
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (48 notes) :
Serveur MCP web fetch local sous Claude Desktop pour contourner les blocages IP de certains sites
Mon installation de Claude Desktop sous Fedora était principalement motivée par l'exécution locale du tool "Web fetch tool" d'Anthropic, afin de contourner le blocage des IP d'Anthropic par certains sites web.
Après avoir passé en revue une demi-douzaine de serveurs MCP de type « web fetch », j'ai retenu zcaceres/fetch-mcp, implémenté en Javascript, qui, après quelques heures d'utilisation, semble bien fonctionner.
Voici mon fichier ~/.config/Claude/claude_desktop_config.json après configuration du serveur MCP :
{
"mcpServers": {
"fetch": {
"command": "npx",
"args": ["mcp-fetch-server"],
"env": {
"DEFAULT_LIMIT": "0"
}
}
},
"isUsingBuiltInNodeForMcp": false,
"isDxtAutoUpdatesEnabled": false,
"preferences": {
"coworkScheduledTasksEnabled": true,
"ccdScheduledTasksEnabled": true,
"coworkWebSearchEnabled": true,
"sidebarMode": "chat"
}
}
zcaceres/fetch-mcp supporte différents types de formats de fetching :
All tools accept the following common parameters:
- fetch_html — Fetch a website and return its raw HTML content.
- fetch_markdown — Fetch a website and return its content converted to Markdown.
- fetch_txt — Fetch a website and return plain text with HTML tags, scripts, and styles removed.
- fetch_json — Fetch a URL and return the JSON response.
- fetch_readable — Fetch a website and extract the main article content using Mozilla Readability, returned as Markdown. Strips navigation, ads, and boilerplate. Ideal for articles and blog posts.
- fetch_youtube_transcript — Fetch a YouTube video's captions/transcript. Uses
yt-dlpif available, otherwise extracts directly from the page. Accepts an additionallangparameter (default:"en") to select the caption language.
C'est le LLM qui choisit quel tool utiliser. J'ai demandé à Claude Sonnet 4.6 comment il effectuait son choix : par défaut, il utilise fetch_markdown ; lorsqu'il sait qu'un site contient des publicités, une sidebar, etc. — généralement les sites de presse —, il utilise fetch_readable.
J'ai observé que les tools fetch_markdown, fetch_readable et fetch_json fonctionnent bien, mais fetch_youtube_transcript n'a pas fonctionné chez moi. D'après les logs, ce tool semble contenir un bug. #JaimeraisUnJour essayer de le corriger.
J'ai découvert Promptfoo qui permet de faire du LLM Eval
Cette note a été partiellement écrite fin novembre 2025 et publiée 3 mois plus tard, fin février 2026.
Souhaitant améliorer mes prompts et combler mes lacunes en prompt engineering, je me suis mis à chercher des outils permettant de pratiquer quelque chose qui ressemblerait au Test driven development appliqué à la conception de prompts.
Via Claude Sonnet 4.5, #JaiDécouvert Promptfoo (https://github.com/promptfoo/promptfoo), un framework Javascript permettant notamment de faire du LLM Eval.
Cela fait plusieurs mois que je croise l'expression LLM Eval, sans avoir jamais pris le temps de comprendre ce que ce concept signifie précisément.
D'après ce que j'ai compris, la différence essentielle entre Unit testing et LLM Eval, c'est que les tests unitaires sont déterministes, alors que la qualité des réponses des LLM est évaluée de manière probabiliste.
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
J'ai découvert AIChat, alternative à llm cli
Dans ce thread, #JaiDécouvert AIChat (https://github.com/sigoden/aichat), une alternative à llm (cli) codée en Rust.
AIChat is an all-in-one LLM CLI tool featuring Shell Assistant, CMD & REPL Mode, RAG, AI Tools & Agents, and More.
En parcourant le README.md, j'ai l'impression que AIChat propose une meilleure UX que llm (cli).
Je constate aussi que AIChat offre plus de fonctionnalités que llm (cli) :
- AI Tools & MCP
- AI Agents
- LLM Arena
- La partie RAG semble plus avancée
Ce qui attire le plus mon attention, c'est le sous-projet llm-functions qui, d'après ce que j'ai lu, permet de créer très facilement des tools en Bash, Python ou Javascript. Exemples :
J'ai hâte de tester ça 🙂 ( #JaimeraisUnJour ).
Par contre, llm-functions ne semble pas encore permettre la configuration de Remote MCP server.
Je suis aussi intéressé par cette issue : TUI for managing, searching, and switching between chat sessions.
Un point qui m'inquiète un peu : le projet semble peu actif ces derniers mois.
Journal du lundi 24 novembre 2025 à 14:35
#JaiÉcouté la vidéo "NLP : Comprendre le Word Embedding à travers Word2Vec" du professeur Jaouad Dabounou. Elle m'a aidé à comprendre les bases du fonctionnement de word2vec. Je l'ai trouvée plutôt accessible.
#JaimeraisUnJour approfondir le sujet et peut-être construire un petit embeddings Models basé sur word2vec pour le tester. Je ne suis pas certain que ce soit à ma portée, mais l'exercice m'intéresse.
J'ai découvert les types "unknown" et "never" en TypeScript
En TypeScript, dans mon projet professionnel, #JaiDécouvert le type unknown qui ressemble à any mais qui est différent.
Exemple (produit par Claude Sonnet 4.5) avec any :
let value: any;
value.foo.bar(); // No error, even if it crashes at runtime
value.trim(); // No error, even if value is a number
Exemple avec unknown :
let value: unknown;
value.trim(); // Error: Object is of type 'unknown'
// You must narrow the type first
if (typeof value === 'string') {
value.trim(); // OK, TypeScript knows it's a string
}
unknown a été introduit dans la version 3.0 de TypeScript en 2018 : Announcing TypeScript 3.0 - The unknown type.
J'ai trouvé les réponses à cette question StackOverflow intéressantes : 'unknown' vs. 'any'.
C'est peut-être parce que je ne suis pas habitué à la documentation de TypeScript , mais j'ai l'impression que la fonctionnalité unknown n'est pas correctement documentée. Par exemple, je suis surpris de trouver presque rien à son sujet dans la page Everyday-types , ni dans les chapitres "Reference" :
Et rien non plus dans les tutoriels.
Au passage, j'ai aussi découvert le type never.
#JaimeraisUnJour prendre le temps de parcourir la documentation de TypeScript de manière exhaustive. Jusqu'à présent, je n'en ai jamais eu réellement besoin, car je n'ai jamais contribué à de projet écrit en TypeScript. Mais maintenant, cela devient une nécessité pour mon projet professionnel.
Quel impact Tailwind CSS a-t-il sur la taille des pages d'un site de contenu ?
En février 2023, j'écrivais ceci :
Par ailleurs, je m'interroge sur l'impact du paradigme Tailwind CSS (utility CSS) concernant l'empreinte mémoire des pages.
J'ai le sentiment que la profusion d'attributsclass="..."va probablement augmenter considérablement la taille des pages.
#JaimeraisUnJour prendre le temps de mesurer cet aspect.
Cette question continue de me trotter dans la tête et mon intuition a évolué au fil du temps. J'ai maintenant l'intuition qu'une compression Brotli fonctionnerait efficacement avec le code Tailwind CSS.
Ce matin j'ai enfin pris le temps de faire des mesures.
J'ai choisi d'effectuer mes mesures sur le site de Blast qui est un site de contenu implémenté en Tailwind CSS.
Voici les mesures que j'ai effectuées :
- Home page https://www.blast-info.fr
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
453 Ko - Taille mémoire du HTML du
body, récupéré avec l'inspecteur Firefox via "copier l'intérieur du HTML" :178Ko - En supprimant tous les attributs
class="...", je passe à145Ko, soit une empreinte brute des attributsclassde33Ko(environ 18% du body) - Taille mémoire du texte seul :
5ko(2%) - Taille du body compressé Brotli :
25Ko - Taille du body sans attributs
class="..."compressé Brotli :23Ko, soit2Kopour les attributs classe (environ8%)
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
- Page intérieure https://www.blast-info.fr/articles/2025/macron-bayrou-vers-un-jour-sans-fin-I0AwyT5KTf6_0ywKmLShVQ
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
404 Ko - Taille mémoire brute du HTML du
body, récupéré avec l'inspecteur Firefox via "copier l'intérieur du HTML" :281ko - En supprimant tous les attributs
class="...", je passe à251Ko, soit une empreinte brute des attributsclassde30Ko(environ 10% du body) - Taille mémoire du texte seul :
34ko(environ 12%) - Taille du body compressé Brotli :
43Ko - Taille du body sans attributs
class="..."compressé Brotli :40Ko, soit3Kopour les attributs classe (environ6%)
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
Une fois compressé, la partie Tailwind CSS représente 2Ko à 3Ko par page. Il faut noter que ces valeurs constituent probablement une estimation haute, car un site utilisant le paradigme CSS traditionnel emploie généralement aussi des class="…" dans ses pages HTML.
Mon constat : je pense que le surcout de Tailwind CSS sur la taille des pages d'un site de contenu demeure négligeable après compression.
Une autre question que je me pose : quel est l'impact de Tailwind CSS sur l'utilisation mémoire du navigateur ?
J'ai pris conscience de l'intérêt de DMARC et de l'alignement SPF et DKIM
Dans le contexte de ma mission Freelance, je poursuis l'actualisation de mes compétences en délivrabilité d'e-mail. J'en profite pour rédiger une note sur DMARC.
DMARC existe depuis 2012, mais je n'avais jamais vraiment creusé le sujet. Je l'avais seulement survolé. Jusqu'à récemment, je n'avais en tête que la fonction "monitoring" :
Sans avoir mesuré l'importance de la partie policy :
If the email fails the check, depending on the instructions held within the DMARC record the email could be delivered, quarantined or rejected.
Je pensais naïvement que les vérifications SPF et DKIM réalisées par les email service providers étaient suffisantes.
Je n'avais pas réalisé l'importance du SPF alignment and DKIM alignment.
Le problème vient du fait que SPF et DKIM vérifient le domaine contenu dans MailFrom (connu aussi sous les noms Return-Path, Bounce Address, ou Envelope From). Ces contrôles s'assurent que le serveur émetteur peut légitimement envoyer des emails pour ce domaine et que le message n'a pas été modifié durant le transport.
Cependant, ces vérifications ne protègent pas du spoofing. Les clients mail n'affichent pas le champ MailFrom, mais le champ From:. Un attaquant peut donc envoyer un email avec un domaine validé par SPF et DKIM tout en utilisant un champ From: qui ne lui appartient pas.
L'alignement vérifie que le domaine utilisé pour les contrôles SPF et DKIM correspond au domaine du champ From:.
Si les domaines diffèrent, le serveur receveur exécute la politique DMARC : reject pour rejeter l'email ou quarantine pour le diriger vers les spam.
De plus, j'ai découvert que DMARC était devenu petit à petit obligatoire :
Comply with email providers requirements: in 2024, Google and Yahoo started requiring DMARC on incoming mail from high-volume senders, and Microsoft followed in 2025. If you send emails to Gmail addresses, you may be affected by this. Even if you aren’t, this is likely just Google’s and Yahoo’s first step in a path to enforce DMARC checks on all incoming email, and organizations must prepare in advance.
Je viens de réaliser que c'est sans doute à cause de l'absence de DMARC sur mon domaine (stephane-klein.info) qui explique pourquoi en janvier 2024, un ami ne recevait aucun de mes mails sur sa boite mail Orange.
$ dig TXT _dmarc.stephane-klein.info +short
;; communications error to 127.0.0.53#53: timed out
Il y a quelques jours, je me suis lancé dans la configuration DMARC de mon domaine.
J'ai commencé par chercher des services de DMARC reporting.
Je suis dans un premier temps tombé sur Google Postmaster Tools, mais celui-ci est limité aux boites mails Gmail.
En cherchant des outils d'inbox placement dans le Subreddit EmailMarketing, j'ai découvert GlockApps qui permet aussi de faire du DMARC reporting.
Ensuite, en étudiant l'excellente documentation dmarc.wiki, j'ai découvert le service DMARCwise réalisé par un Indie Hacker italien : Matteo Contrini.
Il est gratuit pour un usage personnel :
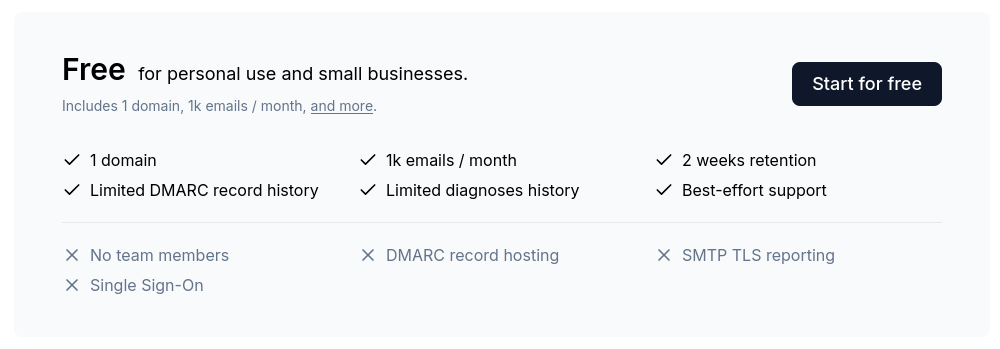
J'ai testé ce service et je l'ai trouvé excellent !
Au départ, j'ai commencé par activer graduellement DMARC comme conseillé ici :
$ dig TXT _dmarc.stephane-klein.info +short
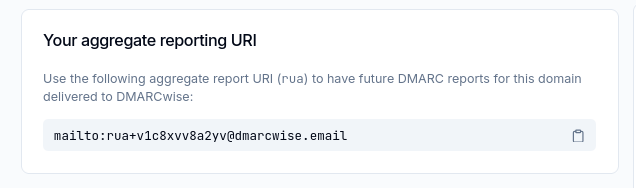
"v=DMARC1; p=none; rua=mailto:rua+v1c8xvv8a2yv@dmarcwise.email;"
L'adresse mail de collecte rua+v1c8xvv8a2yv@dmarcwise.email m'a été donné par DMARCwise :
J'ai ensuite lancé un "DMARC diagnostics" :
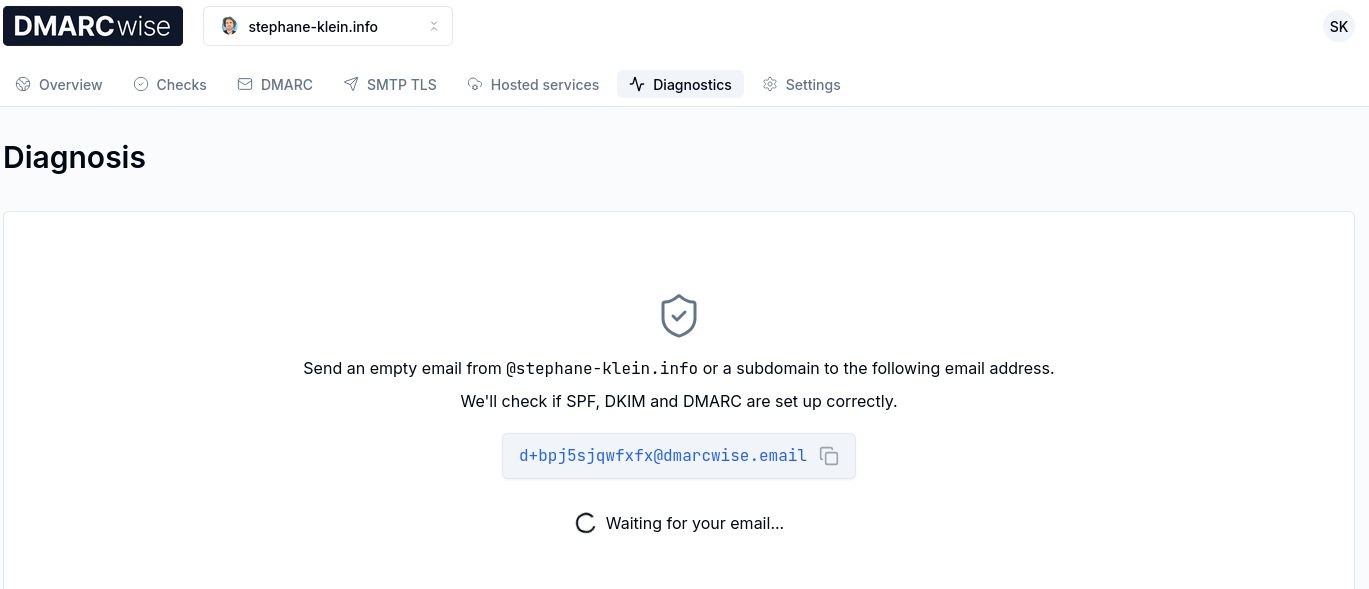
Et j'ai constaté que tout était parfaitement configuré :
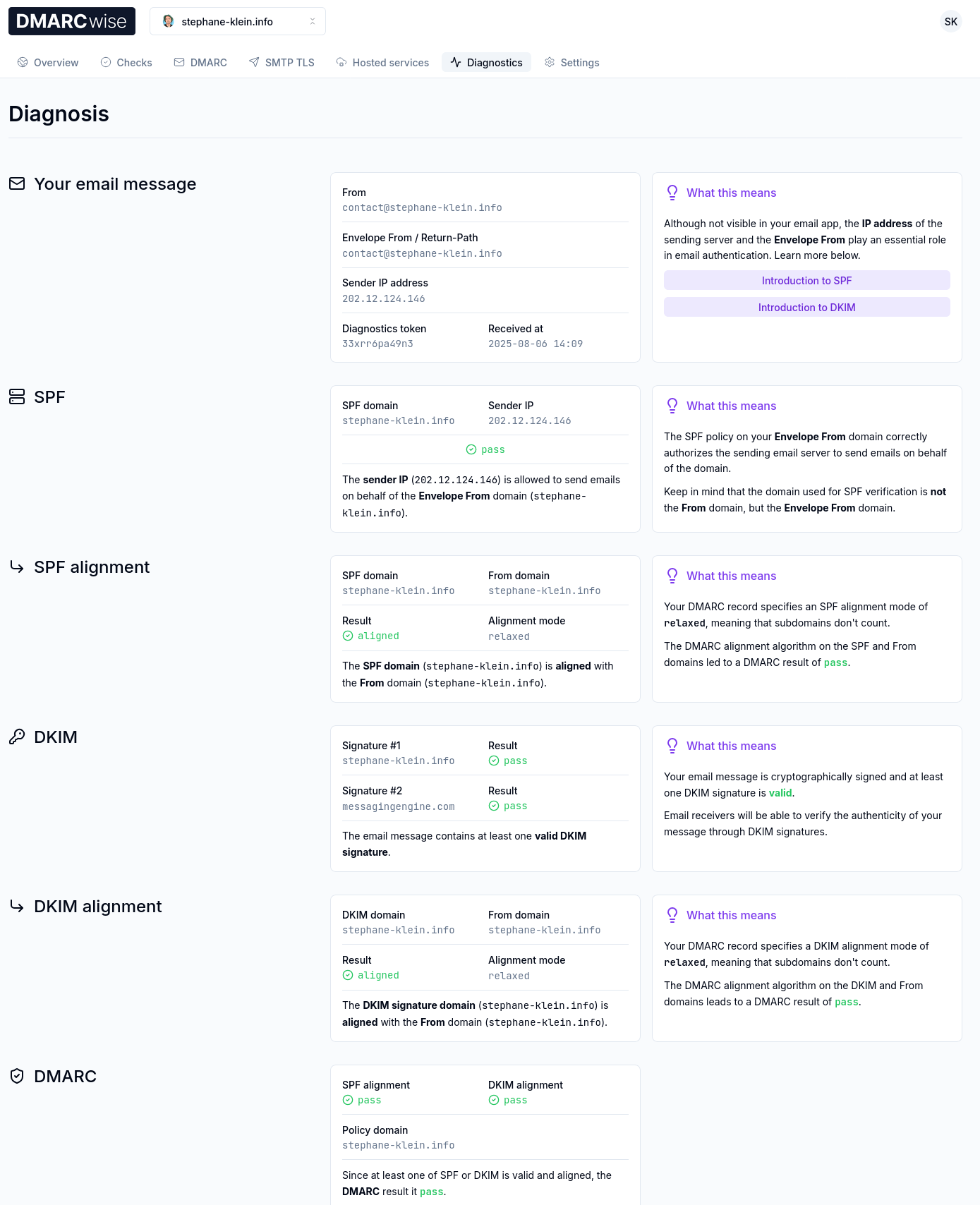
Après réflexion, étant donné que je suis le seul émetteur d'e-mail pour mon domaine, j'ai jugé que je pouvais directement passer de pas de policy (p=none) à p=reject; pct=100;.
$ dig TXT _dmarc.stephane-klein.info +short
"v=DMARC1; p=reject; pct=100; rua=mailto:rua+v1c8xvv8a2yv@dmarcwise.email;"
Après 3 jours d'utilisation de DMARCwise, l'expérience utilisateur me plaît énormément. Il me semble que tout est soigneusement conçu, Matteo Contrini fait clairement attention aux détails !
Voici à quoi cela ressemble :
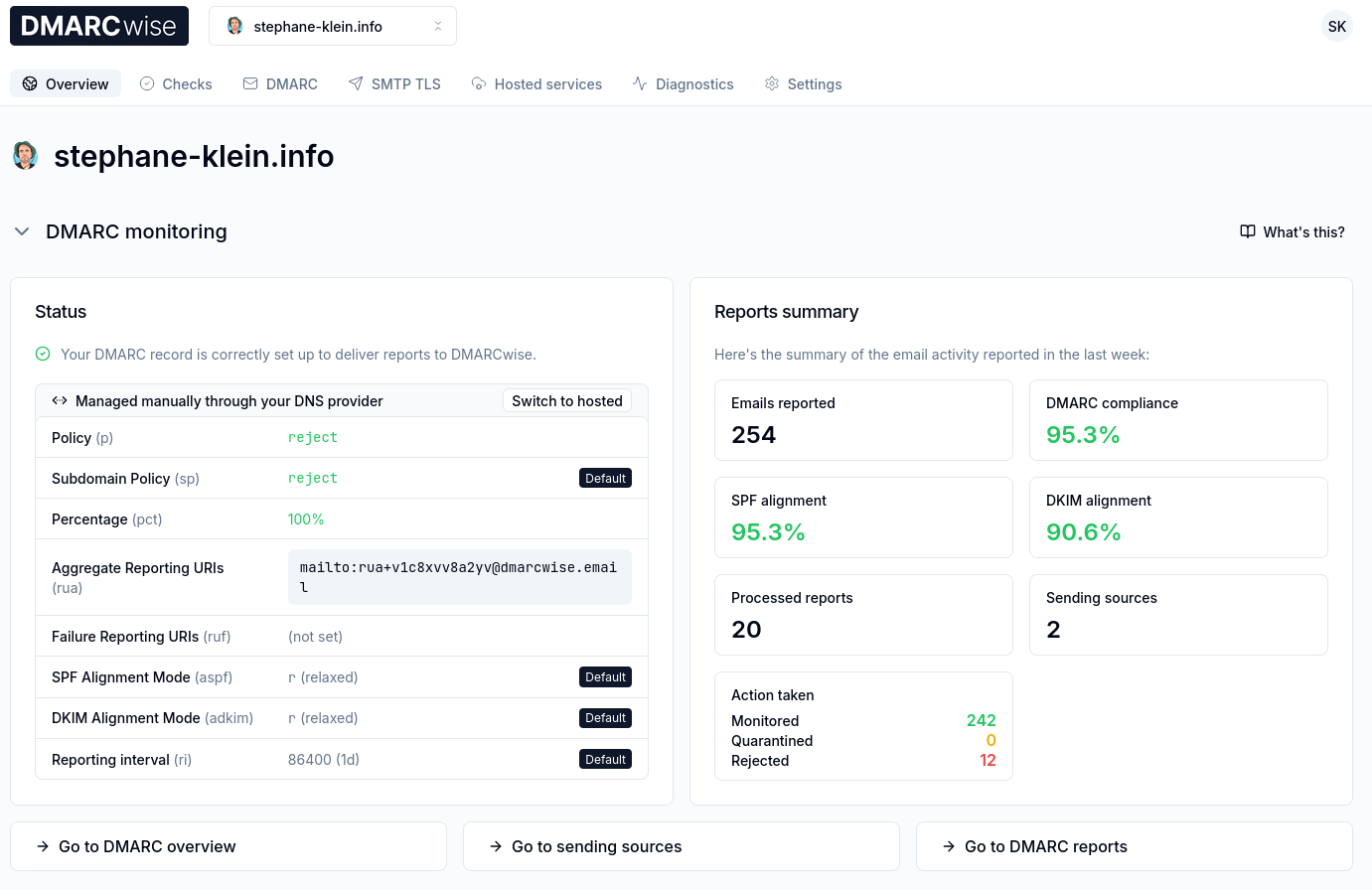
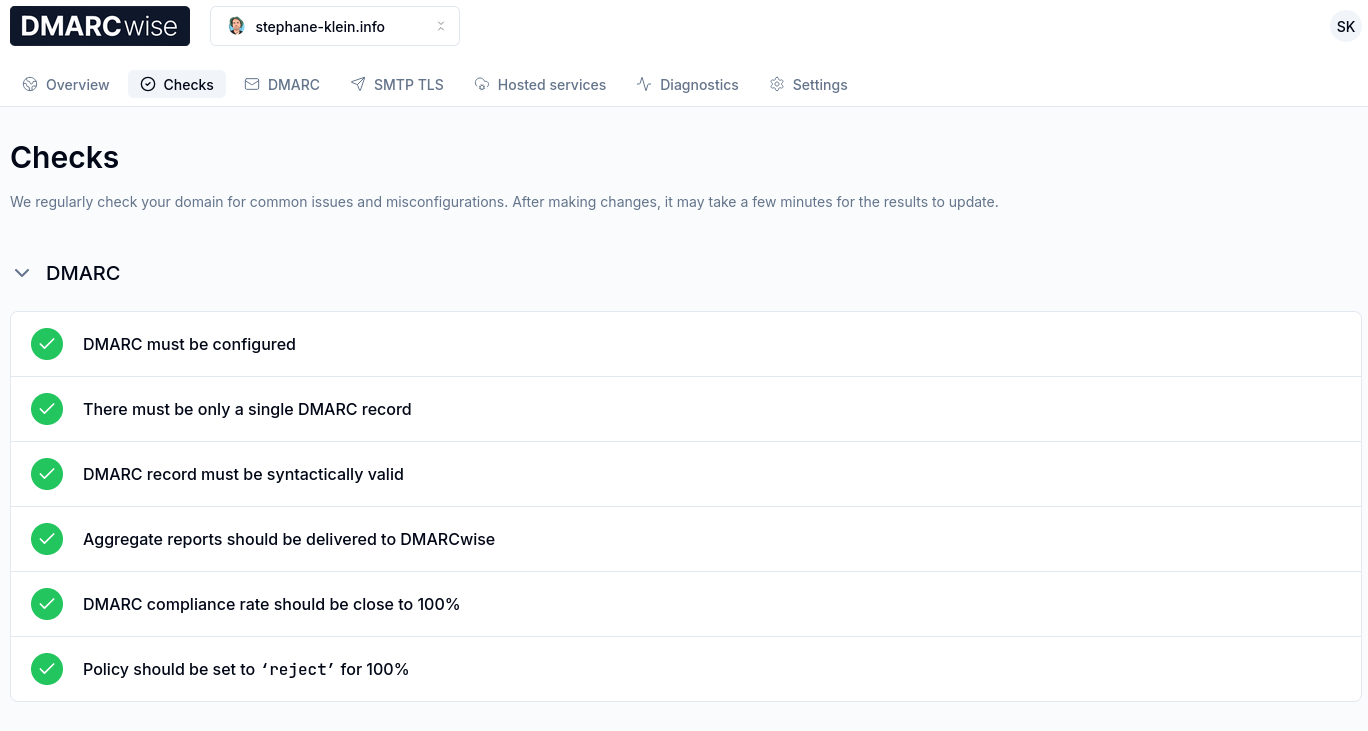
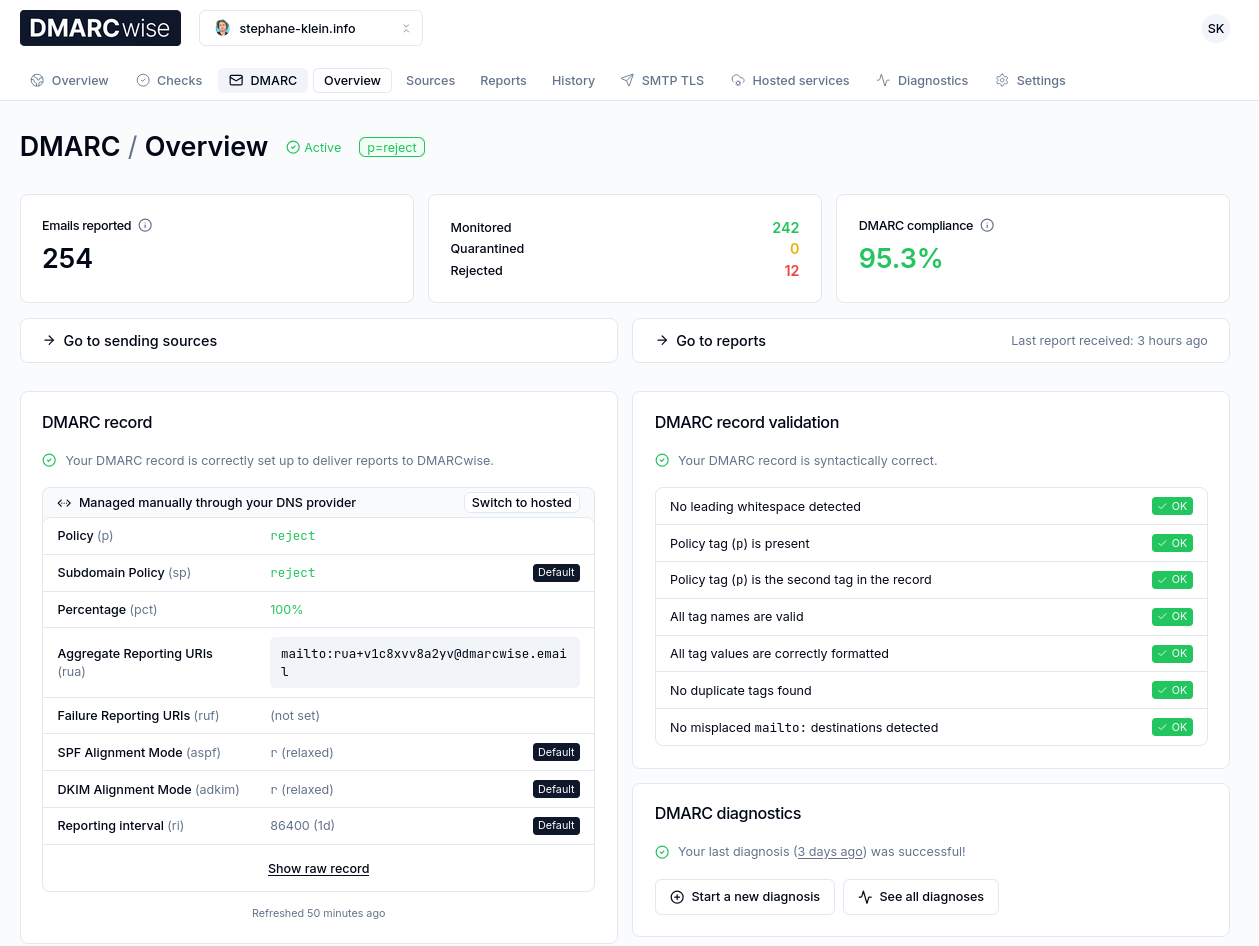
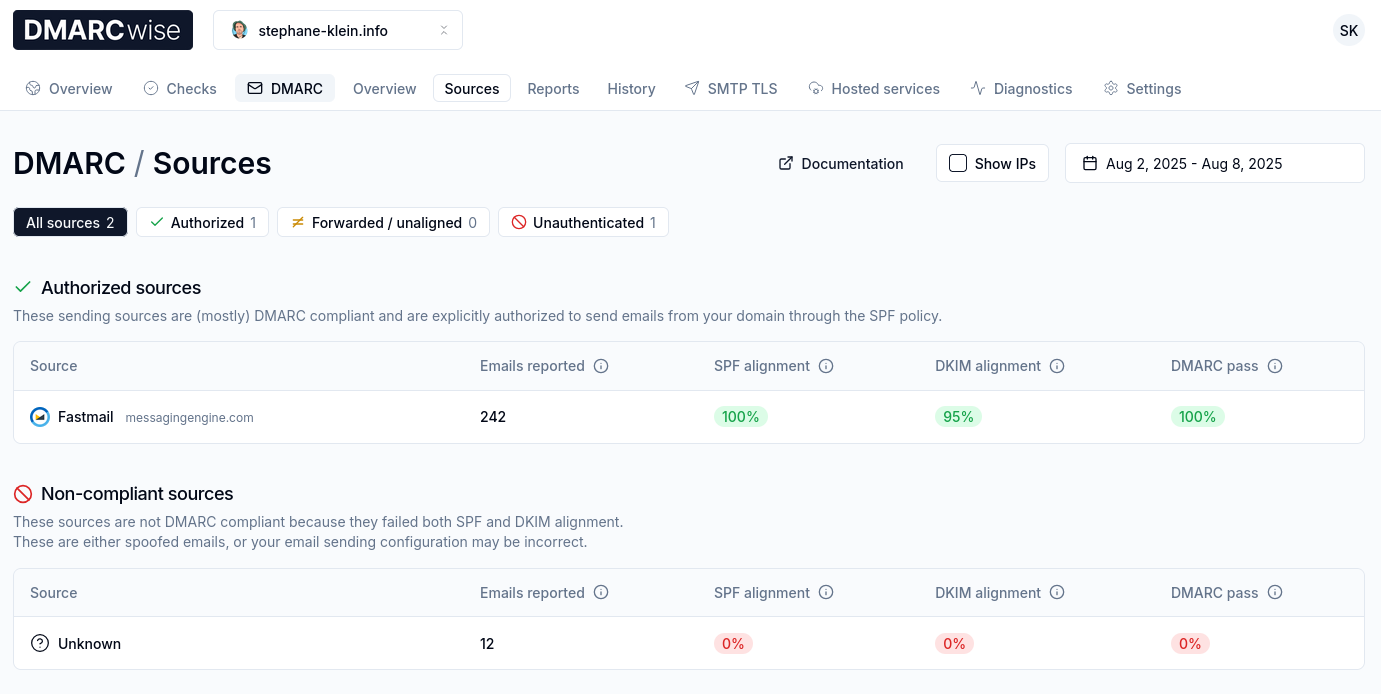
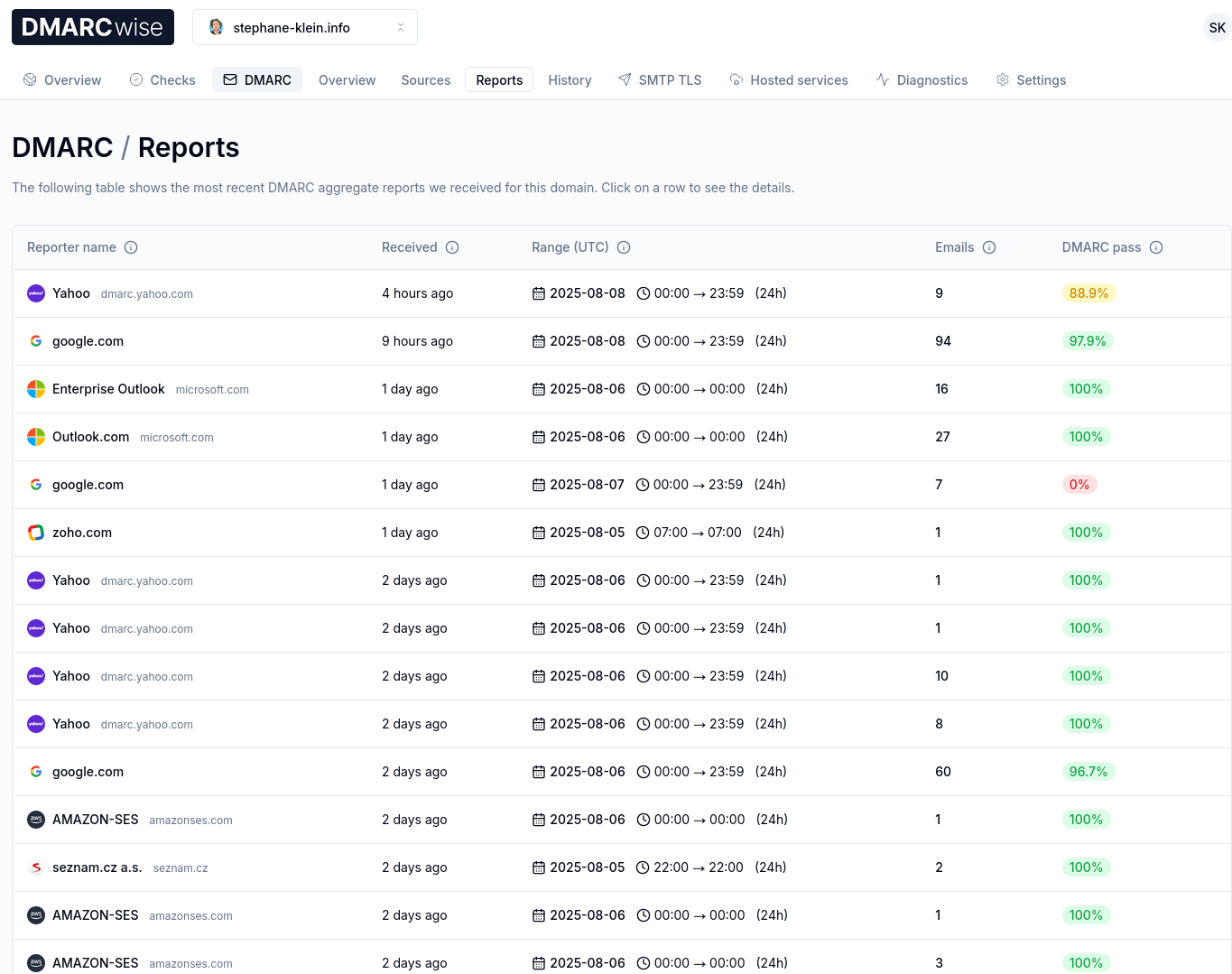
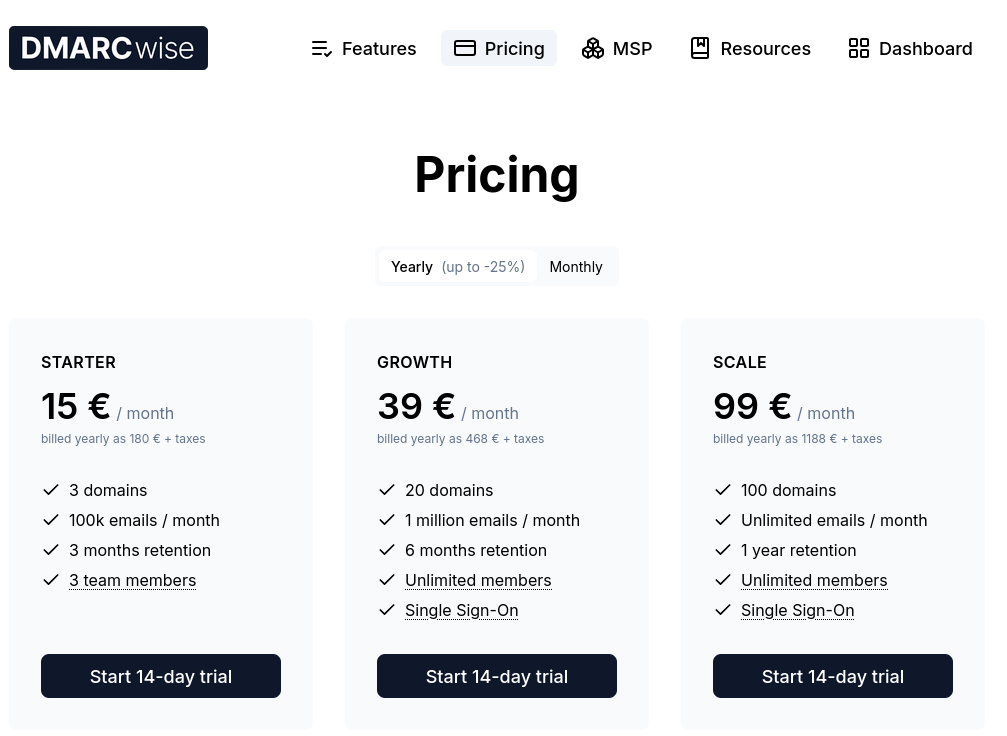
J'ai bien envie de conseiller DMARCwise à mon client.
Je sais qu'il envoie environ 3 millions d'e-mails par mois, ce qui ferait une facture de 1188 € HT par an.
Une autre option serait GlockApps, à $1548 HT par an mais avec une plus 1800 crédit de tests de inbox placement.
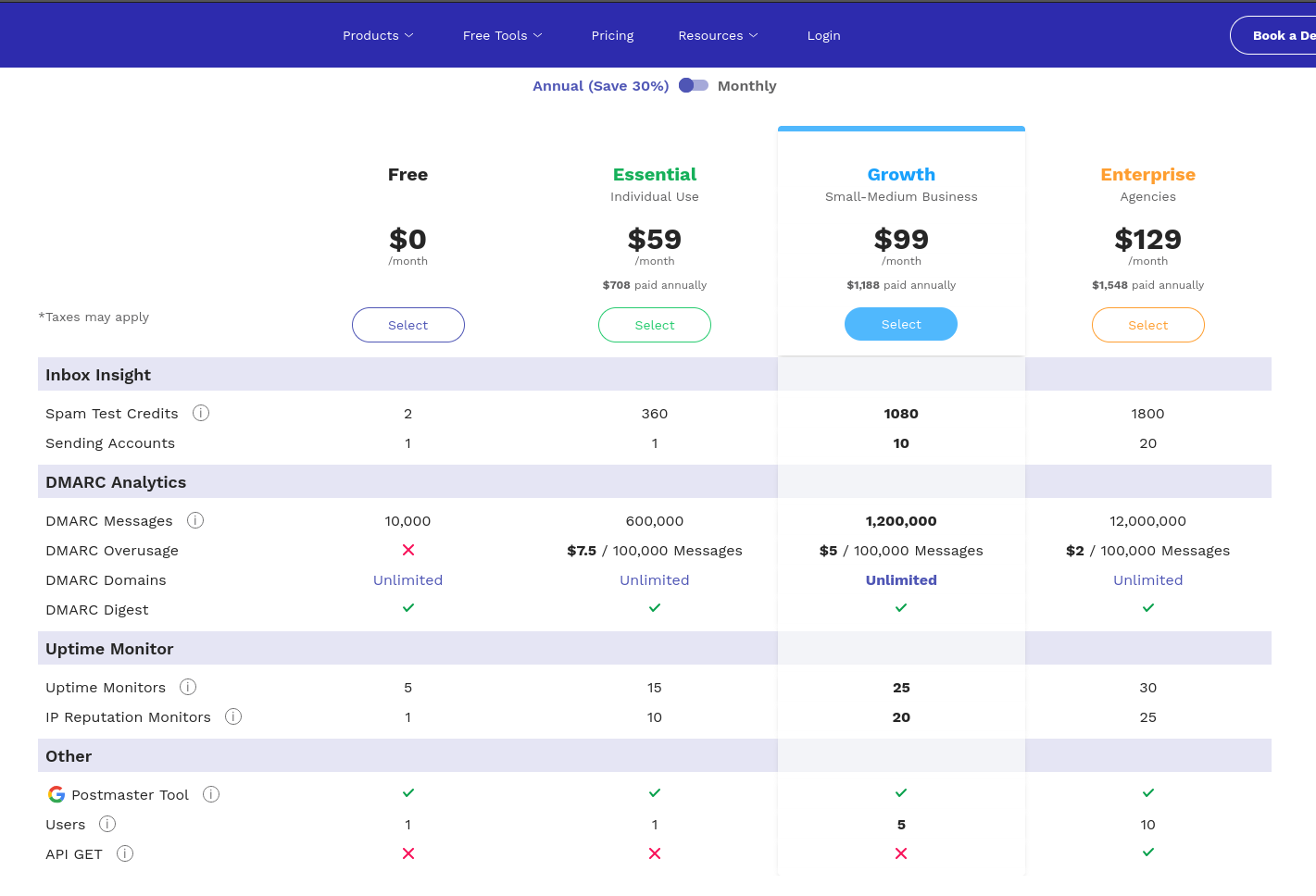
#JaimeraisUnJour prendre le temps de tester le free software de DMARC reporting nommé parsedmarc.
Ma prochaine note sur l'Email deliverability portera probablement sur l'inbox placement.
J'ai découvert la spécification "Brand Indicators for Message Identification"
En travaillant sur une mission freelance d'audit de délivrabilité d'e-mail, #JaiDécouvert la spécification "Brand Indicators for Message Identification".
Il s'agit de la spécification la plus récente qui s'ajoute aux spécifications de lutte contre l'usurpation d'identité email : SPF, DKIM, DMARC, ARC.
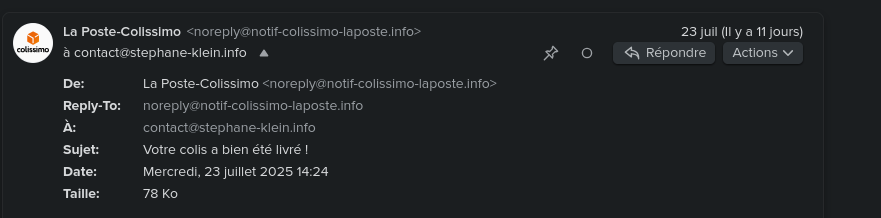
BIMI permet d'afficher le logo "certifié" de l'expéditeur du mail dans un certain nombre de clients mails (Apple, Fastmail, Gmail, La Poste, Yahoo).
Par exemple, cela donne ceci pour l'email noreply@notif-colissimo-laposte.info avec mon client mail Fastmail :
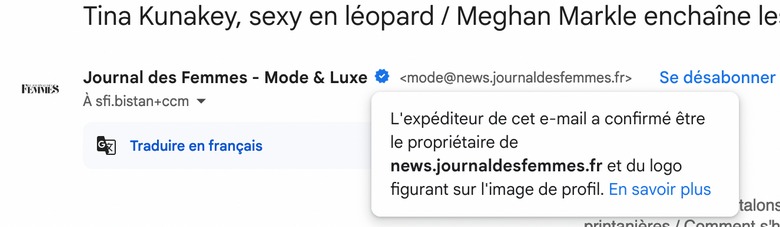
Autre exemple avec Gmail avec le "badge certifié" :
Pour avoir plus d'exemples concrets, je vous conseille de consulter la section [« Quelques exemples d’affichage de BIMI chez les fournisseurs de messagerie »](https://www.badsender.com/guides/bimi-pourquoi-et-comment-le-deployer/#:~:text=les fournisseurs de-,messagerie,-Apple Icloud (Mail) de l'excellent article « Formation BIMI : pourquoi et comment déployer BIMI ? » de l'agence française Badsender, qui offre entre autre des services d'audit de délivrabilité d'e-mail.
Vous pouvez, par exemple, vérifier la configuration BIMI sur cette page, voici le résultat, toujours avec l'adresse mail noreply@notif-colissimo-laposte.info :
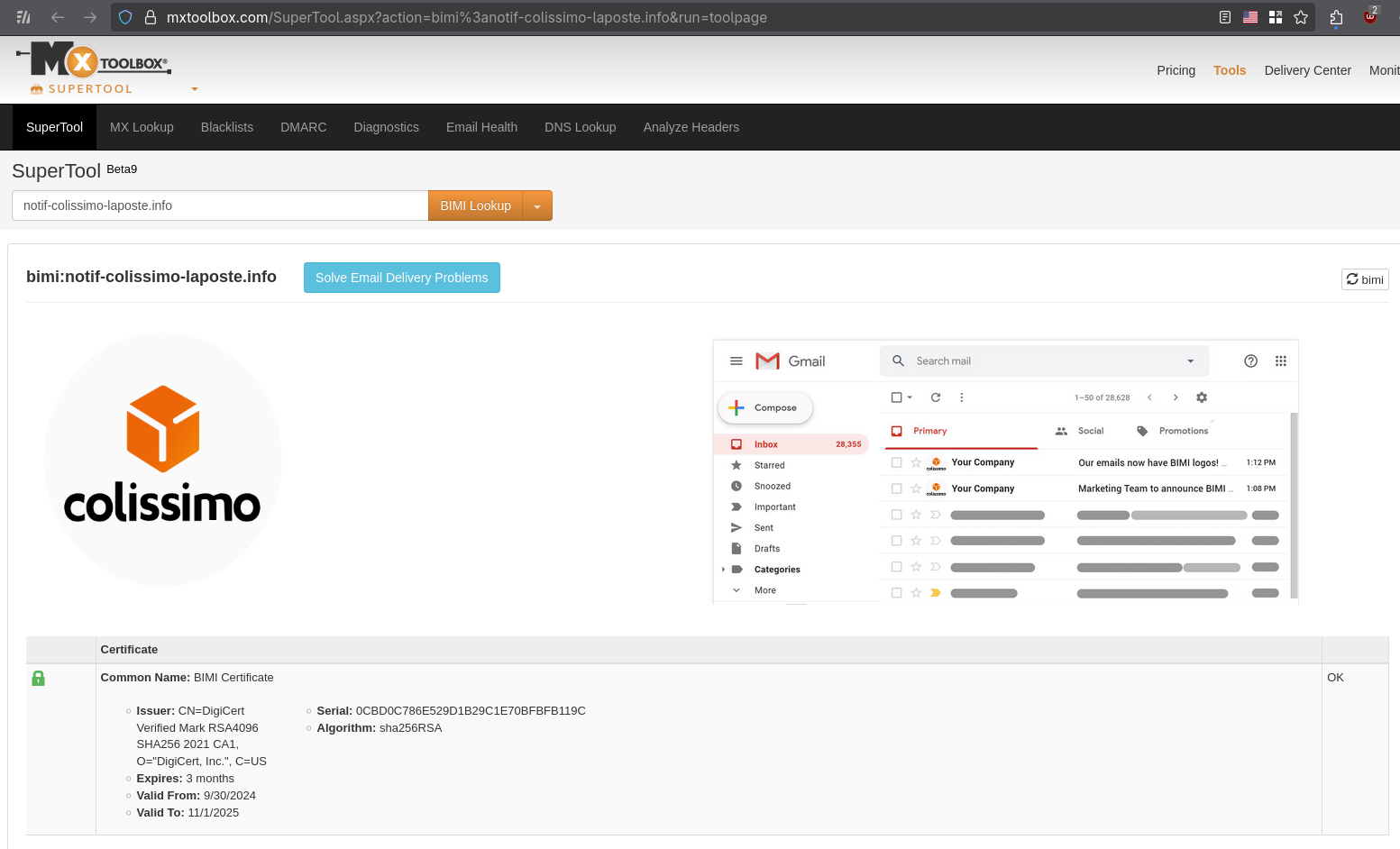
Voici la configuration DNS TXT BIMI du domaine notif-colissimo-laposte.info :
$ dig TXT default._bimi.notif-colissimo-laposte.info +short
"v=BIMI1;l=https://notif-colissimo-laposte.info/logo.svg;a=https://notif-colissimo-laposte.info/la_poste_sa.pem;"
v=BIMI1indique le numéro de version de la spécification.l=https://notif-colissimo-laposte.info/logo.svgcontient l'URL vers le logo au format SVGa=https://notif-colissimo-laposte.info/la_poste_sa.pemcontient l'URL du certificat qui permet de certifier que l'expéditeur d'un email est autorisé à utiliser le logo Colissimo.
Voici ce que contient le certificat :
Issuer: CN=DigiCert Verified Mark RSA4096 SHA256 2021 CA1, O="DigiCert, Inc.", C=US
Expires: 3 months
Valid From: 9/30/2024
Valid To: 11/1/2025
Ce certifact a été généré par DigiCert.
Liste des entreprises de type Mark Verifying Authority pouvant actuellement générer des Verified Mark Certificate ou Common Mark Certificate :
D'après ce que j'ai compris, pour obvenir un Verified Mark Certificate, il est nécessaire de fournir au Mark Verifying Authority une preuve de dépôt de marque, par exemple via l'INPI.
Je pense que "Common" dans Common Mark Certificate est en lien avec le système juridique "Common law". Pour obtenir un Common Mark Certificate, il suffit de prouver qu'on utilise le logo depuis plus de 12 mois. DigiCert indique qu'ils effectuent une vérification en utilisant archive.org.
Depuis fin 2024, un autre type de certificat est disponible. C’est le CMC(Common Mark Certificate). Celui-ci permet de s’affranchir du dépôt de marque. Avoir une marque et un logo déposé sont donc maintenant optionnels. Néanmoins, le certificat CMC ne permet pas de garantir le même niveau de légitimité au destinataire. Certaines messageries, même si elles afficheront le logo BIMI dans le cas d’un certificat CMC n’ajouteront pas de certification de la marque (par exemple, dans Gmail, le checkmark bleu n’est pas affiché en cas de certificat CMC).
Lorsqu’un certificat VMC est choisi, une marque bleue est affichée dans Gmail afin de renforcer le sentiment de légitimité pour le destinataire. Ce qui ne sera pas le cas avec un certificat CMC.
Voici les prix d'un Verified Mark Certificate chez DigiCert : 1668 € par an.
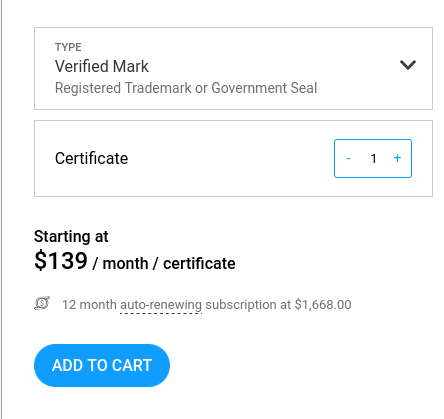
Et 1236 € par an pour un Common Mark Certificate.
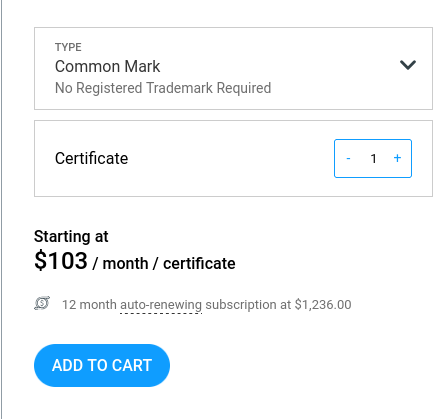
Jusqu'à maintenant, je croyais que les services Gravatar ou Libravatar permettaient d'afficher un avatar dans les clients mail, mais je réalise que ce n'est pas le cas et il semble que je ne sois pas le seul à avoir cette idée fausse :
Many users set up their Gravatar expecting it to be shown when sending emails from their email address. This is not always the case, this page explains why.
Truth be told, there aren’t many email clients (meaning the app or platform your users use to read their emails) that support Gravatar. Most popular email services (like Gmail, Outlook or Apple Mail) don’t. Unfortunately there is nothing we can do.
If you have confirmed your reader’s email client support, then there might be some setting (or addon) that your readers will need to tweak.
Je me suis demandé si BIMI pouvait améliorer l'Email deliverability.
En parcourant le Subreddit EmailMarketing, j'ai découvert ce thread : Is BIMI & VMC worth it? . Tous les contributeurs s'accordent à dire que BIMI n'apporte aucune amélioration à l'Email deliverability.
Pour le moment, aucune information ne suggère que BIMI présente un avantage pour l'Email deliverability.
À ce stade, il me semble que la mise en place d'un Verified Mark Certificate est pertinente pour tout service ciblé par des attaques d'arnaque numérique.
Pour les autres services aux moyens limités, je pense qu'investir 1668 € annuels dans un Verified Mark Certificate n'est probablement pas justifié.
Je conseille néanmoins de configurer un logo BIMI sans certificat. Cette approche permet d'améliorer l'User experience en affichant le logo dans les boîtes mail avec un effort minimal.
Je compte configurer prochainement un logo BIMI sans certificat pour mon domaine personnel stephane-klein.info.
Pendant que j'écrivais cette note, je me suis encore interrogé sur l'absence d'acteurs qui tentent d'intégrer correctement une authentification mail via PKI étatique 🤔.
#JaimeraisUnJour creuser cette question dans une note dédiée.
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité Structured Outputs (LLM) (https://platform.openai.com/docs/guides/structured-outputs)
Journal du dimanche 22 juin 2025 à 23:34
Un collègue m'a fait découvrir Vercel Chat SDK (https://github.com/vercel/ai-chatbot) :
Chat SDK is a free, open-source template built with NextJS and the AI SDK that helps you quickly build powerful chatbot applications.
#JaimeraisUnJour prendre le temps de le décliner vers SvelteKit.
Journal du dimanche 22 juin 2025 à 15:02
Je viens de découvrir les quatre premiers articles de la série "Nouvelle sur l'IA" sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
L'auteur de ces articles indique en introduction :
Avertissement : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz.
Je viens d'ajouter ces deux feed à ma note "Mes sources de veille en IA".
Prise de note de lecture de : Nouvelles sur l’IA de février 2025
Je découvre la signification de l'acronyme STEM : Science, technology, engineering, and mathematics.
Une procédure standard lors de la divulgation d’un nouveau modèle (chez OpenAI en tout cas) est de présenter une "System Card", aka "à quel point notre modèle est dangereux ou inoffensif".
#JaiDécouvert le concept de System Card, concept qui semble avoir été introduit par Meta en février 2022 : « System Cards, a new resource for understanding how AI systems work » (je n'ai pas lu l'article).
#JaiDécouvert ChatGPT Deep Research.
Je retiens :
Derya Unutmaz, MD: J'ai demandé à Deep Researchh de m'aider sur deux cas de cancer plus tôt aujourd'hui. L'un était dans mon domaine d'expertise et l'autre légèrement en dehors. Les deux rapports étaient tout simplement impeccables, comme quelque chose que seul un médecin spécialiste pourrait écrire ! Il y a une raison pour laquelle j'ai dit que c'est un changement radical ! 🤯
Et
Je suis quelque peu déçu par Deep Research d'@OpenAI. @sama avait promis que c'était une avancée spectaculaire, alors j'y ai entré la plainte pour notre procès guidé par o1 contre @DCGco et d'autres, et lui ai demandé de prendre le rôle de Barry Silbert et de demander le rejet de l'affaire.
Malheureusement, bien que le modèle semble incroyablement intelligent, il a produit des arguments manifestement faibles car il a fini par utiliser des données sources de mauvaise qualité provenant de sites web médiocres. Il s'est appuyé sur des sources comme Reddit et ces articles résumés que les avocats écrivent pour générer du trafic vers leurs sites web et obtenir de nouveaux dossiers.
Les arguments pour le rejet étaient précis dans le contexte des sites web sur lesquels il s'est appuyé, mais après examen, j'ai constaté que ces sites simplifient souvent excessivement la loi et manquent des points essentiels des textes juridiques réels.
#JaiDécouvert qu'il est possible de configurer la durée de raisonnement de Clause Sonnet 3.7 :
Aujourd'hui, nous annonçons Claude Sonnet 3.7, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi instantanées ou une réflexion approfondie, étape par étape, qui est rendue visible à l'utilisateur. Les utilisateurs de l'API ont également un contrôle précis sur la durée de réflexion accordée au modèle.
#JaiDécouvert que l'offre LLM par API de Google se nomme Vertex AI.
#JaiDécouvert que les System Prompt d'Anthropic sont publics : https://docs.anthropic.com/en/release-notes/system-prompts#feb-24th-2025
J'ai trouvé la section "Gradual Disempowerement" très intéressante. #JaimeraisUnJour prendre le temps de faire une lecture active de l'article : Gradual Disempowerment.
Je viens de consacrer 1h30 de lecture active de l'article de février 2025. Je le recommande fortement pour ceux qui s'intéressent au sujet. Merci énormément à son auteur Moonz.
Je vais publier cette note et ensuite commencer la lecture de l'article de mars 2025.
Journal du vendredi 13 juin 2025 à 22:32
Dans cette fonction filtre Open WebUI, #JaiDécouvert Detoxify (https://github.com/unitaryai/detoxify).
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
#JaimeraisUnJour prendre le temps de le tester.
Journal du jeudi 15 mai 2025 à 11:59
Un ami m'a partagé la chaine YouTube "Le lab du vieux geek" :
Chaine YouTube consacrée à l'IA l'IT la culture Geek et de nombreux autres sujets autour de l'IA. Je m'appelle Jerome Fortias, je suis français vivant en Belgique, et j'ai utilisé mon premier robot en 1986, depuis je travaille dans le monde de l'IT et de l'IA. Cette chaine c'est un peu une expérimentation d'un youtuber amateur.
J'ai écouté "La fin des LLM (Yann LeCun a raison)" et ensuite "Comment les machines pourraient-elles atteindre l'intelligence humaine ? Conférence de Yann LeCun".
Énormément de contenu, j'en ai saisi qu'une petite partie.
#JaimeraisUnJour prendre le temps de lire les 509 commentaires sous la vidéo "La fin des LLM (Yann LeCun a raison)".
L'écoute de ces vidéos m'a fait penser aux vidéos suivantes de Thibault Neveu que j'ai écoutées il y a un an :
Journal du jeudi 15 mai 2025 à 11:08
En étudiant le projet https://github.com/OriPekelman/alpair, j'ai découvert le blog d'Ori Pekelman, personne que j'ai déjà croisée à divers endroits sur Internet (podcast, commentaires…).
#JaiLu ces deux billets :
et j'ai vraiment beaucoup apprécié le fond et la forme.
#JaimeraisUnJour prendre le temps de lire tous ses autres billets.
Journal du mardi 22 avril 2025 à 17:57
J'ai un collègue qui utilise Terragrunt (https://terragrunt.gruntwork.io/).
Je pense que j'ai déjà croisé cet outil mais sans trop y prêter attention.
Pour le moment, je ne comprends pas très bien l'intérêt de Terragrunt, j'ai l'impression que c'est un wrapper au-dessus de Terraform ou OpenTofu.
#JaimeraisUnJour prendre le temps de faire un POC de Terragrunt.
Journal du vendredi 18 avril 2025 à 11:40
Cela fait des années que je m'intéresse au sujet des solutions de sauvegarde en continu de bases de données PostgreSQL.
Dans cette note, le terme "sauvegarde en continu" ne signifie pas Point In Time Recovery.
Jusqu'à présent, je me suis toujours concentré sur la méthode "mainstream", qui consiste principalement à effectuer un backup binaire couplé avec une sauvegarde continue du WAL. Par exemple des solutions basées sur pg_basebackup, pgBackRest ou barman.
Une autre solution consiste à déployer une seconde instance PostgreSQL en mode streaming replication.
Une troisième solution que #JaimeraisUnJour tester : mettre en place une sauvegarde incrémentale basée sur le filesystème btrfs.
Plus précisément, la commande btrfs-send. La documentation de Dalibo mentionne cette méthode de sauvegarde.
Samedi dernier, j'ai imaginé une autre méthode qui me plait beaucoup par sa relative flexibilité et sa simplicité.
Elle consisterait à sauvegarder des tables de manière granulaire à intervalle de temps régulier vers un Object Storage à l'aide d'un Foreign Data Wrapper.
Pour cela, j'ai identifié parquet_s3_fdw, basé sur le format Apache Parquet qui permet de lire et d'écrire des données sur un bucket Object Storage.
Features
- Support SELECT of parquet file on local file system or Amazon S3.
- Support INSERT, DELETE, UPDATE (Foreign modification).
- Support MinIO access instead of Amazon S3.
J'ai utilisé de nombreuses fois Foreign Data Wrapper pour copier de manière granulaire des données entre deux bases de données PostgreSQL.
J'ai trouvé cette méthode très pratique, en particulier la possibilité de pouvoir utiliser un "pattern" SQL de copie du type :
INSERT INTO clients_local (id, nom, email, date_derniere_maj)
SELECT
d.client_id,
d.nom_client,
d.email_client,
CURRENT_TIMESTAMP
FROM
distant.clients_distant d
WHERE
d.date_modification > (SELECT MAX(date_derniere_maj) FROM clients_local)
ON CONFLICT (id) DO UPDATE
SET
nom = EXCLUDED.nom,
email = EXCLUDED.email,
date_derniere_maj = EXCLUDED.date_derniere_maj;
#JaimeraisUnJour réaliser un POC de cette idée basée sur parquet_s3_fdw.
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.
En attendant de trouver un repository Mise pour PostgreSQL Client Applications
À ce jour, je n'ai pas trouvé de repository Mise ou Asdf pour installer les "Client Applications" de PostgreSQL, par exemple : psql, pg_dump, pg_restore.
Il existe asdf-postgres, mais ce projet me pose quelques problèmes :
- L'installation basée sur le code source de PostgreSQL avec une phase de compilation qui peut être longue et consommer beaucoup d'espace disque.
- L'intégralité de PostgreSQL est installée alors que je n'ai besoin que des "Client Applications".
#JaimeraisUnJour créer une repository Mise ou Asdf qui permet d'installer les "Client Applications" en mode binaire. Pour le moment, je n'ai aucune idée sur quels binaires me baser 🤔.
En attendant de créer ou de trouver ce repository, voici ci-dessous mes méthodes actuelles d'installation des "PostgreSQL Client Applications".
Sous MacOS
Sous MacOS, j'utilise Brew pour installer le package libpq qui contient les "PostgreSQL Client Applications".
$ brew install libpq
ou alors pour l'installation d'une version spécifique :
$ brew install libpq@17.4
Sous Fedora
Sous Fedora, j'installe le package PostgreSQL client proposé sur la page "Downloads" officielle de PostgreSQL.
Cette méthode me permet d'installer précisément une version majeure précise de PostgreSQL :
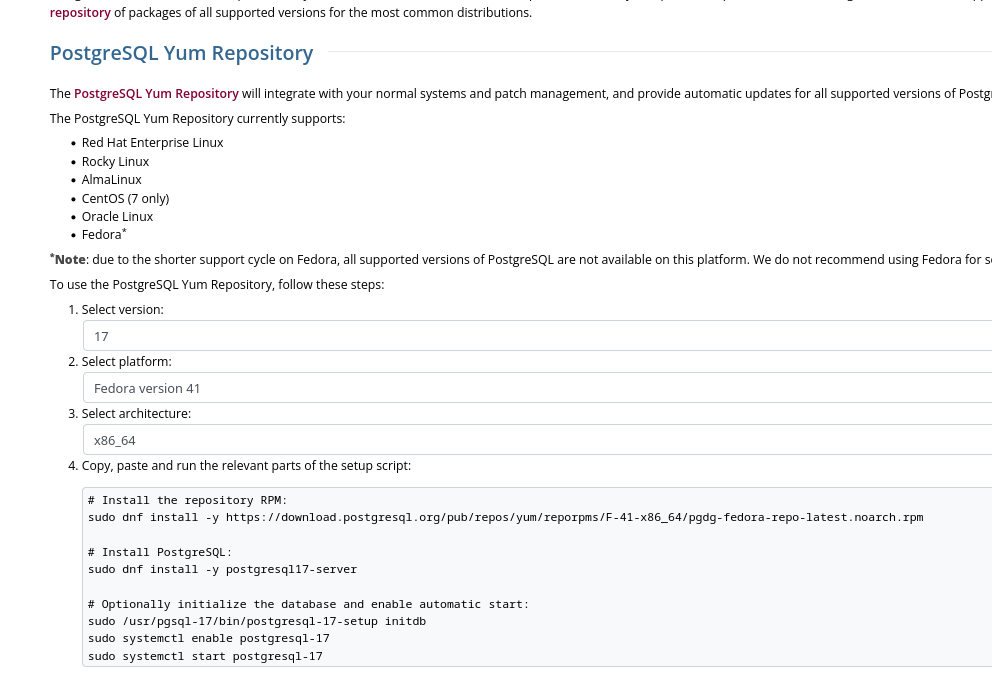
Voici les instructions pour installer la dernière version de PostgreSQL 17 sous Fedora 41 :
$ sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/F-41-x86_64/pgdg-fedora-repo-latest.noarch.rpm
$ sudo rpm --import https://download.postgresql.org/pub/repos/yum/keys/PGDG-RPM-GPG-KEY-Fedora
$ sudo dnf update -y
Le package nommé postgresql17 contient uniquement les "PostgreSQL Client Applications" :
$ dnf info postgresql17
Mise à jour et chargement des dépôts :
Dépôts chargés.
Paquets installés
Nom : postgresql17
Epoch : 0
Version : 17.4
Version : 1PGDG.f41
Architecture : x86_64
Taille une fois installé : 10.7 MiB
Source : postgresql17-17.4-1PGDG.f41.src.rpm
Dépôt d'origine : pgdg17
Résumé : PostgreSQL client programs and libraries
URL : https://www.postgresql.org/
Licence : PostgreSQL
Description : PostgreSQL is an advanced Object-Relational database management system (DBMS).
: The base postgresql package contains the client programs that you'll need to
: access a PostgreSQL DBMS server. These client programs can be located on the
: same machine as the PostgreSQL server, or on a remote machine that accesses a
: PostgreSQL server over a network connection. The PostgreSQL server can be found
: in the postgresql17-server sub-package.
:
: If you want to manipulate a PostgreSQL database on a local or remote PostgreSQL
: server, you need this package. You also need to install this package
: if you're installing the postgresql17-server package.
Fournisseur : PostgreSQL Global Development Group
$ dnf repoquery -l postgresql17 | grep "/bin"
Mise à jour et chargement des dépôts :
Dépôts chargés.
/usr/pgsql-17/bin/clusterdb
/usr/pgsql-17/bin/createdb
/usr/pgsql-17/bin/createuser
/usr/pgsql-17/bin/dropdb
/usr/pgsql-17/bin/dropuser
/usr/pgsql-17/bin/pg_basebackup
/usr/pgsql-17/bin/pg_combinebackup
/usr/pgsql-17/bin/pg_config
/usr/pgsql-17/bin/pg_createsubscriber
/usr/pgsql-17/bin/pg_dump
/usr/pgsql-17/bin/pg_dumpall
/usr/pgsql-17/bin/pg_isready
/usr/pgsql-17/bin/pg_receivewal
/usr/pgsql-17/bin/pg_restore
/usr/pgsql-17/bin/pg_waldump
/usr/pgsql-17/bin/pg_walsummary
/usr/pgsql-17/bin/pgbench
/usr/pgsql-17/bin/psql
/usr/pgsql-17/bin/reindexdb
/usr/pgsql-17/bin/vacuumdb
Installation de ce package :
$ sudo dnf install postgresql17
$ psql --version
psql (PostgreSQL) 17.4
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.
Journal du jeudi 10 avril 2025 à 08:44
#JaiDécouvert ici la fonctionnalité "Incremental Static Regeneration (ISR)" de NextJS.
L'Incremental Static Regeneration (ISR) est un mélange de génération static et de régénération dynamique.
Lors du build du site toutes les pages sont générées de manière statique. Cependant, certaines peuvent être "marquées" : ces pages clairement identifiées seront régénérées à intervalle régulier après le déploiement du site, faisant appel à des API ou une base de données pour garder la donnée à jour.
Lors de la visite d'une page à régénérer, une version "ancienne" de la page s'affiche, mais une demande de régénération est envoyée au serveur. La page est ainsi régénérée et renvoyée instantanément au visiteur, et prête à être affichée au visiteur suivant. Le cycle peut alors recommencer.
J'ai aussi lu cette page de documentation de Vercel :
Incremental Static Regeneration (ISR) allows you to create or update content on your site without redeploying. ISR's main benefits for developers include:
- Better Performance: Static pages can be consistently fast because ISR allows Vercel to cache generated pages in every region on our global Edge Network and persist files into durable storage
- Reduced Backend Load: ISR helps reduce backend load by using cached content to make fewer requests to your data sources
- Faster Builds: Pages can be generated when requested by a visitor or through an API instead of during the build, speeding up build times as your application grows
ISR is available to applications built with:
J'ai étudié le support ISR de SvelteKit. Il semble que cette fonctionnalité soit supportée uniquement par l'adapter-vercel.
J'ai identifié l'issue suivante : Would revalidating a static page work when self-hosted?.
#JaimeraisUnJour prendre le temps de creuser plus en profondeur ce sujet.
Journal du mardi 08 avril 2025 à 17:59
Un collègue m'a fait découvrir Trapeze (https://trapeze.dev/).
Trapeze is a mobile project configuration toolbox for native iOS and Android project management. From a simple YAML format, Trapeze makes it easy to automate the configuration of native mobile iOS and Android projects, and supports traditional native, Ionic, Capacitor, React Native, Flutter, and .NET MAUI. The long-term goal of Trapeze is to enable fully immutable native mobile projects.
Trapeze works by automating the modification of pbxproj, plist, XML, Gradle, JSON, resource, properties, and other files in iOS and Android app projects. It features a configuration-driven tool that takes a YAML file with iOS and Android project modifications and performs those modifications from the command line interactively.
C'est un projet créé par l'équipe Ionic, créatrice de Capacitor.
Je ne comprends pas comment j'ai pu passer à côté de cet outil qui est pourtant mentionné dans la documentation officielle de Capacitor 🙈 !
Both projects and their documentation are available in the Trapeze repo.
J'ai parcouru un peu la documentation et je trouve cet outil excellent !
C'est tout à fait ce dont j'avais besoin dans mon dans "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor" !
Je pense que cet outil me permet d'éliminer tous mes "hacks" pérésents dans le repository : poc-capacitor.
#JaimeraisUnJour prendre le temps d'intégrer Trapeze à poc-capacitor.
Journal du jeudi 27 février 2025 à 10:41
En travaillant sur la note "Je découvre Beszel", #JaiDécouvert ici un autre projet de monitoring intéressant : Dozzle (https://dozzle.dev/).
Dozzle is a small lightweight application with a web based interface to monitor Docker logs. It doesn’t store any log files. It is for live monitoring of your container logs only.
Là aussi, Dozzle est un projet en Golang, commencé fin 2018.
Dozzle est une alternative à Loki + Grafana.
#JaimeraisUnJour déployer Dozzle pour le tester et si ce test est concluant, je l'intégrerai peut-être à ma stack minimaliste de monitoring en complément de Beszel et Gatus.
Je découvre la compression Zstandard
Un ami m'a partagé Zstandard (zstd), un algorithme de compression.
Il y a 2 ans, j'ai étudié et activé Brotli dans mes containers nginx, voir la note : Mise en œuvre du module Nginx Brotli.
Je viens de trouver un module zstd pour nginx : https://github.com/tokers/zstd-nginx-module
Mon ami m'a partagé cet excellent article : Choosing Between gzip, Brotli and zStandard Compression. Très complet, il explique tout, contient des benchmarks…
Voici ce que je retiens.
Brotli a été créé par Google, Zstandard par Facebook :
Je lis sur canIuse, le support Zstandard a été ajouté à Chrome en mars 2024 et à Firefox en mai 2024, c'est donc une technologie très jeune coté browser.
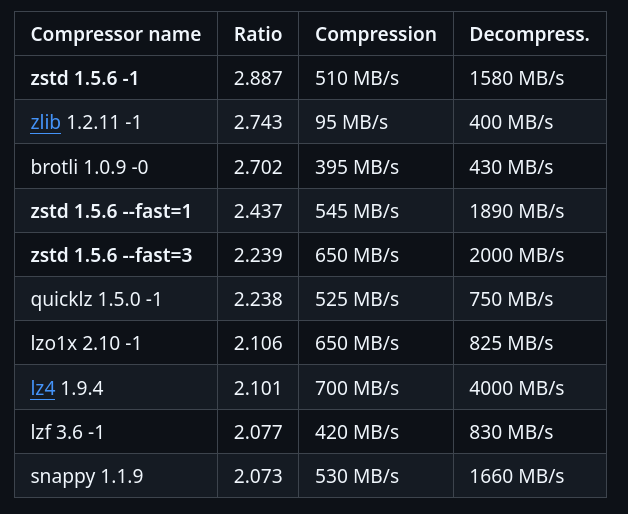
Benchmark sur le dépôt officiel de Zstandard :
J'ai trouvé ces threads Hacker News :
- 2020-05-07 : Introduce ZSTD compression to ZFS
- 2022-08-20 : AWS switch from gzip to zstd – about 30% reduction in compressed S3 storage
Zstandard semble être fortement adopté au niveau de l'écosystème des OS Linux :
In March 2018, Canonical tested the use of zstd as a deb package compression method by default for the Ubuntu Linux distribution. Compared with xz compression of deb packages, zstd at level 19 decompresses significantly faster, but at the cost of 6% larger package files. Support was added to Debian in April 2018
Packages Fedora :
#JeMeDemande si dans mes projets de doit utiliser Zstandard plutôt que Brotli 🤔.
Je pense avoir trouver une réponse ici :
The research I’ve shared in this article also shows that for many sites Brotli will provide better compression for static content. Zstandard could potentially provide some benefits for dynamic content due to its faster compression speeds. Additionally:
- ...
- For dynamic content
- Brotli level 5 usually result in smaller payloads, at similar or slightly slower compression times.
- zStandard level 12 often produces similar payloads to Brotli level 5, with compression times faster than gzip and Brotli.
- For static content
- Brotli level 11 produces the smallest payloads
- zStandard is able to apply their highest compression levels much faster than Brotli, but the payloads are still smaller with Brotli.
#JaimeraisUnJour prendre le temps d'installer zstd-nginx-module à mon image Docker nginx-brotli-docker (ou alors d'en trouver une déjà existante).
Journal du samedi 21 décembre 2024 à 20:40
Chose amusante, alors que ce matin même, j'ai découvert l'existence de o1, sortie il y a seulement quelques jours, le 5 décembre 2024.
Voilà que je découvre ce soir, dans ce thread Hacker News la sortie de o3 le 20 décembre 2024 : "OpenAI O3 breakthrough high score on ARC-AGI-PUB".
Les releases sont très réguliers en ce moment, il est difficile de suivre le rythme 😮 !
Dans ce thread, j'ai découvert le prix ARC (https://arcprize.org), lancé le 11 juin 2024, par le français François Chollet, basé sur le papier de recherche "On the Measure of Intelligence" sorti en 2019, il y a 5 ans.
ARC est un outil de mesure de AGI.
#JaimeraisUnJour prendre le temps de lire On the Measure of Intelligence.
Je lis ici :
OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
OpenAI's new o3 system - trained on the ARC-AGI-1 Public Training set - has scored a breakthrough 75.7% on the Semi-Private Evaluation set at our stated public leaderboard $10k compute limit. A high-compute (172x) o3 configuration scored 87.5%.
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
Plus loin, je lis :
However, it is important to note that ARC-AGI is not an acid test for AGI – as we've repeated dozens of times this year. It's a research tool designed to focus attention on the most challenging unsolved problems in AI, a role it has fulfilled well over the past five years.
Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don't think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Donc, j'en conclus qu'il ne faut pas s'emballer outre mesure sur les résultats de ce test, bien que les progrès soient impressionnants.
La première partie du thread semble aborder la thématique du coût financier de o3 versus un humain : 309 commentaires.
Dans ce commentaire #JaiDécouvert le papier de recherche "H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark" qui date de 2024.
Journal du mercredi 11 décembre 2024 à 11:03
Je viens de croiser pour la première fois la propriété windom.customElements (from).
Elle fait partie de l'ensemble des technologies qui composent ce que l'on appelle les Web Components.
Je connais depuis longtemps les Web Components, mais je n'ai jamais essayé de mettre en œuvre cette technologie. Je me suis contenté de lire et d'écouter des retours d'expérience et de suivre l'évolution des spécifications.
#JaiDécouvert que je peux facilement créer des Web Components en Svelte : https://svelte.dev/docs/svelte/custom-elements.
Custom elements can be a useful way to package components for consumption in a non-Svelte app, as they will work with vanilla HTML and JavaScript as well as most frameworks.
#JaiDécouvert le site Custom Elements Everywhere (https://custom-elements-everywhere.com/). Je lis que les Web Components sont maintenant parfaitement supportés par les frameworks majeurs : ReactJS, VueJS, Angular, Svelte, Solid… Ce qui est une très bonne nouvelle 🙂.
Je vais essayer de garder cette information à l'esprit, les Web Components me seront sans doute utile à l'avenir.
Avec Svelte, j'apprécie une sorte de "retour aux sources", c'est-à-dire, vers un web un peu plus "vannila", celui que j'ai connu au début des années 2000.
Je pense que Web Components vont encore renforcer cette sensation, comme par exemple le fait que si j'utilise la fonctionnalité développeur "inspection" du navigateur sur un Web Component, je vais voir, par exemple, la balise <button>....</button> du Web Component et non sa "soupe" HTML, comme c'est le cas avec un composant ReactJS ou Svelte (je sais qu'il existe des extensions navigateur pour éviter cela).
#JaimeraisUnJour prendre le temps d'étudier les performances des Web Components versus les composants de ReactJS, Svelte et Solid.
#JaiLu le thread du Subreddit ReactJS : Is it worth learning Web Components?. Voici quelques extraits :
Not worth it to be quite honest. I expect to get some hate for this.
I worked on a design system for three years that was written in Stencil (web component framework) that was used by multiple teams all using React, Angular, Vue. I regret everything, it should have all been react but the dumb decision to allow different teams to use different frameworks in order to do "micro frontend architecture" was the reason web components were picked shortly before I joined and took the lead.
Web components are also impossible to version and whichever one loads first is going to be the one that is globally used. This means production breaking changes without teams even knowing their breaking changes were going to fuck over another team.
Un peu plus loin du même auteur :
No, I view “micro frontend architecture” as a total disaster and it usually is implemented badly. When each application is a different framework too it’s quite honestly so difficult as to not even be worth entertaining.
Web components can be a great way to add functionality to legacy web apps. I don't know if I'd set out to use them in any other scenario though. I suppose you could, but I don't know many people writing vanilla HTML/JS apps these days.
J'ai effectué une recherche GitHub sur le topic "web-components" et j'ai trouvé des choses intéressantes :
- wired-elements - j'adore ! ( Voir note la 2024-12-11_1708)
- Open UI (https://open-ui.org) - cela semble être intéressant
- https://github.com/github/github-elements
- https://github.com/nolanlawson/emoji-picker-element
- https://atomicojs.dev
Journal du jeudi 10 octobre 2024 à 11:26
Par sérendipité #JaiÉcouté la #vidéo "Table ronde sur la mutualisation - Congrès ADULLACT 2024"
Table ronde sur la mutualisation - Congrès ADULLACT 2024
Animée par François Élie (Président de l'ADULLACT et Élu local à la ville et à l'Agglomération d'Angoulême), retrouvez cette table-ronde composée de :
- Line Galy, Directrice du Pôle Numérique et Donnée pour Montpellier Méditerranée Métropole;
- Stéphane Vangheluwe, Directeur du SITIV et Trésorier représentant DÉCLIC;
- Jean-Charles Mandique, Directeur Général des Services de Numérian;
- Faycal Braiki, Directeur Général des Services du SITPI.
#JaiDécouvert beaucoup de choses en écoutant cette vidéo. #JaimeraisUnJour prendre le temps de la réécouter afin de rédiger une note qui contiendrait toutes les informations intéressantes que j'y ai trouvées.
Je trouve le sujet de la mutualisation des services et des logiciels à l'échelle des communes passionnant.
Journal du lundi 07 octobre 2024 à 09:22
#JaimeraisUnJour prendre le temps de tester les logiciels de personal finance manager : Firefly III et Actual Budget.
#JaiDécouvert CommunityRule. Je suis vraiment impressionné par ce projet. C'est une idée à laquelle j'avais déjà vaguement pensé, et je suis ravi de voir qu'elle a été réalisée avec autant de qualité. Bravo aux créateurs !
Je suis tombé dans un rabbit hole et j'ai passé 2 heures à explorer le site en détail, à lire toutes les pages et à suivre divers liens externes, etc. Voici mes notes issues de cette exploration.
“For everyone to have the opportunity to be involved in a given group and to participate in its activities the structure must be explicit, not implicit. The rules of decision-making must be open and available to everyone, and this can happen only if they are formalized.” (Jo Freeman, “The Tyranny of Structurelessness”).
-- from
Chose amusante, quand j'ai commencé à lire ce paragraphe, je me suis dit « Cela me fait penser à The Tyranny of Structurelessness » et je constate que c'est le cas 🙂.
#JaiDécouvert les articles "Admins, Mods, and Benevolent Dictators for Life: The Implicit Feudalism of Online Communities" et "Modular Politics Toward a Governance Layer for Online Communities" (from) de Nathan Schneider, que je n'ai pas encore pris le temps de lire (#JaimeraisUnJour).
#JaiDécouvert Manuel de discipline (from).
La page "Points of inspiration" contient beaucoup de liens que je trouve très intéressants.
Je trouve les 8 templates de prise de décision particulièrement intéressants (chaque lien contient la traduction des templates) :
Le livre Comunity Rules décrit davantage ces modèles.
Ces documents m'auraient été très utiles au cours des dix dernières années pour formaliser et mieux communiquer mes propositions de gouvernance, tant dans le milieu associatif que dans le cadre professionnel.
La page Module documentation contient encore beaucoup de savoir que j'aimerais prendre le temps de lire.
#JaiDécouvert le livre The Magna Carta Manifesto - Liberties and Commons for All (from).
J'ai très envie de traduire le site en langue française.
Journal du jeudi 05 septembre 2024 à 13:18
J'ai un peu parcouru la documentation de OpenBao, #JaimeraisUnJour faire un POC de cet outil.
Journal du mardi 27 août 2024 à 14:30
Quelques mots au sujet de kamal. Encore une fois, une oeuvre de David Heinemeier Hansson (DHH de Basecamp) ❤️.
J'aime beaucoup la doctrine de DHH et c'est tout naturellement que kamal me plait.
Cependant, un bémol : je commence à me lasser des projets d'outillage développés en Ruby. Cette approche me semble un peu dépassée. À mon avis, Golang est bien mieux adapté pour ce type d'outil, ne serait-ce que parce qu'un outil développé en Golang peut être distribué sous la forme d'un simple binaire.
#JaimeraisUnJour créer un clone de kamal en Golang. Peut-être que je l'appellerai "Gamal" 🤔. #idée
Journal du mardi 27 août 2024 à 10:17
Alexandre m'a partagé avante.nvim.
#JaimeraisUnJour le setup pour le tester.
Cependant, une question me revient sans cesse à l'esprit en voyant ce genre d'outil utilisant les API d'AI providers : est-ce que le coût d'utilisation de ce type de service ne risque pas d'être exorbitant ? 🤔
Je sais bien que ces AI providers permettent de définir un plafond de dépenses, ce qui est rassurant. La meilleure approche serait donc de tester l'outil et d'évaluer les coûts mensuels pour voir s'ils restent raisonnables.
Journal du vendredi 19 juillet 2024 à 17:35
J'ai passé 10min à étudier ce projet, je n'ai pas vraiment compris ses caractéristiques, mais j'y ai trouvé des choses qui ont attiré ma curiosité. #JaimeraisUnJour prendre du temps pour étudier Atomic Data en profondeur.
En lien avec Systèmes d’organisation des connaissances.
Journal du mercredi 10 juillet 2024 à 11:03
#JeDécouvre ce site perso https://www.arthurperret.fr/ de Arthur Perret, j'aime beaucoup le style. (from).
Dans ses papiers de recherche #JaiDécouvert ces papiers :
Journal du mardi 09 juillet 2024 à 09:52
#JaimeraisUnJour installer et tester le moteur de recherche décentralisé https://yacy.net/.
#JeLis le thread YaCy, a distributed Web Search Engine, based on a peer-to-peer network | Hacker News
- Je suis tombé sur ce commentaire que je trouve intéressant
Journal du lundi 24 juin 2024 à 11:56
#OnMaPartagé cette Étude de UFC-Que Choisir : Dark Pattens Dans l'E-Commerce. - Les interfaces trompeuses sur les places de marché en ligne.
Je ne l'ai pas encore lu, mais le sujet des dark pattern m'intéresse beaucoup.
#JaimeraisUnJour prendre le temps de lire l'intégralité de cette étude.
Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
Cette semaine, j'ai déjeuné avec un ami dont les connaissances dans le domaine du #MachineLearning et des #llm dépassent largement les miennes... J'en ai profité pour lui poser de nombreuses questions.
Voici ci-dessous quelques notes de ce que j'ai retenu de notre discussion.
Avertissement : Le contenu de cette note reflète les informations que j'ai reçues pendant cette conversation. Je n'ai pas vérifié l'exactitude de ces informations, et elles pourraient ne pas être entièrement correctes. Le contenu de cette note est donc à considérer comme approximatif. N'hésitez pas à me contacter à contact@stephane-klein.info si vous constatez des erreurs.
Histoire de Llama.cpp ?
Question : quelle est l'histoire de llama.cpp ? Comment ce projet se positionne dans l'écosystème ?
D'après ce que j'ai compris, début 2023, PyTorch était la solution "mainstream" (la seule ?) pour effectuer de l'inférence sur le modèle LLaMa — sortie en février 2023.
PyTorch — écrit en Python et C++ — est optimisée pour les GPU, plus précisément pour le framework CUDA.
PyTorch est n'est pas optimisé pour l'exécution sur CPU, ce n'est pas son objectif.
Georgi Gerganov a créé llama.cpp pour pouvoir effectuer de l'inférence sur le modèle LLaMa sur du CPU d'une manière optimisé. Contrairement à PyTorch, plus de Python et des optimisations pour Apple Silicon, utilisation des instructions AVX / AVX2 sur les CPU x86… Par la suite, « la boucle a été bouclée » avec l'ajout du support GPU en avril 2023.
À la question « Maintenant que llama.cpp a un support GPU, à quoi sert PyTorch ? », la réponse est : PyTorch permet beaucoup d'autres choses, comme entraîner des modèles…
Aperçu de l'historique du projet :
- 18 septembre 2022 : Georgi Gerganov commence la librairie ggml, sur laquelle seront construits llama.cpp et Whisper.cpp.
- 4 mars 2023 : Georgi Gerganov a publié le premier commit de llama.cpp.
- 10 mars 2023 : je crois que c'est le premier poste Twitter de publication de llama.cpp https://twitter.com/ggerganov/status/1634282694208114690.
- 13 mars 2023 : premier post à propos de LLama.cpp sur Hacker News qui fait zéro commentaire - Llama.cpp can run on Macs that have 64G of RAM (40GB of Free memory).
- 14 mars 2023 : second poste, toujours zéro commentaire - Run a GPT-3 style AI on your local machine, fully on premise.
- 31 mars 2023 : premier thread sur llama.cpp qui fait le buzz avec 414 commentaires - Llama.cpp 30B runs with only 6GB of RAM now.
- 12 avril 2023 : d'après ce que je comprends, voici la Merge Request d'ajout du support GPU à llama.cpp # Add GPU support to ggml (from).
- 6 juin 2023 : Georgi Gerganov lance sa société nommée https://ggml.ai (from) .
- 10 juillet 2023 : Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- 24 juillet 2023 : llama : add support for llama2.c models (from).
- 25 août 2023 : ajout du support ROCm (AMD).
Comment nommer Llama.cpp ?
Question : quel est le nom d'un outil comme llama.cpp ?
Réponse : Je n'ai pas eu de réponse univoque à cette question.
C'est un outil qui effectue des inférences sur un modèle.
Voici quelques idées de nom :
- Moteur d'inférence (Inference Engines) ;
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, #JaiDécidé d'utiliser le terme Inference Engines.
Autre projet comme Llama.cpp ?
Question : Existe-t-il un autre projet comme Llama.cpp
Oui, il existe d'autres projets, comme llm - Large Language Models for Everyone, in Rust. Article Hacker News publié le 14 mars 2023 sous le nom LLaMA-rs: a Rust port of llama.cpp for fast LLaMA inference on CPU.
Et aussi, https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from).
Le README de ce projet liste de nombreuses autres implémentations de Inference Engines.
Mais, à ce jour, llama.cpp semble être l'Inference Engines le plus complet et celui qui fait consensus.
GPU vs CPU
Question : Jai l'impression qu'il est possible de compiler des programmes généralistes sur GPU, dans ce cas, pourquoi ne pas remplacer les CPU par des GPU ? Pourquoi ne pas tout exécuter par des GPU ?
Mon ami n'a pas eu une réponse non équivoque à cette question. Il m'a répondu que l'intérêt du CPU reste sans doute sa faible consommation énergique par rapport au GPU.
Après ce déjeuner, j'ai fait des recherches et je suis tombé sur l'article Wikipedia nommé General-purpose computing on graphics processing units (je suis tombé dessus via l'article ROCm).
Cet article contient une section nommée GPU vs. CPU, mais qui ne répond pas à mes questions à ce sujet 🤷♂️.
ROCm ?
Question : J'ai du mal à comprendre ROCm, j'ai l'impression que cela apporte le support du framework CUDA sur AMD, c'est bien cela ?
Réponse : oui.
J'ai ensuite lu ici :
HIPIFY is a source-to-source compiling tool. It translates CUDA to HIP and reverse, either using a Clang-based tool, or a sed-like Perl script.
RAG ?
Question : comment setup facilement un RAG ?
Réponse : regarde llama_index.
#JaiDécouvert ensuite https://github.com/abetlen/llama-cpp-python
Simple Python bindings for @ggerganov's llama.cpp library. This package provides:
- Low-level access to C API via ctypes interface.
- High-level Python API for text completion
- OpenAI-like API
- LangChain compatibility
- LlamaIndex compatibility
- ...
dottextai / outlines
Il m'a partagé le projet https://github.com/outlines-dev/outlines alias dottxtai, pour le moment, je ne sais pas trop à quoi ça sert, mais je pense que c'est intéressant.
Embedding ?
Question : Thibault Neveu parle souvent d'embedding dans ses vidéos et j'ai du mal à comprendre concrètement ce que c'est, tu peux m'expliquer ?
Le vrai terme est Word embedding et d'après ce que j'ai compris, en simplifiant, je dirais que c'est le résultat d'une "sérialisation" de mots ou de textes.
#JaiDécouvert ensuite l'article Word Embeddings in NLP: An Introduction (from) que j'ai survolé. #JaimeraisUnJour prendre le temps de le lire avec attention.
Transformers ?
Question : et maintenant, peux-tu me vulgariser le concept de transformer ?
Réponse : non, je t'invite à lire l'article Natural Language Processing: the age of Transformers.
Entrainement décentralisé ?
Question : existe-t-il un système communautaire pour permettre de générer des modèles de manière décentralisée ?
Réponse - Oui, voici quelques liens :
- BigScience Research Workshop/
- Distributed Deep Learning in Open Collaborations
- Deep Learning over the Internet: Training Language Models Collaboratively
Au passage, j'ai ajouté https://huggingface.co/blog/ à mon agrégateur RSS (miniflux).
La suite…
Nous avons parlé de nombreux autres sujets sur cette thématique, mais j'ai décidé de m'arrêter là pour cette note et de la publier. Peut-être que je publierai la suite un autre jour 🤷♂️.
Journal du mercredi 05 juin 2024 à 14:42
#JaimeraisUnJour suivre le tutoriel https://github.com/srush/GPU-Puzzles - Solve puzzles. Learn #CUDA.
#GPU architectures are critical to machine learning, and seem to be becoming even more important every day. However, you can be an expert in machine learning without ever touching GPU code. It is hard to gain intuition working through abstractions.
Journal du vendredi 24 mai 2024 à 11:01
#JaiDécouvert La loi du Ripolin :
En 1925, l’architecte Le Corbusier publie L’Art décoratif d’aujourd’hui, ouvrage dans lequel il développe une Loi du Ripolin qui établit un parallèle entre le nettoyage des murs et celle de l’esprit. Passer une couche de blanc sur ses murs serait, pour lui, une opération de renouveau à la fois concret et moral. Cette loi lui permet également de donner sa définition de l’art. (from)
#JaimeraisUnJour lire Le Corbusier, L’Art décoratif d’aujourd’hui et « la loi du ripolin »
Un ami me fait découvrir "ripoliner" dans le sens suivant :
(Sens figuré) Farder, masquer, rafraîchir une image politique.
Journal du mercredi 22 mai 2024 à 12:45
On me demande où j'en suis dans mon expérience notes.sklein.xyz ?
Comment il est déployé ? Pour le moment, d'une manière très minimaliste et assez manuelle comme décrit ici : https://github.com/stephane-klein/obsidian-quartz-playground/tree/main/deployment
Aujourd'hui c'est toujours le cas. Quand je veux déployer je lance le script deployment/scripts/build-and-push.sh.
Je disais aussi :
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
Je ne suis toujours pas satisfait du rendu de notes.sklein.xyz mais je suis satisfait de l'expérience car j'arrive à produire et partager du contenu facilement.
Pour le moment, je pense que produire du contenu est plus important que de soigner le rendu. Le jour où j'aurai beaucoup de contenu, une amélioration de la forme, de la navigation et des fonctionnalités aura alors plus de valeur pour moi.
Je disais aussi :
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Suite à cela, j'ai créé Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et j'ai seulement travailé un tout petit peu sur cette expérience.
#JaimeraisUnJour un jour setup un RAG sur notes.sklein.xyz.
Est-ce que je suis satisfait du client Obsidian ? Je réponds que parfois oui, parfois non. Il m'agace par moments, et j'aimerais prendre le temps de "parfaitement configurer" Obsidian.nvim.
Journal du mardi 21 mai 2024 à 11:58
Dans ce thread je lis :
Linus Torvalds himself uses Fedora
et aussi un peu plus bas, je lis :
the second guy in linux (greg k.-h.) uses arch though 😊
Linus vient s'ajouter aux nombreux developeurs mainstreams qui utilisent Fedora.
#JaimeraisUnJour commencer à dresser cette liste (chose que j'ai commencé à faire avec cette note).
Journal du vendredi 17 mai 2024 à 11:05
Dans l'article "Qu'est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?" je découvre l'acronyme Génération Augmentée de Récupération.
Je constate qu'il existe un paragraphe à ce sujet sur Wikipedia.
The initial phase utilizes dense embeddings to retrieve documents.
Je tombe encore une fois sur "embeddings", #JaimeraisUnJour prendre le temps de comprendre correctement cette notion.
Prenez l'exemple d'une ligue sportive qui souhaite que les fans et les médias puisse utiliser un chat pour accéder à ses données et obtenir des réponses à leurs questions sur les joueurs, les équipes, l'histoire et les règles du sport, ainsi que les statistiques et les classements actuels. Un LLM généralisé pourrait répondre à des questions sur l'histoire et les règles ou peut-être décrire le stade d'une équipe donnée. Il ne serait pas en mesure de discuter du jeu de la nuit dernière ou de fournir des informations actuelles sur la blessure d'un athlète, parce que le LLM n'aurait pas ces informations. Étant donné qu'un LLM a besoin d'une puissance de calcul importante pour se réentraîner, il n'est pas possible de maintenir le modèle à jour.
Le contenu de ce paragraphe m'intéresse beaucoup, parce que c'était un de mes objectifs lorsque j'ai écrit cette note en juin 2023.
Sans avoir fait de recherche, je pensais que la seule solution pour faire apprendre de nouvelles choses — injecter de nouvelle données — dans un modèle était de faire du fine-tuning.
En lisant ce paragraphe, je pense comprendre que le fine-tuning n'est pas la seule solution, ni même, j'ai l'impression, la "bonne" solution pour le use-case que j'aimerais mettre en pratique.
En plus du LLM assez statique, la ligue sportive possède ou peut accéder à de nombreuses autres sources d'information, y compris les bases de données, les entrepôts de données, les documents contenant les biographies des joueurs et les flux d'actualités détaillées concernant chaque jeu.
#JaimeraisUnJour implémenter un POC pour mettre cela en pratique.
Dans la RAG, cette grande quantité de données dynamiques est convertie dans un format commun et stockée dans une bibliothèque de connaissances accessible au système d'IA générative.
Les données de cette bibliothèque de connaissances sont ensuite traitées en représentations numériques à l'aide d'un type spécial d'algorithme appelé modèle de langage intégré et stockées dans une base de données vectorielle, qui peut être rapidement recherchée et utilisée pour récupérer les informations contextuelles correctes.
Intéressant.
Il est intéressant de noter que si le processus de formation du LLM généralisé est long et coûteux, c'est tout à fait l'inverse pour les mises à jour du modèle RAG. De nouvelles données peuvent être chargées dans le modèle de langage intégré et traduites en vecteurs de manière continue et incrémentielle. Les réponses de l'ensemble du système d'IA générative peuvent être renvoyées dans le modèle RAG, améliorant ses performances et sa précision, car il sait comment il a déjà répondu à une question similaire.
Ok, si je comprends bien, c'est la "kill feature" du RAG versus du fine-tuning.
bien que la mise en oeuvre de l'IA générative avec la RAG est plus coûteux que l'utilisation d'un LLM seul, il s'agit d'un meilleur investissement à long terme en raison du réentrainement fréquent du LLM
Ok.
Bilan de cette lecture, je dis merci à Alexandre de me l'avoir partagé, j'ai appris RAG et #JePense que c'est une technologie qui me sera très utile à l'avenir 👌.
Fonctionnalité cluster and edit de OpenRefine
Il y a quelques semaines, #JaiDécouvert le #logiciel OpenRefine, qui permet de réaliser des tâches de #data-curation , plus précisément de #data-cleaning — mais pas seulement.
#JaimeraisUnJour prendre le temps d'essayer de nettoyer mes données Toggl avec OpenRefine.
Je lis ici que je peux manipuler plusieurs type de format de données :
From these sources, you can load any of the following file formats:
- comma-separated values (CSV) or text-separated values (TSV)
- Fixed-width columns
- JSON
et
OpenRefine can connect to PostgreSQL, MySQL, MariaDB, and SQLite database systems
Je souhaite particulièrement tester la fonctionnalité cluster and edit de OpenRefine et surtout les différentes méthode de clustering.
Opération de nettoyage, curation de mes données Toggl
Je souhaite nettoyer ( #data-cleaning, #data-curation ) une année de données que j'ai collectées avec l'application Toggl.
Chaque ligne de données ressemble à ceci :
start: "2024-05-12 09:00"
stop: "2024-05-12 09:23"
duration: 1380
description: "Rédaction d'une note éphémères au sujet du netoyage de données"
tags:
- écriture
- clean-data
Voici les opérations de nettoyage que j'aimerais réaliser :
- homogénéifier le contenu du champ "description" ;
- ajouter ou supprimer des tags sur une liste de lignes sélectionnées par l'application d'un filtre.
Jusqu'à présent, j'effectue ce nettoyage via l'application web Toggl. Cela n'est pas très agréable pour les raisons suivantes :
- Je trouve l'application très lente, ce qui m'insupporte !
- La saisie au clavier dans un champ input est lente.
- La recherche d'un tag est lente.
- ...
- Je ne peux pas sélectionner rapidement plusieurs lignes avec le clavier, je dois cliquer sur une case à cocher sur chaque ligne.
#JaimeraisUnJour trouver une méthode efficace et agréable pour réaliser mes tâches que #data-curation.
Journal du mercredi 01 mai 2024 à 12:05
#JeMeDemande si la librairie mdsvex me permet d'implémenter de manière agréable des nouveaux components qui ont la capacité d'aller chercher des données en backend, typiquement une base de données PostgreSQL.
J'aimerais que la requête soit décrite directement dans le markdown.
Je souhaite aussi que le composant soit rendu seulement côté serveur (SSR).
J'aimerais pouvoir implémenter quelque chose comme :
# Mon titre
Mon paragraphe
``sql posts
SELECT title FROM posts ORDER BY created_at LIMIT 10
``
<ul>
{#each posts as post}
<li>{post}</li>
{/each}
</ul>
(inspiration de https://evidence.dev/).
#JeMeDemande si mdsvex serait adapté pour cet objectif.
Je viens de voir ce thread Thoughts on Mdsvex moving away from Unified : sveltejs. Il contient un lien vers Penguin-flavoured markdown · pngwn/MDsveX · Discussion #293 · GitHub qui me semble intéressant #JaimeraisUnJour prendre le temps de le lire.
Autre thread What remark and rehype plugins are people using? · pngwn/MDsveX · Discussion #354 · GitHub.
#JeMeDemande si remark ou markdown-it serait mieux adapté pour atteindre mon objectif 🤔.
#JaiDécouvert (ou plutôt redécouvert) https://github.com/unifiedjs.
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Evidence semble implémenter un mécanisme qui ressemble à mon objectif et est codé en Svelte.
Journal du mercredi 01 mai 2024 à 11:05
Voici une liste non exhaustive de média que je n'utilise pas comme source d'information :
- Medium
- salons Discord
Et une première liste non exhaustive de mes sources d'informations :
- Univers Hacker
- Ma agréateur perso miniflux self hosted
- https://lobste.rs/
- https://news.ycombinator.com/
- https://lwn.net/ (j'ai une version payante)
- Fediverse https://mamot.fr/deck/getting-started
- https://old.reddit.com/
- https://linuxfr.org/
- Actualité générale :
Voir aussi Je suis abonné à ces chaines YouTube - Jardin numérique de Stéphane Klein/.
Cette note éhémères est très incomplète, je l'ai noté rapidement sur le vif.
#JaimeraisUnJour réaliser un document bien plus exaustif.
Pourquoi j'apprécie le framework SvelteKit ?
La partie que je préfère de plus dans le framework SvelteKit ce sont les fonctionnalités décrient dans la section Routing et Advanced routing de la documentation de SvelteKit.
Si vous survolez ces pages de documentation, vous allez peut-être me poser la question « ok et alors, c'est quoi le truc cool ? ». Je ne vais pas vous répondre maintenant, parce que c'est intégralité de ces deux pages de documentations qui faut lire avec une très grande attention. En utilisant SvelteKit dans plusieurs projets, j'ai appris à découvrir toutes les petites subtilités du système de rooting de SvelteKit.
#JaimeraisUnJour prendre le temps de paraphraser avec mes mots cette documentation pour partager avec vous l'enthousiasme que j'ai à l'égard de SvelteKit.
Est-ce que Nuxt ou NextJS sont moins élégants que SvelteKit ? Pour le moment, je ne sais pas, je n'ai pas pris assez de temps pour pousser assez loin la comparaison. C'est l'objectif de Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit".
Journal du mercredi 22 février 2023 à 10:47
J'ai sans doute découvert Tailwind CSS lors du lancement de sa version 1.0.0 en mai 2019, ou alors en février 2020 en parcourant ce thread Hacker News qui contient plus de 300 commentaires.
Après 2 années partagées entre scepticisme et grande curiosité au sujet de cette technologie et voyant la traction croissante de ce projet, début novembre 2022, j'ai décidé de creuser le sujet et de tester Tailwind CSS sur un side project.
En lisant de nombreux threads Hacker News ou Reddit sur Tailwind CSS, je constate toujours la même chose : c'est une technologie très clivante. Il y a ceux qui l'adorent et ceux, plus conservateurs, qui la trouvent complètement absurde.
Après plus de 3 mois d'utilisation de Tailwind CSS, je suis converti, je trouve l'expérience développeur (DX) excellente !
Un des éléments qui m'a fait reconsidérer ma position concernant Tailwind CSS est l'article "Why Tailwind CSS" de Shawn Wang (dit swyx), en particulier cette toute petite phrase :
A lot of production CSS is append only.
Cette déclaration me semble totalement juste et reflète exactement ce que je constate dans tous les projets CSS depuis 20 ans.
Cet article m'a aussi convaincu : Oh No! Our Stylesheet Only Grows and Grows and Grows! (The Append-Only Stylesheet Problem).
Cependant, je ne suis pas encore convaincu de l'intérêt de Tailwind CSS pour un site de contenu. Pour ce type de site, l'implémentation CSS me semble assez simple, par conséquent, je pense que le paradigme du CSS traditionnel, c'est-à-dire un CSS sémantique, reste plus pertinent.
Par ailleurs, je m'interroge sur l'impact du paradigme Tailwind CSS (utility CSS) concernant l'empreinte mémoire des pages.
J'ai le sentiment que la profusion d'attributs class="..." va probablement augmenter considérablement la taille des pages.
#JaimeraisUnJour prendre le temps de mesurer cet aspect.
Dernière page.