
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (43 notes) :
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
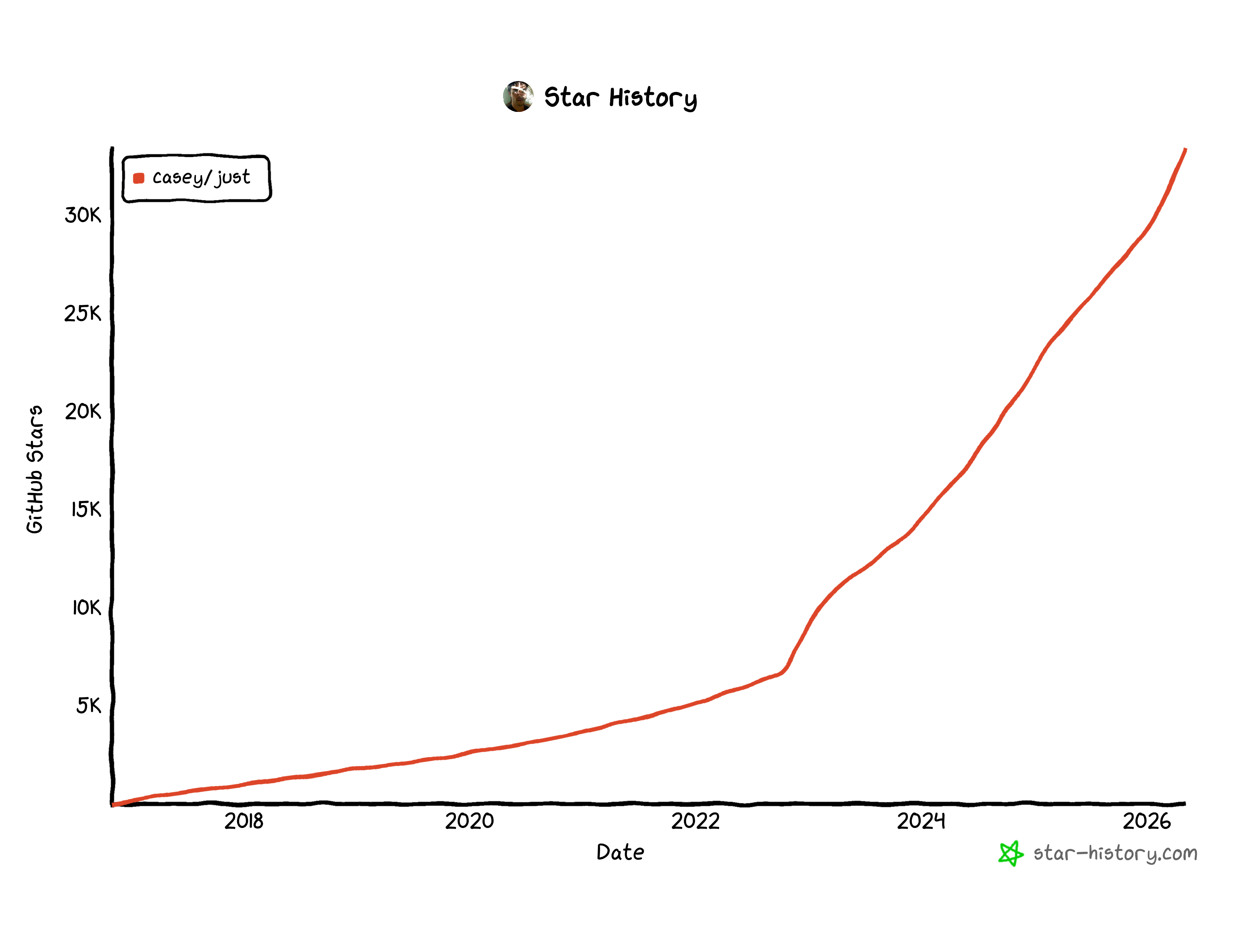
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
Journal du mercredi 03 décembre 2025 à 06:58
#JaiDécouvert usql (https://github.com/xo/usql) qui semble être une alternative à pgcli, écrit en Golang.
Je ne l'ai pas encore testé.
J'ai découvert Kiln, un outil de gestion de secret basé sur Age
#JaiDécouvert dans ce thread Hacker News le projet kiln (https://kiln.sh/).
kiln is a secure environment variable management tool that encrypts your sensitive configuration data using age encryption. It provides a simple, offline-first alternative to centralized secret management services, with role-based access control and support for both age and SSH keys, making it perfect for team collaboration and enterprise environments.
Je n'ai pas encore testé kiln mais j'ai l'intuition qu'il pourrait remplacer le workflow que j'ai présenté il y a quelque mois dans cette note : "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh".
Voici les informations que j'ai identifiées au sujet de kiln :
- Ce projet est très jeune
- Écrit en Golang
- Supporte des clés age ou des clés ssh.
- « Team Collaboration: Fine-grained role-based access control for team members and groups »
- What happens if someone leaves the team?
La lecture de la faq m'a fait penser que je n'ai toujours pas pris le temps d'étudier SOPS 🫣.
J'ai hâte de tester kiln qui grâce à Age me semble plus simple que le workflow basé sur pass, que j'ai utilisé professionnellement de 2019 à 2023.
J'ai découvert le support SSH agent de Bitwarden et ses conséquences sur l'utilisation de Age
J'ai utilisé le "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh" dans un projet professionnel et un collègue a rencontré un problème au niveau du script /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
Sa clé privée ssh n'était pas présente dans ~./ssh/ parce qu'il utilise "1Password SSH agent" (disponible depuis mars 2022).
Je ne connaissais pas cette fonctionnalité (merci).
#JaiDécouvert que cette fonctionnalité existe aussi dans Bitwarden depuis février 2025 : "SSH Agent".
#JaiDécouvert qu'une solution alternative pour Bitwarden existait depuis 2020 : bitwarden-ssh-agent. Mais beaucoup moins bien intégré à Bitwarden.
Au cours des 15 dernières années, j'ai régulièrement reçu des demandes de redéploiement de clés SSH de la part des développeurs, parfois plusieurs mois après leur onboarding. La cause principale : la plupart des développeurs ne pensent pas à sauvegarder leurs clés SSH dans leur gestionnaire de password et les perdent inévitablement lors du changement de workstation ou de réinstallation de leur système.
Face à ce constat récurrent, j'envisageais depuis plusieurs années de créer une issue chez Bitwarden pour leur proposer d'implémenter un système de sauvegarde automatique des clés SSH.
L'approche basée sur un ssh-agent ne m'avait jamais traversé l'esprit.
À l'avenir, j'envisage d'intégrer l'usage de Bitwarden SSH Agent (ou équivalent) dans les processus d'onboarding dont j'ai la responsabilité.
J'ai tenté d'ajouter le support de ssh-agent au script /scripts/decrypt_secrets.sh, mais d'après le thread "ssh-agent support", age ne semble pas supporter ssh-agent.
Conséquence : en attendant, j'ai demandé à mon collègue de placer sa clé privée ssh dans ~/.ssh/.
En attendant de trouver un repository Mise pour PostgreSQL Client Applications
À ce jour, je n'ai pas trouvé de repository Mise ou Asdf pour installer les "Client Applications" de PostgreSQL, par exemple : psql, pg_dump, pg_restore.
Il existe asdf-postgres, mais ce projet me pose quelques problèmes :
- L'installation basée sur le code source de PostgreSQL avec une phase de compilation qui peut être longue et consommer beaucoup d'espace disque.
- L'intégralité de PostgreSQL est installée alors que je n'ai besoin que des "Client Applications".
#JaimeraisUnJour créer une repository Mise ou Asdf qui permet d'installer les "Client Applications" en mode binaire. Pour le moment, je n'ai aucune idée sur quels binaires me baser 🤔.
En attendant de créer ou de trouver ce repository, voici ci-dessous mes méthodes actuelles d'installation des "PostgreSQL Client Applications".
Sous MacOS
Sous MacOS, j'utilise Brew pour installer le package libpq qui contient les "PostgreSQL Client Applications".
$ brew install libpq
ou alors pour l'installation d'une version spécifique :
$ brew install libpq@17.4
Sous Fedora
Sous Fedora, j'installe le package PostgreSQL client proposé sur la page "Downloads" officielle de PostgreSQL.
Cette méthode me permet d'installer précisément une version majeure précise de PostgreSQL :
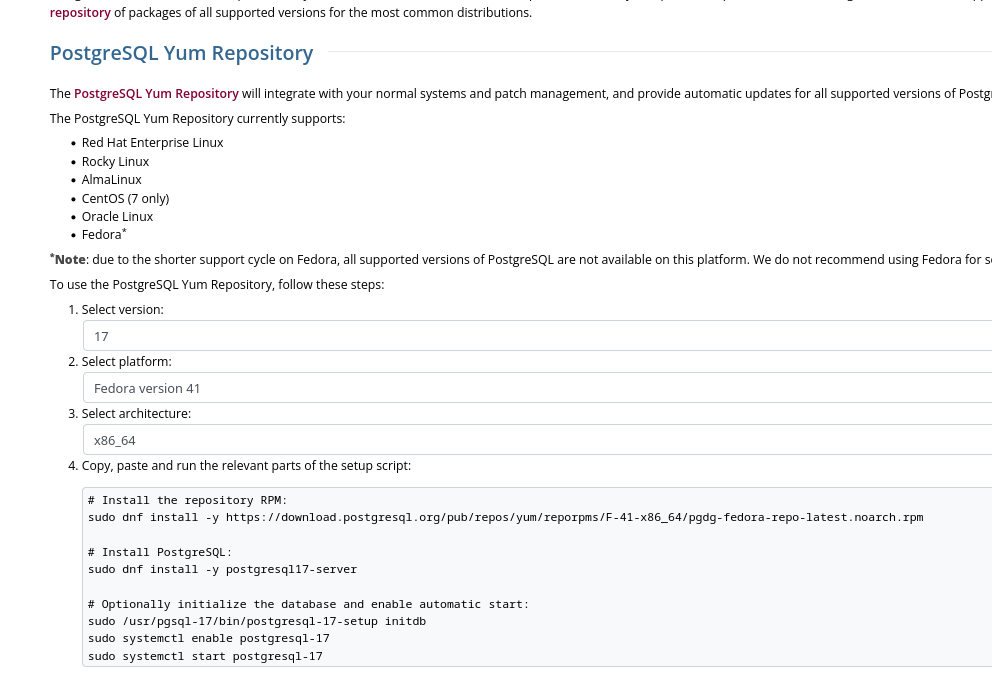
Voici les instructions pour installer la dernière version de PostgreSQL 17 sous Fedora 41 :
$ sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/F-41-x86_64/pgdg-fedora-repo-latest.noarch.rpm
$ sudo rpm --import https://download.postgresql.org/pub/repos/yum/keys/PGDG-RPM-GPG-KEY-Fedora
$ sudo dnf update -y
Le package nommé postgresql17 contient uniquement les "PostgreSQL Client Applications" :
$ dnf info postgresql17
Mise à jour et chargement des dépôts :
Dépôts chargés.
Paquets installés
Nom : postgresql17
Epoch : 0
Version : 17.4
Version : 1PGDG.f41
Architecture : x86_64
Taille une fois installé : 10.7 MiB
Source : postgresql17-17.4-1PGDG.f41.src.rpm
Dépôt d'origine : pgdg17
Résumé : PostgreSQL client programs and libraries
URL : https://www.postgresql.org/
Licence : PostgreSQL
Description : PostgreSQL is an advanced Object-Relational database management system (DBMS).
: The base postgresql package contains the client programs that you'll need to
: access a PostgreSQL DBMS server. These client programs can be located on the
: same machine as the PostgreSQL server, or on a remote machine that accesses a
: PostgreSQL server over a network connection. The PostgreSQL server can be found
: in the postgresql17-server sub-package.
:
: If you want to manipulate a PostgreSQL database on a local or remote PostgreSQL
: server, you need this package. You also need to install this package
: if you're installing the postgresql17-server package.
Fournisseur : PostgreSQL Global Development Group
$ dnf repoquery -l postgresql17 | grep "/bin"
Mise à jour et chargement des dépôts :
Dépôts chargés.
/usr/pgsql-17/bin/clusterdb
/usr/pgsql-17/bin/createdb
/usr/pgsql-17/bin/createuser
/usr/pgsql-17/bin/dropdb
/usr/pgsql-17/bin/dropuser
/usr/pgsql-17/bin/pg_basebackup
/usr/pgsql-17/bin/pg_combinebackup
/usr/pgsql-17/bin/pg_config
/usr/pgsql-17/bin/pg_createsubscriber
/usr/pgsql-17/bin/pg_dump
/usr/pgsql-17/bin/pg_dumpall
/usr/pgsql-17/bin/pg_isready
/usr/pgsql-17/bin/pg_receivewal
/usr/pgsql-17/bin/pg_restore
/usr/pgsql-17/bin/pg_waldump
/usr/pgsql-17/bin/pg_walsummary
/usr/pgsql-17/bin/pgbench
/usr/pgsql-17/bin/psql
/usr/pgsql-17/bin/reindexdb
/usr/pgsql-17/bin/vacuumdb
Installation de ce package :
$ sudo dnf install postgresql17
$ psql --version
psql (PostgreSQL) 17.4
Journal du mardi 25 février 2025 à 14:20
Alexandre vient de partager ce thread : « Asdf Version Manager Has Been Re-Written in Golang »
Je découvre que Asdf n'est pas mort ! La version 0.16.0 publié le 30 janvier 2025 a été réécrite en Golang !
La raison principale semble être une volonté d'amélioration de la vitesse de Asdf :
With improvements ranging from 2x-7x faster than asdf version 0.15.0!
Depuis cette date, Mise a publié un benchmark qui compare la vitesse d'exécution de Asdf et Mise : https://mise.jdx.dev/dev-tools/comparison-to-asdf.html#asdf-in-go-0-16.
Comme mon ami Alexandre, certains utilisateurs sont inquiets de voir Mise faire trop de choses :
I tried mise a while back, and the main reason I went away from it is like you said, it does too much. It tries to be asdf, direnv and a task runner. I just want a tool manager, and is the reason why I switched to aquaproj/aqua.
J'ai migré de Asdf vers Mise en novembre 2023 et pour le moment, je n'ai pas envie, ni de raison pratique particulière pour retourner à Asdf.
De plus, je suis plutôt satisfait d'avoir remplacé direnv par Mise, voir Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Journal du mardi 25 février 2025 à 09:35
Dans cette note, je souhaite décrire et expliquer comment j'intègre des sessions de terminal dans des documentations.
Convention mainstream que j'ai adoptée
Je suis la convention mainstream suivante pour représenter des sessions terminal (de type bash, zsh…) au format Markdown :
Première partie :
$ echo "Hello, world!" Hello, world! $ ls -l total 0 -rw-r--r-- 1 user user 0 Feb 25 10:00 file.txtSeconde partie :
$ sudo su # systemctl restart nginx $ exit $ uptime # Affiche l'uptime uptime 10:00:00 up 1 day, 2:45, 1 user, load average: 0.15, 0.10, 0.05
Les lignes commençant par $ ou # indiquent les commandes saisies par l'utilisateur, tandis que les autres correspondent aux sorties du terminal.
Il m'arrive également d'ajouter des commentaires en fin de ligne à l'aide de # ….
Origine de cette convention ?
J'ai cherché à retracer l'origine de cette pratique et elle semble très ancienne, probablement adoptée dès les débuts d'Unix en 1971.
On retrouve cette syntaxe notamment dans le livre The Unix Programming Environment (pdf), publié en 1984.
Ne pas inclure de $ si un bloc ne contient aucune sortie de commande
La règle MD014 de Markdownlint aborde ce sujet :
MD014 - Dollar signs used before commands without showing output
Tags: code
Aliases: commands-show-output
This rule is triggered when there are code blocks showing shell commands to be typed, and the shell commands are preceded by dollar signs ($):
$ ls $ cat foo $ less barThe dollar signs are unnecessary in the above situation, and should not be included:
ls cat foo less barHowever, an exception is made when there is a need to distinguish between typed commands and command output, as in the following example:
$ ls foo bar $ cat foo Hello world $ cat bar bazRationale: it is easier to copy and paste and less noisy if the dollar signs are omitted when they are not needed. See https://cirosantilli.com/markdown-style-guide#dollar-signs-in-shell-code for more information.
Pendant un certain temps, j’ai suivi la recommandation de ne pas inclure de $ dans un bloc de commande lorsqu’il n’affiche aucune sortie.
Après quelques années, j’ai décidé de ne plus appliquer cette règle pour la raison suivante :
- Lorsque la documentation mélange des fichiers de configuration et des commandes sans
$, j’ai du mal à distinguer ce qui doit être exécuté dans un terminal et ce qui relève de la configuration.
Pour éviter toute ambiguïté, j’ai adopté une approche radicale : toujours utiliser $ pour indiquer une commande à exécuter, même si le bloc ne contient pas de sortie.
Je n'aime pas les $ dans les blocs de commande, car que je ne peux pas copier / coller facilement !
Je comprends tout à fait cette remarque. Cependant, ces "screenshots" de session de terminal n'ont pas vocation à être copiées / collées en masse.
Ils ont avant tout une fonction explicative.
Ce sont des sortes de "screenshot".
Si j'éprouve le besoin de faire souvent des "copier / coller" d'exemples de session terminal, alors je considère que c'est le signe qu'un script "helper" serait plus approprié pour exécuter ce groupe de commandes d’un seul coup.
Par exemple, je peux remplacer ce contenu :
Ensure that the following prerequisites have been installed: mise and direnv, see instruction in ../README.md.
$ mise trust $ mise install $ scw version Version 2.34.0
Par celui-ci (qui indique l'existence du script ./scripts/mise-install.sh) :
Ensure that the following prerequisites have been installed: mise and direnv, see instruction in ../README.md (or execute
./scripts/mise-install.sh).$ mise trust $ mise install $ scw version Version 2.34.0
Cela évite les copier-coller répétitifs tout en conservant la clarté de l’explication.
Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh
Cette note est aussi disponible au format vidéo : https://www.youtube.com/watch?v=J9jsd4m9YkQ.
De 2018 à 2023, j'utilisais l'outil "pass" (https://www.passwordstore.org/) couplé avec GNU Privacy Guard pour chiffrer et déchiffrer les secrets dans mes projets professionnels.
Bien que cette méthode fonctionnait, elle s'avérait laborieuse.
La procédure documentant l'installation, la création des clés et la configuration de gnupg était l'étape posant le plus de difficultés d'onboarding des développeurs sur ces projets.
Au feeling, je dirais que trois développeurs sur quatre bloquaient à cette étape.
En parallèle à cette méthode, j'ai essayé d'utiliser la cli de Bitwarden, mais l'expérience n'a pas été très concluante, principalement à cause de problèmes de latence lors de son exécution.
Aujourd'hui, j'ai exploré une nouvelle méthode basée sur age et son support natif des clés ssh.
Voici le repository Git du résultat de cette exploration : age-secret-skeleton.
Le résultat est très positif et je pense avoir trouvé ma nouvelle méthode de chiffrement des secrets dans mes projets 🙂.
Pour en savoir plus, vous pouvez à la fois suivre le README.md du repository et continuer la lecture de cette note.
Détail des fichiers du repository
.
├── .envrc
├── .gitignore
├── .mise.toml
├── README.md
├── scripts
│ ├── decrypt_secrets.sh
│ └── encrypt_secrets.sh
├── .secret
├── .secret.age
├── .secret.skel
└── ssh-keys
├── john-doe.pub
└── stephane-klein.pub
/.secret: fichier qui contient les secrets en clair. Ce fichier est ignoré par.gitignoreafin qu'il ne soit pas présent dans le repository git/.secret.age: fichier qui contient le contenu du fichier.secretchiffré avec age. Ce fichier est ajouté au repository git./ssh-keys/: ce dossier contient les clés publiques ssh des personnes qui ont accès au contenu de.secret.age/scripts/decrypt_secrets.sh: permet de déchiffrer avec age le contenu de.secret.ageet écrit le résultat en clair dans.secret/scripts/encrypt_secrets.sh: permet de chiffrer avec age le contenu de.secretvers.secret.age. Ce script doit être exécuté quand le contenu de.secretest modifié ou quand une nouvelle clé est ajoutée dans/ssh-keys//.envrc: Dans ce skeleton, ce fichier charge uniquement les variables d'environnement présentes dans.secretmais dans un vrai projet, il permet de charger automatiquement des variables d'environnement qui ne sont pas des secrets./.secret.skel: ce fichier contient l'exemple de contenu du fichier.secret, sans les secrets. Par exemple :
# You can either request these secrets from Stéphane Klein (contact@stephane-klein.info)
# or, if your public ssh key is present in `./ssh-keys/` use the ./scripts/decrypt_secrets.sh command
# which will automatically decrypt the .secret.age file to .secret
export POSTGRES_PASSWORD="..."
export SCW_SECRET_KEY="..."
Ce fichier n'est pas nécessaire au bon fonctionnement du workflow mais je le trouve utile pour :
- documenter le contenu de
.secretaux personnes qui ont juste accès au dépôt Git - permettre de review les modifications de
.secret.skeldans des Merge Request.
Utilisation des clés ssh
L'un des avantages majeurs de age par rapport à pass + gnupg est son support natif des clés SSH pour chiffrer et déchiffrer les secrets.
Ainsi, je n'ai plus besoin de demander aux développeurs deux types de clés (SSH et gnupg) : une seule clé SSH suffit.
De plus, il me semble qu'un grand nombre de développeurs possèdent déjà une clé SSH, alors que je pense que gnupg reste une technologie bien moins répandue.
Détail d'implémentation des scripts
Vvoici le contenu de /scripts/encrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare recipient arguments for age
recipient_args=()
for pubkey in ./ssh-keys/*.pub; do
if [ -f "$pubkey" ]; then
recipient_args+=("-R" "$pubkey")
fi
done
# Execute age with all public keys
age "${recipient_args[@]}" -o .secret.age .secret
La boucle permet de passer toutes les clés ssh du dossier /ssh-keys/* en paramètre d' age.
Voici le contenu de /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
La boucle permet de passer en paramètre toutes les clés privées ssh du dossier ~/.ssh/ en espérant en trouver une qui correspond à une clé publique du dossier /ssh-keys/.
Plusieurs niveaux de sécurisation
Si je veux cloisonner les secrets en limitant leur accès à des groupes d'utilisateurs distincts, je peux utiliser des secrets différents selon l'environnement.
Par exemple :
.
├── production
│ ├── .secret.age
│ └── ssh-keys
└── sandbox
├── .secret.age
└── ssh-keys
Cette structure me permet de donner à certains utilisateurs accès aux secrets de l'environnement sandbox, sans leur donner accès à ceux de production.
Aller plus loin avec par exemple Vault ?
Je pense qu'il est possible d'aller plus loin en matière de sécurité avec des solutions comme Vault, mais trouve que la méthode basée sur age reste plus simple à déployer dans une petite équipe.
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Merci à Alexandre 🤗 qui a pris le temps de tester l'installation sous WSL2 du playground que j'ai présenté dans "Playground qui présente comment je setup un projet Python Flask en 2025".
Le playground : https://github.com/stephane-klein/mise-python-flask-playground
Après quelques petites corrections https://github.com/stephane-klein/mise-python-flask-playground/commits/main/ Alexandre a réussi avec succès à installer et lancer tous les services sous Windows 11 avec WSL2.
C'est une très bonne nouvelle 🙂.
Cela ajoute une « corde à mon arc ». Jusqu'à présent, je précisais bien que mes development kit n'étaient pas compatible MS Windows. Je le mentionnais même dans mes annonces d'embauche, pour ne pas surprendre les candidats.
Maintenant, mes environnements de développement sont compatibles Linux, MacOS, et Linux 🙂.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Je découvre Colima, installation minimaliste de Docker sous MacOS
#JaiDécouvert le projet Colima : https://github.com/abiosoft/colima
Colima - container runtimes on macOS (and Linux) with minimal setup.
Support for Intel and Apple Silicon Macs, and Linux
- Simple CLI interface with sensible defaults
- Automatic Port Forwarding
- Volume mounts
- Multiple instances
- Support for multiple container runtimes
- Docker (with optional Kubernetes)
- Containerd (with optional Kubernetes)
- Incus (containers and virtual machines)
Colima est une solution minimaliste qui permet d'installer sous MacOS docker-engine sans Docker Desktop.
Thread Hacker News à ce sujet de 2023 : Colima: Container runtimes on macOS (and Linux) with minimal setup.
Méthode d'installation que je suis sous MacOS avec Brew :
$ brew install colima docker docker-compose
$ cat << EOF > ~/.docker/config.json
{
"auths": {},
"currentContext": "colima",
"cliPluginsExtraDirs": [
"/opt/homebrew/lib/docker/cli-plugins"
]
}
EOF
$ brew services start colima
Comme indiqué ici, la modification du fichier ~/.docker/config.json permet d'activer de plugin docker compose, ce qui permet d'utiliser, par exemple :
$ docker compose ps
Qui est, depuis 2020, la méthode recommandée d'utiliser docker compose sans -.
Vérification, que tout est bien installé et lancé :
$ colima status
INFO[0000] colima is running using macOS Virtualization.Framework
INFO[0000] arch: aarch64
INFO[0000] runtime: docker
INFO[0000] mountType: sshfs
INFO[0000] socket: unix:///Users/m1/.colima/default/docker.sock
$ docker info
Client: Docker Engine - Community
Version: 27.5.1
Context: colima
Debug Mode: false
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 1
Server Version: 27.4.0
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 88bf19b2105c8b17560993bee28a01ddc2f97182
runc version: v1.2.2-0-g7cb3632
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: builtin
cgroupns
Kernel Version: 6.8.0-50-generic
Operating System: Ubuntu 24.04.1 LTS
OSType: linux
Architecture: aarch64
CPUs: 2
Total Memory: 1.914GiB
Name: colima
ID: 7fd5e4bd-6430-4724-8238-e420b3f23609
Docker Root Dir: /var/lib/docker
Debug Mode: false
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
J'ai suivi de loin l'histoire de Docker Desktop qui est devenu "propriétaire". Je viens prendre le temps d'étudier un peu le sujet, et voici ce que j'ai trouvé :
August 2021: Docker Desktop for Windows and MacOS was no longer available free of charge for enterprise users. Docker ended free Docker Desktop use for larger business customers and replaced its Free Plan with a Personal Plan. Docker on Linux distributions remained unaffected.
Sur le site officiel, sur la page "docker.desktop", quand je clique sur « Choose plan » je tombe sur ceci :

Je n'ai pas tout compris, j'ai l'impression qu'il est tout de même possible d'installer et d'utiliser gratuitement Docker Desktop.
Au final, tout cela n'a pas beaucoup d'importance pour moi, je ne trouve aucune utilité à Docker Desktop, par conséquent, sous MacOS j'utilise Colima.
J'ai vu qu'il est possible d'installer Colima sous Linux, mais je ne l'utilise pas, car je n'y vois aucun intérêt pour le moment.
J'ai publié deux nouveaux playgrounds :
Cela fait depuis 2018 que je souhaite tester la génération d'un certificat de type "wildcard" avec le challenge DNS-01 de la version 2 de ACME.
Bonne nouvelle, j'ai testé avec succès cette fonctionnalité dans le playground : dnsrobocert-playground.
Est-ce que je vais généraliser l'usage de certificats wildcard générés avec un challenge DNS-01 à la place de multiples challenge HTTP-01 ?
Pour le moment, je n'en ai aucune idée. J'ai utilisé un challenge DNS-01 pour déployer sish.
L'avantage d'un certificat wildcard réside dans le fait qu'il n'a besoin d'être généré qu'une seule fois et peut ensuite être utilisé pour tous les sous-domaines. Toutefois, il doit être mis à jour tous les 90 jours.
Actuellement, je n'ai pas trouvé de méthode pratique pour automatiser son déploiement.
Par exemple, pour nginx, il serait nécessaire d'automatiser l'upload du certificat dans le volume du conteneur nginx, ainsi que l'exécution de la commande nginx -s reload pour recharger le certificat.
Concernant le second playground, j'ai réussi à déployer avec succès sish.
Voici un exemple d'utilisation :
$ ssh -p 2222 -R test:80:localhost:8080 playground.stephane-klein.info
Press Ctrl-C to close the session.
Starting SSH Forwarding service for http:80. Forwarded connections can be accessed via the following methods:
HTTP: http://test.playground.stephane-klein.info
HTTPS: https://test.playground.stephane-klein.info
Je trouve l'usage plutôt simple.
Je compte déployer sish sur sish.stephane-klein.info pour mon usage personnel.
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞
Le 6 novembre 2024, j'ai publié la note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
L'issue indiquée dans cette note a été cloturée il y a 3 jours : Use mise tools in env template · Issue #1982.
Voici le contenu de changement de la documentation : https://github.com/jdx/mise/pull/3598/files#diff-e8cfa8083d0343d5a04e010a9348083f7b64035c407faa971074c6f0e8d0d940
Ce qui signifie que je vais pouvoir maintenant utiliser terraform installé via Mise dans le fichier .envrc :
[env]
_.source = { value = "./.envrc.sh", tools = true }
[tools]
terraform="1.9.8"
Après avoir installé la dernière version de Mise, j'ai testé cette configuration dans repository suivant : install-and-configure-mise-skeleton.
Le fichier .envrc suivant a fonctionné :
export HELLO_WORLD=foo3
export NOW=$(date)
export TERRAFORM_VERSION=$(terraform --version | head -n1)
Exemple :
$ mise trust
$ echo $TERRAFORM_VERSION
Terraform v1.9.8
Je n'ai pas trouvé de commande Mise pour recharger les variables d'environnement du dossier courant, sans quitter le dossier. Avec direnv, pour effectuer un rechargement je lançais : direnv allow.
À la place, j'ai trouvé la méthode suivante :
$ source .envrc
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Qu'est-ce qu'un "Script Helper" ?
J'utilise souvent le terme "Script Helper". Dans cette note, je vais tenter de le définir.
Un script dit « helper » est un script qui n'est pas essentiel au cœur du projet et qui ne contient pas de code métier. Son rôle est d’automatiser des tâches courantes et réutilisables pour le développeur.
L’écriture de ces scripts permet de centraliser et de versionner leur contenu, tout en réduisant les risques d’erreurs d’exécution.
Ma définition et objectif d'un "Workspace" dans un "environnement de développement" ?
Dans une note précédente, j'ai donné ma définition et les objectifs d'un "Development kit".
Dans cette note, je souhaite donner ma définition et les objectifs d'un workspace dans un "environnements de développement".
Un workspace est un dossier, qui contient des paramètres de configuration spécifiques — généralement sous la forme de variables d'environnements — qui permettent d'interagir sur une ou plusieurs instances de services, d'un environnement précis.
Généralement ce dossier contient des guides d'instructions pour réaliser des actions spécifiques sur le workspace et des scripts de type "helpers".
Exemple de workspaces :
staging/remote-workspace/: un workspace utilisé pour effectuer des actions sur les services déployés en staging sur des serveurs distants ;staging/local-workspace/: un workspace d'installer localement des services dans les mêmes conditions que sur l'environnement staging ;development/local-workspace/: un dossier workspace, qui permet de travailler — contribuer — localement sur le ou les services.
Voir aussi :
Journal du lundi 09 décembre 2024 à 15:50
J'utilise la fonctionnalité Docker volume mounts dans tous mes projets depuis septembre 2015.
Généralement, sous la forme suivante :
services:
postgres:
image: postgres:17
...
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
D'après mes recherches, la fonctionnalité volumes mounts a été introduite dans la version 0.5.0 en juillet 2013.
À cette époque, je crois me souvenir que Docker permettait aussi de créer des volumes anonymes.
Je n'ai jamais apprécié les volumes anonymes, car lorsqu'un conteneur était supprimé, il devenait compliqué de retrouver le volume associé.
À cette époque, Docker était nouveau et j'avais très peur de perdre des données, par exemple, les volumes d'une instance PostgreSQL.
J'ai donc décidé qu'il était préférable de renoncer aux volumes anonymes et d'opter systématiquement pour des volume mounts.
Ensuite, peut-être en janvier 2016, Docker a introduit les named volumes, qui permettent de créer des volumes avec des noms précis, par exemple :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
name: postgres
$ docker volume ls
DRIVER VOLUME NAME
local postgres
Ce volume est physiquement stocké dans le dossier /var/lib/docker/volumes/postgres/_data.
Depuis, j'ai toujours préféré les volumes mounts aux named volumes pour les raisons pratiques suivantes :
- Travaillant souvent sur plusieurs projets, j'utilise les volume mounts pour éviter les collisions. Lorsque j'ai essayé les named volumes, une question s'est posée : quel nom attribuer aux volumes PostgreSQL ? «
postgres» ? Mais alors, quel nom donner au volume PostgreSQL dans le projet B ? Avec les volume mounts, ce problème ne se pose pas. - J'apprécie de savoir qu'en supprimant un projet avec
rm -rf ~/git/github.com/stephan-klein/foobar/, cette commande effacera non seulement l'intégralité du projet, mais également ses volumes Docker. - Avec les mounted volume, je peux facilement consulter le contenu des volumes. Je n'ai pas besoin d'utiliser
docker volume inspectpour trouver le chemin du volume.
La stratégie que j'ai choisie basée sur volumes mounts a quelques inconvénients :
- Le owner du dossier
volumes/, situé dans le répertoire du projet, estroot. Cela entraîne fréquemment des problèmes de permissions, par exemple lors de l'exécution des scripts de linter dans le dossier du projet. Pour supprimer le projet, je dois donc utilisersudo. Je précise que ce problème n'existe pas sous MacOS. Je pense que ce problème pourrait être contourné sous Linux en utilisant podman. - La commande
docker compose down -vne détruit pas les volumes.
Je suis pleinement conscient que ma méthode basée sur les volume mounts est minoritaire. En revanche, j'observe qu'une grande majorité des développeurs privilégie l'utilisation des named volumes.
Par exemple, cet été, un collègue a repris l'un de mes projets, et l'une des premières choses qu'il a faites a été de migrer ma configuration de volume mounts vers des named volumes pour résoudre un problème de permissions lié à Prettier, eslint ou Jest. En effet, la fonctionnalité ignore de ces outils ne fonctionne pas si NodeJS n'a pas les droits d'accès à un dossier du projet 😔.
Aujourd'hui, je me suis lancé dans la recherche d'une solution me permettant d'utiliser des named volumes tout en évitant les problèmes de collision entre projets.
Je pense que j'ai trouvé une solution satisfaisante 🙂.
Je l'ai décrite et testée dans le repository docker-named-volume-playground.
Ce repository d'exemple contient 2 projets distincts, nommés project_a et project_b.
J'ai instancié deux fois chacun de ces projets. Voici la liste des dossiers :
$ tree
.
├── project_a_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_a_instance_2
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_2
│ ├── docker-compose.yml
│ └── .envrc
└── README.md
Ce repository illustre l'organisation de plusieurs instances de différents projets sur la workstation du développeur.
Il ne doit pas être utilisé tel quel comme base pour un projet.
Par exemple, le "vrai" repository du projet projet_a se limiterait aux fichiers suivants : docker-compose.yml et .envrc.
Voici le contenu d'un de ces fichiers .envrc :
export PROJECT_NAME="project_a"
export INSTANCE_ID=$(pwd | shasum -a 1 | awk '{print $1}' | cut -c 1-12) # Used to define docker volume path
export COMPOSE_PROJECT_NAME=${PROJECT_NAME}_${INSTANCE_ID}
L'astuce que j'utilise est au niveau de INSTANCE_ID. Cet identifiant est généré de telle manière qu'il soit unique pour chaque instance de projet installée sur la workstation du développeur.
J'ai choisi de générer cet identifiant à partir du chemin complet vers le dossier de l'instance, je le passe dans la commande shasum et je garde les 12 premiers caractères.
J'utilise ensuite la valeur de COMPOSE_PROJECT_NAME dans le docker-compose.yml pour nommer le named volume :
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- 5432
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
volumes:
postgres:
name: ${COMPOSE_PROJECT_NAME}_postgres
Exemples de valeurs générées pour l'instance installée dans /home/stephane/git/github.com/stephane-klein/docker-named-volume-playground/project_a_instance_1 :
INSTANCE_ID=d4cfab7403e2COMPOSE_PROJECT_NAME=project_a_d4cfab7403e2- Nom du container postgresql :
project_a_d4cfab7403e2-postgres-1 - Nom du volume postgresql :
project_a_a04e7305aa09_postgres
Conclusion
Cette méthode me permet de suivre une pratique plus mainstream — utiliser les named volumes Docker — tout en évitant la collision des noms de volumes.
Je suis conscient que ce billet est un peu long pour expliquer quelque chose de simple, mais je tenais à partager l'historique de ma démarche.
Je pense que je vais dorénavant utiliser cette méthode pour tous mes nouveaux projets.
20224-12-10 11h27 : Je tiens à préciser qu'avec la configuration suivante :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
Quand le nom du volume postgres n'est pas défini, docker-compose le nomme sous la forme ${COMPOSE_PROJECT_NAME}_postgres. Si le projet est stocké dans le dossier foobar, alors le volume sera nommé foobar_postgres.
$ docker volume ls
DRIVER VOLUME NAME
local foobar_postgres
Journal du dimanche 08 décembre 2024 à 22:19
Je viens de rencontrer l'outil envdir (à ne pas confondre avec direnv) et son modèle de stockage de variables d'environnement, que je trouve très surprenant !
direnv ou dotenv utilisent de simples fichiers texte pour stocker les variables d'environnements, par exemple :
export POSTGRES_URL="postgres://postgres:password@localhost:5432/postgres"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export MAIL_FROM="noreply@example.com"
Contrairement à ces deux outils, pour définir ces quatre variables, le modèle de stockage de envdir nécessite la création de 4 fichiers :
$ tree .
.
├── MAIL_FROM
├── POSTGRES_URL
├── SMTP_HOST
└── SMTP_PORT
1 directory, 4 files
$ cat POSTGRES_URL
postgres://postgres:password@localhost:5432/postgres
$ cat SMTP_HOST
127.0.0.1
$ cat SMTP_PORT
1025
$ cat MAIL_FROM
127.0.0.1
Je trouve ce modèle fort peu pratique. Contrairement à un simple fichier unique, le modèle de envdir présente certaines limitations :
- Organisation : il ne permet pas de structurer librement l'ordre ou de regrouper visuellement les variables.
- Lisibilité : l'ensemble de la configuration est plus difficile à visualiser d'un seul coup d'œil.
- Manipulation : copier ou coller son contenu n'est pas aussi direct qu'avec un fichier texte.
- Documentation : les commentaires ne peuvent pas être inclus pour expliquer les variables.
- Rapidité : la saisie ou la modification de plusieurs variables demande plus de temps, chaque variable étant dans un fichier distinct.
J'ai été particulièrement intrigué par le choix fait par l'auteur de envdir. Sa décision semble vraiment surprenante.
envdir fait partie du projet daemontools, créé en 1990. Ainsi, il est bien plus ancien que dotenv, qui a été lancé autour de 2010, et direnv, qui date de 2014.
Si je me remets dans le contexte des années 1990, je pense que le modèle de envdir a été avant tout motivé par une simplicité d'implémentation plutôt que d'utilisation. En effet, il est plus facile de lister les fichiers d'un répertoire et de charger leur contenu que de développer un parser de fichiers.
Je pense qu'en 2024, envdir n'a plus sa place dans un environnement informatique moderne. Je recommande vivement de le remplacer par des solutions plus récentes, comme devenv ou direnv.
Personnellement, j'utilise direnv dans tous mes projets.
Journal du mercredi 04 décembre 2024 à 14:56
Alexandre a eu un breaking change avec Mise : https://github.com/jdx/mise/issues/3338.
Suite à cela, j'ai découvert que Mise va prévilégier l'utilisation du backend aqua plutôt que Asdf :
we are actively moving tools in the registry away from asdf where possible to backends like aqua and ubi which don't require plugins.
J'ai découvert au passage que Mise supporte de plus en plus de backend, par exemple Ubi et vfox.
Je constate qu'il commence à y avoir une profusion de "tooling version management" : Asdf,Mise, aqua, Ubi, vfox !
Je pense bien qu'ils ont chacun leurs histoires, leurs forces, leurs faiblesses… mais j'ai peur que cela me complique mon affaire : comment arriver à un consensus de choix de l'un de ces outils dans une équipe 🫣 ! Chaque développeur aura de bons arguments pour utiliser l'un ou l'autre de ces outils.
Constatant plusieurs fois que le développeur de Mise a fait des breaking changes qui font perdre du temps aux équipes, mon ami et moi nous sommes posés la question si, au final, il ne serait pas judicieux de revenir à Asdf.
D'autre part, au départ, Mise était une simple alternative plus rapide à Asdf, mais avec le temps, Mise prend en charge de plus en plus de fonctionnalités, comme une alternative à direnv , un système d'exécution de tâches, ou mise watch.
Souvent, avec des petits défauts très pénibles, voir par exemple, ma note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
Alexandre s'est ensuite posé la question d'utiliser un jour le projet devenv, un outil qui va encore plus loin, basé sur le système de package Nix.
Le projet devenv me fait un peu peur au premier abord, il gère "tout" :
- Comme Asdf et Mise : l'installation des outils, packages et langages
- Support de scripts "helper"
- Intégration de Docker
- Support de process
- Support du SDK Android
Il fait énormément de choses et je crains que la barrière à l'entrée soit trop haute et fasse fuir beaucoup de développeurs 🤔.
Tout cela me fait un peu penser à Bazel (utilisé par Google), Pants (utilisé par Twitter), Buck (utilisé par Facebook) et Please.
Tous ces outils sont puissants, je les ai étudiés en 2018 sans arrivée à les adopter.
Pour le moment, mes development kit nécessitent les compétences suivantes :
- Comprendre les rudiments d'un terminal Bash ;
- Arriver à installer et à utiliser Mise et direnv ;
- Maitriser Docker ;
- Savoir lire et écrire des scripts Bash de niveau débutant.
Déjà, ces quatre prérequis posent quelques fois des difficultés d'adoption.
Journal du mercredi 04 décembre 2024 à 10:14
#JaiDécouvert l'outil de "version manager" nommé aqua, une alternative à Mise et Asdf codé en Golang.
Ce projet semble avoir débuté en août 2021.
J'ai fait quelques recherches au sujet d'aqua sur Hacker News, j'ai trouvé très peu d'occurrences. J'ai trouvé "Ask HN: Homebrew, Asdf, Nix, or Other?".
Je pense qu'aqua est bien moins populaire que Asdf et Mise.
Au 4 décembre 2024 :
Journal du jeudi 21 novembre 2024 à 17:36
Dans la note 2024-11-20_1102, je disais :
Prochaine étape du Projet 17 : Setup les iOS Requirements de Capacitor sur ce serveur Apple Silicon.
C'est chose faite 🙂.
Le repository poc-capacitor contient maintenant un script ./scripts/deploy-ios-requirements.sh qui permet d'exécuter ce script de provisioning sur le serveur Scaleway Apple Silicon distant : /provisioning/_ios.sh.
Ensuite, j'ai détaillé les étapes pour :
- Uploader le projet sur le Scaleway Apple Silicon distant
- Démarrer l'émulation d'un iPhone 15
- Compiler et lancer l'application Capacitor dans l'émulateur iPhone 15
- Et visualiser l'émulateur via VNC
Tout cela est détaillé ici : https://github.com/stephane-klein/poc-capacitor/tree/f109fb23dc612f486fad0d55ba939b4679841d06?tab=readme-ov-file#launch-application-on-ios
Je teste l'offre Scaleway Apple Silicon
Dans le projet "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor" je disais :
- Essayer d'utiliser l'offre Apple Mac mini M1 de Scaleway pour builder l'app pour iOS
Voici mon retour d'expérience d'utilisation de l'offre Scaleway Apple Silicon.
Voici la liste des images MacOS disponibles :
$ scw apple-silicon os list
ID NAME LABEL IMAGE URL FAMILY IS BETA VERSION XCODE VERSION
59bf09f1-5584-469d-a0f6-55c8fee1ab81 macos-ventura-13.6 macOS Ventura 13.6 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-ventura.png Ventura false 13.6 14
e08d1e5d-b4b9-402a-9f9a-97732d17e374 macos-sonoma-14.4 macOS Sonoma 14.4 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png Sonoma false 14.4 15
7a8d85fb-781a-4212-8e47-240ec0c3d23f macos-sequoia-15.0 macOS Sequoia 15.0 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sequoia.png Sequoia true 15.0 16
Voici la liste des types de serveurs disponibles dans la zone fr-par-3 :
$ SCW_DEFAULT_ZONE="fr-par-3" scw apple-silicon server-type list
Name CPU Memory Disk Stock Minimum Lease Duration
M1-M Apple M1 (8 cores) 8.0 GB 256 GB high stock 1 days
Et la liste dans la zone fr-par-1 :
$ SCW_DEFAULT_ZONE="fr-par-1" scw apple-silicon server-type list
Name CPU Memory Disk Stock Minimum Lease Duration
M2-M Apple M2 (8 cores) 16 GB 256 GB high stock 1 days
M2-L Apple M2 Pro (10 cores) 16 GB 512 GB high stock 1 days
Je souhaite installer un serveur de type M1-M à 0,11 € HT / heure, soit 2,64 € HT / jour, 80,3 € HT / mois.
Lors de ma première tentative, j'ai essayé de créer un serveur avec la commande suivante :
$ scw apple-silicon server create name=capacitor zone=fr-par-3 "$SCW_PROJECT_ID" M1-M 7a8d85fb-781a-4212-8e47-240ec0c3d23f
Invalid argument '46ad009f-xxxxxx': arg name must only contain lowercase letters, numbers or dashes
Suite à cette erreur, j'ai créé l'issue siuvante : Reduce"scw apple-silicon server create" helper message ambiguity.
$ scw apple-silicon server create name=capacitor project-id=${SCW_PROJECT_ID} type=M1-M os-id=7a8d85fb-781a-4212-8e47-240ec0c3d23f zone=fr-par-3
Mais l'OS n'était pas trouvé, je me suis rendu compte que cette image OS n'était pas disponible dans la zone fr-par-3.
$ SCW_DEFAULT_ZONE="fr-par-3" scw apple-silicon os list
ID NAME LABEL IMAGE URL FAMILY IS BETA VERSION XCODE VERSION
59bf09f1-5584-469d-a0f6-55c8fee1ab81 macos-ventura-13.6 macOS Ventura 13.6 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-ventura.png Ventura false 13.6 14
e08d1e5d-b4b9-402a-9f9a-97732d17e374 macos-sonoma-14.4 macOS Sonoma 14.4 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png Sonoma false 14.4 15
Voici finalement la commande de création de serveur qui a fonctionné avec succès :
$ scw apple-silicon server create name=capacitor project-id=$SCW_PROJECT_ID type=M1-M os-id=e08d1e5d-b4b9-402a-9f9a-97732d17e374 zone=fr-par-3
ID bb34d8ef-6305-4104-801c-1cf1b6b0f99f
Type M1-M
Name capacitor
ProjectID 46ad009f-xxxx
OrganizationID 215d7434-xxxx
IP 51.xxx.xxx.xxx
VncURL vnc://m1:xxxx@51.xxx.xxx.121:5900
SSHUsername m1
SudoPassword xxxxxxx
Os ID e08d1e5d-b4b9-402a-9f9a-97732d17e374
Name macos-sonoma-14.4
Label macOS Sonoma 14.4
ImageURL https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png
Family Sonoma
IsBeta false
Version 14.4
XcodeVersion 15
CompatibleServerTypes:
[M1-M M2-M M2-L]
Status starting
CreatedAt now
UpdatedAt now
DeletableAt 23 hours from now
DeletionScheduled false
Zone fr-par-3
Voici le serveur créé :
$ scw apple-silicon server list
ID TYPE NAME PROJECT ID
bb34d8ef-6305-xxxxx M1-M capacitor 46ad009f-54bc-4125-xxxxxx
Le serveur est passé en ready après environ 1min.
$ scw apple-silicon server get bb34d8ef-6305-xxxxxxx
...
CompatibleServerTypes:
[M1-M M2-M M2-L]
Status ready
...
DeletableAt 23 hours from now
DeletionScheduled false
...
Je peux me connecter directement en ssh au serveur :
$ ssh m1@xxx.xxx.xx.xxx
Last login: Wed Nov 20 16:22:10 2024
m1@bb34d8ef-6305-4104-801c-1cf1b6b0f99f ~ % uname -a
Darwin bb34d8ef-6305-4104-801c-1cf1b6b0f99f 23.4.0 Darwin Kernel Version 23.4.0: Fri Mar 15 00:12:41 PDT 2024; root:xnu-10063.101.17~1/RELEASE_ARM64_T8103 arm64
Je peux aussi me connecter au serveur via VNC (lien vers la documentation à ce sujet).
Installation des dépendances sous Fedora :
$ sudo dnf install -y remmina remmina-plugins-vnc
J'utilise le client VNC nommé Remmina.
$ remmina -c vnc://m1:xxxxx@51.xxxx.xxx.xxxx:5900
Les paramètres vnc et le mot de passe de l'user m1 sont disponibles dans la sortie de :
$ scw apple-silicon server get bb34d8ef-6305-xxxxxxx -o json
{
"id": "bb34d8ef-6305-4104-xxxx-xxxxxxxxx",
...
"vnc_url": "vnc://m1:xxxx@xxx.xxx.xxx.xxx:5900",
"ssh_username": "m1",
"sudo_password": "bTgkdiVUs7yT",
...
}
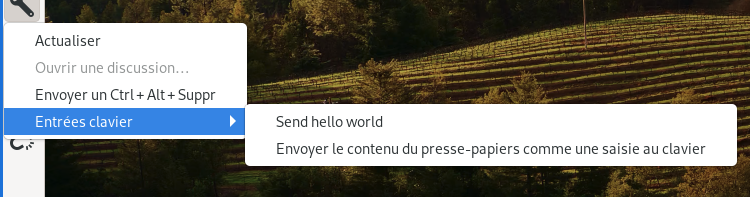
Il est possible de coller le mot de passe via la fonctionnalité « Envoyer le contenu du presse-papiers comme une saisie au clavier » de Remmina :
Attention, la réinstallation d'un serveur Apple Silicon prend au moins 45min.
J'ai implémenté des scritps de déploiement d'un Apple Silicon dans le POC : poc-capacitor.
Prochaine étape du Projet 17 : Setup les iOS Requirements de Capacitor sur ce serveur Apple Silicon.
Journal du mardi 19 novembre 2024 à 23:50
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Dans la note 2024-11-19_1029, je disais :
Pour utiliser Capacitor, j'ai besoin d'installer certains éléments.
In order to develop Android applications using Capacitor, you will need two additional dependencies:
- Android Studio
- An Android SDK installation
Je me demande si Android Studio est optionnel ou non.
La réponse est non, Android Studio n'est pas nécessaire, ni pour compiler l'application, ni pour la lancer dans un émulateur Android. Android SDK est suffisant.
J'ai utilisé le plugin Mise https://github.com/Syquel/mise-android-sdk pour installer les "Android Requirements" de Capacitor. Les instructions détaillées pour Fedora sont listées dans le README.md du repository : https://github.com/stephane-klein/poc-capacitor/tree/4238e80f84a248fdb9e5bb86c10bea8b9f0fdade.
Installation de Android Studio sous Fedora
Dans le Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor, il semble que j'ai besoin d'installer Android Studio.
J'ai exploré la méthode Asdf / Mise, mais j'ai rencontré des difficultés : 2024-11-19_1029 et 2024-11-19_1102.
J'ai ensuite constaté ici que RPM Fusion ne propose pas de package Android Studio. J'ai ensuite cherché sur Fedora COPR, mais j'ai trouvé uniquement de très vieux packages.
J'ai lu ici qu'Android Studio est disponible via Flatpak sur Flathub : https://flathub.org/apps/com.google.AndroidStudio. Je n'avais pas pensé à Flatpak 🙊.
Après réflexion, je trouve cela totalement logique que Android Studio soit distribué via Flatpak.
Voici le repository GitHub de ce package : https://github.com/flathub/com.google.AndroidStudio. Il semble être bien maintenu par Alessandro Scarozza « Senior Android Developer, Android Studio Flatpak Mantainer and old Debian Linux user ».
Le package contient la version 2024.2.1.11 d'Android Studio, j'ai vérifié, elle correspond bien à la dernière version disponible sur https://developer.android.com/studio.
Voici ce que donne l'installation :
$ flatpak install com.google.AndroidStudio
Looking for matches…
Remotes found with refs similar to ‘com.google.AndroidStudio’:
1) ‘flathub’ (system)
2) ‘flathub’ (user)
Which do you want to use (0 to abort)? [0-2]: 1
com.google.AndroidStudio permissions:
ipc network pulseaudio ssh-auth x11 devices multiarch file access [1]
dbus access [2]
[1] home
[2] com.canonical.AppMenu.Registrar, org.freedesktop.Notifications, org.freedesktop.secrets
ID Branch Op Remote Download
1. [✓] com.google.AndroidStudio.Locale stable i flathub 5,6 Ko / 57,2 Ko
2. [✓] com.google.AndroidStudio stable i flathub 1,3 Go / 1,3 Go
Installation complete.
Journal du mardi 19 novembre 2024 à 10:29
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Pour utiliser Capacitor, j'ai besoin d'installer certains éléments.
In order to develop Android applications using Capacitor, you will need two additional dependencies:
- Android Studio
- An Android SDK installation
Je me demande si Android Studio est optionnel ou non.
J'aimerais installer ces deux services avec Mise.
J'ai trouvé des Asdf plugins pour Android SDK :
- https://github.com/Syquel/mise-android-sdk (créé le 2024-03-03)
- https://github.com/huffduff/asdf-android-sdk (créé le 2024-10-10)
- https://github.com/arcticShadow/asdf-android (créé le 2024-11-13)
#JeMeDemande quel plugin utiliser, quelles sont leurs différences.
Pour essayer d'avoir une réponse, j'ai posté les issues suivantes :
- What are the differences with other existing plugins?
- What are the differences with other existing plugins?
Alexandre m'a informé qu'il a utilisé avec succès le plugin https://github.com/Syquel/mise-android-sdk/, il a même créé une issue https://github.com/Syquel/mise-android-sdk/issues/10 qui a été traité 🙂.
La suite : 2024-11-19_1102.
Le support des variables d'environments de Mise est limité, je continue à utiliser direnv
J'ai décidé d'utiliser la fonctionnalité "mise
env._source" pendant quelques semaines pour me faire une opinion.-- (from)
J'ai déjà rencontré un problème : il n'est pas possible de lancer des outils installés via Mise dans un script lancé par _.source.
Voici un exemple, j'ai ce fichier .envrc.sh :
export SERVER1_IP=$(terraform output --json | jq -r '.server1_public_ip | .value')
Terraform est installé avec Mise :
[env]
_.source = "./.envrc.sh"
[tools]
terraform="1.9.8"
Quand je lance mise set, j'ai cette erreur :
$ mise set
.envrc.sh: line 6: terraform: command not found
J'ai trouvé une issue pour traiter cette limitation : "Use mise tools in env template".
En attendant que cette issue soit implémentée, j'ai décidé de continuer d'utiliser direnv.
2024-12-19 : suite à la cloture de l'issue indiquée dans cette note, j'ai publié la note Je pense maintenant pouvoir remplacer Direnv par Mise 🤞.
Je remplace direnv par la fonctionnalité env._source proposée Mise
Depuis avril 2019, j'utilise direnv dans pratiquement tous mes projets de développement informatique.
Ce matin je me suis demandé si avec les nouvelles fonctionnalités de gestion des variables d'environnement de Mise, je pouvais simplifier mes development kit 🤔.
Comme vous pouvez le voir dans install-and-configure-direnv-with-mise-skeleton, actuellement mes development kit contiennent deux étapes de modifications de .bash_profile ou .zshrc. Exemple avec Zsh :
- Une étape pour configurer Mise :
$ echo 'eval "$(~/.local/bin/mise activate zsh)"' >> ~/.zshrc
$ source ~/.zsrhrc
- Seconde étape pour configurer direnv :
$ echo -e "\neval \"\$(direnv hook zsh)\"" >> ~/.zshrc
$ source ~/.zsrhrc
Voici la version simplifiée de ce skeleton basé sur "mise env._source", avec une étape de configuration en moins :
https://github.com/stephane-klein/install-and-configure-mise-skeleton
Voici le contenu du fichier .mise.toml :
[env]
_.source = "./.envrc.sh"
et le contenu de .envrc.sh :
export HELLO_WORLD=foo
J'ai fait le choix de nommer ce fichier .envrc.sh plutôt que .envrc afin d'éviter des problèmes de compatibilité pour les utilisateurs qui ont direnv installé.
J'ai vérifié que les variables d'environnements "parents" sont bien conservées en cas de changement de variable d'environnement par Mise dans un sous dossier.
#JeMeDemande si je vais rencontrer des régressions par rapport à direnv 🤔.
J'ai décidé d'utiliser la fonctionnalité "mise env._source" pendant quelques semaines pour me faire une opinion.
Update : voir 2024-11-06_2109.
development kit skeleton d'installation de direnv
Voici un dépôt GitHub qui contient les instructions que j'indiquais dans mes development kit, avant 2024, pour installer et configurer direnv, sous MacOS.
https://github.com/stephane-klein/install-and-configure-direnv-with-asdf-skeleton
Dans ce skeleton, direnv est installé avec asdf, voir le fichier racine ./.tool-versions
Et voici un exemple de skeleton, que j'utilise depuis novembre 2023, basé sur Mise :
https://github.com/stephane-klein/install-and-configure-direnv-with-mise-skeleton
Dans ce second skeleton, direnv est installé avec Mise, voir le fichier racine ./.mise.toml.
Pourquoi j'utilise direnv dans mes development kit ?
Dans cette note, je souhaite expliquer pourquoi j'utilise et j'aime utiliser direnv.
Je suis toujours en train d'essayer de créer des development kit me permettant de travailler dans un environnements de développement toujours plus agréable.
J'ai découvert direnv en 2017 et j'ai commencé à l'utiliser dans un projet en avril 2019.
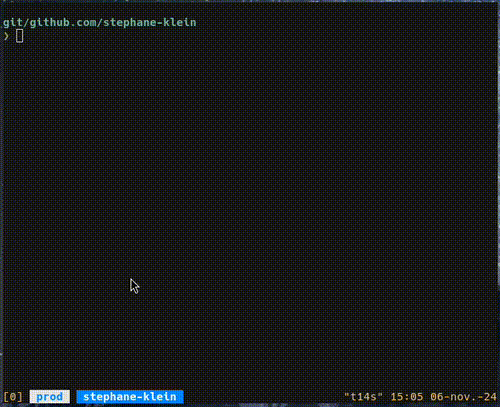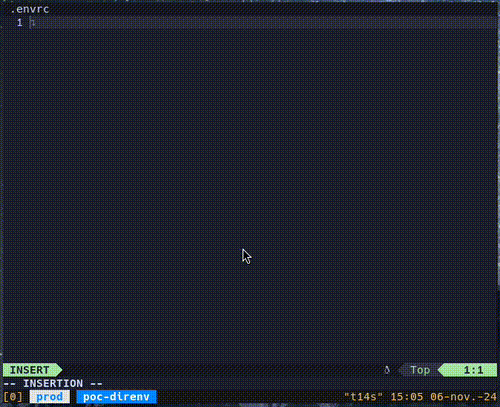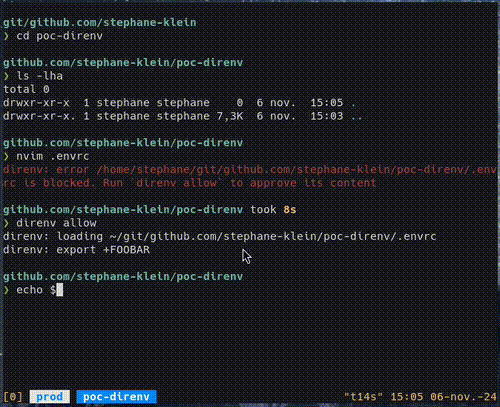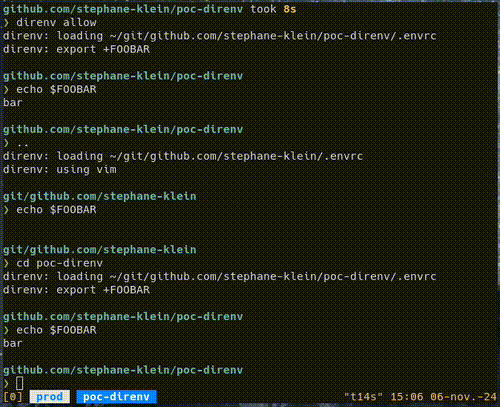
direnv s'utilise dans un shell, il charge et décharge automatiquement les variables d'environnement spécifiées dans un fichier .envrc lorsqu'on entre et quitte un répertoire.
Exemple :
Voici les use cases listées sur le site officiel de direnv :
- Load 12factor apps environment variables
- Create per-project isolated development environments
- Load secrets for deployment
Voici quelques exemples concrets de mon utilisation de direnv :
- chargement automatique des paramètres de configuration et secret pour :
source .secret
export SCW_DEFAULT_ORGANIZATION_ID="...." # Get it, in https://console.scaleway.com/organization/settings
export SCW_ACCESS_KEY="..."
# This variable environments are used by Grafana Grizzly
export GRAFANA_URL=http://grafana.$(terraform output --json | jq -r '.server3_public_ip | .value').nip.io
export GRAFANA_USER=admin
export GRAFANA_TOKEN=password
- dans un projet Javascript :
export POSTGRES_ADMIN_URL="postgres://postgres:password@localhost:5432/myapp"
export POSTGRES_URL="postgres://webapp:password@localhost:5432/myapp"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export SECRET="secret"
export APP_HOSTNAME="localhost"
export MAIL_FROM="noreply@example.com"
Les fichiers .envrc sont des scripts shell, il est possible comme dans l'exemple au-dessus, d'utiliser source .secret pour charger un autre fichier.
Je versionne toujours le fichier .envrc, tandis que j'ignore (.gitignore) les fichiers .secret contenant des informations sensibles qui ne doivent pas être publiés dans le repository git.
Après avoir installé un development kit, j'indique à l'utilisateur les instructions à suivre pour installer les éléments de base du projet, comme Mise, Docker…, et la mise en place des secrets.
Mon objectif est ensuite de permettre à l'utilisateur de l'environnement de développement d'interagir avec des « scripts helpers » sans nécessiter de configuration préalable, simplement en entrant ou sortant des dossiers. Les dossiers sont utilisés comme « workspace contexte ».
Voir aussi : development kit skeleton d'installation de direnv
À la recherche d'un environnement de développement sans le savoir : mes années 1999-2008
Je pense que je m'intéresse au sujet des "development environment" ou development kit depuis 1999.
À l'époque, même si je ne connaissais pas encore ces concepts, j'en ressentais déjà le besoin.
Par exemple, lorsque j'ai voulu contribuer au projet KDE, je cherchais des solutions et des bonnes pratiques pour organiser ma station de travail de manière à pouvoir compiler et installer KDE sans risquer de casser mon environnement de bureau.
Malheureusement, je n'y suis pas parvenu 😔.
Avec le recul, je réalise que ces pratiques étaient souvent transmises de manière informelle, principalement par des échanges oraux ou via des messages sur IRC. En somme, il s'agissait d'un véritable "bouche-à-oreille" numérique.
Je pense que la majorité des développeurs devaient faire face aux mêmes difficultés. Je pense aussi qu’ils devaient prendre beaucoup de temps à trouver leur propre méthode, année après année.
J’en ai eu une fois la confirmation. En 2002, je suis allé au FOSDEM, pour rencontrer entre autres David Faure, un core développeur français de KDE.
J’ai échangé avec lui et il m’a montré de nombreuses astuces qu’il utilisait… je n’ai pas tout compris, je n’ai pas réussi à les retenir…
J’en ai conclu que les développeurs avaient sans doute chacun leurs propres méthodes de développement non documentées.
Question qui me vient alors à l’esprit : alors qu'ils contribuent à des logiciels libres et partagent leur code source, pourquoi les développeurs ne partagent-ils pas aussi leurs environnements de développement ?
Journal du mercredi 06 novembre 2024 à 14:18
Je viens de réfléchir à l'usage des termes "development environment" et "development kit".
Je pense que le dépôt gitlab-development-kit est un "development kit" qui permet d'installer et configurer un "development environment" pour travailler sur le projet GitLab.
Réflexions au sujet des notions d'"environnement", "instance" et "workspace"
Je suis en train d'implémenter un repository playground privé pour un client et je me demande comment bien nommer les choses.
Je souhaite implémenter dans ce playground, des dossiers qui permettent d'interagir avec différents types d'instance.
Je me suis interrogé sur les notions de « environnement » et « d'instance ». Je connais ces termes, mais j'ai souhaité étudier leur différence avec précision.
Environnement :
- Article Wiktionary français : environnement
(Informatique) Ensemble des matériels et logiciels sur lesquels sont exécutés les programmes d'une application.
- "On travaille dans un environnement Linux."
- Article Wiktionary français : environment
(Informatique) Environnement.
- "The primary prompt is changed to help us remember that this session is inside a chroot environment."
- Article Wikipedia anglais : Runtime environment
In computer programming, a runtime system or runtime environment is a sub-system that exists in the computer where a program is created, as well as in the computers where the program is intended to be run.
- Article Wikipedia anglais : Deployment environment
In software deployment, an environment or tier is a computer system or set of systems in which a computer program or software component is deployed and executed. In simple cases, such as developing and immediately executing a program on the same machine, there may be a single environment, but in industrial use, the development environment (where changes are originally made) and production environment (what end users use) are separated, often with several stages in between. This structured release management process allows phased deployment (rollout), testing, and rollback in case of problems.
Instance :
- Article Wiktionary Français : instance
(Réseaux informatiques) Copie d’un logiciel fournissant un service sur un réseau.
- "PeerTube est un logiciel. Ce logiciel, des personnes spécialisées (disons… Bernadette, l’université X et le club de karaté Y) peuvent l’installer sur un serveur. Cela donnera une « instance », c’est à dire un hébergement de PeerTube. Concrètement, héberger une instance crée un site web (disons BernadetTube.fr, UniversiTube.org ou KarateTube.net) sur lequel on peut regarder des vidéos et créer un compte pour interagir ou uploader ses propres contenus."
- Article Wikipedia Anglais : instance
- Instance (computer science), referring to any running process or to an object as an instance of a class.
- Instance can refer to a single virtual machine in a virtualized or cloud computing environment that provides operating-system-level virtualization.
ChatGPT me dit :
Dans un contexte DevOps, les termes environment et instance font référence à des concepts distincts :
- Un environment regroupe les ressources et la configuration nécessaires pour une étape spécifique du cycle de vie de développement.
- Une instance est une unité d'exécution de l'application, isolée, et potentiellement en plusieurs exemplaires au sein d'un même environnement.
À la suite de cette réflexion, j'ai implémenté un exemple de repository contenant plusieurs workspaces, permettant d'interagir avec des instances de différents types d'environnement.
Repository : project-workspaces-skeleton
Je l'ai organisé de la façon suivante :
$ tree
├── development
│ ├── local-workspace
│ │ └── README.md
│ └── remote-workspace
│ └── README.md
├── production
│ ├── local-workspace
│ │ └── README.md
│ └── remote-workspace
│ └── README.md
├── README.md
└── staging
├── local-workspace
│ └── README.md
└── remote-workspace
└── README.md
Voici quelques extraits du contenu des README.md.
development/local-workspace/README.md :
Local development environment workspace
Introduction
This workspace allows you locally launch the equivalent of remote development environment instances (applications, databases, etc.), within the GitOps paradigm.
This workspace provides scripts for injecting and initializing a database with demo data, or for copying the contents of remote instances to the local database.
This workspace is the right place if you want to work (fix bug, improve…) in isolation (without disturbing your colleagues) on development-type configuration changes.
This workspace is also useful for tinkering to better understand how this environment works.
Workspace configuration
...
production/remote-workspace/README.md :
Remote production environment workspace
Be careful when using scripts in this workspace, as you risk breaking production instances!
Introduction
This workspace allows you to interact with remote production environment instances (applications, databases, etc.) within the GitOps paradigm.
This workspace is designed, among other things, to store the configuration of production instances.
It includes scripts for deploying this configuration to remote instances and analysing the differences between the theoretical or desired configuration and that actually deployed.
With Git, these configurations are versioned, making it possible to track changes made over time on these instances.
Furthermore, this paradigm allows modifications to be proposed in the form of Pull Requests, simplifying collaborative work.Workspace configuration
...
Je pense que ce skeleton va me servir de base pour de futurs repository de projets.
Journal du mercredi 30 octobre 2024 à 10:21
Je garde trace dans cette notes de deux plugins Asdf / Mise que j'ai utilisé avec succès ces deux derniers jours.
Le premier, pour installer la cli de Hasura : asdf-hasura
$ mise plugin add hasura-cli https://github.com/gurukulkarni/asdf-hasura.git
Contenu de .mise.toml :
[tools]
hasura-cli = "2.43.0"
$ mise install
$ hasura version
INFO hasura cli version=v2.43.0
Le second, pour installer Gitleaks : asdf-gitleaks
$ mise plugin add gitleaks https://github.com/jmcvetta/asdf-gitleaks.git
Contenu de .mise.toml :
[tools]
gitleaks = "8.21.2"
$ mise install
$ gitleaks --version
gitleaks version 8.21.2
Journal du vendredi 17 novembre 2023 à 17:14
J'ai commencé à migré un projet de asdf vers rtx (ancien nom de Mise).
Journal du vendredi 19 avril 2019 à 17:33
Cela fait des mois que je me demande comment nommer le repository #Git « chapeau », « umbrella » qui est le starting point d'une boite ou d'un projet.
J'ai trouvé une réponse chez GitLab, {compagny_name}-development-kit : https://gitlab.com/gitlab-org/gitlab-development-kit.
Ce repository est un "development kit".
Mise est un "tooling version management", il permet d'installer la plupart des outils nécessaire au bon fonctionnement d'un development environment. Il permet de "pin" les versions précises de ces outils.
Avec direnv et Docker, Mise fait parti des briques de fondactions que j'utilise pour créer mes development kit.
Site officiel : https://mise.jdx.dev
Ubi est un "tooling version management".
Dépôt GitHub : https://github.com/houseabsolute/ubi
Outil de gestion de development kit, créé en novembre 2022, basé sur Nix.
vfox est un tooling version management implémenté en Golang.
Dépôt GitHub : https://github.com/version-fox/vfox
https://github.com/asdf-vm/asdf
Voir aussi les alternatives : Mise et aqua.
Créateur de Asdf : Trevor Brown
Dépôt GitHub : https://github.com/stephane-klein/sklein-devbox
Dernière page.