
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (12 notes) :
J'ai découvert cc-safety-net : des hooks pour sécuriser les agents IA
Suite à ma note "Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code", une amie m'a mise sur la piste des hooks pour intégrer efficacement le blocage de l'exécution de commandes dangereuses dans mon harness.
claude-code-hooks
Elle utilise Claude Code et je pense qu'elle utilise le projet claude-code-hooks (lien direct), et plus précisément son script block-dangerous-commands.js.
Ce projet est présenté dans le billet Claude Code's Most Underrated Feature: Hooks du 25 janvier 2026, que j'ai pris le temps de lire avec attention.
Après lecture, ce billet confirme la piste suggérée par mon amie : les hooks semblent être la solution la plus répandue pour bloquer les commandes dangereuses.
J'ai découvert cc-safety-net
J'ai ensuite cherché une solution "clé en main" équivalente à block-dangerous-commands.js pour OpenCode et suis tombée sur cc-safety-net (lien direct), un projet qui a même démarré un peu avant claude-code-hooks (source) :
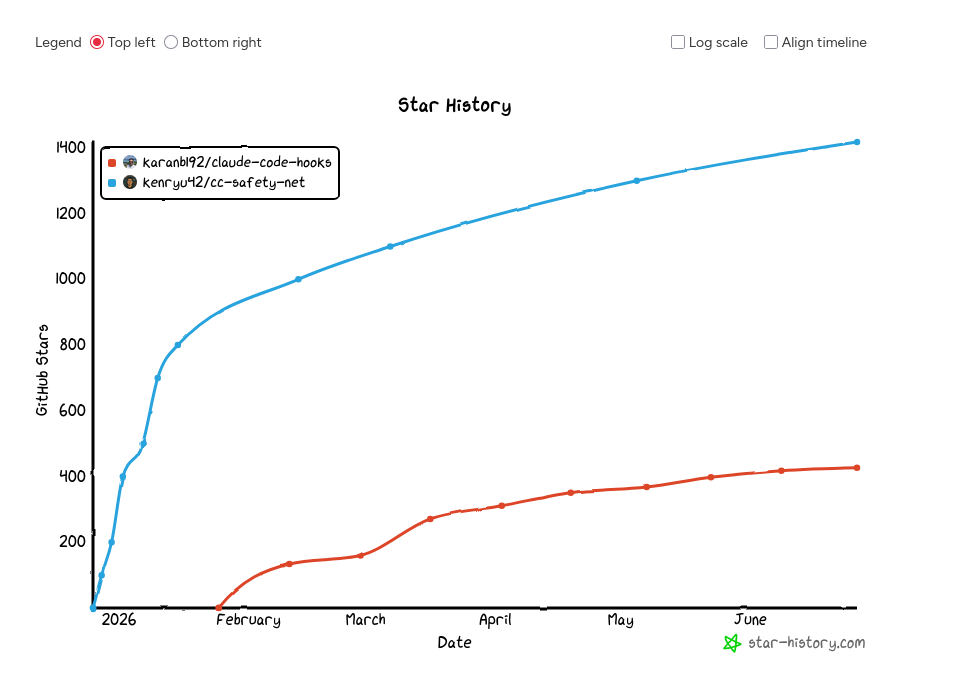
Le nom cc-safety-net combine l'abréviation de Claude Code ("cc") et "safety net", qui veut dire "filet de sécurité".
cc-safety-net ne se limite pas à Claude Code et OpenCode : il prend aussi en charge Codex, Gemini CLI, GitHub Copilot CLI et Kimi Code.
J'ai installé cc-safety-net
J'ai installé cc-safety-net sur mon instance OpenCode. Bien qu'il ne soit pas visible dans la liste des plugins de l'interface OpenCode — ce qui semble normal — il fonctionne correctement d'après mes tests :
$ git init
$ touch file1.md
$ git add file1.md
$ git commit -m "First import"
$ touch file2.md
$ opencode run --agent="build" "exécute git reset --hard"
> build · deepseek-v4-flash
✗ git reset --hard failed
Error: BLOCKED by CC Safety Net
Reason: git reset --hard destroys all uncommitted changes permanently. Use 'git stash' first.
Command: git reset --hard
If this operation is truly needed, ask the user for explicit permission and have them run the command manually.
La commande `git reset --hard` est bloquée par le CC Safety Net car elle détruit irréversiblement les changements non commités.
**Alternatives :**
- `git stash` pour sauvegarder les changements avant de reset
- Exécute la commande toi-même manuellement si tu confirms vouloir tout perdre
Que veux-tu faire ?
Par défaut, cc-safety-net contient peu de règles : il bloque les commandes de suppression sur le système de fichiers et git, comme documenté ici : "blocked-commands".
Après la lecture de la page "allowed-commands", j'ai cru que cc-safety-net proposait aussi un mode whitelist. En réalité, il fonctionne seulement en mode blocklist — pas de mode "tout bloquer" avec un système de whitelist.
Pour le moment, j'ai décidé d'activer le mode par défaut de cc-safety-net.
Création de rulebooks pour mon projet homelab
Ce que je trouve très intéressant avec cc-safety-net, c'est la possibilité d'ajouter facilement des "Custom Rules" grâce aux "rulebooks". Cette fonctionnalité est jeune, à peine 3 semaines. Pour le moment, je n'ai trouvé que 2 "rulebooks" sur GitHub.
J'ai utilisé le skill /cc-safety-net pour créer mes "rulebooks" pour les commandes kubectl, helmfile, tofu et mise de mon projet homelab.sklein.xyz.
Pas sans difficulté : le skill a dû corriger plusieurs erreurs de syntaxe dans les fichiers json qu'il a générés. Je ne sais pas si c'est normal. Mais à la fin, ça a fonctionné.
Je viens de configurer tout cela, je n'ai aucun retour d'expérience, j'essaierai d'en donner un d'ici une semaine.
Encore un problème avec rtk !
Par contre, j'ai découvert que cc-safety-net a lui aussi des difficultés avec rtk : [Bug]: rtk bypasses safety net.
Pour les secrets, je compte tester Rehydra
Contrairement à claude-code-hooks, cc-safety-net ne propose pas de hooks pour cacher les secrets à l'agent.
#JaiDécouvert le projet rehydra qui me semble très intéressant :
PII security for AI workflows, coding agents and browser workloads. Detects, replaces, encrypts, and rehydrates back when needed.
cc-safety-net versus agentsh ?
J'ai seulement survolé le sujet, mais j'ai l'impression que agentsh analyse et intercepte ce qui se passe directement au niveau du système d'exploitation, du système de fichiers, réseau, et processus. Il n'agit pas au niveau applicatif, il n'a pas besoin de comprendre ce que fait en théorie la commande, il observe réellement son action sur l'OS.
Pour le moment je pense que cc-safety-net est une bonne première étape de sécurité pour mes besoins. Mais agentsh a attiré ma curiosité, peut-être que je le testerai prochainement.
Remerciement
Merci à mon amie CC de m'avoir mise sur la piste des hooks 🤗.
rtk contourne le système de permissions d'OpenCode
En étudiant la compatibilité de Prempti avec rtk (voir cette note : "Danger des permissions par défaut d'OpenCode sur un projet d'infrastructure as code"), j'ai découvert ici que rtk contourne les règles de permissions de OpenCode ! Mais aussi Claude Code d'après ce que j'ai compris.
J'ai testé et c'est vrai ! Voici mon test.
J'ai rtk installé et configuré pour OpenCode au niveau global, avec rtk init -g --opencode.
Voici à quoi ressemble le dossier de mon projet de test :
$ tree -a
.
├── .opencode
│ └── opencode.json
└── foobar
2 directories, 2 files
$ cat .opencode/opencode.json
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"build": {
"permission": {
"bash": {
"git *": "deny",
}
}
},
}
}
La commande git est interdite à l'agent build.
Je lance :
$ opencode run --agent="build" "exécute la commande unix 'git status'"
> build · deepseek-v4-flash
$ rtk git status
* No commits yet on main
?? .opencode/
?? foobar
Pas encore de commit sur `main`. Fichiers non suivis : `.opencode/` et `foobar`.
rtk a réussi à lancer la commande git status !
Voici un test sans rtk :
$ mv ~/.config/opencode/plugins/rtk.ts /tmp/rtk.ts
$ opencode run --agent="build" "exécute la commande unix 'git status'"
> build · deepseek-v4-flash
✗ git status failed
Error: The user has specified a rule which prevents you from using this specific tool call. Here are some of the relevant rules [{"permission":"*","action":"allow","pattern":"*"},{"permission":"bash","action":"allow","pattern":"*"},{"permission":"bash","pattern":"git *","action":"deny"}]
La commande `git status` est bloquée par une règle de permission qui interdit les commandes `git *` dans bash.
Souhaites-tu autoriser cette commande ?
Sans rtk, le système de permissions d'OpenCode fonctionne parfaitement, l'exécution de git status est interdite.
D'après mes recherches snip a le même problème de sécurité.
Je pense que pour le moment je vais arrêter d'utiliser rtk 🤔.
Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code
Cette après-midi, DeepSeek V4 Flash (via OpenCode) a fait une boulette dans mon projet homelab.sklein.xyz !

En voulant corriger le Helmfile de déploiement de Hindsight, il a lancé :
$ mise run destroy-cnpg-hindsight
sans réaliser que cette task Mise allait lancer la commande suivante :
helmfile -f helmfile/helmfile.yaml.gotmpl destroy
sans remarquer que mon fichier helmfile/helmfile.yaml.gotmpl contenait tous mes services et pas seulement cnpg-hindsight !
Ce qui est marrant, c'est qu'après le « Oups », il a tout de suite essayé de se rattraper. Heureusement, je suis au début de l'installation de mon homelab — rien d'important à perdre — et j'ai pu tester que la restauration du backup continu de CloudNativePG basé sur barman fonctionne bien.
DeepSeek V4 Flash n'est pas à blâmer : je ne l'ai pas aidé avec mes instructions, je lui ai tendu un piège.
Suite à cet incident sans gravité, j'ai pris conscience que faire travailler un agent de coding sur un projet d'Infrastructure as code est bien plus risqué que sur un projet de développement cloisonné, sans accès à la production.
J'ai commencé par ajouter ces quelques lignes dans mon fichier AGENTS.md :
## Safety Rules
- **Never run any `destroy-*` script or `helmfile destroy` command without explicit user confirmation** in the same conversation turn. Always ask first.
- If you must run `helmfile destroy`, always use `--selector name=<release>` to target only one release.
- When in doubt about a command's destructiveness, ask before executing.
Ensuite, j'ai remarqué que l'agent plan de OpenCode avait par défaut un accès trop large au tool bash pour un projet d'Infrastructure as code, je me suis lancé dans le renforcement des permissions :
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"plan": {
"permission": {
"bash": {
"*": "ask",
"kubectl get *": "allow",
"kubectl describe *": "allow",
"kubectl logs *": "allow",
"kubectl top *": "allow",
"tofu plan*": "allow",
"tofu show*": "allow",
"tofu output*": "allow",
"tofu state*": "allow",
"helm list*": "allow",
"helm status*": "allow",
"helm diff*": "allow",
"helmfile *list*": "allow",
"helmfile *status*": "allow",
"helmfile *diff*": "allow",
"git log*": "allow",
"git diff*": "allow",
"git status": "allow",
"git show*": "allow",
"jj log*": "allow",
"jj diff*": "allow",
"jj status": "allow",
"ls*": "allow",
"find*": "allow"
}
}
}
}
}
Ensuite, je me suis demandé s'il existait des solutions clé en main de limitation d'accès aux commandes cli, du même style que rtk, pour autoriser seulement des commandes de lecture sans risque.
#JaiDécouvert Prempti et agentsh. Je me suis demandé si l'intégration de l'un de ces outils n'allait pas entrer en conflit avec rtk. En étudiant les issues sur la sécurité de rtk, j'ai découvert que : rtk contourne le système de permissions d'OpenCode.
Premier test minimaliste de Promptfoo avec le provider OpenCode SDK
Depuis au moins novembre 2025, je cherche à rédiger mes prompts, mes fichiers AGENTS.md, mes fichiers SKILLS.md — et plus largement mon harness OpenCode — avec une méthode rigoureuse et contrôlée. J'ai découvert dans cette issue le nom du mécanisme que j'essaie de mettre en place : agent-eval-harness, terme plutôt simple et explicite.
En février, je disais :
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Quelques mois plus tard, j'ai enfin implémenté un premier POC utilisant Promptfoo couplé avec le provider OpenCode SDK : https://github.com/stephane-klein/opencode-promptfoo-poc.
Cette première itération est volontairement minimaliste. J'ai testé :
- 3 LLMs (dans 2 configurations chacune)
- 3 cas de test
L'intégralité de mon évaluation tient dans un seul fichier promptfooconfig.yaml :
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: "Hello World - minimal test"
providers:
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
prompts:
- "Translate the following English text to {{language}}: {{input}}"
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-all
value:
- "Bonjour"
- "monde"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: contains-any
value:
- "Donde esta la biblioteca"
providers:
- "with-agent*"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: not-contains-any
value:
- "Donde esta la biblioteca"
providers:
- "without-agent*"
L'exécution de promptfoo eval donne ceci :
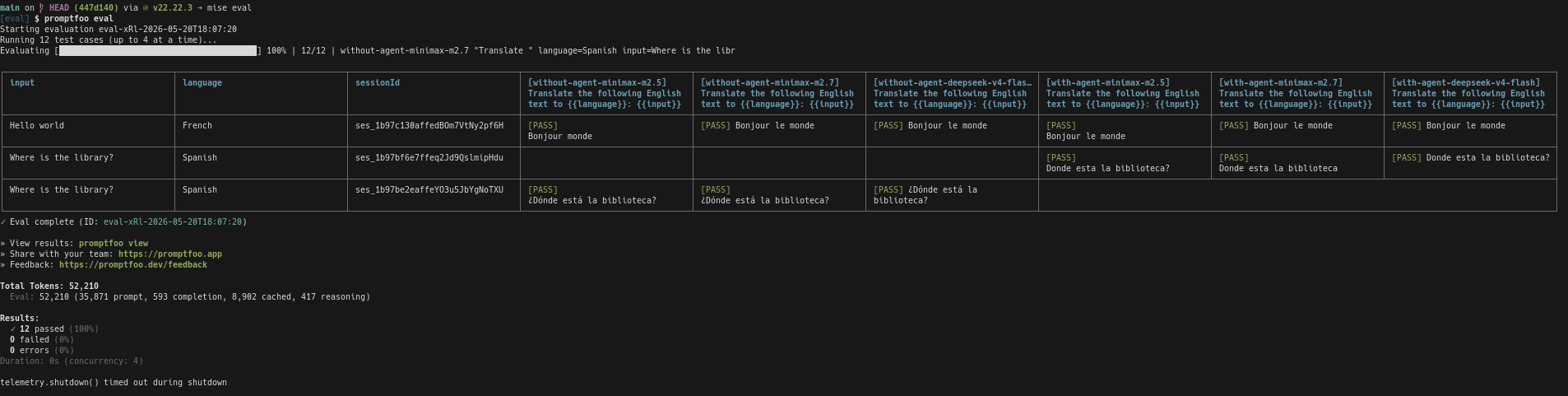
Et voici ce qu'affiche promptfoo viewer dans un browser :
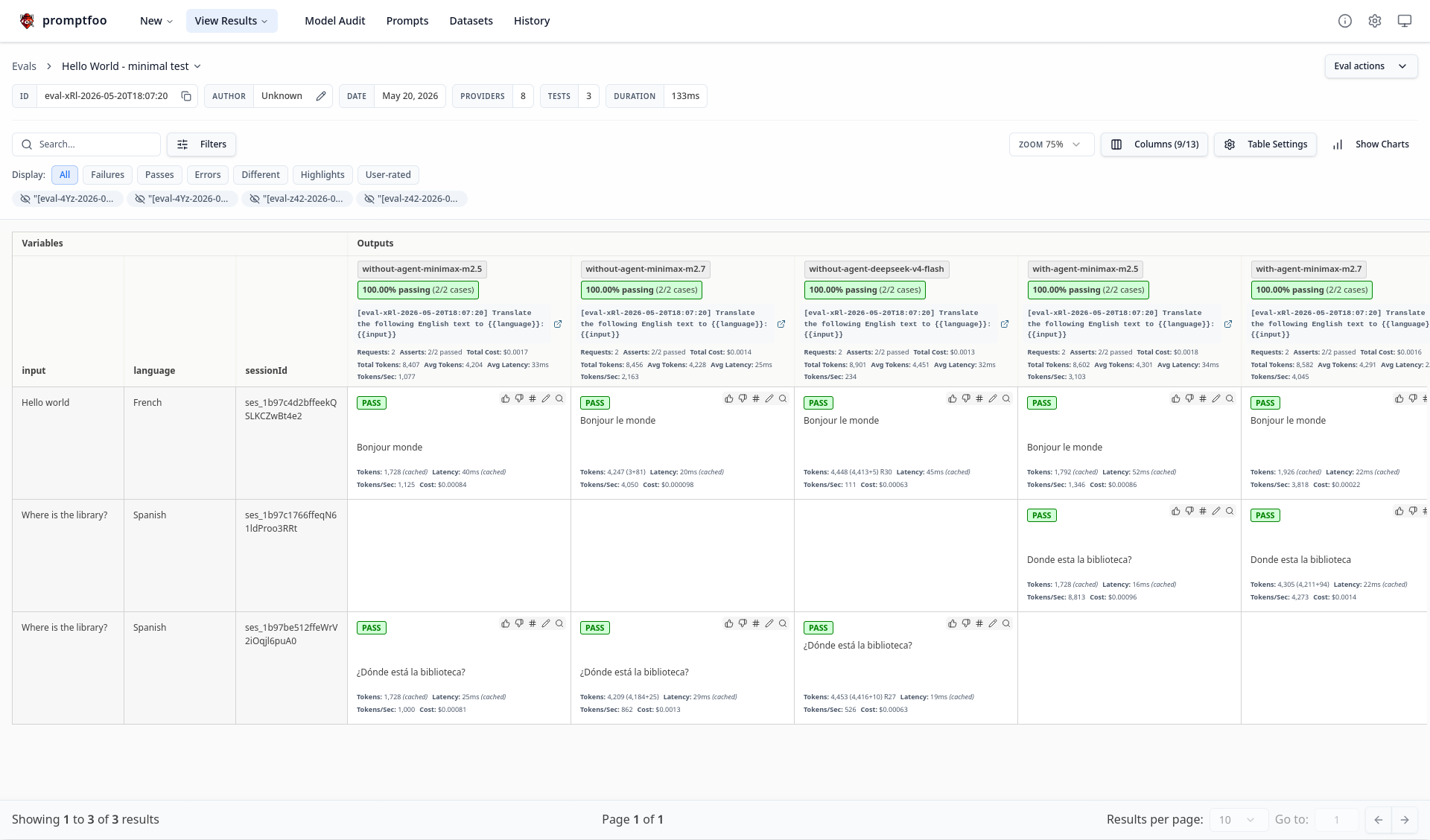
Dans mes tests, j'ai mis en œuvre uniquement contains-all et contains-any, mais Promptfoo propose beaucoup d'autres « Deterministic metrics ».
Promptfoo propose aussi de nombreuses assertions effectuées par des modèles de langage, les « Model-graded metrics », dont la plupart peuvent être qualifiées de LLM-as-a-Judge. Je ne les ai pas encore testées.
Je n'ai pas non plus exploré l'évaluation de « Chat conversations / threads ». Par ailleurs, en examinant la documentation du provider OpenCode SDK, j'ai constaté ce qui me semble être une limitation : il n'est probablement pas possible de changer d'agent dans un thread, c'est-à-dire d'alterner entre le mode plan et le mode build, comme on le ferait dans un usage normal de OpenCode.
Mais après réflexion, il me semble que cette limitation n'est pas importante. Dans un test d'évaluation, chaque cas est un appel unique à l'agent, avec l'historique complet de la conversation fourni en contexte — il n'est pas nécessaire de simuler un flux interactif multi-tours avec alternance d'agents.
Dans ce POC, je configure le provider OpenCode SDK pour qu'il utilise le dossier de configuration ./config/opencode du repository, afin que le harness évalué soit précisément celui qui est versionné, et afin de ne pas subir de perturbation par la configuration OpenCode globale.
Quand j'ai démarré ce POC, j'ai essayé d'indiquer différentes configurations OpenCode au niveau des tests, pour tester différents fichiers AGENTS.md. Mais j'ai constaté que la configuration OpenCode ne peut être définie qu'une seule fois, ici, via une variable d'environnement XDG_CONFIG_HOME.
J'ai mis un certain temps à réaliser que je pouvais procéder autrement, en plaçant les fichiers AGENTS.md dans différents working_dir. Les working_dir se configurent au niveau des providers, voici deux exemples :
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
Cela permet de charger et de tester ./workdir1/AGENTS.md ou ./workdir2/AGENTS.md. Il est possible d'utiliser la même méthode pour évaluer différents SKILLS.md.
Pour le moment, je ne sais pas encore si Promptfoo est un bon outil pour mettre au point mon harness.
Avant de poursuivre mes tests de harness engineering avec Promptfoo, j'aimerais tester agent-catalog-eval pour voir si cet outil serait plus simple à mettre en œuvre.
Comment "harness" s'est répandu en IA et pourquoi ce terme a été choisi
Le week-end dernier, j'ai commencé à chercher d'où venait le terme harness et pourquoi il a été choisi pour désigner ce concept dans les AI agents comme OpenCode ou Claude Code.
Cette note est le résultat de ce travail de recherche, basé sur des échanges avec Sonnet 4.6, des lectures de commentaires Hacker News et divers articles sur le sujet.
En novembre 2025, Anthropic a publié l'article « Effective Harnesses for Long-Running Agents », qui utilise explicitement « agent harness » dans le sens moderne.
Le terme « harness engineering » semble avoir été popularisé par Mitchell Hashimoto dans la section 5 de son billet publié le 5 février 2026. Il y décrit une pratique qu'il a développée au fil de son usage des agents IA :
Je ne sais pas s'il existe un terme largement accepté par l'industrie pour cela, mais j'en suis venu à appeler cela « harness engineering ». C'est l'idée que chaque fois qu'on constate qu'un agent commet une erreur, on prend le temps de concevoir une solution pour que l'agent ne commette plus jamais cette erreur. Je n'ai pas besoin d'inventer de nouveaux termes ici ; s'il en existe un autre, je m'y joindrai.
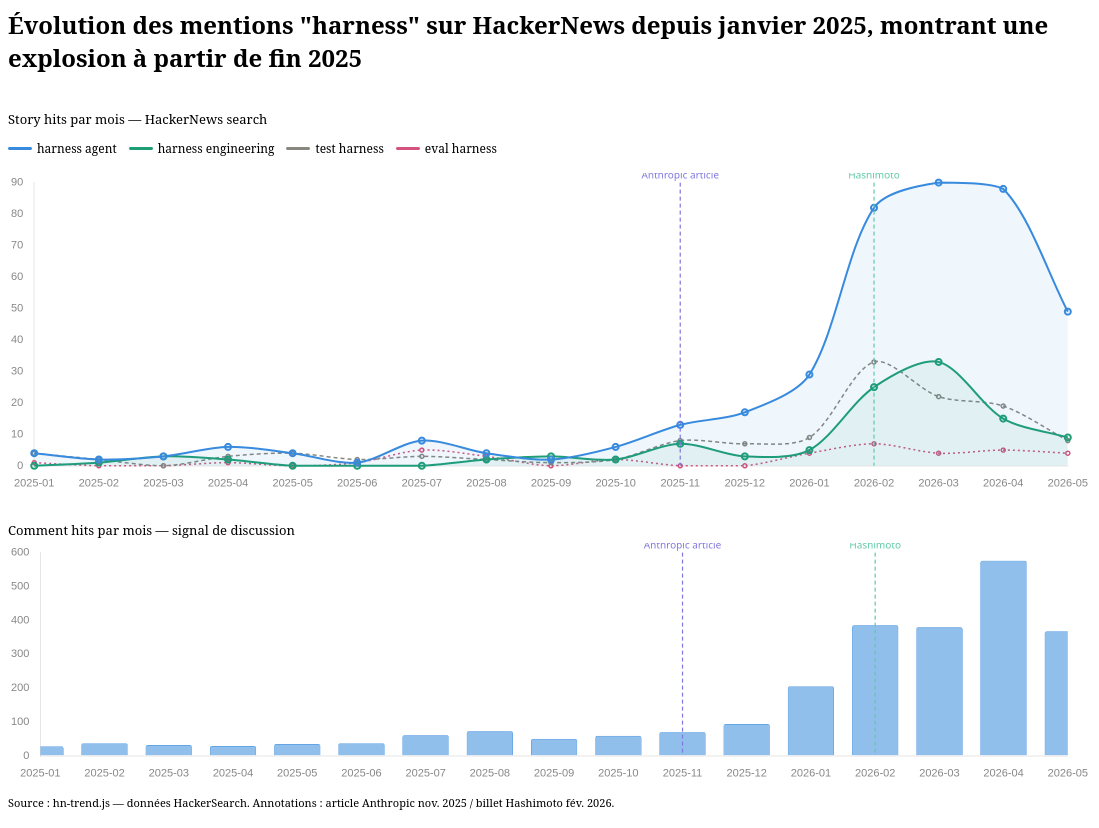 Données extraites avec hackernews-trends-poc.
Données extraites avec hackernews-trends-poc.
Jusqu'à présent, je pensais à tort que l'analogie du harnais correspondait simplement à l'équipement qu'on pose sur un cheval, sans saisir la pertinence de ce terme, par manque de culture de cette langue. En anglais, on trouve les expressions « harness the sun » ou « harness the wind ». Voici la définition du verbe harness :
Verb
harness (third-person singular simple present harnesses, present participle harnessing, simple past and past participle harnessed)
- (transitive) To place a harness on something; to tie up or restrain. Synonym: tackle
« They harnessed the horse to the post. »- (transitive) To capture, control or put to use. « Imagine what might happen if it were possible to harness solar energy fully. »
- (transitive) To equip with armour.
Le terme français qui me semble le plus proche du verbe harness serait « canaliser » ou « dompter ».
Le terme harness désigne donc l'action de canaliser et d'orienter la puissance d'un LLM vers un objectif souhaité.
Avant l'usage du terme harness dans le domaine de l'AI — que ce soit pour agent harness, harness engineering ou LM Evaluation Harness — j'ai découvert en travaillant sur cette note qu'il était déjà utilisé en software engineering, principalement dans l'expression test harness. Il me semble que c'était d'ailleurs l'usage principal du mot dans notre domaine, bien avant qu'il ne soit repris pour les agents IA.
Les concepts que je pense avoir identifiés et que je retiens
- Le harness est un artefact à installer et configurer dans OpenCode. Il est composé de :
- Le harness engineering est le processus humain d'amélioration itérative du harness. Quand l'utilisateur observe une erreur de l'agent, il modifie ou ajoute des fichiers
AGENTS.md,SKILLS.md, des outils MCP ou des configurations pour qu'elle ne se reproduise plus. Ce terme désigne le processus, par opposition au harness qui est l'artefact. - Agent-eval-harness est un outil externe au harness permettant de lancer des sortes de tests unitaires. Il est utilisé pendant les phases de harness engineering pour valider les modifications de façon contrôlée et reproductible.
Cette note ne traite pas de la boucle agent en elle-même — j'ai documenté ce concept séparément ici :
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise.
Le concept de harness vient encadrer cette boucle pour la configurer et la contraindre, mais il ne la définit pas. Comprendre la boucle aide à saisir ce qu'orchestre le harness.
Extrait d'un article de Sebastian Raschka :
Pour clarifier les concepts :
- LLM : le modèle brut de prédiction du prochain token
- Modèle de raisonnement : un LLM optimisé pour produire des traces de raisonnement intermédiaires et se vérifier davantage
- Agent : une boucle qui combine un modèle avec des outils, de la mémoire et des retours d'environnement
- Agent harness : le scaffold logiciel autour d'un agent qui gère le contexte, l'utilisation des outils, les prompts, l'état et le flux de contrôle
- Coding harness : un cas particulier d'agent harness ; un harness spécifique au génie logiciel qui gère le contexte du code, les outils, l'exécution et les retours itératifs
Quelques articles que j'ai lus avec attention :
- Effective harnesses for long-running agents — Anthropic, nov. 2025
- My AI Adoption Journey — Mitchell Hashimoto, fév. 2026
- Components of a Coding Agent — Sebastian Raschka, avr. 2026
En explorant le sujet de harness, je constate que, comme beaucoup de concepts, sa définition peut varier selon les sources et les communautés. Par exemple, l'article Components of a Coding Agent de Sebastian Raschka semble en proposer une définition plus large que Mitchell Hashimoto.
Pour le moment, je souhaite adopter la version de Mitchell Hashimoto, que j'arrive mieux à appréhender et dont je parviens mieux à délimiter le périmètre : un dispositif qui canalise la fougue du LLM, comme le harnais canalise le cheval sauvage.
gh-issue-sync: sync GitHub issues locally and back
gh-issue-sync is a command line tool that syncs GitHub issues to local Markdown files for offline editing, batch updates, and integration with coding agents.
Pull issues locally, refine them until you are satisfied, and sync changes back. Also useful for offline access to your issues.
C'est un outil qui répond à un besoin que j'ai depuis 2018 : préparer avec un process précis des issues GitLab ou GitHub en draft, dans un format texte versionnable, particulièrement utile pendant la phase de meta-spec-writing.
C'est pour répondre à ce besoin que j'avais spécifié les fonctionnalités suivantes dans Projet 24 - Prototyper le gestionnaire de projet de mes rêves :
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
Je trouve curieux de voir émerger des projets comme Beads en octobre 2025 ou gh-issue-sync en décembre 2025, portés par la mouvance Specs Driven Development des agents IA, alors que j'explore ce formalisme depuis environ 2010. Ce qui m'intrigue surtout : pourquoi les développeurs s'intéressent à la spécification maintenant, et pas avant ? J'ai commencé à rédiger des choses à ce sujet, que je souhaite publier.
Le 15 mars dernier, j'ai créé des commandes OpenCode issue-create.md, issue-pull.md, issue-push.md, issue-update.md dont l'objectif était plus ou moins identique à gh-issue-sync : rédiger une issue dans un fichier local, la raffiner, puis l'envoyer vers GitHub. J'ai utilisé ces commandes pour créer les issues du projet sklein-devbox : https://github.com/stephane-klein/sklein-devbox/issues.
En l'état, je ne suis pas satisfait de mon expérience de développeur (DX). Il me semble que la fonctionnalité SKILL.md de gh-issue-sync offre probablement une meilleure architecture que l'utilisation des commandes OpenCode.
Ces prochains jours, je compte tester gh-issue-sync pour un éventuel remplacement. À plus long terme, j'aimerais pousser plus loin le sujet en testant Beads.
Comment déclencher des questions interactives dans OpenCode et ClaudeCode ?
Cela fait plusieurs mois que je me demande comment fonctionne le mécanisme de questions interactives présent dans OpenCode et Claude Code.
Plus précisément, je me demande comment je peux déclencher, de manière certaine, des questions interactives dans mes SKILLS.md.
Dans cet exemple :
> Pose-moi la question pour savoir si je suis une femme ou un homme.
Es-tu une femme ou un homme ?
OpenCode ne me pose pas cette question de manière interactive, la question est posée sous la forme de "texte libre".
J'ai cherché à en savoir plus et voici ce que j'ai trouvé.
Le mécanisme de questions interactives est déclenché par un tool.
- Chez Claude Code, ce tool est nommé "
AskUserQuestion" - Et chez OpenCode, ce tool est nommé simplement "
question"
Et voici le contenu des descriptions de ces tools (qui jouent le rôle de prompt) :
- Pour OpenCode : https://github.com/anomalyco/opencode/blob/dev/packages/opencode/src/tool/question.txt
Use this tool when you need to ask the user questions during execution. This allows you to:
1. Gather user preferences or requirements
2. Clarify ambiguous instructions
3. Get decisions on implementation choices as you work
4. Offer choices to the user about what direction to take.
Usage notes:
- When `custom` is enabled (default), a "Type your own answer" option is added automatically; don't include "Other" or catch-all options
- Answers are returned as arrays of labels; set `multiple: true` to allow selecting more than one
- If you recommend a specific option, make that the first option in the list and add "(Recommended)" at the end of the label
- Pour Claude Code : https://github.com/Piebald-AI/claude-code-system-prompts/blob/main/system-prompts/tool-description-askuserquestion.md
Use this tool when you need to ask the user questions during execution. This allows you to:
1. Gather user preferences or requirements
2. Clarify ambiguous instructions
3. Get decisions on implementation choices as you work
4. Offer choices to the user about what direction to take.
Usage notes:
- Users will always be able to select "Other" to provide custom text input
- Use multiSelect: true to allow multiple answers to be selected for a question
- If you recommend a specific option, make that the first option in the list and add "(Recommended)" at the end of the label
Plan mode note: In plan mode, use this tool to clarify requirements or choose between approaches BEFORE finalizing your plan. Do NOT use this tool to ask "Is my plan ready?" or "Should I proceed?" - use ${EXIT_PLAN_MODE_TOOL_NAME} for plan approval. IMPORTANT: Do not reference "the plan" in your questions (e.g., "Do you have feedback about the plan?", "Does the plan look good?") because the user cannot see the plan in the UI until you call ${EXIT_PLAN_MODE_TOOL_NAME}. If you need plan approval, use ${EXIT_PLAN_MODE_TOOL_NAME} instead.
Aucun des deux prompts ne dit quand ne pas poser les questions en texte libre. Les deux disent "use this tool when you need to ask questions" — mais le modèle juge lui-même si la situation justifie le tool ou une réponse textuelle directe.
Pour être certain que l'agent IA pose une question en mode interactif, il faut lui demander explicitement de l'utiliser, par exemple, avec la mention (use question tool) ou dans cet exemple :
Utilise le tool question pour me poser deux questions :
1. Mon sexe (homme, femme, autre)
2. Mon prénom, avec "Stéphane" comme première option suggérée, et une option pour saisir autre chose
Autres ressources :
- Le code source du tool
questionde OpenCode : https://github.com/anomalyco/opencode/blob/e3c983c21f925fef4b03f46a06663f1b29cfed34/packages/opencode/src/tool/question.ts - https://github.com/vtemian/octto - un plugin permettant de créer des formulaires avancés, avec gestion de branches et 14 types de saisie. À noter : l'interface s'ouvre dans un navigateur, ce qui casse le flux TUI.
J'ai découvert snip et rtk et testé rtk (reduce LLM usage)
Le 13 avril 2026, j'ai découvert le projet snip :
Quelques semaines plus tard, le 29 avril, Alexandre m'a fait découvrir rtk, une alternative à snip.
rtk est un projet Rust dont le développement a commencé le 18 janvier 2026. snip, quant à lui, est un projet Golang initié par un français basé à la Réunion le 15 février 2026, directement inspiré de rtk.
Voici comment le projet snip compare les deux projets :
Design Philosophy
snip chose a fundamentally different approach to LLM token reduction: filters are data, not code. The binary is the engine, filters are YAML data files, and the two evolve independently.
rtk (Rust) snip (Go) Filter authoring Write Rust, recompile, wait for release Write YAML, drop in a folder, done Filter format Compiled into the binary Declarative YAML, engine and filters evolve independently Custom filters Fork the repo, add Rust code Create a .yamlfile in~/.config/snip/filters/Concurrency 2 OS threads Goroutines (lightweight, no thread pool) SQLite Requires CGO + C compiler Pure Go driver, static binary, no dependencies Cross-compilation Per-target C toolchain GOOS=linux GOARCH=arm64 go buildPipeline actions Built-in strategies 19 composable actions (keep, remove, regex, JSON, state machine...) Contributing Rust knowledge required YAML knowledge sufficient Both tools solve the same problem: reducing AI token costs from verbose CLI output. snip's bet is that extensibility wins. When anyone can write a filter in 5 minutes without touching Go or Rust, the filter ecosystem grows faster.
Voici à quoi ressemble un filtre dans rtk : https://github.com/rtk-ai/rtk/blob/master/src/filters/jj.toml.
Et voici l'équivalent pour snip : https://github.com/edouard-claude/snip/blob/master/filters/jj.yaml.
Je trouve la possibilité d'ajouter de nouvelles commandes à snip simplement en créant un fichier YAML intéressante, mais pour le moment je ne sais pas si j'en aurai besoin.
D'autre part, rtk est supporté par Mise : https://mise-versions.jdx.dev/tools/rtk.
Par conséquent, j'ai décidé de tester la configuration de rtk avec OpenCode. Voici le commit d'intégration à sklein-devbox : https://github.com/stephane-klein/sklein-devbox-chezmoi/commit/0fa4917ee2f31605f8d124223ec650961bf057b6.
Voici comment j'ai initialisé le plugin OpenCode pour rtk :
$ rtk init -g --opencode
OpenCode plugin installed (global).
OpenCode: /home/sklein/.config/opencode/plugins/rtk.ts
Restart OpenCode. Test with: git status
--- Telemetry ---
RTK collects anonymous usage metrics once per day to improve filters.
What: command names (not arguments), token savings, OS, version
Why: prioritize filter development for the most-used commands
Who: RTK AI Labs, contact@rtk-ai.app
Rights: disable anytime with `rtk telemetry disable`,
request erasure with `rtk telemetry forget`
Details: https://github.com/rtk-ai/rtk/blob/main/docs/TELEMETRY.md
Enable anonymous telemetry? [y/N] y
Telemetry enabled. Disable anytime: rtk telemetry disable
Et voici un exemple d'utilisation :
$ opencode run "Quels sont les derniers changements de ce projet ?"
> build · minimax-m2.5
$ rtk git log --oneline -10
0fffe04 Remove mode -x dot_config/tmux/scripts/executable_current-path.sh
832f03b Add peeble/ to Chezignore # <m-r> Reset Message
0fa4917 Setup rtk to reduces OpenCode LLM token consumption
983b77d s6-overlay migration to Pebble (#25)
1f7cbcd Start Mise eval before atuin to fix a bug
c8e6194 Remove gopass and GPG agent management since both services start automatically on first use
71e64e1 Enable Mise environment activation so Neovim can access Mise-managed tools
679f53f Purge empty mise installs/ dirs to force reinstall of incomplete tools
4c32db8 Extract init process into standalone script
8258ab9 Add infomation messages in init scripts
...
Je constate que la commande rtk git log est correctement utilisée par OpenCode.
Voici ce que m'affiche la commande rtk gain :
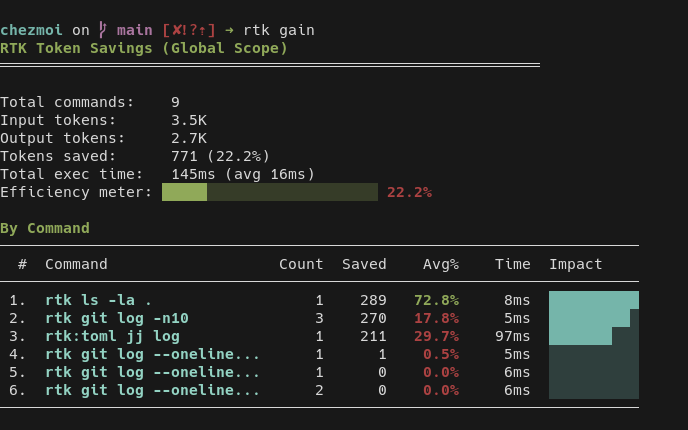
Pour le moment ceci n'est pas représentatif, car je viens de l'installer et j'ai lancé uniquement des tests fictifs.
Je compte publier une note de bilan d'ici quelques semaines pour analyser si c'est vraiment impactant ou non.
Je suis ravi de voir l'offre de modèles OpenCode Go s'enrichir semaine après semaine
Le 12 mars 2026, quand j'ai commencé à utiliser OpenCode Go, seuls 3 modèles étaient disponibles : MiniMax M2.5, Kimi K2.5 et GLM-5. J'ai depuis eu l'agréable surprise de voir arriver de nouveaux modèles Open Weights, souvent dès le lendemain de leur publication.
Aujourd'hui, l'offre est bien plus vaste :
- 18 mars, ajout de MiniMax M2.7
- 19 mars OpenCode supprime le support d'accès à l'offre Claude Pro
- 2 avril, ajout de MiMo-V2-Pro et MiMo-V2-Omni de Xiaomi
- 7 avril, ajout de GLM-5.1
- 15 avril, ajout de Qwen 3.5 Plus et Qwen3.6 Plus
- 20 avril, ajout de Kimi K2.6
- 22 avril, ajout de MiMo v2.5 et MiMo v2.5 Pro de Xiaomi
- 24 avril, ajout de DeepSeek V4 Pro et DeepSeek V4 Flash
Et depuis, j'ai pris la fâcheuse habitude — un peu par FoMo, je l'avoue — de consulter presque une fois par jour le compte Twitter de OpenCode (https://xcancel.com/opencode/) pour voir si un nouveau modèle est sorti.
Après 45 jours d'utilisation de OpenCode Go à 10$ par mois, je n'ai jamais été limité par les quotas
Comme je l'avais décidé dans ma note de découverte de OpenCode Go, j'utilise OpenCode Go depuis le 12 mars 2026.
Voici mes coûts d'utilisation par jour du mois de mars :
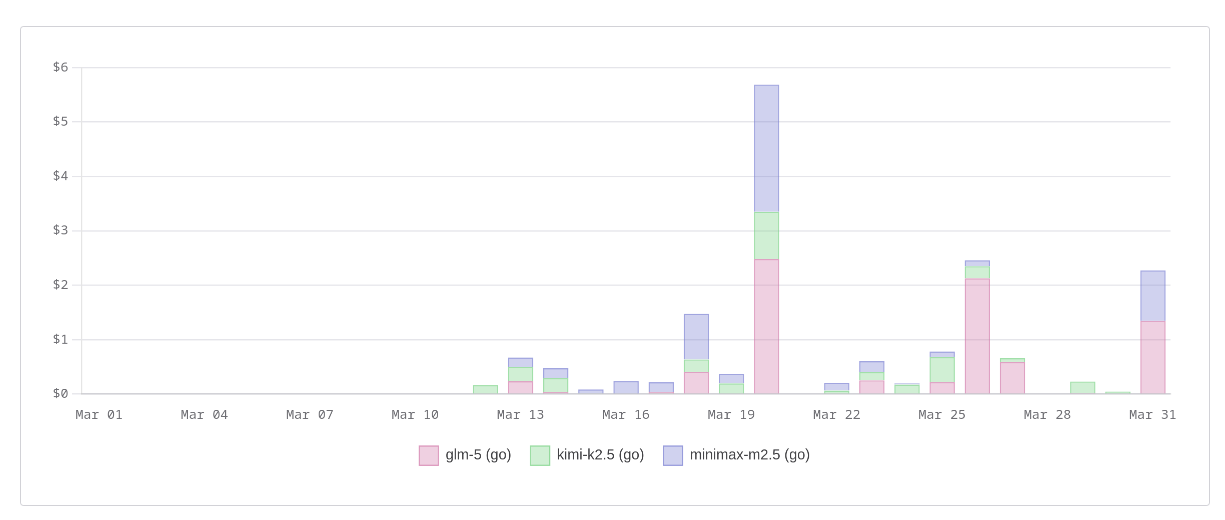
Et ceux du mois d'avril :
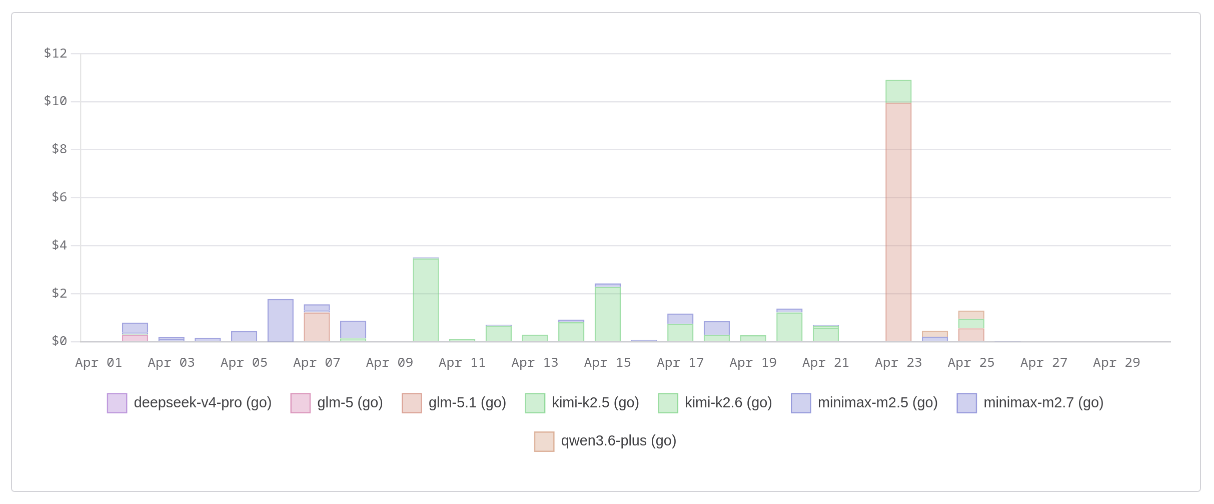
Mais attention, la lecture de ce graphe peut être trompeuse : ces montants correspondent au coût réel de l'offre OpenCode Zen, de type Pay-As-You-Go. Concrètement, je paie 10 $/mois avec l'offre OpenCode Go, qui me donne l'équivalent d'environ 60 $ de crédits Zen.
Après environ 14 jours sur mon abonnement d'avril — soit près de la moitié du mois —, j'ai consommé 35 % de mon quota. Pour le mois de mars, je n'ai pas de chiffre précis en tête, mais il me semble que j'avais atteint environ 60 %.
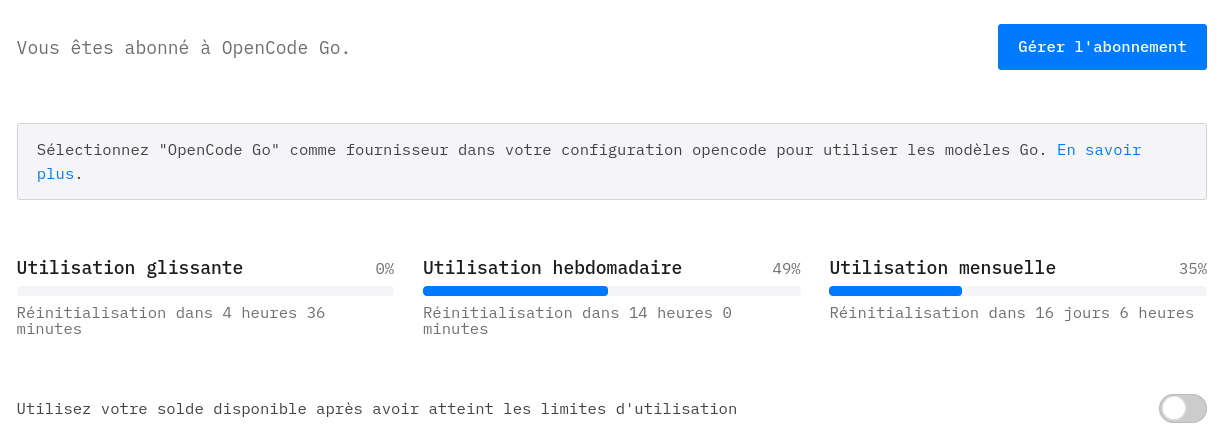
En 45 jours d'utilisation, je n'ai jamais atteint les limitations des fenêtres de 5 h, ni les limites hebdomadaires.
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Dernière page.