
Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
Journal du jeudi 06 juin 2024 à 10:47
Cette semaine, j'ai déjeuné avec un ami dont les connaissances dans le domaine du #MachineLearning et des #llm dépassent largement les miennes... J'en ai profité pour lui poser de nombreuses questions.
Voici ci-dessous quelques notes de ce que j'ai retenu de notre discussion.
Avertissement : Le contenu de cette note reflète les informations que j'ai reçues pendant cette conversation. Je n'ai pas vérifié l'exactitude de ces informations, et elles pourraient ne pas être entièrement correctes. Le contenu de cette note est donc à considérer comme approximatif. N'hésitez pas à me contacter à contact@stephane-klein.info si vous constatez des erreurs.
Histoire de Llama.cpp ?
Question : quelle est l'histoire de llama.cpp ? Comment ce projet se positionne dans l'écosystème ?
D'après ce que j'ai compris, début 2023, PyTorch était la solution "mainstream" (la seule ?) pour effectuer de l'inférence sur le modèle LLaMa — sortie en février 2023.
PyTorch — écrit en Python et C++ — est optimisée pour les GPU, plus précisément pour le framework CUDA.
PyTorch est n'est pas optimisé pour l'exécution sur CPU, ce n'est pas son objectif.
Georgi Gerganov a créé llama.cpp pour pouvoir effectuer de l'inférence sur le modèle LLaMa sur du CPU d'une manière optimisé. Contrairement à PyTorch, plus de Python et des optimisations pour Apple Silicon, utilisation des instructions AVX / AVX2 sur les CPU x86… Par la suite, « la boucle a été bouclée » avec l'ajout du support GPU en avril 2023.
À la question « Maintenant que llama.cpp a un support GPU, à quoi sert PyTorch ? », la réponse est : PyTorch permet beaucoup d'autres choses, comme entraîner des modèles…
Aperçu de l'historique du projet :
- 18 septembre 2022 : Georgi Gerganov commence la librairie ggml, sur laquelle seront construits llama.cpp et Whisper.cpp.
- 4 mars 2023 : Georgi Gerganov a publié le premier commit de llama.cpp.
- 10 mars 2023 : je crois que c'est le premier poste Twitter de publication de llama.cpp https://twitter.com/ggerganov/status/1634282694208114690.
- 13 mars 2023 : premier post à propos de LLama.cpp sur Hacker News qui fait zéro commentaire - Llama.cpp can run on Macs that have 64G of RAM (40GB of Free memory).
- 14 mars 2023 : second poste, toujours zéro commentaire - Run a GPT-3 style AI on your local machine, fully on premise.
- 31 mars 2023 : premier thread sur llama.cpp qui fait le buzz avec 414 commentaires - Llama.cpp 30B runs with only 6GB of RAM now.
- 12 avril 2023 : d'après ce que je comprends, voici la Merge Request d'ajout du support GPU à llama.cpp # Add GPU support to ggml (from).
- 6 juin 2023 : Georgi Gerganov lance sa société nommée https://ggml.ai (from) .
- 10 juillet 2023 : Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- 24 juillet 2023 : llama : add support for llama2.c models (from).
- 25 août 2023 : ajout du support ROCm (AMD).
Comment nommer Llama.cpp ?
Question : quel est le nom d'un outil comme llama.cpp ?
Réponse : Je n'ai pas eu de réponse univoque à cette question.
C'est un outil qui effectue des inférences sur un modèle.
Voici quelques idées de nom :
- Moteur d'inférence (Inference Engines) ;
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, #JaiDécidé d'utiliser le terme Inference Engines.
Autre projet comme Llama.cpp ?
Question : Existe-t-il un autre projet comme Llama.cpp
Oui, il existe d'autres projets, comme llm - Large Language Models for Everyone, in Rust. Article Hacker News publié le 14 mars 2023 sous le nom LLaMA-rs: a Rust port of llama.cpp for fast LLaMA inference on CPU.
Et aussi, https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from).
Le README de ce projet liste de nombreuses autres implémentations de Inference Engines.
Mais, à ce jour, llama.cpp semble être l'Inference Engines le plus complet et celui qui fait consensus.
GPU vs CPU
Question : Jai l'impression qu'il est possible de compiler des programmes généralistes sur GPU, dans ce cas, pourquoi ne pas remplacer les CPU par des GPU ? Pourquoi ne pas tout exécuter par des GPU ?
Mon ami n'a pas eu une réponse non équivoque à cette question. Il m'a répondu que l'intérêt du CPU reste sans doute sa faible consommation énergique par rapport au GPU.
Après ce déjeuner, j'ai fait des recherches et je suis tombé sur l'article Wikipedia nommé General-purpose computing on graphics processing units (je suis tombé dessus via l'article ROCm).
Cet article contient une section nommée GPU vs. CPU, mais qui ne répond pas à mes questions à ce sujet 🤷♂️.
ROCm ?
Question : J'ai du mal à comprendre ROCm, j'ai l'impression que cela apporte le support du framework CUDA sur AMD, c'est bien cela ?
Réponse : oui.
J'ai ensuite lu ici :
HIPIFY is a source-to-source compiling tool. It translates CUDA to HIP and reverse, either using a Clang-based tool, or a sed-like Perl script.
RAG ?
Question : comment setup facilement un RAG ?
Réponse : regarde llama_index.
#JaiDécouvert ensuite https://github.com/abetlen/llama-cpp-python
Simple Python bindings for @ggerganov's llama.cpp library. This package provides:
- Low-level access to C API via ctypes interface.
- High-level Python API for text completion
- OpenAI-like API
- LangChain compatibility
- LlamaIndex compatibility
- ...
dottextai / outlines
Il m'a partagé le projet https://github.com/outlines-dev/outlines alias dottxtai, pour le moment, je ne sais pas trop à quoi ça sert, mais je pense que c'est intéressant.
Embedding ?
Question : Thibault Neveu parle souvent d'embedding dans ses vidéos et j'ai du mal à comprendre concrètement ce que c'est, tu peux m'expliquer ?
Le vrai terme est Word embedding et d'après ce que j'ai compris, en simplifiant, je dirais que c'est le résultat d'une "sérialisation" de mots ou de textes.
#JaiDécouvert ensuite l'article Word Embeddings in NLP: An Introduction (from) que j'ai survolé. #JaimeraisUnJour prendre le temps de le lire avec attention.
Transformers ?
Question : et maintenant, peux-tu me vulgariser le concept de transformer ?
Réponse : non, je t'invite à lire l'article Natural Language Processing: the age of Transformers.
Entrainement décentralisé ?
Question : existe-t-il un système communautaire pour permettre de générer des modèles de manière décentralisée ?
Réponse - Oui, voici quelques liens :
- BigScience Research Workshop/
- Distributed Deep Learning in Open Collaborations
- Deep Learning over the Internet: Training Language Models Collaboratively
Au passage, j'ai ajouté https://huggingface.co/blog/ à mon agrégateur RSS (miniflux).
La suite…
Nous avons parlé de nombreux autres sujets sur cette thématique, mais j'ai décidé de m'arrêter là pour cette note et de la publier. Peut-être que je publierai la suite un autre jour 🤷♂️.
Journaux liées à cette note :
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
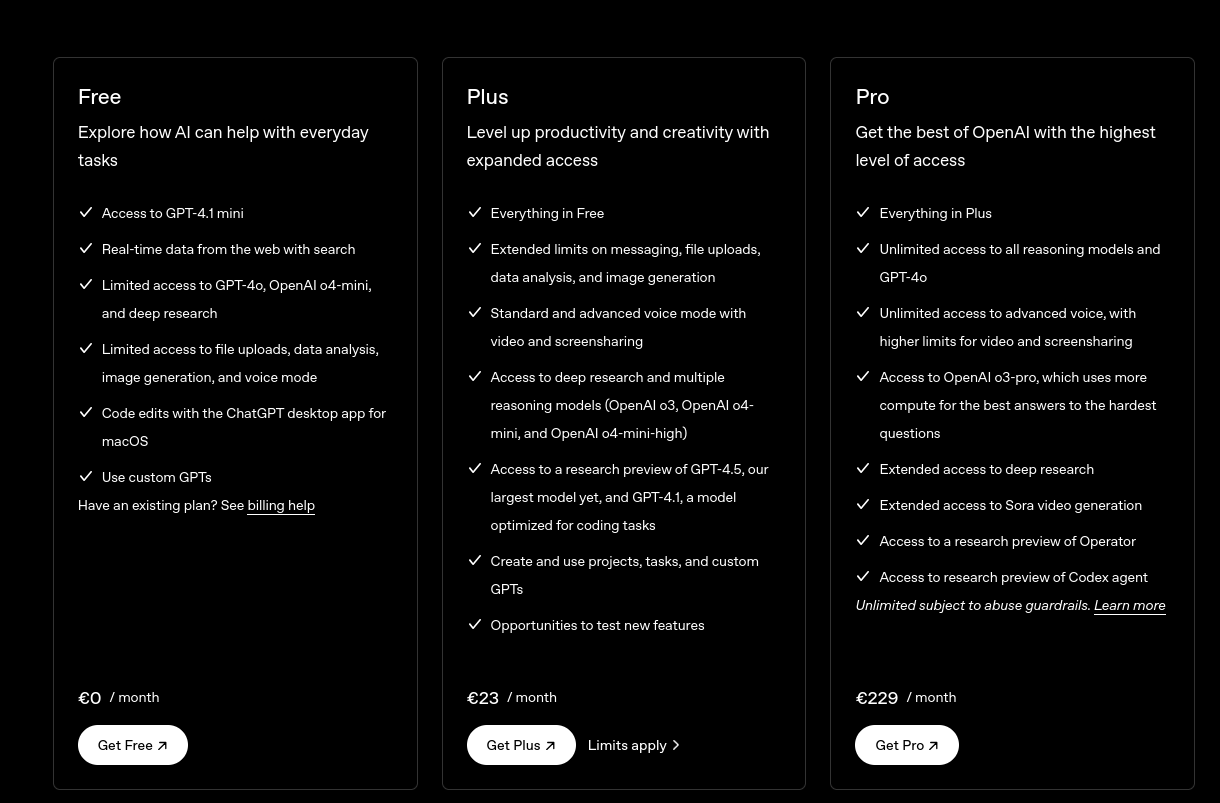
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
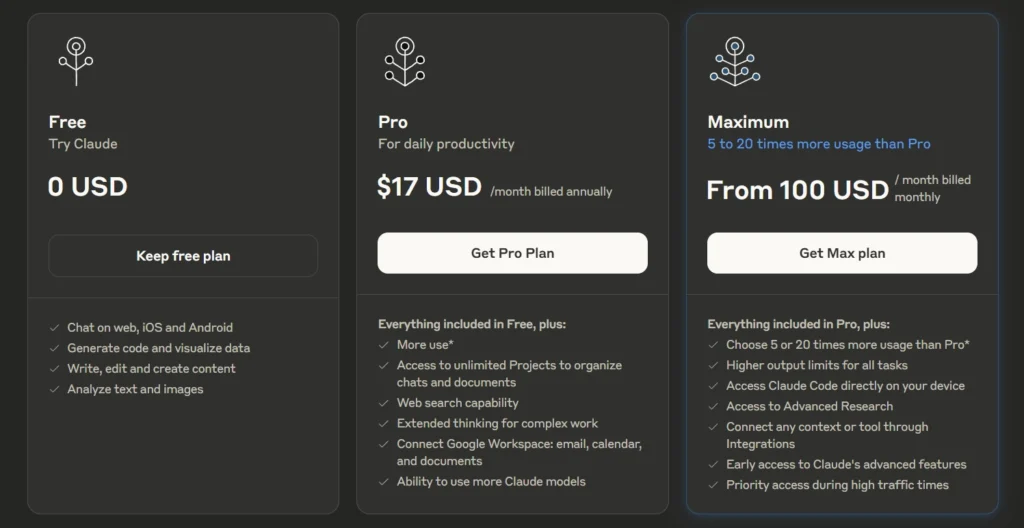
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
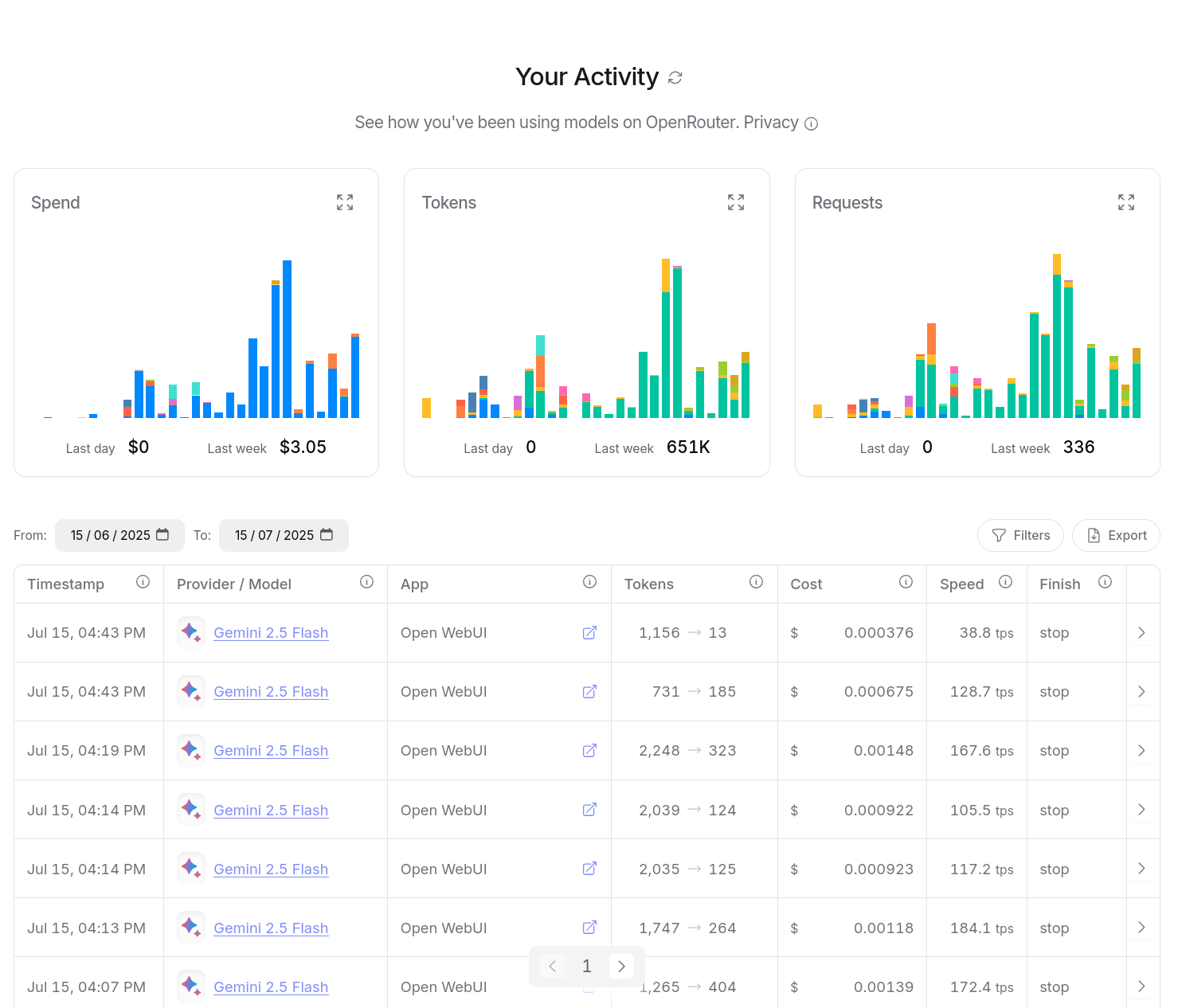
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
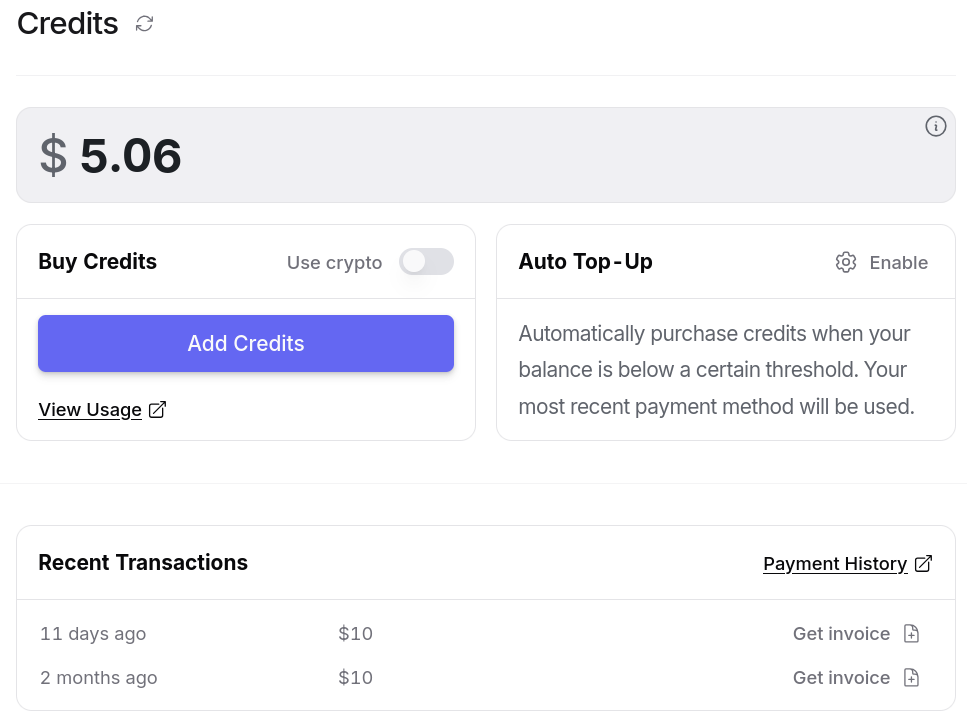
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
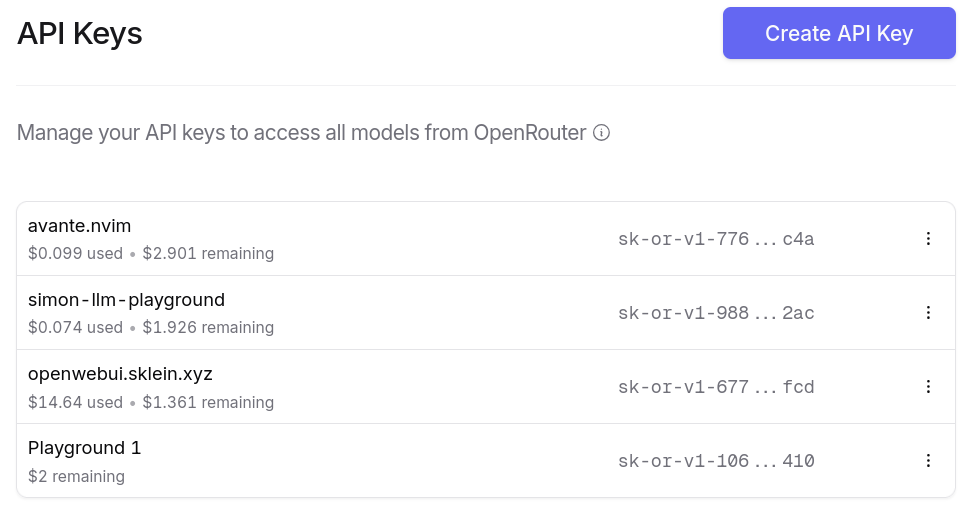
Tout ceci est configurable dans l'interface web de OpenRouter :
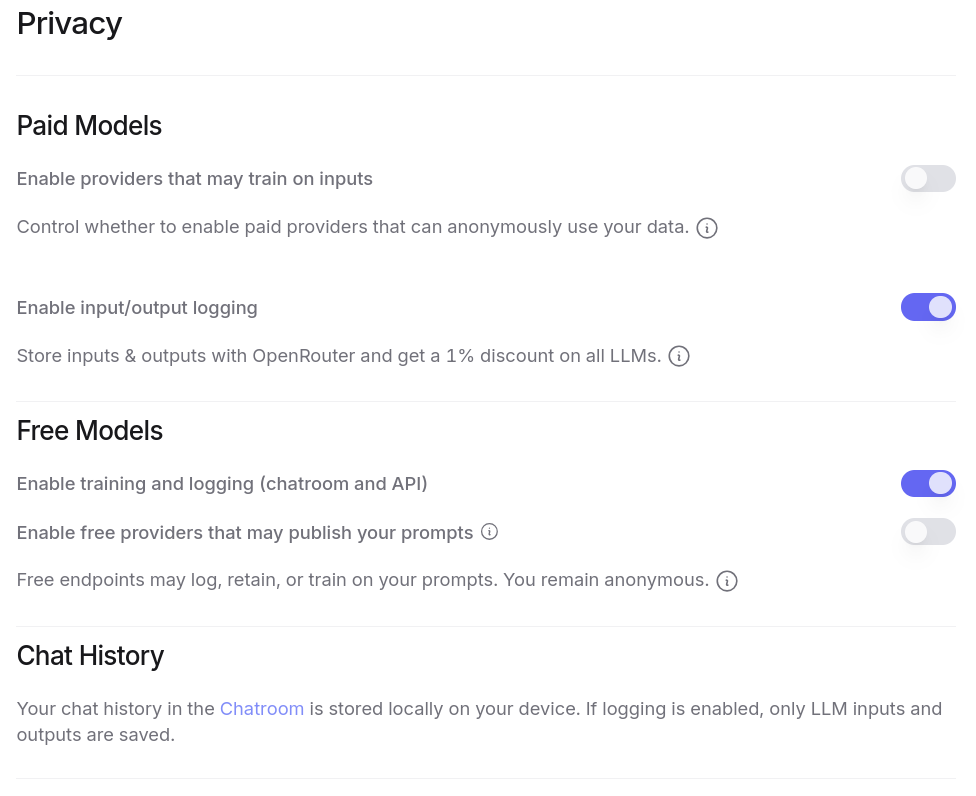
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Journal du dimanche 07 juillet 2024 à 15:11
L'année dernière, j'ai publié poc-api-gpt-generate-demo-datas, dont le but était de générer du contenu fictif pour un blog avec l'API de OpenAI.
J'étais moyennement satisfait du résultat, en particulier au niveau de la définition des contraintes de rendu : un fichier JSON.
Aujourd'hui, j'aimerais essayer de générer du contenu fictif d'un knowlege management system, créé par Obsidian, que j'aimerais utiliser pour le projet obsidian-vault-to-apache-age-poc.
Pour réaliser ce projet, j'aimerais essayer de mettre en œuvre :
- Outlines et/ou DotTXT AI (mentionné dans la note du 2024-06-06_1047)
- Replicate.com
Je viens de créer le Projet 10.
Journal du samedi 08 juin 2024 à 10:35
Dans 2024-06-06_1047 #JaiDécidé d'utiliser le terme Inference Engines pour définir la fonction ou la catégorie de llama.cpp.
J'ai échangé avec un ami au sujet des NPU et j'ai dit que j'avais l'impression que ces puces sont spécialés pour exécuter des Inference Engines, c'est-à-dire, effectuer des calculs d'inférence à partir de modèles.
Après vérification, dans cet article je lis :
An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed to accelerate artificial intelligence and machine learning applications, including artificial neural networks and machine vision.
et je comprends que mon impression était fausse. Il semble que les NPU ne sont pas seulement dédiés aux opérations d'exécution d'inférence, mais semblent être optimisés aussi pour faire de l'entrainement 🤔.
Un ami me précise :
Inference Engines
Pour moi, c'est un terme très générique qui couvre tous les aspects du machine learning, du deep learning et des algorithmes type LLM mis en œuvre.
et il me partage l'article Wikipedia Inference engine que je n'avais pas lu quand j'avais rédigé 2024-06-06_1047, honte à moi 🫣.
Dans l'article Wikipedia Inference engine je lis :
In the field of artificial intelligence, an inference engine is a software component of an intelligent system that applies logical rules to the knowledge base to deduce new information.
et
Additionally, the concept of 'inference' has expanded to include the process through which trained neural networks generate predictions or decisions. In this context, an 'inference engine' could refer to the specific part of the system, or even the hardware, that executes these operations.
Je comprends qu'un Inference Engines n'effectue pas l'entrainement de modèles.
Pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Le contenu de l'article Wikipedia Llama.cpp augmente mon niveau de confiance dans ce choix de vocabulaire :
llama.cpp is an open source software library written in C++, that performs inference on various Large Language Models such as Llama
Journal du jeudi 06 juin 2024 à 16:20
En travaillant sur 2024-06-06_1047 :
- #JaiDécouvert https://github.com/PABannier/bark.cpp - Suno AI's Bark model in C/C++ for fast text-to-speech (from)
- #JaiDécouvert https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from)
- #JaiLu au sujet de GGUF :
Hugging Face Hub supports all file formats, but has built-in features for GGUF format, a binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes. GGUF is designed for use with GGML and other executors. GGUF was developed by @ggerganov who is also the developer of llama.cpp, a popular C/C++ LLM inference framework.
https://huggingface.co/docs/hub/gguf
- #JaiDécouvert llama : add pipeline parallelism support by slaren autrement dit « Multi-GPU pipeline parallelism support » (from)
- #JaiDécouvert https://github.com/ggerganov/whisper.cpp de Georgi Gerganov
- #JaiDécouvert https://github.com/ggerganov/llama.cpp/discussions/3471
- #JaiDécouvert la Merge Request d'ajout du support de ROCm Port : ROCm Port 1087 (from)
- #JaiDécouvert Basic Vim plugin for llama.cpp
- #JaiDécouvert https://github.com/rgerganov/ggtag par le même auteur que llama.cpp, c'est-à-dire Georgi Gerganov
- #JaiDécouvert Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- #JaiDécouvert : d'après ce que j'ai compris la librairie ggml est le composant de base de llama.cpp et Whisper.cpp
- #JaiDécouvert que Georgi Gerganov a lancé sa société nommée https://ggml.ai (from) et que celle-ci est financé entre autre part Nat Friedman ! Ha ha, encore lui 😍.
ggml.ai is a company founded by Georgi Gerganov to support the development of ggml. Nat Friedman and Daniel Gross provided the pre-seed funding.
We are currently seeking to hire full-time developers that share our vision and would like to help advance the idea of on-device inference. If you are interested and if you have already been a contributor to any of the related projects, please contact us at jobs@ggml.ai
- #JaiDécouvert Text-to-phoneme-to-speech https://twitter.com/ConcreteSciFi/status/1641166275446714368, j'adore 🙂