
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (10 notes) :
Ma lutte contre mon affaiblissement cognitif
#JaiLu cet excellent billet de Tristan Nitot qui traite du processus de prolétarisation : L'IA fait elle de nous des prolétaires ?.
Il rejoint totalement ce que je disais dans ma note : J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes.
Cela pose la question de la façon dont on aborde l’IA : peut-on profiter de l’IA sans y laisser son intelligence ?
À cette question, ma réponse imparfaite est celle-ci : j'essaie d'utiliser, autant que possible, les IA générative de texte comme un ami expert d'un domaine. J'essaie de ne jamais lui faire faire mon travail à ma place.
J'essaie de résister à l'injonction néolibérale d'effectuer chaque tâche le plus rapidement possible au nom de la rentabilité immédiate. Pour cela, tous les jours, j'essaie de trouver un équilibre entre la vitesse et prendre le temps de comprendre, de maîtriser les concepts et d'exécuter les gestes techniques. C'est loin d'être facile !
Pour lutter contre mon affaiblissement cognitif, j'essaie depuis quelques semaines d'intégrer Anki dans mes habitudes quotidiennes.
Mon objectif : créer une carte-mémoire pour chaque tâche que je délègue à un LLM alors que je devrais pouvoir l'accomplir moi-même.
Pour le moment, je n'ai pas la discipline pour respecter cet objectif, mais j'y travaille.
J'ai bien conscience que ma pratique est hétérodoxe. J'observe autour de moi que la tendance est la course à l'automatisation du maximum de tâches par l'IA. Je souhaite rester un artisan.
#JaiLu aussi le billet "Prolétarisation" de Carnets de La Grange.
Divers types d'issues, une issue Vision ou Epic est floue, une issue task est précise
En mars 2024, je me suis demandé comment utiliser correctement les termes Epic, issue, User Story, Goal, Job Story, Vision, Pitch, Feature, Task, Bug, Spike, Dette technique, Theme.
Voici quelques réflexions à ce propos.
Tout d'abord, tous les artefacts suivants sont des Issues : Epic, User Story, Job Story, Vision, Pitch, Feature, Bug, Spike, Task.
Ensuite, Feature, Bug, Spike et Dette technique indiquent la finalité de l'issue, définissant la nature du travail à réaliser.
User Story et Job Story sont des méthodes de formulation d'issues.
J'ai mis beaucoup de temps à réaliser que les termes Epic, Vision, Theme, Pitch, Goal et Task permettent d'indiquer le niveau d'imprécision d'un objectif.
Exemple allant du flou très prononcé à une version faiblement floue :
- Vision – Le niveau le plus large et abstrait, décrivant une aspiration à long terme.
- Theme – Une direction stratégique regroupant plusieurs objectifs ou Epics.
- Pitch – Une proposition d'idée ou une justification d'un projet, pouvant inclure des objectifs mais restant plus conceptuel.
- Goal – Un objectif spécifique à atteindre, souvent mesurable.
- Epic – Une grande fonctionnalité ou un ensemble de tâches qui contribuent à un objectif plus large.
- Task – Niveau le plus précis, une tâche est une unité de travail concrète et actionnable.
Une ou plusieurs Merge Requests constituent une réponse formelle, exprimée en code, parmi toutes les réponses possibles à une demande formulée dans une issue.
Seule cette réponse formelle, exprimée en code, est véritablement précise. Même l'issue, aussi détaillée soit-elle, conserve toujours une part de flou.
Attention tout de même : quand je dis qu'une issue de type Vision est floue, cela ne veut pas dire que son auteur peut bâcler sa rédaction.
Si, par exemple, la description est limitée à 500 mots, l'auteur doit exploiter au mieux cette limite pour présenter sa vision avec précision. L'objectif n'est pas de créer du flou volontairement, mais plutôt d'exprimer clairement un concept qui, par nature, comporte encore des zones d'incertitude à explorer.
Voici quelques exemples d'issue floue publiés ici :
Une issue, en tant que texte écrit, comporte une part inévitable d'ambiguïté et nécessite donc son auteur pour être défendue :
C’est que l’écriture, Phèdre, a, tout comme la peinture, un grave inconvénient. Les œuvres picturales paraissent comme vivantes ; mais, si tu les interroges, elles gardent un vénérable silence. Il en est de même des discours écrits. Tu croirais certes qu’ils parlent comme des personnes sensées ; mais, si tu veux leur demander de t’expliquer ce qu’ils disent, ils te répondent toujours la même chose. Une fois écrit, tout discours roule de tous côtés ; il tombe aussi bien chez ceux qui le comprennent que chez ceux pour lesquels il est sans intérêt ; il ne sait point à qui il faut parler, ni avec qui il est bon de se taire. S’il se voit méprisé ou injustement injurié, il a toujours besoin du secours de son père, car il n’est pas par lui-même capable de se défendre ni de se secourir.
Conséquence pratique de tout cela :
- L'auteur d'une issue doit être disponible et accorder du temps à la personne qui va implémenter son issue.
- La personne qui implémente cette issue doit accepter l'imprécision de cette issue. En posant des questions, le développeur doit aider l'auteur à rendre cette issue plus précise.
- L'auteur de l'issue doit accepter de recevoir une implémentation qui ne correspond pas exactement à sa vision… et dans ce cas, il doit soit l'accepter ou accorder plus de temps à cette issue afin d'effectuer plusieurs itérations de correction de l'implémentation.
Ces règles pratiques sont aussi valables lorsqu'une issue est déclinée dans des issues avec un niveau de précision supérieur. Par exemple, lors de la rédaction d'issues de type Epic à partir d'une issue de type Vision.
« Permettre à l'auteur de défendre son texte » ne signifie pas exclusivement un dialogue oral. Ce dialogue peut s'effectuer :
- Par chat synchrone ;
- Par commentaire d'issue asynchrone ;
- Par visioconférence ;
- etc
Je pense que le niveau de précision d'une issue détermine le mode de communication à privilégier. Pour les issues de haut niveau d'abstraction — très floues (Vision, Theme, Pitch), la communication orale se révèle généralement plus efficace, car elle permet des échanges dynamiques et immédiats sur des concepts abstraits.
En revanche, pour les issues plus précises (Tasks, certaines Features), je privilégie une approche asynchrone avec des questions écrites détaillées. Cette méthode offre à l'auteur le temps nécessaire pour réfléchir et affiner sa rédaction. Je ne recours à la communication orale que lorsque des problèmes de compréhension persistent malgré les échanges écrits, afin de débloquer rapidement la situation.
Je cherche des solutions pour bien indiquer le niveau de précision des issues que j'écris.
Voici quelques exemples d'introductions d'issues :
Cette issue est de type "vision", c'est donc normal qu'elle soit imprécise. Les zones d'ombre seront affinées progressivement dans des sous-issues spécifiques. Pour clarifier certains aspects, des échanges oraux pourront être organisés afin de répondre à vos questions et d'enrichir cette vision.
Autre exemple :
Cette issue a été rédigée avec un souci particulier de précision. Si vous identifiez des erreurs, des incohérences ou si certains points nécessitent des éclaircissements, n'hésitez pas à les signaler dans les commentaires. Pour toute difficulté de compréhension ou doute persistant, je reste disponible pour organiser une session en visioconférence afin de faciliter nos échanges.
La fonctionnalité "Activité" de GitLab me manque dans GitHub
La fonctionnalité "Activité" de GitLab me manque dans GitHub.
Voici trois exemples concrets de fonctionnement de cette fonctionnalité, dans trois contextes différents.
Le premier, dans le projet GNOME Shell :
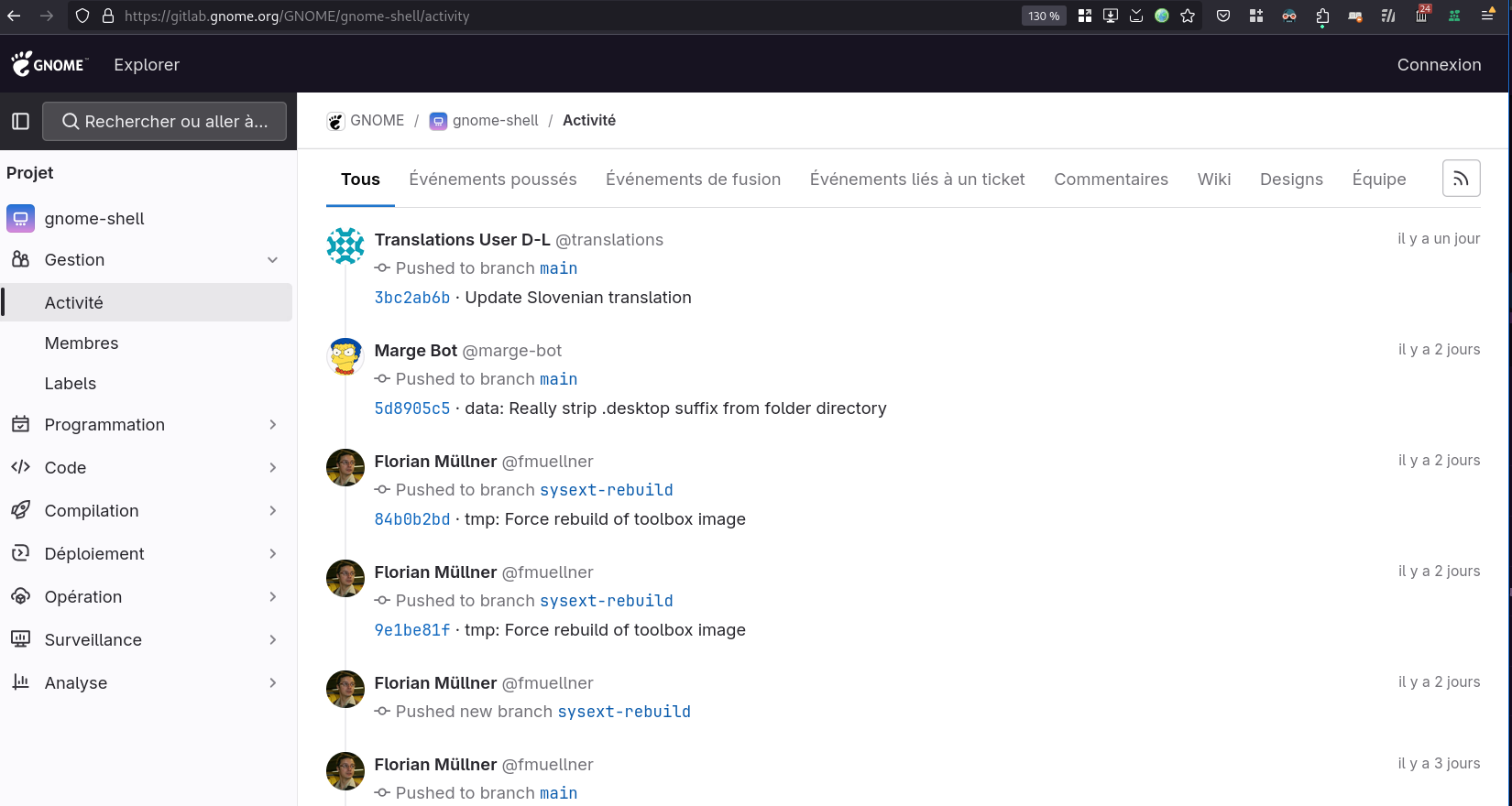
Le second, dans le groupe Wayland : https://gitlab.freedesktop.org/groups/wayland/-/activity
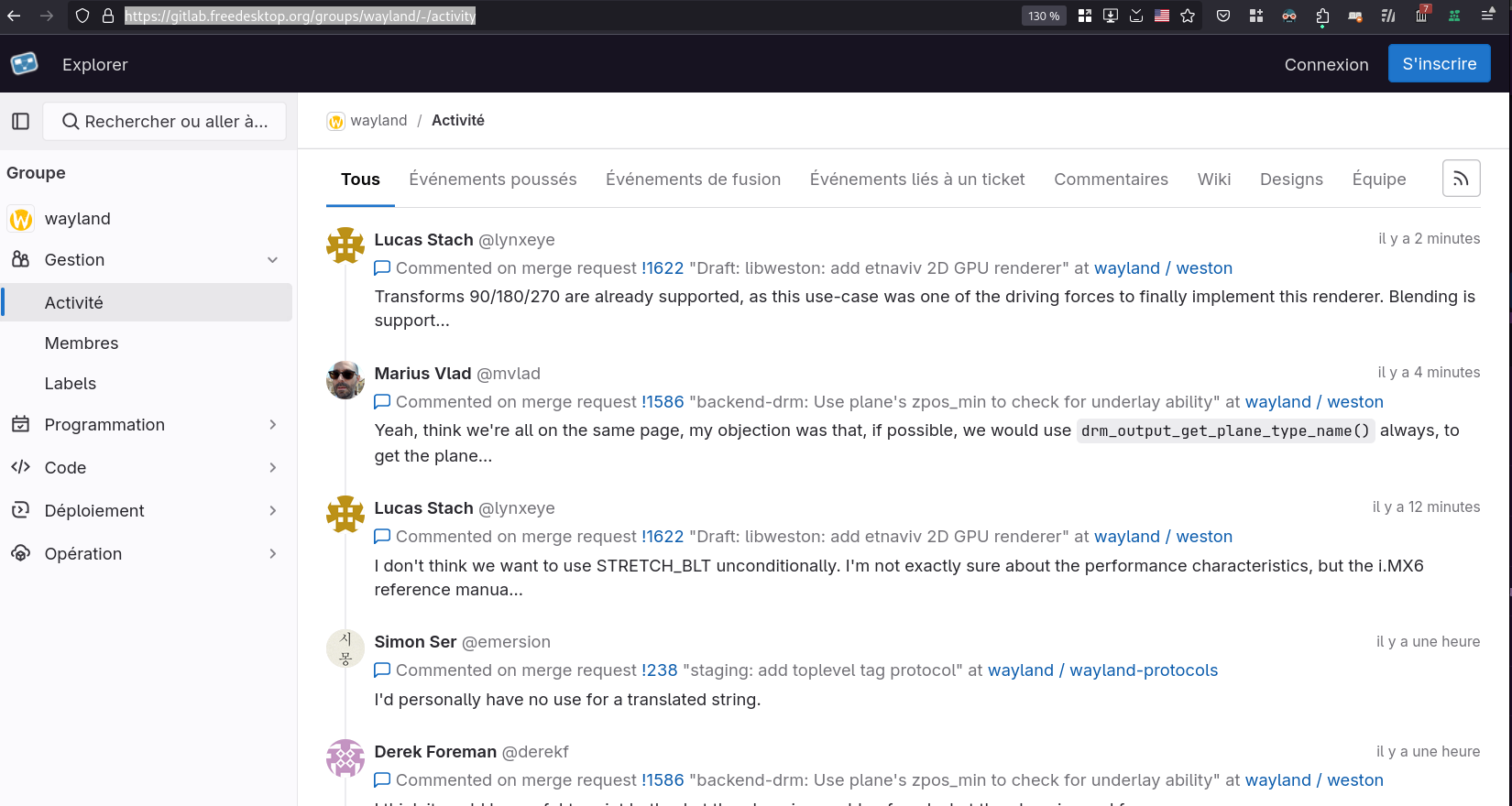
Et le troisième, pour l'utilisateur Lucas Stach: https://gitlab.freedesktop.org/users/lynxeye/activity
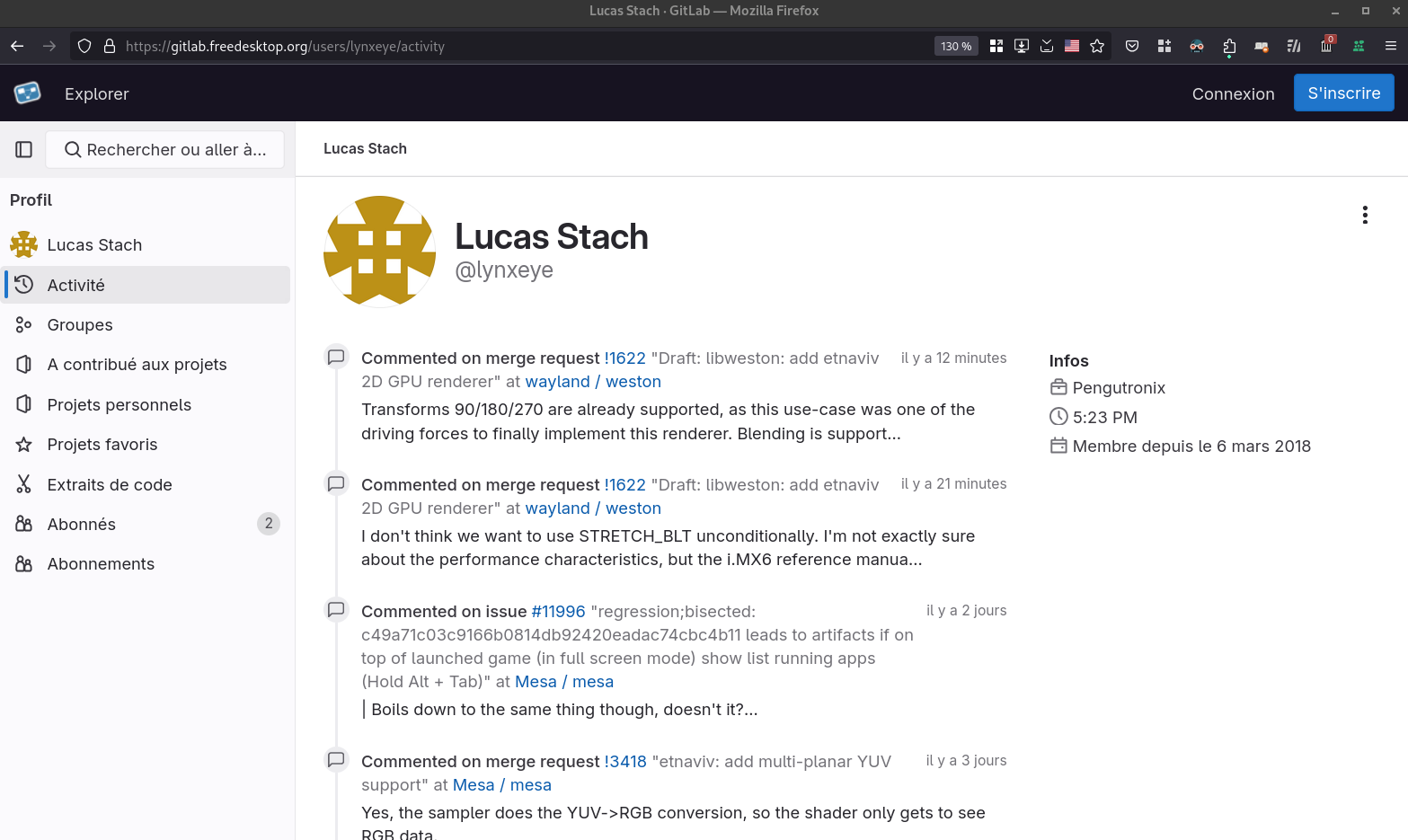
Je trouve cette fonctionnalité très utile quand on travaille sur un projet. Elle permet d'avoir une vue d'ensemble de ce qui s'est passé sur un projet sur une période. Elle vient en complément de l'historique Git qui est limité aux changements effectués sur le code source.
Dans certaines situations, je sais qu'un collègue travaille sur un sujet qui me concerne et la fonctionnalité "Activité" me permet de mieux comprendre où il en est, de suivre facilement ce qu'il fait.
Cette fonctionnalité "Activité" permet de pratiquer la stigmergie.
J'utilise aussi cette fonctionnalité lors de la rédaction d'un rapport d'activité ou d'un message de Daily Scrum. Elle m'aide à retrouver précisément ce que j'ai fait dernièrement.
Je trouve la page "Contribution activity" d'un user GitHub limité, par exemple, elle ne contient pas l'historique des commentaires.
Même chose au niveau d'un projet, dans la page "Pulse", par exemple : https://github.com/sveltejs/kit/pulse.
Je viens de regarder du côté de Codeberg / Forgejo : <https://codeberg.org/forgejo/forgejo/activity. Même constat que pour GitHub, les informations sont très réduites.
Journal du vendredi 22 novembre 2024 à 17:03
Je découvre une nouvelle limitation de Hasura par rapport à PostGraphile.
Hasura permet d'exécuter des fonctions PostgreSQL seulement si leur type de retour est une table. De plus, cette table doit être tracked par Hasura.
Return type: MUST be
SETOF <table-name>OR<table-name>where<table-name>is already tracked.Return type workaround: If the required SETOF table doesn't already exist or your function needs to return a custom type i.e. row set, you can create and track an empty table with the required schema to support the function.
-- from
D'autre part, Hasura doit avoir des permissions d'accès à cette table utilisée en retour de fonction.
Par exemple, Hasura ne supporte pas ce type de configuration :
REVOKE ALL PRIVILEGES ON TABLE foobar FROM hasurauser;
CREATE FUNCTION myfunction() RETURNS SETOF foobar
LANGUAGE sql VOLATILE SECURITY DEFINER
AS $$
SELECT * FROM foobar
$$;
Cette limitation, parmi d'autres, renforce ma préférence pour PostGraphile plutôt que Hasura dans un contexte d'utilisation avec PostgreSQL — PostGraphile supporte uniquement PostgreSQL.
Pourquoi le badge Website Carbon me dérange ?
Je viens de voir à nouveau un badge Website Carbon Calculator sur un site.

Ce type d'initiative me dérange, parce que je considère la méthode de calcul comme non rigoureuse.
Quelques exemples :
- Elle semble ne pas prendre en compte la consommation du device côté client (smartphone, desktop…) ;
- Elle semble ne pas prendre en compte la charge cotée serveur.
Je pense que les personnes qui intègrent ce type de badge sur leur site sont dans une démarche de Greenwashing. Je pense qu'elles ne maitrisent pas le sujet.
Le projet Lighthouse est bien plus honnête dans sa démarche. N'étant pas en mesure de donner des mesures rigoureuses, il semble avoir abandonné ce projet : 🍃 adding environment protection KPI and audits (like CO2 footprint)
Pour fournir une information plus rigoureuse, je pense qu'il serait possible d'agréger les statistiques de consommation via PowerTOP de tous les serveurs qui servent à héberger le site web, croiser cette information avec les statistiques de visites tout en prenant en compte les caractéristiques énergétiques du data center.
Mais, tout cela est très compliqué.
En attendant, je pense qu'il est bien plus honnête de simplement intégrer un badge Lighthouse qui prends en compte les paramètres suivants :
- la taille de la page et de ses dépendances ;
- la complexité de rendu de la page.
Plus la note Lighthouse est élevée, moins le site web consomme d'énergie, à conditions égales.
Exemple : https://sklein.xyz/reports/report.html
Voir aussi : co2.js.
Journal du lundi 19 août 2024 à 15:52
#Jadore le projet shadcn-svelte. Je trouve l'expérience développeur (DX) excellente ❤️.
Journal du samedi 17 août 2024 à 14:50
Depuis le début des années 2000, j'éprouve une certaine aversion dès que je suis confronté à une technologie basée sur Java. Pourquoi ? Parce que, à tort ou à raison, j'ai remarqué que les applications Java sont souvent très longues à démarrer et consomment une quantité excessive de RAM.
Je pense par exemple à Logstash, dont la lenteur était insupportable, que j'ai fini par remplacer d'abord par Fluentd, puis par Vector.
Je pense également à Eclipse IDE.
Et bien sûr, aux serveurs Jakarta EE.
Journal du lundi 12 août 2024 à 11:04
Voici un extrait de l'article Turbo 8 is dropping TypeScript de David Heinemeier Hansson (DHH de Basecamp) :
This isn't a plea to convert anyone of anything, though. As I discussed in Programming types and mindsets, very few programmers are typically interested in having their opinion on typing changed. Most programmers find themselves drawn strongly to typing or not quite early in their career, and then spend the rest of it rationalizing The Correct Choice to themselves and others.
Je trouve ce point de vue intéressant.
Voir aussi : TypeScript
Pourquoi j'apprécie le framework SvelteKit ?
La partie que je préfère de plus dans le framework SvelteKit ce sont les fonctionnalités décrient dans la section Routing et Advanced routing de la documentation de SvelteKit.
Si vous survolez ces pages de documentation, vous allez peut-être me poser la question « ok et alors, c'est quoi le truc cool ? ». Je ne vais pas vous répondre maintenant, parce que c'est intégralité de ces deux pages de documentations qui faut lire avec une très grande attention. En utilisant SvelteKit dans plusieurs projets, j'ai appris à découvrir toutes les petites subtilités du système de rooting de SvelteKit.
#JaimeraisUnJour prendre le temps de paraphraser avec mes mots cette documentation pour partager avec vous l'enthousiasme que j'ai à l'égard de SvelteKit.
Est-ce que Nuxt ou NextJS sont moins élégants que SvelteKit ? Pour le moment, je ne sais pas, je n'ai pas pris assez de temps pour pousser assez loin la comparaison. C'est l'objectif de Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit".
Journal du lundi 25 mars 2024 à 20:00
Après 11 mois de procrastination, j'ai enfin pris le temps de faire ce script https://github.com/stephane-klein/toggl-report-helper-script
Au départ, j'hésitais entre une implémentation en Python ou en JavaScript. J'ai finalement opté pour JavaScript, car cela correspond à ma nouvelle doctrine.
Même si Python reste le langage que j'affectionne profondément, que je trouve toujours aussi élégant, j'ai pris la décision de me consacrer pleinement à JavaScript.
Dernière page.