
podman
Article Wikipedia : https://en.wikipedia.org/wiki/Podman
Voir aussi Podman Quadlets.
Journaux liées à cette note :
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Journal du lundi 22 septembre 2025 à 21:26
Dans le cadre du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab", j'étudie CoreOS.
Dans la page "Fedora CoreOS Release Notes stable" je vois quelques packages mis en avant :
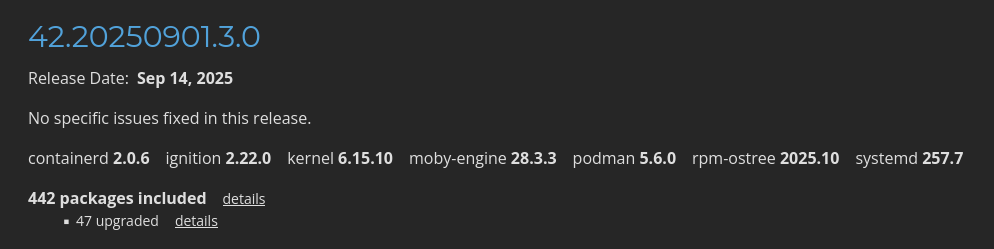
Je constate que CoreOS installe par défaut containerd, moby-engine et podman.
Information de type #mémento #mémo au sujet de containerd, moby-engine et podman.
- Kubernetes intéragie directement avec containerd.
- Depuis 2017, Docker est basé sur containerd + moby-engine. Sous Fedora, la commande
dockerest installée par le packagedocker-cli. - podman est une alternative rootless à Docker. podman n'est pas basé sur containerd, ni moby-engine.
Journal du lundi 09 décembre 2024 à 15:50
J'utilise la fonctionnalité Docker volume mounts dans tous mes projets depuis septembre 2015.
Généralement, sous la forme suivante :
services:
postgres:
image: postgres:17
...
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
D'après mes recherches, la fonctionnalité volumes mounts a été introduite dans la version 0.5.0 en juillet 2013.
À cette époque, je crois me souvenir que Docker permettait aussi de créer des volumes anonymes.
Je n'ai jamais apprécié les volumes anonymes, car lorsqu'un conteneur était supprimé, il devenait compliqué de retrouver le volume associé.
À cette époque, Docker était nouveau et j'avais très peur de perdre des données, par exemple, les volumes d'une instance PostgreSQL.
J'ai donc décidé qu'il était préférable de renoncer aux volumes anonymes et d'opter systématiquement pour des volume mounts.
Ensuite, peut-être en janvier 2016, Docker a introduit les named volumes, qui permettent de créer des volumes avec des noms précis, par exemple :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
name: postgres
$ docker volume ls
DRIVER VOLUME NAME
local postgres
Ce volume est physiquement stocké dans le dossier /var/lib/docker/volumes/postgres/_data.
Depuis, j'ai toujours préféré les volumes mounts aux named volumes pour les raisons pratiques suivantes :
- Travaillant souvent sur plusieurs projets, j'utilise les volume mounts pour éviter les collisions. Lorsque j'ai essayé les named volumes, une question s'est posée : quel nom attribuer aux volumes PostgreSQL ? «
postgres» ? Mais alors, quel nom donner au volume PostgreSQL dans le projet B ? Avec les volume mounts, ce problème ne se pose pas. - J'apprécie de savoir qu'en supprimant un projet avec
rm -rf ~/git/github.com/stephan-klein/foobar/, cette commande effacera non seulement l'intégralité du projet, mais également ses volumes Docker. - Avec les mounted volume, je peux facilement consulter le contenu des volumes. Je n'ai pas besoin d'utiliser
docker volume inspectpour trouver le chemin du volume.
La stratégie que j'ai choisie basée sur volumes mounts a quelques inconvénients :
- Le owner du dossier
volumes/, situé dans le répertoire du projet, estroot. Cela entraîne fréquemment des problèmes de permissions, par exemple lors de l'exécution des scripts de linter dans le dossier du projet. Pour supprimer le projet, je dois donc utilisersudo. Je précise que ce problème n'existe pas sous MacOS. Je pense que ce problème pourrait être contourné sous Linux en utilisant podman. - La commande
docker compose down -vne détruit pas les volumes.
Je suis pleinement conscient que ma méthode basée sur les volume mounts est minoritaire. En revanche, j'observe qu'une grande majorité des développeurs privilégie l'utilisation des named volumes.
Par exemple, cet été, un collègue a repris l'un de mes projets, et l'une des premières choses qu'il a faites a été de migrer ma configuration de volume mounts vers des named volumes pour résoudre un problème de permissions lié à Prettier, eslint ou Jest. En effet, la fonctionnalité ignore de ces outils ne fonctionne pas si NodeJS n'a pas les droits d'accès à un dossier du projet 😔.
Aujourd'hui, je me suis lancé dans la recherche d'une solution me permettant d'utiliser des named volumes tout en évitant les problèmes de collision entre projets.
Je pense que j'ai trouvé une solution satisfaisante 🙂.
Je l'ai décrite et testée dans le repository docker-named-volume-playground.
Ce repository d'exemple contient 2 projets distincts, nommés project_a et project_b.
J'ai instancié deux fois chacun de ces projets. Voici la liste des dossiers :
$ tree
.
├── project_a_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_a_instance_2
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_2
│ ├── docker-compose.yml
│ └── .envrc
└── README.md
Ce repository illustre l'organisation de plusieurs instances de différents projets sur la workstation du développeur.
Il ne doit pas être utilisé tel quel comme base pour un projet.
Par exemple, le "vrai" repository du projet projet_a se limiterait aux fichiers suivants : docker-compose.yml et .envrc.
Voici le contenu d'un de ces fichiers .envrc :
export PROJECT_NAME="project_a"
export INSTANCE_ID=$(pwd | shasum -a 1 | awk '{print $1}' | cut -c 1-12) # Used to define docker volume path
export COMPOSE_PROJECT_NAME=${PROJECT_NAME}_${INSTANCE_ID}
L'astuce que j'utilise est au niveau de INSTANCE_ID. Cet identifiant est généré de telle manière qu'il soit unique pour chaque instance de projet installée sur la workstation du développeur.
J'ai choisi de générer cet identifiant à partir du chemin complet vers le dossier de l'instance, je le passe dans la commande shasum et je garde les 12 premiers caractères.
J'utilise ensuite la valeur de COMPOSE_PROJECT_NAME dans le docker-compose.yml pour nommer le named volume :
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- 5432
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
volumes:
postgres:
name: ${COMPOSE_PROJECT_NAME}_postgres
Exemples de valeurs générées pour l'instance installée dans /home/stephane/git/github.com/stephane-klein/docker-named-volume-playground/project_a_instance_1 :
INSTANCE_ID=d4cfab7403e2COMPOSE_PROJECT_NAME=project_a_d4cfab7403e2- Nom du container postgresql :
project_a_d4cfab7403e2-postgres-1 - Nom du volume postgresql :
project_a_a04e7305aa09_postgres
Conclusion
Cette méthode me permet de suivre une pratique plus mainstream — utiliser les named volumes Docker — tout en évitant la collision des noms de volumes.
Je suis conscient que ce billet est un peu long pour expliquer quelque chose de simple, mais je tenais à partager l'historique de ma démarche.
Je pense que je vais dorénavant utiliser cette méthode pour tous mes nouveaux projets.
20224-12-10 11h27 : Je tiens à préciser qu'avec la configuration suivante :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
Quand le nom du volume postgres n'est pas défini, docker-compose le nomme sous la forme ${COMPOSE_PROJECT_NAME}_postgres. Si le projet est stocké dans le dossier foobar, alors le volume sera nommé foobar_postgres.
$ docker volume ls
DRIVER VOLUME NAME
local foobar_postgres