
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (18 notes) :
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
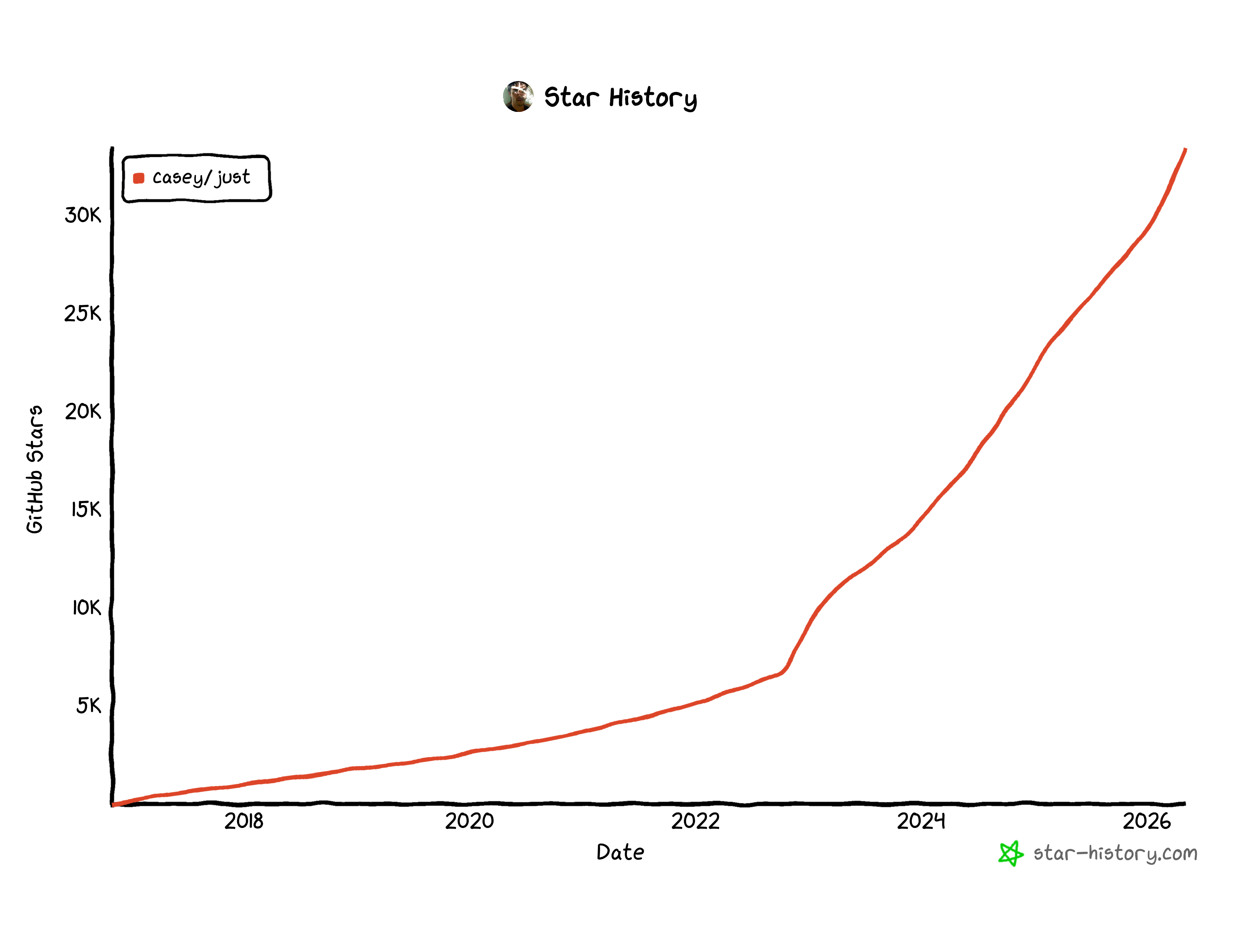
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
Collecter les sujets dans un issue tracker pour ne pas se répéter
En essayant de répondre à une question d'un ami au sujet du chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp, j'ai cherché à mettre des mots sur les raisons qui me poussent à utiliser un issue tracker, une pratique que j'expérimente depuis plus de 15 ans. Cette note est le résultat de cette réflexion.
Pendant 5 ans, de 2018 à 2023, j'ai utilisé GitLab comme outil de issue tracker, en équipe, dans deux organisations différentes.
Avant d'aller plus loin, il me semble utile de montrer concrètement les types d'issue présentes dans ces trackers (voir aussi ces labels) :
- Bug — corriger un comportement qui ne correspond pas à ce qui est attendu
- Feature — implémenter une nouvelle fonctionnalité
- Enhancement — améliorer une capacité existante ; DoD : le comportement amélioré est mesurable ou observable
- Knowledge Gap — répondre à une question sans réponse accessible ; DoD : répondre à la question, indiquer comment trouver la réponse à cette question, si l'information n'était pas documentée, alors la documenter ou améliorer la documentation existante
- Spike — explorer une question technique ou une hypothèse incertaine dans un temps imparti ; DoD : du code est livré, une décision binaire est posée (concluante / non concluante) et documentée dans l'issue
- Enabler — préparer le terrain technique pour qu'une ou plusieurs issues futures soient implémentables en moins de 10h ; DoD : mergé sur main sans régression, les issues qu'il débloque sont identifiées
- User story développeur — exprimer un besoin d'infrastructure ou d'outillage interne sous forme de user story dont le "user" est un développeur ; DoD : code produit, environnement de développement amélioré, documentation ajoutée, etc.
- meta-spec-writing — décomposer un périmètre flou en issues actionnables ; DoD : les issues enfants sont créées, estimées et prêtes pour le sprint planning
- Sprint planning — préparer et documenter une session de sprint planning ; DoD : date, participants et issues candidates documentés avant la réunion, décisions prises et issues assignées documentées après
- Sprint retrospective — préparer et documenter une session de rétrospective ; DoD : date et sujets à aborder documentés avant la réunion, décisions et actions correctives documentées après, chaque action corrective génère une issue de suivi
Pourquoi je crée systématiquement une issue ?
Mon approche consiste à créer une issue dès qu'une idée, un bug ou un sujet émerge — même sans intention de le traiter immédiatement.
C'est un point qui me tient à cœur, parce qu'il m'agace profondément de voir les mêmes sujets resurgir sans cesse sans jamais être vraiment travaillés.
J'ai souvent observé dans les open spaces des conversations de 10-20 minutes autour d'un sujet où chacun y va de son opinion, de son intuition, de ses mises en garde et de ses objections, puis retourne à ses activités… pour recommencer le même débat deux jours plus tard. Tout ce qui a été dit est perdu et rarement approfondi.
Ces "conversations de couloir" récurrentes sont un symptôme classique de non-décision : personne ne bloque explicitement, personne n'avance vraiment — la discussion tourne en boucle, invisible et non tracée. Dans certains cas, elles dégénèrent en Stop Energy : les mêmes objections ressurgissent à chaque fois, épuisant le porteur de l'idée sans jamais produire de résolution.
Je préfère de loin créer l'issue avant toute conversation. À défaut, quand j'assiste à une discussion informelle qui tourne en rond, je la crée à chaud, y dépose les idées échangées, et la partage aux participants pour vérifier que j'ai bien retranscrit. La prochaine fois que le sujet resurgit, j'invite chacun à la lire et ajouter son commentaire ou voter "+1".
L'issue devient un espace formel où chacun peut argumenter et enrichir le fil à son rythme ; le Sprint Planning devient le moment de délibération légitime où l'équipe arbitre collectivement si l'issue doit être traitée dans le nouveau sprint ou non.
Cette rigueur n'est pas simple à tenir : quand l'équipe a l'habitude de tout régler à l'oral, créer une issue peut passer pour de la lourdeur bureaucratique. Je la tiens malgré tout, parce que le coût de la répétition me paraît plus élevé que celui du traçage. Surtout, à long terme, cela évite le brouillard organisationnel.
Cette utilisation d'un issue tracker s'inspire du monde du logiciel libre, où des issues peuvent rester ouvertes des années, voire des décennies, et servent de mémoire collective pour comprendre la complexité d'une demande, les trade-offs, les ressources disponibles.
Quand cette méthode est appliquée pendant plusieurs années dans une organisation, un issue tracker peut contenir des centaines voire des milliers d'issues ouvertes, mais ceci ne pose pas de problème car ces issues ne constituent pas un backlog.
Un backlog est une liste d'items extraits et sélectionnés de l'ensemble des issues de l'issue tracker — un sous-ensemble volontairement restreint et de meilleure qualité. Priorisée, maintenue à jour et régulièrement affiné, cette liste représente le travail potentiel sérieusement envisagé pour le produit. Lors du Sprint Planning, les parties prenantes — développeurs, produit et autres contributeurs concernés — discutent et arbitrent ensemble les priorités pour décider quels items intégreront le Sprint Backlog.
De 2000 à 2016, j'ai essentiellement déployé la distribution Linux Debian sur mes serveurs et après cette date des Ubuntu LTS.
Depuis 2022, j'utilise une Fedora sur ma workstation. Distribution que je maitrise et que j'apprécie de plus en plus.
J'envisage peut-être d'utiliser une distribution de la famille Fedora sur mes serveurs personnels.
J'avais suivi de loin les événements autour de CentOS en décembre 2020 :
- 8 décembre 2020 : CentOS Project shifts focus to CentOS Stream
- 16 décembre 2020 : Rocky Linux: A CentOS replacement by the CentOS founder
J'ai enfin compris l'origine du nom Rocky Linux :
"Thinking back to early CentOS days... My cofounder was Rocky McGaugh. He is no longer with us, so as a H/T to him, who never got to see the success that CentOS came to be, I introduce to you...Rocky Linux"
J'aime beaucoup cet hommage 🤗 !
J'ai étudié AlmaLinux et il me semble que cette distribution est principalement développée par l'entreprise CloudLinux, une entreprise à but lucratif qui vend du support Linux.
Personnellement, je trouve le positionnement d'AlmaLinux peu "fair-play" envers Red Hat : Red Hat investit massivement dans le développement de Red Hat Enterprise Linux et AlmaLinux récupère ce travail gratuitement pour ensuite vendre du support commercial en concurrence directe.
À mon avis, si une entreprise souhaite un vrai support sur une distribution de la famille Red Hat, elle devrait se tourner vers Red Hat Enterprise Linux et acheter du support directement à Red Hat plutôt qu'à CloudLinux.
Suite à ce constat, j'ai décidé d'utiliser Rocky Linux plutôt qu'AlmaLinux.
21h30 : j'ai reçu le message suivant sur Mastodon :
@stephane_klein you have things quite backwards. AlmaLinux is a non-profit foundation while Rocky is owned 100% by Greg kurtzer and they have over $100M in venture capital funding.
AlmaLinux has a community-elected board.
Suite à ce message, j'ai essayé d'en savoir plus, mais il est difficile d'y voir clair.
Par exemple : I’m confused about the different organizational structure when it comes to Rocky and Alma.
La page "AlmaLinux OS Foundation " que j'ai consultée m'a particulièrement plu.
J'ai révisé ma position, j'ai décidé d'utiliser AlmaLinux plutôt que Rocky Linux.
2025-12-02 : j'ai révisé ma position, pour des serveurs de production, j'ai décidé d'utiliser la version stable de CoreOS, plutôt que AlmaLinux ou Rocky Linux.
Depuis un an, j'ai pris conscience d'une difficulté inhérente aux organisations qui suivent le paradigme Multirepos, difficulté dont je ne m'étais pas rendu compte auparavant : décider où publier ses issues !
J'ai observé que dès qu'une organisation commence à utiliser plusieurs repositories, la question de l'endroit où créer de nouvelles issues se pose. Par exemple :
- Où poster une issue d'amélioration qui nécessite des changements dans le repository A et B ?
- Où créer une issue d'une proposition d'un process qui ne concerne pas spécifiquement le code source d'un projet hébergé dans un repository ?
- Où créer une issue dont le but est de créer un nouveau service ?
Quand une organisation suit le paradigme Monorepo avec issues colocalisées et utilise, comme je l'explique dans la note "Nom et arborescence de Monorepo" un nom non spécifique, alors la question de l'endroit où publier ses issues ne se pose pas ! Il suffit de publier l'issue dans le Monorepo (par exemple sur GitHub, GitLab ou Forgejo).
Le gestionnaire d'issue du Monorepo est un point de schelling, c'est-à-dire un endroit où tous les développeurs convergent naturellement en l'absence de communication explicite pour trouver et créer des issues.
Ce paradigme évite des débats à propos de l'endroit où publier les issues.
Journal du samedi 22 mars 2025 à 10:58
Voici quelques principes qui me guident. Je pense qu'ils contribuent à rendre une organisation efficace et efficiente.
1. La loi empirique de Gall :
« Un système complexe qui fonctionne se trouve invariablement avoir évolué depuis un système simple qui fonctionnait.
La proposition inverse se révèle également exacte : Un système complexe développé de A à Z ne fonctionne jamais et vous n'arriverez jamais à le faire fonctionner. Vous devez recommencer depuis le début, en commençant par un système simple. »
2. Je suis convaincu de la pertinence du modèle de Tuckman pour comprendre comment les équipes se construisent et évoluent au fil du temps.
En conséquence, je crois qu'une organisation doit accorder suffisamment de temps aux équipes pour qu'elles atteignent leur phase de performance, puis veiller à maintenir la composition de l'équipe sur la durée.
3. Le modèle du triangle de gestion de projet qui je trouve est très bien expliqué dans le livre Getting Real :
Voici un moyen simple de lancer le projet dans les délais et le budget impartis : ne pas les modifier. Il ne faut jamais consacrer plus de temps ou d'argent à un problème, mais simplement en réduire la taille (le périmètre).
Il existe un mythe qui dit que l'on peut lancer un projet dans les délais, en respectant le budget et le champ d'application. Cela n'arrive presque jamais et, lorsque c'est le cas, la qualité s'en ressent souvent.
Si vous ne pouvez pas tout faire tenir dans le temps et le budget impartis, n'augmentez pas le temps et le budget. Au contraire, réduisez le champ d'application. Il sera toujours temps d'ajouter des choses plus tard - plus tard est éternel, maintenant est éphémère.
Il vaut mieux lancer quelque chose d'excellent dont la portée est un peu plus réduite que prévu que de lancer quelque chose de médiocre et plein de trous parce qu'il fallait respecter une fenêtre magique de temps, de budget et de portée. Laissez la magie à Houdini. Vous avez une véritable entreprise à gérer et un véritable produit à livrer.
Un ami m'a partagé le projet Beszel (https://beszel.dev/).
Beszel is a lightweight server monitoring platform that includes Docker statistics, historical data, and alert functions.
It has a friendly web interface, simple configuration, and is ready to use out of the box. It supports automatic backup, multi-user, OAuth authentication, and API access.
Beszel est codé en Golang, il est très récent, il a commencé en été 2024, c'est sans doute pour cela que je ne l'avais jamais croisé.
De prime abord, j'ai pensé que Beszel était un outil de Status / Uptime pages comme Uptime Kuma ou Gatus, mais ce n'est pas le cas.
Je qualifierai plutôt Beszel d'alternative "plug and play" de Prometheus + Grafana + node_exporter + cAdvisor.
Alors que l'annonce de Beszel a fait "choux blanc" sur Hacker News « Beszel: Lightweight server resource monitoring with history, Docker stats,alerts », le projet a suscité plus de réaction — 270 commentaires — sur Subreddit SelfHosted : « I just released Beszel, a server monitoring hub with historical data, docker stats, and alerts. It's a lighter and simpler alternative to Grafana + Prometheus or Checkmk. Any feedback is appreciated! ».
Les retours sont très positifs 🙂 :
« There is beauty in simplicity. Very nice little application! »
« Kiss »
« Just installed on all of my servers, gorgeous project, simple but also not simple. »
« Awesome work. I think you identified a good use case for the self hosting community, a simple server monitor running as a simple service. I will give it a go soon! »
« I never installed Grafana and Prometheus because it’s overkill for my little server.. but this looks really good! I’ll give it a go »
Prometheus propose bien plus d'exporter que Beszel, mais je pense que Beszel est un bon point de départ pour une stack de monitoring minimaliste.
À l'avenir, mon choix par défaut en matière monitoring sera probablement un couple Beszel + Gatus. Si des besoins plus avancés émergent, comme du monitoring poussé de PostgreSQL, Redis ou d'autres services, j'envisagerai alors de commencer la mise en place du couple Prometheus + Grafana.
Journal du mardi 25 février 2025 à 09:35
Dans cette note, je souhaite décrire et expliquer comment j'intègre des sessions de terminal dans des documentations.
Convention mainstream que j'ai adoptée
Je suis la convention mainstream suivante pour représenter des sessions terminal (de type bash, zsh…) au format Markdown :
Première partie :
$ echo "Hello, world!" Hello, world! $ ls -l total 0 -rw-r--r-- 1 user user 0 Feb 25 10:00 file.txtSeconde partie :
$ sudo su # systemctl restart nginx $ exit $ uptime # Affiche l'uptime uptime 10:00:00 up 1 day, 2:45, 1 user, load average: 0.15, 0.10, 0.05
Les lignes commençant par $ ou # indiquent les commandes saisies par l'utilisateur, tandis que les autres correspondent aux sorties du terminal.
Il m'arrive également d'ajouter des commentaires en fin de ligne à l'aide de # ….
Origine de cette convention ?
J'ai cherché à retracer l'origine de cette pratique et elle semble très ancienne, probablement adoptée dès les débuts d'Unix en 1971.
On retrouve cette syntaxe notamment dans le livre The Unix Programming Environment (pdf), publié en 1984.
Ne pas inclure de $ si un bloc ne contient aucune sortie de commande
La règle MD014 de Markdownlint aborde ce sujet :
MD014 - Dollar signs used before commands without showing output
Tags: code
Aliases: commands-show-output
This rule is triggered when there are code blocks showing shell commands to be typed, and the shell commands are preceded by dollar signs ($):
$ ls $ cat foo $ less barThe dollar signs are unnecessary in the above situation, and should not be included:
ls cat foo less barHowever, an exception is made when there is a need to distinguish between typed commands and command output, as in the following example:
$ ls foo bar $ cat foo Hello world $ cat bar bazRationale: it is easier to copy and paste and less noisy if the dollar signs are omitted when they are not needed. See https://cirosantilli.com/markdown-style-guide#dollar-signs-in-shell-code for more information.
Pendant un certain temps, j’ai suivi la recommandation de ne pas inclure de $ dans un bloc de commande lorsqu’il n’affiche aucune sortie.
Après quelques années, j’ai décidé de ne plus appliquer cette règle pour la raison suivante :
- Lorsque la documentation mélange des fichiers de configuration et des commandes sans
$, j’ai du mal à distinguer ce qui doit être exécuté dans un terminal et ce qui relève de la configuration.
Pour éviter toute ambiguïté, j’ai adopté une approche radicale : toujours utiliser $ pour indiquer une commande à exécuter, même si le bloc ne contient pas de sortie.
Je n'aime pas les $ dans les blocs de commande, car que je ne peux pas copier / coller facilement !
Je comprends tout à fait cette remarque. Cependant, ces "screenshots" de session de terminal n'ont pas vocation à être copiées / collées en masse.
Ils ont avant tout une fonction explicative.
Ce sont des sortes de "screenshot".
Si j'éprouve le besoin de faire souvent des "copier / coller" d'exemples de session terminal, alors je considère que c'est le signe qu'un script "helper" serait plus approprié pour exécuter ce groupe de commandes d’un seul coup.
Par exemple, je peux remplacer ce contenu :
Ensure that the following prerequisites have been installed: mise and direnv, see instruction in ../README.md.
$ mise trust $ mise install $ scw version Version 2.34.0
Par celui-ci (qui indique l'existence du script ./scripts/mise-install.sh) :
Ensure that the following prerequisites have been installed: mise and direnv, see instruction in ../README.md (or execute
./scripts/mise-install.sh).$ mise trust $ mise install $ scw version Version 2.34.0
Cela évite les copier-coller répétitifs tout en conservant la clarté de l’explication.
Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh
Cette note est aussi disponible au format vidéo : https://www.youtube.com/watch?v=J9jsd4m9YkQ.
De 2018 à 2023, j'utilisais l'outil "pass" (https://www.passwordstore.org/) couplé avec GNU Privacy Guard pour chiffrer et déchiffrer les secrets dans mes projets professionnels.
Bien que cette méthode fonctionnait, elle s'avérait laborieuse.
La procédure documentant l'installation, la création des clés et la configuration de gnupg était l'étape posant le plus de difficultés d'onboarding des développeurs sur ces projets.
Au feeling, je dirais que trois développeurs sur quatre bloquaient à cette étape.
En parallèle à cette méthode, j'ai essayé d'utiliser la cli de Bitwarden, mais l'expérience n'a pas été très concluante, principalement à cause de problèmes de latence lors de son exécution.
Aujourd'hui, j'ai exploré une nouvelle méthode basée sur age et son support natif des clés ssh.
Voici le repository Git du résultat de cette exploration : age-secret-skeleton.
Le résultat est très positif et je pense avoir trouvé ma nouvelle méthode de chiffrement des secrets dans mes projets 🙂.
Pour en savoir plus, vous pouvez à la fois suivre le README.md du repository et continuer la lecture de cette note.
Détail des fichiers du repository
.
├── .envrc
├── .gitignore
├── .mise.toml
├── README.md
├── scripts
│ ├── decrypt_secrets.sh
│ └── encrypt_secrets.sh
├── .secret
├── .secret.age
├── .secret.skel
└── ssh-keys
├── john-doe.pub
└── stephane-klein.pub
/.secret: fichier qui contient les secrets en clair. Ce fichier est ignoré par.gitignoreafin qu'il ne soit pas présent dans le repository git/.secret.age: fichier qui contient le contenu du fichier.secretchiffré avec age. Ce fichier est ajouté au repository git./ssh-keys/: ce dossier contient les clés publiques ssh des personnes qui ont accès au contenu de.secret.age/scripts/decrypt_secrets.sh: permet de déchiffrer avec age le contenu de.secret.ageet écrit le résultat en clair dans.secret/scripts/encrypt_secrets.sh: permet de chiffrer avec age le contenu de.secretvers.secret.age. Ce script doit être exécuté quand le contenu de.secretest modifié ou quand une nouvelle clé est ajoutée dans/ssh-keys//.envrc: Dans ce skeleton, ce fichier charge uniquement les variables d'environnement présentes dans.secretmais dans un vrai projet, il permet de charger automatiquement des variables d'environnement qui ne sont pas des secrets./.secret.skel: ce fichier contient l'exemple de contenu du fichier.secret, sans les secrets. Par exemple :
# You can either request these secrets from Stéphane Klein (contact@stephane-klein.info)
# or, if your public ssh key is present in `./ssh-keys/` use the ./scripts/decrypt_secrets.sh command
# which will automatically decrypt the .secret.age file to .secret
export POSTGRES_PASSWORD="..."
export SCW_SECRET_KEY="..."
Ce fichier n'est pas nécessaire au bon fonctionnement du workflow mais je le trouve utile pour :
- documenter le contenu de
.secretaux personnes qui ont juste accès au dépôt Git - permettre de review les modifications de
.secret.skeldans des Merge Request.
Utilisation des clés ssh
L'un des avantages majeurs de age par rapport à pass + gnupg est son support natif des clés SSH pour chiffrer et déchiffrer les secrets.
Ainsi, je n'ai plus besoin de demander aux développeurs deux types de clés (SSH et gnupg) : une seule clé SSH suffit.
De plus, il me semble qu'un grand nombre de développeurs possèdent déjà une clé SSH, alors que je pense que gnupg reste une technologie bien moins répandue.
Détail d'implémentation des scripts
Vvoici le contenu de /scripts/encrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare recipient arguments for age
recipient_args=()
for pubkey in ./ssh-keys/*.pub; do
if [ -f "$pubkey" ]; then
recipient_args+=("-R" "$pubkey")
fi
done
# Execute age with all public keys
age "${recipient_args[@]}" -o .secret.age .secret
La boucle permet de passer toutes les clés ssh du dossier /ssh-keys/* en paramètre d' age.
Voici le contenu de /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
La boucle permet de passer en paramètre toutes les clés privées ssh du dossier ~/.ssh/ en espérant en trouver une qui correspond à une clé publique du dossier /ssh-keys/.
Plusieurs niveaux de sécurisation
Si je veux cloisonner les secrets en limitant leur accès à des groupes d'utilisateurs distincts, je peux utiliser des secrets différents selon l'environnement.
Par exemple :
.
├── production
│ ├── .secret.age
│ └── ssh-keys
└── sandbox
├── .secret.age
└── ssh-keys
Cette structure me permet de donner à certains utilisateurs accès aux secrets de l'environnement sandbox, sans leur donner accès à ceux de production.
Aller plus loin avec par exemple Vault ?
Je pense qu'il est possible d'aller plus loin en matière de sécurité avec des solutions comme Vault, mais trouve que la méthode basée sur age reste plus simple à déployer dans une petite équipe.
Journal du vendredi 07 février 2025 à 14:03
Pendant l'année 2014, Athoune m'a fait découvrir les concepts DevOps "Baking" et "Frying".
Je le remercie, car ce sont des concepts que je considère très importants pour comprendre les différents paradigmes de déploiement.
Je n'ai aucune idée dans quelles conditions il avait découvert ces concepts. J'ai essayé de faire des recherches limitées à l'année 2014 et je suis tombé sur cette photo :
J'en déduis que cela devait être un sujet à la méthode dans l'écosystème DevOps de 2014.
Cet ami me l'avait très bien expliqué avec une analogie du type :
« Le baking en DevOps, c’est comme dans un restaurant où les plats sont préparés en cuisine et ensuite apportés tout prêt salle à la table du client. Le frying, c’est comme si le plat était préparé directement en salle sur la table du client. »
Bien que cette analogie ne soit pas totalement rigoureuse, elle m'a bien permis de saisir, en 2014, le paradigme Docker qui consiste à préparer des images de container en amont. Ce paradigme permet d'installer, de configurer ces images "en cuisine", donc pas sur les serveurs de production, "de goûter les plats" et de les envoyer ensuite de manière prédictible sur le serveur de production.
Ces images peuvent être construites soit sur la workstation du développeur ou mieux, sur des serveurs dédiés à cette fonction, comme Gitlab-Runner…
Définitions proposées par LLaMa :
Baking (ou "Image Baking") : Il s'agit de créer une image de serveur prête à l'emploi, avec tous les logiciels et les configurations nécessaires déjà installés et configurés. Cette image est ensuite utilisée pour déployer de nouveaux serveurs, qui seront ainsi identiques et prêts à fonctionner immédiatement. L'avantage de cette approche est qu'elle permet de réduire le temps de déploiement et d'assurer la cohérence des environnements.
Frying (ou "Server Frying") : Il s'agit de déployer un serveur "nu" et de le configurer et de l'installer à la volée, en utilisant des outils d'automatisation tels que Ansible, Puppet ou Chef. Cette approche permet de personnaliser la configuration de chaque serveur en fonction des besoins spécifiques de l'application ou du service.
Exemple :
Cas d'usage Baking Frying Docker Construire une image complète ( docker build) et la stocker dans un registreLancer un conteneur minimal et installer les dépendances au démarrage. Machines virtuelles (VMs) Créer une image VM avec Packer et la déployer telle quelle Démarrer une VM de base et appliquer un script d’installation à la volée CI/CD Compiler et packager une application en image prête à être déployée Construire l’application à chaque déploiement sur la machine cible
En 2014, lorsque le concept de baking m’a été présenté, j’ai immédiatement été enthousiasmé, car il répondait à trois problèmes que je cherchais à résoudre :
- Réduire les risques d’échec d’une installation sur le serveur de production
- Limiter la durée de l’indisponibilité (pendant la phase d’installation)
- Éviter d'augmenter la charge du serveur durant les opérations de build lors de l’installation
Depuis, j'évite au maximum le frying et j'ai intégré le baking dans ma doctrine d'artisan développeur.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Journal du mardi 28 janvier 2025 à 13:49
Alexandre me dit : « Le contenu de Speed of Code Reviews (https://google.github.io/eng-practices/review/reviewer/speed.html) ressemble à ce dont tu faisais la promotion dans notre précédente équipe ».
En effet, après lecture, les recommandations de cette documentation font partie de ma doctrine d'artisan développeur.
Note: j'ai remplacé CL qui signifie Changelist par Merge Request.
When code reviews are slow, several things happen:
- The velocity of the team as a whole is decreased. Yes, the individual who doesn’t respond quickly to the review gets other work done. However, new features and bug fixes for the rest of the team are delayed by days, weeks, or months as each Merge Request waits for review and re-review.
- Developers start to protest the code review process. If a reviewer only responds every few days, but requests major changes to the Merge Request each time, that can be frustrating and difficult for developers. Often, this is expressed as complaints about how “strict” the reviewer is being. If the reviewer requests the same substantial changes (changes which really do improve code health), but responds quickly every time the developer makes an update, the complaints tend to disappear. Most complaints about the code review process are actually resolved by making the process faster.
- Code health can be impacted. When reviews are slow, there is increased pressure to allow developers to submit Merge Request that are not as good as they could be. Slow reviews also discourage code cleanups, refactorings, and further improvements to existing Merge Request.
J'ai fait le même constat et je trouve que cette section explique très bien les conséquences 👍️.
How Fast Should Code Reviews Be?
If you are not in the middle of a focused task, you should do a code review shortly after it comes in.
One business day is the maximum time it should take to respond to a code review request (i.e., first thing the next morning).
Following these guidelines means that a typical Merge Request should get multiple rounds of review (if needed) within a single day.
Je partage et recommande cette pratique 👍️.
If you are too busy to do a full review on a Merge Request when it comes in, you can still send a quick response that lets the developer know when you will get to it, suggest other reviewers who might be able to respond more quickly.
👍️
Large Merge Request
If somebody sends you a code review that is so large you’re not sure when you will be able to have time to review it, your typical response should be to ask the developer to split the Merge Request into several smaller Merge Requests that build on each other, instead of one huge Merge Request that has to be reviewed all at once. This is usually possible and very helpful to reviewers, even if it takes additional work from the developer.
Je partage très fortement cette recommandation et je pense que c'est celle que j'avais le plus de difficulté à faire accepter par les nouveaux développeurs.
Quand je code, j'essaie de garder à l'esprit que mon objectif est de faciliter au maximum le travail du reviewer plutôt que de chercher à minimiser mes propres efforts.
J'ai sans doute acquis cet état d'esprit du monde open source. En effet, l'un des principaux défis lors d'une contribution à un projet open source est de faire accepter son patch par le mainteneur. On comprend rapidement qu'un patch doit être simple à comprendre et rapide à intégrer pour maximiser ses chances d'acceptation.
Un bon patch doit remplir un objectif unique et ne contenir que les modifications strictement nécessaires pour l'atteindre.
Je suis convaincu que si une équipe de développeurs applique ces principes issus de l'open source dans leur contexte professionnel, leur efficacité collective s'en trouvera grandement améliorée.
Par ailleurs, une Merge Request de taille réduite présente plusieurs avantages concrets :
- elle est non seulement plus simple à rebase,
- mais elle a aussi plus de chances d'être mergée rapidement.
Cela permet à l'équipe de bénéficier plus rapidement des améliorations apportées, qu'il s'agisse de corrections de bugs ou de nouvelles fonctionnalités.
Journal du lundi 09 septembre 2024 à 15:59
Dans cette note, je souhaite présenter ma doctrine de mise à jour d'OS de serveurs.
Je ne traiterai pas ici de la stratégie d'upgrade pour un Cluster Kubernetes.
La mise à jour d'un serveur, par exemple, sous un OS Ubuntu LTS, peut être effectuée avec les commandes suivantes :
sudo apt upgrade -y- ou
sudo apt dist-upgrade -y(plus risqué) - ou
sudo do-release-upgrade(encore plus risqué)
L'exécution d'un sudo apt upgrade -y peut :
- Installer une mise à jour de docker, entraînant une interruption des services sur ce serveur de quelques secondes à quelques minutes.
- Installer une mise à jour de sécurité du kernel, nécessitant alors un redémarrage du serveur, ce qui entraînera une coupure de quelques minutes.
Une montée de version de l'OS via sudo do-release-upgrade peut prendre encore plus de temps et impliquer des ajustements supplémentaires.
Bien que ces opérations se déroulent généralement sans encombre, il n'y a jamais de certitude totale, comme l'illustre l'exemple de la Panne informatique mondiale de juillet 2024.
Sachant cela, avant d'effectuer la mise à jour d'un serveur, j'essaie de déterminer quelles seraient les conséquences d'une coupure d'une journée de ce serveur.
Si je considère que ce risque de coupure est inacceptable ou ne serait pas accepté, j'applique alors la méthode suivante pour réaliser mon upgrade.
Je n'effectue pas la mise à jour le serveur existant. À la place, je déploie un nouveau serveur en utilisant mes scripts automatisés d'Infrastructure as code / GitOps.
C'est pourquoi je préfère éviter de nommer les serveurs d'après le service spécifique qu'ils hébergent (voir aussi Pets vs Cattle). Par exemple, au lieu de nommer un serveur gitlab.servers.example.com, je vais le nommer server1.servers.example.com et configurer gitlab.servers.example.com pour pointer vers server1.servers.example.com.
Ainsi, en cas de mise à jour de server1.servers.example.com, je crée un nouveau serveur nommé server(n+1).servers.example.com.
Ensuite, je lance les scripts de déploiement des services qui étaient présents sur server1.servers.example.com.
Idéalement, j'utilise mes scripts de restauration des données depuis les sauvegardes des services de server1.servers.example.com, ce qui me permet de vérifier leur bon fonctionnement.
Ensuite, je prépare des scripts rsync pour synchroniser rapidement les volumes entre server1.servers.example.com et server(n+1).servers.example.com.
Je teste que tout fonctionne bien sur server(n+1).servers.example.com.
Si tout fonctionne correctement, alors :
- J'arrête les services sur
server(n+1).servers.example.com; - J'exécute le script de synchronisation
rsyncdeserver1.servers.example.comversserver(n+1).servers.example.com; - Je relance les services sur
server(n+1).servers.example.com - Je modifie la configuration DNS pour faire pointer les services de
server1.servers.example.comversserver(n+1).servers.example.com - Quelques jours après cette intervention, je décommissionne
server1.servers.example.com.
Cette méthode est plus longue et plus complexe qu'une mise à jour directe de l'OS sur le server1.servers.example.com, mais elle présente plusieurs avantages :
- Une grande sécurité ;
- L'opération peut être faite tranquillement, sans stress, avec de la qualité ;
- Une durée de coupure limitée et maîtrisée ;
- La possibilité de confier la tâche en toute sécurité à un nouveau DevOps ;
- La garantie du bon fonctionnement des scripts de déploiement automatisé ;
- La vérification de l'efficacité des scripts de restauration des sauvegardes ;
- Un test concret des scripts et de la documentation du Plan de reprise d'activité.
Si le serveur à mettre à jour fonctionne sur une Virtual instance, il est également possible de cloner la VM et de tester la mise à niveau. Cependant, je préfère éviter cette méthode, car elle ne permet pas de valider l'efficacité des scripts de déploiement.
Journal du jeudi 25 juillet 2024 à 16:56
Rich Harris explains this clearly. JSDoc for writing a lib. TypeScript for writing an app. (from)
Ce conseil entre en opposition avec ce que j'ai écrit en octobre 2023 :
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Ce conseil entre aussi en opposition avec ce second élément que j'ai écrit en octobre 2023 :
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Je pense qu'il serait bon que je revoie ma doctrine d'artisan développeur sur ce sujet.
Journal du vendredi 24 mai 2024 à 13:32
Cela fait depuis décembre 2023 que je souhaite traduire l'article The Platinum Rule de Shawn Wang (dit swyx), c'est chose faite :
Voici la Traduction de "The Platinum Rule" 🙂.
Pourquoi avoir traduit cet article ?
Parce que quand je l'ai lu, il m'a fait beaucoup réfléchir parce que j'ai réalisé que j'ai été depuis tout petit très conditionné par la règle d'or. J'essayais au maximum de la respecter et j'imaginais que si tout le monde la respectait, tout irait pour le mieux… mais avant de lire cet article, c'est bête à dire, mais je n'avais pas réalisé qu'en pratique, cela ne fonctionnait pas.
En lisant cet article, je pense qu'il est bon de garder à l'esprit que Shawn Wang (dit swyx) est un développeur et je pense qu'il a écrit cet article en rapport à des difficultés de travailler en équipe sur des projets de développement.
Pensez, par exemple, aux conventions de coding style et à bien d'autre sujets !
N'hésitez pas à venir échanger avec moi pour me partager votre avis sur le sujet, cela m'intéresse 🙂.
Journal du samedi 06 mai 2023 à 07:39
#JaiLu l'article Don’t Build A General Purpose API To Power Your Own Front End.
TL;DR YAGNI, unless you’re working in a big company with federated front-ends or GraphQL.
It’s popular in web dev nowadays to build a backend that serves JSON, and a frontend that renders the app. This is fine. I’m not the biggest fan, but it’s really okay. Except it’s not okay if you think that your backend needs to be designed like a generic public API. This will not save you time.
Journal du jeudi 01 septembre 2022 à 20:26
Je trouve que Best current practice est intéressant pour éviter de tomber dans la rigidité d'un process 🤔.
Traduction de "The Platinum Rule"
Ma traduction de l'article The Platinum Rule de Shawn Wang (dit swyx) avec quelques modifications et ajouts qui me permettent — peux-être à vous aussi — de mieux comprendre l'article.
La traduction commence ici ⬇️
Vous avez entendu parler de la la règle d'or : « Traiter les autres comme on voudrait être traité » ou « Ne fais pas aux autres ce que tu ne voudrais pas qu'on te fasse ».
Je pense qu'elle est incomplète. Je pense que les gens fonctionnent en réalité selon une norme plus élevée. Je propose la Règle de Platine : Traiter les autres comme ILS veulent être traités.
La Règle de Platine
Pour comprendre comment j'en suis arrivé là, il faut savoir que j'ai des traits de personnalité particuliers qui rendent la règle de Platine pertinente pour moi. Je préfère la franchise. Mon seuil pour considérer quelque chose comme "terminé" est plus bas que le vôtre. J'aime les personnes conscientes d'elles-mêmes et l'humour. Je préfère l'amour vache.
Cela signifie que je préfère livrer une chose imparfaite et itérer plutôt que de mettre de l'ordre dans mes affaires. Cela signifie que je dis les choses sans les adoucir pour les rendre plus agréables à entendre. Cela signifie que je me moque de moi-même et de tout ce à quoi je m'identifie fortement, ce qui peut parfois inclure les personnes avec lesquelles je travaille. Cela signifie que je suis souvent trop dur à l'égard de quelque chose qui me tient à cœur.
En lisant ce paragraphe — ci-dessus — certains d'entre vous ont sans doute pensée « ok, et alors ? » sans voir ce qu'il ne va pas dans ce comportement. Voici ce qui ne va pas.
Pourquoi la règle d'or pose problème ?
Imaginons que nous simplifions les préférences humaines en deux catégories : « plus particulières » et « moins particulières ».
Et supposons que les interactions humaines se résument à deux aspects : « comment vous traitez les autres » et « comment vous voulez être traité ».
La règle d'or — traiter les autres comme vous voulez être traité — suggère que les personnes plus particulières devraient traiter les autres selon leurs propres standards élevés — peu importe comment vous définissez ces standards.
C'est une bonne chose car cela rend les personnes particulières très prévenantes.
Cependant, si les personnes moins particulières appliquaient cette règle et traitaient les autres comme elles veulent être traitées, elles paraîtraient vraiment désagréables aux yeux des personnes plus particulières, qui ne pourraient pas travailler avec elles.
Par exemple, imaginez quelqu'un qui aime que tout soit toujours bien rangé et organisé. Cette personne, très particulière sur la propreté, pourrait être très attentive à maintenir un environnement propre et ordonné pour tout le monde.
Cependant, si une personne qui ne se soucie pas autant du rangement appliquait la règle d'or et traitait les autres comme elle veut être traitée (c'est-à-dire sans se soucier de l'ordre), elle semblerait désordonnée et négligente aux yeux de la personne qui apprécie l'ordre. Cela créerait des tensions, car la personne qui aime l'ordre se sentirait frustrée et incapable de travailler efficacement avec l'autre.
Dans cet exemple, la règle d'or ne fonctionne pas bien, la personne qui aime l'ordre traite l'autre comme elle aimerait être traité, mais son souhaite ne se réalise pas !
Les nombres relatifs de personnes plus particulières et de personnes moins particulières n'ont pas d'importance - si ces personnes doivent travailler ensemble, elles doivent coexister dans le cadre d'un contrat social différent.
La règle de platine ?
Pour essayer de résoudre ce problème, je propose que la règle de platine soit ce contrat : traiter les autres comme ils veulent être traités.
D'un côté, cela semble relever de la plus simple politesse : bien sûr, il faut tenir compte des sentiments des autres. Utilisez leurs pronoms. Respecter leur autonomie et leur liberté.
D'un autre côté, cela peut sembler beaucoup trop accommodant - que faire si les gens abusent du système et veulent être traités de manière déraisonnable ? Il y a deux poids, deux mesures partout lorsqu'il s'agit d'intérêt personnel. Il faut bien tracer une ligne quelque part.
Elle est imparfaite, mais il est probable que le bon équilibre entre vous et moi se situe quelque part entre la Règle d'Or (empathie extrêmement centrée sur soi) et la Règle de Platine (accommodement extrêmement centré sur les autres).
La Règle d'Argent
En réfléchissant à cela dans un avion, j'ai également pensé à une belle conclusion pour ce message. Si la règle de platine est "meilleure" que la règle d'or, à quoi ressemblerait une règle d'argent ? (j'aime étendre les idées comme celle-ci, j'ai pris cela de Brian Chesky).
Une règle d'argent serait quelque chose qui est souvent considéré comme secondaire par rapport aux autres, mais qui reste important et précieux. Et sous la forme suivante : « Traitez x comme X veut être traité ».
Voici ma proposition pour une règle d'argent : Traitez-vous comme vous traitez les autres. Une belle inversion de la règle d'or.
Le framework des quatre tendances de Gretchen Rubin divise les gens en fonction de la façon dont ils répondent aux attentes intérieures et extérieures, ce qui semble tout à fait approprié à ce sujet. Les profils "Questioners" ont le plus besoin de la Règle de Platine. Mais les "Obligers" ont probablement le plus besoin de la Règle d'Argent.
Le souci de soi ne doit pas céder la place au sacrifice de soi.
Dernière page.