
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (1 notes) :
Premier test minimaliste de Promptfoo avec le provider OpenCode SDK
Depuis au moins novembre 2025, je cherche à rédiger mes prompts, mes fichiers AGENTS.md, mes fichiers SKILLS.md — et plus largement mon harness OpenCode — avec une méthode rigoureuse et contrôlée. J'ai découvert dans cette issue le nom du mécanisme que j'essaie de mettre en place : agent-eval-harness, terme plutôt simple et explicite.
En février, je disais :
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Quelques mois plus tard, j'ai enfin implémenté un premier POC utilisant Promptfoo couplé avec le provider OpenCode SDK : https://github.com/stephane-klein/opencode-promptfoo-poc.
Cette première itération est volontairement minimaliste. J'ai testé :
- 3 LLMs (dans 2 configurations chacune)
- 3 cas de test
L'intégralité de mon évaluation tient dans un seul fichier promptfooconfig.yaml :
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: "Hello World - minimal test"
providers:
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
prompts:
- "Translate the following English text to {{language}}: {{input}}"
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-all
value:
- "Bonjour"
- "monde"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: contains-any
value:
- "Donde esta la biblioteca"
providers:
- "with-agent*"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: not-contains-any
value:
- "Donde esta la biblioteca"
providers:
- "without-agent*"
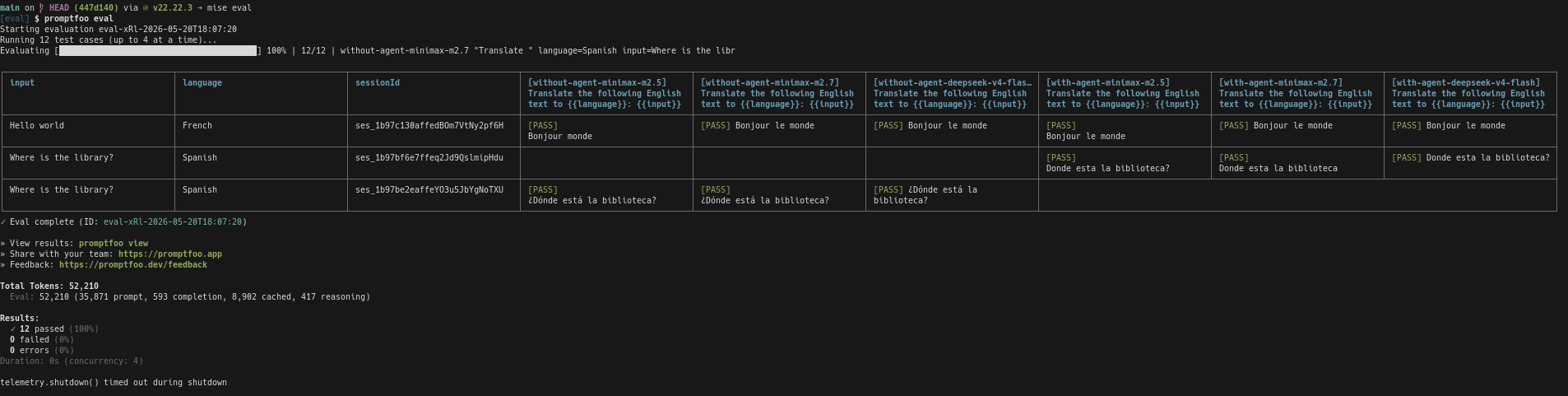
L'exécution de promptfoo eval donne ceci :
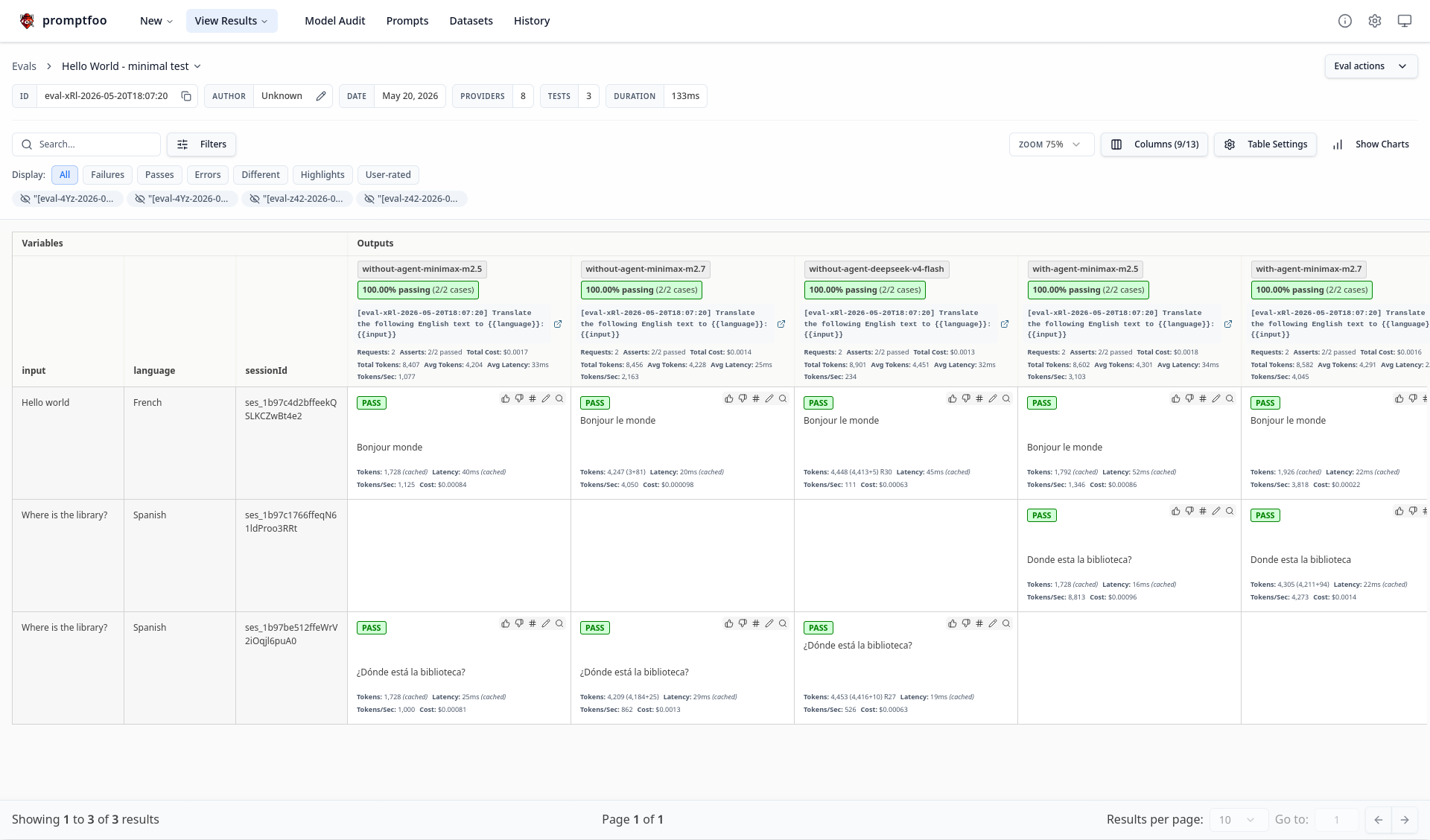
Et voici ce qu'affiche promptfoo viewer dans un browser :
Dans mes tests, j'ai mis en œuvre uniquement contains-all et contains-any, mais Promptfoo propose beaucoup d'autres « Deterministic metrics ».
Promptfoo propose aussi de nombreuses assertions effectuées par des modèles de langage, les « Model-graded metrics », dont la plupart peuvent être qualifiées de LLM-as-a-Judge. Je ne les ai pas encore testées.
Je n'ai pas non plus exploré l'évaluation de « Chat conversations / threads ». Par ailleurs, en examinant la documentation du provider OpenCode SDK, j'ai constaté ce qui me semble être une limitation : il n'est probablement pas possible de changer d'agent dans un thread, c'est-à-dire d'alterner entre le mode plan et le mode build, comme on le ferait dans un usage normal de OpenCode.
Mais après réflexion, il me semble que cette limitation n'est pas importante. Dans un test d'évaluation, chaque cas est un appel unique à l'agent, avec l'historique complet de la conversation fourni en contexte — il n'est pas nécessaire de simuler un flux interactif multi-tours avec alternance d'agents.
Dans ce POC, je configure le provider OpenCode SDK pour qu'il utilise le dossier de configuration ./config/opencode du repository, afin que le harness évalué soit précisément celui qui est versionné, et afin de ne pas subir de perturbation par la configuration OpenCode globale.
Quand j'ai démarré ce POC, j'ai essayé d'indiquer différentes configurations OpenCode au niveau des tests, pour tester différents fichiers AGENTS.md. Mais j'ai constaté que la configuration OpenCode ne peut être définie qu'une seule fois, ici, via une variable d'environnement XDG_CONFIG_HOME.
J'ai mis un certain temps à réaliser que je pouvais procéder autrement, en plaçant les fichiers AGENTS.md dans différents working_dir. Les working_dir se configurent au niveau des providers, voici deux exemples :
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
Cela permet de charger et de tester ./workdir1/AGENTS.md ou ./workdir2/AGENTS.md. Il est possible d'utiliser la même méthode pour évaluer différents SKILLS.md.
Pour le moment, je ne sais pas encore si Promptfoo est un bon outil pour mettre au point mon harness.
Avant de poursuivre mes tests de harness engineering avec Promptfoo, j'aimerais tester agent-catalog-eval pour voir si cet outil serait plus simple à mettre en œuvre.
Dernière page.