
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (4 notes) :
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Journal du lundi 09 septembre 2024 à 15:00
Dans cette note, j'essaie autant que possible de comparer des offres Bare-metal server, Elastic Metal et Virtual Instances de Scaleway, pour une puissance égale.
Je lis ici que les Virtual Instances "Workload-Optimized - POP2HC" sont exécutés sur des serveurs « AMD EPYC™ 7003 Series processors ».
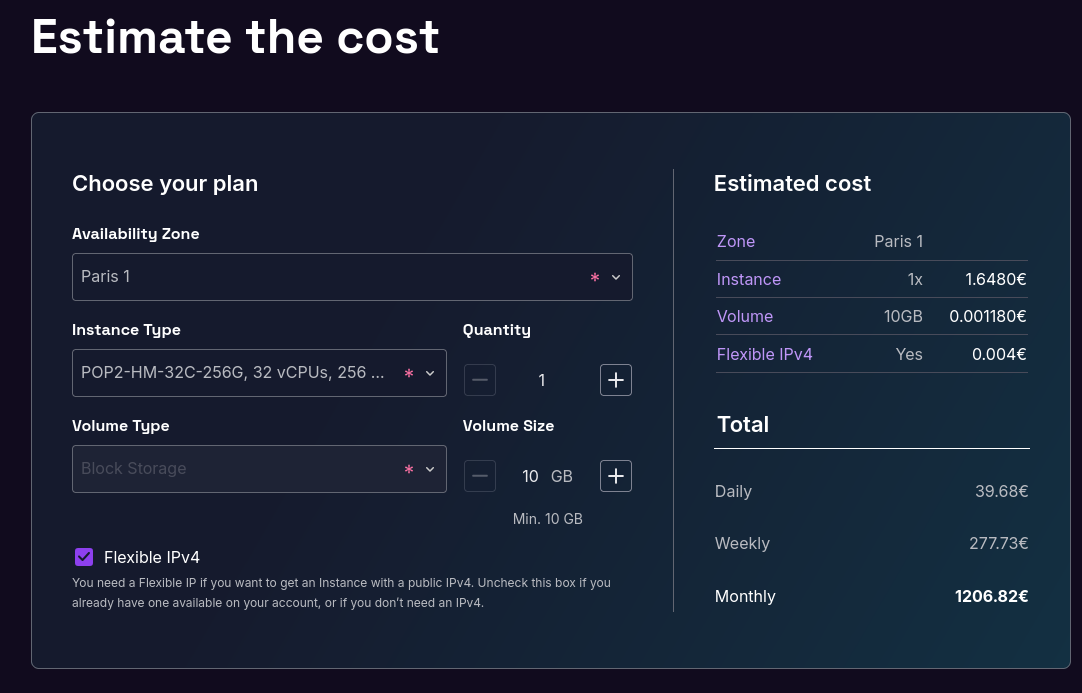
Le serveur Dedibox Core-9-L avec un CPU "AMD EPYC 7313P" fait partie de la famille des 7003, équivalent je pense aux serveurs qui font tourner les Virtual Instances POP3HC.

Coté Elastic Metal, j'ai identifié le modèle EM-I210E-NVME avec un processeur de la famille 7003 : "AMD EPYC 7313P".
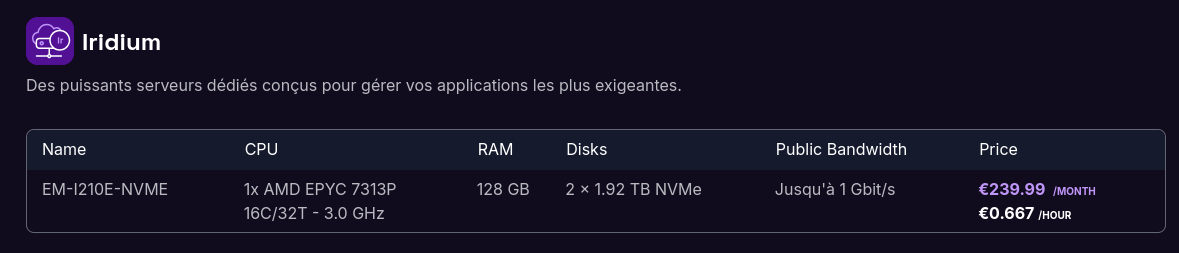
Tarif de ce serveur avec un engagement au mois : 239,99 € / mois et sans cet engagement : environ 480 € / mois.
Si je fais un bilan de comparaison :
- Dedibox
Core-9-L: 249 € / mois avec 256 GB de Ram et 3x1TB, engagement au mois. À cela il faut ajouter 329.99 € de frais de setup. - Elastic Metal
EM-I210E-NVME: 239 € / mois avec 128 GB de Ram et 2x1.9 TB, engagement au mois. À cela il faut ajouter 239,99 € de frais de setup. - Elastic Metal
EM-I210E-NVME: 480 € / mois avec 128 GB de Ram et 2x1.9 TB, engagement à l'heure - Virtual Instances
POP2HC: 1464 € / mois, avec 256 GB de Ram et 3TB de volume
À puissance égale, une Virtual Instances est approximativement 6 fois plus cher qu'une Dedibox (sans prise en compte des frais de setup Dedibox qui s'élèvent à 329 €).
Il est important de noter que je pourrais manquer d'informations concernant les serveurs hébergeant les Virtual Instances, ce qui pourrait entraîner des erreurs dans mon analyse.
Je tiens également à préciser qu'une Virtual Instance offre, en théorie, une meilleure fiabilité grâce à la possibilité — toujours en théorie — de migrer à chaud d'un serveur à un autre.
Dernière page.