
Simon Willison
Développeur de Datasette et llm (cli)
Site web : https://simonwillison.net
Journaux liées à cette note :
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
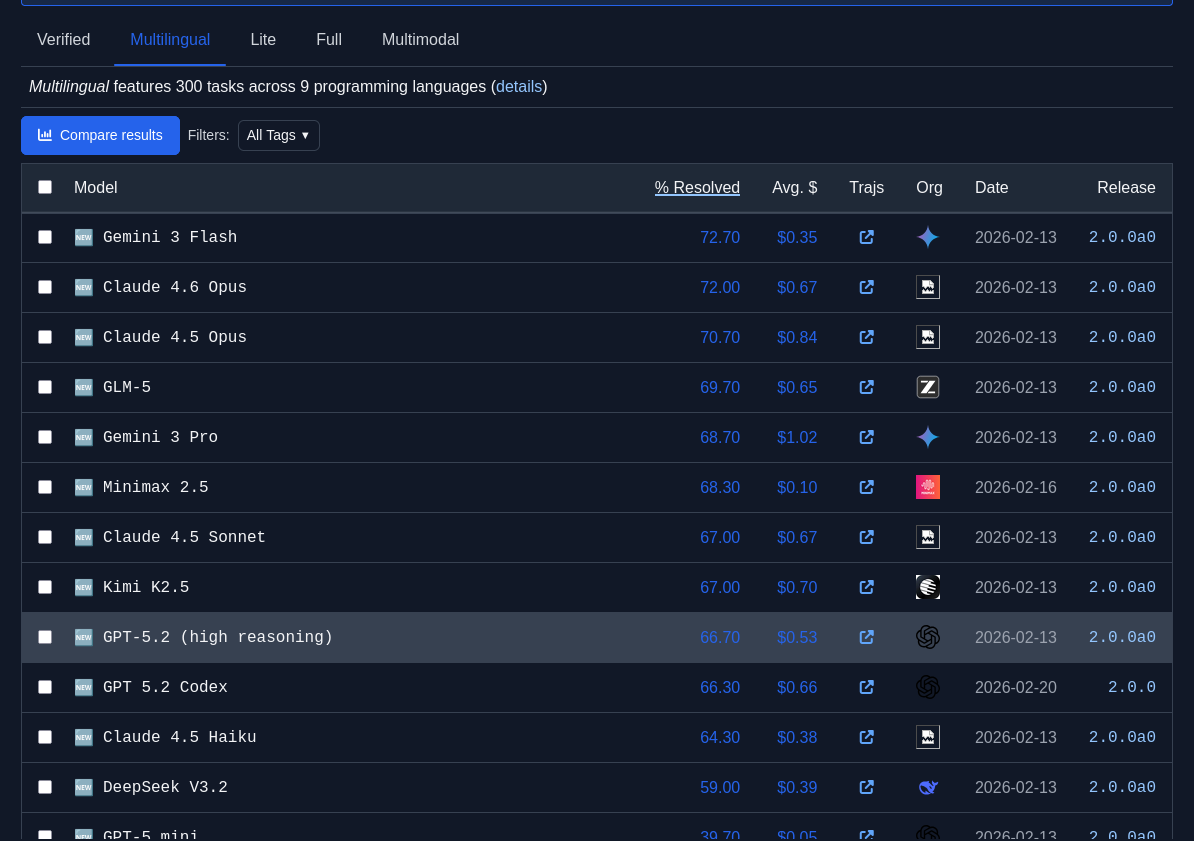
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.
Journal du mercredi 21 mai 2025 à 14:25
#JaiDécouvert le concept de LLM-as-a-Judge.
#JaiLu l'article Wikipédia à ce sujet "LLM-as-a-Judge".
"Abstract" du papier de recherche Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena datant du 24 décembre 2023 :
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, including position, verbosity, and self-enhancement biases, as well as limited reasoning ability, and propose solutions to mitigate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and [[Chatbot Arena]], a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA and Vicuna. The MT-bench questions, 3K expert votes, and 30K conversations with human preferences are publicly available at https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge.
J'ai parcouru rapidement l'article "Evaluating RAG with LLM as a Judge" du blog de Mistral AI. Je n'ai pas pris le temps d'étudier les concepts que je ne connaissais pas dans cet article, par exemple RAG Triad.
J'ai effectué une recherche sur « LLM as Judge » sur le blog de Simon Willison.
Journal du lundi 18 novembre 2024 à 09:44
Un ami me demande des ressources pour se former au Machine Learning.
Je ne suis pas expert dans ce domaine.
Lorsque je me forme sur un sujet, j’aime commencer par comprendre le contexte global, son histoire et alterner entre l’acquisition de connaissances théoriques et pratiques.
Pour me former sérieusement, j'envisage un jour de prendre le temps de :
- Suivre les vidéos de Thibault Neveu, en particulier :
- Écouter et essayer de reproduire le contenu des 16 vidéos de la série "Formation au Deep Learning" (~3h)
- Ensuite la série de 5 vidéos "Tensorflow et Keras" (~5h)
- Ensuite la série de 13 vidéos "Apprentissage par renforcement" (~8h)
- Ensuite la série de 10 vidéos "Deep learning avancé" (~8h)
- Ensuite la série de 22 vidéos "Formation à Tensorflow 2.0" (~8h)
- Ensuite la série de 4 vidéos "Pytorch NLP" (~2h)
- Ensuite là série de 3 vidéos "Créer une intelligence artificielle sur StarCraft II" (~2h)
- Essayer de comprendre le fonctionnement des "transformer" :
- Pour cela, je commencerai écouter la vidéo "À quoi ressemble ChatGPT ? 🌶️" de Lê Nguyên Hoang, qui présente la structure des transformers (~1h)
- Lire les articles Wikipedia (~1h) :
- Lire l'article "Natural Language Processing: the age of Transformers" (~2h)
- Lire l'article : "Word Embeddings in NLP: An Introduction" (~2h)
- Lire l'article : "Attention Is All You Need" (~2h)
- Parcourir les mises en pratique de Simon Willison : https://til.simonwillison.net/llms (~3h)
Je n'ai pas classé l'ordre d'étude des séries avec rigueur, cet ordre est sans doute à modifier.
Pour chaque élément, j'ai précisé entre parenthèses une estimation optimiste du temps nécessaire à l'écoute ou à la lecture.
D'après cette liste, j'estime à environ 86 heures pour me former sur ce sujet, soit l'équivalent de 15 jours à temps plein ou presque un mois complet.
Ensuite, j'ai quelques idées de projets de mise en pratique :
- Développer une extension pour navigateur qui, lors de la rédaction d’un e-mail depuis Fastmail, transforme automatiquement le contenu du message en HTML en texte brut au format Markdown.
- Ajouter ensuite une fonctionnalité pour supprimer automatiquement les signatures.
- Concevoir un outil capable de découper une vidéo de Tennis de Table en segments correspondant à chaque point joué.
Journal du lundi 13 mai 2024 à 20:05
Note en lien avec Opération de nettoyage, curation de mes données Toggl et Fonctionnalité cluster and edit de OpenRefine.
Je pensais que Datasette pouvait être utilisé comme un outil de #data-curation mais je comprends que non, ce n'est pas dans "l'adn" du projet.
Voici ce que dit ici le développeur de Datasette :
For some developers, this is an odd choice - SQLite is an OLTP database, so why not support a few INSERT INTO or UPDATE statements?
The reasons, as laid out in that original blog post, are short and simple. For one, only handling read-only connections greatly reduces security risks. Datasette has SQL code execution as a first-class feature, so limiting any potential risk is important.
Plus, Datasette is a tool for publishing and exploring data. If you're investigating a government data dump or analyzing your city's annual budget, you don't want to edit data anyway!
J'ai trouvé ici une mention de OpenRefine par Simon Willison. J'y ai découvert datasette-reconcile mais pour le moment #JeMeDemande comment l'utiliser et à quoi cela pourrait me servir 🤔.