
Mercredi 07 juin 2023 à 19:37
#JaiDécouvert le projet PrivateGPT (https://github.com/zylon-ai/private-gpt).
Cela fait plusieurs mois que je souhaite trouver une solution pour self hosted une alternative à ChatGPT. J'ai bien envie de tester ce projet.
Journaux liées à cette note :
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
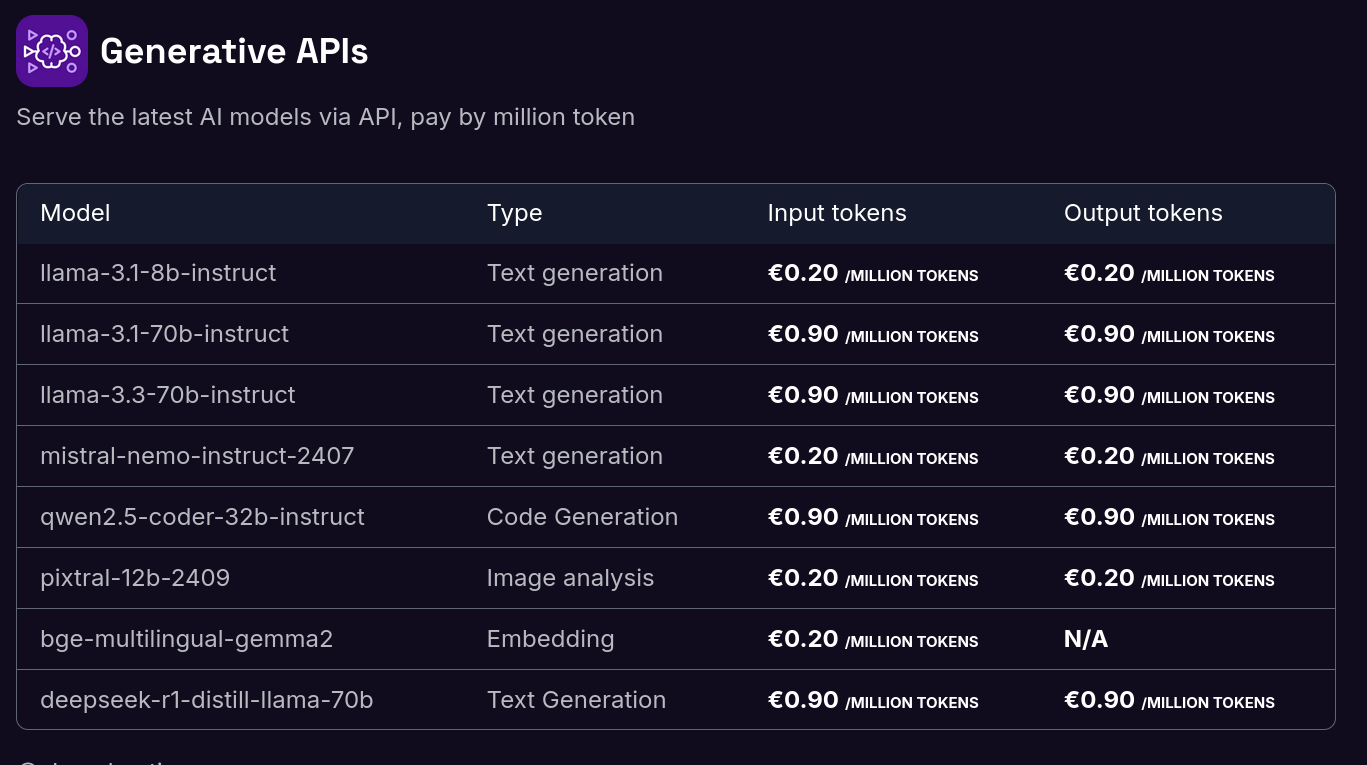
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
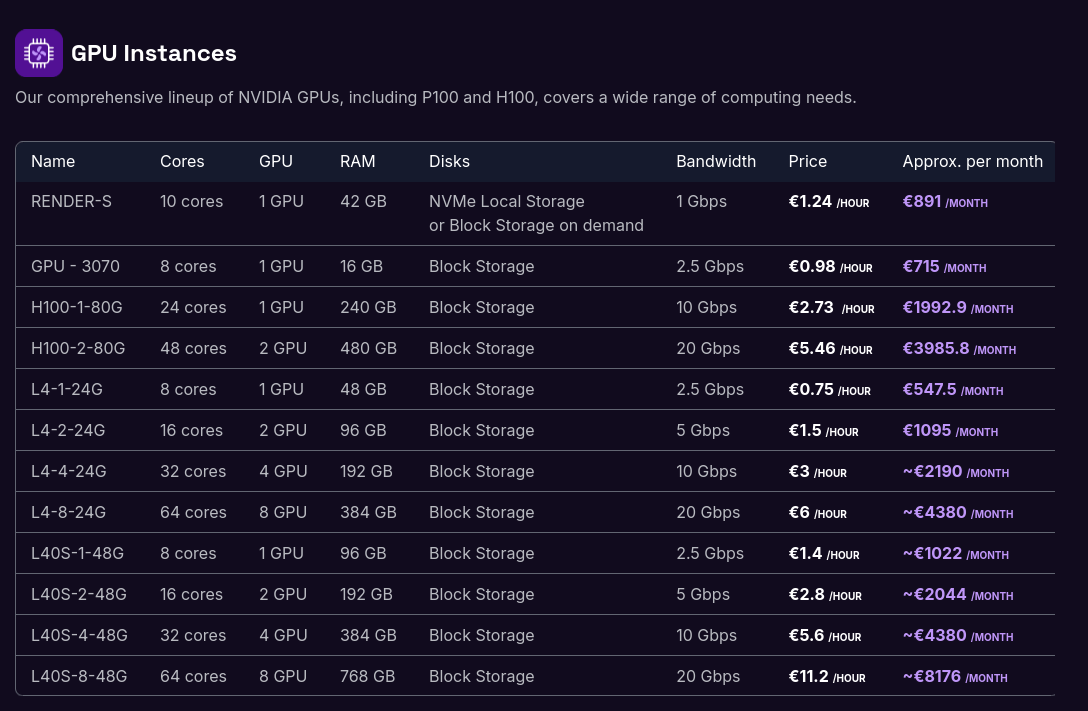
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
Journal du vendredi 17 mai 2024 à 11:05
Dans l'article "Qu'est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?" je découvre l'acronyme Génération Augmentée de Récupération.
Je constate qu'il existe un paragraphe à ce sujet sur Wikipedia.
The initial phase utilizes dense embeddings to retrieve documents.
Je tombe encore une fois sur "embeddings", #JaimeraisUnJour prendre le temps de comprendre correctement cette notion.
Prenez l'exemple d'une ligue sportive qui souhaite que les fans et les médias puisse utiliser un chat pour accéder à ses données et obtenir des réponses à leurs questions sur les joueurs, les équipes, l'histoire et les règles du sport, ainsi que les statistiques et les classements actuels. Un LLM généralisé pourrait répondre à des questions sur l'histoire et les règles ou peut-être décrire le stade d'une équipe donnée. Il ne serait pas en mesure de discuter du jeu de la nuit dernière ou de fournir des informations actuelles sur la blessure d'un athlète, parce que le LLM n'aurait pas ces informations. Étant donné qu'un LLM a besoin d'une puissance de calcul importante pour se réentraîner, il n'est pas possible de maintenir le modèle à jour.
Le contenu de ce paragraphe m'intéresse beaucoup, parce que c'était un de mes objectifs lorsque j'ai écrit cette note en juin 2023.
Sans avoir fait de recherche, je pensais que la seule solution pour faire apprendre de nouvelles choses — injecter de nouvelle données — dans un modèle était de faire du fine-tuning.
En lisant ce paragraphe, je pense comprendre que le fine-tuning n'est pas la seule solution, ni même, j'ai l'impression, la "bonne" solution pour le use-case que j'aimerais mettre en pratique.
En plus du LLM assez statique, la ligue sportive possède ou peut accéder à de nombreuses autres sources d'information, y compris les bases de données, les entrepôts de données, les documents contenant les biographies des joueurs et les flux d'actualités détaillées concernant chaque jeu.
#JaimeraisUnJour implémenter un POC pour mettre cela en pratique.
Dans la RAG, cette grande quantité de données dynamiques est convertie dans un format commun et stockée dans une bibliothèque de connaissances accessible au système d'IA générative.
Les données de cette bibliothèque de connaissances sont ensuite traitées en représentations numériques à l'aide d'un type spécial d'algorithme appelé modèle de langage intégré et stockées dans une base de données vectorielle, qui peut être rapidement recherchée et utilisée pour récupérer les informations contextuelles correctes.
Intéressant.
Il est intéressant de noter que si le processus de formation du LLM généralisé est long et coûteux, c'est tout à fait l'inverse pour les mises à jour du modèle RAG. De nouvelles données peuvent être chargées dans le modèle de langage intégré et traduites en vecteurs de manière continue et incrémentielle. Les réponses de l'ensemble du système d'IA générative peuvent être renvoyées dans le modèle RAG, améliorant ses performances et sa précision, car il sait comment il a déjà répondu à une question similaire.
Ok, si je comprends bien, c'est la "kill feature" du RAG versus du fine-tuning.
bien que la mise en oeuvre de l'IA générative avec la RAG est plus coûteux que l'utilisation d'un LLM seul, il s'agit d'un meilleur investissement à long terme en raison du réentrainement fréquent du LLM
Ok.
Bilan de cette lecture, je dis merci à Alexandre de me l'avoir partagé, j'ai appris RAG et #JePense que c'est une technologie qui me sera très utile à l'avenir 👌.