
OS
Journaux liées à cette note :
20 ans après avoir été traumatisé par le projet Palladium de Microsoft, je m'intéresse enfin au TPM2
Comme beaucoup de libristes, en 2002, j'ai été effrayé par le projet Palladium de Microsoft.
Palladium (NGSCB) était une initiative Microsoft annoncée en 2002 pour créer une plateforme de "trusted computing" basée sur du matériel sécurisé (une puce TPM dédiée) contrôlant strictement quels logiciels pouvaient s'exécuter et quels périphériques étaient autorisés à communiquer avec le système. L'objectif était de permettre à Microsoft de certifier cryptographiquement l'intégrité de toute la chaîne matérielle et logicielle, depuis le démarrage de l'ordinateur jusqu'aux applications en cours d'exécution.
On imaginait des scénarios concrets comme une carte son qui refuserait de capturer de l'audio depuis une sortie protégée par DRM, ou une carte graphique qui bloquerait la capture d'écran de contenu vidéo protégé.
À cette époque, Microsoft était en position hégémonique écrasante sur le marché des ordinateurs personnels : MacOS d'Apple représentaient moins de 3% des parts de marché.
Palladium représentait concrètement une forme de totalitarisme numérique sous contrôle total de Microsoft et des ayants droit.
Pour la communauté du libre, cela signifiait concrètement que ce système pourrait empêcher l'exécution de systèmes d'exploitation libres, bloquer l'accès aux périphériques sans drivers signés par Microsoft, et conduire à une génération d'ordinateurs où Linux serait techniquement banni ou très difficile à installer.
Heureusement, les critiques venues de toutes parts , combinées aux accusations de monopole et aux risques antitrust, ont contraint Microsoft à faire marche arrière. Cela a abouti à la situation actuelle où le TPM est davantage orienté vers la sécurité que vers le DRM et la restriction des libertés des utilisateurs.
Cet épisode a eu des conséquences durables pour moi : depuis, dès que j'entendais parler de puce de sécurité ou de TPM, j'avais immédiatement une réaction de rejet, parce que cela évoquait pour moi vendor lock-in, restrictions et contrôle par Microsoft. Je n'ai jamais cherché à en savoir plus.
C'est seulement en septembre 2025, lors de mon exploration du filesystem fs-verity, que j'ai découvert que les fonctionnalités du TPM2 sont en réalité très intéressantes et peuvent servir des objectifs de sécurité légitimes, très bien supportées par Linux.
2014-2018 approche alternative avec Atomic Project
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "CoreOS de 2013 à 2018".
La première version d'Atomic Project paraît en 2014, avec rpm-ostree comme élément central, développé principalement par Colin Walters de Red Hat.
rpm-ostree utilise libostree comme fondation, composant qui lui confère "toute sa puissance".
OSTree composant central de Atomic Project
Colin Walters a créé libostree en 2011 pour les besoins de GNOME Continuous.
libostree est un outil qui s'inspire de Git, mais se spécialise dans la gestion d'arbres de fichiers complets de système d'exploitation.
Principales différences avec Git :
- Aucune copie lors des checkouts : libostree repose sur des hardlinks, donc pas de working copy du fait de l'immutabilité des fichiers.
- libostree préserve les contextes SELinux, les xattrs, les uid/gid, ainsi que des timestamps précis
- libostree peut gérer les device nodes (
/dev/zero,/dev/null…), les sockets (/run/systemd/notify...), et tous les types de fichiers d'un filesystem d'OS - Un mécanisme de déduplication
- …
Avec OSTree, pas besoin de double partition
À la différence de CoreOS Container Linux qui utilisait le système de mise à jour A/B (seamless) system updates, Fedora Atomic Host (puis Fedora CoreOS) n'a pas besoin de deux partitions grâce à libostree.
Lors d'un upgrade, libostree réalise un "checkout" en utilisant la commande ostree-admin-deploy .
Puis grub communique au kernel le paramètre ostree= qui détermine sur quel déploiement booter.
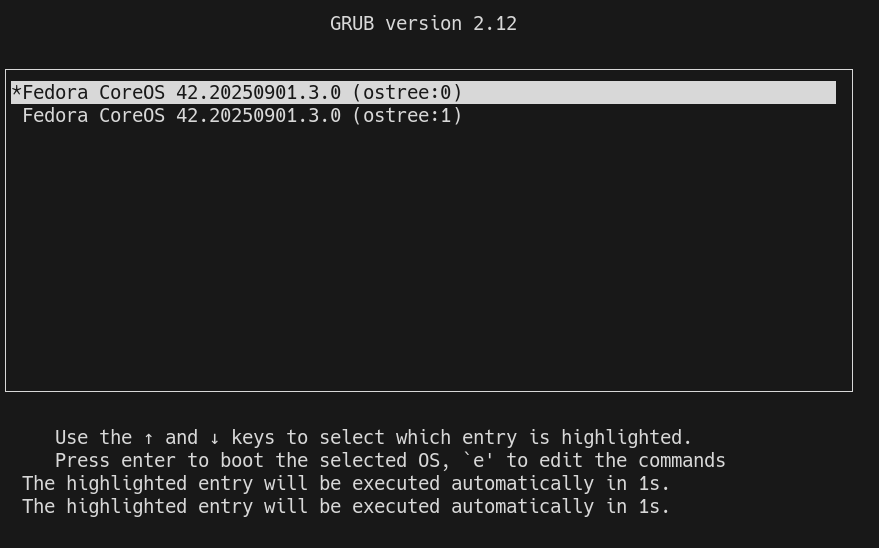
Voici les avantages de l'utilisation de libostree par rapport au système A/B (seamless) system updates :
- libostree permet de conserver plusieurs déploiements, sans se limiter à 2
- Grâce au système de déduplication, libostree consomme beaucoup moins d'espace disque
- Grâce au téléchargement uniquement des deltas, les mises à jour sont très rapides
Néanmoins, alors que libostree offre techniquement la possibilité de créer autant de déploiements que souhaité, d'après mes tests, Fedora CoreOS semble actuellement limité à 2 déploiements seulement.
J'ai trouvé cette issue qui aborde ce sujet : support configuring host to retain more than two deployments.
rpm-ostree
Les utilisateurs d'Fedora Atomic Host n'interagissent pas directement avec libostree mais avec rpm-ostree.
rpm-ostree s'appuie sur les librairies libostree et libdnf pour installer des packages RPM et propose de nombreuses commandes d'administration de l'OS :
stephane@stephane-coreos:~$ rpm-ostree
Usage:
rpm-ostree [OPTION…] COMMAND
Builtin Commands:
apply-live Apply pending deployment changes to booted deployment
cancel Cancel an active transaction
cleanup Clear cached/pending data
compose Commands to compose a tree
db Commands to query the RPM database
deploy Deploy a specific commit
finalize-deployment Unset the finalization locking state of the staged deployment and reboot
initramfs Enable or disable local initramfs regeneration
initramfs-etc Add files to the initramfs
install Overlay additional packages
kargs Query or modify kernel arguments
override Manage base package overrides
rebase Switch to a different tree
refresh-md Generate rpm repo metadata
reload Reload configuration
reset Remove all mutations
rollback Revert to the previously booted tree
search Search for packages
status Get the version of the booted system
uninstall Remove overlayed additional packages
upgrade Perform a system upgrade
usroverlay Apply a transient overlayfs to /usr
Note suivante : "Fusion de CoreOS et Atomic Project en 2018.
Journal du lundi 09 septembre 2024 à 15:59
Dans cette note, je souhaite présenter ma doctrine de mise à jour d'OS de serveurs.
Je ne traiterai pas ici de la stratégie d'upgrade pour un Cluster Kubernetes.
La mise à jour d'un serveur, par exemple, sous un OS Ubuntu LTS, peut être effectuée avec les commandes suivantes :
sudo apt upgrade -y- ou
sudo apt dist-upgrade -y(plus risqué) - ou
sudo do-release-upgrade(encore plus risqué)
L'exécution d'un sudo apt upgrade -y peut :
- Installer une mise à jour de docker, entraînant une interruption des services sur ce serveur de quelques secondes à quelques minutes.
- Installer une mise à jour de sécurité du kernel, nécessitant alors un redémarrage du serveur, ce qui entraînera une coupure de quelques minutes.
Une montée de version de l'OS via sudo do-release-upgrade peut prendre encore plus de temps et impliquer des ajustements supplémentaires.
Bien que ces opérations se déroulent généralement sans encombre, il n'y a jamais de certitude totale, comme l'illustre l'exemple de la Panne informatique mondiale de juillet 2024.
Sachant cela, avant d'effectuer la mise à jour d'un serveur, j'essaie de déterminer quelles seraient les conséquences d'une coupure d'une journée de ce serveur.
Si je considère que ce risque de coupure est inacceptable ou ne serait pas accepté, j'applique alors la méthode suivante pour réaliser mon upgrade.
Je n'effectue pas la mise à jour le serveur existant. À la place, je déploie un nouveau serveur en utilisant mes scripts automatisés d'Infrastructure as code / GitOps.
C'est pourquoi je préfère éviter de nommer les serveurs d'après le service spécifique qu'ils hébergent (voir aussi Pets vs Cattle). Par exemple, au lieu de nommer un serveur gitlab.servers.example.com, je vais le nommer server1.servers.example.com et configurer gitlab.servers.example.com pour pointer vers server1.servers.example.com.
Ainsi, en cas de mise à jour de server1.servers.example.com, je crée un nouveau serveur nommé server(n+1).servers.example.com.
Ensuite, je lance les scripts de déploiement des services qui étaient présents sur server1.servers.example.com.
Idéalement, j'utilise mes scripts de restauration des données depuis les sauvegardes des services de server1.servers.example.com, ce qui me permet de vérifier leur bon fonctionnement.
Ensuite, je prépare des scripts rsync pour synchroniser rapidement les volumes entre server1.servers.example.com et server(n+1).servers.example.com.
Je teste que tout fonctionne bien sur server(n+1).servers.example.com.
Si tout fonctionne correctement, alors :
- J'arrête les services sur
server(n+1).servers.example.com; - J'exécute le script de synchronisation
rsyncdeserver1.servers.example.comversserver(n+1).servers.example.com; - Je relance les services sur
server(n+1).servers.example.com - Je modifie la configuration DNS pour faire pointer les services de
server1.servers.example.comversserver(n+1).servers.example.com - Quelques jours après cette intervention, je décommissionne
server1.servers.example.com.
Cette méthode est plus longue et plus complexe qu'une mise à jour directe de l'OS sur le server1.servers.example.com, mais elle présente plusieurs avantages :
- Une grande sécurité ;
- L'opération peut être faite tranquillement, sans stress, avec de la qualité ;
- Une durée de coupure limitée et maîtrisée ;
- La possibilité de confier la tâche en toute sécurité à un nouveau DevOps ;
- La garantie du bon fonctionnement des scripts de déploiement automatisé ;
- La vérification de l'efficacité des scripts de restauration des sauvegardes ;
- Un test concret des scripts et de la documentation du Plan de reprise d'activité.
Si le serveur à mettre à jour fonctionne sur une Virtual instance, il est également possible de cloner la VM et de tester la mise à niveau. Cependant, je préfère éviter cette méthode, car elle ne permet pas de valider l'efficacité des scripts de déploiement.