
PostgreSQL
Quelques notes au sujet de PostgreSQL :
Ressource :
Journaux liées à cette note :
Certification HDS : ce que j'ai appris en creusant pour un ami
Un ami, professionnel libéral de santé, a vibe codé une application de gestion pour ses patients actuellement hébergée sur Supabase. Il souhaite migrer vers un Hébergeur de Données de Santé — il a notamment vu que Scaleway propose des services certifiés HDS — et m'a demandé si je connaissais un développeur pour l'accompagner dans ce projet.
J'ai croisé la notion de HDS pour la première fois en 2016, chez Tech-Angels. Depuis, j'ai suivi le sujet de loin sans jamais creuser.
Je profite de sa demande pour étudier le sujet en profondeur avant de lui répondre, et publier une note de ce que j'aurai appris.
Hébergeur de Données de Santé, c'est quoi ?
Toute personne physique ou morale qui héberge des données de santé à caractère personnel recueillies à l’occasion d’activités de prévention, de diagnostic, de soins ou de suivi médico-social pour le compte de personnes physiques ou morales à l'origine de la production ou du recueil de ces données ou pour le compte du patient lui-même, doit être agréée ou certifiée à cet effet.
Texte de loi : article L.1111-8 du Code de la santé publique
Qu'est-ce qu'une donnée de santé (DDS) ?
Avant d'aller plus loin, j'ai eu besoin de comprendre précisément ce qu'est une "donnée de santé".
La CNIL distingue trois catégories (source) :
- Les données de santé par nature : antécédents médicaux, diagnostics, traitements, résultats d'examens, ordonnances, comptes-rendus d'hospitalisation.
- Les données qui deviennent des données de santé par croisement : le poids ou le nombre de pas seuls ne le sont pas, mais croisés avec d'autres mesures (tension artérielle, apports caloriques), ils le deviennent.
- Les données qui deviennent des données de santé par leur usage : un rendez-vous chez un médecin, à lui seul, n'est pas une donnée de santé — mais le motif de la consultation, si.
Concrètement, dans l'application de mon ami, cela inclut probablement les noms des patients, leurs comptes-rendus, leurs ordonnances, les notes de suivi, et potentiellement les créneaux de rendez-vous liés à des actes de soins. Ce n'est pas seulement la « base médicale » au sens strict — c'est tout ce qui, relié à une personne identifiée, révèle qu'elle a reçu ou consulté pour des soins.
Un document médical sans identifiant, est-ce encore une donnée de santé ?
Une question qui m'est tout de suite venue à l'esprit : un document médical sans identifiant — pas de nom, pas de numéro de patient — est-ce encore une donnée de santé ?
La réponse dépend de la possibilité de ré-identification. Si le document est véritablement anonymisé, qu'il n'existe aucun moyen raisonnable de le relier à une personne, alors ce n'est plus une donnée de santé à caractère personnel — ça sort du périmètre du RGPD et du HDS.
Mais en pratique, c'est très difficile de le rendre vraiment anonyme. Un diagnostic rare, une date de traitement, ou un hôpital spécifique croisés avec d'autres sources, peuvent permettre de ré-identifier la personne.
La CNIL considère qu'une donnée est « personnelle » dès qu'il existe des « moyens raisonnablement susceptibles » de ré-identification.
Je pense qu'une bonne méthode pour estimer si c'est une DDS ou non, est de se mettre dans la peau d'un détective privé : si on me donnait ce document et tous les indices disponibles (date, hôpital, pathologie rare…), est-ce que je pourrais remonter à la personne ? Si la réponse est oui, c'est une donnée de santé. La question n'est donc pas « y a-t-il un nom dans le document ? » mais « quelqu'un, avec les moyens raisonnables, pourrait-il retrouver à qui ça appartient ? ».
Quels liens entre PII et DDS ?
Pour faire le lien avec les PII : toute Données de santé (DDS) est une PII, mais l'inverse n'est pas vrai. Un nom, une adresse email ou une adresse IP sont des PII parce qu'ils permettent d'identifier une personne.
Une donnée de santé est une PII qui révèle en plus quelque chose sur l'état de santé de cette personne. La distinction importe parce que le régime juridique n'est pas le même : les DDS sont soumises au RGPD comme les PII, mais avec des protections supplémentaires — secret médical, consentement explicite, obligation d'hébergement certifié HDS.
Qui est le "responsable de traitement" ?
Pour comprendre à qui s'applique la certification HDS, j'ai eu besoin de creuser la notion de "responsable de traitement" au sens du RGPD. Je croise ce terme régulièrement, je pense le comprendre dans les grandes lignes, mais j'ai voulu comprendre précisément où se situent les frontières.
D'après ce que j'ai compris, le responsable de traitement est la personne morale (ou la personne physique en entreprise individuelle) qui décide quoi faire avec les données personnelles. C'est elle qui détermine pourquoi on collecte les données et comment on les traite. Ce n'est pas l'individu (le médecin, l'infirmière) — c'est la structure juridique qui a la relation de soin avec le patient.
Concrètement :
| Situation | Responsable de traitement | Pourquoi ? |
|---|---|---|
| Médecin salarié à l'hôpital | L'hôpital (personne morale) | C'est l'hôpital qui a la relation avec le patient, pas le médecin individuellement |
| Médecin dans un cabinet en SARL | La SARL (personne morale) | C'est la SARL qui signe les contrats et est responsable en cas de fuite |
| Médecin libéral en entreprise individuelle | Le médecin (personne physique) | Il n'y a pas de structure intermédiaire |
| Cabinet médical | Le cabinet (personne morale) | Le cabinet détermine les règles de gestion du système d'information |
| Doctolib | Non — c'est un sous-traitant | Doctolib est un moyen de communication entre le médecin et le patient, comme un téléphone amélioré |
| Scaleway | Non — c'est un hébergeur | Scaleway fournit l'infrastructure, il ne traite pas les données pour ses propres fins |
| Un développeur freelance qui maintient le serveur | Non — c'est un sous-traitant | Il administre l'infrastructure pour le compte du responsable de traitement |
Cette distinction est cruciale pour comprendre la certification HDS. La loi dit que l'hébergement doit être certifié quand il est fait "pour le compte de" un responsable de traitement. Si tu es toi-même le responsable de traitement, tu n'héberges pas pour un tiers — tu héberges pour toi-même alors pas besoin de certification HDS (mais tu restes soumis au RGPD).
C'est pour ça qu'un médecin qui gère son propre dossier patient n'a pas besoin de HDS, mais qu'un hébergeur qui stocke les données pour le compte de ce médecin doit être certifié.
Un cas limite : les services médicaux numériques
Le cas des services médicaux numériques comme Poppins — "le dispositif médical numérique à domicile pour les enfants dyslexiques" — est compliqué. Qui est le responsable de traitement ?
La réponse dépend de qui décide quoi faire avec les données :
- Si Poppins décide quelles données collecter et comment les utiliser (recherche, amélioration du produit) alors Poppins est responsable de traitement
- Si l'orthophoniste décide quelles données utiliser pour le suivi du patient alors l'orthophoniste est responsable de traitement
- Si les deux ont un rôle de décision → co-responsabilité (article 26 RGPD)
Où est la documentation officielle HDS ?
La documentation officielle est trouvable sur le site https://esante.gouv.fr/ => "Produits et services" => "HDS" => "Les référentiels de la procédure de certification".
La documentation HDS est nommée "référentiel de certifications HDS", elle est disponible au format PDF à cette adresse https://esante.gouv.fr/sites/default/files/media_entity/documents/referentiel_certification_hds---fr--v2.pdf.
Je n'ai pas trouvé de version HTML de ce document.
D'après ce que j'ai compris, ce sont des personnes de l'Agence du Numérique en Santé (ANS) qui ont rédigé les 29 pages du référentiel de certifications HDS.
Ce référentiel a été officialisé dans le Journal Officiel le 16 mai 2024 https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000049537692 par un ministre délégué à la santé. Ce document remplace la version précédente de 2018.
Et voici le communiqué de presse de l'ANS : Publication au Journal Officiel du référentiel de certification HDS : souveraineté des données et améliorations du référentiel.
Je suis ravi de lire la section Focus sur l’ajout d’exigences relatives à la souveraineté des données qui indique :
L’hébergement physique des données de santé doit être réalisé exclusivement sur le territoire d’un pays situé au sein de l’Espace Economique Européen.
🙂
Les 6 activités du référentiel HDS
Est considérée comme une activité d'hébergement de données de santé à caractère personnel sur support numérique ... des activités suivantes :
- La mise à disposition et le maintien en condition opérationnelle de sites physiques permettant d'héberger l'infrastructure matérielle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure matérielle du système d'information utilisé pour le traitement de données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure virtuelle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de la plateforme d'hébergement d'applications du système d'information ;
- L'administration et l'exploitation du système d'information contenant les données de santé ;
- La sauvegarde des données de santé
Cette liste, reformulée en activités concrètes :
| # | Activité |
|---|---|
| 1 | Gestion des sites physiques : datacenters, baies serveurs, climatisation, alimentation électrique, sécurité des locaux |
| 2 | Gestion de l'infrastructure matérielle : serveurs physiques, stockage, câblage réseau, commutation |
| 3 | Gestion de l'infrastructure virtuelle : machines virtuelles, réseaux virtuels, stockage virtuel, hyperviseurs |
| 4 | Gestion de la plateforme applicative : bases de données managées, conteneurs, serveurs d'application |
| 5 | Gestion des sauvegardes : sauvegardes automatisées, stockage hors site, restauration |
| 6 | Administration et exploitation du SI : supervision, mises à jour, gestion des accès, support technique, astreinte |
Il y a un point important que j'ai mis du temps à saisir : l'obligation de certification ne s'applique qu'à l'hébergement de données de santé pour un tiers qui est responsable de traitement.
Par conséquent, un professionnel de santé qui auto-héberge ses propres données n'a pas besoin de certification HDS pour les activités de cette liste qu'il administre lui-même.
Un exemple concret
Imaginons un cabinet de médecin, qui développe une application web qui contient des données de santé. Cette application est à destination de ses utilisateurs finaux, ses patients.
L'application web est codée en JavaScript avec PostgreSQL pour la persistance des données.
Pour le déploiement, le développeur employé directement par le cabinet de médecin fait le choix de déployer le tout sur une Virtual machine Scaleway.
D'après la version du 18 juin 2026 de la page "L’hébergement des données de santé et la certification HDS" de la documentation Scaleway, voici la liste des services certifiés HDS :

Les composants de fondations les plus importants sont bien certifiés. Je note au passage que l'offre "Managed Database for PostgreSQL and MySQL" n'est pas certifiée pour le moment.
Ceci n'est pas grave dans mon exemple si je déploie directement une image Docker de PostgreSQL directement sur la Virtual machine. Les sauvegardes peuvent être déposées dans Scaleway Object Storage qui lui est certifié.
Le cabinet de médecin devra souscrire un plan de support niveau Business à 250 € par mois pour pouvoir ensuite signer un contrat HDS :

Ensuite, Scaleway remettra au cabinet de médecin (son client) un document de garantie HDS, conformément au chapitre 8 du référentiel :
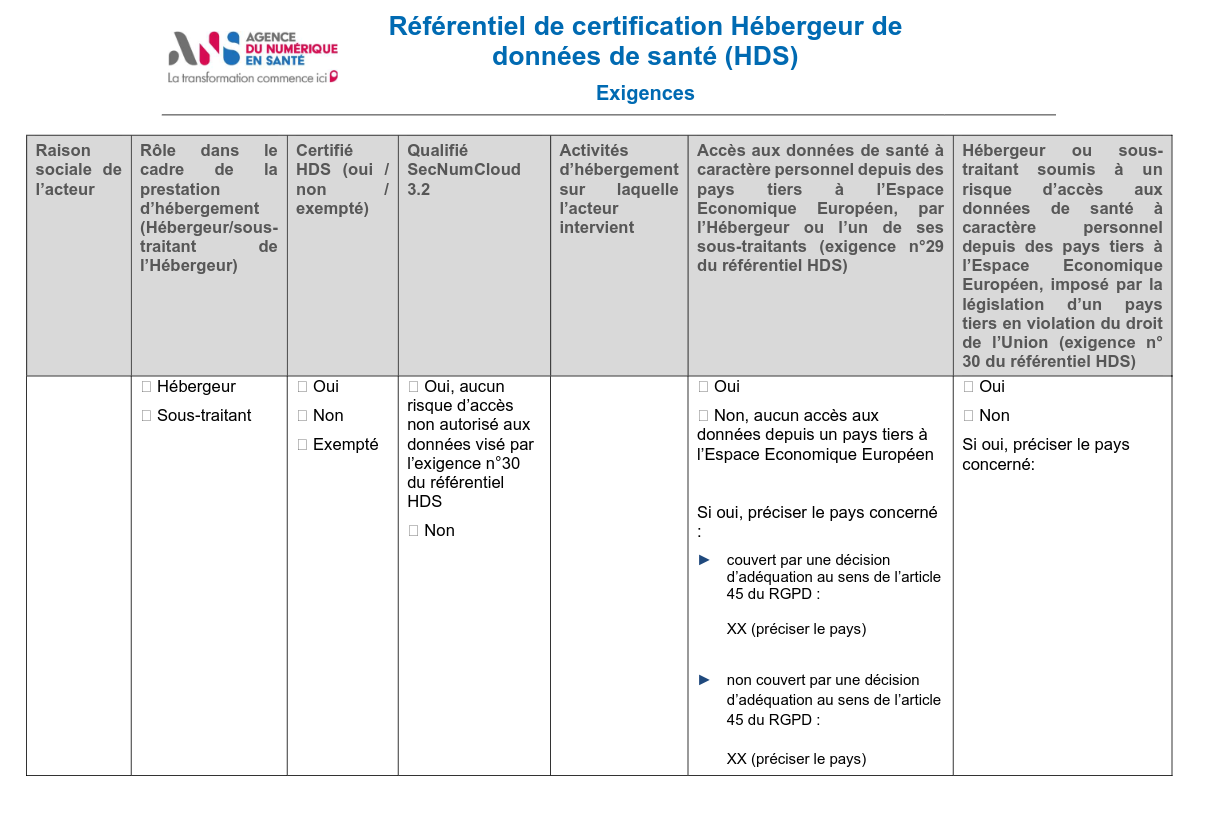
Voici à quoi pourrait ressembler ce document : "Exemple fictif d'une garantie de certification HDS de Scaleway".
Ensuite, les DevOps salariés directement du cabinet de santé déploient, maintiennent, administrent l'application sur les Virtual machine de Scaleway sans que le cabinet de médecin n'ait besoin de certification HDS car il n'est pas un hébergeur de données parce qu'il ne vend pas son service à d'autres professionnels. Seuls les patients directs utilisent son service.
Employé vs freelance : une distinction absurde mais légale
Il y a un point que j'ai mis du temps à saisir, et qui me paraît absurde mais qui est juridiquement cohérent.
Un employé (CDD ou CDI) du cabinet de santé qui gère le serveur, fait les mises à jour et les sauvegardes n'a pas besoin de certification HDS. Il fait partie de l'organisation du responsable de traitement — il n'est pas un sous-traitant.
Le même développeur, faisant exactement le même travail (SSH, mises à jour, sauvegardes), mais en freelance vendant 5 heures de prestation, a besoin de la certification HDS pour l'activité 5 (administration et exploitation). Pourquoi ? Parce qu'il est une entité séparée, un sous-traitant au sens RGPD, qui assure une activité d'hébergement pour le compte d'un tiers responsable de traitement.
La distinction ne se fait pas sur la nature du travail, mais sur le statut juridique de la personne qui le fait :
- Employé du cabinet (CDD/CDI) avec accès SSH → pas de HDS, il fait partie du responsable de traitement
- Freelance avec accès SSH permanent → HDS requis, il est sous-traitant et assure l'activité 5
Le cas du freelance qui livrerait uniquement du code
Si le freelance se contente de fournir du code — application, scripts d'infrastructure, configs de déploiement — et qu'il push tout dans un repo Git sans jamais avoir accès au serveur, à la base de données ni aux données, alors il n'assure aucune des 6 activités d'hébergement. Il livre un produit (du code), il n'opère pas un service.
Le test légal reste le même : "le fait d'assurer pour le compte du responsable de traitement tout ou partie des activités suivantes." Le verbe clé est "assurer" — c'est-à-dire exécuter, opérer, maintenir en condition opérationnelle. Les 6 activités décrivent des opérations sur l'infrastructure et le système, pas de la production de code.
La frontière se joue sur un point précis : qui appuie sur le bouton "déployer" ?
- Si c'est un employé du cabinet de santé qui contrôle l'outil de déploiement (par exemple ArgoCD) et déclenche les déploiements → freelance = livreur de code → pas de HDS
- Si le freelance a accès à cet outil et déclenche lui-même les déploiements → il participe à l'exploitation (activité 5) → HDS requis
Combien coûte une certification HDS pour les activités 4, 5 et 6 ?
J'ai cherché le processus officiel pour obtenir la certification HDS, voici ce que j'ai retenu :
- Mettre en place un Système de Management de la Sécurité de l'Information (SMSI) conforme à ISO 27001 (politique de sécurité, analyse de risques, gestion des accès, plan de continuité) — prérequis obligatoire.
- Choisir un organisme certificateur accrédité Comité français d'accréditation (Cofrac) (BSI, AFNOR, Bureau Veritas, LRQA…).
- Audit sur site en deux volets : conformité ISO 27001, puis exigences HDS spécifiques.
- Correction des non-conformités relevées.
- Obtention du certificat (valable 3 ans, avec audit de surveillance annuel).
J'ai volontairement laissé de côté le contenu concret du SMSI et de la norme ISO 27001 — je les connais mal. Cette note m'a donné envie d'explorer le sujet en profondeur, mais je le ferai dans une note séparée pour ne pas allonger encore celle-ci.
Les coûts typiques pour une TPE (< 10 personnes) :
| Poste | Estimation |
|---|---|
| Mise en place SMSI (conseil externe) | 2 000 – 6 000 € |
| Audit initial COFRAC (ISO 27001 + HDS) | 8 000 – 15 000 € |
| Audits de surveillance annuels (×2) | 2 000 – 5 000 € |
| Sous-total coûts externes | 12 000 – 26 000 € |
| Coût interne du salarié (100 – 200 h à 500 €/j soit ~70 €/h super brut) | 7 000 – 14 000 € |
| Total sur 3 ans | 19 000 – 40 000 € |
Estimation en temps humain (pour une personne seule, en charge de tout) :
| Étape | Effort humain estimé | Durée calendrier estimée |
|---|---|---|
| Mise en place SMSI (rédaction, procédures, analyse de risques, choix des outils) | 40 – 100 heures | 2 – 4 mois |
| Choix du certificateur et préparation du dossier | 15 – 30 heures | 3 – 6 semaines |
| Audit initial (sur site + préparation) | 15 – 30 heures | 1 – 2 semaines |
| Correction des non-conformités | 20 – 60 heures | 2 – 6 semaines |
| Obtention du certificat + 1er audit de surveillance | 10 – 30 heures | 1 – 2 mois |
| Total (avec SMSI ou maturité existante) | 100 – 250 heures | 6 – 9 mois |
| Total (sans SMSI préalable) | 200 – 400 heures | 12 – 18 mois |
Sources
Les fourchettes de coûts et de durées ci-dessus sont des estimations de Fermi calculées par MiMO-V2-Pro, recalibrées pour coller aux données publiées :
- Legiscope — Certification HDS hébergeur de données de santé 2026 (Dr. Thiébaut Devergranne, 23 mai 2026) : fourchette de 20 000 à 35 000 € sur 3 ans pour une TPE. Durée de 6 à 9 mois si l'organisation dispose déjà d'un SMSI ou d'une maturité ISO 27001 ; 12 à 18 mois sans SMSI préalable (dont 9-12 mois pour la certification ISO 27001 seule).
- Galeon — Certification HDS en 2026 (21 avril 2026) : « Les audits représentent généralement plusieurs dizaines de milliers d'euros, auxquels s'ajoutent les coûts internes de préparation et de mise en conformité. »
Je pense que des outils de service d'automatisation de conformité du type Oneleet que j'ai testés, peuvent accélérer le processus de mise en place d'un SMSI pour obtenir une certification ISO 27001.
Le risque sécurité du code vibe codé
Ça me fait un peu peur, honnêtement. Mon ami a vibe codé une application qui contient des données de santé. Et payer les frais importants d'une agence de développeur certifiée HDS n'aurait aucun sens dans ce contexte d'une application amateur sur mesure.
Qu'est-ce que je vais répondre à mon ami ?
D'abord, son idée d'hébergement chez Scaleway va coûter cher ! Déjà 250 € par mois rien que pour le plan de support Business.
Pour éviter cela, une solution serait d'auto-héberger l'application chez soi, dans son bureau, sur un petit serveur. Tant qu'on n'héberge pas pour un tiers, il n'y a pas besoin de certification HDS.
Mais il ne pourra pas demander à un développeur freelance d'administrer ce serveur. Dès qu'un freelance intervient sur l'infrastructure (accès SSH, mises à jour, sauvegardes), il assure l'activité 5 du référentiel HDS — et il devrait être certifié ! Et le coût de la certification pour administrer ce serveur, pour une seule instance, sera bien trop élevé.
Autre solution : embaucher un développeur en CDD pour toute intervention. C'est légalement possible sans HDS, mais c'est lourd à gérer et coûteux.
Réflexion sur le Vibe coding : libération ou prolétarisation ?
En tant qu'artisan développeur, je trouve amusant d'observer plusieurs de mes amis vibe coder des applications sur mesure pour leur besoin.
Pour le moment je n'ai pas cherché à savoir s'ils essaient de comprendre le code produit, ou si le code reste une boîte noire dont ils se fichent tant que ça marche. Mais c'est un phénomène socialement intéressant, et je ne sais pas si c'est une bonne nouvelle ou non.
Si le vibe coding reste un outil d'appropriation, si la personne comprend ce qu'elle fait, peut modifier, adapter, expliquer — alors c'est un acte de déprolétarisation : il reprend le contrôle sur ses outils de travail.
Mais si le code reste opaque, s'il ne s'agit que de produire sans comprendre, alors le vibe coding n'est qu'une nouvelle forme de prolétarisation. Le savoir ne passe plus par la machine au sens de Bernard Stiegler — il passe par l'IA, et la personne reste aussi démunie que devant si l'outil disparaît ou change, c'est de la désindividuation au sens de Bernard Stiegler. La personne n'a pas acquis de savoir, elle a acquis un résultat, elle "consomme".
C'est ce qui fait de ces outils des pharmakons : ils peuvent désindividuer autant qu'ils peuvent aider à s'individuer, selon l'usage qu'on en fait.
J'ai développé cette réflexion dans "J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes" et dans "Ma lutte contre mon affaiblissement cognitif". En résumé, j'essaie personnellement d'éviter cette prolétarisation : plutôt que de consommer l'IA pour produire des choses, j'essaie de groker — comprendre en profondeur, pas seulement obtenir un résultat.
J'ai découvert Beads, Dolt et DoltgreSQL
En parcourant awesome-opencode, je suis tombé sur opencode-beads, qui m'a fait découvrir le projet Beads :
Beads is a distributed graph issue tracker for AI agents, powered by Dolt.
J'ai passé un peu de temps à parcourir la documentation du projet et je vois beaucoup de choses intéressantes et qui rejoignent les idées que j'ai pour "Projet 24 - Prototyper le gestionnaire de projet de mes rêves".
Ce projet m'a aussi fait découvrir Dolt :
Dolt is a SQL database that you can fork, clone, branch, merge, push and pull just like a Git repository.
et DoltgreSQL :
From the creators of Dolt, the world's first version controlled SQL database, comes DoltgreSQL, the postgres-flavored version of Dolt. It's a SQL database that you can branch and merge, fork and clone, push and pull just like a Git repository. Connect to your Doltgres server just like any Postgres database to read or modify schema and data. Version control functionality is exposed in SQL via system tables, functions, and procedures.
J'ai découvert pgfmt, un formater de code SQL
A PostgreSQL SQL formatter with multiple style options.
pgfmt parses SQL using tree-sitter PostgreSQL and reformats it according to one of several well-known style guides. Formatting is powered by libpgfmt.
Ce formatter supporte plusieurs types de style de formatage. Pour le moment, le formatage "river" est celui qui se rapproche le plus de mon style.
Je pense qu'il serait même possible de créer mon propre style de formatage en modifiant ce projet à l'aide d'un agentic coding tool 🤔.
J'ai découvert Adminer, alternative à PhpMyAdmin et je me suis intéressé à OPCache
En travaillant sur un playground d'étude de Podman Quadlets, dans le README.md de l'image Docker mariadb, #JaiDécouvert le projet Adminer (https://www.adminer.org) qui semble être l'équivalent de PhpMyAdmin, mais sous la forme d'un fichier unique.
Je découvre aussi que contrairement à PhpMyAdmin, Adminer n'est pas limité à Mysql / MariaDB, il supporte aussi PostgreSQL.
En regardant le dépôt GitHub d'Adminer, je découvre que le gros fichier PHP de 496 kB est le résultat de la concaténation de nombreux fichiers php.
Ça me rassure, parce que je me demandais comment l'édition d'un fichier unique de cette taille pouvait être humainement gérable.
Je trouve astucieux ce mode de déploiement d'un projet PHP sous forme d'un seul fichier qui me fait penser à la méthode Golang. Cependant, je me pose des questions sur la performance de cette technique étant donné que PHP fonctionne en mode process-per request (CGI), ce qui signifie que ce gros fichier PHP est interprété à chaque action sur la page 🤔.
En creusant un peu le sujet avec Claude Sonnet 4.5, je découvre que depuis la version 5.5 de PHP, OPCache améliore significativement la vitesse des requêtes PHP, sans pour autant atteindre celle de Golang, NodeJS, Python ou Ruby qui utilisent des serveurs HTTP intégrés. La consommation mémoire reste supérieure dans des conditions d'implémentation comparables.
Avec OPCache, Adminer semble rester performant malgré l'utilisation d'un fichier unique.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
2026-04-02 : étudier Beads comme source d'inspiration ou outil à intégrer.
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
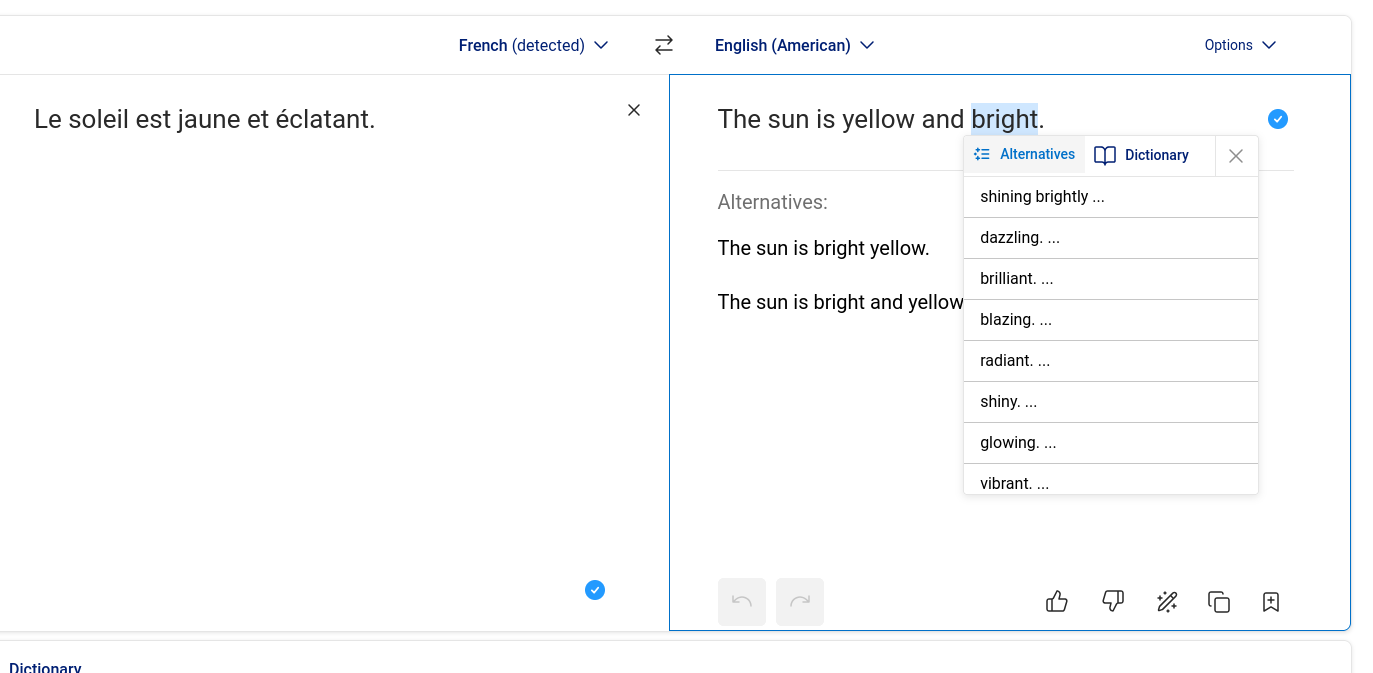
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité Structured Outputs (LLM) (https://platform.openai.com/docs/guides/structured-outputs)
Journal du vendredi 18 avril 2025 à 11:40
Cela fait des années que je m'intéresse au sujet des solutions de sauvegarde en continu de bases de données PostgreSQL.
Dans cette note, le terme "sauvegarde en continu" ne signifie pas Point In Time Recovery.
Jusqu'à présent, je me suis toujours concentré sur la méthode "mainstream", qui consiste principalement à effectuer un backup binaire couplé avec une sauvegarde continue du WAL. Par exemple des solutions basées sur pg_basebackup, pgBackRest ou barman.
Une autre solution consiste à déployer une seconde instance PostgreSQL en mode streaming replication.
Une troisième solution que #JaimeraisUnJour tester : mettre en place une sauvegarde incrémentale basée sur le filesystème btrfs.
Plus précisément, la commande btrfs-send. La documentation de Dalibo mentionne cette méthode de sauvegarde.
Samedi dernier, j'ai imaginé une autre méthode qui me plait beaucoup par sa relative flexibilité et sa simplicité.
Elle consisterait à sauvegarder des tables de manière granulaire à intervalle de temps régulier vers un Object Storage à l'aide d'un Foreign Data Wrapper.
Pour cela, j'ai identifié parquet_s3_fdw, basé sur le format Apache Parquet qui permet de lire et d'écrire des données sur un bucket Object Storage.
Features
- Support SELECT of parquet file on local file system or Amazon S3.
- Support INSERT, DELETE, UPDATE (Foreign modification).
- Support MinIO access instead of Amazon S3.
J'ai utilisé de nombreuses fois Foreign Data Wrapper pour copier de manière granulaire des données entre deux bases de données PostgreSQL.
J'ai trouvé cette méthode très pratique, en particulier la possibilité de pouvoir utiliser un "pattern" SQL de copie du type :
INSERT INTO clients_local (id, nom, email, date_derniere_maj)
SELECT
d.client_id,
d.nom_client,
d.email_client,
CURRENT_TIMESTAMP
FROM
distant.clients_distant d
WHERE
d.date_modification > (SELECT MAX(date_derniere_maj) FROM clients_local)
ON CONFLICT (id) DO UPDATE
SET
nom = EXCLUDED.nom,
email = EXCLUDED.email,
date_derniere_maj = EXCLUDED.date_derniere_maj;
#JaimeraisUnJour réaliser un POC de cette idée basée sur parquet_s3_fdw.
Journal du vendredi 18 avril 2025 à 10:31
Il existe deux familles de méthodes de backup d'une base de données PostgreSQL :
- Backup logique
- Backup binaire à "chaud et à froid"
Voici une présentation simplifiée des différences entre ces deux modes de sauvegarde, qui peut comporter certaines imprécisions dues à cette vulgarisation.
Un backup logique est effectué par pg_dump sur une instance PostgreSQL en cours d'exécution (nommée "à chaud"). pg_dump supporte plusieurs formats d'archivage dont plain et custom.
Le format plain génère un fichier SQL classique, lisible "humainement".
Le format custom génère un fichier binaire, qui est plus flexible et a une taille bien plus réduite que le format plain. Il est toujours possible de générer un fichier SQL comme plain à partir d'un fichier custom : avec la commande pg_restore -f output.sql fichier_custom.
Il est possible de réaliser des sauvegardes et restaurations à "distance", via le protocole classique PostgreSQL Frontend Backend Protocol.
Il est possible d'importer un backup logique vers une instance PostgreSQL de version différente, en général plus récente.
Un backup binaire peut être effectué à "chaud" ou à "froid". En simplifiant, cela consiste à sauvegarder les fichiers PostgreSQL du filesystem et optionnellement sauvegarder aussi les journaux (WAL) de PostgreSQL. Pour effectuer un backup binaire, il existe la commande officielle pg_basebackup, mais aussi d'autres solutions plus complètes, comme pgBackRest ou barman.
Les systèmes de backup binaire de PostgreSQL ont l'avantage de pouvoir restaurer une sauvegarde à un point précis dans le temps (fonctionnalité PITR).
Je constate que la mise en place d'un backup binaire est plus complexe à mettre en place qu'un backup logique.
Voici mon POC le plus avancé concernant les backup binaire : poc-pg_basebackup_incremental.
Actuellement, pour sauvegarder des instances PostgreSQL, j'utilise pg_back-docker-sidecar qui est une solution de backup logique, basé sur pg_back, déployé sous la forme d'un Docker sidecar.
J'envisage aussi d'expérimenter une méthode basée sur parquet_s3_fdw que j'ai décrite dans 2025-04-18_1140.
Pour des informations plus approfondies à propos de ces sujets, je vous conseille la documentation de ces formations de Dalibo :
Journal du jeudi 17 avril 2025 à 12:02
Alexandre m'a partagé le projet Postgres Operator, que j'avais peut-être croisé par le passé, mais que j'avais oublié.
Postgres Operator permet entre autres de déployer des instances PostgreSQL dans un cluster Kubernetes mais aussi de mettre en place des systèmes de backup logique et backup binaire.
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.