
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (79 notes) :
Journal du jeudi 26 mars 2026 à 14:47
#JaiDécouvert https://keepachangelog.com, un guide pour maintenir les changelog de ses projets.
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
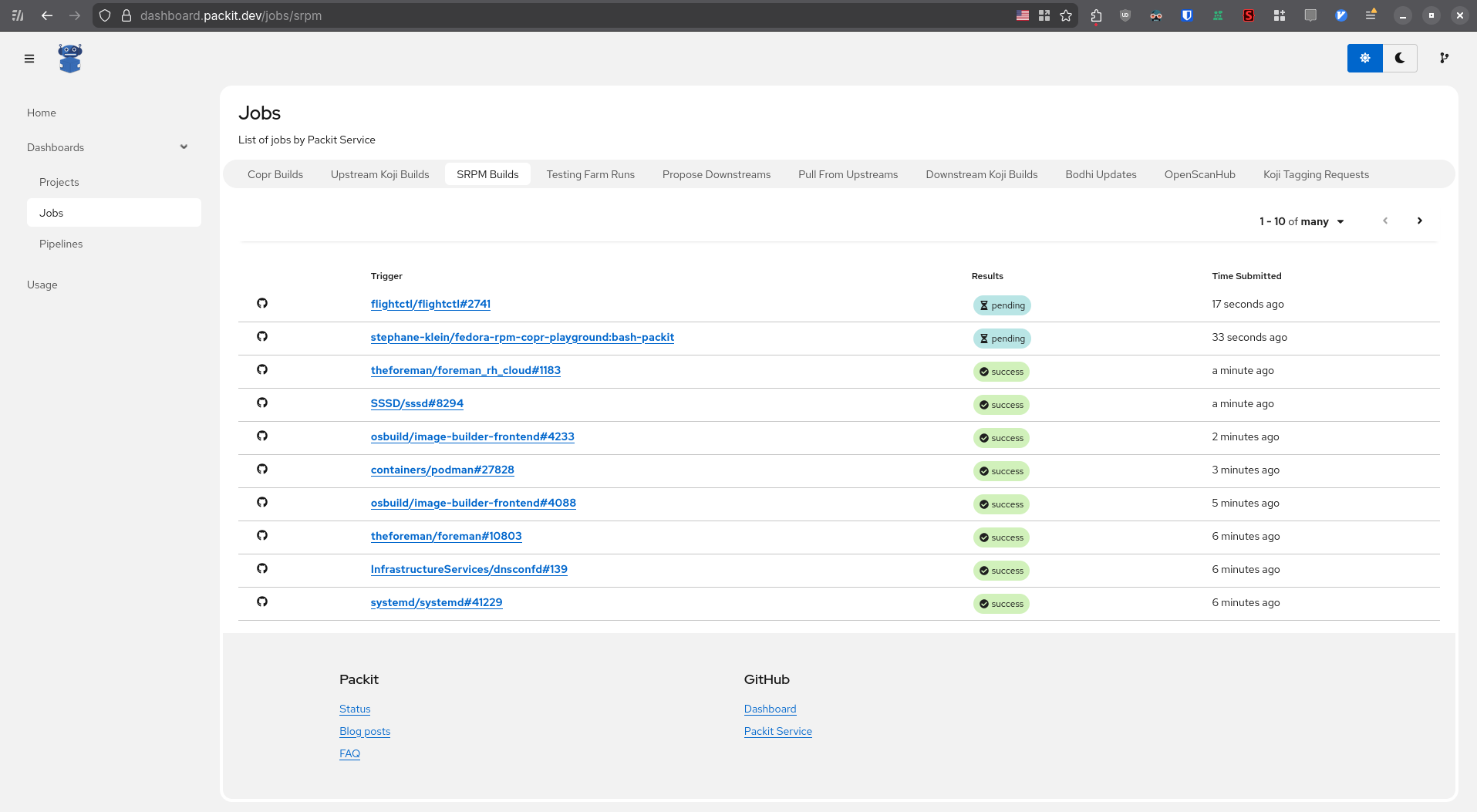
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
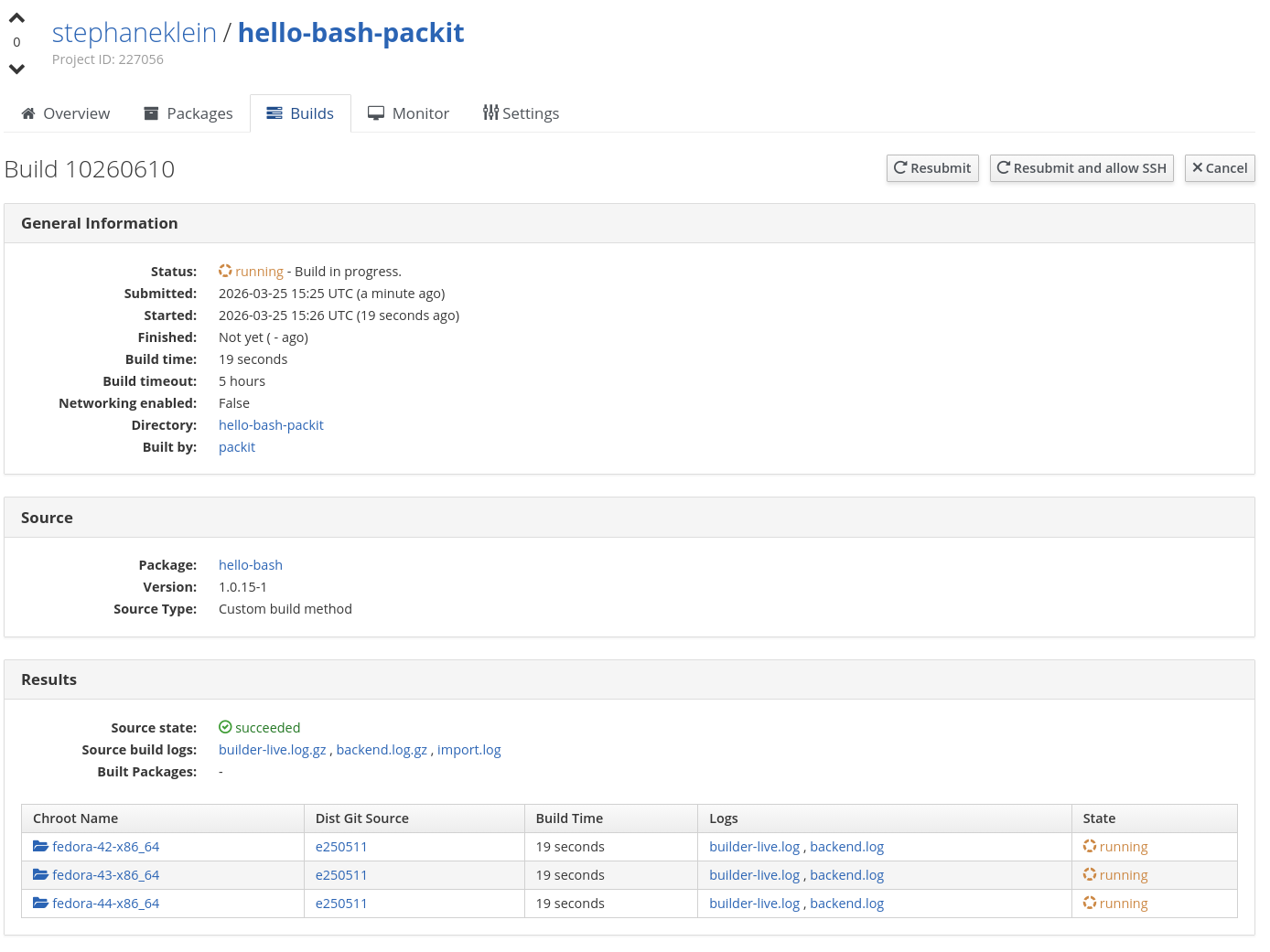
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR
Introduction
Après trois ans à repousser ce projet, je me suis enfin lancé en janvier 2026 dans la création de paquets RPM pour Fedora COPR.
J'ai créé et publié les packages aichat-git (repository) et text-to-audio (repository). L'expérience a été beaucoup plus simple et rapide que je le pensais. Les agents IA simplifient certes ce genre de tâche, mais même sans eux, le code reste plutôt minimaliste.
Pourquoi est-ce que je me suis intéressé à ce sujet ? Au départ, c'était pour distribuer qemu-compose sous forme de package RPM (voir issue).
Pour bien maîtriser ces opérations, la semaine dernière, je suis reparti de zéro et j'ai implémenté et publié le playground : fedora-rpm-copr-playground. Voici les objectifs de ce playground :
- Générer un package pour distribuer un simple script Bash qui affiche un "Hello world" (dans la branche
bash). - Générer un package pour distribuer une application Golang qui affiche un "Hello world" (dans la branche
golang)
Pour chacun de ces packages, j'ai testé trois méthodes de build :
- build du package RPM 100% local
- build du package SRPM en local, puis upload sur Fedora COPR qui génère les RPM pour plusieurs plateformes et architectures (x86_64, aarch64, etc.)
- une méthode basée à 100% sur Fedora COPR à partir des sources d'un dépôt GitHub, déclenchée automatiquement par un script GitHub Actions
Cette note documente ce playground et rassemble les difficultés que j'ai rencontrées. Le README.md reste consultable si vous préférez suivre un exemple pas à pas.
Le fichier .spec
Le point central pour créer un package RPM est le fichier .spec /rpm/hello-bash.spec :
#
Name: hello-bash
Version: 1.0.7
Release: 1%{?dist}
Summary: A simple Hello World bash script
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: hello-bash
BuildArch: noarch
%description
A simple "Hello World" Bash script packaged as an RPM for Fedora COPR.
%prep
# Nothing to prepare, source is ready
%build
# Nothing to build, it's a bash script
%install
mkdir -p %{buildroot}/%{_bindir}
cp %{SOURCE0} %{buildroot}/%{_bindir}/hello-bash
chmod 755 %{buildroot}/%{_bindir}/hello-bash
%files
%{_bindir}/hello-bash
%changelog
* Thu Mar 19 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les lignes importantes dans ce fichier :
BuildArch: noarch, étant donnée que c'est un simple script, ce package n'est pas dépendant de l'architecture (processeur).- La section
%install - La section
%files
La syntaxe du format .spec peut sembler étrange en 2026. Elle date de 1995 — avant même l'existence de YAML (2001) et JSON (1999). Cette ancienneté explique les %... et %{...} qui peuvent paraitre cryptiques aujourd'hui.
Historiquement, le champ Source0 pointe vers une archive (généralement un tar.gz), contenant les sources du projet. Pour des cas simples, comme ici avec le script Bash, Source0 peut directement référencer le fichier source.
J'ai aussi implémenté une variante bash-multifiles dans le playground, pour tester le packaging de plusieurs scripts accompagnés d'un fichier de documentation. J'y indique les fichiers via Source0:, Source1:, Source2:, puis je les copie dans %install avec %{SOURCE0}, %{SOURCE1}, %{SOURCE2}. Cela fonctionne correctement, bien qu'au-delà de trois ou quatre fichiers, je pense qu'il soit probablement plus pratique d'utiliser une archive.
Build local du package RPM
Le script /build.sh suivant permet de générer un package RPM :
#!/bin/bash
set -e
TOPDIR="$(pwd)/rpmbuild"
mkdir -p "$TOPDIR"/{BUILD,RPMS,SRPMS,SOURCES,SPECS}
echo "Copying source to SOURCES..."
cp hello-bash "$TOPDIR/SOURCES/"
echo "Building RPM..."
rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec
echo ""
echo "Build complete!"
echo "RPM: $TOPDIR/RPMS/noarch/"
Il commence par préparer la structure de dossier suivante :
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
├── SPECS
└── SRPMS
Ensuite les fichiers à packager sont copiés dans rpmbuild/SOURCES
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
Pour finir, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec génère à la fois le package SRPM (source RPM) et le RPM binaire. L'option -ba signifie "build all". Pour générer uniquement le SRPM, il faudrait utiliser -bs (build source). Ici, comme le package contient un script Bash, il est de type noarch :
/rpmbuild/
├── BUILD
├── RPMS
│ └── noarch
│ └── hello-bash-1.0.7-1.fc42.noarch.rpm
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
└── hello-bash-1.0.7-1.fc42.src.rpm
Publication sur Fedora COPR
Le playground contient un second script qui permet de publier le package sur Fedora COPR, ce qui permet de rendre accessible publiquement son package.
Voici comment cette méthode fonctionne. Tout d'abord, il faut créer un compte et un projet sur Fedora COPR. Dans le playground, j'ai implémenté le script init-copr-project.sh basé sur copr-cli, qui me permet d'automatiser la création du projet (paradigme GitOps).
$ copr-cli create "hello-bash" \
--description "A simple Hello World Bash script packaged as an RPM (auto-build on tags)" \
--chroot fedora-42-x86_64 \
--chroot fedora-43-x86_64 \
--chroot fedora-44-x86_64
Dans cet exemple, je demande à COPR de builder les packages du projet pour les distributions fedora-42-x86_64, fedora-43-x86_64, fedora-44-x86_64.
Après avoir configuré le projet COPR, je lance le script /build-copr.sh qui exécute :
copr-cli build "hello-bash" /rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
Le premier paramètre "hello-bash" est le nom du projet et le second est le package source SRPM préalablement construit localement par le script /build.sh.
Voici ce que donne l'exécution de ./build-copr.sh côté cli :
$ ./build-copr.sh
...
Build complete!
RPM: /home/stephane/git/github.com/stephane-klein/fedora-rpm-copr-playground/.worktree/bash/rpmbuild/RPMS/noarch/
Uploading package ./rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
|################################| 8.5 kB 47.1 kB/s eta 0:00:00
Build was added to hello-bash:
https://copr.fedorainfracloud.org/coprs/build/10252699
Created builds: 10252699
Watching build(s): (this may be safely interrupted)
08:59:15 Build 10252699: pending
08:59:45 Build 10252699: running
09:00:15 Build 10252699: starting
09:00:46 Build 10252699: running
Voici ce qui est visible sur l'interface web de COPR, https://copr.fedorainfracloud.org/coprs/stephaneklein/hello-bash/builds/ :
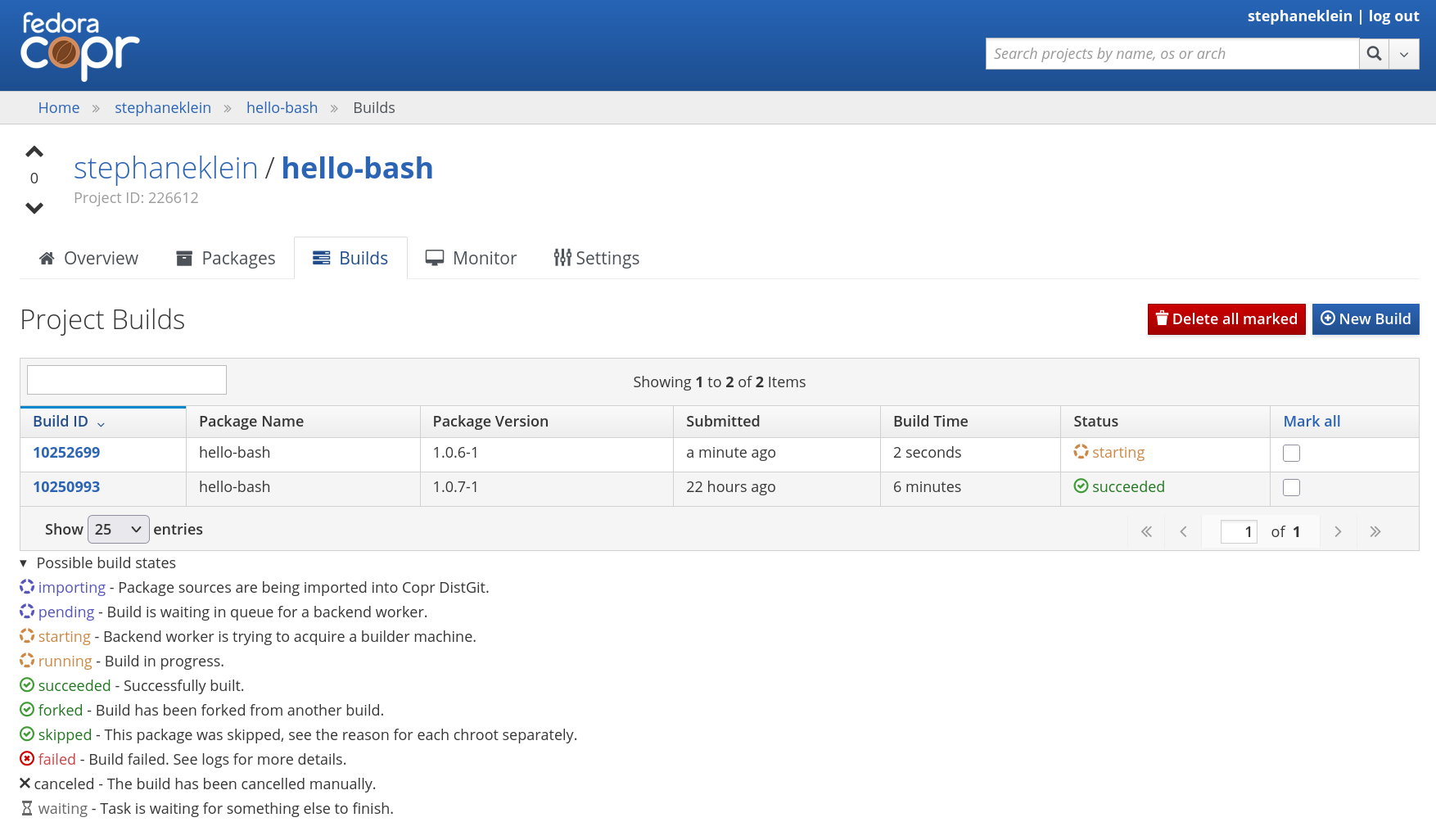
Une fois le build des packages terminé, il est facile d'installer le package avec les commandes suivantes :
$ sudo dnf copr enable -y stephaneklein/hello-bash
$ sudo dnf install -y hello-bash
$ hello-bash
Hello World
Automatisation GitOps avec COPR
Et pour finir, j'ai implémenté dans le playground l'automatisation complète de la compilation et publication des packages sur l'infrastructure COPR.
Pour cela, dans le script init-copr-project.sh j'ai déclaré l'URL du repository qui contient le code source :
...
copr-cli add-package-scm "$COPR_PROJECT" \
--name hello-bash \
--clone-url https://github.com/stephane-klein/fedora-rpm-copr-playground.git \
--commit bash \
--subdir . \
--spec rpm/hello-bash.spec \
--type git \
--method make_srpm \
--webhook-rebuild on
Le paramètre --commit bash permet de définir la branche Git à utiliser comme source.
Le paramètre --method make_srpm, qui permet à l'utilisateur d'utiliser un script personnalisé de génération du SRPM, à placer dans /.copr/Makefile à la racine du dépôt avec une cible srpm, exemple :
specfile = rpm/hello-bash.spec
.PHONY: srpm
srpm: $(specfile)
mkdir -p /tmp/copr-srpm-build
cp rpm/hello-bash.spec /tmp/copr-srpm-build/hello-bash.spec
cp -r . /tmp/copr-srpm-build/source/
cd /tmp/copr-srpm-build && \
rpmbuild -bs hello-bash.spec \
--define "_topdir /tmp/copr-srpm-build/rpmbuild" \
--define "dist .fc42" \
--define "_sourcedir /tmp/copr-srpm-build/source"
cp /tmp/copr-srpm-build/rpmbuild/SRPMS/*.src.rpm $(outdir)
Je ne souhaite pas détailler ici d'autres méthodes comme tito ou Packit, mais la méthode make_srpm est la plus flexible, elle permet de contrôler entièrement comment le SRPM est construit.
Une fois tout ceci configuré, il est possible de rebuild le package directement en cliquant sur le bouton "Rebuild" sur l'interface web de COPR :
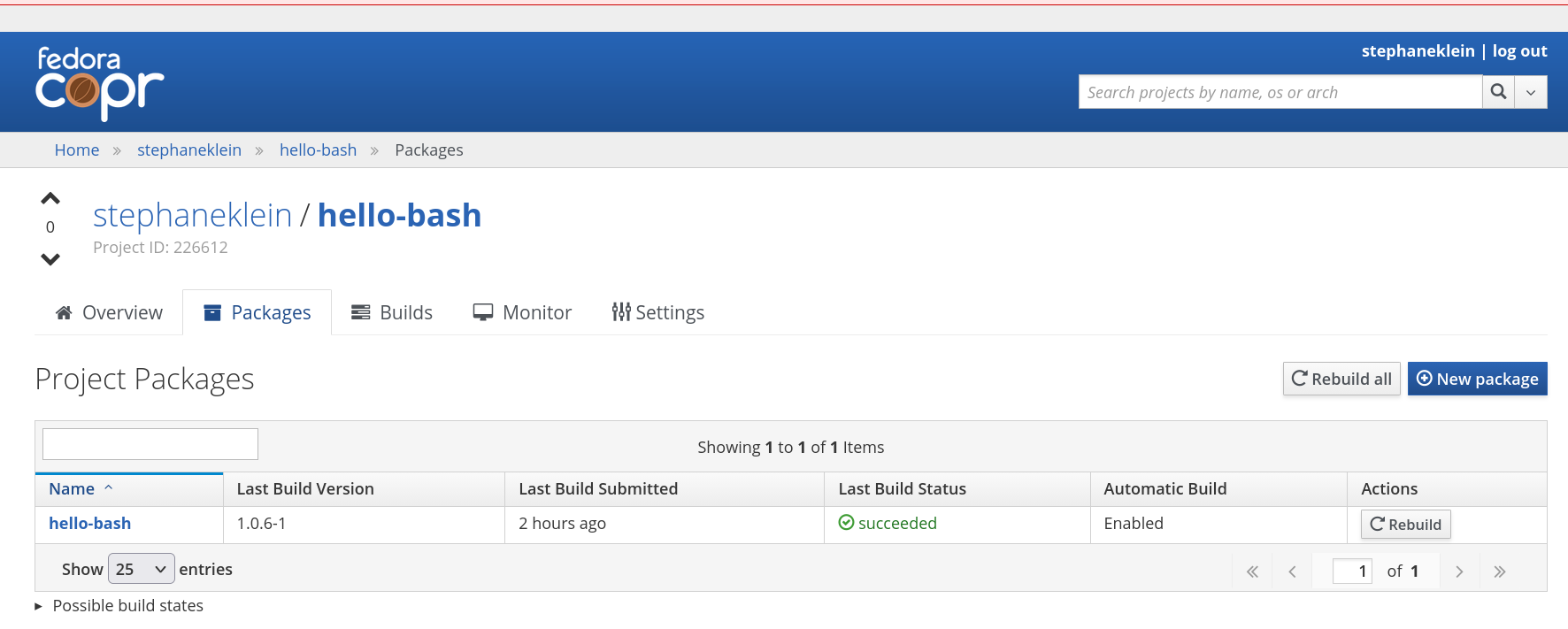
Dernière étape : j'ai implémenté un build automatique qui est déclenchée par un appel curl dans le job GitHub Actions /.github/workflows/trigger-copr-build.yml, dont voici le contenu :
name: Trigger Copr Build
on:
push:
tags:
- '*'
jobs:
trigger-copr-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Verify tag is on bash branch
run: |
if ! git branch -r --contains ${{ github.ref_name }} | grep -q "origin/bash"; then
echo "Tag ${{ github.ref_name }} is not on branch bash"
exit 1
fi
- name: Trigger Copr webhook
run: |
curl -X POST https://copr.fedorainfracloud.org/webhooks/custom/226325/3cf20247-820b-4050-bfb1-593b01a6996f/hello-bash/
Ce job est exécuté à chaque publication d'un nouveau Git tag, suivi d'une vérification que le tag provient bien de la branche bash.
Claude Sonnet 4.6 m'a suggéré l'existence d'une méthode de polling de dépôt Git intégrée à COPR, mais je n'ai trouvé aucune trace de celle-ci dans la documentation.
J'ai aussi essayé d'utiliser la méthode basée sur les webhooks GitHub de COPR, mais je n'ai pas réussi à la faire fonctionner. L'interface de GitHub m'indiquait à chaque fois une erreur dans la réponse des calls HTTP. C'est pour cela que j'ai fini par déclencher le webhook custom via un job GitHub Actions.
Package d'un projet en Golang
Le playground contient aussi le packaging d'une application en Golang, consultable dans la branche golang.
Voici le contenu du fichier /golang/rpm/hello-golang.spec :
Name: hello-golang
Version: 1.0.10
Release: 1%{?dist}
Summary: A simple Hello World Go application
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: %{name}-%{version}.tar.gz
BuildRequires: golang >= 1.21
%description
A simple "Hello World" Go application packaged as an RPM for Fedora COPR.
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
%install
mkdir -p %{buildroot}%{_bindir}
cp %{name} %{buildroot}%{_bindir}/
%files
%{_bindir}/%{name}
%changelog
* Fri Mar 20 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les principales différences avec la version pour Bash :
- Absence de
BuildArch: noarch - Présence de
BuildRequires: golang >= 1.21 - Et l'ajout des instructions suivantes :
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
Peu de changement au niveau du script /build-rpm-locally.sh, qui génère ces fichiers :
rpmbuild
├── BUILD
├── RPMS
│ └── x86_64
│ ├── hello-golang-1.0.10-1.fc42.x86_64.rpm
│ ├── hello-golang-debuginfo-1.0.10-1.fc42.x86_64.rpm
│ └── hello-golang-debugsource-1.0.10-1.fc42.x86_64.rpm
├── SOURCES
│ ├── hello-golang-1.0.10
│ │ ├── go.mod
│ │ └── main.go
│ └── hello-golang-1.0.10.tar.gz
├── SPECS
└── SRPMS
└── hello-golang-1.0.10-1.fc42.src.rpm
Cette fois, plus rien dans le dossier RPMS/noarch/, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-golang.spec build le package pour la distribution de la workstation du développeur.
Pour le reste, je n'ai pas identifié de différence majeure entre la version Bash et la version Golang
La suite… méthode Tito et Packit
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour stephane-klein/fedora-rpm-copr-playground pour les tester et ensuite publier une nouvelle note de compte rendu.
Journal du vendredi 21 novembre 2025 à 12:03
Dans ce thread, #JaiDécouvert OpenCode (https://github.com/sst/opencode) qui semble être une alternative à Aider et Claude Code.
Après avoir parcouru la documentation, j'ai l'impression qu'OpenCode propose des fonctionnalités et une User experience plus avancées qu'Aider.
Le projet est récent (démarré en mars 2025) et publié sous licence MIT.
D'après le footer du site de documentation, je comprends qu'OpenCode est développé par l'entreprise Anomaly, financée par du Venture capital.
#JaiLu ce commentaire à propos d'OpenCode dans les issues d'Aider.
En cherchant sur Hacker News, je suis tombé sur ce thread de juillet 2025.
J'ai retenu ce commentaire :
Two big differences:
opencode is much more "agentic": It will just take off and do loads of stuff without asking, whereas aider normally asks permission to do everything. It will make a change, the language server tells it the build is broken, it goes and searches for the file and line in the error message, reads it, and tries to fix it; rinse repeat, running (say) "go vet" and "go test" until it doesn't see anything else to do. You can interrupt it, of course, but it won't wait for you otherwise.
aider has much more specific control over the context window. You say exactly what files you want the LLM to be able to see and/or edit; and you can clear the context window when you're ready to move on to the next task. The current version of opencode has a way to "compact" the context window, where it summarizes for itself what's been done and then (it seems) drops everything else. But it's not clear exactly what's in and out, and you can't simply clear the chat history without exiting the program. (Or if you can, I couldn't find it documented anywhere.)
Je retiens donc qu'Aider offre un contrôle plus précis qu'OpenCode. OpenCode fonctionne de manière plus autonome.
Pour ma part, je préfère contrôler finement les actions d'un AI code assistant sur mon code, à la fois pour comprendre ses interventions et pour gérer ma consommation de tokens.
Je n'ai pas envie de tester OpenCode pour le moment, je vais continuer avec Aider.
Journal du samedi 15 novembre 2025 à 14:23
Dans ce commentaire, #JaiDécouvert une alternative à Grafana (partie dashboard) : Perses (https://github.com/perses/perses).
For exclusively dashboards, the CNCF has https://perses.dev/, which supports Prometheus Loki and Pyroscope, and has a Grafana importer but I haven't given it a shot.
Journal du samedi 02 août 2025 à 13:07
#JaiÉcouté l'épisode « Open Source Experts : conseiller et faire du support Open Source » du podcast Projets Libres.
J'y ai découvert :
- La société Open Source Experts nommée aussi OSE
- Le projet Qualification and Selection of Open Source Software
J'ai trouvé cette interview à 3 intéressante.
Si je décide de continuer à vendre des prestations freelance à l'avenir, j'aimerais prendre le temps de les contacter pour leur demander si mes compétences pourraient être utiles à l'un de leurs clients.
Journal du lundi 23 juin 2025 à 11:49
Dans la slide 18 de la conférence "Nubo: the French government sovereign cloud" du FOSDEM 2025, j'ai découvert l'article "Un logiciel libre est un produit et un projet" (https://bzg.fr/fr/logiciel-produit-projet/).
Je viens de réaliser une lecture active de cet article. Je l'ai trouvé très intéressant. Je vais garder à l'esprit cette distinction "produit / projet".
Voici quelques extraits de cet article.
La popularité de GitHub crée des attentes sur ce qu'est un logiciel « open source » (comme disent les jeunes) ou « libre » (comme disent les vrais). Il s'agit d'un dépôt de code avec une licence, une page de présentation (souvent nommée README), un endroit où remonter des problèmes (les issues), un autre où proposer corrections et évolutions (les pull requests) et, parfois, d'autres aspects : un espace de discussion, des actions lancées à chaque changement, un lien vers le site web officiel, etc.
Je trouve que ce paragraphe décrit très bien les fonctions remplies par un dépôt GitHub :
Pourquoi distinguer produit et projet ?
Cette distinction permet d'abord de décrire une tension inhérente à tout logiciel libre : d'un côté les coûts de distribution du produit sont quasi-nuls, mais de l'autre, l'énergie à dépenser pour maintenir le projet est élevée. Lorsque le nombre d'utilisateurs augmente, la valeur du produit augmente aussi, de même que la charge qui pèse sur le projet. C'est un peu comme l'amour et l'attention : le premier se multiplie facilement, mais le deuxième ne peut que se diviser.
Je partage cet avis 👍️.
C'est d'ailleurs cette tension qu'on trouve illustrée dans l'opposition entre les deux sens de fork. Dans le sens technique, forker un code source ne coûte rien. Dans le sens humain, forker un projet demande beaucoup d'effort : il faut recréer la structure porteuse, à la fois techniquement (hébergement du code, site web, etc.), juridiquement (éventuelle structure pour les droits, etc.) et humainement (attirer les utilisateurs et les contributeurs vers le projet forké.)
J'approuve 👍️.
Côté morale, il y a les principes et les valeurs. Les principes sont des règles que nous nous donnons pour les suivre ; les valeurs expriment ce qui nous tient à coeur. Les deux guident notre action.
Intéressant 🤔
Un logiciel libre est un produit qui suit un principe, celui d'octroyer aux utilisateurs les quatre libertés. Il est porté par un projet ayant des valeurs, dont voici des exemples : l'importance de ne pas utiliser des plateformes dont le code source n'est pas libre pour publier un code source libre, celle d'utiliser des outils libres pour communiquer, de produire un logiciel accessible et bien documenté, d'être à l'état de l'art technique, d'être inclusif dans les contributions recherchées, d'avoir des règles pour prendre des décisions collectivement, de contribuer à la paix dans le monde, etc.
Je trouve cela très bien exprimé 👍️.
Journal du dimanche 22 juin 2025 à 23:34
Un collègue m'a fait découvrir Vercel Chat SDK (https://github.com/vercel/ai-chatbot) :
Chat SDK is a free, open-source template built with NextJS and the AI SDK that helps you quickly build powerful chatbot applications.
#JaimeraisUnJour prendre le temps de le décliner vers SvelteKit.
Journal du samedi 14 juin 2025 à 00:06
#JaiDécouvert OmniPoly (https://github.com/kWeglinski/OmniPoly)
Welcome to a solution for translation and language enhancement tool. This project integrates LibreTranslate for accurate translations, LanguageTool for grammar and style checks, and AI Translation for modern touch of sentiment analysis and interesting sentences extraction.
Je souhaite intégrer cet outil au dépôt sklein-open-webui-instance.
Comme ce projet ne sera plus exclusivement dédié à Open WebUI, il me semble qu'un changement de nom s'impose.
Journal du vendredi 13 juin 2025 à 22:32
Dans cette fonction filtre Open WebUI, #JaiDécouvert Detoxify (https://github.com/unitaryai/detoxify).
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
#JaimeraisUnJour prendre le temps de le tester.
Alexandre m'a partagé le projet LocalAI (https://localai.io/).
Ce projet a été mentionné une fois sur Lobster dans un article intitulé Everything I’ve learned so far about running local LLMs, et quatre fois sur Hacker News (recherche pour "localai.io"), mais avec très peu de commentaires.
C’est sans doute pourquoi je n'ai jamais remarqué ce projet auparavant.
Pourtant, il ne s’agit pas d’un projet récent : son développement a débuté en mars 2023.
J'ai l'impression que LocalAI propose à la fois des interfaces web comme Open WebUI, mais qu'il est aussi une sorte de "wrapper" au-dessus de nombreux Inference Engines comme l'illustre cette longue liste.
Pour le moment, j'ai vraiment des difficultés à comprendre son positionnement dans l'écosystème.
LocalAI versus vLLM ou Ollama ? LocalAI versus Open WebUI ?, etc.
Je vais garder ce projet dans mon radar.
Journal du vendredi 16 mai 2025 à 13:31
Je me suis posé la question suivante : « Qui contribue au projet Open WebUI ? »
Si je regarde les contributions au projet, je constate que, à la louche, 95% du repository /open-webui/open-webui/ et /pipelines/graphs/ est réalisé par Tim Jaeryang Baek.
Contributions au dépôt /open-webui/open-webui/ :
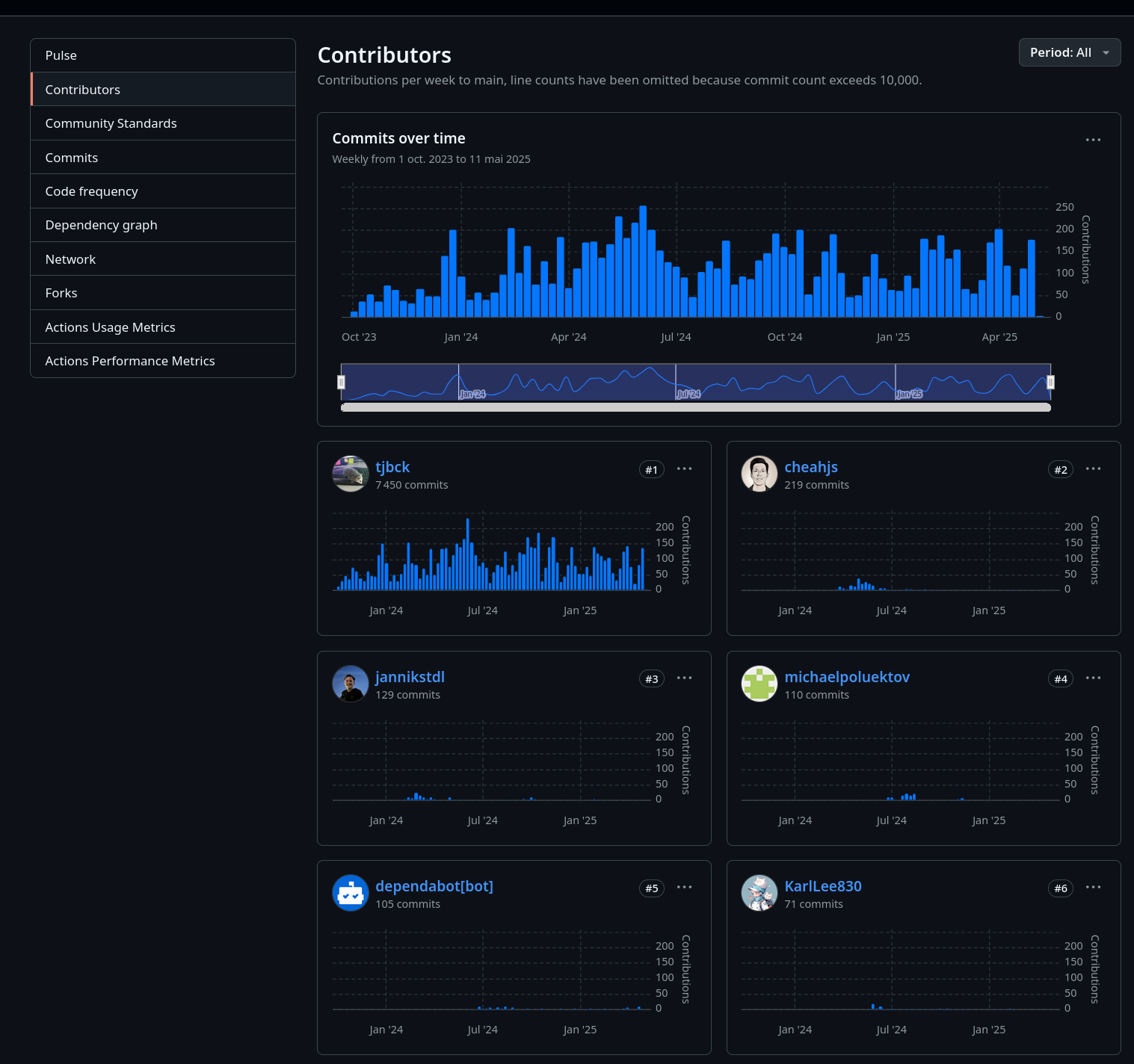
Contributions au dépôt /open-webui/open-webui/ sur les 6 derniers mois :
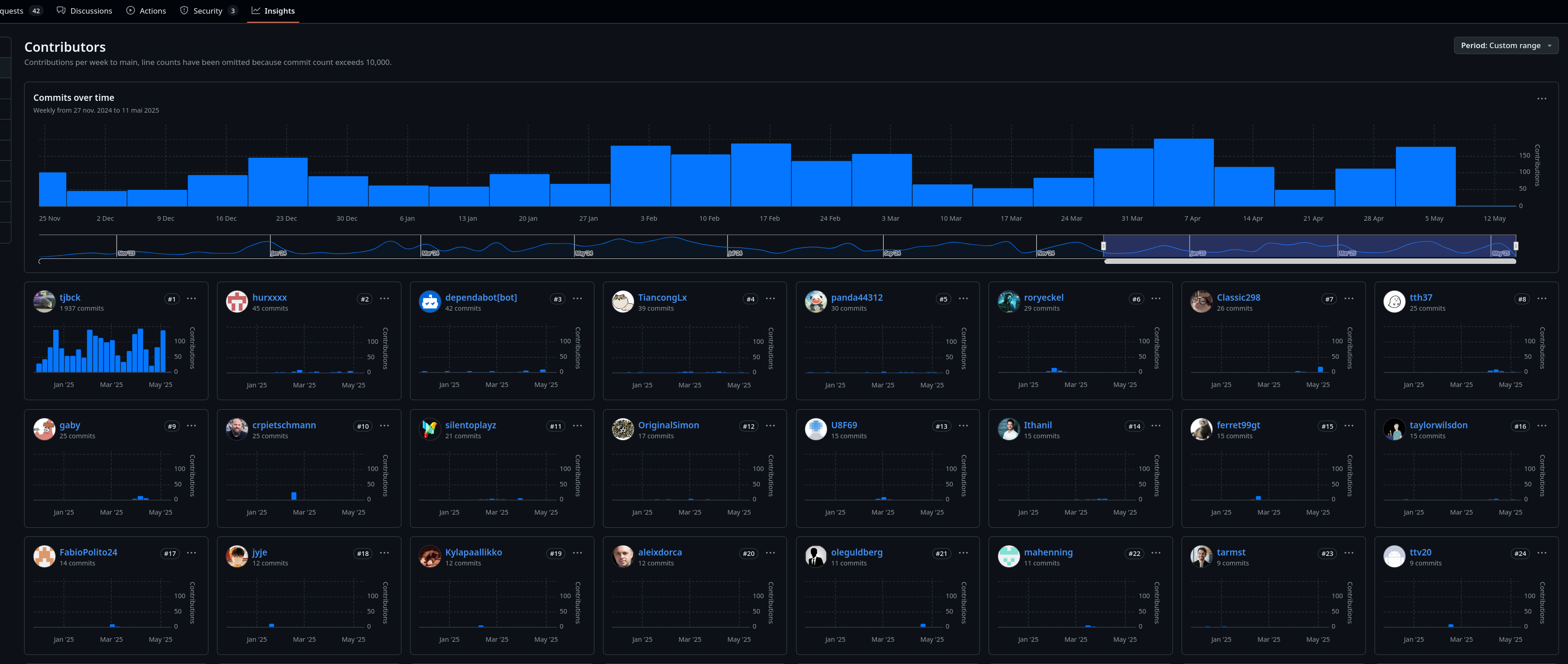
D'après la section "People" de la page LinkedIn "Open WebUI", James W. semble être dédié et peut-être rémunéré pour travailler sur /open-webui/helm-charts/.
Voici mon estimation de Fermi de calcul du coût de développement d'Open WebUI (seulement ce composant) :
- Estimation du taux journalier de Tim Jaeryang Baek : bien que Tim a commencé depuis peu sa carrière professionnelle, je pense qu'il n'aurait pas de difficulté à trouver des missions entre 500 et 1000 € HT la journée.
- Le dépôt Open WebUI a reçu ses premiers commits le 1ᵉʳ octobre 2023. Cela fait 20 mois de travail.
- Si j'estime, 20 jours de travail par mois sans vacances, j'obtiens 400 jours de travail
- J'obtiens un coût total entre :
- 500 x 400 = 200 000 €
- 1000 x 400 = 400 000 €
Je tiens à préciser que ce montant n'a pas de lien avec une valeur économique d'usage, ni une valeur d'échange.
Comme on a pu le voir au début de cette note, ce projet a été développé par une seule personne, réduisant considérablement les "frais de couplage" (coûts liés à la coordination, communication et synchronisation entre développeurs, management, recrutement…). Si ce même projet avait été réalisé au sein d'une startup, son coût aurait été d'un ordre de grandeur nettement supérieur. Selon mon estimation, il aurait été multiplié par 50, voire davantage.
Journal du vendredi 25 avril 2025 à 16:08
Note du 21 mars 2025, publiée le 25 avril 2025.
J'ai écouté l'épisode « Agnes Crepet - Head of software longevity & IT chez FAIRPHONE » du 1ᵉʳ septembre 2023 du podcast "Projets Libres" (from).
Avant l'écoute de cet épisode, je pensais que Fairphone faisait du Greenwashing, mais non, pas du tout. Dans cet épisode, j'ai découvert le travail difficile réalisé par Fairphone pour :
- réaliser autant que possible des téléphones démontables et réparables
- essayer de proposer des pièces de rechange le plus longtemps possible
- essayer de maintenir des mises à jour logiciels le plus longtemps possible
- essayer d'ouvrir au maximum leur téléphone, c'est-à-dire de pouvoir installer facilement des OS customisés
J'ai trouvé Agnes Crepet très humble, elle reconnait que leurs téléphones ne sont pas parfaits, mais que Fairphone suit une philosophie de transparence et essaie de jouer au maximum le jeu de l'open-source.
Voici quelques sujets abordés dans cet épisode :
- La mission de Fairphone
- Faire sa propre version d’Android avec un support long terme
- Faire du support long terme sans perdre de fonctionnalités
- Les leçons apprises du Fairphone 2
- Le retour d’expérience sur Fairphone Open OS
- Les relations avec les communautés libres (LineageOS, etc)
- La collaboration avec /e/OS (Murena)
- Les relations avec la coopérative Commown et la location d’appareils
- La longévité matérielle chez Fairphone
J'ai toujours essayé d'acheter des smartphones qui proposent une version d'Android la plus "vanilla" possible. C'est pour cela qu'en 2015 j'ai choisi d'acheter un OnePlus One (bien moins cher que le Google Pixel).
En 2022, j'ai choisi un smartphone Oppo un peu par défaut.
Fairphone proposent des Android "vanilla".
Après avoir écouté cet épisode, je pense que mon choix est fait, maintenant j'achèterai des Fairphone même si ce ne sont pas les smartphones qui offrent le meilleur ratio prix / puissance. Je souhaite soutenir leur travail parce que j'apprécie leur philosophie, leur mission.
Étant donné que j'ai besoin d'un smartphone supplémentaire pour réinstaller les smartphones de ma compagne et de mes beaux-parents, j'ai décidé d'acheter un Fairphone 5 - 5G.
Le 21 mars 2025, j'ai commandé :
- Un Fairphone 5 - 5G - Noir Mat, 128GB, 6GB Ram à 549 €TTC
Après un mois d'utilisation, je suis très satisfait et j'apprécie le forum de Fairphone : https://forum.fairphone.com/.
Journal du jeudi 20 mars 2025 à 12:20
En rédigeant la note 2025-03-20_1020, #JaiDécouvert ici la Licence Publique de l'Union Européenne (EUPL) :
Afin de simplifier ce partage, la Commission a mis sur pied la licence publique de l’Union européenne; elle est disponible en vingt-trois langues officielles de l’Union et est compatible avec de nombreuses licences open source.
Article Wikipedia de la licence : https://fr.wikipedia.org/wiki/Licence_publique_de_l'Union_européenne
Journal du jeudi 20 mars 2025 à 10:28
En étudiant E/OS, j'ai découvert Murena (https://murena.com/fr/) :
Nous fournissons des smartphones et un espace de travail en ligne privés, durables et entièrement libres.
Je vois Fairphone dans la section "Nos partenaires". Je suppose que les smartphones vendus par Murena sont des Fairphone.
Je lis ici que Murena prend 3% de commission sur la vente des smartphones.
Je remarque que le fondateur et CEO de Murena est Gaël Duval, fondateur de Mandriva Linux.
Journal du jeudi 20 mars 2025 à 10:20
Le dimanche 17 novembre 2024, j'ai signé la pétition "nº 0729/2024, présentée par N. W., de nationalité autrichienne, sur le déploiement d’un système d’exploitation «UE-Linux» dans les administrations publiques de tous les États membres".
La commission des pétitions du Parlement européen a communiqué sa réponse le 10 janvier 2025 : PETI-CM-767965_FR.pdf .
Quelques extraits :
Le pétitionnaire demande à l’Union de développer un système d’exploitation pour ordinateur sous Linux, appelé «EU-Linux», et de le déployer dans tous les services publics des États membres.
Cette initiative vise à réduire la dépendance à l’égard des produits Microsoft, à garantir le respect du règlement général sur la protection des données et à favoriser la transparence, la durabilité et la souveraineté technologique au sein de l’Union.
Le pétitionnaire insiste sur l’importance de recourir à des solutions open source se substituant à Microsoft 365, telles que Libre Office et Nextcloud, et propose d’adopter le système d’exploitation mobile E/OS sur les appareils utilisés par les pouvoirs publics. Il souligne par ailleurs le potentiel de création d’emplois dans le secteur des technologies de l’information.
Bon résumé 👍️.
L’Union soutient toujours davantage la création de logiciels open source, qui limitent la dépendance à l’égard de fournisseurs uniques, favorisent la transparence et renforcent la sécurité des données. Récemment, le règlement pour une Europe interopérable, entré en vigueur en avril 2024 afin de favoriser une coopération fluide entre les États membres, a fait du recours à l’open source et aux normes ouvertes dans les services publics une priorité; les administrations sont ainsi plus transparentes, sûres et à l’abri de tout enfermement propriétaire.
Lien vers le texte du règlement : "Règlement (UE) 2024/903 du Parlement européen et du Conseil du 13 mars 2024 établissant des mesures destinées à assurer un niveau élevé d’interopérabilité du secteur public dans l’ensemble de l’Union (règlement pour une Europe interopérable)".
#UnJourPeuxÊtre je lirais ce règlement qui, après un parcours rapide de son contenu, me semble très intéressant.
a Commission continue de soutenir une transformation numérique de l’Union fondée sur des solutions open source, en établissant des programmes tels que le programme pour une Europe numérique, le CEF Telecom, et l’ancien programme d’interopérabilité ISA². De plus, son programme de financement Horizon Europe subventionne de nombreux projets qui ont trait au développement et à l’utilisation de logiciels et de matériel open source. Enfin, son initiative sur l’internet de nouvelle génération a permis d’investir plus de 140 millions d’EUR dans plus d’un millier de projets participatifs open source.
Dans cet extrait, #JaiDécouvert :
- Le programme pour une Europe numérique
- CEF Telecom
- J'ai suivi des liens et j'ai constaté qu'il est possible de consulter les projets financés. Par exemple, 200 000 € sont allés à DINUM pour un travail sur France Connect : Setting up, integration with “France Connect” and implementation of eID
- ISA² - Interoperability solutions for public administrations, businesses and citizens
- Horizon Europe
- En lisant cette présentation en français, je constate que le soutien aux free software est indirect et secondaire.
- NGI Innovations - qui finance en partie des projets NLNET, qui finance précisément des free software.
La Commission surveille également l’adoption de l’open source par les services publics de l’Union. Pendant près de deux décennies, son Observatoire open source a passé au crible des articles, des rapports ainsi que des études de cas témoignant de l’adoption croissante de l’open source à travers l’Union.
#JaiDécouvert : Open Source Observatory.
Mentionnons notamment les récents efforts des gouvernements nationaux afin de développer et de mettre en œuvre des solutions open source se substituant aux suites collaboratives de logiciels propriétaires, situation largement conforme à la volonté du pétitionnaire.
#JaiDécouvert ici le projet openDesk.
Le portail «Europe interopérable», hébergeur de l’Observatoire, incite par ailleurs au partage et à la réutilisation de solutions communes, notamment open source, grâce au catalogage de logiciels.
Le lien est ici. J'ai l'impression que la page contient une liste de documents d'actualités.
Afin de simplifier ce partage, la Commission a mis sur pied la licence publique de l’Union européenne; elle est disponible en vingt-trois langues officielles de l’Union et est compatible avec de nombreuses licences open source.
#JaiDécouvert la licence EUPL.
La Stratégie logicielle open source de la Commission incite à l’utilisation de l’open source en interne, encourage la collaboration sur le site code.europa.eu et ouvre la voie à des infrastructures numériques plus durables et transparentes. La Commission organise des hackathons et prévoit des primes aux bogues pour tester des solutions open source prometteuses, comme Nextcloud; elle soutient du reste le passage à l’open source dans des domaines clés, ce qui est d’autant plus conforme aux volontés exprimées dans la pétition.
Je découvre la forge https://code.europa.eu qui semble être limitée à un usage interne. Je suis surpris de ne voir aucun projet public 🤔.
Conclusion
Il n’y a actuellement pas de projet officiel d’établir un «EU-Linux», mais un grand nombre d’initiatives soutiennent activement l’adoption de solutions open source au sein des administrations publiques des États membres. Ces efforts contribuent plus largement aux objectifs européens de transparence, de sécurité et d’indépendance technologique dans le domaine numérique.
Journal du mardi 18 mars 2025 à 14:03
Ce midi, j'ai échangé avec un ami au sujet de ForgeFed (https://forgefed.org/) :
ForgeFed is a federation protocol for software forges and code collaboration tools for the software development lifecycle and ecosystem. This includes repository hosting websites, issue trackers, code review applications, and more.
ForgeFed est une extension d'ActivityPub.
Voici la roadmap d'intégration d'implémentation de ForgeFed dans Forgejo : Roadmap for Federation.
Journal du jeudi 12 décembre 2024 à 10:20
#JaiDécouvert le projet Match ID (https://matchid.io/) et plus précisément l'instance deces.matchid.io (https://deces.matchid.io/search).
Le projet matchID a été initié au ministère de l'Intérieur dans le contexte des challenges d' Entrepreneur d'intérêt général. La réconciliation des personnes décédées avec le permis de conduire a été le premier cas d'usage réalisé avec matchID.
Le projet a été libéré et mis en open source. L'équipe est maintenant composée de développeurs, anciens du ministère de l'Intérieur, contribuant bénévolement au service sur leur temps libre.
Nous avons créé ce service en complément, car il semblait d'utilité publique notamment pour la lutte contre la fraude, ou pour la radiation des décédés aux différents fichiers clients (e.g. hôpitaux).
L'exposition sur deces.matchid.io au profit du public est assurée par Fabien ANTOINE, avec le soutien de Cristian Brokate notamment pour le soutien technique à l'API. Le service est offert sans garantie de fonctionnement, nous nous efforçons de répondre aux messages (hors "absence du fichier") sur notre temps libre, faut de support officiel par les services de l'Administration.
Pour en savoir plus sur le projet matchID, consultez notre site https://matchid.io.
#Jadore ❤️
Le site exploite les fichiers des personnes décédées, disponibles en open data sur data.gouv.fr et recueillies par l'INSEE.
Les fichiers des personnes décédées sont établis par l’INSEE à partir des informations reçues des communes dans le cadre de leur mission de service public.
Quelques informations sur le fichier :
le fichier comporte 27983578 décès et NaN doublons (stricts)
il comporte les décès de 1970 à aujourd'hui (jusqu'au 31/10/2024)
il a été mis à jour le 05/11/2024
Un projet open source du Ministère de l'Intérieur.
Journal du jeudi 14 novembre 2024 à 10:26
DomainMOD is a self-hosted open source application used to manage your domains and other Internet assets in a central location.
Journal du mercredi 13 novembre 2024 à 15:05
Par curiosité, j'ai cherché des alternatives open-source à Customer.io, voici ce que j'ai trouvé :
- LimeJourney, projet d'un Solo Développeur, débuté en août 2024 (from)
- Laudspeaker, projet débuté en octobre 2022 (from)
- Dittofeed, projet Californien, codé par Max Gurewitz et Chandler Craig (marketing), incubé par Y Combinator, débuté en septembre 2022 (from) J'ai lu ces autres threads de Chandler Craig :
Journal du mardi 29 octobre 2024 à 12:20
Après quelques heures d'utilisation de Hasura, j'ai l'impression que le projet manque de soin :
Journal du dimanche 20 octobre 2024 à 21:42
En lisant le thread Reddit "Desktop version 2024.10.0 is no longer free software · Issue #11611 · bitwarden/clients" #JaiDécouvert Psono.
Open Source Self Hosted Password Manager for Companies
Secure self-hosted solution for businesses
-- from
Journal du mardi 01 octobre 2024 à 10:16
#JaiDécouvert au nouveau SaaS de signature électronique : OpenSign (from).
Le code source est disponible sous licence AGPL. Le projet semble actif.
Le projet semble avoir été créé en 2023 par un anglais nommé Amol Shejole.
Je viens de découvrir l'existence d'un long thread Hacker News qui date de novembre 2023 : Show HN: OpenSign – Open source alternative to DocuSign. Je n'ai pas encore pris le temps de lire tout le thread, mais il semble contenir des commentaires intéressants.
Voir aussi la note 2023-07-24_2046.
Journal du mardi 01 octobre 2024 à 09:48
J'ai redécouvert peer-calls (from), logiciel libre de visioconférence basé sur le backend Pion.
peer-calls propose deux types de réseaux : SFU et mesh. Le mode mesh semble être du p2p.
J'ai fait un petit test, le logiciel est très simple à utiliser et semble correctement fonctionner.
peer-calls semble être simple à déployer, un simple container Docker.
Journal du mardi 27 août 2024 à 10:33
#JaiDécouvert le mouvement Copie Publique (from)
Ce mouvement formalise et donne un nom à une pratique que j'ai essayé maintes fois de mettre en place par le passé sans succès.
À l'avenir, Copie Publique m'aidera dans mon travail d'évangélisation.
Journal du mardi 20 août 2024 à 09:46
#JaiLu les slides Mozilla va-t-il sauver le web ?.
Je suis attristé par la gouvernance de Mozilla 😭.
Journal du mardi 30 juillet 2024 à 16:33
Free and Open Source Machine Translation API. Self hosted, offline capable and easy to setup.
Qui utilise Argos Translate :
Open Source offline translation library written in Python.
Qui utilise OpenNMT.
Open source ecosystem for neural machine translation and neural sequence learning.
#JeMeDemande quelle est la différence en termes de qualité de traduction et de consommation d'énergie entre la technologie OpenNMT et les modèles de langage classiques tels que Llama 🤔.
Un ami m'a dit que DeepL utilise un Neural Machine Translation. Ce que semble confirmer cette source.
Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo
Je vous partage une réflexion que je viens d'avoir.
- Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo (mon moteur de recherche actuel).
- Je commence souvent par dégrossir une question avec ChatGPT, puis j'utilise mon moteur de recherche pour vérifier l'information avec une source que je juge "fiable".
- À d'autres moments, je préfère un article Wikipédia ou une documentation de référence plus exhaustive ou structurée — question d'habitude, sans doute — que la réponse de ChatGPT.
Suite à cela, je me suis dit que Google doit très rapidement revoir ses produits. Sinon, il est fort probable que Google perde énormément de revenus.
Je me suis ensuite demandé à quoi pourrait ressembler un produit Google basé sur un LLM qui remplacerait totalement ou en partie Google Search. Là, j'ai pensé directement à l'intégration de publicité à l'intérieur des réponses du LLM de Google 😱.
- Les publicités pourraient être intégrées de manière subtile sous forme de conseil dans les réponses.
- Je ne pourrais plus utiliser de bloqueurs de publicité comme uBlock Origin 😟.
- La situation pourrait être encore pire : Google pourrait se faire financer par des États, des grandes entreprises ou des milliardaires pour nous influencer légèrement via les réponses du LLM.
Je pense plus que jamais qu'il est important pour l'avenir de construire des modèles #open-source, auditables et reproductibles.
Journal du mardi 21 mai 2024 à 11:51
Sur Reddit, je suis tombé sur le thread concernant l'article de David Heinemeier Hansson (DHH de Basecamp) intitulé « Open source is neither a community nor a democracy ». Après lecture, je pense être en accord avec son contenu.
Journal du jeudi 02 mai 2024 à 19:37
#OnMaPartagé ce projet https://pts-project.org/ :
The PiRogue Tool Suite is an open-source consensual digital forensic analysis and incident response solution that empowers organizations with comprehensive tools for network traffic analysis, mobile forensics, knowledge management, and artifact handling.
J'ai l'impression que c'est un outil lié à la sécurité informatique, mais après une première lecture de 2min, je ne comprends pas très bien ni son utilité ni son usage 🤔.
Gotify est un logiciel de Messagerie push.
A simple server for sending and receiving messages in real-time per WebSocket. (Includes a sleek web-ui)
Site officiel : https://gotify.net/
Dépôt GitHub : https://github.com/gotify/server
Voir aussi : ntfy
Site officiel : https://firefly-iii.org/
The simple and elegantfeature voting tool
Create a community of users who feedback, vote and discuss the features that really matter to them. Take the guesswork out, learn and build features they really need.
Site officiel : https://fider.io/
Dépôt GitHub : https://github.com/getfider/fider
FerretDB was founded to become the de-facto open-source substitute to MongoDB. FerretDB is an open-source proxy, converting the MongoDB 5.0+ wire protocol queries to SQL - using PostgreSQL or SQLite as a database engine.
DomainMOD is a self hosted open-source application used to manage your domain name and other Internet assets in a central location.
Dépôt GitHub : https://github.com/dittofeed/dittofeed
Alternative à Customer.io.
Projet soutenu par Y Combinator.
Decidim est un logiciel de prise de décision.
Site officiel : https://decidim.org
Article Wikipedia : https://fr.wikipedia.org/wiki/Decidim
Dépôt GitHub : https://github.com/decidim/decidim/
Consul Democracy est un logiciel de prise de décision.
Site officiel : https://consuldemocracy.org/
Dépôt GitHub : https://github.com/consuldemocracy/consuldemocracy
Site officiel : https://caprover.com/
CapRover utilise Docker Swarm.
Cap Collectif est un logiciel de prise de décision.
Site officiel : https://www.cap-collectif.com
Dépôt GitHub : https://github.com/cap-collectif/cap-collectif
Logiciel de personal finance manager.
Site officiel : https://actualbudget.org/
The self-hosted search, analysis, and alerting server built for structured logs and traces.
Site officiel : https://datalust.co/seq
SWC (stands for Speedy Web Compiler) is a super-fast TypeScript / JavaScript compiler written in Rust.
Dépôt GitHub : https://github.com/swc-project/swc
SWC is 20x faster than Babel on a single thread and 70x faster on four cores.
-- from
Site web : https://www.rootdb.fr/ Code source : https://github.com/orgs/RootDBApp/repositories
Rolldown is a JavaScript/TypeScript bundler written in Rust intended to serve as the future bundler used in Vite. It provides Rollup-compatible APIs and plugin interface, but will be more similar to esbuild in scope.
Dépôt GitHub : https://github.com/rolldown/rolldown
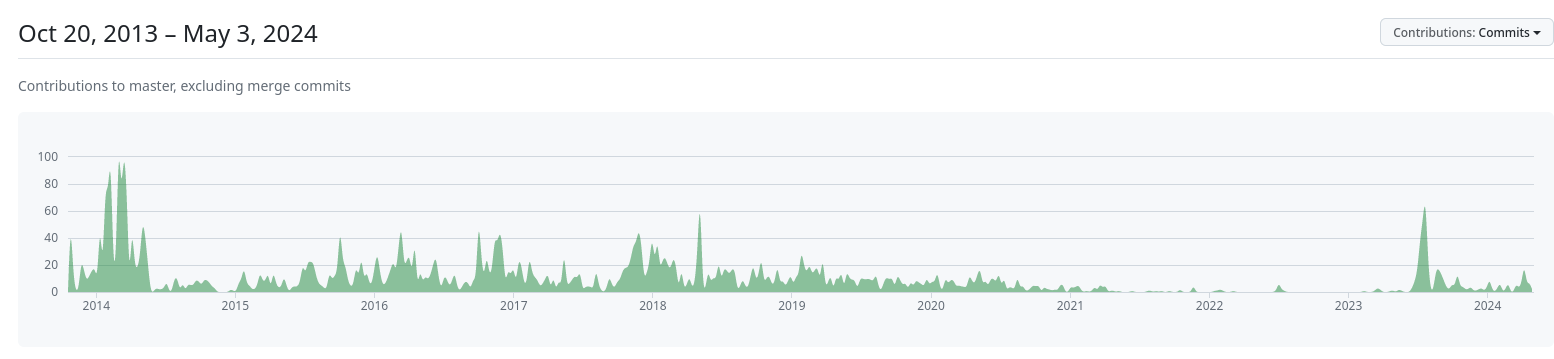
Site web : https://github.com/getredash/redash
Je constatais que ce projet était mort depuis son rachat en juin 2020 par Databricks : Redash is joining Databricks mais j'ai l'impression que le projet a repris vie depuis mi 2023 :
Open Source Self Hosted Password Manager for Companies
Secure self-hosted solution for businesses
Site officiel : https://psono.com/
Vous êtes sur la première page | [ Page suivante (29) >> ]