
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (107 notes) :
Journal du lundi 12 janvier 2026 à 09:36
Il y a exactement 1 an, j'ai publié cette note pour citer ce message de Salvatore Sanfilippo, créateur de Redis :
About "people still thinking LLMs are quite useless", I still believe that the problem is that most people are exposed to ChatGPT 4o that at this point for my use case (programming / design partner) is basically a useless toy. And I guess that in tech many folks try LLMs for the same use cases. Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
Aujourd'hui, je viens de lire son nouveau billet : Don't fall into the anti-AI hype (1106 commentaires sur HackerNews, 217 commentaires sur Lobsters).
Ces observations rejoignent ce que je constate avec OpenCode et les modèles Claude Sonnet 4.5 ou Claude Opus 4.5. Il me semble que "coder à la main" pourrait devenir un jeu, comme faire des sudoku ou jouer à des jeux vidéo. Pour le moment, je n'ai aucune idée de l'impact que cela aura sur mes capacités cognitives. J'ai l'impression que mes compétences pourraient décliner.
En fait, j'ai très peur de ne plus faire d'efforts de compréhension et qu'après quelques mois ou années, je devienne de plus en plus bête en déléguant systématiquement la réflexion à l'IA.
Voici cet article, traduit en français avec Claude Sonnet 4.5 :
Ne tombez pas dans le battage anti-IA
J'adore écrire du logiciel, ligne par ligne. On pourrait dire que ma carrière a été un effort continu pour créer des logiciels bien écrits, minimaux, où la touche humaine était la caractéristique fondamentale. J'espère également une société où les derniers ne sont pas oubliés. De plus, je ne souhaite pas que l'IA réussisse économiquement, je me fiche que le système économique actuel soit subverti (je pourrais être très heureux, honnêtement, si cela va dans la direction d'une redistribution massive de la richesse). Mais, je ne me respecterais pas moi-même et mon intelligence si mon idée du logiciel et de la société devait altérer ma vision : les faits sont les faits, et l'IA va changer la programmation pour toujours.
En 2020, j'ai quitté mon emploi pour écrire un roman sur l'IA, le revenu de base universel, une société qui s'adaptait à l'automatisation du travail en faisant face à de nombreux défis. À la toute fin de 2024, j'ai ouvert une chaîne YouTube axée sur l'IA, son utilisation dans les tâches de codage, ses effets sociaux et économiques potentiels. Mais bien que j'aie reconnu très tôt ce qui allait se passer, je pensais que nous avions plus de temps avant que la programmation ne soit complètement remodelée, au moins quelques années. Je ne crois plus que ce soit le cas. Récemment, les LLM de pointe sont capables de compléter de grandes sous-tâches ou des projets de taille moyenne seuls, presque sans assistance, avec un bon ensemble d'indices sur ce que devrait être le résultat final. Le degré de succès que vous obtiendrez est lié au type de programmation que vous faites (plus c'est isolé et textuellement représentable, mieux c'est : la programmation système est particulièrement adaptée), et à votre capacité à créer une représentation mentale du problème à communiquer au LLM. Mais, en général, il est maintenant clair que pour la plupart des projets, écrire le code soi-même n'a plus de sens, si ce n'est pour s'amuser.
Au cours de la semaine dernière, simplement en promptant, et en inspectant le code pour fournir des conseils de temps en temps, en quelques heures j'ai accompli les quatre tâches suivantes, en heures au lieu de semaines :
J'ai modifié ma bibliothèque linenoise pour supporter l'UTF-8, et créé un framework pour tester l'édition de ligne qui utilise un terminal émulé capable de rapporter ce qui est affiché dans chaque cellule de caractère. Quelque chose que j'ai toujours voulu faire, mais il était difficile de justifier le travail nécessaire juste pour tester un projet personnel. Mais si vous pouvez simplement décrire votre idée, et qu'elle se matérialise dans le code, les choses sont très différentes.
J'ai corrigé des échecs transitoires dans le test de Redis. C'est un travail très ennuyeux, des problèmes liés au timing, des conditions de deadlock TCP, etc. Claude Code a itéré pendant tout le temps nécessaire pour le reproduire, a inspecté l'état des processus pour comprendre ce qui se passait, et a corrigé les bugs.
Hier, je voulais une bibliothèque C pure capable de faire l'inférence de modèles d'embedding de type BERT. Claude Code l'a créée en 5 minutes. Même sortie et même vitesse (15% plus lent) que PyTorch. 700 lignes de code. Un outil Python pour convertir le modèle GTE-small.
Au cours des dernières semaines, j'ai effectué des modifications des mécanismes internes de Redis Streams. J'avais un document de conception pour le travail que j'ai fait. J'ai essayé de le donner à Claude Code et il a reproduit mon travail en, genre, 20 minutes ou moins (principalement parce que je suis lent à vérifier et à autoriser l'exécution des commandes nécessaires).
Il est tout simplement impossible de ne pas voir la réalité de ce qui se passe. Écrire du code n'est plus nécessaire pour la plupart. Il est maintenant beaucoup plus intéressant de comprendre quoi faire, et comment le faire (et, à propos de cette deuxième partie, les LLM sont aussi d'excellents partenaires). Peu importe si les entreprises d'IA ne pourront pas récupérer leur argent et que le marché boursier s'effondrera. Tout cela est sans importance, à long terme. Peu importe si tel ou tel PDG d'une licorne vous dit quelque chose de rebutant, ou d'absurde. La programmation a changé pour toujours, de toute façon.
Comment je me sens, à propos de tout le code que j'ai écrit qui a été ingéré par les LLM ? Je suis ravi d'en faire partie, parce que je vois cela comme une continuation de ce que j'ai essayé de faire toute ma vie : démocratiser le code, les systèmes, la connaissance. Les LLM vont nous aider à écrire de meilleurs logiciels, plus rapidement, et permettront aux petites équipes d'avoir une chance de rivaliser avec les plus grandes entreprises. La même chose que les logiciels open source ont fait dans les années 90.
Cependant, cette technologie est beaucoup trop importante pour être entre les mains de quelques entreprises. Pour l'instant, vous pouvez faire le pré-entraînement mieux ou pas, vous pouvez faire l'apprentissage par renforcement de manière beaucoup plus efficace que d'autres, mais les modèles ouverts, en particulier ceux produits en Chine, continuent de rivaliser (même s'ils sont en retard) avec les modèles de pointe des laboratoires fermés. Il y a une démocratisation suffisante de l'IA, jusqu'à présent, même si elle est imparfaite. Mais : il n'est absolument pas évident qu'il en sera ainsi pour toujours. J'ai peur de la centralisation. En même temps, je crois que les réseaux de neurones, à l'échelle, sont simplement capables de faire des choses incroyables, et qu'il n'y a pas assez de "magie" dans l'IA de pointe actuelle pour que les autres laboratoires et équipes ne rattrapent pas leur retard (sinon il serait très difficile d'expliquer, par exemple, pourquoi OpenAI, Anthropic et Google sont si proches dans leurs résultats, depuis des années maintenant).
En tant que programmeur, je veux écrire plus d'open source que jamais, maintenant. Je veux améliorer certains de mes dépôts abandonnés pour des raisons de temps. Je veux appliquer l'IA à mon workflow Redis. Améliorer l'implémentation des Vector Sets et ensuite d'autres structures de données, comme je le fais avec Streams maintenant.
Mais je m'inquiète pour les gens qui vont être licenciés. Il n'est pas clair quelle sera la dynamique en jeu : les entreprises vont-elles essayer d'avoir plus de personnes, et de construire plus ? Ou vont-elles essayer de réduire les coûts salariaux, en ayant moins de programmeurs qui sont meilleurs au prompting ? Et, il y a d'autres secteurs où les humains deviendront complètement remplaçables, je le crains.
Quelle est la solution sociale, alors ? L'innovation ne peut pas être annulée après tout. Je crois que nous devrions voter pour des gouvernements qui reconnaissent ce qui se passe, et qui sont prêts à soutenir ceux qui resteront sans emploi. Et, plus les gens seront licenciés, plus il y aura de pression politique pour voter pour ceux qui garantiront un certain degré de protection. Mais j'attends également avec impatience le bien que l'IA pourrait apporter : de nouveaux progrès en science, qui pourraient aider à réduire la souffrance de la condition humaine, qui n'est pas toujours heureuse.
Quoi qu'il en soit, revenons à la programmation. J'ai une seule suggestion pour vous, mon ami. Quoi que vous croyiez sur ce qui devrait être la Bonne Chose, vous ne pouvez pas la contrôler en refusant ce qui se passe actuellement. Éviter l'IA ne va pas vous aider, vous ou votre carrière. Pensez-y. Testez ces nouveaux outils, avec soin, avec des semaines de travail, pas dans un test de cinq minutes où vous ne pouvez que renforcer vos propres convictions. Trouvez un moyen de vous multiplier, et si cela ne fonctionne pas pour vous, réessayez tous les quelques mois.
Oui, peut-être pensez-vous que vous avez travaillé si dur pour apprendre à coder, et maintenant les machines le font pour vous. Mais quel était le feu en vous, quand vous codiez jusqu'à la nuit pour voir votre projet fonctionner ? C'était construire. Et maintenant vous pouvez construire plus et mieux, si vous trouvez votre façon d'utiliser l'IA efficacement. Le plaisir est toujours là, intact.
Journal du dimanche 06 juillet 2025 à 10:14
Il m'arrive régulièrement de perdre du temps en tentant d'insérer des lignes de commentaires dans des commandes Bash multiline, par exemple comme ceci :
sudo qemu-system-x86_64 \
-m 8G \
-smp 4 \
-enable-kvm \
-drive file=ubuntu-working-layer.qcow2,format=qcow2 \
-drive file=cloud-init.img,format=raw \
-nographic \
\ # Folder sharing between the host system and the virtual machine:
-fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share \
\ # Allows virtual machine to access the Internet
\ # and port forwarding to access virtual machine via ssh:
-nic user,ipv6-net=fd00::/64,hostfwd=tcp::2222-:22
Malheureusement, cette syntaxe n'est pas supportée par Bash et à ma connaissance, il n'existe aucune solution en Bash pour atteindre mon objectif.
Je suis ainsi contraint de diviser la documentation en deux parties : l'une pour l'exécution de la commande, l'autre pour expliquer les paramètres. Voici ce que cela donne :
sudo qemu-system-x86_64 \
-m 8G \
-smp 4 \
-enable-kvm \
-drive file=ubuntu-working-layer.qcow2,format=qcow2 \
-drive file=cloud-init.img,format=raw \
-nographic \
-fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share \
-nic user,ipv6-net=fd00::/64,hostfwd=tcp::2222-:22
# Here are some explanations of the parameters used in this command
#
# Folder sharing between the host system and the virtual machine:
#
# ```
# -fsdev local,id=fsdev0,path=$(pwd)/shared/,security_model=mapped-file
# -device virtio-9p-pci,fsdev=fsdev0,mount_tag=host_share
# ```
#
# Allows virtual machine to access the Internet
# and port forwarding to access virtual machine via ssh:
#
# ```
# -nic user,ipv6-net=fd00::/64,hostfwd=tcp::2222-:22
# ```
Je me souviens d'avoir étudié Oils shell en octobre dernier et je me suis demandé si ce shell supporte ou non les commentaires sur des commandes multiline.
La réponse est oui : "multiline-command".
Exemple dans ce playground :
#!/usr/bin/env osh
... ls
-l
# comment 1
--all
# comment 2
--human-readable;
Chaque fois que je me plonge dans Oils, je trouve ce projet intéressant.
J'aimerais l'utiliser, mais je sais que c'est un projet de niche et qu'en contexte d'équipe, je rencontrerais sans doute des difficultés d'adoption. Je pense que je ferais face à des oppositions.
Je pense tout de même à l'utiliser dans mes projets personnels, mais j'ai peur de trop l'apprécier et d'être frustré ensuite si je ne peux pas l'utiliser en équipe 🤔.
Réflexions au sujet des notions d'"environnement", "instance" et "workspace"
Je suis en train d'implémenter un repository playground privé pour un client et je me demande comment bien nommer les choses.
Je souhaite implémenter dans ce playground, des dossiers qui permettent d'interagir avec différents types d'instance.
Je me suis interrogé sur les notions de « environnement » et « d'instance ». Je connais ces termes, mais j'ai souhaité étudier leur différence avec précision.
Environnement :
- Article Wiktionary français : environnement
(Informatique) Ensemble des matériels et logiciels sur lesquels sont exécutés les programmes d'une application.
- "On travaille dans un environnement Linux."
- Article Wiktionary français : environment
(Informatique) Environnement.
- "The primary prompt is changed to help us remember that this session is inside a chroot environment."
- Article Wikipedia anglais : Runtime environment
In computer programming, a runtime system or runtime environment is a sub-system that exists in the computer where a program is created, as well as in the computers where the program is intended to be run.
- Article Wikipedia anglais : Deployment environment
In software deployment, an environment or tier is a computer system or set of systems in which a computer program or software component is deployed and executed. In simple cases, such as developing and immediately executing a program on the same machine, there may be a single environment, but in industrial use, the development environment (where changes are originally made) and production environment (what end users use) are separated, often with several stages in between. This structured release management process allows phased deployment (rollout), testing, and rollback in case of problems.
Instance :
- Article Wiktionary Français : instance
(Réseaux informatiques) Copie d’un logiciel fournissant un service sur un réseau.
- "PeerTube est un logiciel. Ce logiciel, des personnes spécialisées (disons… Bernadette, l’université X et le club de karaté Y) peuvent l’installer sur un serveur. Cela donnera une « instance », c’est à dire un hébergement de PeerTube. Concrètement, héberger une instance crée un site web (disons BernadetTube.fr, UniversiTube.org ou KarateTube.net) sur lequel on peut regarder des vidéos et créer un compte pour interagir ou uploader ses propres contenus."
- Article Wikipedia Anglais : instance
- Instance (computer science), referring to any running process or to an object as an instance of a class.
- Instance can refer to a single virtual machine in a virtualized or cloud computing environment that provides operating-system-level virtualization.
ChatGPT me dit :
Dans un contexte DevOps, les termes environment et instance font référence à des concepts distincts :
- Un environment regroupe les ressources et la configuration nécessaires pour une étape spécifique du cycle de vie de développement.
- Une instance est une unité d'exécution de l'application, isolée, et potentiellement en plusieurs exemplaires au sein d'un même environnement.
À la suite de cette réflexion, j'ai implémenté un exemple de repository contenant plusieurs workspaces, permettant d'interagir avec des instances de différents types d'environnement.
Repository : project-workspaces-skeleton
Je l'ai organisé de la façon suivante :
$ tree
├── development
│ ├── local-workspace
│ │ └── README.md
│ └── remote-workspace
│ └── README.md
├── production
│ ├── local-workspace
│ │ └── README.md
│ └── remote-workspace
│ └── README.md
├── README.md
└── staging
├── local-workspace
│ └── README.md
└── remote-workspace
└── README.md
Voici quelques extraits du contenu des README.md.
development/local-workspace/README.md :
Local development environment workspace
Introduction
This workspace allows you locally launch the equivalent of remote development environment instances (applications, databases, etc.), within the GitOps paradigm.
This workspace provides scripts for injecting and initializing a database with demo data, or for copying the contents of remote instances to the local database.
This workspace is the right place if you want to work (fix bug, improve…) in isolation (without disturbing your colleagues) on development-type configuration changes.
This workspace is also useful for tinkering to better understand how this environment works.
Workspace configuration
...
production/remote-workspace/README.md :
Remote production environment workspace
Be careful when using scripts in this workspace, as you risk breaking production instances!
Introduction
This workspace allows you to interact with remote production environment instances (applications, databases, etc.) within the GitOps paradigm.
This workspace is designed, among other things, to store the configuration of production instances.
It includes scripts for deploying this configuration to remote instances and analysing the differences between the theoretical or desired configuration and that actually deployed.
With Git, these configurations are versioned, making it possible to track changes made over time on these instances.
Furthermore, this paradigm allows modifications to be proposed in the form of Pull Requests, simplifying collaborative work.Workspace configuration
...
Je pense que ce skeleton va me servir de base pour de futurs repository de projets.
Journal du dimanche 20 octobre 2024 à 22:50
Nouvelle #iteration du Projet 14 - Script de base d'installation d'un serveur Ubuntu LTS.
Il y a quelques jours, j'ai migré de vagrant-hostmanger vers vagrant-dns. J'ai ensuite souhaité mettre en œuvre Grizzly, mais j'ai rencontré un problème.
J'ai installé une version binaire statiquement liée de Grizzly à l'aide de Mise. Dans cette version, Go ne fait pas appel à la fonction getaddrinfo pour la résolution des noms d'hôte. Au lieu de cela, Go se limite à lire les informations de configuration DNS dans /etc/resolv.conf (champ nameserver) et les entrées de /etc/hosts.
Cela signifie que les serveurs DNS gérés par systemd-resolved ne sont pas pris en compte 😭.
Pour régler ce problème, j'utilise en même temps vagrant-dns et Vagrant Host Manager : voici le commit.
J'active uniquement ici le paramètre config.hostmanager.manage_host = true et je laisse vagrant-dns résoudre les hostnames à l'intérieur des machines virtuelles et des containers Docker.
Journal du dimanche 20 octobre 2024 à 10:04
La version 5 de Svelte vient de sortir : 5.0.0.
Il y a un an, j'avais lu le billet Introducing runes. Depuis, j'ai suivi ce sujet de loin.
J'aimerais tester et apprendre à utiliser la fonctionnalité rune.
#JeMeDemande dans quel projet 🤔. Est-ce que je préfère refactorer vers rune le projet sklein-pkm-engine ou gibbon-replay 🤔. Je pense que ces deux projets utilisent trop peu de "reactive state".
Je souhaite prochainement débuter le projet que j'ai présenté dans 2023-10-28_2008. Je pense que ça serait une bonne occasion pour créer mon premier projet 100% TypeScript avec Svelte 5 avec Rune.
Journal du mardi 03 septembre 2024 à 13:26
Je viens de vérifier, il n'est toujours pas possible d'utiliser des slot nommés dans les layout SvelteKit : Treat layout pages like components when using named slots.
Journal du dimanche 01 septembre 2024 à 17:50
#JaiDécouvert que des fontes de caractères sont distribuées directement via npm.
Par exemple, la police de caractères source-serif utilisé par gwern.net, sous licence SIL Open Font est disponible via ce package npm https://www.npmjs.com/package/source-serif.
En creusant un peu plus le sujet, #JaiDécouvert https://fontsource.org qui est le projet qui semble packager toutes ces polices de caractères sur npm.
Journal du mercredi 28 août 2024 à 09:46
#JaiLu la documentation de UnoCSS.
Tailwind CSS is a PostCSS plugin, while UnoCSS is an isomorphic engine with a collection of first-class integrations with build tools (including a PostCSS plugin). This means UnoCSS can be much more flexible to be used in different places (for example, CDN Runtime, which generates CSS on the fly) and have deep integrations with build tools to provide better HMR, performance, and developer experience (for example, the Inspector).
-- Why UnoCSS?
Si je souhaite utiliser UnoCSS tout en conservant une compatibilité Tailwind CSS je dois utiliser Uno preset :
This preset is compatible with Tailwind CSS and Windi CSS, you can refer to their documentation for detailed usage.
#JaiDécouvert les features innovantes de UnoCSS :
<button
bg="blue-400 hover:blue-500 dark:blue-500 dark:hover:blue-600"
text="sm white"
font="mono light"
p="y-2 x-4"
border="2 rounded blue-200"
>
Button
</button>
Est l'équivalent de :
<button class="bg-blue-400 hover:bg-blue-500 text-sm text-white font-mono font-light py-2 px-4 rounded border-2 border-blue-200 dark:bg-blue-500 dark:hover:bg-blue-600">
Button
</button>
<text-red> red text </text-red>
<flex> flexbox </flex>
I'm feeling <i-line-md-emoji-grin /> today!
Est l'équivalent de :
<span class="text-red"> red text </span>
<div class="flex"> flexbox </div>
I'm feeling <span class="i-line-md-emoji-grin"></span> today!
Je trouve ces syntaxes élégantes, mais, à ma connaissance, elles sont très peu courantes. Si je me mets à la place d'un développeur "onbordé" dans un nouveau projet utilisant le "attributify mode" et Tagify mode, je crains que cela puisse être un choc pour lui. Il me faudrait probablement plusieurs semaines avant que mon cerveau s'habitue à interpréter automatiquement cette syntaxe.
Je me demande donc si le gain final est réellement positif ou négatif.
Pour le moment, j'ai décidé que n'utiliserait pas les fonctionnalités "attributify mode" et Tagify mode.
Journal du mardi 27 août 2024 à 14:06
Suite à une réflexion sur les solutions de chiffrement coté browser, #JaiDécouvert https://age-online.com/ :
Easily pass around secure data with age (everything is in-browser, powered by WASM, data does not go ANYWHERE).
Toujours sur le même sujet, #JaiDécouvert libsodium et libsodium.js.
#JaiDécouvert aussi que age utilise pour le chiffrement symétrique l'algorithme ChaCha20-Poly1305, qui est aussi proposé par libsodium.
Journal du lundi 26 août 2024 à 21:59
Alexandre m'a partagé JS Dates Are About to Be Fixed
Many people think that by working with UTC or communicating dates in ISO format, they are safe; however, this is not correct, as information is still lost.
Oui ! J'ai souvent fait l'erreur !
La librairie : Temporal
Journal du dimanche 25 août 2024 à 18:58
Dans le thread Lobster Printing the web, part 2: HTML and CSS for printing books
#JaiDécouvert plusieurs la propriétés CSS :
The orphans property specifies the minimum number of line boxes in a block container that must be left in a fragment before a fragmentation break. The widows property specifies the minimum number of line boxes of a block container that must be left in a fragment after a break. Examples of how they are used to control fragmentation breaks are given below.
-- from
et
In addition to the specific CSS counter for page, you can use counter(pages) to get the total number of pages.
-- from
et
We are going to make use of the
string-setproperty defined in the CSS Generated Content for Paged Media Module which is still a working draft at the W3C.-- from
#JaiDécouvert aussi le projet Paged.js.
Paged.js is an Open source library to display paginated content in the browser and to generate print books using web technology.
-- from
Journal du dimanche 25 août 2024 à 12:44
En cherchant des informations au sujet de l'origine de la fonctionnalité compose watch, #JaiDécouvert Tilt (from).
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.
Journal du samedi 24 août 2024 à 10:47
Je cherche à mieux comprendre la syntaxe let:close utilisée dans le contexte de Svelte, comme dans l'exemple suivant :
<Popover>
<PopoverButton>Solutions</PopoverButton>
<PopoverPanel let:close>
<button
on:click={async () => {
await fetch("/accept-terms", { method: "POST" });
close();
}}
>
Read and accept
</button>
<!-- ... -->
</PopoverPanel>
</Popover>
Ce code provient du projet svelte-headlessui.
À première vue, cette syntaxe me faisait penser aux <slot key={value}> dans Svelte 🤔.
Cette intuition s'est confirmée après avoir exploré le concept plus en détail à travers l'exemple suivant :
<!-- FancyList.svelte -->
<ul>
{#each items as item}
<li class="fancy">
<slot prop={item} />
</li>
{/each}
</ul>
<!-- App.svelte -->
<FancyList {items} let:prop={thing}>
<div>{thing.text}</div>
</FancyList>
Après avoir lu la section sur les <slot key={value}> , je me rends compte que je n'utilise presque jamais les slots, à l'exception des layout. C'est dommage, car je passe à côté d'une fonctionnalité très pratique.
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Journal du mercredi 21 août 2024 à 15:30
#JaiLu pour la première fois la page de la Web API nommée Intersection Observer API.
Dans un projet Svelte, je crée dynamiquement un composant qui est inséré dans un élément non Svelte :
component = new myComponent({
target: element,
props: {
foo: bar
}
});
Cette Web API m'a permis de déterminer la position d'un composant lorsque celui-ci est réellement attaché à la page web.
<script lang="js">
import { onMount } from "svelte";
export let rootElement;
onMount(() => {
const observer = new IntersectionObserver(
(entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
console.log(entry.boundingClientRect);
observer.disconnect();
}
});
}
);
observer.observe(rootElement);
});
</script>
<span bind:this={rootElement}>
...
</span>
Journal du mercredi 21 août 2024 à 10:37
Note de type snippets concernant docker compose et l'utilisation de la fonctionnalité healthcheck et depends_on.
Cette méthode évite que le service webapp démarre avant que les services postgres et redis soient prêts.
# Fichier docker-composexyml
services:
postgres:
image: postgres:16
...
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
redis:
image: redis:7
...
healthcheck:
test: ["CMD", "redis-cli", "ping"]
timeout: 10s
retries: 3
start_period: 10s
webapp:
image: ...
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
Ici la commande :
$ docker compose up -d webapp
s'assure du lancement de ses dépendances, les services postgres et redis.
De plus, si le Dockerfile du service webapp contient par exemple :
# Fichier Dockerfile
...
RUN apt update -y; apt install -y curl
...
HEALTHCHECK --interval=30s --timeout=10s --retries=3 CMD curl --fail http://localhost:3000 || exit 1
Alors, je peux lancer webapp avec :
$ docker compose up -d webapp --wait
Avec l'option --wait docker compose "rend la main" lorsque le service webapp est prêt à recevoir des requêtes.
Ressources :
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
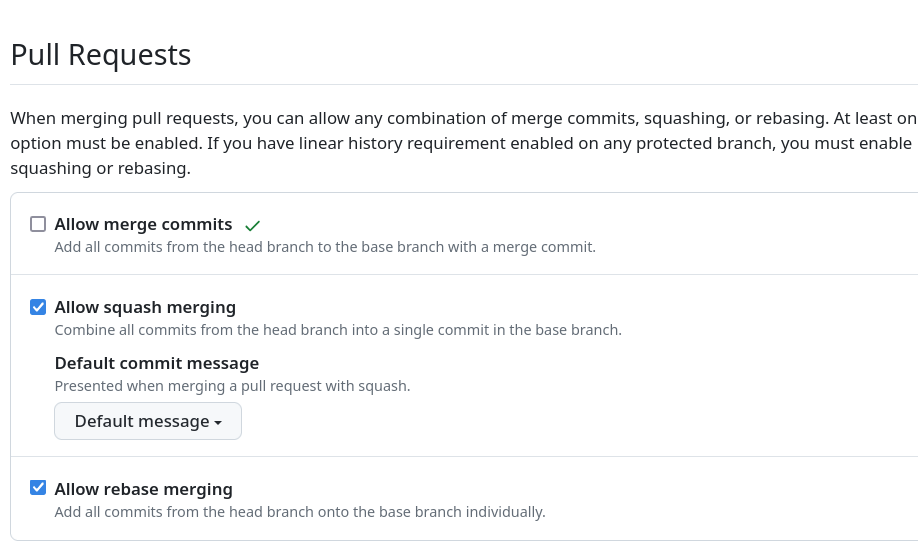
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
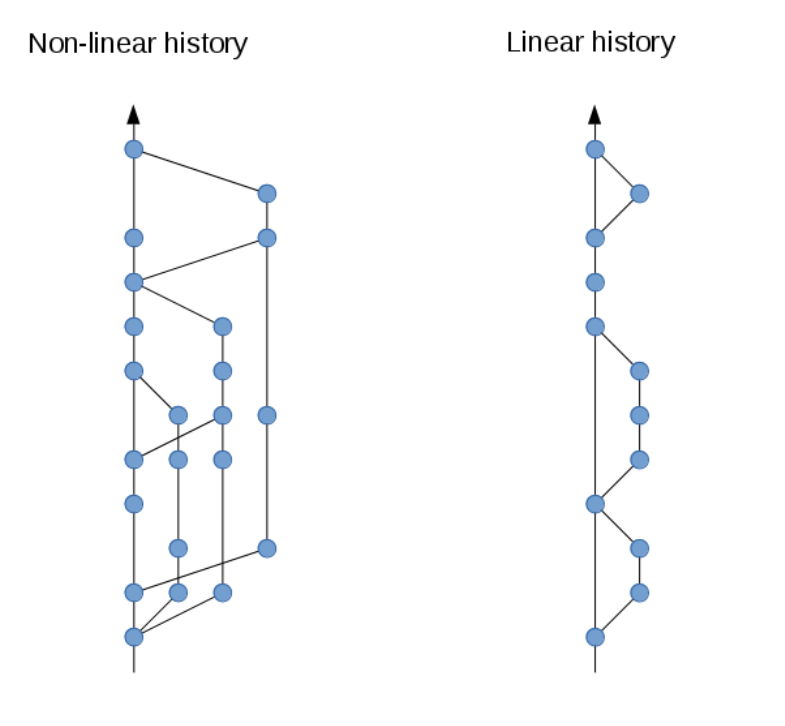
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.
Journal du mardi 20 août 2024 à 17:37
#JaiDécouvert un article très intéressant qui répertorie les difficultés classiques rencontrées par les développeurs avec git rebase, ainsi que des solutions pour y remédier :git rebase: what can go wrong?.
Journal du mardi 20 août 2024 à 17:27
#JaiDécouvert ce guide pour Git : Flight rules for Git.
Je le trouve excellent 👌.
Et voici une autre article intéressant au sujet de Git rebase : git rebase in depth.
Journal du lundi 19 août 2024 à 17:21
#JaiDécouvert https://github.com/romkor/svelte-portal (from ChatGPT).
Vraiment trop pratique !
Journal du lundi 19 août 2024 à 16:28
Dans l'introduction de la documentation de bits-ui, #JaiDécouvert encore une autre #librairie de composants UI pour Svelte : melt.
Journal du lundi 19 août 2024 à 15:52
#Jadore le projet shadcn-svelte. Je trouve l'expérience développeur (DX) excellente ❤️.
Journal du lundi 19 août 2024 à 15:28
Je souhaite setup Tailwind CSS dans un projet SvelteKit avec svelte-add.
https://svelte-add.com/adder/tailwindcss
Mais ne comprends pas pourquoi, svelte-add semble ne plus fonctionner comme avant, il ne modifie pas mon projet SvelteKit existant, mais il souhaite l'écraser 🤔.
$ pnpx svelte-add@latest tailwindcss
svelte-add version 2.7.3
┌ Welcome to Svelte Add!
│
◇ Create new Project?
│ No
│
└ Exiting.
En attendant de comprendre pourquoi, je vais setup Tailwind CSS manuellement en suivante cette documentation https://tailwindcss.com/docs/guides/sveltekit.
Journal du samedi 17 août 2024 à 15:21
Je repository GitHub officiel des images Docker de Elasticsearch se trouve ici : https://github.com/elastic/elasticsearch/tree/main/distribution/docker.
Journal du samedi 17 août 2024 à 14:50
Depuis le début des années 2000, j'éprouve une certaine aversion dès que je suis confronté à une technologie basée sur Java. Pourquoi ? Parce que, à tort ou à raison, j'ai remarqué que les applications Java sont souvent très longues à démarrer et consomment une quantité excessive de RAM.
Je pense par exemple à Logstash, dont la lenteur était insupportable, que j'ai fini par remplacer d'abord par Fluentd, puis par Vector.
Je pense également à Eclipse IDE.
Et bien sûr, aux serveurs Jakarta EE.
Journal du vendredi 16 août 2024 à 13:17
J'ai relu cette note de David Larlet :
Silk = documentation et tests
Markdown based document-driven web API testing.
La rapidité d’exécution d’un outil écrit en Go est toujours surprenante, j’ai eu besoin de vérifier que les tests étaient bien passés pour être sûr de son bon fonctionnement… Mon expérience me montre qu’une documentation qui n’est pas testée/proche du code n’est jamais synchronisée et conduit à des frustrations pour les utilisateurs. Silk est un moyen de faire cela directement depuis votre markdown, ça me rappelle d’une certaine manière le couple docutils/reStructuredText. En rapide. Et je ne saurais trop insister sur l’importance d’avoir une suite de tests rapide pour qu’elle reste pertinente.
Raconter une histoire dans vos tests est plus verbeux mais assurément plus intéressant pour la personne qui cherchera à comprendre ce que vous avez implémenté. Il y a de grandes chances que ce soit vous. Le README du dépôt est un exemple de ce qui peut être réalisé.
Je pense que ce billet a participer à ma sensibilitasion à la notion de colocated documentation.
Journal du vendredi 16 août 2024 à 13:06
Dans ma note Keep it simple, stupid le plus longtemps possible j'ai écris :
Je me souviens de la quête vers le minimaliste dans le code de David Larlet : « Est-ce qu’il est possible d'enlever des couches dans la stack ? »
Je viens d'essayer de retrouver ces articles, mais ce n'est pas facile tellement les articles de David Larlet sont nombreux.
Pour le moment j'ai retrouvé les extraits ci-dessous ceci en lien avec le sujet.
Paternité
- Ajouter des couches
- Changer des couches
- Enlever des couches
- Changer des couches
- Mettre des couches
J’en suis à l’étape 3 dans ma maturité en tant que développeur. La paternité change les priorités et je pense qu’elle a un grand rôle dans le fait de vouloir remettre le focus sur la valeur apportée plus que sur la technique. Me battre pour une meilleure expérience utilisateur plutôt que contre un framework, chercher à se faire plaisir davantage via ce qui est produit que par un contentement technique.
Lorsque j’expérimente aujourd’hui, ce n’est plus pour découvrir une nouvelle bibliothèque mais pour trouver de nouveaux moyens de simplifier un problème. Dans ce contexte, il est intéressant de re-questionner la page blanche (cache), de re-challenger certaines bonnes pratiques communément admises (cache).
Autre extrait :
Leftpad
Every package that you use adds yet another dependency to your project. Dependencies, by their very name, are things you need in order for your code to function. The more dependencies you take on, the more points of failure you have. Not to mention the more chance for error: have you vetted any of the programmers who have written these functions that you depend on daily?
J’étais en train de préparer cette intervention lorsque le fiasco leftpad est arrivé dans l’écosystème NPM. Du coup, j’ai eu immédiatement plein d’articles faisant une ode à la simplicité, à la réduction de dépendances et mettant en garde contre les couches d’abstraction. Merci Azer Koçulu, je pouvais difficilement rêver mieux :-). Je ne vais pas tirer sur l’ambulance mais ça illustre presque trop bien mon propos.
as your project progresses, your team’s productivity will drop because of all the complexity and dependencies. You’ll need more people to maintain it, and more people with specific knowledge to maintain it. If your lead developers leave, you’re dead. You should be fighting complexity and not embracing it. Every added framework, and even library, makes your project more difficult to maintain. Avoid unnecessary frameworks and libraries from day one.
Jusqu’où aller dans cette démarche ? Par où commencer ?
Autre extrait :
Maybe it’s not too late for you, though. Perhaps, like me, you aren’t feeling particularly overworked. But are you feeling irritable, tired, and apathetic about the work you need to do? Are you struggling to concentrate on simple tasks?
Then maybe what you’re feeling is burnout, too.
J’ai travaillé pendant un an et demi avec Mozilla sur la partie paiement du Marketplace puis sur le site des extensions de Firefox. Et depuis un an avec Etalab sur la plateforme datagouv. Dans les deux situations, j’ai passé davantage de temps à lutter contre les outils plutôt qu’à les apprécier pour le travail rendu. C’est terrible car ceux-ci sont censés théoriquement faire gagner du temps mais sur le long terme cela se révèle être faux dans mon cas.
Je me demande si je ne suis pas en train de faire un burnout technique, non pas par trop de travail mais par manque de contrôle dans mes outils.
Autre extrait :
The aesthetic microlith
Growth for the sake of growth is the ideology of the cancer cell.
Edward Abbey
Toutes ces raisons m’ont amené à étudier une nouvelle piste. Cette appellation est une combinaison du Majestic Monolith (cache) et des microservices. Je me persuade qu’il y a une voie différente entre ces deux extrêmes. Une voie qui limite les fuites d’abstraction (cache) afin de réduire la dette technique et de favoriser l’inclusion de nouveaux membres dans une équipe. Une voie qui ne demande pas de réécrire la moitié de l’application tous les six mois car une nouvelle montée en version majeure n’est pas rétro-compatible. Une voie où l’on ne raisonne plus en termes de features et de bugs mais d’expérience utilisateur et de satisfaction pour l’ensemble des parties prenantes. Un environnement qui permet de faire une pause dans les développements afin de prendre le temps de davantage considérer les besoins des personnes qui utilisent le produit.
We all want things to be simpler. But we may not know what to sacrifice in order to achieve that goal.
Dans cette recherche de simplicité, j’ai essayé de remettre en question chaque concept de programmation, chaque bonne pratique, chaque bibliothèque, chaque ligne de code. J’ai essayé de produire un prototype qui soit un peu plus conséquent que celui proposé à Confoo pour voir jusqu’où cela pouvait aller. Ce qu’il me manque c’est non pas du temps de développement mais du temps de vie du projet pour analyser les effets produits sur le moyen terme. Je devrais avoir l’occasion d’expérimenter cela avec scopyleft prochainement, ça sent la trilogie.
À court terme en tout cas, c’est extrêmement plus fun à coder et l’on arrive au résultat finalement aussi rapidement. Cela devient une matière beaucoup plus malléable, dont on connait les forces et les faiblesses car le périmètre est réduit. En contrepartie, certains cas aux limites vont être écartés et l’expérience de certains utilisateurs se dégrade plus rapidement. Ce n’est pas que le coût de prise en compte soit énorme, il s’agit davantage de le prendre en considération lorsque le besoin est réel.
Autre extrait :
Maintenance
Capitalism excels at innovation but is failing at maintenance, and for most lives it is maintenance that matters more
Innovation is overvalued. Maintenance often matters more (cache)
Le problème ici c’est que je n’ai jamais rencontré de projet qui réduisent leur complexité dans le temps. Que ce soit via des itérations de retrait ou des réécritures complètes on arrive toujours à des usines à gaz si l’on ne s’est pas fixé en amont — de manière consentie par toutes les parties prenantes — les budgets évoqués plus haut. Pourtant en restant à l’échelle du microlith, la maintenance se trouverait potentiellement réduite de beaucoup.
Si l’on s’en tient à l’estimation selon laquelle la maintenance représente 67% d’un produit (cache), il devient important de trouver comment réduire ce coût.
Autre extrait :
Frameworks, API et prolétarisation
La présentation 6 reasons why APIs are reshaping your business fait l’analogie du développement Web avec l’industrie automobile et le passage de l’artisanat à l’intégration de pièces toutes faites.
Si le passage aux frameworks JavaScript et CSS a entraîné la perte de savoir des développeurs front-end et leur prolétarisation, le passage aux API va avoir le même effet sur les développeurs back-end, ceux-ci devenant de simples intégrateurs de solutions existantes s’éloignant de la problématique métier et de ses données pour se perdre dans les couches du pragmatisme. N’oubliez pas qu’en facilitant le travail de la machine, on finit par être remplacé par la machine, c’est ce que nous réserve l’industrialisation du Web. Et ça me rend nostalgique.
Autre extrait :
A system where you can delete parts without rewriting others is often called loosely coupled, but it’s a lot easier to explain what one looks like rather than how to build it in the first place.
Even hardcoding a variable once can be loose coupling, or using a command line flag over a variable. Loose coupling is about being able to change your mind without changing too much code.
Write code that is easy to delete, not easy to extend (cache)
Partant de ce constat, j’ai essayé de produire une stack minimaliste qui comportent très peu de dépendances qui peuvent évoluer en fonction du besoin. De cette manière, on accède à un LEAN technique : l’ajout de complexité architecturale en fonction du besoin uniquement.
Le code produit accorde une place importante à l’esthétique et à la modularité sans endommager la compréhension de l’ensemble grâce à la documentation et aux tests.
Autre extrait :
Thus teams are often confronting the uncomfortable choice between a risky refactoring operation and clean amputation. The best developers can be positively gleeful about amputating a diseased piece of code (even when it’s their own baby, so to speak), recognizing that it’s often the best choice for the overall health of the project. Better a single module should die than continue to bog down the rest of the project.
…
The organic, evolutionary nature of code also highlights the importance of getting your APIs right. By virtue of their public visibility, APIs can exert a lot of influence on the future growth of the codebase. A good API acts like a trellis, coaxing the code to grow where you want it. A bad API is like a cancer, and it will metastasize all over your codebase.
L’intérêt de partir d’un périmètre aussi restreint est de pouvoir se ré-interroger à chaque nouvel ajout sur sa pertinence, cela constitue une base itérative sans renoncer au plaisir technique. Le code est lisible et explicable en quelques heures pour des personnes ayant un faible niveau et il n’y a pas besoin de télécharger la moitié d’internet pour faire tourner une page web. Ma démarche est de renoncer à la complexité par défaut qui est prônée par tous les frameworks actuels, l’ajout de dépendances doit se faire au moment du besoin.
La durée de vie d’une composition de technologies est forcément réduite et demande de se ré-interroger à échéances régulières sur sa pertinence. Toute la difficulté actuelle est de pouvoir allonger ces échéances pour trouver le bon ratio entre focus et exploration. Plus vous bâtirez sur des concepts simples, universels et standardisés, plus vous aurez de chances de pouvoir être conservateur dans votre choix technique. Et plus vous serez inclusif auprès des potentiels contributeurs.
Journal du vendredi 16 août 2024 à 11:30
#JaiDécouvert l'expression Core-stack developer dans cet article de David Larlet :
… when in doubt, focus on the core. When in doubt, learn CSS over any sort of tooling around CSS. Learn JavaScript instead of React or Angular or whatever other library seems hot at the moment. Learn HTML. Learn how browsers work. Learn how connections are established over the network.
The reason for focusing on the core has nothing to do with the validity of any of those other frameworks, libraries or tools. On the contrary, focusing on the core helps you to recognize the strengths and limitations of these tools and abstractions. A developer with a solid understanding of vanilla JavaScript can shift fairly easily from React to Angular to Ember. More importantly, they are well equipped to understand if the shift should be made at all. You can’t necessarily say the same thing about an INSERT-NEW-HOT-FRAMEWORK-HERE developer.
Building your core understanding of the web and the underlying technologies that power it will help you to better understand when and how to utilize abstractions.
That’s part one of dealing with the rapid pace of the web.
À défaut d’être complet (full) en raison de l’effervescence technique difficile à suivre au quotidien, il me semble de plus en plus pertinent de miser sur le cœur (core) des technologies utilisées. Comprendre et maîtriser les bases avant tout pour pouvoir ponctuellement et rapidement se spécialiser en fonction du besoin. Connaître ES6 vous servira ces 10 prochaines années, savoir utiliser React sera obsolète l’année prochaine. Sages développeurs, investissez.
-- from
Core-stack developer me fait penser à Choose Boring Technology et à mon article nommé Sur quelles compétences j'ai décidé ou non d'investir mon temps ?. Je me rends compte rétrospectivement que j'ai listé ma core-stack 🙂.
Journal du jeudi 15 août 2024 à 20:00
Depuis que j'utilise @tabler/icons-svelte pour intégrer des tabler-icons sur un projet SvelteKit SSR, je rencontre d'énormes problèmes de performance en mode développement (pnpm run dev).
Pour traiter le problème, j'ai essayé ce hack indiqué dans l'issue Slow experience in SvelteKit, mais cela ne fonctionne pas.
Toujours dans cette issue, #JaiDécouvert Iconify.
Je pense me souvenir d'avoir commencé à utiliser tabler-icons comme alternative Open source à Font Awesome.
J'ai lu la page page raconte l'histoire du projet et j'apprends que le projet s'est réellement lancé en 2020.
Iconify est devenu un projet Open source en 2021 :
In mid 2022 plans changed, thanks to people showing interest in sponsoring open source development.
The new plan is to:
- Open source everything, encourage developers to create their own open source solutions that use Iconify.
- Rely on sponsors to finance development.
-- from
Mais, d'après la page contributors le projet semble toujours très majoritairement développé par Vjacheslav Trushkin.
Je lis aussi :
Unlike fonts, it downloaded data only for icons used on page, rendered pixel perfect SVG. (from)
Par contre, je pense comprendre qu'Iconify n'est pas un projet de création d'icônes, mais un framework qui regroupe énormément d'icônes.
Par exemple, j'ai constaté qu'Iconify intègre entre autres :
Iconify propose des composants icônes pour Svelte : Iconify for Svelte.
Mais, je lis :
Loads icons on demand. No need to bundle icons, component will automatically load icon data for icons that you use from Iconify API. -- from
Cette technique « Loads icons on demand » ne me plait pas. Je souhaite réduire au maximum les latences dans mes applications web.
J'ai continué mes recherches.
#JaiLu Icon library for svelte? : sveltejs
#JaiDécouvert unplugin-icons (from).
unplugin-icons est un projet qui a commencé en 2021 et qui est basé sur Iconify.
Je constate que unplugin-icons propose une configuration SvelteKit.
J'ai testé et cela semble très bien fonctionner 🙂.
Le site https://icones.js.org permet de facilement copier-coller le code Javascript pour intégrer une icône. Par exemple, un click sur "Unplugin Icons" :
permet de copier :
import TablerChevronDown from '~icons/tabler/chevron-down'
Je ne constate aucun problème de lenteur au mode développement (pnpm run dev) et aucun chargement réseau externe des icônes dans la version de production.
#JaiDécidé d'adopter cette librairie pour gérer les icons de mes projets SvelteKit.
Journal du jeudi 15 août 2024 à 19:08
#JaiDécouvert la #library classix un équivalent à clsx mais :
String expressions have a few benefits over objects:
- A faster typing experience
- A more intuitive syntax (conditions first)
- else support through ternary operators
What's more, by leveraging them, classix provides:
- A simpler and consistent API
- A smaller library size
- Better performance
-- from
Après avoir vu cela, j'ai creusé un peu le sujet et #JaiDécouvert que clsx a sorti une nouvelle release après la création de classix : https://github.com/lukeed/clsx/releases/tag/v2.1.0
Add new
clsx/litesubmodule for string-only usage: 1a49142This is a 140b version of clsx that is ideal for Tailwind and/or React contexts, which typically follow this clsx usage pattern.
clsx('foo bar', props.maybe && 'conditional classes', props.className);
Qui, d'après ce que je comprends, reprend en partie l'implémentation de classix.
Afin d'éviter un effet de balkanisation, je vais utiliser clsx.
Journal du jeudi 15 août 2024 à 16:00
#iteration Projet 11 - "Première version d'un moteur web PKM".
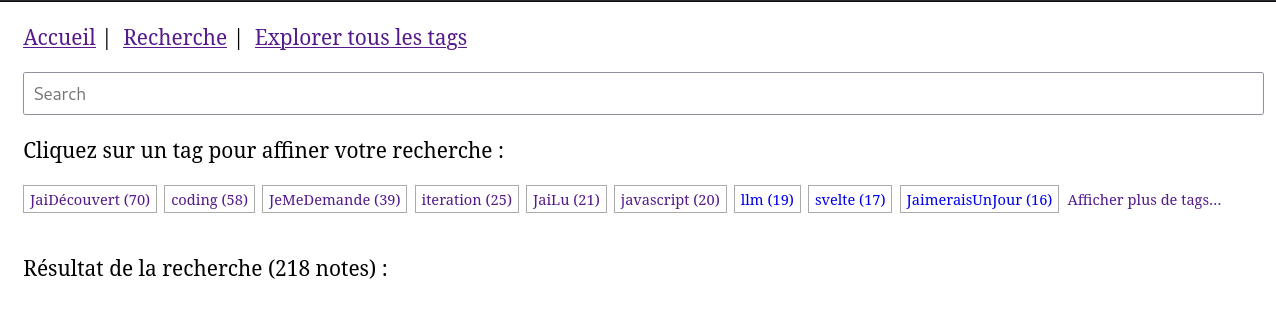
Le nombre de tags listé sur ce screenshot est limité par un flex-wrap: wrap + height: 2em + overflow: hidden.
Problème : j'aimerais que le bouton "Afficher plus de tags…" soit affiché directement à droite du dernier tag (ici "Svelte").
Je souhaite limiter le nombre de tags affiché non pas via du css (overflow: hidden), mais via une action Svelte.
J'aimerais pouvoir utiliser cette svelte/action comme ceci :
<ul use:ItemOverflowLimiter={{itemClass: "tag"}}>
{#each data.tags as tag}
<li class="tag">
<a
href={`/search/?tags=${tag.name}`}
>{tag.name} ({tag.note_counts})</a>
</li>
{/each}
<li>Afficher plus de tags…</li>
</ul>
1 heure plus tard, j'ai réussi à atteindre mon objectif avec ce commit.
Voici le résulat 🙂 :
Voici le code de la fonction svelte/action ItemOverflowLimiter.js :
export default function ItemOverflowLimiter(node, options) {
let destroyAllNextItems = false;
let itemsToDestroy = [];
// search width of items to keep
let widthItemsToKeep = 0;
for (let item of node.children) {
if (
(options?.itemClass) &&
(!item.classList.contains(options.itemClass))
) {
widthItemsToKeep += item.clientWidth;
}
}
for (let item of node.children) {
if (destroyAllNextItems) {
if (
(!options?.itemClass) ||
(item.classList.contains(options.itemClass))
) {
itemsToDestroy.push(item);
}
} else if (
(item.offsetTop > 0) ||
(item.offsetLeft + item.clientWidth > (node.clientWidth - widthItemsToKeep))
) {
itemsToDestroy.push(item);
destroyAllNextItems = true;
}
}
for (let item of itemsToDestroy) {
item.remove();
}
}
Je trouve les svelte/action très agréable à utiliser.
Journal du mardi 13 août 2024 à 21:32
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
J'ai enfin analysé la Merge Request qui m'a été envoyé par un ami 🤗 : https://github.com/stephane-klein/postgres-tags-model-poc/pull/9
6 mois plus tard, j'ai fini l'implémentation de la première version du "Query string javascript parser" : https://github.com/stephane-klein/postgres-tags-model-poc/commit/f0f363b78c136e8e67a38f95b5c627d874537949
Pour la coloration syntaxique des fichiers Peggy sous Neovim, j'utilise avec succès https://github.com/TheGrandmother/peggy-vim : https://github.com/stephane-klein/dotfiles/commit/20cba4ba646a0793f66f9b19788920a4ff1f1838
Journal du lundi 12 août 2024 à 13:25
Quel est mon rapport aux langages typés ?
Pour bien comprendre mon approche des langages typés, il est utile de revenir sur mon parcours.
Enfant, j'ai commencé par du Locomotive Basic (non typé), j'ai ensuite fait beaucoup de Turbo Pascal (typé) et un peu de C, C++ (typé).
À cette époque, je préférais les langages typés pour des raisons de performances.
En 2000, j'ai vraiment aimé utiliser à nouveau des langages non typés, comme PHP et surtout Python qui a été pendant très longtemps mon langage de prédilection.
J'ai à nouveau beaucoup pratiqué un langage typé de 2013 à 2018 : Golang.
Aujourd'hui, je considère qu'il est souvent plus facile et plus rapide de programmer dans un langage non typé, notamment grâce au Duck Typing. Cependant, je reconnais que les langages typés offrent des avantages indéniables, notamment en matière de refactoring de code.
Je pense qu'il est préférable d'utiliser un langage typé sur un projet critique.
Je pense qu'il est préférable d'utiliser un langage typé pour les programmes qui manipule des données complexes et divers.
C'est, par exemple, pour cela que ne suis pas un utilisateur de MongoDB. Je préfère une base de données PostgreSQL où tout est bien typé.
Il ne me viendrait pas à l'esprit d'implémenter une base de données ou un moteur web dans un langage non typé.
Par contre, je suis moins convaincu par l'utilisation d'un langage typé pour les applications d'interface utilisateur lourde ou web.
Lorsqu'une équipe de développement travaillant sur un code commun atteint une certaine taille — je n'ai aucune idée de ce nombre — je suis convaincu qu'il devient préférable d'utiliser un langage typé.
Journal du lundi 12 août 2024 à 11:04
Voici un extrait de l'article Turbo 8 is dropping TypeScript de David Heinemeier Hansson (DHH de Basecamp) :
This isn't a plea to convert anyone of anything, though. As I discussed in Programming types and mindsets, very few programmers are typically interested in having their opinion on typing changed. Most programmers find themselves drawn strongly to typing or not quite early in their career, and then spend the rest of it rationalizing The Correct Choice to themselves and others.
Je trouve ce point de vue intéressant.
Voir aussi : TypeScript
Journal du vendredi 02 août 2024 à 13:40
Je souhaite partager une réflexion sur un risque potentiel lié à l'usage des spikes.
Lorsque les équipes réalisent des spikes avec un taux de réussite très élevé, il existe un risque significatif que les développeurs et les stakeholders commencent progressivement à considérer ces spikes comme des issues ordinaires. Si cela se produit, les caractéristiques et l'utilité intrinsèques des spikes risquent d'être compromises :
- Les développeurs pourraient se sentir obligés de réussir chaque spike ;
- Ils pourraient alors être tentés d'augmenter la qualité de réalisation de leurs spikes, transformant ainsi des explorations en livrables de production ;
- Les stakeholders, quant à eux, pourraient ne plus prendre en compte le risque d'échec des spikes dans leur stratégie.
Pour ces raisons, je rappelle régulièrement aux stakeholders que l'échec fait partie intégrante des spikes et qu'il est essentiel de préserver cette caractéristique pour maintenir leur véritable utilité.
Journal du dimanche 28 juillet 2024 à 09:14
Pour des raisons Developer eXperience — convivialité — j'apprécie d'avoir la possibilité de me connecter facilement à un serveur PostgreSQL distant, par exemple, pour :
- Simplement ouvrir un terminal interactif psql ;
- Exécuter un fichier SQL local sur un serveur distant ;
- Exécuter un script local, Python, JavaScript ou autre sur un serveur distant.
Cependant, par choix déontologique, je préfère ne jamais ouvrir PostgreSQL sur l'extérieur.
Je me limite à ouvrir uniquement les services SSH et HTTP sur l'extérieur.
Pour contourner cette limitation, j'utilise des tunnels SSH pour accéder à mes serveurs PostgreSQL distants.
Dans ce dossier /deployment/develop, voici mes scripts idiosyncrasiques que j'ai l'habitude d'utiliser pour ouvrir ou fermer mes tunnels SSH :
Voici un exemple d'utilisation :
$ ./scripts/open_ssh_tunnel_postgres.sh
$ ./scripts/enter-in-pg.sh ../../init.sql
$ ../../import.js
$ ./scripts/close_ssh_tunnel_postgres.sh
Dans les scripts open_ssh_tunnel_postgres.sh et close_ssh_tunnel_postgres.sh, j'utilise simplement nohup pour exécuter ssh en tâche de fond et récuperer son PID.
Journal du jeudi 25 juillet 2024 à 16:56
Rich Harris explains this clearly. JSDoc for writing a lib. TypeScript for writing an app. (from)
Ce conseil entre en opposition avec ce que j'ai écrit en octobre 2023 :
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Ce conseil entre aussi en opposition avec ce second élément que j'ai écrit en octobre 2023 :
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Je pense qu'il serait bon que je revoie ma doctrine d'artisan développeur sur ce sujet.
Journal du lundi 22 juillet 2024 à 15:15
Merci à Alexandre de m'avoir partagé le projet Mailpit une alternative à Maildev ou MailCatcher.
Journal du vendredi 19 juillet 2024 à 23:16
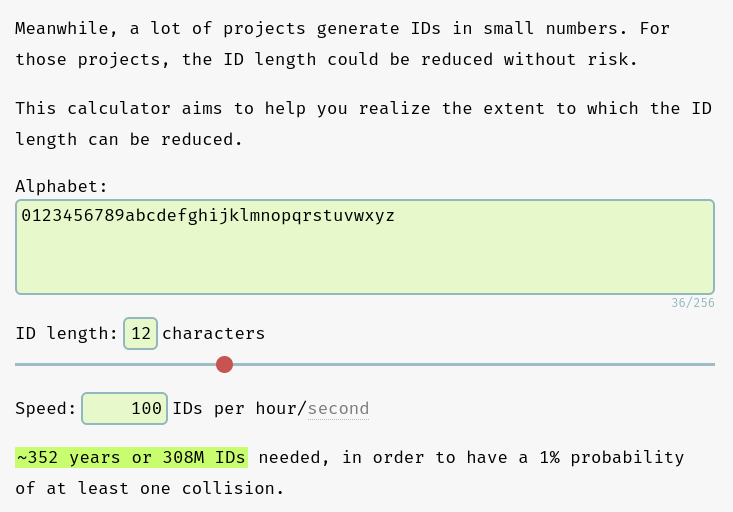
Pour la génération de nanoid du Projet 11, j'ai choisi les paramètres suivants :
const nanoid = customAlphabet('0123456789abcdefghijklmnopqrstuvwxyz', 12);
D'après les calculs effectués sur https://zelark.github.io/nano-id-cc/, à raison de 100 nouvelles notes par jour (ce qui est irréaliste), sur 352 années, le risque de doublon d'id est de 1%, ce qui est largement acceptable 😉.
Journal du mardi 16 juillet 2024 à 09:57
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
- Extraction des tags présents dans le corps des notes.
C'est fait 🙂 : Extract tags from note bodies to create and associate them with the note
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
C'est fait 🙂 : Implementation of a markdown-to-html rendering function that takes tags and wikilinks into account
J’ai préparé une première ébauche, mais étant incertain de la manière dont je vais intégrer cette fonctionnalité avec pg_search ou Typesense, j’ai décidé de ne pas continuer à la développer pour le moment : Implementation of a function that transforms markdown content into plain text.
Journal du lundi 15 juillet 2024 à 15:25
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search.- Créer un repository GitHub nommé
obsidian-vault-to-typesense.- Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc
C'est fait 🙂.
Après cela, je souhaite implémenter dans
obsidian-vault-to-apache-age-pocles fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]).
C'est implémenté par ce commit 🙂.
Je ne suis pas satisfait de l'implémentation de cette partie et celle-ci.
Journal du dimanche 14 juillet 2024 à 12:11
Avec l'intégration de pg_search et Typesense, j'ai bien conscience de m'être un peu perdu dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search. - Créer un repository GitHub nommé
obsidian-vault-to-typesense. - Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc.
Après cela, je souhaite implémenter dans obsidian-vault-to-apache-age-poc les fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]). - Extraction des tags présents dans le corps des notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en texte brut, sans lien, destiné à être injecté dans un moteur de recherche comme pg_search ou Typesense.
Après avoir traité ces tâches, je souhaite travailler sur un moteur de rendu HTML basé sur SvelteKit, obsidian-vault-to-apache-age-poc et sans doute obsidian-vault-to-typesense.
Journal du dimanche 14 juillet 2024 à 10:26
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans 2024-07-10_0941 je disais :
je souhaite tester l'intégration de Typesense à
obsidian-vault-to-apache-age-pocen complément de pg_search.
Voici un screencast du résulat de cette implémentation de InstantSearch connecté à Typesense :
Journal du mercredi 10 juillet 2024 à 09:41
Suite à 2024-07-09_0846 (Projet 5) et suite à la publication de poc-meilisearch-blog-sveltekit en 2023, je souhaite tester l'intégration de Typesense à obsidian-vault-to-apache-age-poc en complément de pg_search.
J'ai bien conscience que Typesense fait doublon avec pg_search, mais mon objectif dans ce projet est de comparer les résultats de Typesense avec ceux de pg_search.
J'espère que cet environnement de travail me permettra d'itérer afin de répondre à cette question.
Idéalement, j'aimerais uniquement utiliser pg_search afin de mettre en œuvre un seul serveur de base de données et de bénéficier de la mise à jour automatique de l'index du moteur de recherche :
A BM25 index must be created over a table before it can be searched. This index is strongly consistent, which means that new data is immediately searchable across all connections. Once an index is created, it automatically stays in sync with the underlying table as the data changes. (from)
Journal du jeudi 20 juin 2024 à 22:11
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans cette version du 20 juin j'ai implémenté :
- Importation des fichiers dans des nodes de type
notesdans un graph. - Le contenu des notes dans une table
public.notes - Les aliases dans la table
public.note_aliases - Importation des tags et leurs liaisons vers les notes dans un graph.
Au stade où j'en suis, je suis encore loin d'être en capacité de juger si le moteur de graph — Age — me sera utile ou non pour réaliser des requêtes simplement 🤔.
Prochaine fonctionnalités que je souhaite implémenter dans ce projet :
- [ ] Recherche de type fuzzy search sur les
Note.title,aliasetTag.namebasé sur la méthode Levenshtein du module fuzzystrmatch - [ ] Recherche plain text sur le contenu des Notes basé sur pg_search
Dans la liste des features de pg_search je lis :
- Autocomplete
- Fuzzy search
Je pense donc intégrer pg_search avant fuzzystrmatch. Peut-être que je n'aurais pas besoin d'utiliser fuzzystrmatch.
Journal du jeudi 20 juin 2024 à 00:14
#JaiLu Ask HN: Why do message queue-based architectures seem less popular now? | Hacker News.
Je trouve la question très intéressante.
Ce commentaire m'a bien fait rire :
Going to give the unpopular answer. Queues, Streams and Pub/Sub are poorly understood concepts by most engineers. They don't know when they need them, don't know how to use them properly and choose to use them for the wrong things. I still work with all of the above (SQS/SNS/RabbitMQ/Kafka/Google Pub/Sub).
I work at a company that only hires the best and brightest engineers from the top 3-4 schools in North America and for almost every engineer here this is their first job.
My engineers have done crazy things like:
- Try to queue up tens of thousands of 100mb messages in RabbitMQ instantaneously and wonder why it blows up.
- Send significantly oversized messages in RabbitMQ in general despite all of the warnings saying not to do this
- Start new projects in 2024 on the latest RabbitMQ version and try to use classic queues
- Creating quorum queues without replication policies or doing literally anything to make them HA.
- Expose clusters on the internet with the admin user being guest/guest.
- The most senior architect in the org declared a new architecture pattern, held an organization-wide meeting and demo to extol the new virtues/pattern of ... sticking messages into a queue and then creating a backchannel so that a second consumer could process those queued messages on demand, out of order (and making it no longer a queue). And nobody except me said "why are you putting messages that you need to process out of order into a queue?"...and the 'pattern' caught on!
- Use Kafka as a basic message queue
- Send data from a central datacenter to globally distributed datacenters with a global lock on the object and all operations on it until each target DC confirms it has received the updated object. Insist that this process is asynchronous, because the data was sent with AJAX requests.
As it turns out, people don't really need to do all that great of a job and we still get by. So tools get misused, overused and underused.
In the places where it's being used well, you probably just don't hear about it.
Edit: I forgot to list something significant. There's over 30 microservices in our org to every 1 engineer. Please kill me. I would literally rather Kurt Cobain myself than work at another organization that has thousands of microservices in a gigantic monorepo.
Vous êtes sur la première page | [ Page suivante (57) >> ]