
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (59 notes) :
Journal du dimanche 16 novembre 2025 à 22:17
Suite à publication des notes "Setup Fedora CoreOS avec LUKS et TPM, non sécurisé contre le vol physique de serveur", "Setup Fedora CoreOS avec LUKS et Tang", j'ai réfléchi à mes prochaines itérations du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab".
Je souhaite réaliser et publier un playground pour étudier et tester les solutions VPN suivantes :
- Tailscale (solution partiellement libre, opéré par une entreprise basée au Canada)
- netbird (solution totalement libre, qui propose une version SaaS opérée par une entreprise basée en Allemagne)
- headscale (solution totalement libre à self hosted)
Dans un premier temps, je souhaite pouvoir accéder en ssh aux serveurs de mon Homelab depuis n'importe où. L'objectif est d'utiliser une méthode unique pour me connecter à ces serveurs en utilisant simplement leur hostname, sans avoir à gérer leurs adresses IP locales ni à configurer manuellement des entrées DNS.
Je souhaite tester l'installation de ces solutions sur des serveurs sous CoreOS, ma workstation sous Fedora et sous Android.
Idéalement, je souhaite configurer les services netbird et Tailscale via Terraform.
Je ne pense pas tester tout le suite headscale.
Setup Fedora CoreOS avec LUKS et Tang
Il y a quelques jours, dans ma note "Setup Fedora CoreOS avec LUKS et TPM", je disais :
Une solution pour traiter ce point faible est d'utiliser un pin éloigné physiquement du serveur qui l'utilise.
Le framework Clevis utilise le terme "pins" pour désigner les différents méthodes de déverrouillage d'un volume LUKS.
Origine du mot "pin" ?
Claude Sonnet 4.5 m'a expliqué que le terme "pin", qui se traduit par "goupille" en français, désigne la pièce mécanique qui bloque l'ouverture d'un cadenat.
Par exemple, dans un contexte self hosting dans un homelab, je peux héberger physiquement un serveur dans mon logement et le connecter à un pin sur un serveur Scaleway ou sur un serveur dans le homelab d'un ami.
Les pins distants, accessibles via réseau, sont appelés serveurs Network-Bound Disk Encryption.
Si le serveur Network-Bound Disk Encryption est configuré pour répondre uniquement aux requêtes provenant de l'IP de mon réseau homelab, en cas de vol du serveur, le voleur ne pourra pas récupérer le secret permettant de déchiffrer le volume LUKS.
Dans le playground install-coreos-iso-on-qemu-with-luks-and-tang, j'ai testé avec succès le déverrouillage d'un volume LUKS avec un serveur Network-Bound Disk Encryption nommé tang.
Pour être précis, dans la configuration de ce playground, deux pins sont obligatoires pour déverrouiller automatiquement le volume : un pin tang et un pin TPM2. Le nombre minimum de pins requis pour le déverrouillage est défini par le paramètre threshold.
clevis, qui permet de configurer les pins et de gérer la récupération de la passphrase à partir des pins, utilise l'algorithme Shamir's secret sharing (SSS) pour répartir le secret à plusieurs endroits.
Voici quelques scénarios de conditions de déverrouillage que clevis permet de configurer grâce à SSS :
- TPM2 ou Tang serveur 1
- TPM2 et Tang serveur 1
- Tang serveur 1 ou Tang serveur 2
- 2 parmi Tang serveur 1, Tang serveur 2, Tang serveur 3
- ...
Si les conditions ne sont pas remplies, systemd-ask-password demande à l'utilisateur de saisir sa passphrase au clavier.
Je n'ai pas trouvé d'image docker officielle de tang. Toutefois, j'ai trouvé ici l'image non officielle padhihomelab/tang (son dépôt GitHub : https://github.com/padhi-homelab/docker_tang).
Dans mon playground, je l'ai déployé dans ce docker-compose.yml.
J'ai trouvé la configuration butane de tang simple à définir (lien vers le fichier) :
luks:
- name: var
device: /dev/disk/by-partlabel/var
wipe_volume: true
key_file:
inline: password
clevis:
tpm2: true
tang:
- url: "http://10.0.2.2:1234"
# $ docker compose exec tang jose jwk thp -i /db/pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw.jwk
# pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw
thumbprint: dx9dNzgs-DeXg0SCBQW5rb7WQkSIN1B8MIgcO6WxJfI
threshold: 2 # TMP2 + Tang (or passphrase keyboard input)
La seule complexité que j'ai rencontrée est la méthode pour récupérer le paramètre thumbprint de l'instance tang.
Voici la méthode que j'ai utilisée :
$ docker compose exec tang jose jwk thp -i /db/pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw.jwk
pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw
Autre difficulté, il faut ajouter les arguments kernel suivants pour activer l'accès réseau dès le début du process de boot afin de permettre à clevis d'accéder au serveur tang :
variant: fcos
version: 1.6.0
kernel_arguments:
should_exist:
- ip=dhcp
- rd.neednet=1
J'ai intégré au README.md du playground une section nommée "How to switch from 2 required ping to 1 or the opposite?", pour documenter comment modifier à chaud la configuration clevis.
Par exemple pour changer de serveur tang ou modifier le nombre de pins nécessaires pour déverrouiller la partition chiffrée.
Il est conseillé d'activer le pin TPM2 en complément de tang pour éviter ce type d'attaque décrit par Claude Sonnet 4.5 :
Imaginons un admin malveillant dans ton entreprise :
- Il a accès physique aux serveurs
- Il a accès au réseau (donc au serveur Tang)
- Il clone un disque pendant la nuit
- Il essaie de le monter sur sa propre machine pour extraire des données
Tang seul : ❌ Il réussit
TPM + Tang : ✅ Il échoue
À noter que l'instance tang ne contient pas la passphrase et ne voit jamais passer la passphrase via son API.
Voici les explications que m'a données Claude Sonnet 4.5 :
Tang ne stocke pas la passphrase secrète de chiffrement LUKS. C'est justement tout l'intérêt de cette solution !
Voici comment ça fonctionne :
Le principe de Tang + Clevis
- Génération de clé dérivée : Clevis (le client) contacte le serveur Tang et récupère sa clé publique
- Chiffrement avec la clé de Tang : Clevis utilise cette clé publique pour chiffrer la passphrase LUKS
- Stockage local : La passphrase chiffrée est stockée localement dans l'en-tête LUKS du disque (pas sur le serveur Tang)
- Déchiffrement au boot :
- La machine contacte Tang
- Tang utilise sa clé privée pour aider à déchiffrer
- La passphrase LUKS est reconstituée
- Le disque est déverrouillé
Ce que Tang sait et ne sait pas
- ❌ Tang ne connaît jamais votre passphrase LUKS
- ❌ Tang ne stocke rien concernant vos clés
- ✅ Tang fournit juste un service cryptographique (un oracle de déchiffrement)
- ✅ C'est un serveur sans état (stateless)
C'est du chiffrement asymétrique avec un mécanisme appelé "network-bound disk encryption" : le disque ne peut être déchiffré que si la machine peut contacter le serveur Tang sur le réseau.
Voici quelques ressources supplémentaires au sujet des techniques de déverrouillage automatique des volumes LUKS :
Setup Fedora CoreOS avec LUKS et TPM, non sécurisé contre le vol physique de serveur
Comme je l'ai dit dans cette précédente note, jusqu'il y a peu de temps, je ne m'étais jamais intéressé et j'avais même évité les technologies liées aux trusted computing.
Il y quelques jours, j'ai testé avec succès l'installation d'une Fedora CoreOS avec une clé de déchiffrement LUKS sauvegardée dans une puce TPM2 à l'aide de clevis.
Grâce à TPM, cette configuration évite de devoir saisir la clé de déchiffrement au moment du boot de l'OS.
Je trouve cette approche particulièrement pertinente sur une distribution CoreOS qui utilise zincati pour appliquer automatiquement les mises à jour de l'OS à des horaires définis (voir note à ce sujet).
Pour tester cette configuration, j'ai créé le playground install-coreos-iso-on-qemu-with-luks , qui me permet de tester localement l'installation dans une VM QEMU.
Pour émuler le TPM2, j'utilise swtpm et le BIOS UEFI Open source edk2-ovmf .
Dans ce test, j'ai choisi de créer et de chiffrer une partition pour stocker les données du dossier /var/, qui sur CoreOS est l'emplacement qui contient les données mutables (accessibles en écriture).
Voici la configuration butane de LUKS encryption avec les options TPM2 et clevis que j'ai utilisées (fichier complet) :
storage:
disks:
- device: /dev/nvme0n1
wipe_table: false
partitions:
- number: 4
label: root
size_mib: 15000
resize: true
- number: 5
label: var <=== label
size_mib: 0 # 0 = use all remaining space
luks:
- name: var <=== label
device: /dev/disk/by-partlabel/var
wipe_volume: true
key_file:
inline: password
clevis:
tpm2: true
filesystems:
- path: /var
device: /dev/mapper/var
format: xfs
wipe_filesystem: true
label: var
with_mount_unit: true
Je trouve le contenu de ce fichier de configuration assez simple et explicite.
J'ai ensuite créé un second playground install-coreos-iso-on-baremetal-with-luks.
L'installation automatique s'est déroulée sans problème sur un serveur baremetal.
J'ai testé la désactivation de TPM2 dans le BIOS : la console m'a alors demandé de saisir la clé manuellement. C'est plutôt pratique en cas de problème TPM, branchement du disque sur une autre machine…
La clé de chiffrement LUKS n'est pas stockée en clair dans le fichier ISO, il n'est donc pas nécessaire de sécuriser l'accès à ce fichier.
Attention, j'ai découvert que cette méthode n'est pas sécurisée en cas de vol physique du serveur !
Si un attaquant boot depuis un autre disque avec le même firmware et le même kernel, il pourra extraire en clair la clé LUKS stockée dans le TPM 🫣.
D'après mes recherches, la seule approche qui semble permettre à la fois la protection contre le vol physique et le reboot automatique serait d'utiliser clevis avec un serveur tang plutôt que le TPM.
Je compte tester cette configuration dans les prochaines semaines (depuis, cette note a été publiée : Setup Fedora CoreOS avec LUKS et Tang).
Quelques outils CoreOS : coreos-installer, graphe de migration et zincati
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Fusion de CoreOS et Atomic Project en 2018".
coreos-installer
L'outil coreos-installer est un composant essentiel de Fedora CoreOS. Il propose différentes méthodes pour installer Fedora CoreOS.
La commande coreos-installer download permet de télécharger tout type de version de CoreOS, sous différents formats, par exemple iso, raw, qemu, cloud image, etc (toutes celles présentes dans la page download).
Ensuite, la commande coreos-installer install permet d'installer la version téléchargée vers un disque. Cette commande est par exemple disponible à la fin du boot d'une image ISO. Contrairement à Fedora Silverblue qui propose d'installer la distribution avec Anaconda, l'installation de CoreOS s'effectue en cli via coreos-installer install.
Ensuite, la commande coreos-installer install permet d'installer la version téléchargée sur un disque. Cette commande est notamment accessible après le démarrage d'une image ISO. Contrairement à Fedora Silverblue qui utilise l'installateur graphique Anaconda, CoreOS s'installe exclusivement en cli via coreos-installer install.
Toutefois, coreos-installer permet de préparer une installation automatique. La commande coreos-installer iso customize modifie une image ISO existante pour y intégrer directement une configuration ignition, rendant l'installation entièrement automatisée au démarrage.
Voici un exemple dans mon playground : atomic-os-playground/create-coreos-custom-iso.sh.
coreos-installer pxe permet aussi d'effectuer une configuration automatique par réseau, via PXE, mais je ne l'ai pas testé.
Graphe de migration de versions
Lors de mes tests d'upgrade de CoreOS à partir d'une ancienne release (environ n-10), j'ai constaté que la transition vers la dernière version ne se faisait pas directement mais nécessitait le passage par des versions intermédiaires.
J'ai découvert que CoreOS maintient un graphe qui définit le parcours d'upgrade requis. Certaines versions intermédiaires doivent être installées pour gérer des breaking changes, comme la migration de configurations.
zincati
Un autre composant important de Fedora CoreOS est zincati, le service responsable de l'exécution des mises à jour automatiques.
zincati décide d'effectuer les mises à jour en fonction du seuil de prudence de déploiement (rollout_wariness) et de la stratégie de mise à jour : immediate ou periodic (plage horaire définie dans la semaine).
CoreOS utilisant par défaut la stratégie immediate, zincati détecte automatiquement les nouvelles releases dès le premier démarrage et lance immédiatement leur téléchargement, suivi d'un redémarrage.
Le téléchargement par deltas rend l'upgrade vers la dernière release très rapide.
zincati permet également de coordonner les mises à jour de plusieurs serveurs, fonctionnalité particulièrement utile dans le contexte d'un cluster Kubernetes. Je n'ai pas encore testé cette fonctionnalité.
Note suivante : "composefs, un filesystem spécialement créé pour les besoins des distributions atomic".
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Rocky Linux semble reproduire CentOS de manière plus fidèle que AlmaLinux
Hier, j'ai écrit la note "AlmaLinux ou Rocky Linux ?".
En ce moment, je suis en train d'approfondir mes connaissances sur le fonctionnement des différents network backend de QEMU et j'en ai profité pour comparer le comportement d'Ubuntu, AlmaLinux, Rocky Linux et CentOS.
J'ai lancé QEMU avec le paramètre qemu ... -nic user avec chacune de ces distributions et voici les résultats de ip addr dans chacune de ces VMs:
Ubuntu :
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
inet 10.0.2.15/24 metric 100 brd 10.0.2.255 scope global dynamic ens3
valid_lft 83314sec preferred_lft 83314sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic mngtmpaddr noprefixroute
valid_lft 86087sec preferred_lft 14087sec
inet6 fe80::5054:ff:fe12:3456/64 scope link
valid_lft forever preferred_lft forever
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute ens3
valid_lft 83596sec preferred_lft 83596sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86379sec preferred_lft 14379sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
CentOS :
$ sudo ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute ens3
valid_lft 86341sec preferred_lft 86341sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86342sec preferred_lft 14342sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute eth0
valid_lft 84221sec preferred_lft 84221sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86053sec preferred_lft 14053sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Ce que j'observe :
- Rocky Linux et CentOS semblent se comporter de manière identique :
- une interface réseau nommée
ens3qui signifie : ethernet slot 3 - et les noms alternatifs :
enp0s3qui signifie : ethernet, PCI bus 0, slot 3enx525400123456qui signifie : ethernet +x+ la adresse MAC sans les:
- une interface réseau nommée
- Ubuntu :
- une interface réseau nommée
ens3 - et un nom alternatif :
enp0s3
- une interface réseau nommée
- AlmaLinux :
- une interface réseau nommée
eth0 - et les noms alternatifs :
ens3enp0s3enx525400123456
- une interface réseau nommée
Voici les configurations de GRUB_CMDLINE_LINUX_DEFAULT :
Rocky Linux et CentOS :
GRUB_CMDLINE_LINUX_DEFAULT="console=ttyS0,115200n8 no_timer_check crashkernel=1G-4G:192M,4G-64G:256M,64G-:512M"
GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,115200n8 no_timer_check biosdevname=0 net.ifnames=0"
Ubuntu :
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
Conclusion de cette analyse : il me semble que Rocky Linux cherche à reproduire CentOS de manière très fidèle, alors qu'AlmaLinux se permet davantage de libertés dans son approche.
Journal du vendredi 04 juillet 2025 à 14:46
En étudiant IPv6 et Linux bridge, j'ai découvert que Netlink a été introduit pour remplacer ioctl et procfs.
Netlink permet à des programmes user-land de communiquer avec le kernel via une API asynchrone. C'est une technologie de type inter-process communication (IPC).
La partie "Net" de "Netlink" s'explique par l'histoire : au départ, Netlink servait exclusivement à iproute2 pour la configuration réseau.
L'usage de Netlink s'est ensuite généralisé à d'autres aspects du kernel.
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Journal du jeudi 10 avril 2025 à 22:48
Dans la documentation de restic, #JaiDécouvert resticprofile :
Scheduling backups
Restic does not have a built-in way of scheduling backups, as it’s a tool that runs when executed rather than a daemon. There are plenty of different ways to schedule backup runs on various different platforms, e.g. systemd and cron on Linux/BSD and Task Scheduler in Windows, depending on one’s needs and requirements. If you don’t want to implement your own scheduling, you can use resticprofile.
Le projet resticprofile a commencé en 2019, tout comme restic, il est écrit en Golang.
resticprofile permet de lancer restic à partir d'un fichier de configuration. D'après l'extrait ci-dessous, l'équipe de restic ne semble pas vouloir intégrer un système de fichiers de configuration.
Configuration profiles manager for restic backup
resticprofile is the missing link between a configuration file and restic backup. Creating a configuration file for restic has been discussed before, but seems to be a very low priority right now.
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.
Journal du mercredi 02 avril 2025 à 16:48
J'ai souvent besoin d'exécuter l'équivalent de :
$ scp -r root@myserver:/foo/bar/ ./tmp/
ou l'inverse :
$ scp -r ./tmp/ root@myserver:/foo/bar/
sur des serveurs sur lesquels je n'ai pas directement accès à l'utilisateur root par ssh.
J'accède, par exemple, à ce serveur via l'utilisateur ubuntu.
L'utilisateur ubuntu n'a pas accès aux fichiers que je souhaite download ou upload.
Sur le serveur, j'ai accès aux fichiers de l'utilisateur root via sudo.
Voici une astuce pour download des fichiers via ssh et sudo :
$ ssh ubuntu@myserver "sudo tar cf - -C /foo/bar/ ." | tar xf - -C ./tmp/
Et, voici une méthode pour upload :
$ tar cf - -C ./tmp/ . | ssh ubuntu@myserver "sudo tar xf - -C /foo/bar/"
Object Storage append-only backup playground
Pour un projet, je dois mettre en place un système de sauvegarde sécurisé (WORM).
Ici, "sécurisé" signifie :
- qui empêche la suppression accidentelle ou intentionnelle des données ;
- une protection contre les ransomwares.
Pour cela, j'ai décidé de sauvegarder ces données chez deux fournisseurs d'Object Storage :
Je viens de publier le playground append-only-backup-playground qui m'a permis de tester la configuration de bucket Backblaze et Scaleway.
Object Storage append-only backup playground
In this "playground" repository, I explore different methods to configure object storage services in append-only or write-once-read-many (WORM) mode.
J'ai testé deux méthodes qui interdisent la suppression des données :
1.La première, basée sur une clé d'accès avec des droits limités : l'interdiction de supprimer des fichiers. Si un attaquant parvient à s'infiltrer sur un serveur qui effectue des sauvegardes, la clé ne lui permettra pas d'effacer les anciennes sauvegardes.2.La seconde méthode plus stricte utilise la fonctionnalité object lock en modeGOVERNANCEouCOMPLIANCE.
Je vous recommande d'être vigilant avec le mode COMPLIANCE, car il vous sera impossible de supprimer les fichiers avant leur date de rétention, sauf si vous décidez de supprimer entièrement votre compte client !
Personnellement, je recommande d'utiliser la méthode 1 pour tous les environnements de développement.
En général, je pense que la méthode 1 est suffisante, même pour les environnements de production. Mais si les données sont vraiment critiques, alors je conseille le mode GOVERNANCE ou COMPLIANCE.
Le repository append-only-backup-playground contient 4 playgrounds :
- Pour tester la méthode
1:/scaleway/: configuration d'un bucket Scaleway Object Storage et une clé qui ne peut pas supprimer de fichier. L'option de versionning est activée./backblaze/: configuration d'un bucket Backblaze et une clé qui ne peut pas supprimer de fichier. L'option de versionning est activée.
- Pour tester la méthode
2:/scaleway-object-lock/: la même chose que/scaleway/avec en plus la configuration de object lock en modeGOVERNANCEavec une durée de rétention définie à 1 jour./backblaze-object-lock/: la même chose que/backblaze/avec en plus la configuration de object lock en modeGOVERNANCEavec une durée de rétention définie à 1 jour.
Journal du vendredi 07 février 2025 à 14:03
Pendant l'année 2014, Athoune m'a fait découvrir les concepts DevOps "Baking" et "Frying".
Je le remercie, car ce sont des concepts que je considère très importants pour comprendre les différents paradigmes de déploiement.
Je n'ai aucune idée dans quelles conditions il avait découvert ces concepts. J'ai essayé de faire des recherches limitées à l'année 2014 et je suis tombé sur cette photo :
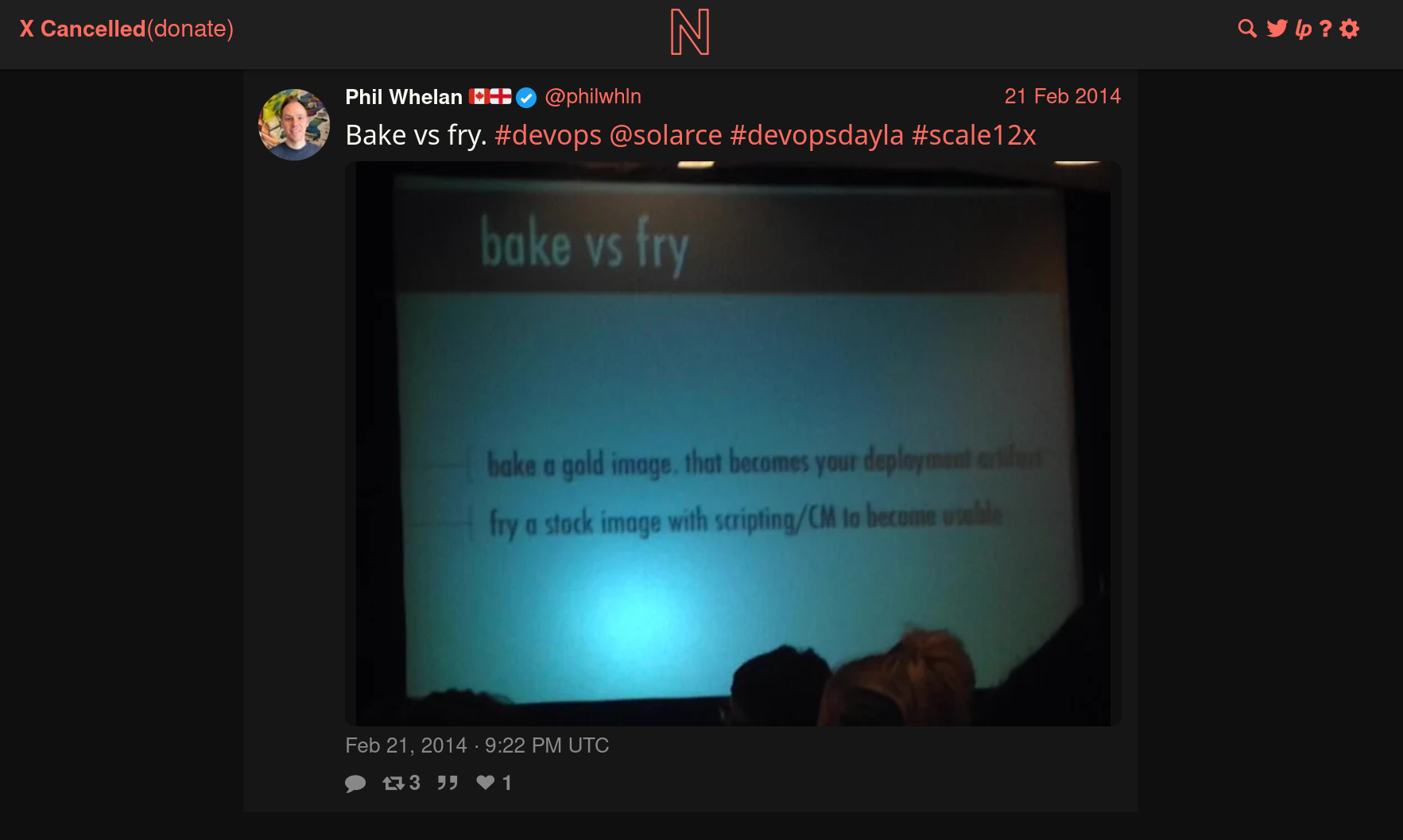
J'en déduis que cela devait être un sujet à la méthode dans l'écosystème DevOps de 2014.
Cet ami me l'avait très bien expliqué avec une analogie du type :
« Le baking en DevOps, c’est comme dans un restaurant où les plats sont préparés en cuisine et ensuite apportés tout prêt salle à la table du client. Le frying, c’est comme si le plat était préparé directement en salle sur la table du client. »
Bien que cette analogie ne soit pas totalement rigoureuse, elle m'a bien permis de saisir, en 2014, le paradigme Docker qui consiste à préparer des images de container en amont. Ce paradigme permet d'installer, de configurer ces images "en cuisine", donc pas sur les serveurs de production, "de goûter les plats" et de les envoyer ensuite de manière prédictible sur le serveur de production.
Ces images peuvent être construites soit sur la workstation du développeur ou mieux, sur des serveurs dédiés à cette fonction, comme Gitlab-Runner…
Définitions proposées par LLaMa :
Baking (ou "Image Baking") : Il s'agit de créer une image de serveur prête à l'emploi, avec tous les logiciels et les configurations nécessaires déjà installés et configurés. Cette image est ensuite utilisée pour déployer de nouveaux serveurs, qui seront ainsi identiques et prêts à fonctionner immédiatement. L'avantage de cette approche est qu'elle permet de réduire le temps de déploiement et d'assurer la cohérence des environnements.
Frying (ou "Server Frying") : Il s'agit de déployer un serveur "nu" et de le configurer et de l'installer à la volée, en utilisant des outils d'automatisation tels que Ansible, Puppet ou Chef. Cette approche permet de personnaliser la configuration de chaque serveur en fonction des besoins spécifiques de l'application ou du service.
Exemple :
Cas d'usage Baking Frying Docker Construire une image complète ( docker build) et la stocker dans un registreLancer un conteneur minimal et installer les dépendances au démarrage. Machines virtuelles (VMs) Créer une image VM avec Packer et la déployer telle quelle Démarrer une VM de base et appliquer un script d’installation à la volée CI/CD Compiler et packager une application en image prête à être déployée Construire l’application à chaque déploiement sur la machine cible
En 2014, lorsque le concept de baking m’a été présenté, j’ai immédiatement été enthousiasmé, car il répondait à trois problèmes que je cherchais à résoudre :
- Réduire les risques d’échec d’une installation sur le serveur de production
- Limiter la durée de l’indisponibilité (pendant la phase d’installation)
- Éviter d'augmenter la charge du serveur durant les opérations de build lors de l’installation
Depuis, j'évite au maximum le frying et j'ai intégré le baking dans ma doctrine d'artisan développeur.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Journal du vendredi 07 février 2025 à 10:48
Note de type #mémento pour ajouter le support healthcheck à nginx-proxy et nginx-proxy acme-companion.
J'ai effectué des recherches dans les dépôts GitHub des projets :
- nginx-proxy « health », j'ai trouvé :
- acme-companion « health », j'ai trouvé :
J'ai aussi trouvé « Adding health check support to nginx-proxy nginx.tmpl file · nginx-proxy/nginx-proxy » qui est un sujet qui m'intéresse, mais pas en lien avec le sujet de cette note.
N'ayant rien trouvé de clés en main, voici ci-dessous mon implémentation.
Je ne suis pas certain qu'elle soit très robuste 🤔.
Elle a tout de même l'avantage de me permettre d'utiliser l'option --wait dans docker-compose up -d --remove-orphans --wait.
J'ai partagé aussi posté un commentaire à l'issue pour partager mon implémentation.
# docker-compose.yml
services:
nginx-proxy:
image: nginxproxy/nginx-proxy:1.6.4
container_name: nginx-proxy
restart: unless-stopped
network_mode: "host"
volumes:
- ./vhost.d/:/etc/nginx/vhost.d:rw
- ./htpasswd:/etc/nginx/htpasswd:ro
- html:/usr/share/nginx/html
- certs:/etc/nginx/certs:ro
- /var/run/docker.sock:/tmp/docker.sock:ro
healthcheck:
test: ["CMD-SHELL", "nginx -t && kill -0 $$(cat /var/run/nginx.pid)"]
interval: 10s
timeout: 2s
retries: 3
acme-companion:
image: nginxproxy/acme-companion:2.5.1
restart: unless-stopped
volumes_from:
- nginx-proxy
depends_on:
- "nginx-proxy"
environment:
DEFAULT_EMAIL: contact@stephane-klein.info
volumes:
- certs:/etc/nginx/certs:rw
- acme:/etc/acme.sh
- /var/run/docker.sock:/var/run/docker.sock:ro
healthcheck:
test: ["CMD-SHELL", "ps aux | grep -v grep | grep -q '/bin/bash /app/start.sh'"]
interval: 30s
timeout: 3s
retries: 3
start_period: 10s
volumes:
html:
certs:
acme:
Journal du mercredi 15 janvier 2025 à 13:50
Suite de la note 2025-01-14_2152 au sujet de Scaleway Domains and DNS.
Dans l'e-mail « External domain name validation » que j'ai reçu, je lis :
Alternative validation process (if your current registrar doesn't offer basic DNS service):
Please set your nameservers at your registrar to:
9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud
J'ai essayé cette méthode alternative pour le sous-domaine scw.stephane-klein.info :
Voici les DNS Records correspondants :
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
J'ai vérifié ma configuration :
$ dig NS scw.stephane-klein.info @ali.ns.cloudflare.com
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
J'ai attendu plus d'une heure et cette méthode de validation n'a toujours pas fonctionné.
Je pense que cela ne fonctionne pas 🤔.
Je vais créer un ticket de support Scaleway pour savoir si c'est un bug ou si j'ai mal compris comment cela fonctionne.
2025-01-17 : réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Conclusion : la documentation était imprécise, ce que j'ai essayé de réaliser ne peut pas fonctionner.
Journal du mardi 14 janvier 2025 à 21:52
J'ai réalisé un test pour vérifier que la délégation DNS par le managed service de Scaleway nommé Domains and DNS (lien direct) fonctionne correctement pour un sous-domaine tel que testscaleway.stephane-klein.info.
Je commence par suivre les instructions du how to : How to add an external domain to Domains and DNS.
Sur la page https://console.scaleway.com/domains/internal/create :
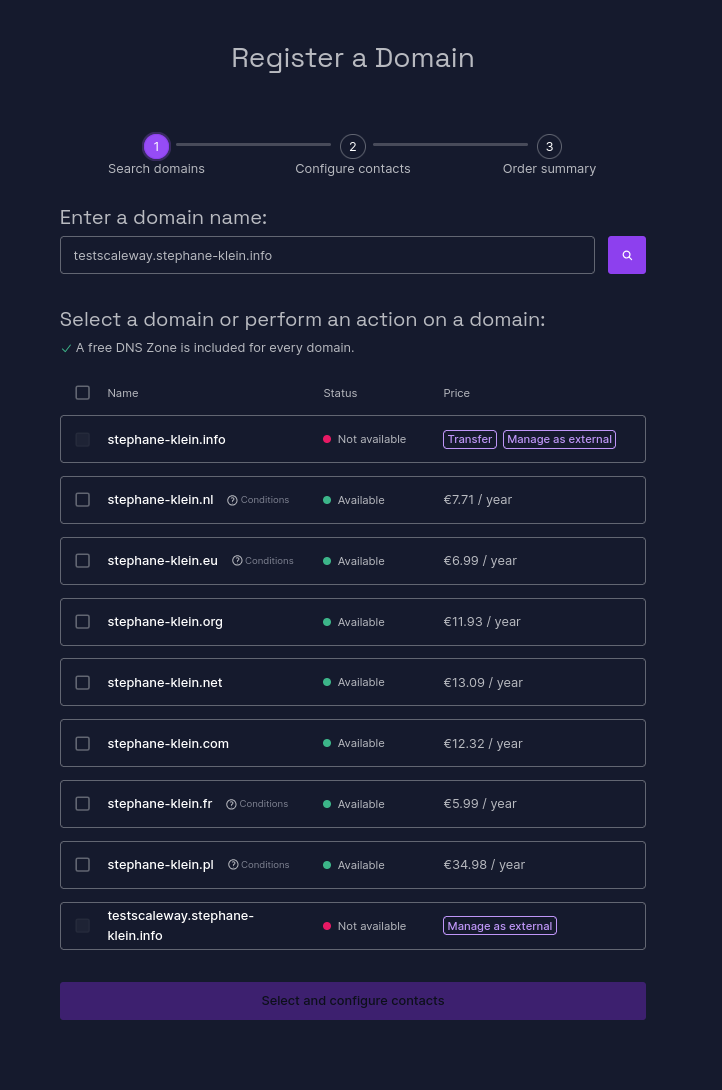
Je sélectionne la dernière entrée « Manage as external ».
Ensuite :

J'ai ajouté le DNS Record suivant à mon serveur DNS géré par cloudflare :
_scaleway-challenge.testscaleway.stephane-klein.info. 1 IN TXT "dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Vérification :
$ dig TXT _scaleway-challenge.testscaleway.stephane-klein.info +short
"dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Je n'ai aucune idée de la fréquencede passage du job Scaleway qui effectue la vérification de l'entrée TXT :
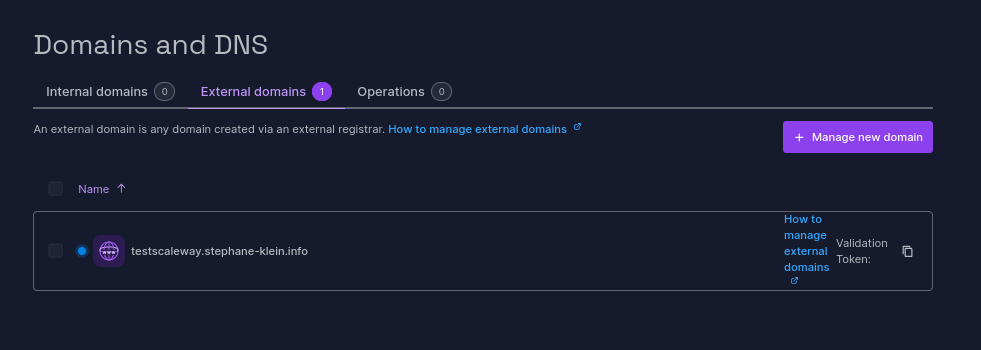
J'ai ajouté mon domaine à 22h22 et il a été validé à 22h54 :
Ensuite, j'ai ajouté les DNS Records suivants :
testscaleway.stephane-klein.info. 1 IN NS ns1.dom.scw.cloud.
testscaleway.stephane-klein.info. 1 IN NS ns0.dom.scw.cloud.
Vérification :
$ dig NS testscaleway.stephane-klein.info +short
ns0.dom.scw.cloud.
ns1.dom.scw.cloud.
Ensuite, j'ai configuré dans la console Scaleway, le DNS Record :
test1 3600 IN A 8.8.8.8
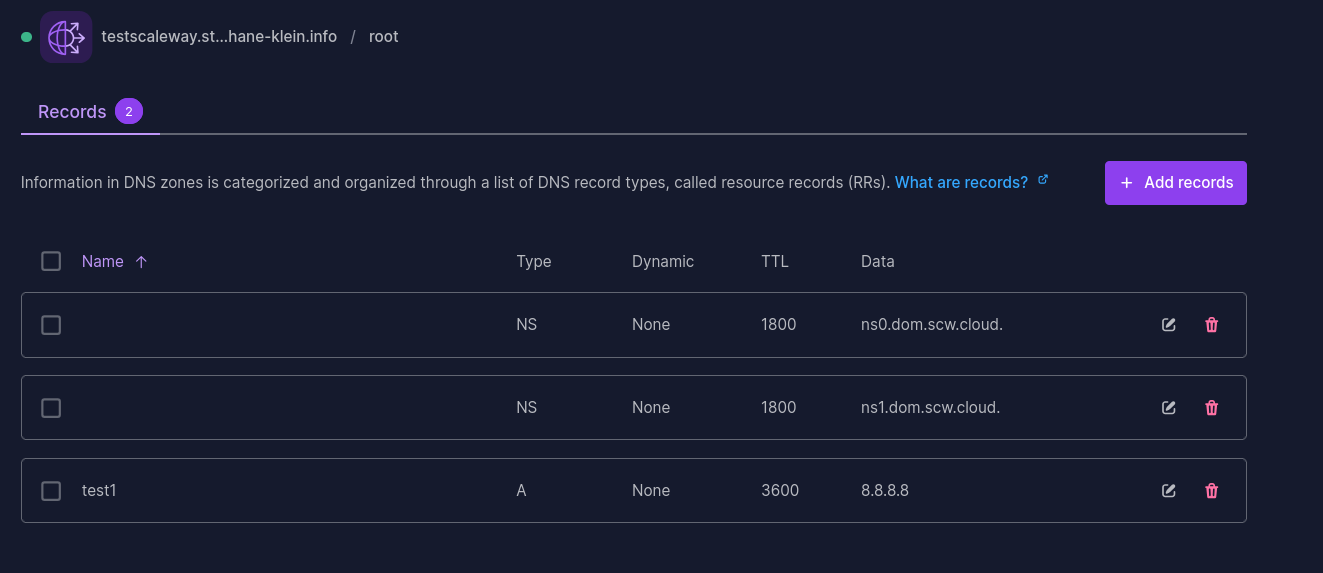
Vérification :
$ dig test1.testscaleway.stephane-klein.info +short
8.8.8.8
Conclusion : la réponse est oui, le managed service Scaleway Domains and DNS permet la délégation de sous-domaines 🙂.
Journal du samedi 28 décembre 2024 à 17:10
Comme mentionné dans la note 2024-12-28_1621, j'ai implémenté un playground nommé powerdns-playground.
J'ai fait le triste constat de découvrir encore un projet (PowerDNS-Admin) qui ne supporte pas une "automated and unattended installation" 🫤.
PowerDNS-Admin ne permet pas de créer automatiquement un utilisateur admin.
Pour contourner cette limitation, j'ai implémenté un script configure_powerdns_admin.py qui permet de créer un utilisateur basé sur les variables d'environnement POWERDNS_ADMIN_USERNAME, POWERDNS_ADMIN_PASSWORD, POWERDNS_ADMIN_EMAIL.
Le script ./scripts/setup-powerdns-admin.sh se charge de copier le script Python dans le container powerdns-admin et de l'exécuter.
J'ai partagé ce script sur :
- le SubReddit self hosted : https://old.reddit.com/r/selfhosted/comments/1hocrjm/powerdnsadmin_a_python_script_for_automating_the/?
- et le Discord de PowerDNS-Admin : https://discord.com/channels/1088963190693576784/1088963191574376601/1322661412882874418
Journal du samedi 28 décembre 2024 à 16:21
Je viens de tomber dans un Yak! 🙂.
Je cherchais des alternatives Open source à ngrok et j'ai trouvé sish (https://docs.ssi.sh/).
Côté client, sish utilise exclusivement ssh pour exposer des services (lien la documentation).
Voici comment exposer sur l'URL http://hereiam.tuns.sh le service HTTP exposé localement sur le port 8080 :
$ ssh -R hereiam:80:localhost:8080 tuns.sh
Je trouve cela très astucieux 👍️.
Après cela, j'ai commencé à étudier comment déployer sish et j'ai lu cette partie :
This includes taking care of SSL via Let's Encrypt for you. This uses the adferrand/dnsrobocert container to handle issuing wildcard certifications over DNS.
Après cela, j'ai étudié dnsrobocert qui permet de générer des certificats SSL Let's Encrypt avec la méthode DNS challenges, mais pour cela, il a besoin d'insérer et de modifier des DNS Record sur un serveur DNS.
Je n'ai pas envie de donner accès à l'intégralité de mes zones DNS à un script.
Pour éviter cela, j'ai dans un premier temps envisagé d'utiliser un serveur DNS managé de Scaleway, mais j'ai constaté que le provider Scaleway n'est pas supporté par Lexicon (qui est utilisé par dnsrobocert).
Après cela, j'ai décidé d'utiliser PowerDNS et je viens de publier ce playground : powerdns-playground.
Journal du dimanche 03 novembre 2024 à 18:58
Dans le blog de Richard Jones, j'ai découvert nbdkit.
nbdkit is an NBD server. NBD — Network Block Device — is a protocol for accessing Block Devices (hard disks and disk-like things) over a Network.
-- from
Journal du dimanche 03 novembre 2024 à 18:35
Dans le tutoriel "Proxmox Template with Cloud Image and Cloud Init", #JaiDécouvert un usage de la commande virt-customize :
# wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Je trouve cela extrêmement pratique, cela évite de devoir utiliser Packer pour personnaliser une image disque.
J'ai fait quelques recherches et j'ai appris que la fonctionnalité d'installation de package est ancienne, elle a été implémentée dans libguestfs en 2014 par Richard Jones, employé de chez Red Hat (auteur de libguestfs).
Journal du samedi 02 novembre 2024 à 23:36
#JaiDécouvert Harvester qui me semble être une alternative moderne à Proxmox, basé sur KubeVirt et Longhorn.
J'ai regardé la vidéo Kubevirt: Et si Kubernetes orchestrait vos VMs? (Mickael ROGER) qui m'a découragé d'utiliser KubeVirt.
AWS RDS playground et fixe du problème pg_dumpall
En 2019, j'ai rencontré un problème lors de l'exécution de pg_dumpall sur une base de données PostgreSQL hébergée sur AWS RDS. À l'époque, ce problème était "la goutte d'eau" qui m'avait empressé de migrer de RDS vers une instance PostgreSQL self hosted avec une simple image Docker dans un docker-compose.yml, mais je digresse, ce n'est pas le sujet de cette note.
Aujourd'hui, j'ai fait face à nouveau à ce problème, mais cette fois, j'ai décidé de prendre le temps pour bien comprendre le problème et d'essayer de le traiter.
Pour cela, j'ai implémenté et publié un playground nommé rds-playground.
Je peux le dire maintenant, j'ai trouvé une solution à mon problème 🙂.
Ce playground contient :
- Un exemple de déploiement d'une base de données AWS RDS avec Terraform.
- Un script qui permet d'importer avec succès la base de données AWS RDS vers une instance locale de PostgreSQL, en incluant les rôles.
Au départ, je pensais que le problème venait d'un problème de configuration des rôles du côté de AWS RDS ou alors que je n'utilisais pas le bon user. J'ai ensuite compris que c'était une fausse piste.
J'ai ensuite découvert ce billet : "Using pg_dumpall with AWS RDS Postgres".
For those interested, RDS Postgres (by design) doesn't allow you to read
pg_authid, which was earlier necessary for pg_dumpall to work.
J'ai compris que pour exécuter un pg_dumpall sur une instance RDS, il est impératif d'utiliser l'option --no-role-passwords.
Autre subtilité : sur une instance RDS, le rôle SUPERUSER est attribué au rôle rlsadmin, tandis que cette option est supprimé du rôle postgres.
ALTER ROLE postgres WITH NOSUPERUSER INHERIT CREATEROLE
CREATEDB LOGIN NOREPLICATION NOBYPASSRLS VALID UNTIL 'infinity';
Par conséquent, j'ai décidé d'utiliser le même nom d'utilisateur superuser pour l'instance locale PostgreSQL :
services:
postgres:
image: postgres:13.15
environment:
POSTGRES_USER: rdsadmin
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
...
Pour aller plus loin, je vous invite à suivre le README.md de rds-playground.
Journal du vendredi 18 octobre 2024 à 19:15
Nouvelle #iteration de Projet 14.
Pour traiter ce problème, je souhaite essayer de remplacer Vagrant Host Manager par vagrant-dns.
-- from
Résultat : j'ai migré de Vagrant Host Manager vers vagrant-dns avec succès 🙂.
Voici le commit : lien vers le commit.
Voici quelques explications de la configuration Vagrantfile.
Les lignes suivantes permettent d'utiliser la seconde IP des machines virtuelles pour les identifier (renseignés par le serveur DNS).
config.dns.ip = -> (vm, opts) do
ip = nil
vm.communicate.execute("hostname -I | cut -d ' ' -f 2") do |type, data|
ip = data.strip if type == :stdout
end
ip
end
La commande hostname retourne les deux IP de la machine virtuelle :
vagrant@server1:~$ hostname -I
10.0.2.15 192.168.56.22
La commande hostname -I | cut -d ' ' -f 2 capture la seconde IP, ici 192.168.56.22.
La configuration DNS qui retourne cette IP est consultable via :
$ vagrant dns -l
/server1.vagrant.test/ => 192.168.56.22
/server2.vagrant.test/ => 192.168.56.23
/grafana.vagrant.test/ => 192.168.56.23
/loki.vagrant.test/ => 192.168.56.23
vb.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
Cette ligne configure la machine virtuelle pour qu'elle utilise le serveur DNS de vagrant-dns.
Cela permet de résoudre les noms des autres machines virtuelles. Exemple :
vagrant@server1:~$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23 -- link: eth0
-- Information acquired via protocol DNS in 12.3ms.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
En mettant en place vagrant-dns sur ma workstation qui tourne sous Fedora, j'ai rencontré la difficulté suivante.
J'avais la configuration suivante installée :
$ cat /etc/systemd/resolved.conf.d/csd.conf
[Resolve]
DNS=10.57.40.1
Domains=~csd
Elle me permet de résoudre les hostnames des machines qui appartiennent à un réseau privé exposé via OpenVPN (voir cette note).
Voici ma configuration complète de systemd-resolved :
$ systemd-analyze cat-config systemd/resolved.conf
# /etc/systemd/resolved.conf
...
[Resolve]
...
# /etc/systemd/resolved.conf.d/1-vagrant-dns.conf
# This file is generated by vagrant-dns
[Resolve]
DNS=127.0.0.1:5300
Domains=~test
# /etc/systemd/resolved.conf.d/csd.conf
[Resolve]
DNS=10.57.40.1
Domains=~csd
Quand je lançais resolvectl query server2.vagrant.test pour la première fois après redémarrage de sudo systemctl restart systemd-resolved, tout fonctionnait correctement :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 7.5073s.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
Mais, la seconde fois, j'avais l'erreur suivante :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: Name 'server2.vagrant.test' not found
Ce problème disparait si je supprime /etc/systemd/resolved.conf.d/csd.conf.
Je n'ai pas compris pourquoi. D'après la section "Protocols and routing" de systemd-resolved, le serveur 10.57.40.1 est utilisé seulement pour les hostnames qui se terminent par .csd.
J'ai activé les logs de systemd-resolved au niveau debug avec
$ sudo resolvectl log-level debug
$ journalctl -u systemd-resolved -f
Voici le contenu des logs lors de la première exécution de resolvectl query server2.vagrant.test : https://gist.github.com/stephane-klein/506a9fc7d740dc4892e88bfc590bee98.
Voici le contenu des logs lors de la seconde exécution de resolvectl query server2.vagrant.test : https://gist.github.com/stephane-klein/956befc280ef9738bfe48cdf7f5ef930.
J'ai l'impression que la ligne 13 indique que le cache de systemd-resolved a été utilisé et qu'il n'a pas trouvé de réponse pour server2.vagrant.test. Pourquoi ? Je ne sais pas.
Ligne 13 : NXDOMAIN cache hit for server2.vagrant.test IN A
Ensuite, je supprime /etc/systemd/resolved.conf.d/csd.conf :
$ sudo rm /etc/systemd/resolved.conf.d/csd.conf
Je relance systemd-resolved et voici le contenu des logs lors de la seconde exécution de resolvectl query server2.vagrant.test : https://gist.github.com/stephane-klein/9f87050524048ecf9766f9c97b789123#file-systemd-resolved-log-L11
Je constate que cette fois, la ligne 11 contient : Cache miss for server2.vagrant.test IN A.
Pourquoi avec .csd le cache retourne NXDOMAIN et sans .csd, le cache retourne Cache miss et systemd-resolved continue son algorithme de résosultion du hostname ?
Je soupçonne systemd-resolved de stocker en cache la résolution de server2.vagrant.test par le serveur DNS 10.57.40.1. Si c'est le cas, je me demande pourquoi il fait cela alors qu'il est configuré pour les hostnames qui se terminent par .csd 🤔.
Autre problème rencontré, la latence de réponse :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 7.5073s.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
La réponse est retournée en 7 secondes, ce qui ne me semble pas normal.
J'ai découvert que je n'ai plus aucune latence si je passe le paramètre DNSStubListener à no :
$ sudo cat <<EOF > /etc/systemd/resolved.conf.d/0-vagrant-dns.conf
[Resolve]
DNSStubListener=no
EOF
$ sudo systemctl restart systemd-resolved
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 2.9ms.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
Le temps de réponse passe de 7.5s à 2.9ms. Je n'ai pas compris la signification de ma modification.
Je récapitule, pour faire fonctionner correctement vagrant-dns sur ma workstation Fedora j'ai dû :
- supprimer
/etc/systemd/resolved.conf.d/csd.conf - et paramétrer
DNSStubListeneràno
Migration de vagrant-hostmanager vers vagrant-dns
Dans le cadre du Projet 14 - Script de base d'installation d'un serveur Ubuntu LTS, j'utilise Vagrant avec le plugin Vagrant Host Manager pour gérer les hostnames des machines virtuelles.
Vagrant Host Manager met correctement à jour les fichiers /etc/hosts sur ma machine hôte, c'est-à-dire, ma workstation, et dans les machines virtuels.
Cependant, ces noms d'hôtes ne sont pas accessibles à l'intérieur des containers Docker.
Par exemple, ici, http://grafana.example.com:3100/ n'est pas accessible à l'intérieur du container Promtail.
Pour traiter ce problème, je souhaite essayer de remplacer Vagrant Host Manager par vagrant-dns.
vagrant-dns semble exposer un serveur DNS qui sera accessible et utilisé par les containers Docker.
D'autre part, vagrant-dns (page contributors) semble un peu plus actif que Vagrant Host Manager (page contributors).
Journal du lundi 14 octobre 2024 à 18:27
#JaiDécouvert le site Formation DevOps | DevSecOps de Stéphane Robert. Énormément d'informations très bien catégorisées et en français !
J'ai parcouru la section Analyser le code ! et j'y ai découvert :
Alexandre m'a partagé l'article "Linux : Enregistrer toutes les commandes saisies avec auditd" qui présente Linux Audit.
The Linux audit framework provides a CAPP-compliant (Controlled Access Protection Profile) auditing system that reliably collects information about any security-relevant (or non-security-relevant) event on a system. It can help you track actions performed on a system.
-- from
La norme de sécurité de l'industrie des cartes de paiement (Payment Card Industry Data Security Standard ou PCI DSS) est un standard destiné à poser les normes de la sécurité des systèmes d'information amenés à traiter et stocker des process ou des informations relatives aux systèmes de paiement.
Dans ce cadre, de nombreuses conditions sont à respecter afin d'être compatible avec cette norme. Parmi celles-ci, l'enregistrement des commandes et instructions saisies par les utilisateurs à privilèges sur un système.
-- from
D'après ce que j'ai compris, la fonctionnalité Linux Audit est implémentée au niveau du kernel.
Linux Audit permet de surveiller les actions effectuées sur les fichiers (lecture, écriture…) et les appels syscalls.
D'après ce que je comprends, Linux Audit est conçu à des fins de sécurité. Il semble peu adapté pour documenter les opérations réalisées sur un serveur dans le cadre d'un travail collaboratif.
Journal du mardi 10 septembre 2024 à 13:20
#JaiDécouvert l'option "append-only" mode de restic.
#JaiDécouvert rustic, un clone de restic implémenté en Rust (from).
Journal du mardi 10 septembre 2024 à 12:48
#JaiLu L'option ControlMaster de ssh_config.
J'y ai découvert l'open ControlMaster de OpenSSH.
Journal du lundi 09 septembre 2024 à 15:59
Dans cette note, je souhaite présenter ma doctrine de mise à jour d'OS de serveurs.
Je ne traiterai pas ici de la stratégie d'upgrade pour un Cluster Kubernetes.
La mise à jour d'un serveur, par exemple, sous un OS Ubuntu LTS, peut être effectuée avec les commandes suivantes :
sudo apt upgrade -y- ou
sudo apt dist-upgrade -y(plus risqué) - ou
sudo do-release-upgrade(encore plus risqué)
L'exécution d'un sudo apt upgrade -y peut :
- Installer une mise à jour de docker, entraînant une interruption des services sur ce serveur de quelques secondes à quelques minutes.
- Installer une mise à jour de sécurité du kernel, nécessitant alors un redémarrage du serveur, ce qui entraînera une coupure de quelques minutes.
Une montée de version de l'OS via sudo do-release-upgrade peut prendre encore plus de temps et impliquer des ajustements supplémentaires.
Bien que ces opérations se déroulent généralement sans encombre, il n'y a jamais de certitude totale, comme l'illustre l'exemple de la Panne informatique mondiale de juillet 2024.
Sachant cela, avant d'effectuer la mise à jour d'un serveur, j'essaie de déterminer quelles seraient les conséquences d'une coupure d'une journée de ce serveur.
Si je considère que ce risque de coupure est inacceptable ou ne serait pas accepté, j'applique alors la méthode suivante pour réaliser mon upgrade.
Je n'effectue pas la mise à jour le serveur existant. À la place, je déploie un nouveau serveur en utilisant mes scripts automatisés d'Infrastructure as code / GitOps.
C'est pourquoi je préfère éviter de nommer les serveurs d'après le service spécifique qu'ils hébergent (voir aussi Pets vs Cattle). Par exemple, au lieu de nommer un serveur gitlab.servers.example.com, je vais le nommer server1.servers.example.com et configurer gitlab.servers.example.com pour pointer vers server1.servers.example.com.
Ainsi, en cas de mise à jour de server1.servers.example.com, je crée un nouveau serveur nommé server(n+1).servers.example.com.
Ensuite, je lance les scripts de déploiement des services qui étaient présents sur server1.servers.example.com.
Idéalement, j'utilise mes scripts de restauration des données depuis les sauvegardes des services de server1.servers.example.com, ce qui me permet de vérifier leur bon fonctionnement.
Ensuite, je prépare des scripts rsync pour synchroniser rapidement les volumes entre server1.servers.example.com et server(n+1).servers.example.com.
Je teste que tout fonctionne bien sur server(n+1).servers.example.com.
Si tout fonctionne correctement, alors :
- J'arrête les services sur
server(n+1).servers.example.com; - J'exécute le script de synchronisation
rsyncdeserver1.servers.example.comversserver(n+1).servers.example.com; - Je relance les services sur
server(n+1).servers.example.com - Je modifie la configuration DNS pour faire pointer les services de
server1.servers.example.comversserver(n+1).servers.example.com - Quelques jours après cette intervention, je décommissionne
server1.servers.example.com.
Cette méthode est plus longue et plus complexe qu'une mise à jour directe de l'OS sur le server1.servers.example.com, mais elle présente plusieurs avantages :
- Une grande sécurité ;
- L'opération peut être faite tranquillement, sans stress, avec de la qualité ;
- Une durée de coupure limitée et maîtrisée ;
- La possibilité de confier la tâche en toute sécurité à un nouveau DevOps ;
- La garantie du bon fonctionnement des scripts de déploiement automatisé ;
- La vérification de l'efficacité des scripts de restauration des sauvegardes ;
- Un test concret des scripts et de la documentation du Plan de reprise d'activité.
Si le serveur à mettre à jour fonctionne sur une Virtual instance, il est également possible de cloner la VM et de tester la mise à niveau. Cependant, je préfère éviter cette méthode, car elle ne permet pas de valider l'efficacité des scripts de déploiement.
Journal du samedi 07 septembre 2024 à 19:32
#JeMeDemande souvent comment nommer la méthode permettant d'installer des applications de manière scriptée.
Lorsque je recherche cette fonctionnalité, j'utilise généralement les mots-clés : "headless", "script", "cli".
Je constate que la roadmap de Proxmox utilise le terme « automated and unattended installation » :
Support for automated and unattended installation of Proxmox VE.
-- from
#JaiPublié cette question dans la section discussion du projet Plausible : Plausible automated and unattended installation support (create user and web site by script) · plausible/analytics.
Journal du mercredi 04 septembre 2024 à 11:11
#JaiLu la page Wikipedia de Teleport.
Je pense que cela fait plus de 5 ans que #JeSouhaiteTester cet outil.
Journal du mardi 27 août 2024 à 14:23
#JaiLu en partie le thread Hacker News Dokku: My favorite personal serverless platform.
- https://github.com/skateco/skate
- dokploy
- kamal
- ptah.sh (sous licence fair source)
J'ai apprécié ce tableau de comparaison de fonctionnalités entre dokploy, CapRover, Dokku et Coolify.
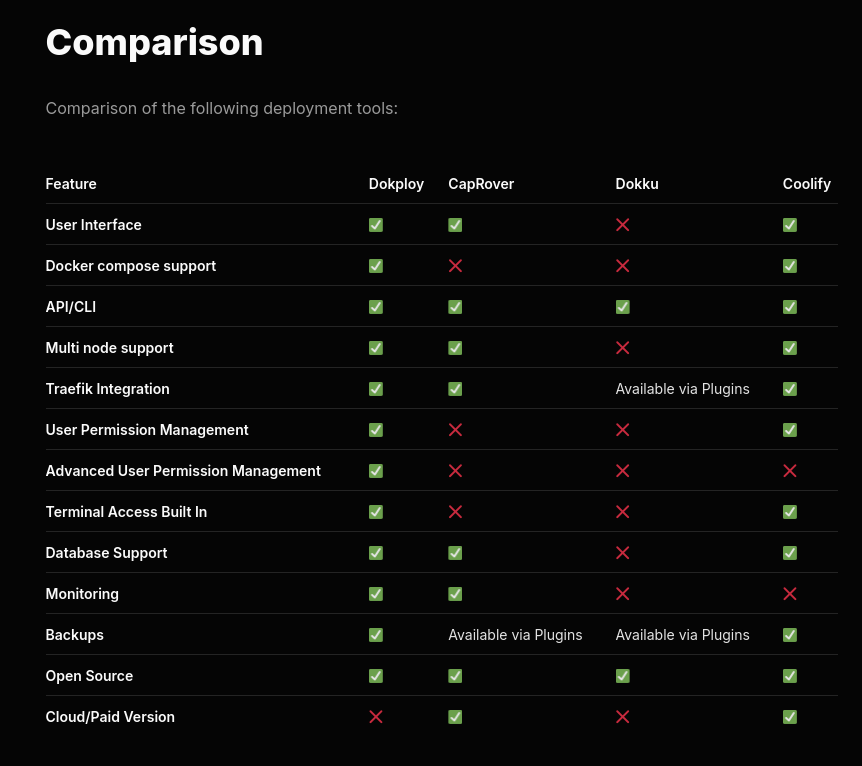
C'est la ligne "Docker compose support" qui a attiré mon attention.
Je reste très attaché au support de docker compose qui je trouve est une spécification en même temps simple, complète et flexible qui ne m'a jamais déçu ces 9 dernières années.
Attention, je n'ai pas bien compris si Dokku est réellement open source ou non 🤔.
Je constate que Dokploy est basé sur Docker Swarm.
Dokploy leverages Docker Swarm to orchestrate and manage container deployments for your applications, providing an intuitive interface for monitoring and control.
-- from
Choix qui me paraît surprenant puisque Docker Swarm est officieusement déprécié.
Je me suis demandé si K3s pourrait être une alternative à Docker Swarm 🤔.
Journal du dimanche 28 juillet 2024 à 09:43
Je viens d'apprendre que l'option -N de ssh permet de ne pas ouvrir une session shell interactive sur le serveur distant.
Option très utile lors de l'ouverture de tunnels ssh.
Exemple :
ssh -L 8080:localhost:80 user@host -N
Commandes valables sous Fedora mais aussi plus généralement sous Linux.
Affiche la configuration DNS actuelle :
$ resolvectl status
Global
Protocols: LLMNR=resolve -mDNS -DNSOverTLS DNSSEC=no/unsupported
resolv.conf mode: stub
Current DNS Server: 127.0.0.1:5300
DNS Servers: 127.0.0.1:5300
DNS Domain: ~test
Link 2 (wlp1s0)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
Protocols: +DefaultRoute LLMNR=resolve -mDNS -DNSOverTLS DNSSEC=no/unsupported
Current DNS Server: 192.168.31.1
DNS Servers: 192.168.31.1
Intéroge directement un serveur DNS :
$ dig @127.0.0.1 -p 5300 server2.vagrant.test +short
192.168.56.21
Résolution d'un hostname avec resolvectl :
$ resolvectl query server2.vagrant.test
server2.vagrant.test: 192.168.56.23
-- Information acquired via protocol DNS in 4.2ms.
-- Data is authenticated: no; Data was acquired via local or encrypted transport: no
-- Data from: network
La commande suivante affiche toutes la configuration de resolved.conf :
$ systemd-analyze cat-config systemd/resolved.conf
Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker"
Date de la création de cette note : 2024-06-05.
Ce projet est terminé : voir 2024-07-06_1116.
Quel est l'objectif de ce projet ?
Bien que j'aie beaucoup travaillé de décembre 2023 janvier 2024 sur le projet Implémenter un POC de pgBackRest, je souhaite mettre à jour et améliorer le repository restic-pg_dump-docker.
Quelques tâches à réaliser :
- [x] Mettre à jour tous les composants ;
- [x] Publier le
Dockerfiledestephaneklein/restic-backup-docker; - [ ] Réaliser et publier un screencast ;
- [x] Améliorer le
README.md.
Pourquoi je souhaite réaliser ce projet ?
Pourquoi continuer ce projet alors que j'ai travaillé sur pgBackRest qui semble bien mieux ?
Pour plusieurs raisons :
- Je ne peux pas installer pgBackRest dans un « sidecar container Docker » — en tout cas, je n'ai pas trouvé comment réaliser cela 🤷♂️. Je dois utiliser un container Docker PostgreSQL qui intègre pgBackRest.
- Pour le moment, je ne comprends pas très bien la taille consommée par les "WAL segments" sauvegardés dans les buckets.
- Pour le moment, je ne sais pas combien de temps prend la restauration d'un backup d'une base de données d'une taille supérieure à un test. Par exemple, combien de temps prend la restauration d'une base de données de 100 Mo 🤔.
- Je ne suis pas rassuré de devoir lancer un cron —
supercronic— lancé partini
Bien que pgBackRest permette un backup en temps "réel" et est sans doute plus rapide que "ma" méthode "restic-pg_dump", pour toutes les raisons listée ci-dessus, je pense que la méthode "restic-pg_dump" est moins complexe à mettre en place et à utiliser.
#JeMeDemande si la fonctionnalité "incremental backups" la version 17 de PostgreSQL sera une solution plus pratique que pgBackRest et la méthode "restic-pg_dump" 🤔.
Repository de ce projet :
https://github.com/stephane-klein/restic-pg_dump-docker
Je vais travailler dans la branche nommée june-2024-working-session
Projet 14 - Script de base d'installation d'un serveur Ubuntu LTS
Date de création de cette note : 2024-10-11.
Quel est l'objectif de ce projet ?
Je souhaite implémenter et publier un projet de "référence", de type skeleton, dont la fonction est d'installer les éléments de base d'un serveur Ubuntu LTS sécurisé.
Comme point de départ, je peux utiliser mon repository poc-bash-ssh-docker-deployement-example et le faire évoluer.
Le script _install_basic_server_configuration.sh se contente d'installer Docker.
J'aimerais y intégrer les recommandations présentes dans l'excellent article "Securing A Linux Server".
J'aimerais, entre autres, ajouter les fonctionnalités suivantes :
- [x] Amélioration de la configuration de OpenSSH ;
- [x] Installation et configuration de ufw ;
- [x] Mise en place de ipsum ;
- [x] Installation et configuration de fail2ban ;
- [x] Système d'installation / suppression de clés ssh ;
- [x] En option : installation et configuration de node exporter ;
- [x] En option : installation et configuration de l'envoi des logs de journald et Docker vers Loki en utilisatant Promtail (
installation et configuration de l'envoi des logs de journald vers Loki en utilisant Vector) ; - [x] En option : installation de configuration de Grafana ; avec Grizzly configuration des dashboards
- [x] des logs et
- [x] metrics des serveurs
- [x] En option : installer et configurer apticron pour envoyer un message dans les logs dès qu'un package de sécurité doit être installé.
- [x] Génération d'une alerte Grafana si une mise à jour de sécurité doit être installé
- [x] En option : envoie de notification sur smartphone en cas d'alerte Grafana, via ntfy
- [ ] En option : installation et configuration de Linux Audit ;
Le repository doit présenter cette installation :
- [x] via Vagrant
- [ ] sur un Virtual machine Scaleway avec Terraform
Repository de ce projet :
Ressources :
Projet 12 - "Implémentation nodemailer-scaleway-transport"
Date de la création de cette note : 2024-07-30.
Quel est l'objectif de ce projet ?
Implémenter et publier un plugin Nodemailer de transport pour l'API HTTP Transactional Email de Scaleway.
Pourquoi je souhaite réaliser ce projet ?
Les ports SMTP des instances computes de Scaleway sont par défaut fermés. Pour contourner cette contrainte, il est nécessaire d'effectuer une demande au support pour les ouvrir.
Partant de ce constat, #JaiDécidé d'utiliser le protocole HTTP autant que possible pour envoyer des e-mails.
Problème : je n'ai pas trouvé de plugin de transport Nodemailer pour Scaleway, ce qui a motivé la création de ce projet.
Repository de ce projet :
https://github.com/stephane-klein/nodemailer-scaleway-transport (non publié au moment de la rédaction de cette note)
Ressources :
🚀 10x easier, 🚀 140x lower storage cost, 🚀 high performance, 🚀 petabyte scale - Elasticsearch / Splunk / Datadog alternative for 🚀 (logs, metrics, traces, RUM, Error tracking, Session replay).
Dépôt GitHub : https://github.com/openobserve/openobserve.
openITCOCKPIT is an Open Source system monitoring tool built for different monitoring engines like Nagios, Naemon and Prometheus.
Dépôt GitHub : https://github.com/it-novum/openITCOCKPIT
Vous êtes sur la première page | [ Page suivante (9) >> ]