
Spacefill
Journaux liées à cette note :
Exemples de labels de gestion de projet
Voici-ci dessous, une partie de la liste de labels d'Issues que l'équipe tech de Spacefill utlisait sous GitLab. Cette liste de labels est le fruit d'un travail itératif d'environ 15 personnes, sur une période de 4 ans.
Voici comment cette liste a été élaborée :
- Au départ, quelques labels ont été créés de manière organique par 3 développeurs et un product manager.
- Après 3 mois d'usage, une page de documentation nommée "GitLab Spacefill labels" a été ajoutée au handbook de l'équipe.
- Ensuite, au fur et à mesure des nouvelles problématiques rencontrées et de l'évolution des workflows, ce fichier de documentation a été amendé plus de 70 fois en 3 ans, par 11 contributeurs différents.
- Ce document était modifié suivant le même processus que le reste du handbook et le code :
- Une personne commençait par créer une issue pour décrire une problématique
- Ensuite, cette même personne ou une autre faisait une proposition d'évolution du processus par la rédaction d'une Merge Request qui modifiait cette page de documentation
- Puis cette Merge Request entrait dans une phase de review par l'équipe, était corrigée, amendée...
- Et finalement, quand cette Merge Request était approuvée par toute l'équipe, elle était mergée et ensuite respectée par tous
J'ai conservé cette liste afin de pouvoir l'utiliser comme source d'inspiration ou de fondation pour mes prochains projets en équipe.
Pour ceux qui souhaitent s'en inspirer, je recommande de ne pas adopter cette liste intégralement d'emblée. Privilégiez plutôt une sélection ciblée des labels qui correspondent à vos processus actuels, puis incorporez progressivement de nouveaux labels selon l'évolution de vos besoins.
Mon expérience m'a démontré que la mise en place de processus dans une organisation humaine fonctionne mieux par petites étapes successives. Cette approche incrémentale s'avère bien plus efficace que de tenter d'imposer en bloc un processus complet qui risquerait d'être inadapté à votre contexte spécifique.
Voici cette liste.
Labels pour indiquer les types d'issue
Une issue doit avoir dans tous les cas un seul type.
type::user-story: une issue qui apporte une fonctionnalité à l'applicationtype::improve: une issue qui apporte une amélioration mineure à une fonctionnalité existante, qui est plus simple de ne pas exprimer sous forme d'une user story, et qui bien sûr n'est pas un bug.type::documentation-and-process: problème ou amélioration d'un process ou d'une documentation interne (les deux sujets documentation et processus sont liés parce que les processus sont documentés). La documentation du logiciel à destination des usagers de l'application n'entre pas dans cette catégorie, elles sont du typeuser-story,improveoubug.type::enabler: un changement qui n'apporte pas directement de valeur aux utilisateurs de l'application. Ce type est utilisé pour des issues dont le but est d'améliorer l'expérience des développeurs (voir définitions : SAFe Enablers,Les enablers en agile)type::technical-debt: definition, label à utiliser, par exemple pour des issues dont le bug est d'upgrader une librairie, d'améliorer une implémentation, ou une proposition de refactoring… Ce label ne doit pas être utilisé pour des issues "produit".type::support-ops: pour les tâches de support qui ne nécessitent généralement pas de merge request, par exemple : des migrations de données, des corrections de données, des extractions de données…type::spike: voir la definitiontype::meta: pour des issues de type "meta", par exemple, des issues dont le but est de créer d'autres issues, de faire de l'affinage d'issues, ou organiser des rituels…type::meta-spec-writing: pour des issues dont l'objectif est de créer des issues ou des Epic, dont le but est de rédiger des spécifications techniques, ce sont des sortes d'issues de type "meta", mais plus spécifiques.
type::bug: pour des issues qui décrivent des dysfonctionnements de l'applicationtype::bug-job-CI: pour des issues qui décrivent des bugs de CI
Labels pour indiquer la priorité des issues
priority::critical: une issue qui doit obligatoirement être traitée tout de suite par un développeurpriority::24h: une issue qui doit être traitée d'ici 24hpriority::7days: une issue qui doit être traitée d'ici à 1 semaine
Labels de workflow
Une issue doit avoir un et seulement un label de type workflow, un et un seul label de type product-review.
- Draft
workflow::need-product-specs: l'issue doit être spécifiée par un membre de l'équipe produitworkflow::need-design: l'issue a besoin de wireframe, design, …workflow::need-tech-specs: l'issue doit être affiner par un membre de l'équipe tech
- To do
workflow::ready-for-development: l'issue est prête à être implémentéeworkflow::to-be-continued: l'issue a été commencée, mais mise en pause parce que le développeur est assigné sur une autre issue.workflow::doing: un développeur est en train de travailler sur cette issueworkflow::ready-for-first-review: l'issue est prête à être review par un développeurworkflow::ready-for-maintainer-review: l'issue est prête à être review par un maintainersworkflow::blocked: l'issue est bloquée Par exemple :- l'issue est commencée, elle peut avoir une merge request de prête, mais le développeur ne peut pas la terminer, car elle dépend d'une autre Merge Request en cours d'élaboration ;
- l'auteur de l'issue attend une réponse d'une personne externe de l'équipe produit ou tech, par exemple un client.
workflow::ready-for-merge: l'issue a été review et est prête à être mergéneed-cto: l'issue est bloquée parce qu'elle est en attente d'une validation par le CTO
- Product review
product-review::needed: indique que l'issue doit être review par un membre de l'équipe produitproduct-review::not-needed: indique que l'issue n'a pas besoin d'être review par l'équipe produitproduct-review::pending: issue en attente de review par un membre de l'équipe produitproduct-review::feedback: une demande de correction a été émise par un membre de l'équipe produitproduct-review::approved: la Merge Request a été review et validée par un membre de l'équipe produit avec plus aucune demande de correction
Labels d'intégration dans des boards
board-product-refinement: pour intégrer des issues dans un Kanban board qui contient une liste d'issues que l'équipe produit doit affinerboard-tech-refinement: pour intégrer des issues dans un Kanban board qui contient une liste d'issues que l'équipe tech doit affinerboard-support: pour intégrer des issues dans un Kanban board qui contient une liste d'issues de support qui traitent des demandes externes à l'équipe tech ou produit.board-cto: utilisé par le CTO pour suivre des issues "cross team"
Labels divers
first-contribution: pour identifier des issues en théorie facilement réalisables par un nouveau développeur en phase d'onboarding.sprint-planning: pour les issues de typemeta, dont l'objectif est d'organiser le rituel Sprint Planning.sprint-retrospective: pour les issues de typemeta, dont l'objectif est d'organiser le rituel Sprint Retrospective.sprint-retro-follow-up: pour identifier les sujets qui ont été remontés lors d'une session de Sprint Retrospective.triage: pour identifier les issues qui doivent être triées, c'est-à-dire, décider si l'issue doit être abandonnée pour être placée dans un backlog.need-to-be-planned: pour identifier des issues validées, mais qui doivent être planifiées, c'est-à-dire, être ajoutées dans un sprintdanger: pour identifier des issues qui doivent être traitées avec prudence, qui par exemple risquent de détruire des données.tech-refinement: pour identifier une issue qui doit être affiner par l'équipe tech, mais qui n'a pas encore été ajoutée dans leboard-tech-refinement.tech-refinement-removed: pour identifier des issues qui étaient dans unboard-tech-refinementmais qui n'ont pas été affiné par manque de temps et donc repoussées à une future session.security: pour identifier des issues en lien avec la sécurité informatique, par exemple, un risque de fuite de données, de perte de données, d'intrusion…version-outdated: pour identifier les issues dont l'objectif est la mise à jour de librairies ou de services.
Label de compétences nécessaires
Liste de labels peu utilisés, ils permettaient d'identifier les compétences techniques nécessaires pour pouvoir traiter l'issue.
skills:ansibleskills:terraformskills:nodejsskills:postgraphileskills:html/cssskills:dockerskills:gitlab-ciskills:dockerskills:dev-opsskills:postgresskills:postgres-rlsskills:postgres-rbacskills:postgresql-plsqlskills:postgresql-policyskills:reactjsskills:shellscriptskills:sql
Nom et arborescence de Monorepo
Je suis un adepe du paradigme Monorepo, de la documentation colocalisée et des issues colocalisées.
Je conseille de nommer le repository avec le nom de l'organisation.
Par exemple, si mon organisation se nomme « Dummy Tech » et si elle utilise GitLab, alors je conseille d'utiliser le slug dummy-tech, ce qui donne gitlab.com/dummy-tech/dummy-tech/ et « Dummy Tech Monorepo » comme titre de repository.
La neutralité de ce nom facilite les décisions concernant ce qui peut ou non être inclus dans le repository, sans être limité par un nom trop restrictif. Il est flexible face à l'évolution du projet. Il permet d'éviter bien des débats à propos du nommage.
En 2018, sur GitHub, j'ai découvert un exemple de monorepo d'une organisation. Cet exemple m'a servi de base et je l'ai fait évoluer quand je travaillais chez Spacefill.
Voici un exemple d'arborescence de monorepo que j'aime utiliser :
dummy-tech
├── deployments
│ ├── prod
│ └── sandbox
├── ci
├── docs
├── playgrounds
│ ├── playground_a
│ └── playground_b
├── services
│ ├── service_a
│ ├── service_b
│ └── service_c
└── tools
├── tool_a
├── tool_b
└── tool_c
Journal du mardi 06 mai 2025 à 13:42
Suite à la lecture du thread "jj tips and tricks" Lobster, je suis tombé dans un rabbit hole (1h30) : #JaiLu les articles ci-dessous au sujet de Jujutsu.
- "What I've learned from jj" (134 commentaires Hacker News et 57 commentaires Lobster)
- Et ses sous-articles :
- "jj tips and tricks"
Quelques commentaires au sujet de l'article "What I've learned from jj"
Along with describing and making new changes, jj squash allows you to take some or all of the current change and “squash” it into another revision. This is usually the immediate parent, but can be any revision.
...
With jj squash, the current change is pushed into whatever target revision you want. And if that change has children, they’ll all be automatically rebased to incorporate the updated code, no additional work is needed.
J'ai hâte de tester si, à l'usage, c'est sensiblement plus simple qu'avec Git 🤔.
Conflict resolution
One of the consequences of being able to modify changes in-place is that all subsequent changes need to be rebased to account for the updated parent. If there were a sequence
s -> t -> u -> vand you’d modifiedt, jj will automatically rebase the rest:s -> t' -> u' -> v'. This includes conflicts, if any arise. The difference from git is that conflicts are not a stop-the-world event! You’ll see in the jj log output that changes have a conflict, but it won’t prevent a command (like an explicit or implicit rebase) from running to completion. You get to choose when and how to resolve the conflicts afterward. I found this a surprising benefit: rebases are already less stressful because of how easyundois, but now I’m no longer interrupted and forced to resolve conflicts immediately.
Cette simplicité annoncée me surprend vraiment. J'ai du mal à imaginer le fonctionnement, sans doute parce que je suis trop habitué à utiliser Git. J'ai l'impression que c'est de la magie !
J'ai hâte de tester !
... efforts to add
Change-IDas a supported header in git itself to enable durable change tracking on top of commits.
J'ai découvert cette initiative, je trouve cela très intéressant👌.
Un commentaire au sujet de l'article "First-class conflicts"
First-class conflicts
...
Unlike most other VCSs, Jujutsu can record conflicted states in commits. For example, if you rebase a commit and it results in a conflict, the conflict will be recorded in the rebased commit and the rebase operation will succeed. You can then resolve the conflict whenever you want. Conflicted states can be further rebased, merged, or backed out. Note that what's stored in the commit is a logical representation of the conflict, not conflict markers; rebasing a conflict doesn't result in a nested conflict markers (see technical doc for how this works).
Je trouve cela très intéressant.
Voici une commande pour extraire un patch avec l'inclusion des "Conflict markers" (je n'ai pas encore testé) :
$ jj diff --include-conflicts > conflicts.patch
Un commentaire au sujet de l'article "In Praise of Stacked PRs"
“Stacked PRs” is the practice of breaking up a large change into smaller, individually reviewable PRs which can depend on each other, forming a DAG.
Je suis ravi de découvrir que le terme "Stacked PRs" existe pour décrire le concept que j'expliquais souvent quand j'étais chez Spacefill.
En lisant ces articles, #JaiDécouvert :
git-rerere- Mercurial Changset Evolution
git-machete- git-stack (
git-stack) - GitBulter (https://github.com/gitbutlerapp/gitbutler)
et j'ai "redécouvert" :
Journal du jeudi 10 octobre 2024 à 18:08
Je pense que l'utilisation du framework CommunityRule et Loomio peut être très efficace pour travailler en équipe.
J'aurais aimé expérimenter ces deux outils quand j'étais CTO chez Spacefill.
Première itération de mon aventure Malt
Il y a quelques mois, j'ai envisagé de créer plusieurs profils sur Malt pour me présenter sous différentes "casquettes". Par exemple :
- CTO as a Service
- CPTO
- DevOps
- Expert en Web Scraping
- Développeur Frontend
- Développeur Backend
- Développeur Fullstack
- …
Cette idée m'est venue en 2022, lorsque j'étais CTO chez Spacefill et que je recrutais des freelances pour des missions très spécifiques.
Je m'étais alors rendu compte que la sélection des profils était fastidieuse et que je passais à côté de candidats intéressants simplement à cause de problèmes liés aux mots-clés.
C'est à ce moment-là que je me suis dit que si un jour je m'inscrivais sur une place de marché de freelances, il serait judicieux de créer plusieurs types de profils pour contourner ces limitations de filtres.
En août dernier, j'ai fait quelques recherches sur la possibilité de créer plusieurs profils sur Malt et je suis tombé sur cette page (webarchive):
Créer plusieurs profils dans Malt ?
Vous pouvez créer plusieurs profils dans Malt. Chaque compte doit être associé à une adresse e-mail différente.
Chez Malt, nous déconseillons de créer deux profils différents sur la marketplace sauf si vous avez deux activités très différentes, par exemple si vous êtes développeur et graphiste.
Vos filleuls et gains cumulés seront alors répartis entre plusieurs profils.
Si vous exercez deux activités indépendantes très différentes, nous vous conseillons de créer deux comptes distincts en prenant soin de télécharger les documents liés à votre(vos) activité(s).
Nous ne pourrons pas fusionner vos notes et projets entre vos deux profils.
Création de mon compte Malt
Je me suis ensuite dit qu'avant de mettre en place une stratégie complexe, qu'il serait plus judicieux de commencer par créer et publier un simple profil.
En remplissant ce profil, j'ai constaté que je pouvais renseigner une longue liste de compétences. J'ai alors pensé que l'idée de créer plusieurs profils n'était finalement plus nécessaire.
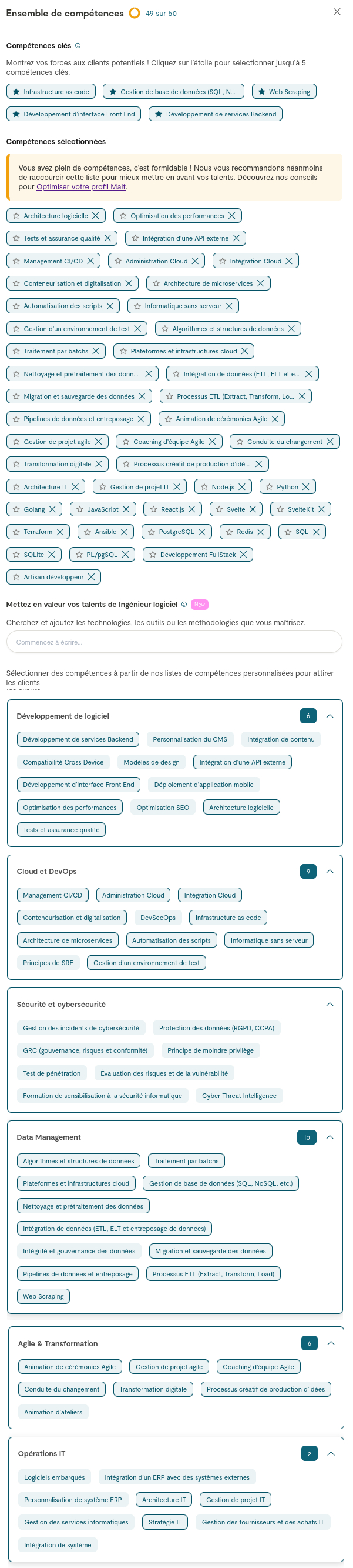
Premier point de difficulté, le choix de la catégorie :
J'ai opté pour une catégorie générique, celle de "Ingénieur logiciel".
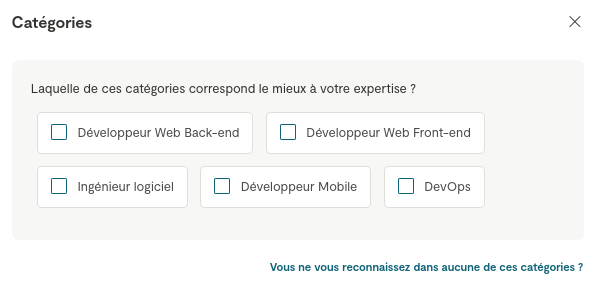
Cependant, je doute fortement que ce soit le premier choix d'une personne que utilise le recherche de Malt 🤔 :
'ai fait un test en choisissant l'intitulé "Développeur". Après avoir filtré par mon tarif journalier exact et mon niveau d'expérience, je suis présent en page 6 des résultats.
Si je sélectionne la catégorie "Développeur Web Back-end" ou "Développeur Web Front-end" je ne suis plus présente dans la liste des résultats 😟.
Bilan Malt après 25 jours
Mon bilan Malt après 25 jours ? Pour le moment, personne ne m'a contacté. J'observe que mes statistiques sont plutôt mauvaises. De plus, je pense que les 3 personnes qui ont vu mon profil sont des amis.
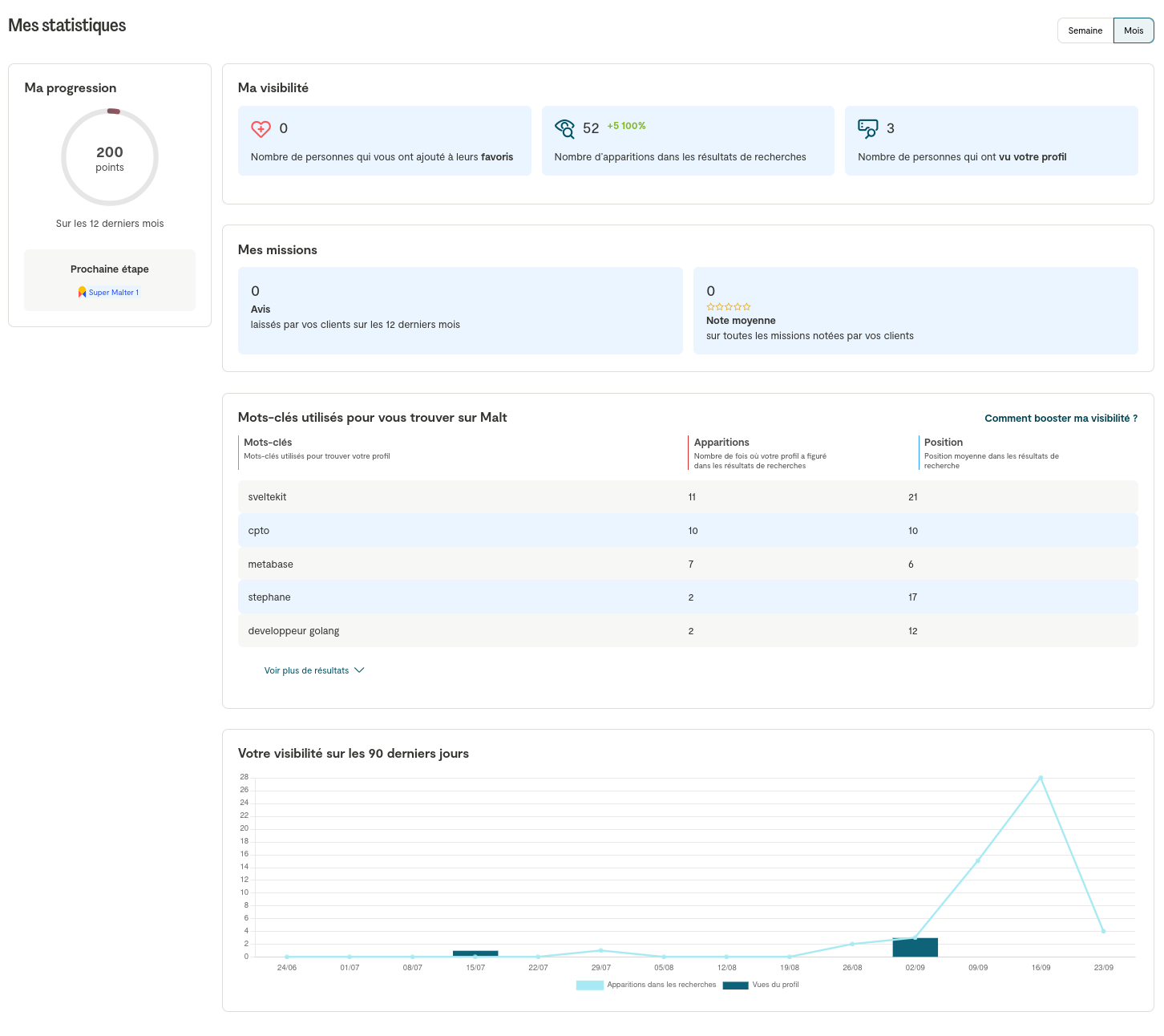
Un ami freelance m'a confié qu'il n'avait reçu qu'une seule proposition de mission sur Malt en plus de trois ans.
Un autre ami freelance m'a confié avoir eu, sur un an, sur Malt, environ 40 propositions de mission, 5 échanges constructifs et signé deux missions.
Suite de stratégie Malt ?
Il est clair que mon profil Malt n'est pas optimisé.
J'ai visé trop large en listant mes compétences, et je pense que ce n'est pas la meilleure stratégie.
Le problème, c'est que si je veux rendre mon profil plus spécialisé, je vais devoir faire des choix et retirer des compétences que je ne souhaite pas supprimer 😞.
Pour éviter cela, je vois deux stratégies :
- Modifier mon profil chaque semaine, en ajustant les technologies, les catégories et le tarif journalier ;
- Créer plusieurs profils.
#JeMeDemande si l'étape de vérification des documents d'entreprise va m'empêcher de créer plusieurs profils 🤔.
#JeMeDemande s'il est préférable que je consacre prioritairement du temps à l'optimisation de mon profil Malt ou alors de travailler sur ma Stratégie de promotion de mon activité freelance sur LinkedIn 🤔.
#JaiDécidé de reporter l'optimisation de mon profil Malt.
Journal du vendredi 16 août 2024 à 11:39
#JaiLu la note de David Larlet nommée Initiateurs et mainteneurs.
There are two roles for any project: starters and maintainers. People may play both roles in their lives, but for some reason I’ve found that for a single project it’s usually different people. Starters are good at taking a big step in a different direction, and maintainers are good at being dedicated to keeping the code alive.
…
I am definitely a starter. I tend to be interested in a lot of various things, instead of dedicating myself to a few concentrated areas. I’ve maintained libraries for years, but it’s always a huge source of guilt and late Friday nights to catch up on a backlog of issues.
Je suis également un initiateur. J’aime créer de nouvelles choses en expérimentant des usages et des techniques. Lorsque je me retrouve dans un rôle de mainteneur, j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses. Or l’apprentissage nait de l’échec et du test des limites. C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. À moins que la maintenance soit un vestige du passé (cache).
-- from
Ces réflexions résonnent profondément en moi 🤗, car ce sont des questions et des pensées qui m'habitent depuis de nombreuses années.
« j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses »
Pour éviter cette tendance à complexifier l’existant, j'utilise la stratégie suivante. Lorsque je ressens le besoin d'expérimenter ou d'apprendre quelque chose de nouveau, je le fais au travers des side projects personnels ou dans le cadre de POC (Proof of Concept) et Spike officiellement décidés en équipe. C'est entre autres pour cette raison que j'avais proposé de mettre en place les Spike and Learn Day.
Cette approche me permet de satisfaire ma curiosité et mon envie d'apprendre, tout en maintenant l'utilisation de Boring Technology pour les projets critiques ou ceux menés en équipe. Ainsi, je parviens à éviter le piège du Resume Driven Development.
J'aime bien la distinction suivante :
« There are two roles for any project: starters and maintainers »
Jusqu'à présent, j'ai tendance à utiliser le terme solo développeurs pour les "starters" et team développeurs pour les "maintainers".
Petite anecdote amusante : lors de mon expérience chez Spacefill, j'avais proposé de nommer le rôle des développeurs d'expérience au sein de l'équipe les "maintainers" 😉.
« C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. »
C'est une réflexion que j'ai moi-même eue par le passé.
Je crois en effet que les solo développeurs apprécient particulièrement les microservices et les multi repositories car cela leur permet d'éviter les contraintes d'équipes.
Cela leur permet d'explorer des nouveaux langages et frameworks et d'échaper aux revues de code.
À mes yeux, cette approche favorise davantage l'individualisme que la cohésion d'équipe.
J'ai également remarqué que c'est souvent lors des phases de storming du modèle de Tuckman que les développeurs semblent se tourner vers les microservices comme une forme d'évitement des défis collectifs. Cette stratégie peut sembler séduisante, mais elle risque de renforcer les silos et de freiner la collaboration au sein de l'équipe 🤔.
Journal du samedi 06 avril 2024 à 20:00
Article publié sur https://sklein.xyz/fr/posts/2024-04-06_spike-and-learn-day/
Concept que mon équipe et moi avions nommé "Spike and Learn day"
Quand j’étais CTO chez Spacefill, en mai 2021, j’ai mis en place avec mes collègues un rituel que nous avons nommé “Spike and Learn day”.
Un vendredi sur deux — soit 10 % du temps de travail — chaque développeur pouvait librement décider de consacrer sa journée à l’apprentissage d’une nouvelle chose, tester une idée, travailler sur de la dette technique, ou implémenter en autonomie des choses qu’il pensait utiles pour la société.
Pendant cette journée, le développeur n’avait pas à suivre le sprint, ni la roadmap, c’était un espace de liberté.
Les sujets pouvaient être aussi des initiatives d’amélioration produits.
Limites : les sujets devaient être en rapport avec des stacks technologiques utilisés ou potentiellement utilisable par la société (exemple, l’étude d’un moteur de jeu vidéo n’était pas autorisé, car il y avait peu de chance que ça soit utile au business de la société).
Précision importante : l’intégration du résultat de ces journées « Spike and Learn » pouvait être refusé ou non priorisé par l’équipe produit ou non accepté lors de la phase de review par les autres développeurs. Cela faisait partie du jeu de l’expérimentation.
Si un “Spike and Learn day” tombait un jour férié ou pendant les congés d’un développeur, la journée était considérée comme perdue.
Cette idée était largement inspirée de l’initiative de Google nommée “20% Project”.
Pourquoi le mot “spike” ? J’ai puisé le concept de Spike dans le Extreme Programming — qui m’avait été souflé par Ronan —, pour en avoir une définition, je vous conseille l’article What is Spike in Scrum? (archive).
Initialement, j’avais prévu mettre à disposition des projets bootcamps dans lesquels les développeurs auraient pu puiser pour la partie “learn” de leurs journées.
J’envisageais, par exemple, des sujets DevOps, exploration de Docker, déployer un serveur de A à Z via Vagrant, ou alors de recontruire les bases de la stack web employé par la société depuis zéro…
Mais malheureusement — et Claire me l’a souvent rappelé 😉 — en 2 ans, je n’ai produit aucun bootcamp 😭 !
Ajustement au cours du temps
Avec l’expérience, nous avons décidé — quand c’était possible — de placer cette journée en fin de sprint afin de ne pas “casser” sa dynamique.
Ce qui donnait l’emploi du temps théorique suivant :
- Travail sur les issues du Sprint Scrum du lundi de la semaine 1 au jeudi matin de la semaine 2
- Jeudi après-midi de la semaine 2 : Sprint rétrospective et Sprint planning
- Vendredi de la semaine 2 : “Spike and Learn day”
Quels ont été les effets de cette initiative ?
D’après ce que j’ai pu observer ou ce qui m’a été dit, je pense que cette initiative était plutôt appréciée des développeurs.
J’ai pu noter que la plupart des développeurs avaient leurs préférences :
- Certains privilégiaient fortement des activités de dette technique
- D’autres préfèraient terminer une issue en retard du sprint
- Et d’autres préféraient explorer de nouvelles choses, tester des fonctionnalités
Les développeurs m’ont remonté une frustration concernant le défi que représente la réalisation d’un projet nécessitant plusieurs jours de travail avec seulement deux jours alloués par mois. De plus, le délai de quinze jours entre chaque session rend difficile la reprise du travail sur le sujet.
J’ai été agréablement surpris de voir que ce rituel ait été respecté sans difficulté majeure pendant plusieurs années. Je n’ai pas souvenir de suppression exceptionnelle de cette journée par l’équipe produit ou de management.
Si j’en ai un jour la possibilité, si je suis à nouveau en responsabilité, je pense que c’est une initiative que je proposerai à nouveau de mettre en place.