
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (50 notes) :
J'ai découvert Beads, Dolt et DoltgreSQL
En parcourant awesome-opencode, je suis tombé sur opencode-beads, qui m'a fait découvrir le projet Beads :
Beads is a distributed graph issue tracker for AI agents, powered by Dolt.
J'ai passé un peu de temps à parcourir la documentation du projet et je vois beaucoup de choses intéressantes et qui rejoignent les idées que j'ai pour "Projet 24 - Prototyper le gestionnaire de projet de mes rêves".
Ce projet m'a aussi fait découvrir Dolt :
Dolt is a SQL database that you can fork, clone, branch, merge, push and pull just like a Git repository.
et DoltgreSQL :
From the creators of Dolt, the world's first version controlled SQL database, comes DoltgreSQL, the postgres-flavored version of Dolt. It's a SQL database that you can branch and merge, fork and clone, push and pull just like a Git repository. Connect to your Doltgres server just like any Postgres database to read or modify schema and data. Version control functionality is exposed in SQL via system tables, functions, and procedures.
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du samedi 30 août 2025 à 20:17
Je viens de publier : Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch".
Journal du mardi 26 août 2025 à 21:45
Voici une note pour présenter la seconde #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
J'ai tout d'abord implémenté dans ce commit un mécanisme qui exécute du code JavaScript automatiquement après chaque git push.
Pour cela, j'ai choisi de me baser sur le mécanisme Server-Side Hooks natif de Git : post-receive.
Voici le contenu de ce script hook en Bash :
#!/bin/bash
while read oldrev newrev refname; do
branch=$(git rev-parse --symbolic --abbrev-ref $refname)
curl -X POST \
-H "Content-Type: application/json" \
-d "{
\"oldrev\": \"${oldrev}\",
\"newrev\": \"${newrev}\",
\"refname\": \"${refname}\",
\"branch\": \"${branch}\",
\"repository\": \"$(basename $(pwd))\"
}" \
"${POST_RECIEVE_HOOK_URL}" >> /dev/null
done
Chaque événement git push déclenche un appel HTTP vers le endpoint http://localhost:3334/post_recieve_hook_url/ exposé par le serveur NodeJS. Le payload contient notamment :
oldrev: l'identifiant du dernier commit présent dans le repository avant le pushnewrev: l'identifiant du commit le plus récent envoyé lors du push
L'intervalle entre oldrev et newrev permet d'identifier précisément l'ensemble des commits qui ont été poussés lors de cette opération.
J'ai ensuite implémenté une version SvelteKit iso-fonctionnelle de node-git-http-server. Voici le repository poc-node-git-server-in-sveltekit .
Contrairement à ce que j'avais prévu initialement, pour cette implémentation, je ne me suis pas basé sur SvelteKit Custom Server, mais sur la fonctionnalité Server hooks : src/hooks.server.js#L11.
Journal du dimanche 24 août 2025 à 12:42
Je viens de publier la première #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push" dans le repository node-git-http-server.
L'implémentation d'un serveur Git HTTP via Apache ou nginx, en s'appuyant sur git-http-backend , paraît plutôt simple à réaliser.
Comme mon objectif est d'intégrer cette fonctionnalité dans le projet sklein-pkm-engine et que j'ai une préférence pour les monolith, j'ai exploré les solutions basées sur NodeJS.
J'ai dans un premier temps étudié le projet node-git-http-server et ensuite node-git-server.
Ces deux projets semblent peu actifs.
J'ai échoué à faire fonctionner le projet node-git-server, probablement à cause d'une erreur de ma part — j'ai sans doute oublié d'initialiser au préalable les dépôts Git en mode bare.
Par la suite, en utilisant Claude Sonnet 4, j'ai créé une implémentation basée uniquement sur les modules natifs de NodeJS et l'exécutable git-http-backend , sans recourir à aucun package NodeJS externe.
Voici le résultat : node-git-http-server/server.js.
Prochaines étapes
- Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. - Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server.
Journal du samedi 23 août 2025 à 18:29
Je viens de publier : Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
Journal du mardi 06 mai 2025 à 14:49
Je gère actuellement un projet comprenant 8 Merge Requests empilées (Stacked PRs) en cours de review, s'étendant sur une période d'environ deux mois.
Au fur et à mesure que je continue à travailler sur ce projet, j'ai effectué à plusieurs reprises des améliorations ou des corrections qui concernent des commits déjà en cours de review.
Si ces Merge Request étaient mergés, cela ne me poserait pas de problème. Je proposerai de nouvelles Merge Request avec ces changements.
Dans la situation actuelle, si je souhaite effectuer une amélioration dans la Merge Request numéro 2, je préfère modifier directement cette Merge Request plutôt que d'en créer une nouvelle. Cette approche me semble plus logique et propre, surtout pour une Merge Request qui n'a pas encore été review.
En pratique, la modification de la Merge Request numéro 2 est une tâche fastidieuse. Si je modifie cette Merge Request, je vais devoir propager mon changement sur 6 branches et résoudre de nombreux conflits. J'ai peur de faire une erreur.
Cette opération est très pénible.
C'est pour cette raison que j'ai étudié dernièrement Stacked Git et Jujutsu.
Je me demande quel outil serait le plus adapté pour gérer ma problématique.
git-stack, git-branchless, Stacked Git ou Jujutsu 🤔.
Journal du mardi 06 mai 2025 à 13:42
Suite à la lecture du thread "jj tips and tricks" Lobster, je suis tombé dans un rabbit hole (1h30) : #JaiLu les articles ci-dessous au sujet de Jujutsu.
- "What I've learned from jj" (134 commentaires Hacker News et 57 commentaires Lobster)
- Et ses sous-articles :
- "jj tips and tricks"
Quelques commentaires au sujet de l'article "What I've learned from jj"
Along with describing and making new changes, jj squash allows you to take some or all of the current change and “squash” it into another revision. This is usually the immediate parent, but can be any revision.
...
With jj squash, the current change is pushed into whatever target revision you want. And if that change has children, they’ll all be automatically rebased to incorporate the updated code, no additional work is needed.
J'ai hâte de tester si, à l'usage, c'est sensiblement plus simple qu'avec Git 🤔.
Conflict resolution
One of the consequences of being able to modify changes in-place is that all subsequent changes need to be rebased to account for the updated parent. If there were a sequence
s -> t -> u -> vand you’d modifiedt, jj will automatically rebase the rest:s -> t' -> u' -> v'. This includes conflicts, if any arise. The difference from git is that conflicts are not a stop-the-world event! You’ll see in the jj log output that changes have a conflict, but it won’t prevent a command (like an explicit or implicit rebase) from running to completion. You get to choose when and how to resolve the conflicts afterward. I found this a surprising benefit: rebases are already less stressful because of how easyundois, but now I’m no longer interrupted and forced to resolve conflicts immediately.
Cette simplicité annoncée me surprend vraiment. J'ai du mal à imaginer le fonctionnement, sans doute parce que je suis trop habitué à utiliser Git. J'ai l'impression que c'est de la magie !
J'ai hâte de tester !
... efforts to add
Change-IDas a supported header in git itself to enable durable change tracking on top of commits.
J'ai découvert cette initiative, je trouve cela très intéressant👌.
Un commentaire au sujet de l'article "First-class conflicts"
First-class conflicts
...
Unlike most other VCSs, Jujutsu can record conflicted states in commits. For example, if you rebase a commit and it results in a conflict, the conflict will be recorded in the rebased commit and the rebase operation will succeed. You can then resolve the conflict whenever you want. Conflicted states can be further rebased, merged, or backed out. Note that what's stored in the commit is a logical representation of the conflict, not conflict markers; rebasing a conflict doesn't result in a nested conflict markers (see technical doc for how this works).
Je trouve cela très intéressant.
Voici une commande pour extraire un patch avec l'inclusion des "Conflict markers" (je n'ai pas encore testé) :
$ jj diff --include-conflicts > conflicts.patch
Un commentaire au sujet de l'article "In Praise of Stacked PRs"
“Stacked PRs” is the practice of breaking up a large change into smaller, individually reviewable PRs which can depend on each other, forming a DAG.
Je suis ravi de découvrir que le terme "Stacked PRs" existe pour décrire le concept que j'expliquais souvent quand j'étais chez Spacefill.
En lisant ces articles, #JaiDécouvert :
git-rerere- Mercurial Changset Evolution
git-machete- git-stack (
git-stack) - GitBulter (https://github.com/gitbutlerapp/gitbutler)
et j'ai "redécouvert" :
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Journal du mardi 18 mars 2025 à 14:03
Ce midi, j'ai échangé avec un ami au sujet de ForgeFed (https://forgefed.org/) :
ForgeFed is a federation protocol for software forges and code collaboration tools for the software development lifecycle and ecosystem. This includes repository hosting websites, issue trackers, code review applications, and more.
ForgeFed est une extension d'ActivityPub.
Voici la roadmap d'intégration d'implémentation de ForgeFed dans Forgejo : Roadmap for Federation.
Journal du samedi 07 décembre 2024 à 20:49
Je pense être arrivé à une solution plus ou moins satisfaisante pour le Projet 19 - "Documenter une méthode pour synchroniser un monorepo vers des multirepos qui fonctionne dans les deux sens".
Voici-ci, ci-dessous, les étapes de la démonstration qui sont détaillées dans le README.md du repository poc-git-monorepo-multirepos-sync.
- Je crée deux repositories :
frontendetbackend(multi repositories) ; - J'utilise le script tomono pour les intégrer dans un monorepo nommé
monorepo; - J'ajoute deux fichiers à la racine de
monorepo:README.mdet.mise.toml; - J'effectue des changements dans le repository
frontend, je commit ; - Je pull les changements du repository
frontendversmonorepo; - Dans
monorepo, j'effectue des changements dans le dossierfrontend/, je commit ; - J'utilise
cd frontend/; git format-patch --relative -1 HEADpour générer un patch qui contient les changements que j'ai effectués dans le dossierfrontend/; - Je vais dans le repository
frontendet j'applique les changements contenus dans ce patch avec la commandgit apply monpatch.patchou avecgit am monptach.patch.
Pour le moment, j'ai privilégié l'option git patch, parce que je souhaite suivre la méthode la plus "manuelle" que j'ai pu trouver lorsque je dois intervenir sur les repositories upstream, parce que je ne veux prendre aucun risque de perturber mes collègues avec mon initiative de monorepo.
Le repository GitHub suivant contient le résultat final du monorepo : https://github.com/stephane-klein/poc-git-monorepo-multirepos-sync-result-example/.
Est-ce que je suis satisfait du résultat de cette démo ?
La réponse est oui, bien que je ne sois pas satisfait de quelques éléments.
Par exemple, les fichiers de frontend présents dans ce commit ne sont pas dans le dossier frontend.
J'aimerais que ces titres de commits contiennent un prefix [frontend] ... et [backend].... Je pense que cela doit être possible à implémenter en modifiant le script tomono.
Est-ce que c'est pénible à utiliser ? Pour le moment, ma réponse est « je ne sais pas ».
Je vais tester cette méthode avec deux projets. Je pense écrire une note de bilan de cette expérience d'ici à quelques semaines.
Journal du samedi 07 décembre 2024 à 19:04
En travaillant sur Projet 19, #JaiDécouvert le projet git-branchless (https://github.com/arxanas/git-branchless).
High-velocity, monorepo-scale workflow for Git.
Je n'ai pas encore compris à quoi cela sert.
Journal du mercredi 02 octobre 2024 à 10:04
#JaiDécouvert Sourcebot (from) :
Sourcebot is an open-source code search tool that allows you to quickly search across many large codebases.
C'est une alternative à Sourcegraph.
Je suis ravi de voir qu'il existe de plus en plus d'alternatives communautaires à GitHub ou GitLab, comme Forgejo, Weblate, Woodpecker CI et maintenant Sourcebot.
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Journal du mercredi 21 août 2024 à 09:39
Après avoir rédigé la note Commit Cavalier, #JaiDécouvert le concept de des projets de loi omnibus.
« Depuis les années 1980, cependant, les projets de loi omnibus sont devenus plus courants : ces projets de loi contiennent des dispositions, parfois importantes, sur un éventail de domaines politiques. »
-- from
Ceci m'a fait penser aux Merge Requests qui contiennent de nombreux petits commits, souvent de refactoring, qu'il serait fastidieux de passer en revue individuellement.
Je pense que je vais nommer ces Merge Request, des Merge Request Omnibus, ce néologisme sera une de mes marques idiosyncrasiques 😉.
J'ai donc décidé de baptiser ces Merge Requests des Merge Requests Omnibus. Ce néologisme deviendra l'une de mes marques idiosyncrasiques 😉.
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
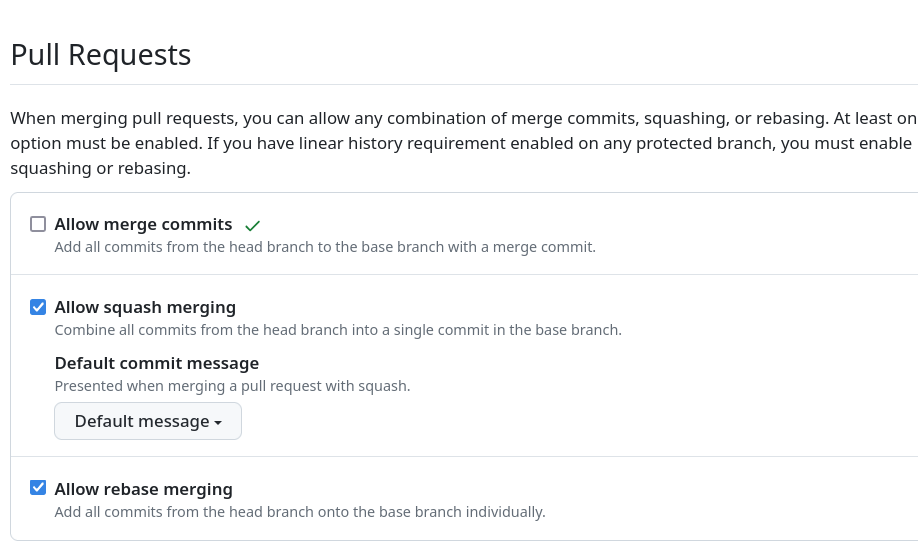
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
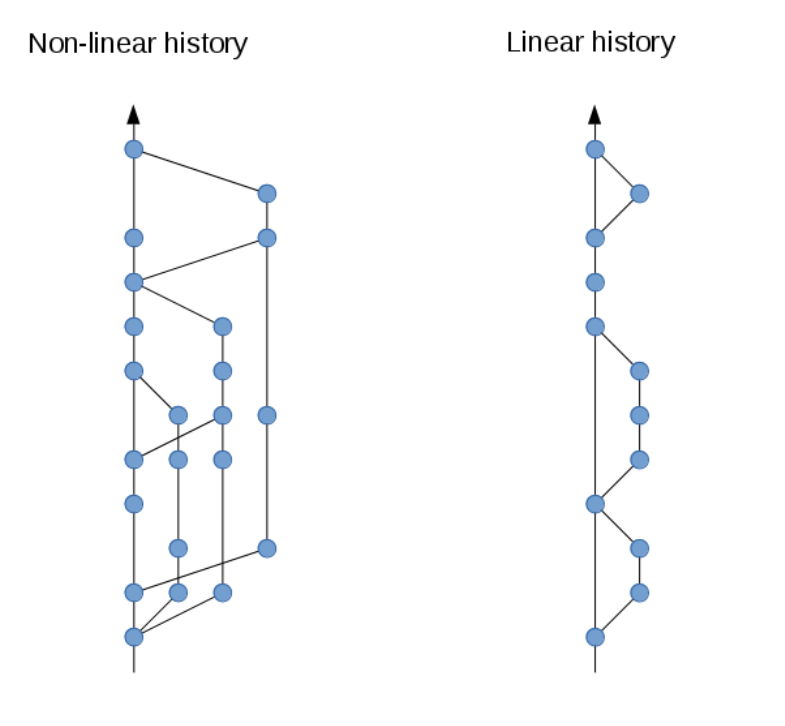
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.
Journal du mardi 20 août 2024 à 17:37
#JaiDécouvert un article très intéressant qui répertorie les difficultés classiques rencontrées par les développeurs avec git rebase, ainsi que des solutions pour y remédier :git rebase: what can go wrong?.
Journal du mardi 20 août 2024 à 17:27
#JaiDécouvert ce guide pour Git : Flight rules for Git.
Je le trouve excellent 👌.
Et voici une autre article intéressant au sujet de Git rebase : git rebase in depth.
Journal du jeudi 16 mai 2024 à 09:36
Article que je trouve intéressant au sujet du le découpage des commit #git When to split patches for PostgreSQL | Peter Eisentraut
Journal du mardi 15 janvier 2019 à 15:22
Ce mois de janvier est riche en article au sujet des Monorepo !
#JaiLu le contre pied du l'article "Monorepos: Please don’t" : Monorepo: please do! !
As a leader, I’ll pick the monorepo every time: because tools must reinforce the culture I want, and culture comes from the tiny decisions and behaviors of a team every day.
👌
Son thread Hacker News : 161 commentaires.
Journal du mardi 08 janvier 2019 à 17:28
#JaiLu ce thread Hacker News au sujet des Monorepo : "Monorepos and the Fallacy of Scale | Hacker News".
J'ai trouvé l'article très intéressant ainsi que les commentaires.
Journal du jeudi 03 janvier 2019 à 15:13
#JaiLu ce thread Hacker News au sujet des Monorepo : "Monorepos: Please don’t".
Il contient de très bons commentaires biens argumentés qui expliquent les avantages des Monorepo, j'ai trouvé cela passionnant 🙂.
Journal du mercredi 17 octobre 2018 à 16:06
#JaiDécouvert le site "Advantages of monorepos" (https://danluu.com/monorepo/).
Avantages :
- « Simplified organization » 👌
- « Simplified dependency management » 👌
- « atomic changes » 👌
- « Extensive code sharing and reuse » 👌
- « Unified versioning, one source of truth » 👌
- « Code visibility and clear tree structure providing implicit team namespacing » 👌
- « Large-scale refactoring » 👌
- « Collaboration across teams » 👌
Journal du mardi 12 décembre 2017 à 10:29
J'ai été perturbé par le contenu des slides « Monolithic repositories vs. Many repositories » de Fabien Potencier : https://speakerdeck.com/fabpot/a-monorepo-vs-manyrepos (voir 2017-12-03_1217).
J'ai continué à étudier le sujet des Monorepo et j'ai commencé à migrer un side project vers ce pattern. Pour le moment, l'expérience est très agréable. Je pense que je vais continuer dans cette direction.
Ma définition dans 2024-08-20_2326.
Date de la création de cette note : 6 décembre 2024.
Quel est l'objectif de ce projet ?
En décembre 2017, convaincu par les avantages du modèle Monorepo, j'ai effectué un véritable changement de paradigme en abandonnant le modèle Multirepos.
Depuis, je n'ai eu aucun regret. J'utilise le modèle Monorepo dans tous mes projets, car il simplifie énormément la plutpart des workflow, notamment l'onboarding, grâce à des kits de développement simplifiés.
Cependant, le modèle Multirepos est très populaire, je le rencontre partout où j'interviens.
Cela me perturbe beaucoup, car je constate à chaque fois que ce modèle complique tout. L'onboarding, le flux de travail, de déploiement, la documentation…
L'objectif de ce projet est de documenter une méthode et des outils qui me permettent de maintenir en douceur, sans rien imposer, un monorepo qui contient un development kit de qualité, agréable à utiliser.
Je souhaite pouvoir travailler dans ce monorepo tout en envoyant mon travail dans des branches sur les multi repositories d'origine.
Je souhaite aussi pouvoir pull les changements des multi repositories vers mon monorepo.
Ces deux user stories me permettront d'améliorer le monorepo sans modifier le workflow de développement des autres membres de l'équipe.
Une fois le kit de développement du monorepo opérationnel, je pourrai présenter ce projet à l'équipe pour leur en montrer le fonctionnement, les avantages, ainsi que sa simplicité d'utilisation et d'onboarding.
Au final, il reviendra à l'équipe de décider si elle souhaite adopter ce paradigme ou non.
Repository de ce projet :
Ressources :
Voir aussi Monorepo.
Voir aussi Multirepos.
Voir aussi Pull Request utilisé par GitHub.
Dépôt GitHub : https://github.com/gitext-rs/git-stack
Thread à sujet de git-stack sur Lobster : https://lobste.rs/s/4zjln3/praise_stacked_prs
Dépôt GitHub : https://github.com/arxanas/git-branchless
Dépôt GitHub : https://github.com/gitbutlerapp/gitbutler
Site officiel : https://pre-commit.com
Site officiel : https://gitolite.com/gitolite/index.html
Dépôt GitHub : https://github.com/gabrielcsapo/node-git-server
Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push"
Date de la création de cette note : 2025-08-23.
Quel est l'objectif de ce projet ?
Mon objectif est de développer un POC d'un serveur Git capable de :
- Gérer les opérations push et pull d'un repository Git via HTTP
- Déclencher automatiquement un script lors d'un push sur une branche
Voir aussi la suite de ce projet : Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch".
Pourquoi je souhaite réaliser ce projet ?
Je souhaite intégrer les apprentissages de ce POC dans le projet sklein-pkm-engine pour éliminer la dépendance à import-to-es-database.js.
L'idée est de permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement par git push, sans rien avoir à installer sur ma workstation.
Je souhaite aussi utiliser à l'avenir la technique mise au point dans ce POC dans le Projet 24 - Prototyper le gestionnaire de projet de mes rêves.
Par le passé, entre 2014 et 2016, j'ai déjà réalisé un projet de ce type, dans mon ancien projet CmsHub. J'avais utilisé dans un premier temps Gitolite et par la suite git2go.
Pour le moment, je n'ai aucune idée de comment je vais implémenter ce POC.
Todo :
- [x] Implémenter un serveur Git HTTP minimaliste en NodeJS
- [x] Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. (voir commit) - [x] Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server
Repository de ce projet :
- https://github.com/stephane-klein/node-git-http-server
- https://github.com/stephane-klein/poc-node-git-server-in-sveltekit
Notes
Ressources :
Dépôt GitHub : https://github.com/libgit2/git2go
Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Date de la création de cette note : 2025-08-29.
Quel est l'objectif de ce projet ?
Mon objectif est de développer un POC d'un serveur Git capable d'injecter du contenu dans une base de données OpenSearch. Cette base de données pourra ensuite être utilisée comme un content repository.
Ce projet aura comme base le résultat du projet 32 : poc-node-git-server-in-sveltekit
Quelques détails d'implémentation du projet :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Potentiels futurs projets basés sur ce POC :
- Implémentation d'un web frontend en SvelteKit qui s'occupe du rendu des données du content repository via des requêtes OpenSearch.
- Implémentation d'un web frontend en Astro qui s'occupe du rendu des données du content repository via des requêtes OpenSearch.
- Explorer comment TinaCMS pourrait s'intégrer dans ce système.
Pourquoi je souhaite réaliser ce projet ?
Je considère ce projet comme l'étape suivante du projet 32 et donc il a le même objectif, c'est-à-dire, intégrer les apprentissages de ce POC dans le projet sklein-pkm-engine pour éliminer la dépendance à import-to-es-database.js.
L'idée est de permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement par git push, sans rien avoir à installer sur ma workstation.
Je souhaite aussi utiliser à l'avenir la technique mise au point dans ce POC dans le Projet 24 - Prototyper le gestionnaire de projet de mes rêves.
Repository de ce projet :
Ressources :
Dépôt GitHub : https://github.com/dandavison/delta
Dépôt GitHub : https://github.com/NeogitOrg/neogit
Voir aussi : Fugitive.
Dépôt GitHub : https://github.com/dolthub/dolt
Dépôt GitHub : https://github.com/dolthub/doltgresql
Dernière page.