
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (9 notes) :
Journal du vendredi 03 janvier 2025 à 15:45
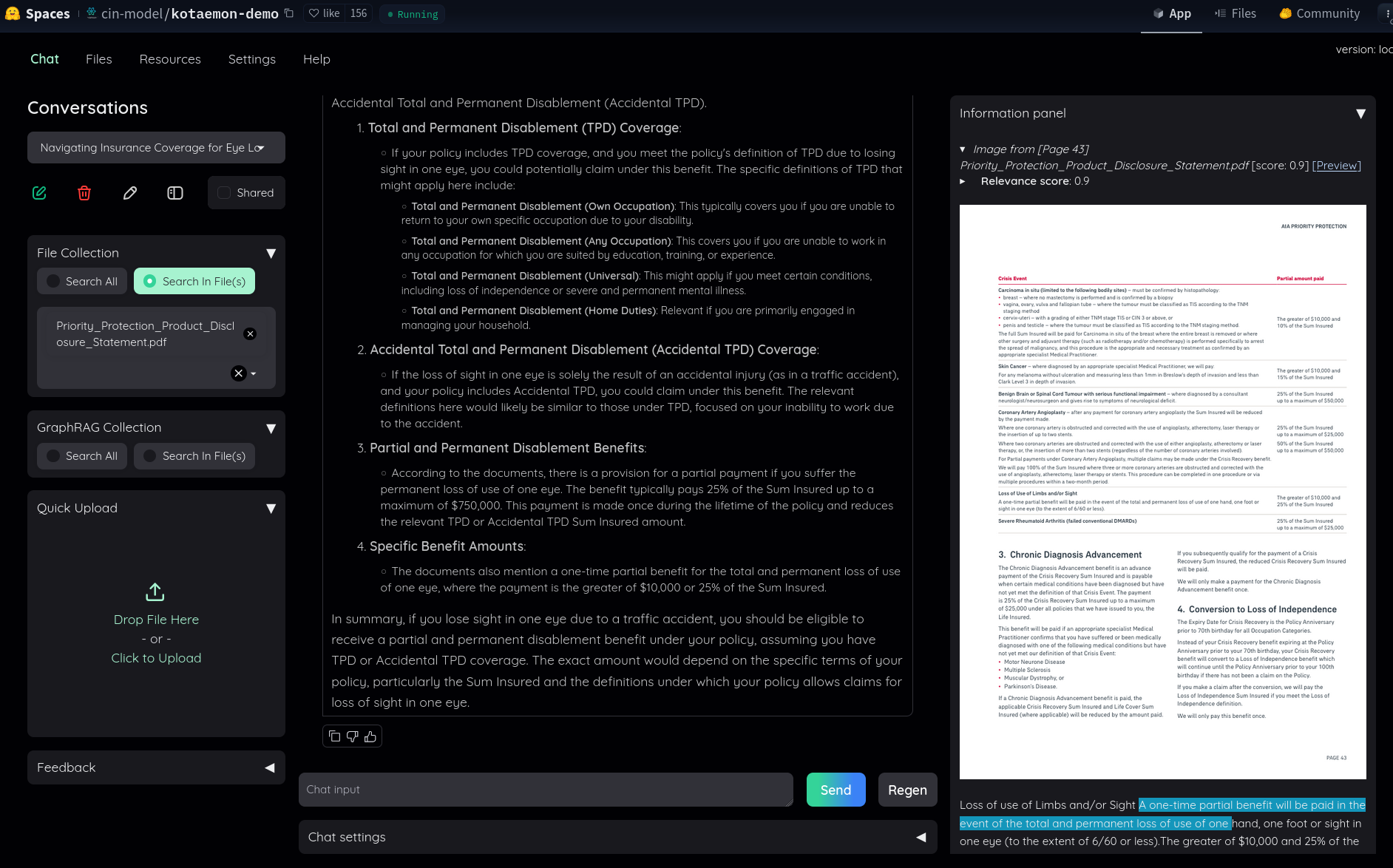
Dans ce thread Hacker News, #JaiDécouvert le RAG kotaemon (https://github.com/Cinnamon/kotaemon).
J'ai fait un simple test sur "Live Demo", j'ai trouvé le résultat très intéressant :
Dans le README, #JaiDécouvert GraphRAG (https://github.com/microsoft/graphrag), nano-graphrag (https://github.com/gusye1234/nano-graphrag) et LightRAG (https://github.com/HKUDS/LightRAG).
J'ai compris que kotaemon peut fonctionner avec nano-graphrag, LightRAG et GraphRAG et que nano-graphrag était recommandé.
J'ai lu :
Support for Various LLMs: Compatible with LLM API providers (OpenAI, AzureOpenAI, Cohere, etc.) and local LLMs (via
ollamaandllama-cpp-python).
J'ai l'impression que kotaemon est un outil de RAG complet, prêt à l'emploi, contrairement à llama_index qui se positionne davantage comme une bibliothèque de plus bas niveau.
Dans le Projet 20 - "Créer un POC d'un RAG", je pense commencer par tester kotaemon.
Journal du jeudi 26 décembre 2024 à 15:03
J'ai partagé Projet 20 - "Créer un POC d'un RAG" à un ami, il m'a dit « Pourquoi ne pas entraîner directement un modèle ? ».
Voici ma réponse sous forme de note.
Je tiens à préciser que je ne suis pas un expert du domaine.
Dans le manuscrit de l'épisode Augmenter ChatGPT avec le RAG de Science4All, je lis :
Quatre grandes catégories de solutions ont été proposées pour faire en sorte qu'un algorithme de langage apprenne une information.
Voici cette liste :
-
- le pré-entraînement, ou "pre-training" en anglais
-
- "peaufinage", qu'on appelle "fine-tuning" en anglais
Concernant le pre-training, je lis :
En pratique, ce pré-entraînement est toutefois très insuffisant pour que les algorithmes de langage soient capables de se comporter de manière satisfaisante.
Ensuite, je lis au sujet du fine-tuning :
Pour augmenter la fiabilité de l'algorithme, on peut alors effectuer un "peaufinage", qu'on appelle "fine-tuning" en anglais, et qui consiste typiquement à demander à des humains d'évaluer différentes réponses de l'algorithme.
...
Cependant, cette approche de peaufinage est coûteuse, à la fois en termes de ressources humaines et de ressources en calculs, et son efficacité est loin d'être suffisante pour une tâche aussi complexe que le langage.
Notez qu'on parle aussi de "peaufinage" pour la poursuite du pré-entraînement, mais cette fois sur des données proches du cas d'usage de l'algorithme. C'est typiquement le cas quand on part d'un algorithme open-weight comme Llama, et qu'on cherche à l'adapter aux contextes d'utilisation d'une entreprise particulière. Mais là encore, le coût de cette approche est important, et son efficacité est insuffisante.
Ensuite, au sujet du pré-prompting, je lis :
si cette approche est la plus efficace et la moins coûteuse, elle demeure encore très largement non-sécurisée ; et il faut s'attendre à ce que le chatbot déraille. Mais surtout, le pré-prompting est nécessairement limité car il ne peut pas être trop long.
Et, pour finir, je lis :
Je trouve que le paragraphe suivant donne une bonne explication du fonctionnement d'un RAG :
L'idée du RAG est la suivante : on va indexer tout un tas de documents qu'on souhaite enseigner à l'algorithme, et on va définir des méthodes pour lui permettre d'identifier, étant donné une requête d'un utilisateur, les bouts de documents qui sont les plus pertinents pour répondre à la requête de l'utilisateur. Ces bouts de documents sont ainsi "récupérés", et ils seront alors ajoutés à un preprompt fourni à l'algorithme, d'où "l'augmentation". Enfin, on va demander à l'algorithme de générer une réponse avec ce préprompt, d'où le nom de "Retrieval Augmented Generation". La boucle est bouclée !
Après lecture de ces informations, je pense qu'entrainer directement un modèle est une solution moins efficace qu'utiliser un RAG pour les objectifs décrits dans le Projet 20 - "Créer un POC d'un RAG".
Journal du vendredi 17 mai 2024 à 11:05
Dans l'article "Qu'est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?" je découvre l'acronyme Génération Augmentée de Récupération.
Je constate qu'il existe un paragraphe à ce sujet sur Wikipedia.
The initial phase utilizes dense embeddings to retrieve documents.
Je tombe encore une fois sur "embeddings", #JaimeraisUnJour prendre le temps de comprendre correctement cette notion.
Prenez l'exemple d'une ligue sportive qui souhaite que les fans et les médias puisse utiliser un chat pour accéder à ses données et obtenir des réponses à leurs questions sur les joueurs, les équipes, l'histoire et les règles du sport, ainsi que les statistiques et les classements actuels. Un LLM généralisé pourrait répondre à des questions sur l'histoire et les règles ou peut-être décrire le stade d'une équipe donnée. Il ne serait pas en mesure de discuter du jeu de la nuit dernière ou de fournir des informations actuelles sur la blessure d'un athlète, parce que le LLM n'aurait pas ces informations. Étant donné qu'un LLM a besoin d'une puissance de calcul importante pour se réentraîner, il n'est pas possible de maintenir le modèle à jour.
Le contenu de ce paragraphe m'intéresse beaucoup, parce que c'était un de mes objectifs lorsque j'ai écrit cette note en juin 2023.
Sans avoir fait de recherche, je pensais que la seule solution pour faire apprendre de nouvelles choses — injecter de nouvelle données — dans un modèle était de faire du fine-tuning.
En lisant ce paragraphe, je pense comprendre que le fine-tuning n'est pas la seule solution, ni même, j'ai l'impression, la "bonne" solution pour le use-case que j'aimerais mettre en pratique.
En plus du LLM assez statique, la ligue sportive possède ou peut accéder à de nombreuses autres sources d'information, y compris les bases de données, les entrepôts de données, les documents contenant les biographies des joueurs et les flux d'actualités détaillées concernant chaque jeu.
#JaimeraisUnJour implémenter un POC pour mettre cela en pratique.
Dans la RAG, cette grande quantité de données dynamiques est convertie dans un format commun et stockée dans une bibliothèque de connaissances accessible au système d'IA générative.
Les données de cette bibliothèque de connaissances sont ensuite traitées en représentations numériques à l'aide d'un type spécial d'algorithme appelé modèle de langage intégré et stockées dans une base de données vectorielle, qui peut être rapidement recherchée et utilisée pour récupérer les informations contextuelles correctes.
Intéressant.
Il est intéressant de noter que si le processus de formation du LLM généralisé est long et coûteux, c'est tout à fait l'inverse pour les mises à jour du modèle RAG. De nouvelles données peuvent être chargées dans le modèle de langage intégré et traduites en vecteurs de manière continue et incrémentielle. Les réponses de l'ensemble du système d'IA générative peuvent être renvoyées dans le modèle RAG, améliorant ses performances et sa précision, car il sait comment il a déjà répondu à une question similaire.
Ok, si je comprends bien, c'est la "kill feature" du RAG versus du fine-tuning.
bien que la mise en oeuvre de l'IA générative avec la RAG est plus coûteux que l'utilisation d'un LLM seul, il s'agit d'un meilleur investissement à long terme en raison du réentrainement fréquent du LLM
Ok.
Bilan de cette lecture, je dis merci à Alexandre de me l'avoir partagé, j'ai appris RAG et #JePense que c'est une technologie qui me sera très utile à l'avenir 👌.
Dépôt GitHub : https://github.com/microsoft/graphrag
Dépot GitHub : https://github.com/HKUDS/LightRAG
Dépôt GitHub : https://github.com/gusye1234/nano-graphrag
Dépôt GitHub : https://github.com/Cinnamon/kotaemon
Projet 20 - "Créer un POC d'un RAG"
Date de la création de cette note : 2024-12-20.
Quel est l'objectif de ce projet ?
Je souhaite réaliser un POC qui setup un Retrieval-augmented generation (RAG) qui permet d'aller chercher des informations dans des documents.
Fonctionnalités que j'aimerais arriver à implémenter :
- Le LLM doit pouvoir indiquer précisément ses sources pour chaque réponse.
- Le LLM devrait être en mesure de s’inspirer du style des documents importés dans le RAG.
- Les informations importées dans le RAG doivent avoir une priorité absolue sur les connaissances préexistantes du moteur LLM.
Je souhaite me baser sur LLaMa.
Dans ce projet, je souhaite aussi étudier les coûts d'hébergement d'un RAG.
Documents à importer dans le RAG ?
Mes critères de sélection sont les suivants :
- Des documents récents, contenant de préférence des informations inconnues des modèles LLaMa.
- Des documents en français.
- Des documents en libre accès.
- Si possible, avec peu de tableaux.
J’avais envisagé d’importer des threads de Hacker News via https://hnrss.github.io/, mais je préfère réaliser mes tests en français.
J’ai également exploré https://fr.wikinews.org, mais le projet contient malheureusement trop peu d’articles.
Finalement, je pense importer les 10 derniers articles disponibles sur https://www.projets-libres.org/interviews/.
Autres projets en lien avec celui-ci
Pourquoi je souhaite réaliser ce projet ?
Je souhaite implémenter un RAG depuis que j'ai commencé à utiliser ChatGPT — début 2023 (par exemple, ici ou ici).
Alexandre souhaite aussi réaliser ce type de POC : https://github.com/Its-Alex/backlog/issues/25.
Je pense qu'un RAG me serait utile pour interroger mon Personal knowledge management. Un RAG m'aurait été utile quand j'étais président du club de Tennis de Table d'Issy-les-Moulineaux.
De plus, j'ai plusieurs projets professionnels qui pourraient bénéficier d'un RAG.
Repository de ce projet :
rag-poc(je n'ai pas encore créé ce repository)
Liste de tâches
- [ ] Étudier kotaemon. Après cette étude, à moins d'avoir découvert des éléments bloquants :
- [ ] Réaliser un POC de kotaemon
- [ ] Étudier llama_index
Ressources :
- Augmenter ChatGPT avec le RAG de Science4All (version texte)
- https://github.com/topics/rag
- https://github.com/run-llama/llama_index
- https://github.com/run-llama/llama_parse
- https://www.youtube.com/watch?v=u5Vcrwpzoz8
- https://ollama.com/blog/embedding-models
- https://github.com/Cinnamon/kotaemon (voir note 2025-01-03_1545)
Dernière page.