fichier version.json, comme ceci (example) :
cat <<EOF > version.json
{
"environment": "prod",
"branch": "$(git rev-parse --abbrev-ref HEAD)",
"gitDate": "$(git show -s --format=%ci | sed "s/ /_/g")",
"buildStamp": "$(env TZ=Europe/Paris date '+%Y-%m-%d_%H:%M:%S-%Z')",
"gitHash": "$(git rev-parse HEAD)"
}
EOF
Ensuite je l'insert au moment du docker build et je l'expose sur une URL http.
Ce qui donne, par exemple, ceci :
$ curl https://notes.sklein.xyz/version.json
{
"environment": "prod",
"branch": "main",
"gitDate": "2024-12-03_23:43:26_+0100",
"buildStamp": "2024-12-03_23:51:09-CET",
"gitHash": "04c83c82a663260626e02502be1015d23b4859c2"
}
Ma méthode ne correspond pas exactement dans la forme à la méthode TrunkVer mais cela s'en rapproche.
Journal du mercredi 27 novembre 2024 à 10:52
Depuis des années, j'hésite toujours entre get et fetch lors du naming de fonctions.
Je viens de demander à ChatGPT la différence entre ces deux verbes et quand est-ce qu'il est préférable d'utiliser l'un ou l'autre.
Voici sa réponse :
Pour
get:
- Signification : Indique une opération simple pour récupérer ou accéder à des données.
- Contexte d'utilisation :
- Utilisé pour des accès rapides et directs à des données qui sont déjà disponibles localement (en mémoire, en cache, etc.).
- Souvent employé dans des fonctions "getter" ou des méthodes utilitaires simples.
Pour
fetch:
- Signification : Suggère une opération potentiellement asynchrone ou coûteuse, comme récupérer des données d'une source externe.
- Contexte d'utilisation :
- Lorsqu'une action supplémentaire est requise pour obtenir les données, comme un appel réseau ou une requête vers une API.
- Implique souvent un effort ou une complexité plus grande que
get.
J'ai essayé d'obtenir plus de ressources concernant cette déclaration.
J'ai trouvé ceci :
Example: fetch implies that some entity needs to go and get something that is remote and bring it back. Dogs fetch a stick, and retrieve is a synonym for fetch with the added semantic that you may have had possession of the thing prior as well. get is a synonym for obtain as well which implies that you have sole possession of something and no one else can acquire it simultaneously.
-
Ma recherche "
fetch get" sur English Language and Usage Stack Exchange : -
Sur MDN Web Docs, j'ai effectué des recherches de fonctions qui commencent par
getoufetch. Je constate que le verbefetchest utilisé lorsque la fonction va chercher des données sur le réseau.
Suite à cette étude, j'ai décidé d'utiliser fetch plutôt que get pour toutes les fonctions allant chercher des données en dehors du "processus local". Quelques exemples :
- Utilisation de
fetchpour nommer une fonction javascript frontend ou backend, qui effectue des requêtes REST ou GraphQL. - Utilisation de
getpour nommer une fonction PL/pgSQL qui effectue uniquement des requêtes SQL sur la base de données locale (pas de requêtes vers des Foreign Data (PostgreSQL)). Ici "locale" signifie que l'instance qui exécute la fonction PL/pgSQL est la même que celle qui contient les tables requêtées (voir cet échange).
Pourquoi j'utilise direnv dans mes development kit ?
Dans cette note, je souhaite expliquer pourquoi j'utilise et j'aime utiliser direnv.
Je suis toujours en train d'essayer de créer des development kit me permettant de travailler dans un environnements de développement toujours plus agréable.
J'ai découvert direnv en 2017 et j'ai commencé à l'utiliser dans un projet en avril 2019.
direnv s'utilise dans un shell, il charge et décharge automatiquement les variables d'environnement spécifiées dans un fichier .envrc lorsqu'on entre et quitte un répertoire.
Exemple :
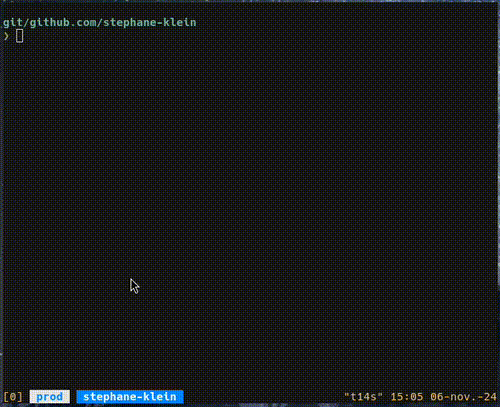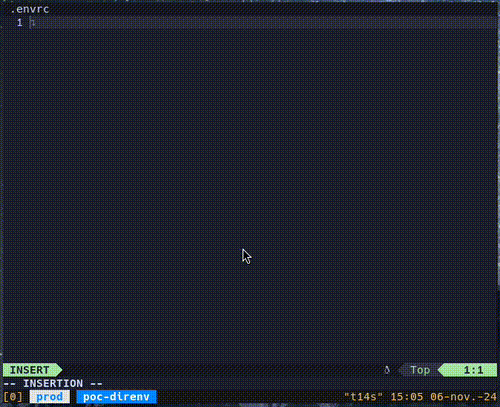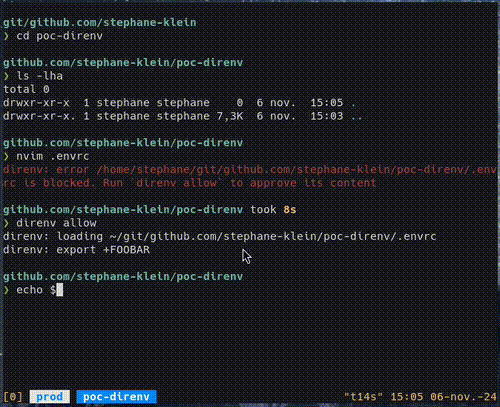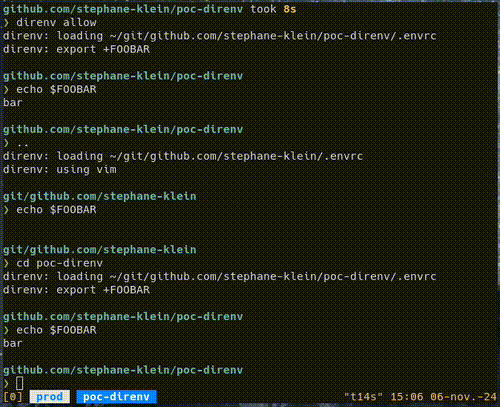
Voici les use cases listées sur le site officiel de direnv :
- Load 12factor apps environment variables
- Create per-project isolated development environments
- Load secrets for deployment
Voici quelques exemples concrets de mon utilisation de direnv :
- chargement automatique des paramètres de configuration et secret pour :
source .secret
export SCW_DEFAULT_ORGANIZATION_ID="...." # Get it, in https://console.scaleway.com/organization/settings
export SCW_ACCESS_KEY="..."
# This variable environments are used by Grafana Grizzly
export GRAFANA_URL=http://grafana.$(terraform output --json | jq -r '.server3_public_ip | .value').nip.io
export GRAFANA_USER=admin
export GRAFANA_TOKEN=password
- dans un projet Javascript :
export POSTGRES_ADMIN_URL="postgres://postgres:password@localhost:5432/myapp"
export POSTGRES_URL="postgres://webapp:password@localhost:5432/myapp"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export SECRET="secret"
export APP_HOSTNAME="localhost"
export MAIL_FROM="noreply@example.com"
Les fichiers .envrc sont des scripts shell, il est possible comme dans l'exemple au-dessus, d'utiliser source .secret pour charger un autre fichier.
Je versionne toujours le fichier .envrc, tandis que j'ignore (.gitignore) les fichiers .secret contenant des informations sensibles qui ne doivent pas être publiés dans le repository git.
Après avoir installé un development kit, j'indique à l'utilisateur les instructions à suivre pour installer les éléments de base du projet, comme Mise, Docker…, et la mise en place des secrets.
Mon objectif est ensuite de permettre à l'utilisateur de l'environnement de développement d'interagir avec des « scripts helpers » sans nécessiter de configuration préalable, simplement en entrant ou sortant des dossiers. Les dossiers sont utilisés comme « workspace contexte ».
Voir aussi : development kit skeleton d'installation de direnv
À la recherche d'un environnement de développement sans le savoir : mes années 1999-2008
Je pense que je m'intéresse au sujet des "development environment" ou development kit depuis 1999.
À l'époque, même si je ne connaissais pas encore ces concepts, j'en ressentais déjà le besoin.
Par exemple, lorsque j'ai voulu contribuer au projet KDE, je cherchais des solutions et des bonnes pratiques pour organiser ma station de travail de manière à pouvoir compiler et installer KDE sans risquer de casser mon environnement de bureau.
Malheureusement, je n'y suis pas parvenu 😔.
Avec le recul, je réalise que ces pratiques étaient souvent transmises de manière informelle, principalement par des échanges oraux ou via des messages sur IRC. En somme, il s'agissait d'un véritable "bouche-à-oreille" numérique.
Je pense que la majorité des développeurs devaient faire face aux mêmes difficultés. Je pense aussi qu’ils devaient prendre beaucoup de temps à trouver leur propre méthode, année après année.
J’en ai eu une fois la confirmation. En 2002, je suis allé au FOSDEM, pour rencontrer entre autres David Faure, un core développeur français de KDE.
J’ai échangé avec lui et il m’a montré de nombreuses astuces qu’il utilisait… je n’ai pas tout compris, je n’ai pas réussi à les retenir…
J’en ai conclu que les développeurs avaient sans doute chacun leurs propres méthodes de développement non documentées.
Question qui me vient alors à l’esprit : alors qu'ils contribuent à des logiciels libres et partagent leur code source, pourquoi les développeurs ne partagent-ils pas aussi leurs environnements de développement ?
Journal du mercredi 06 novembre 2024 à 14:18
Je viens de réfléchir à l'usage des termes "development environment" et "development kit".
Je pense que le dépôt gitlab-development-kit est un "development kit" qui permet d'installer et configurer un "development environment" pour travailler sur le projet GitLab.
Journal du lundi 07 octobre 2024 à 15:48
Je viens de déjeuner avec un ami qui m'avait fait découvrir Team Topologies. Cette fois, il m'a fait découvrir le modèle unFIX.
First, the unFIX model is a pattern library that provides many options for describing an organization design, ways of working within a team, decision-making, goal-setting, and more.
Think of the pattern options in the unFIX model as Lego blocks. Like these building blocks, they provide the flexibility to construct and adapt your organization according to your unique needs and preferences.
-- from
Je n'ai pas encore étudié le modèle unFIX.
Un autre sujet de notre discussion a porté sur la difficulté de définir des noms d'équipe générique pour des Stream-aligned team.
Il m'a raconté : « J'ai essayé de m'opposer à l'utilisation des Avengers comme nom d'équipe, mais je n'ai pas réussi ».
Cela m'a fait sourire, car j'ai rencontré un problème similaire avec des noms de Pokémon. Finalement, j'ai cédé et accepté ces noms, à condition de les accompagner de préfixes génériques comme "Team A - ", "Team B - ", etc.
Cette approche s’inspire du pattern de nommage des versions d’Ubuntu, qui utilise un format combinant un identifiant technique et un nom plus créatif, par exemple : "Ubuntu 24.10 - Oracular Oriole".
Pour ma prospection Freelance, il m'a conseillé de regarder du côté de la communauté Tech.Rocks.
Il a confirmé mes retours au sujet de Malt : ses amis ne reçoivent pas de propositions de mission via Malt.
Il m'a partagé cet article Building Stronger, Happier Engineering Teams with Team Topologies (Docker et Team Topologies).
Stratégie de grosse mise à jour de dépendances
Un ami m'a posé la question suivante :
Imaginez-vous face à un projet React avec des dépendances fortement obsolètes, fonctionnant sur une version de Node datant d’il y a cinq ans. En plus, il n’existe aucun test automatisé, qu'il s'agisse de tests unitaires ou d'intégration. Vous êtes contraint de réaliser cette mise à jour, car elle bloque les futurs développements et entraîne une accumulation excessive de dette technique. Quelle serait votre approche dans cette situation ?
- Affronter le problème de front : On prend le taureau par les cornes, on met tout à jour d’un coup, quitte à rencontrer des breaking changes ou des bugs non anticipés, que l’on corrigera rapidement (option rapide mais risquée).
- Prudence avant tout : On commence par ajouter des tests sur les parcours critiques, puis on met à jour les dépendances une par une, même si cela prend plus de temps (option lente mais sécurisée).
- Déléguer la décision : Ce n’est pas à moi de décider. Je présente ces options aux responsables et leur laisse la décision finale.
Avant de pouvoir répondre à cette question, j'ai besoin de déterminer la criticité business de cette application.
Est-ce que les décideurs acceptent que l'application puisse être en panne pendant 1 heure ? 1 jour ? 3 jours ? Ou aucune interruption n'est-elle tolérée ?
Si la réponse est "moins de 24 heures", alors je considère que l'application est critique.
Ensuite j'ai besoin de savoir si la mise à jour du projet peut être réaliser de manière iso-fonctionnelle (sans changement fonctionnel), sans changement d'User Interface et sans changement du modèle de donnée.
Si la réponse est positive, cela signifie qu'il sera facile de revenir à la version précédente en cas de problème, ce qui simplifie grandement le processus de refactoring.
Une de mes premières actions concrètes serait de "dockeriser" le projet pour faciliter son déploiement et permettre un retour rapide à une version antérieure si nécessaire.
Une autre question importante : d'autres développeurs interviendront-ils sur le projet pendant la période de refactoring ? Est-ce que des corrections de bugs ou de nouvelles fonctionnalités doivent être intégrées durant cette période ?
Si la réponse à l'une de ces questions est "oui", je recommande de dupliquer le projet dans deux dossiers distincts au sein d'un monorepo :
- Le premier dossier contiendra la version actuelle de l'application.
- Le second dossier contiendra la version en cours de refactoring.
Pendant toute la durée du refactoring, les corrections de bugs et les nouvelles fonctionnalités devront être appliquées aux deux versions.
Dans tous les cas, pour ne pas perdre pied, j'essaierai de mettre à jour l'application petit à petit.
Je commencerai par essayer de mettre à jour toutes les versions mineures des packages.
Ensuite, j'essaierai de me renseigner sur les breaking changes des mises à jour majeures des packages.
Ma réponse si l'application est critique
Si l'application est critique, alors il est inacceptable que les utilisateurs découvrent eux-mêmes les bugs et doivent contacter le support pour signaler les problèmes.
Si l'application ne comporte aucun test, je suppose qu'elle est testée manuellement et que son périmètre fonctionnel reste limité.
L'une de mes premières actions serait de définir un ou plusieurs scénarios de tests manuels prioritaires, que je ferais valider par les décideurs.
Ensuite, je proposerai aux décideurs d'envisager le développement de quelques tests fonctionnels automatisés. Une décision rationnelle à ce sujet dépendrait du temps nécessaire pour effectuer ces tests manuellement et, encore une fois, de la criticité business de l'application.
Enfin, je mettrai en place un système de déploiement progressif, de type A/B testing, permettant de déployer la nouvelle version de l'application à un nombre très restreint d'utilisateurs dans un premier temps.
Ma réponse si l'application est non critique
Si, d'un point de vue business, il est acceptable que les utilisateurs découvrent les bugs, alors je n'implémenterai pas de tests automatisés.
Je définirai tout de même quelques scénarios de tests manuels que le développeur seul exécutera.
Si cela ne demande pas trop de temps, je mettrai en place un système de déploiement progressif, tel que l'A/B testing, permettant de déployer la nouvelle version de l'application à un nombre restreint d'utilisateurs dans un premier temps.
Journal du mercredi 25 septembre 2024 à 11:50
#OnMaPartagé la vidéo YouTube nommée Pourquoi les projets informatiques vont dans le mur ?.
Je ne connaissais pas la dérive de ce projet de migration de SAP vers ERP Oracle Fusion de la mairie de Birmingham : La 2e ville du Royaume-Uni s'est déclarée en faillite, plombée entre autres par les dérives d'un projet de migration vers l'ERP Oracle Fusion. Après des années de retards, de problèmes de contrôle, de gestion hasardeuse, la facture du projet a quintuplé pour atteindre 115 M€.
J'ai fait quelques recherches dans les commentaires Hacker News et j'ai trouvé ceci :
My state of Oregon paid Oracle something like $250M for a healthcare system that never materialized. The lawsuit that followed was settled for $100M, but most of that was “free” Oracle licenses and no less than $60M of customer support.
-- from
🙈
Actually it's the opposite. I worked for an NGO half a decade ago, and they wanted to add 2FA authentication to their login system used by ~400 staff. I created a quick demo using Google Authenticator in less than a week.
However the director of IT didn't like this solution. He insisted we use RSA keys and hire IBM to build a solution using that - I think the original estimate was a few million $ and it would take six months or so for their team (of basically new graduates) to build.
I asked my boss why the director was pushing so much for IBM to build it:
He told me that if we build it, and it doesn't work, then the director has to take the blame. If IBM build it, and it doesn't work, then IBM take the blame.
-- from
😭
Yes. There’s also the revolving door problem. The bureaucrat making the decision is often angling for a cushy role at the contractor. And the contractor is making the offer under the table to get the gig. From the decision makers perspective, it doesn’t matter if the project succeeds, they’ll be long gone. I’ve seen this with my own eyes.
-- from
😔
How do they stay in business?
Oracle's main line of competency is not providing good software services. They are in fact, specialists of acquiring government contracts.
-- from
Has anyone ever heard of an Oracle project that has ever ended well?
After 25 years in IT consulting all over the US in different businesses, Oracle is never NOT a 4 letter world, where projects involving them always over-promise, under-deliver, and project costs end up some 3-10x any initial projection. Particularly any ERP, CRM, now EMR in hospitals as well since acquiring Cerner. Anyone that does use them only do as a necessary evil of some dubious or shady circumstances, otherwise Oracle is a term almost universally reviled and hated amongst end users and organization leadership alike.
An insider at Birmingham City Council who has been closely involved in the project told Computer Weekly it went live “despite all the warnings telling them it wouldn’t work”.
Discussing how the Oracle system failure impacted the council’s ability to manage its finances, the insider said: “We were withholding thousands of supplier payments because we couldn’t make any payments. We didn’t have any direct debits for cash collection. We had no cash collection, no bank reconciliation. When you do a project of this size, you must have your financial reporting and you must have a bank reconciliation system that tells you where the money is, what’s being spent and what’s being paid.”
Since going live, the Oracle system effectively scrambled financial data, which meant the council had no clear picture of its overall finances.
The insider said that by January 2023, Birmingham City Council could not produce an accurate account of its spending and budget for the next financial year: “There’s no way that we could do our year-end accounts because the system didn’t work.”
-- from
The June 2023 Birmingham City Council report to cabinet stated that due to issues with the council’s bank reconciliation system (BRS), a significant number of transactions had to be manually allocated to accounts rather than automatically via the Oracle system. However, Computer Weekly has seen an enterprise resource planning (ERP) implementation presentation given in 2019, which shows that the council was made aware of these issues at that time, three years before the go-live date.
...
The lack of a functioning BRS has directly contributed to the council’s current financial crisis. In BCC’s April 2024 audit report, councillor Grindrod said: “We couldn’t accurately collect council tax or business rates.”
As of April 2024, it is believed the manual intervention needed for the bank reconciliation process is costing the council £250,000 per month.
-- from
Peoplesoft/Oracle ERP has had over 30 year of experience selling to local governments globally.
When dealing with procurement in countries that aren't the US, riles and regulations are much more difficult and unintuitive, and also provide marginal RoI.
This is why companies like Workday and Salesforce don't care to compete with Oracle or SAPs in these kinds of contracts - they don't have the right relationships with channel partners and systems integrators needed.
When a city council places a tender for an ERP system, they won't be doing the work in-house due to regulatory and budget allocation reasons. Instead they'll farm out the work to local contractors, MSPs, and Systems Integrators instead.
PLG driven companies like Workday and Salesforce dislike working with SIs and MSPs as much because channel partners don't care about upselling features in the products they bought - they wanna keep the customer satiated instead.
Also, the dollars spent getting the contract might not have a significant RoI when factoring the contract size itself.
-- from
J'ai trouvé ceci sur Reddit :
I work as an implementation consultant for finance software, albeit a much smaller scale one than SAP/Oracle, but I’ve been in this line of work for several years. This kind of thing is fairly common, and I think a several year long project that Lidl undertook to do the same thing went the same way, which is money down the toilet.
All of the cost is in the services. The clients are billed at an hourly or daily rate for meetings, project management, issue resolution, emails etc. The problem with huge projects like these is that institutions like councils have their own very specific processes and are unwilling to change, because more often than not the employees are set in their ways and don’t want to learn anything, but also changing one or two things could have a huge effect on other things. In finance systems there are often several integrations, both incoming and outgoing, and the client will need a tailored solution to migrate everything. It would be easy if the client accepted that some things would have to change, but SAP and Oracle are very very customisable, and depending on the company doing the implementation everything will get customised to where there are all these new moving parts, new problems, and new things to learn. People also change their minds about what they want all the time, especially if the project wasn’t scoped or managed correctly.
In short, the software may be established, but the way it is implemented never is. Templates exist, but every business is different, and the public sector is particularly messy to deal with (underpaid and undertrained staff, tend to be a bit less motivated than private sector IME).
-- from
I tried several different SaaS solutions, mostly aimed at breweries. It was infuriating watching these things fit 98% of the requirement, but the missing 2% rendered the whole system inoperable. But the choice is just take it for £50/user/month or leave it.
I tried some open source options which were better, but were still far too rigid to a point where we'd be shaping our whole operations around the way our ERP wants us to do things, and getting to that point would take a lot of development.
In the end, it was legitimately easier to do it ourselves. And by that I mean me, a distiller, to develop a system from scratch. We now have a fully integrated ERP system that works around our processes, but was built using good practices so that things are very versatile and don't inherently depend on working a certain way. Some of these systems had moronic limitations that wouldn't even allow for an output to be used as an input into another process. Apparently everything has to be made in one process! Can you imagine how many use cases that single, completely unnecessary, restriction... restricts?
-- from
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Journal du mercredi 21 août 2024 à 09:39
Après avoir rédigé la note Commit Cavalier, #JaiDécouvert le concept de des projets de loi omnibus.
« Depuis les années 1980, cependant, les projets de loi omnibus sont devenus plus courants : ces projets de loi contiennent des dispositions, parfois importantes, sur un éventail de domaines politiques. »
-- from
Ceci m'a fait penser aux Merge Requests qui contiennent de nombreux petits commits, souvent de refactoring, qu'il serait fastidieux de passer en revue individuellement.
Je pense que je vais nommer ces Merge Request, des Merge Request Omnibus, ce néologisme sera une de mes marques idiosyncrasiques 😉.
J'ai donc décidé de baptiser ces Merge Requests des Merge Requests Omnibus. Ce néologisme deviendra l'une de mes marques idiosyncrasiques 😉.
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.
Journal du mardi 20 août 2024 à 09:33
#JaiLu Software estimates have never worked and never will
Je suis en accord — depuis très longtemps — avec le contenu de cet article.
Give up on estimates, and embrace the alternative method for making software by using budgets, or appetites, as we call them in our Shape Up methodology.
Cette méthode fait parti de ma doctrine d'artisan développeur.
Journal du vendredi 16 août 2024 à 13:17
J'ai relu cette note de David Larlet :
Silk = documentation et tests
Markdown based document-driven web API testing.
La rapidité d’exécution d’un outil écrit en Go est toujours surprenante, j’ai eu besoin de vérifier que les tests étaient bien passés pour être sûr de son bon fonctionnement… Mon expérience me montre qu’une documentation qui n’est pas testée/proche du code n’est jamais synchronisée et conduit à des frustrations pour les utilisateurs. Silk est un moyen de faire cela directement depuis votre markdown, ça me rappelle d’une certaine manière le couple docutils/reStructuredText. En rapide. Et je ne saurais trop insister sur l’importance d’avoir une suite de tests rapide pour qu’elle reste pertinente.
Raconter une histoire dans vos tests est plus verbeux mais assurément plus intéressant pour la personne qui cherchera à comprendre ce que vous avez implémenté. Il y a de grandes chances que ce soit vous. Le README du dépôt est un exemple de ce qui peut être réalisé.
Je pense que ce billet a participer à ma sensibilitasion à la notion de colocated documentation.
Journal du vendredi 16 août 2024 à 13:06
Dans ma note Keep it simple, stupid le plus longtemps possible j'ai écris :
Je me souviens de la quête vers le minimaliste dans le code de David Larlet : « Est-ce qu’il est possible d'enlever des couches dans la stack ? »
Je viens d'essayer de retrouver ces articles, mais ce n'est pas facile tellement les articles de David Larlet sont nombreux.
Pour le moment j'ai retrouvé les extraits ci-dessous ceci en lien avec le sujet.
Paternité
- Ajouter des couches
- Changer des couches
- Enlever des couches
- Changer des couches
- Mettre des couches
J’en suis à l’étape 3 dans ma maturité en tant que développeur. La paternité change les priorités et je pense qu’elle a un grand rôle dans le fait de vouloir remettre le focus sur la valeur apportée plus que sur la technique. Me battre pour une meilleure expérience utilisateur plutôt que contre un framework, chercher à se faire plaisir davantage via ce qui est produit que par un contentement technique.
Lorsque j’expérimente aujourd’hui, ce n’est plus pour découvrir une nouvelle bibliothèque mais pour trouver de nouveaux moyens de simplifier un problème. Dans ce contexte, il est intéressant de re-questionner la page blanche (cache), de re-challenger certaines bonnes pratiques communément admises (cache).
Autre extrait :
Leftpad
Every package that you use adds yet another dependency to your project. Dependencies, by their very name, are things you need in order for your code to function. The more dependencies you take on, the more points of failure you have. Not to mention the more chance for error: have you vetted any of the programmers who have written these functions that you depend on daily?
J’étais en train de préparer cette intervention lorsque le fiasco leftpad est arrivé dans l’écosystème NPM. Du coup, j’ai eu immédiatement plein d’articles faisant une ode à la simplicité, à la réduction de dépendances et mettant en garde contre les couches d’abstraction. Merci Azer Koçulu, je pouvais difficilement rêver mieux :-). Je ne vais pas tirer sur l’ambulance mais ça illustre presque trop bien mon propos.
as your project progresses, your team’s productivity will drop because of all the complexity and dependencies. You’ll need more people to maintain it, and more people with specific knowledge to maintain it. If your lead developers leave, you’re dead. You should be fighting complexity and not embracing it. Every added framework, and even library, makes your project more difficult to maintain. Avoid unnecessary frameworks and libraries from day one.
Jusqu’où aller dans cette démarche ? Par où commencer ?
Autre extrait :
Maybe it’s not too late for you, though. Perhaps, like me, you aren’t feeling particularly overworked. But are you feeling irritable, tired, and apathetic about the work you need to do? Are you struggling to concentrate on simple tasks?
Then maybe what you’re feeling is burnout, too.
J’ai travaillé pendant un an et demi avec Mozilla sur la partie paiement du Marketplace puis sur le site des extensions de Firefox. Et depuis un an avec Etalab sur la plateforme datagouv. Dans les deux situations, j’ai passé davantage de temps à lutter contre les outils plutôt qu’à les apprécier pour le travail rendu. C’est terrible car ceux-ci sont censés théoriquement faire gagner du temps mais sur le long terme cela se révèle être faux dans mon cas.
Je me demande si je ne suis pas en train de faire un burnout technique, non pas par trop de travail mais par manque de contrôle dans mes outils.
Autre extrait :
The aesthetic microlith
Growth for the sake of growth is the ideology of the cancer cell.
Edward Abbey
Toutes ces raisons m’ont amené à étudier une nouvelle piste. Cette appellation est une combinaison du Majestic Monolith (cache) et des microservices. Je me persuade qu’il y a une voie différente entre ces deux extrêmes. Une voie qui limite les fuites d’abstraction (cache) afin de réduire la dette technique et de favoriser l’inclusion de nouveaux membres dans une équipe. Une voie qui ne demande pas de réécrire la moitié de l’application tous les six mois car une nouvelle montée en version majeure n’est pas rétro-compatible. Une voie où l’on ne raisonne plus en termes de features et de bugs mais d’expérience utilisateur et de satisfaction pour l’ensemble des parties prenantes. Un environnement qui permet de faire une pause dans les développements afin de prendre le temps de davantage considérer les besoins des personnes qui utilisent le produit.
We all want things to be simpler. But we may not know what to sacrifice in order to achieve that goal.
Dans cette recherche de simplicité, j’ai essayé de remettre en question chaque concept de programmation, chaque bonne pratique, chaque bibliothèque, chaque ligne de code. J’ai essayé de produire un prototype qui soit un peu plus conséquent que celui proposé à Confoo pour voir jusqu’où cela pouvait aller. Ce qu’il me manque c’est non pas du temps de développement mais du temps de vie du projet pour analyser les effets produits sur le moyen terme. Je devrais avoir l’occasion d’expérimenter cela avec scopyleft prochainement, ça sent la trilogie.
À court terme en tout cas, c’est extrêmement plus fun à coder et l’on arrive au résultat finalement aussi rapidement. Cela devient une matière beaucoup plus malléable, dont on connait les forces et les faiblesses car le périmètre est réduit. En contrepartie, certains cas aux limites vont être écartés et l’expérience de certains utilisateurs se dégrade plus rapidement. Ce n’est pas que le coût de prise en compte soit énorme, il s’agit davantage de le prendre en considération lorsque le besoin est réel.
Autre extrait :
Maintenance
Capitalism excels at innovation but is failing at maintenance, and for most lives it is maintenance that matters more
Innovation is overvalued. Maintenance often matters more (cache)
Le problème ici c’est que je n’ai jamais rencontré de projet qui réduisent leur complexité dans le temps. Que ce soit via des itérations de retrait ou des réécritures complètes on arrive toujours à des usines à gaz si l’on ne s’est pas fixé en amont — de manière consentie par toutes les parties prenantes — les budgets évoqués plus haut. Pourtant en restant à l’échelle du microlith, la maintenance se trouverait potentiellement réduite de beaucoup.
Si l’on s’en tient à l’estimation selon laquelle la maintenance représente 67% d’un produit (cache), il devient important de trouver comment réduire ce coût.
Autre extrait :
Frameworks, API et prolétarisation
La présentation 6 reasons why APIs are reshaping your business fait l’analogie du développement Web avec l’industrie automobile et le passage de l’artisanat à l’intégration de pièces toutes faites.
Si le passage aux frameworks JavaScript et CSS a entraîné la perte de savoir des développeurs front-end et leur prolétarisation, le passage aux API va avoir le même effet sur les développeurs back-end, ceux-ci devenant de simples intégrateurs de solutions existantes s’éloignant de la problématique métier et de ses données pour se perdre dans les couches du pragmatisme. N’oubliez pas qu’en facilitant le travail de la machine, on finit par être remplacé par la machine, c’est ce que nous réserve l’industrialisation du Web. Et ça me rend nostalgique.
Autre extrait :
A system where you can delete parts without rewriting others is often called loosely coupled, but it’s a lot easier to explain what one looks like rather than how to build it in the first place.
Even hardcoding a variable once can be loose coupling, or using a command line flag over a variable. Loose coupling is about being able to change your mind without changing too much code.
Write code that is easy to delete, not easy to extend (cache)
Partant de ce constat, j’ai essayé de produire une stack minimaliste qui comportent très peu de dépendances qui peuvent évoluer en fonction du besoin. De cette manière, on accède à un LEAN technique : l’ajout de complexité architecturale en fonction du besoin uniquement.
Le code produit accorde une place importante à l’esthétique et à la modularité sans endommager la compréhension de l’ensemble grâce à la documentation et aux tests.
Autre extrait :
Thus teams are often confronting the uncomfortable choice between a risky refactoring operation and clean amputation. The best developers can be positively gleeful about amputating a diseased piece of code (even when it’s their own baby, so to speak), recognizing that it’s often the best choice for the overall health of the project. Better a single module should die than continue to bog down the rest of the project.
…
The organic, evolutionary nature of code also highlights the importance of getting your APIs right. By virtue of their public visibility, APIs can exert a lot of influence on the future growth of the codebase. A good API acts like a trellis, coaxing the code to grow where you want it. A bad API is like a cancer, and it will metastasize all over your codebase.
L’intérêt de partir d’un périmètre aussi restreint est de pouvoir se ré-interroger à chaque nouvel ajout sur sa pertinence, cela constitue une base itérative sans renoncer au plaisir technique. Le code est lisible et explicable en quelques heures pour des personnes ayant un faible niveau et il n’y a pas besoin de télécharger la moitié d’internet pour faire tourner une page web. Ma démarche est de renoncer à la complexité par défaut qui est prônée par tous les frameworks actuels, l’ajout de dépendances doit se faire au moment du besoin.
La durée de vie d’une composition de technologies est forcément réduite et demande de se ré-interroger à échéances régulières sur sa pertinence. Toute la difficulté actuelle est de pouvoir allonger ces échéances pour trouver le bon ratio entre focus et exploration. Plus vous bâtirez sur des concepts simples, universels et standardisés, plus vous aurez de chances de pouvoir être conservateur dans votre choix technique. Et plus vous serez inclusif auprès des potentiels contributeurs.
Journal du vendredi 16 août 2024 à 11:39
#JaiLu la note de David Larlet nommée Initiateurs et mainteneurs.
There are two roles for any project: starters and maintainers. People may play both roles in their lives, but for some reason I’ve found that for a single project it’s usually different people. Starters are good at taking a big step in a different direction, and maintainers are good at being dedicated to keeping the code alive.
…
I am definitely a starter. I tend to be interested in a lot of various things, instead of dedicating myself to a few concentrated areas. I’ve maintained libraries for years, but it’s always a huge source of guilt and late Friday nights to catch up on a backlog of issues.
Je suis également un initiateur. J’aime créer de nouvelles choses en expérimentant des usages et des techniques. Lorsque je me retrouve dans un rôle de mainteneur, j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses. Or l’apprentissage nait de l’échec et du test des limites. C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. À moins que la maintenance soit un vestige du passé (cache).
-- from
Ces réflexions résonnent profondément en moi 🤗, car ce sont des questions et des pensées qui m'habitent depuis de nombreuses années.
« j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses »
Pour éviter cette tendance à complexifier l’existant, j'utilise la stratégie suivante. Lorsque je ressens le besoin d'expérimenter ou d'apprendre quelque chose de nouveau, je le fais au travers des side projects personnels ou dans le cadre de POC (Proof of Concept) et Spike officiellement décidés en équipe. C'est entre autres pour cette raison que j'avais proposé de mettre en place les Spike and Learn Day.
Cette approche me permet de satisfaire ma curiosité et mon envie d'apprendre, tout en maintenant l'utilisation de Boring Technology pour les projets critiques ou ceux menés en équipe. Ainsi, je parviens à éviter le piège du Resume Driven Development.
J'aime bien la distinction suivante :
« There are two roles for any project: starters and maintainers »
Jusqu'à présent, j'ai tendance à utiliser le terme solo développeurs pour les "starters" et team développeurs pour les "maintainers".
Petite anecdote amusante : lors de mon expérience chez Spacefill, j'avais proposé de nommer le rôle des développeurs d'expérience au sein de l'équipe les "maintainers" 😉.
« C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. »
C'est une réflexion que j'ai moi-même eue par le passé.
Je crois en effet que les solo développeurs apprécient particulièrement les microservices et les multi repositories car cela leur permet d'éviter les contraintes d'équipes.
Cela leur permet d'explorer des nouveaux langages et frameworks et d'échaper aux revues de code.
À mes yeux, cette approche favorise davantage l'individualisme que la cohésion d'équipe.
J'ai également remarqué que c'est souvent lors des phases de storming du modèle de Tuckman que les développeurs semblent se tourner vers les microservices comme une forme d'évitement des défis collectifs. Cette stratégie peut sembler séduisante, mais elle risque de renforcer les silos et de freiner la collaboration au sein de l'équipe 🤔.
Journal du vendredi 16 août 2024 à 11:30
#JaiDécouvert l'expression Core-stack developer dans cet article de David Larlet :
… when in doubt, focus on the core. When in doubt, learn CSS over any sort of tooling around CSS. Learn JavaScript instead of React or Angular or whatever other library seems hot at the moment. Learn HTML. Learn how browsers work. Learn how connections are established over the network.
The reason for focusing on the core has nothing to do with the validity of any of those other frameworks, libraries or tools. On the contrary, focusing on the core helps you to recognize the strengths and limitations of these tools and abstractions. A developer with a solid understanding of vanilla JavaScript can shift fairly easily from React to Angular to Ember. More importantly, they are well equipped to understand if the shift should be made at all. You can’t necessarily say the same thing about an INSERT-NEW-HOT-FRAMEWORK-HERE developer.
Building your core understanding of the web and the underlying technologies that power it will help you to better understand when and how to utilize abstractions.
That’s part one of dealing with the rapid pace of the web.
À défaut d’être complet (full) en raison de l’effervescence technique difficile à suivre au quotidien, il me semble de plus en plus pertinent de miser sur le cœur (core) des technologies utilisées. Comprendre et maîtriser les bases avant tout pour pouvoir ponctuellement et rapidement se spécialiser en fonction du besoin. Connaître ES6 vous servira ces 10 prochaines années, savoir utiliser React sera obsolète l’année prochaine. Sages développeurs, investissez.
-- from
Core-stack developer me fait penser à Choose Boring Technology et à mon article nommé Sur quelles compétences j'ai décidé ou non d'investir mon temps ?. Je me rends compte rétrospectivement que j'ai listé ma core-stack 🙂.
Journal du lundi 12 août 2024 à 13:25
Quel est mon rapport aux langages typés ?
Pour bien comprendre mon approche des langages typés, il est utile de revenir sur mon parcours.
Enfant, j'ai commencé par du Locomotive Basic (non typé), j'ai ensuite fait beaucoup de Turbo Pascal (typé) et un peu de C, C++ (typé).
À cette époque, je préférais les langages typés pour des raisons de performances.
En 2000, j'ai vraiment aimé utiliser à nouveau des langages non typés, comme PHP et surtout Python qui a été pendant très longtemps mon langage de prédilection.
J'ai à nouveau beaucoup pratiqué un langage typé de 2013 à 2018 : Golang.
Aujourd'hui, je considère qu'il est souvent plus facile et plus rapide de programmer dans un langage non typé, notamment grâce au Duck Typing. Cependant, je reconnais que les langages typés offrent des avantages indéniables, notamment en matière de refactoring de code.
Je pense qu'il est préférable d'utiliser un langage typé sur un projet critique.
Je pense qu'il est préférable d'utiliser un langage typé pour les programmes qui manipule des données complexes et divers.
C'est, par exemple, pour cela que ne suis pas un utilisateur de MongoDB. Je préfère une base de données PostgreSQL où tout est bien typé.
Il ne me viendrait pas à l'esprit d'implémenter une base de données ou un moteur web dans un langage non typé.
Par contre, je suis moins convaincu par l'utilisation d'un langage typé pour les applications d'interface utilisateur lourde ou web.
Lorsqu'une équipe de développement travaillant sur un code commun atteint une certaine taille — je n'ai aucune idée de ce nombre — je suis convaincu qu'il devient préférable d'utiliser un langage typé.
Journal du vendredi 02 août 2024 à 14:11
J'ai partagé la note au sujet des Quick Fixes du 31 juillet 2024 à un ami — profil Développeur sénior, Architecte informatique, plus de 20 ans d'expérience — et voici ma réponse à ses commentaires.
« Je tiens à préciser que la solution « On le fera plus tard quand on aura le temps » n'arrive jamais. » -- from
« Je confirme ... remettre à plus tard, reviens à dire que ce ne sera jamais fait. Quand t'as un ticket dans le backlog qui s'appelle "C'était pas terrible faudrait refaire mieux .." et qui n'a pas été touché depuis 6 mois, tu sais que tu peux le foutre à la benne. » -- mon ami
🙂.
« a. Durant toute la vie du projet, accorder entre 20 et 40% du temps — "de l'énergie" — au traitement de la dette technique. » -- from
« Oui, mais ça ne marche que dans les équipes en mode produit ... pas dans les équipes qui fournissent du "service" 😉 » -- mon ami
Je pense que tu as malheureusement raison.
C'est pour cela que je pense qu'il est préférable que les services de l'État internalisent les compétences informatiques plutôt que passer par des ESN.
C'est pourquoi je crois qu'il est préférable que les services de l'État internalisent les compétences informatiques plutôt que de passer par des ESN. Je pense à des projets comme Louvois (projet), SIRHEN (projet), ou ONP (projet).
Journal du vendredi 02 août 2024 à 10:40
J'ai partagé la note au sujet des Quick Fixes du 31 juillet 2024 à un ami — profil Product Manager — et voici ma réponse à ses commentaires.
« Ce que je retiens principalement et qui est, à mon avis, sous-estimé, c’est l’impact psychologique de travailler dans le chaos et d’avoir l’impression d’une dette insurmontable. Pour moi, la motivation et le sens de ce qu’on fait, c’est vraiment l’enjeu clé. Je pense donc qu’il est essentiel d’avoir une gestion saine et transparente de tout ça, le quick fix est néfaste à long terme. » -- mon ami
Je trouve cela intéressant que tu soulignes "l'impact psychologique" 👍️. Je partage cet avis et cela rejoint cette partie de ma note :
« D'après mon expérience, lorsque le développement d'une application est fait en équipe, l'accumulation de Quick Fixes entraîne rapidement :
- Une perte de contrôle — analogie "des sables mouvants" dans l'article.
- Un risque de perte de confiance de l'équipe, surtout des nouveaux venus en période de storming : voir le concept sociologique de l'hypothèse de la vitre brisée. » -- (from)
Ensuite :
« Sur la question des explorations/spikes, je suis partagé. De ma modeste expérience, ça n’a jamais été concluant. Ça ne permet pas de valider une quelconque « pain » business qu’on n’aurait pas pu valider d’une autre manière. » -- mon ami
Je comprends ton point de vue.
Comme toi, autant que je me souvienne, je n'ai jamais participé à une exploration de produit réussie destinée aux utilisateurs B2B ou B2C.
Je pense qu'il y a deux raisons à cela : la première est que, de mon point de vue, ces expériences n'étaient pas réalisées avec le niveau de rigueur nécessaire.
La seconde est que ce type d'activité est intrinsèquement difficile à mener.
Cependant, j'ai réalisé des spikes produits — objectifs d'explorations de features — avec succès pour des utilisateurs internes — stakeholder.
Ces spikes m'ont permis plusieurs choses :
- De rendre concrètes des idées pas toujours comprises par des descriptions verbales ;
- De gagner la confiance des stakeholders, et d'éviter une longue période de vaporware ;
- De créer un artefact facilitant la convergence d'un groupe — développeurs, product managers, stakeholders — vers un objectif commun.
« et ça n’aide pas franchement la tech à débroussailler les écueils techniques. » -- mon ami
Mon expérience concernant les spikes techniques est différente. Pour moi, c'est une méthode qui fonctionne sans hésitation.
Ce que j'observe sur moi-même et je pense chez d'autres personnes :
- Les spikes mettent moins de pression aux développeurs sur des tâches complexes.
- Les spikes réduisent l'Effet Ikea des développeurs. Ils savent que c'est un spike et que sa solution sera probablement abandonnée.
- Les spikes réduisent l'entêtement, facilitant la pratique du timeboxing.
- Les spikes indiquent clairement aux développeurs qu'on n'attend pas une fonctionnalité finie et sans bug.
(Voir aussi ma note à propos d'un risque potentiel lié à l'usage des spikes).
J’ai pas encore avancé dans ma réflexion là-dessus, mais j’ai l’impression qu’un projet, s’il est important, doit être conduit proprement dès le départ. Si on n’a pas le temps de le faire proprement, c’est que c’était pas nécessaire, et ça va ajouter de la complexité inutilement.
Je te rejoins très fortement sur cette dernière phrase 👍️.
Journal du mercredi 31 juillet 2024 à 11:11
Une amie m'a demandé ce que je pense de cette déclaration :
« Selon moi, la résolution de problème se déroule en deux étapes : d'abord, on traite les symptômes. Si le problème persiste, on prend plus de temps pour en identifier et résoudre la cause profonde.
Cette doctrine est particulièrement adapté aux Startup ».
Cette question de fait penser à la citation du chapitre "Quick Fixes Become Quicksand" du livre Practices of an Agile Developer :
« You don't need to really understand that piece of code; it seems, to work OK as is. Oh, but it just needs one small tweak. Just add one to the result, and it works. Go ahead and put that in; it's probably fine. »
De mon expérience — dans le domaine du software engineering —, le bon dosage de l'usage des Quick Fixes, QuickWin est une source de désacord classique au sein d'une organisation.
Et ceci arrive d'autant plus lorsqu'une équipe est dans sa période de storming.
La lecture du chapitre Quick Fixes Become Quicksand en 2007 m'a beaucoup marqué et ne m'a jamais quitté depuis, je peux dire qu'il fait parti de ma doctrine d'artisan développeur.
Voici-ci dessous les screenshot et la version texte de ce chapiter.
(cliquer ici pour voir ces screenshots en grand)

Voici la version texte de ce chapitre.
Quick Fixes Become Quicksand
You don't need to really understand that piece of code; it seems, to work OK as is. Oh, but it just needs one small tweak. Just add one to the result, and it works. Go ahead and put that in; it's probably fine.”
We've all been there. There's a bug, and there's time pressure. The quick fix seems to work— just add one or ignore that last entry in the list, and it works OK for now. But what happens next distinguishes good programmers from crude hackers.
The crude hacker leaves the code as is and quickly moves on to the next problem.
The good programmer will go to the next step and try to understand why that +1 is necessary, and—more important—what else is affected.
Now this might sound like a contrived, even silly, example, except that it really happened — on a large scale. A former client of Andy's had this very problem. None of the developers or architects understood the underlying data model of their domain, and over the course of several years the code base became littered with thousands of +1 and -1 corrections. Trying to add features or fix bugs in that mess was a hair-pulling nightmare (and indeed, many of the developers had gone bald by then).
But like most catastrophes, it didn't get like that all at once. Instead, it happened one quick fix at a time. Each quick fix — which ignored the pervasive, underlying problem — added up to a swamp-like morass of quicksand that eventually sucked the life out of the project.
« Beware of land mines »
Shallow hacks are the problem — those quick changes that you make under pressure without a deep understanding of the true problem and any possible consequences. It's easy to fall prey to this temptation: the quick fix is a very seductive proposition. With a short enough lens, it looks like it works. But in any longer view, you may as well be walking across a field strewn with land mines. You might make it halfway across — or even more — and everything seems fine. But sooner or later...
As soon as that quick hack goes in, the clarity of the code goes down. Once a number of those pile up, clarity is out the window, and opacity takes over. You've probably worked places where they say, “Whatever you do, don’t touch that module of code. The guy who wrote it is no longer here, and no one knows how it works.” There's no clarity. The code is opaque, and no one can understand it.
You can't possibly be agile with that kind of baggage. But some agile techniques can help prevent this from happening. We'll look at these in more depth in later chapters, but here's a preview.
Isolation is dangerous; don’t let your developers write code in complete isolation (see Practice 40, Practice Collective Ownership, on page 155). If team members take the time to read the code that their colleagues write, they can ensure that it's readable and understandable—and isn’t laced with arbitrary “+1s and -1s”. The more frequently you read the code, the better. These ongoing code reviews not only help make the code understandable but they are also one of the most effective ways of spotting bugs (see Practice 44, Review Code, on page 165).
The other major technique that can help prevent opaque code is unit testing. Unit testing helps you naturally layer the code into manageable pieces, which results in better designed, clearer code. Further into the project, you can go back and read the unit tests — they're a kind of executable documentation (see Practice 19, Put Angels on Your Shoulders, on page 78). Unit tests allow you to look at smaller, more comprehensible modules of code and help you get a thorough understanding by running and working with the code.
Conseil de petit ange : A Don't fall for the quick hack. Invest the energy to keep code clean and out in the open.
What It Feels Like
It feels like the code is well lit; there are no dark corners in the project. You may not know every detail of every piece of code or every step of every algorithm, but you have a good general working knowledge. No code is cordoned off with police tape or “Keep Out” signs.
Keeping Your Balance
- You need to understand how a piece of code works, but you don't necessarily have to become an expert at it. Know enough to work with it effectively, but don't make a career of it.
- If a team member proclaims that a piece of code is too hard for anyone else to understand, then it will be too hard for anyone (including the original author) to maintain. Simplify it.
- Never kludge in a fix without understanding. The +1/-1 syndrome starts innocently enough but rapidly escalates into an opaque mess. Fix the problem, not the symptom.
- Most nontrivial systems are too complex for any one person to understand entirely. You need to have a high-level understanding of most of the parts in order to understand what pieces of the system interact with each other, in addition to a deeper understanding of the particular parts on which you're working.
- If the system has already become an opaque mess, follow the advice given in Practice 4, Damn the Torpedoes, Go Ahead, on page 23.
Andy Says : Understand Process. Too
Although we're talking about understanding code, and especially understanding code well before you make changes to it, the same argument holds for your team’s methodology or development process.
You have to understand the development methodology in use on your team. You have to understand how the methodology in place is supposed to work, why things are the way they are, and how they got that way.
Only with that understanding can you begin to make changes effectively.
Mon point de vue plus détaillé
Voici une version plus personnelle de ma philosophie — ma doctrine d'artisan développeur — à ce sujet. Je précise qu'elle est bien plus longue que ce que j'avais prévu et qu'elle dépasse la question de départ de mon ami… oui, je suis tombé dans un Yak! 🙂.
J'accepte d'utiliser des Quick Fixes — même sans bien comprendre le problème — dans les situations suivantes :
- Dans un Proof of Concept ou un code exploratoire ;
- Dans une application ou un composant d'application destiné à être rapidement abandonné ;
- En cas d'urgence, si le bug impacte les clients. Dans ce cas, j'applique un Quick Fixes en production, puis, je m'efforce, dans un second temps, de comprendre et de corriger correctement le problème par la suite ;
- Si je suis solo développeur sur l'application et que celle-ci n'est pas critique pour le client.
D'après mon expérience, lorsque le développement d'une application est fait en équipe, l'accumulation de Quick Fixes entraîne rapidement :
-
Une perte de contrôle — analogie "des sables mouvants" dans l'article.
-
Un risque de perte de confiance de l'équipe, surtout des nouveaux venus en période de storming : voir le concept sociologique de l'hypothèse de la vitre brisée.
-
Risque de "game over de la partie de Tetris", voir l'article La dette technique est comme une partie de Tetris.
Je tiens à préciser que la solution « On le fera plus tard quand on aura le temps » n'arrive jamais.
En 20 ans d'expérience, j'ai toujours travaillé dans des organisations où l'urgence était la norme. L'urgence permanente est tout ce que j'ai connu. Je pense que cela reflète la nature humaine.
Ainsi, la déclaration « Oui, mais nous, c'est différent, tu comprends, on n'a pas le temps » n'a pas de sens à mes yeux, car c'est le cas pour tout le monde.
Avec le temps, j'ai construit la doctrine suivante pour gérer les Quick Fixes et donc la dette technique en équipes :
- a. Durant toute la vie du projet, accorder entre 20 et 40% du temps — "de l'énergie" — au traitement de la dette technique.
- b. Si une dette jugée critique ne peut pas être traitée durant ce temps imparti, je propose de l'expliquer au Product Management et éventuellement à la direction afin qu'un choix stratégique soit fait pour lui allouer plus de temps en la priorisant comme objectif de Sprint (scrum).
Par expérience, j'observe que si la règle a est appliquée, alors la situation b se produit exceptionnellement.
L'itération pour éviter de tomber dans l'overthinking et l'overengineering !
Je pense qu'un certain nombre de leaders de startup créent un climat d'urgence pour éviter que les développeurs tombent dans de l'overthinking et de l'overengineering.
Bien que cette approche soit compréhensible, j'ai personnellement une autre méthode pour éviter ces écueils sans recourir à l'urgence.
Ma solution pour éviter de tomber dans ces travers sont :
- l'itération ;
- le time boxing, autrement dit l'utilisation de spikes ou la définition de l'appétit d'un sprint ;
- sensibiliser les développeurs aux Yak!.
Par itération, j'entends la livraison du plus petit Incrément (Scrum) possible et sa mise en production dès que possible.
Le choix du plus petit incrément possible doit être associé aux principes Keep it simple, stupid! (KISS) et You aren't gonna need it (YAGNI).
L'esprit marathon en meuthe plutôt que des courses de 100m !
Comme le dit la Loi de Gall, je pense que :
Un système complexe qui fonctionne se trouve invariablement avoir évolué depuis un système simple qui fonctionnait. La proposition inverse se révèle également exacte : Un système complexe développé de A à Z ne fonctionne jamais et vous n'arriverez jamais à le faire fonctionner. Vous devez recommencer depuis le début, en commençant par un système simple.
Ici j'entends par "système complexe" à la fois le logiciel et l'organisation humaine.
Je crois également à « New systems mean new problems ».
Depuis des années, j'observe de nombreuses startups en situation d'urgence vivre des cycles sans fin de reboot — une fois par an ou tous les deux ans —, accompagnés d'un turnover élevé.
Les projets sont constamment recommencés à zéro, avec de nouvelles équipes.
Je doute fortement que le pari de la vitesse — la course de 100m — soit plus efficace que celui du marathon.
Attention à bien identifier les projets et phases d'explorations !
Il m'est arrivé à plusieurs reprises de ne pas identifier correctement les signaux faibles indiquant qu'un projet dont j'avais la responsabilité devait en réalité être traité comme un projet d'exploration..
Je pense que les projets d'exploration ne doivent pas être traités comme des courses de 100 mètres, mais plutôt comme des spikes — prototypes.
J'insiste sur l'utilisation du terme Spike pour bien communiquer :
- Aux décideurs — stakeholder — que l'implémentation de ce projet n'est pas destinée à être conservée sur le long terme. Si l'exploration est concluante, le projet sera recommencé à zéro et attribué à une équipe dédiée.
- Aux développeurs qu'ils peuvent échouer, que le code peut contenir des bugs et être développé avec une grande dette technique.
- Aux utilisateurs qu'il est fort probable que l'application contienne des bugs ou que l'User experience ne soit pas optimale.
Ces messages sont souvent difficiles à faire passer, et c'est sans doute pour se protéger que les développeurs choisissent souvent de traiter le projet comme un projet pérenne de long terme plutôt que comme un spike.
De plus, je constate que les décideurs pensent souvent que leur idée est valide et ne jugent pas utile de réaliser des prototypes. Ce n'est souvent qu'après 1 ou 2 ans de vie de la startup que les décideurs considèrent rétrospectivement que les premières versions étaient des prototypes. Problème : ces premières versions n'ont pas été développées comme des prototypes.
Vous êtes sur la première page | [ Page suivante (45) >> ]