
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (6 notes) :
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
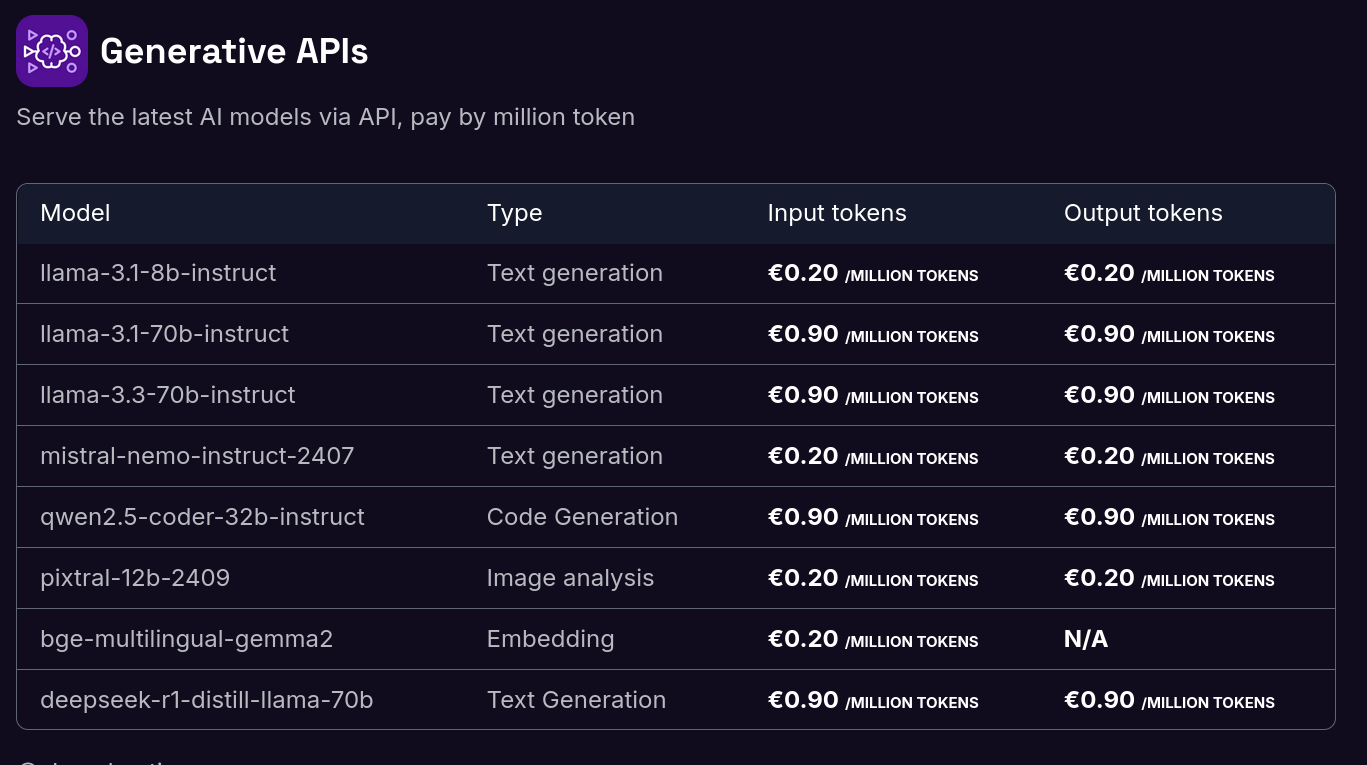
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
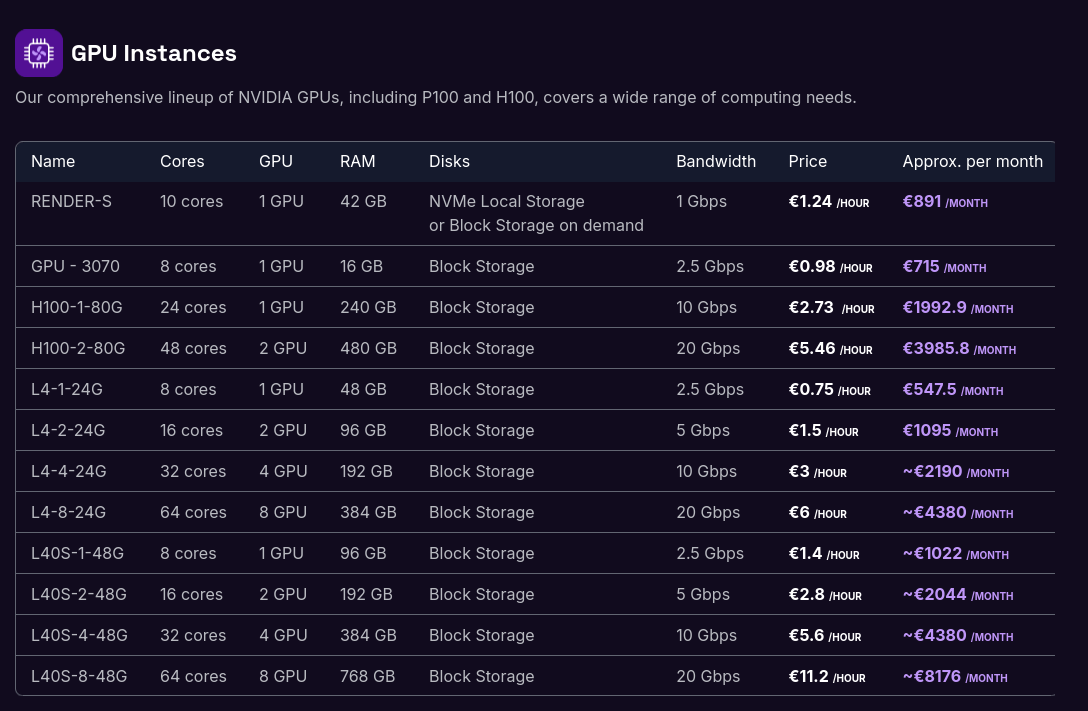
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
Journal du mardi 23 juillet 2024 à 21:08
« C'est quoi vos 3 meilleures sources de veille ? Par source j'entends,l'endroit ou vous allez chercher vos informations (Un channel reddit précis, un site précis, etc...) »
Voici mes habitudes quotidiennes de veille informatique, technologique et anglo-saxonne :
-
- En premier, je consulte https://lobste.rs/ ;
-
- Ensuite, Hacker News, soit directement via https://news.ycombinator.com/ ou alors via mon instance miniflux ;
-
- Ensuite, mon instance miniflux ;
-
- Ensuite, mon flux Fediverse : https://mamot.fr/deck/@stephane_klein.
Très souvent, je m'arrête à l'étape 2, car comme je lis surtout les commentaires, cela me prend beaucoup de temps.
Pour les actualités :
- Souvent https://www.youtube.com/@HugoDecrypte ;
- Souvent Le 6/9 de France Inter ;
- Et rarement Brief.me (je suis abonné).
Au quotidien :
- Mon flux YouTube (voir Je suis abonné à ces chaines YouTube) ;
- Et les Podcasts de Radio France.
Je n'utilise pas le feed de suggestion de YouTube, je consulte mes abonnements.
#JutilisePeu Twitter (de moins en moins).
- J'utilise actuellement Facebook uniquement comme un carnet d'adresse + quelque Goupe, je ne consulte presque jamais mon feed
- J'utilise LinkedIn uniquement comme un carnet d'adresse. Je ne consulte presque jamais mon feed
- TikTok
Journal du lundi 06 mai 2024 à 13:56
#OnMePoseLaQuestion suivante :
C'est quoi ta stats de temps moyenne d'écriture de notes éphémères ?
Entre le 29 avril au 6 mai inclus, j'ai passé 7h pour publier 40 notes éphémères et 5 projets, soit environ 10 minutes par note…
D'après toi, quel problème a cherché à résoudre Svelte ?
D'après toi, quel problème a cherché à résoudre Svelte ?
Comme le dit ici Richard Harris :
The first version of Svelte was all about testing a hypothesis — that a purpose-built compiler could generate rock-solid code that delivered a great user experience. The second was a small upgrade that tidied things up a bit.
Je pense que la réponse se trouve dans ce billet https://svelte.dev/blog/frameworks-without-the-framework
D'après ce que j'ai compris il voulait tester si une librairie compilé pourrait :
- Générer des projets plus petit
- Générer des projets plus rapide
- Apporté des choses élégantes
Après les résultats de ce POC et 8 ans plus tard, je pense que les réponses à ces questions étaient oui.
J'ai lu ce billet il y a plusieurs année, je n'ai pas pris le temps de le relire.
Tu utilises quoi pour publier ton Obsidian sur notes.sklein.xyz ?
Pour le moment, j'utilise Obsidian Quartz pour déployer https://notes.sklein.xyz.
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Comment il est déployé ? Pour le moment, d'une manière très minimaliste et assez manuelle comme décrit ici : https://github.com/stephane-klein/obsidian-quartz-playground/tree/main/deployment
Dernière page.