
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (16 notes) :
Journal du vendredi 25 avril 2025 à 18:33
Au mois de janvier, j'ai écrit :
Voici mes prochaines #intentions d'amélioration de ma workstation :
- ...
- Essayer de remplacer les services ChatGPT ou Claude.ai par Open WebUI.
- ...
Le hasard de la vie fait que je commence une mission professionnelle pour la DINUM en lien avec Open WebUI : Ablert Conversation.
Au mois de décembre, j'ai déjà installé et testé rapidement Open WebUI connecté à Scaleway Generative APIs, mais je n'ai pas pris le temps de le faire avec rigueur.
Dans les prochains jours, je souhaite réaliser les projets suivants :
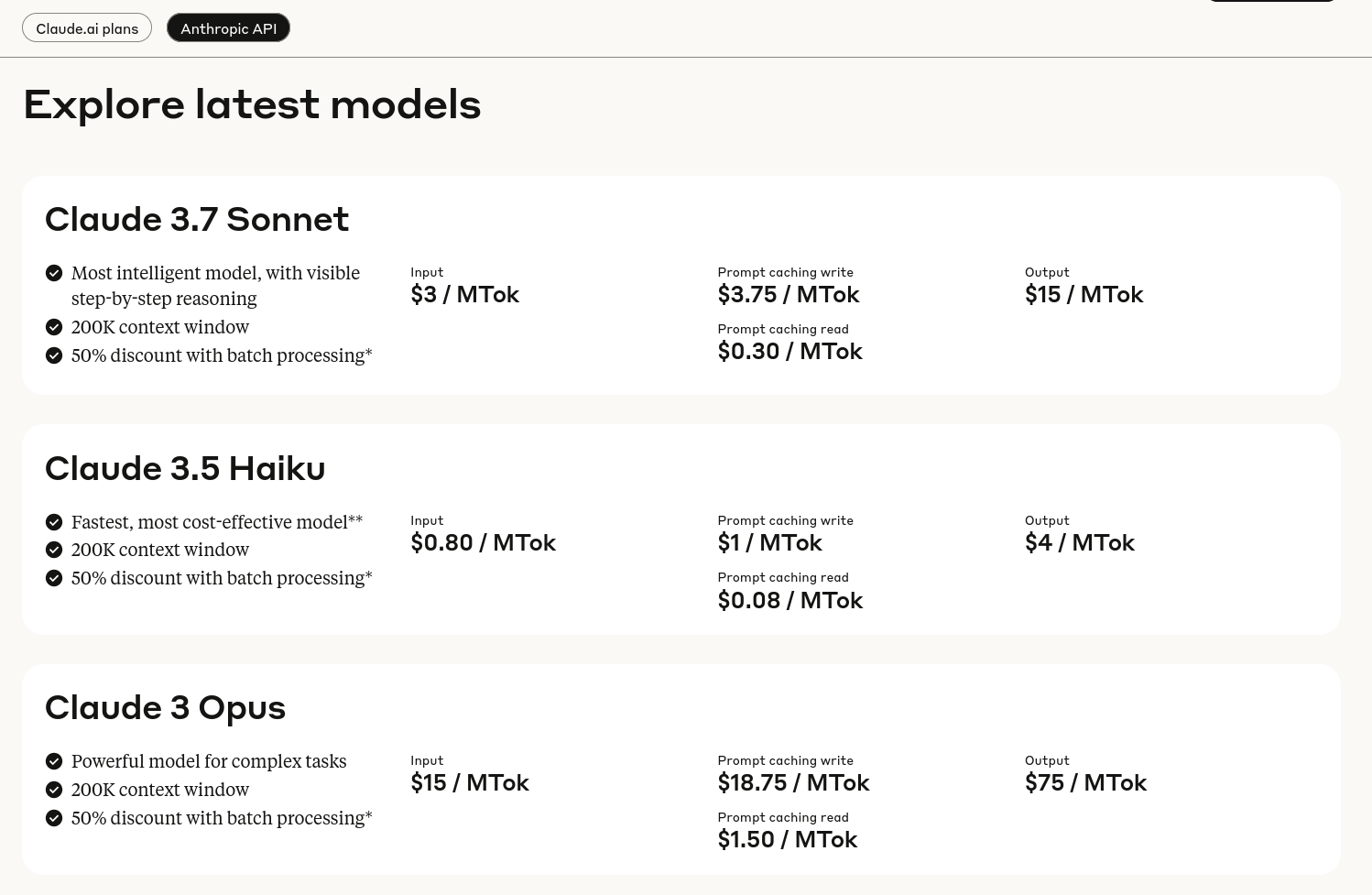
Journal du mardi 25 février 2025 à 23:29
#JaiDécouvert cette page web qui permet de savoir quel LLM peut être exécuté sur une machine en particuler : https://canirunthisllm.com/ll
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
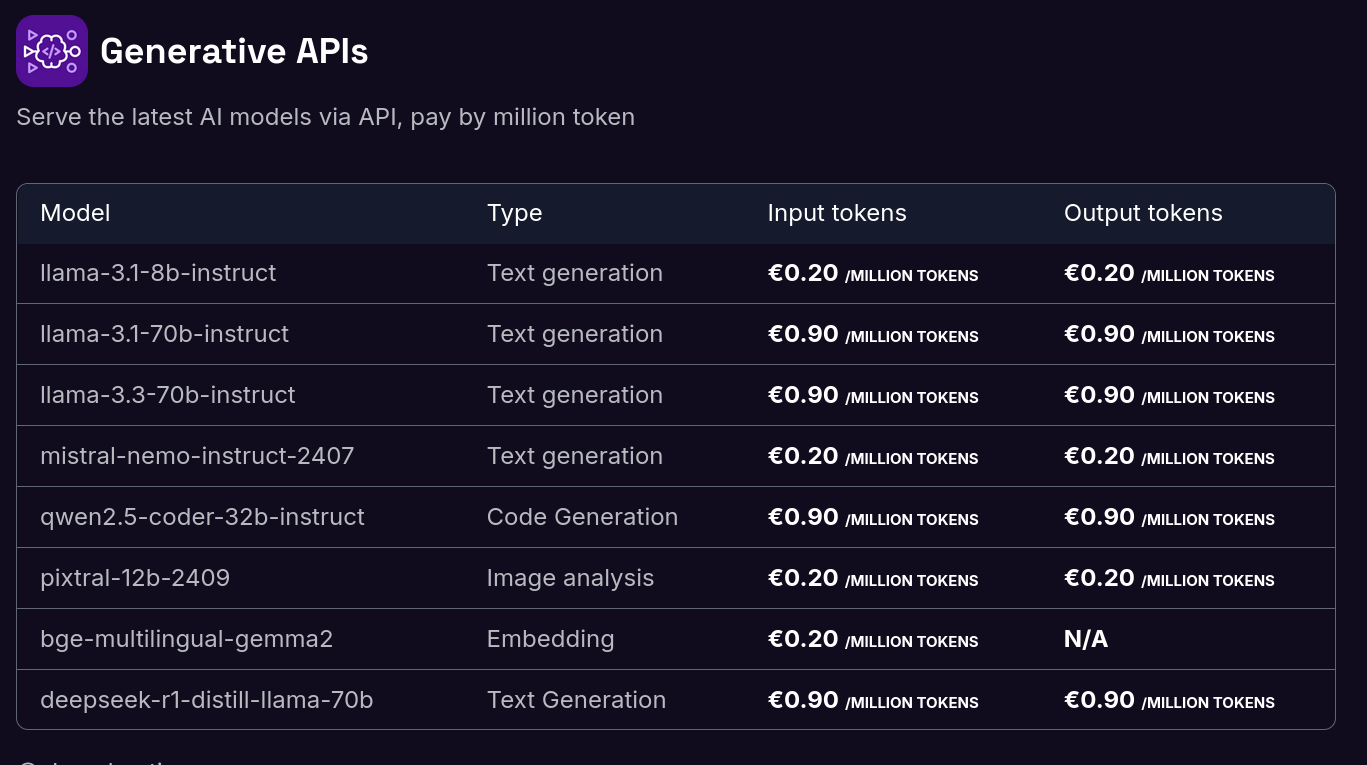
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
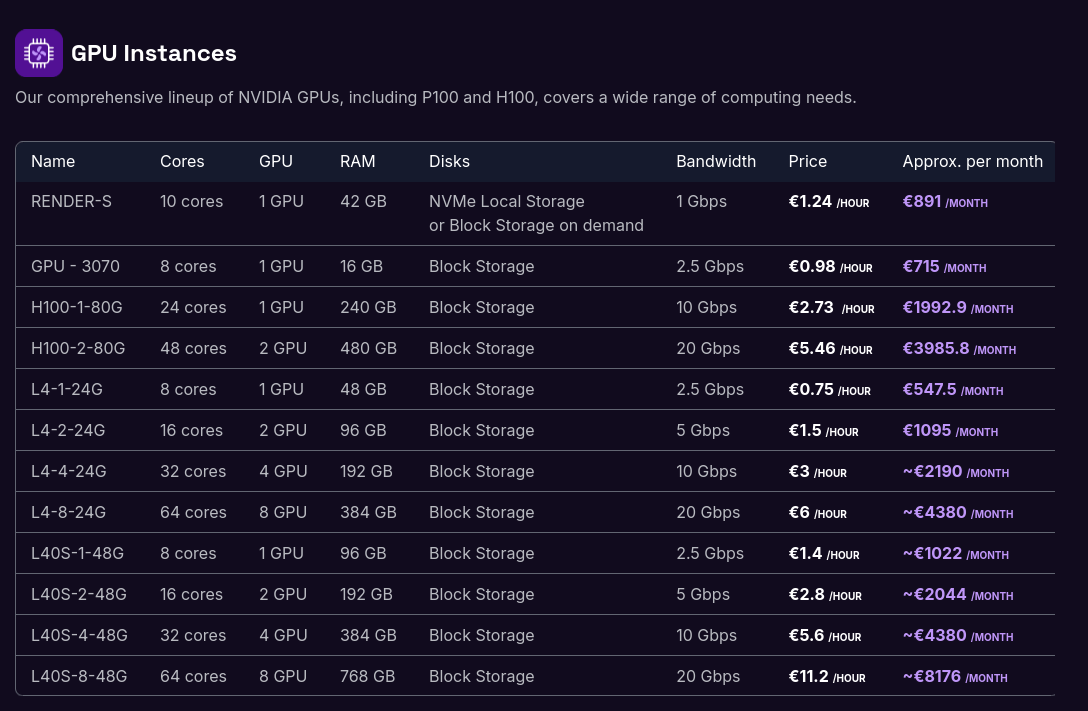
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
Journal du jeudi 23 janvier 2025 à 14:37
#JaiDécouvert Moshi (https://github.com/kyutai-labs/moshi).
Moshi is a speech-text foundation model and full-duplex spoken dialogue framework. It uses Mimi, a state-of-the-art streaming neural audio codec.
Moshi models two streams of audio: one corresponds to Moshi, and the other one to the user. At inference, the stream from the user is taken from the audio input, and the one for Moshi is sampled from the model's output. Along these two audio streams, Moshi predicts text tokens corresponding to its own speech, its inner monologue, which greatly improves the quality of its generation.
Journal du samedi 31 août 2024 à 17:29
Alexandre m'a partagé Continue.
Continue is the leading open-source AI code assistant. You can connect any models and any context to build custom autocomplete and chat experiences inside VS Code and JetBrains
Je lis ici que ce projet peut être assimilé à avante.nvim ou llm.nvim.
Je constate qu'il est possible de connecter Continue à beaucoup de types de LLM : Model Providers.
D'autre part, chose intéressante, Continue permet d'intégrer facilement du contexte provenant de diverses sources, telles que :
Je me pose toujours la même question que le 27 août :
Cependant, une question me revient sans cesse à l'esprit en voyant ce genre d'outil utilisant les API d'AI providers : est-ce que le coût d'utilisation de ce type de service ne risque pas d'être exorbitant ? 🤔 Je sais bien que ces AI providers permettent de définir un plafond de dépenses, ce qui est rassurant. La meilleure approche serait donc de tester l'outil et d'évaluer les coûts mensuels pour voir s'ils restent raisonnables.
Journal du samedi 08 juin 2024 à 10:56
En lisant ceci :
AI accelerators are used in mobile devices, such as neural processing units (NPUs) in Apple iPhones, AMD Laptops or Huawei cellphones, and personal computers such as Apple silicon Macs, to cloud computing servers such as tensor processing units (TPU) in the Google Cloud Platform.
#JaiDécouvert que AMD XDNA semble être l'architecture des puces NPU de AMD.
Je lis ici que Ryzen AI est le nom commercial du matériel AMD qui implémente l'architecture XDNA.
La première puce qui intégrèe AMD XDNA est le Ryzen 7040 sorti 2023.
Dans cet article je lis :
- Des puces de la série Ryzen 7040 intègrent des NPU à 10 TOPS
- Des puces de la série Ryzen 8000 intègrent des NPU à 16 TOPS
- Des puces de la série Ryzen AI 300 intègrent des NPU à 50 TOPS
Journal du samedi 08 juin 2024 à 10:35
Dans 2024-06-06_1047 #JaiDécidé d'utiliser le terme Inference Engines pour définir la fonction ou la catégorie de llama.cpp.
J'ai échangé avec un ami au sujet des NPU et j'ai dit que j'avais l'impression que ces puces sont spécialés pour exécuter des Inference Engines, c'est-à-dire, effectuer des calculs d'inférence à partir de modèles.
Après vérification, dans cet article je lis :
An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed to accelerate artificial intelligence and machine learning applications, including artificial neural networks and machine vision.
et je comprends que mon impression était fausse. Il semble que les NPU ne sont pas seulement dédiés aux opérations d'exécution d'inférence, mais semblent être optimisés aussi pour faire de l'entrainement 🤔.
Un ami me précise :
Inference Engines
Pour moi, c'est un terme très générique qui couvre tous les aspects du machine learning, du deep learning et des algorithmes type LLM mis en œuvre.
et il me partage l'article Wikipedia Inference engine que je n'avais pas lu quand j'avais rédigé 2024-06-06_1047, honte à moi 🫣.
Dans l'article Wikipedia Inference engine je lis :
In the field of artificial intelligence, an inference engine is a software component of an intelligent system that applies logical rules to the knowledge base to deduce new information.
et
Additionally, the concept of 'inference' has expanded to include the process through which trained neural networks generate predictions or decisions. In this context, an 'inference engine' could refer to the specific part of the system, or even the hardware, that executes these operations.
Je comprends qu'un Inference Engines n'effectue pas l'entrainement de modèles.
Pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Le contenu de l'article Wikipedia Llama.cpp augmente mon niveau de confiance dans ce choix de vocabulaire :
llama.cpp is an open source software library written in C++, that performs inference on various Large Language Models such as Llama
Journal du samedi 20 janvier 2024 à 17:22
#JaiLu le README de Ollama https://github.com/ollama/ollama
https://github.com/ollama/ollama
Get up and running with Llama 3.1, Mistral, Gemma 2, and other large language models.
Ollama est un Inference Engine (comme LLama.cpp).
Dépôt GitHub : https://github.com/ggerganov/whisper.cpp
Date de la création de cette note : 2025-04-25 .
Quel est l'objectif de ce projet ?
Ce projet est la suite du Projet 28. Le but est de créer un dépôt GitHub playground d'installation d'Open WebUI chez Scaleway, sur un k8s, en utilisant Open WebUI Helm Charts.
Quelques précisions sur l'objectif :
- [ ] Utiliser le Kubernetes managé de Scaleway : Kubernetes Kapsule
- [ ] Connecter Open WebUI à Scaleway Generative APIs
- [ ] Connecter Open WebUI à un Object Storage (voir)
- [ ] Setup Redis Websocket Support
- [ ] Connecter Open WebUI à un PostgreSQL (voir)
- [ ] Déployer Open WebUI sur 3 nodes Kubernetes différents
Autres projets en lien avec celui-ci
- Projet 28 - "Publier un repository playground de déploiement de Open WebUI basé sur docker-compose.yml"
- Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter"
Pourquoi je souhaite réaliser ce projet ?
J'ai commencé une mission liée à Open WebUI, service qui est déployé sur un cluster Kubernetes avec ArgoCD.
Je souhaite mieux comprendre le projet Open WebUI et remettre à niveau mon expérience pratique en Kubernetes.
Repository de ce projet :
- https://github.com/stephane-klein/open-webui-k8s-deployment-playground/ (travail en cours dans la branche wip)
Ressources :
Page officiel : https://www.scaleway.com/fr/generative-apis/
Site officiel : https://vast.ai/
Dépôt GitHub : https://github.com/vllm-project/vllm
Nom alternatifs à "Inference Engines" :
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, j'ai décidé d'utiliser le terme Inference Engines.
Update du 2024-06-08 : suite à 2024-06-08_1035, pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Exemples de "Inference Engines" :
Dernière page.