
Anthropic
Journaux liées à cette note :
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Journal du jeudi 12 mars 2026 à 11:18
En étudiant l'offre OpenCode Go, je suis tombé sur une page marketing du service ApiYi : « Is the OpenCode GO Plan Worth Buying? $10/Month 3 Model Tests + 5 Major Alternative Solutions Compared ».
En analysant le contenu avec Sonnet 4.6, j'ai compris qu'ApiYi fonctionne vraisemblablement comme une solution de contournement à destination du marché chinois : les utilisateurs qui ne peuvent pas acheter directement auprès d'Anthropic — en raison des risques de bannissement liés aux adresses IP et aux moyens de paiement chinois — y trouvent un accès indirect aux modèles.
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Serveur MCP web fetch local sous Claude Desktop pour contourner les blocages IP de certains sites
Mon installation de Claude Desktop sous Fedora était principalement motivée par l'exécution locale du tool "Web fetch tool" d'Anthropic, afin de contourner le blocage des IP d'Anthropic par certains sites web.
Après avoir passé en revue une demi-douzaine de serveurs MCP de type « web fetch », j'ai retenu zcaceres/fetch-mcp, implémenté en Javascript, qui, après quelques heures d'utilisation, semble bien fonctionner.
Voici mon fichier ~/.config/Claude/claude_desktop_config.json après configuration du serveur MCP :
{
"mcpServers": {
"fetch": {
"command": "npx",
"args": ["mcp-fetch-server"],
"env": {
"DEFAULT_LIMIT": "0"
}
}
},
"isUsingBuiltInNodeForMcp": false,
"isDxtAutoUpdatesEnabled": false,
"preferences": {
"coworkScheduledTasksEnabled": true,
"ccdScheduledTasksEnabled": true,
"coworkWebSearchEnabled": true,
"sidebarMode": "chat"
}
}
zcaceres/fetch-mcp supporte différents types de formats de fetching :
All tools accept the following common parameters:
- fetch_html — Fetch a website and return its raw HTML content.
- fetch_markdown — Fetch a website and return its content converted to Markdown.
- fetch_txt — Fetch a website and return plain text with HTML tags, scripts, and styles removed.
- fetch_json — Fetch a URL and return the JSON response.
- fetch_readable — Fetch a website and extract the main article content using Mozilla Readability, returned as Markdown. Strips navigation, ads, and boilerplate. Ideal for articles and blog posts.
- fetch_youtube_transcript — Fetch a YouTube video's captions/transcript. Uses
yt-dlpif available, otherwise extracts directly from the page. Accepts an additionallangparameter (default:"en") to select the caption language.
C'est le LLM qui choisit quel tool utiliser. J'ai demandé à Claude Sonnet 4.6 comment il effectuait son choix : par défaut, il utilise fetch_markdown ; lorsqu'il sait qu'un site contient des publicités, une sidebar, etc. — généralement les sites de presse —, il utilise fetch_readable.
J'ai observé que les tools fetch_markdown, fetch_readable et fetch_json fonctionnent bien, mais fetch_youtube_transcript n'a pas fonctionné chez moi. D'après les logs, ce tool semble contenir un bug. #JaimeraisUnJour essayer de le corriger.
J'ai installé Claude Desktop sous Fedora
Anthropic ne propose pas de version GNU Linux de Claude Desktop.
#JaiDécouvert le projet Claude Desktop for Linux qui a repackagé la version de Claude Desktop Windows pour GNU Linux. Ce projet propose des packages pour Debian, Fedora, ArchLinux et NixOS.
Je l'ai installé avec succès sous Fedora avec les commandes suivantes trouvé ici :
$ sudo curl -fsSL https://aaddrick.github.io/claude-desktop-debian/rpm/claude-desktop.repo -o /etc/yum.repos.d/claude-desktop.repo
$ sudo dnf install claude-desktop
J'ai ensuite testé la connexion de Claude Desktop au Filesystem MCP Server lancé en local :
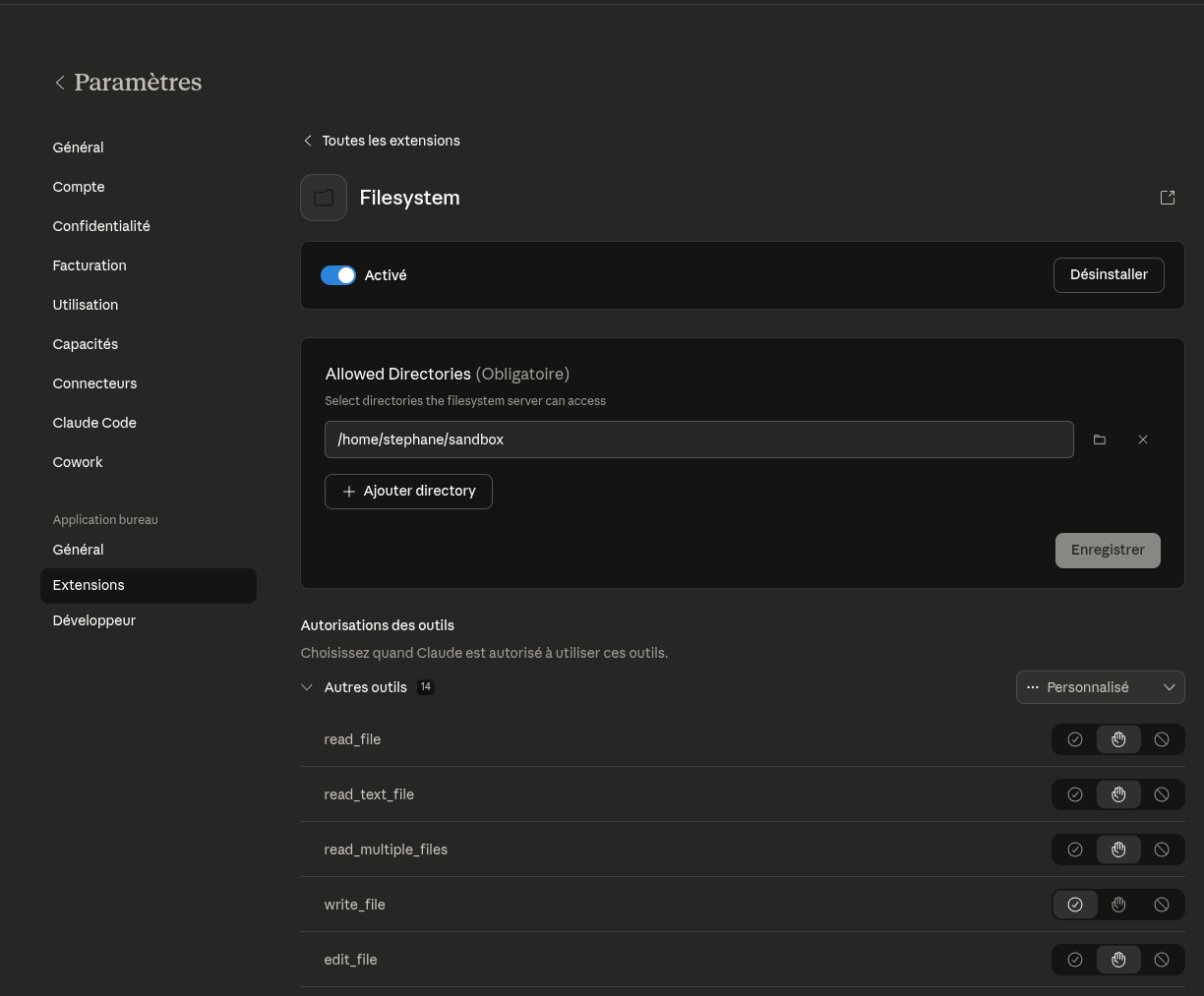
Seul élément négatif pour l'instant : la version Desktop ne permet pas d'utiliser l'extension Claude Counter (extension), contrairement à la version web.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals ou harnais (harness). Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
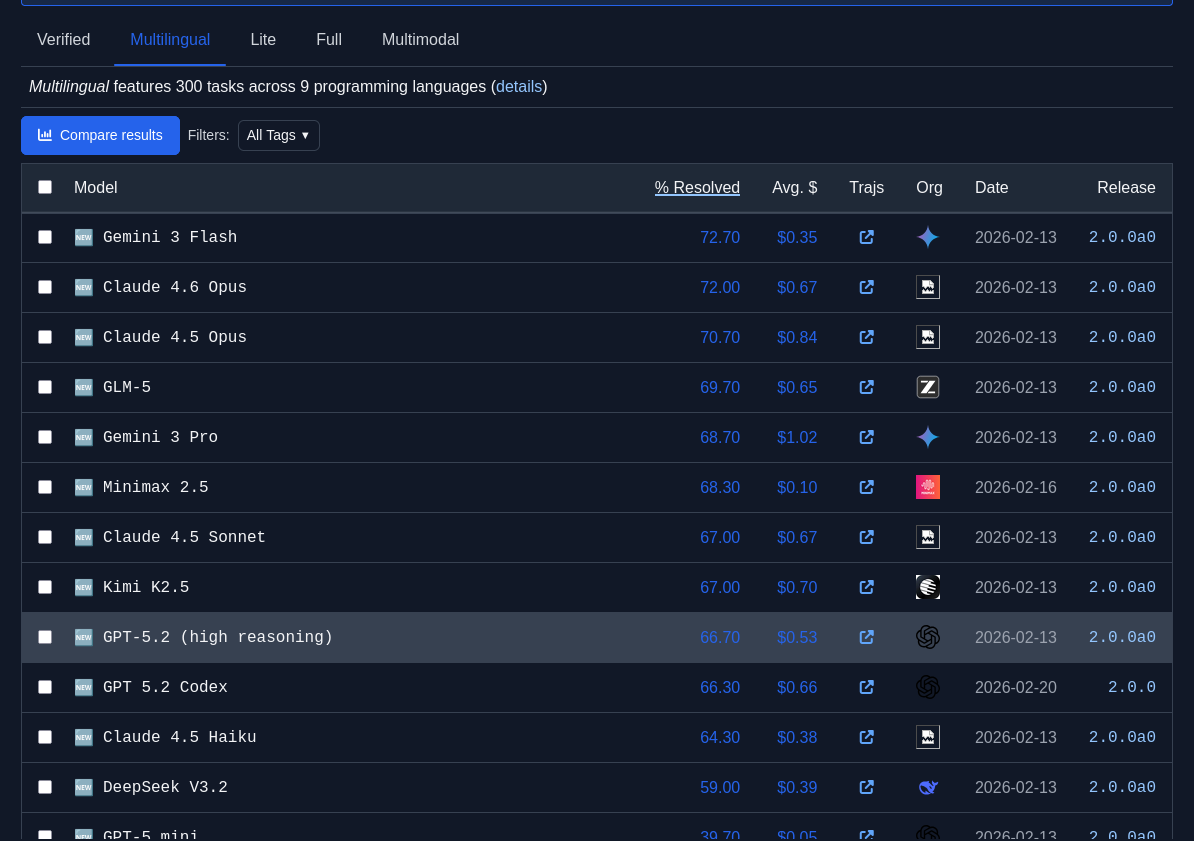
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?
Dans une note de juillet 2025, j'évoquais ne pas avoir trouvé d'information sur les limites de consommation de tokens de l'offre "Pro" de Claude.
J'avais observé empiriquement qu'avec mon usage de Claude Sonnet à l'époque, l'API directe était plus avantageuse qu'un abonnement Pro :
Entre le 30 mai et le 15 juillet 2025, j'ai consommé
$14,94de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
En 2026, avec la forte augmentation de l'usage des AI code assistant de type Claude Code ou OpenCode, la consommation de tokens a explosé, ce qui change la donne.
Je me pose à nouveau la question suivante : « Est-ce que les abonnements sont maintenant réellement plus économiques que l'utilisation directe de l'API ? ».
Cette semaine, j'ai effectué de nouvelles recherches pour en savoir plus sur les limites des abonnements Claude et cette fois, j'ai trouvé dans ce thread Reddit des informations.
Dans cette article, l'auteur explique les résultats qu'il a trouvé par reverse engineering.
Attention, l'unité "credits" est différente de "tokens". La définition de crédit est donné un peu plus loin dans cette note.
Le plan 20× n'est pas aussi avantageux qu'on pourrait le croire. Sur le site d'Anthropic, toutes les mentions « 20× plus d'utilisation* » comportent cet astérisque gênant. Les limites de session de cinq heures sont bien 20× plus élevées qu'en Pro, mais la vraie question est : quelle quantité de travail peut-on en tirer ? La réponse est : seulement deux fois plus par semaine que le plan 5×.
En revanche, le plan 5× offre un excellent rapport qualité-prix. Il tient largement ses promesses. C'est le point idéal du tableau tarifaire. Vous obtenez une limite de session six fois plus élevée que Pro (et non cinq), et plus de huit fois la limite hebdomadaire (davantage que l'éponyme cinq).
Tier Credits/5h Credits/week Pro 550,000 (1×) 5,000,000 (1×) Max 5× 3,300,000 (6×) 41,666,700 (8.33×) Max 20× 11,000,000 (20×) 83,333,300 (16.67×) Comparés aux tarifs de l'API, tous les abonnements semblent fantastiques. Les estimations de valeur dans le tableau sont des bornes inférieures, car la mise en cache rend l'équivalent API effectif encore plus favorable (je l'expliquerai dans un moment). Dans tous les cas, si vous pouvez utiliser un abonnement plutôt que l'API, foncez.
Tier Price Credits/month Opus-rate tokens Equivalent API cost Pro $20 21.7M 32.5M in or 6.5M out $163 (8.1×) Max 5× $100 180.6M 270.9M in or 54.2M out $1,354 (13.5×) Max 20× $200 361.1M 541.7M in or 108.3M out $2,708 (13.5×)
Voici un autre avantage de l'abonnement versus l'API :
Les lectures de cache. Elles sont entièrement gratuites.
Cela rend la balance encore plus favorable aux abonnements. Dans une boucle agentique (par exemple Claude Code), le modèle effectue des dizaines d'appels d'outils par tour. Après chaque appel d'outil, le modèle est invoqué à nouveau. Lecture du cache sur l'intégralité du contexte. L'API facture 10% pour chaque lecture ; les abonnements ne facturent rien. Ça s'accumule vite, comme nous allons le voir dans un instant.
Les écritures de cache sont également moins chères : elles coûtent 1,25×/2× le prix d'entrée sur l'API, tandis que sur l'abonnement elles sont facturées au prix d'entrée normal. Chaque tour de conversation est écrit dans le cache avant de pouvoir être lu, ce qui a donc aussi son importance.
Voici le lien entre credit et tokens :
Ce sont les unités utilisées en interne pour suivre la consommation de votre abonnement. « Crédits » est mon nom arbitraire pour ça — ces valeurs n'apparaissent pas directement dans un champ de l'API, donc il n'y a pas de mot évident pour les désigner. Je trouve que « crédits » sonne bien.
Comment passe-t-on des crédits aux tokens ? Voici la formule :
credits_used = ceil(input_tokens × input_rate + output_tokens × output_rate)...et les valeurs à y insérer :
Modèle Crédits/token en entrée Crédits/token en sortie Haiku 2/15 = 0,133... 10/15 = 2/3 = 0,666... Sonnet 6/15 = 2/5 = 0,4 30/15 = 2 Opus 10/15 = 2/3 = 0,666... 50/15 = 10/3 = 3,333... Les valeurs spécifiques semblent assez arbitraires, mais les ratios entre elles reflètent la tarification de l'API : la sortie coûte 5× l'entrée, vous paierez 5× plus pour Opus que pour Haiku, etc.
Après la lecture de cet article, il est clair que je vais utiliser principalement un abonnement Claude plutôt que des tokens d'API. Cependant, l'accès à un LLM par abonnement est moins flexible qu'une OpenAI Chat Completions compatible API.
Par exemple, je ne peux pas connecter Open WebUI, LibreChat ou toute autre application qui nécessite un accès direct à un LLM.
Mi-janvier 2026, j'ai lu ce thread à propos d'un "hack" utilisé par OpenCode pour accéder directement à l'API Anthropic avec un abonnement Claude. Ça m'a donné l'idée de chercher des outils de type "proxy" capables d'exposer une OpenAI Chat Completions compatible API à partir d'un abonnement Claude.
En fouillant sur Reddit, dans ce thread, j'ai trouvé les projets suivants :
Je compte tester ces deux projets dans les semaines à venir.
Comment j'ai perdu ma discipline en décembre et janvier
Jusqu'à mi-décembre 2025, cela faisait environ 2 ans que j'arrivais à rester concentré sur un sujet à la fois. J'avais réussi à éviter de papillonner d'un sujet à l'autre. Pour moi, un sujet n'est vraiment terminé que lorsque j'ai publié la note correspondante.
Le dernier sujet que j'avais exploré avec succès était mon étude de Fedora CoreOS.
Je me suis ensuite lancé dans l'étude pratique approfondie de Podman Quadlets. J'ai réussi à publier coreos-quadlet-playground, mais avant même d'avoir commencé à rédiger ma note de synthèse, j'ai perdu ma discipline.
Dans cette note, je vais tenter d'expliquer comment et pourquoi j'ai "dérapé" et faire un bilan des side-projects sur lesquels j'ai papillonné pendant ces deux derniers mois (depuis mi-décembre).
Lors de mon travail sur Podman Quadlets, j'ai découvert comment ce projet utilise avec élégance systemd-run et le mécanisme des generators (systemd-run-generator) de systemd pour incarner la philosophie Unix.
Suite à cette découverte, j'ai repensé aux scripts manuels que j'utilisais ces derniers mois pour lancer mes VM QEMU. Exemple : up-qemu-vm.sh. Je me suis dit qu'il serait élégant de lancer des VM QEMU de la même manière que Podman Quadlets.
Je n'ai pas réussi à résister à cette idée. Le 10 décembre au soir, je me suis dit que j'allais consacrer une petite heure à tester cette idée via du vibe coding avec Aider et Claude Sonnet 4.5.
Cette heure s'est transformée en 12h de session non-stop. J'ai réussi à publier une première version de qemu-compose, mais je venais de rompre ma discipline : je n'avais toujours pas écrit ma note sur Podman Quadlets.
Depuis, je n'ai pas réussi à retrouver ma discipline. Je suis tombé dans une spirale de papillonnage qui a duré deux mois 🙈.
En rédigeant cette note, j'ai essayé de comprendre pourquoi j'avais dérapé.
Je pense que c'était la combinaison de plusieurs facteurs :
- Le déclencheur : Ma première expérience réelle de vibe coding sur un projet complet. Cette expérience m'a tellement excité et en même temps tellement perturbé que j'ai perdu la motivation de rédiger ma note sur Podman Quadlets.
- La cascade : Une fois le premier écart fait, l'effet "What the hell" s'est enclenché : mon cerveau a rationalisé la continuation du comportement déviant par un "de toute façon, c'est déjà foutu, autant continuer".
- Le contexte : J'étais dans une période de stress et de frustration. L'illusion de toute-puissance qu'offrent les derniers modèles 4.5 d'Anthropic — obtenir des résultats rapides — m'a poussé dans une fuite en avant, un échappatoire pour combler mes frustrations du moment.
Depuis 2 ans, j'utilise trois garde-fous (circuit breakers) pour m'empêcher de démarrer un nouveau projet sans avoir terminé le précédent — autrement dit, pour éviter de papillonner et de survoler les sujets :
- Je tracke toutes mes activités via Toggl. Quand je démarre une activité, je lance consciemment le chronomètre. Cette friction me force à nommer ce que je fais et à rester conscient du temps que j'y consacre. C'est un premier filtre contre les distractions impulsives.
- Tous les matins, je rédige mes todo lists pro et perso dans Obsidian. L'élément clé est une section "Je ne veux pas faire" où je liste explicitement les tâches tentantes mais hors priorité. C'est mon exutoire pour les idées qui me donnent envie sans pour autant y céder.
- La publication de notes sur notes.sklein.xyz me force à définir ma "Definition of Done". Une itération (un sujet) n'est terminée que quand la note est publiée.
En analysant mes notes, je constate que j'ai progressivement abandonné la rédaction de mes todo lists quotidiennes à partir du 5 décembre — soit 5 jours avant mon dérapage sur qemu-compose.
Je pense que ce n'est pas un hasard.
#JaiDécidé de reprendre cette routine dès demain. C'est mon garde-fou le plus important.
Voici les sujets en vrac que j'ai survolés pendant ces 2 derniers mois — tous sans note de synthèse publiée :
- Réimplémentation complète de ma configuration chezmoi (inachevée)
- Développement de
gnome-settings-import-export
- Développement de
- Étude de timeshift et snapper
- Installation et configuration de netbird sur mes NUC
- Tentative d'installation de Kodi sur un de mes NUC (inachevée)
- Nouvelle configuration Neovim from scratch basée sur LazyVim (inachevée) :
lazyvim-playground - Migration de Fugitive vers Neogit
- Développement et publication du plugin
neo-tree-session.nvim - Étude puis abandon d'une migration Alacritty + tmux → wezterm (branche WIP)
- Étude puis abandon d'une migration Alacritty + tmux → kitty
- Étude d'une migration Alacritty → foot + tmux (en cours)
- Contribution au projet foot avec 2 Merge Requests :
- Test d'avante.nvim, notamment Avante Zen Mode — piste abandonnée
- Migration de Aider vers OpenCode
- Adoption de Jujutsu à la place de Git — utilisation quotidienne depuis plus d'un mois, progression continue mais pas encore fluide
Bilan : 13 explorations, 2 contributions open source, 1 plugin publié, 0 note de synthèse 😔.
En publiant cette note, je souhaite casser cet effet "What the hell".
Je vais sans doute accepter de ne pas publier de notes sur les sujets que j'ai abandonnés. Par contre, je souhaite à l'avenir publier des notes au sujet de :