
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (10 notes) :
Journal du jeudi 10 octobre 2024 à 11:26
Par sérendipité #JaiÉcouté la #vidéo "Table ronde sur la mutualisation - Congrès ADULLACT 2024"
Table ronde sur la mutualisation - Congrès ADULLACT 2024
Animée par François Élie (Président de l'ADULLACT et Élu local à la ville et à l'Agglomération d'Angoulême), retrouvez cette table-ronde composée de :
- Line Galy, Directrice du Pôle Numérique et Donnée pour Montpellier Méditerranée Métropole;
- Stéphane Vangheluwe, Directeur du SITIV et Trésorier représentant DÉCLIC;
- Jean-Charles Mandique, Directeur Général des Services de Numérian;
- Faycal Braiki, Directeur Général des Services du SITPI.
#JaiDécouvert beaucoup de choses en écoutant cette vidéo. #JaimeraisUnJour prendre le temps de la réécouter afin de rédiger une note qui contiendrait toutes les informations intéressantes que j'y ai trouvées.
Je trouve le sujet de la mutualisation des services et des logiciels à l'échelle des communes passionnant.
Fonctionnalité cluster and edit de OpenRefine
Il y a quelques semaines, #JaiDécouvert le #logiciel OpenRefine, qui permet de réaliser des tâches de #data-curation , plus précisément de #data-cleaning — mais pas seulement.
#JaimeraisUnJour prendre le temps d'essayer de nettoyer mes données Toggl avec OpenRefine.
Je lis ici que je peux manipuler plusieurs type de format de données :
From these sources, you can load any of the following file formats:
- comma-separated values (CSV) or text-separated values (TSV)
- Fixed-width columns
- JSON
et
OpenRefine can connect to PostgreSQL, MySQL, MariaDB, and SQLite database systems
Je souhaite particulièrement tester la fonctionnalité cluster and edit de OpenRefine et surtout les différentes méthode de clustering.
Voir aussi csvbase.
Site web : https://github.com/getredash/redash
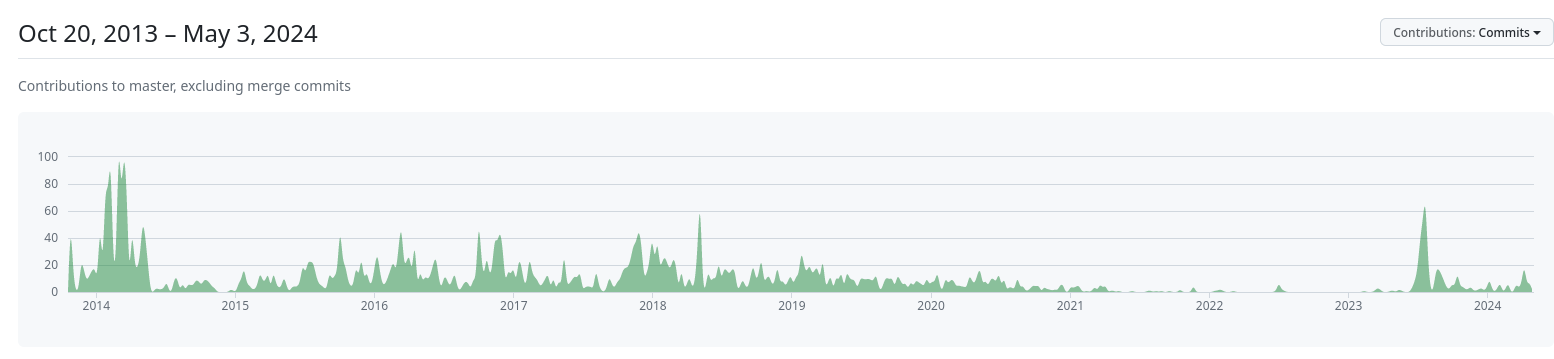
Je constatais que ce projet était mort depuis son rachat en juin 2020 par Databricks : Redash is joining Databricks mais j'ai l'impression que le projet a repris vie depuis mi 2023 :
Site : https://openrefine.org/
Permet entre autre de réaliser des opérations de Data Curation.
Semble compter plus de 80 employés d'après LinkedIn. Basé à New York.
Lancé en 2014.
Semble compter plus de 300 employés d'après LinkedIn. Basé à San Francisco.
Lancé en 2014, en même temps que Shortcut
Semble compter plus de 70 employés d'après LinkedIn. Basé à San Francisco.
Lancé en 2019, bien après Productboard et Shortcut.
Site web https://observablehq.com/
Ce dépôt GitHub sert de playground pour documenter mes découvertes et expérimentations avec Observable : https://github.com/stephane-klein/observable-playground
Dernière page.