
YAML
Journaux liées à cette note :
J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR
Introduction
Après trois ans à repousser ce projet, je me suis enfin lancé en janvier 2026 dans la création de paquets RPM pour Fedora COPR.
J'ai créé et publié les packages aichat-git (repository) et text-to-audio (repository). L'expérience a été beaucoup plus simple et rapide que je le pensais. Les agents IA simplifient certes ce genre de tâche, mais même sans eux, le code reste plutôt minimaliste.
Pourquoi est-ce que je me suis intéressé à ce sujet ? Au départ, c'était pour distribuer qemu-compose sous forme de package RPM (voir issue).
Pour bien maîtriser ces opérations, la semaine dernière, je suis reparti de zéro et j'ai implémenté et publié le playground : fedora-rpm-copr-playground. Voici les objectifs de ce playground :
- Générer un package pour distribuer un simple script Bash qui affiche un "Hello world" (dans la branche
bash). - Générer un package pour distribuer une application Golang qui affiche un "Hello world" (dans la branche
golang)
Pour chacun de ces packages, j'ai testé trois méthodes de build :
- build du package RPM 100% local
- build du package SRPM en local, puis upload sur Fedora COPR qui génère les RPM pour plusieurs plateformes et architectures (x86_64, aarch64, etc.)
- une méthode basée à 100% sur Fedora COPR à partir des sources d'un dépôt GitHub, déclenchée automatiquement par un script GitHub Actions
Cette note documente ce playground et rassemble les difficultés que j'ai rencontrées. Le README.md reste consultable si vous préférez suivre un exemple pas à pas.
Le fichier .spec
Le point central pour créer un package RPM est le fichier .spec /rpm/hello-bash.spec :
#
Name: hello-bash
Version: 1.0.7
Release: 1%{?dist}
Summary: A simple Hello World bash script
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: hello-bash
BuildArch: noarch
%description
A simple "Hello World" Bash script packaged as an RPM for Fedora COPR.
%prep
# Nothing to prepare, source is ready
%build
# Nothing to build, it's a bash script
%install
mkdir -p %{buildroot}/%{_bindir}
cp %{SOURCE0} %{buildroot}/%{_bindir}/hello-bash
chmod 755 %{buildroot}/%{_bindir}/hello-bash
%files
%{_bindir}/hello-bash
%changelog
* Thu Mar 19 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les lignes importantes dans ce fichier :
BuildArch: noarch, étant donnée que c'est un simple script, ce package n'est pas dépendant de l'architecture (processeur).- La section
%install - La section
%files
La syntaxe du format .spec peut sembler étrange en 2026. Elle date de 1995 — avant même l'existence de YAML (2001) et JSON (1999). Cette ancienneté explique les %... et %{...} qui peuvent paraitre cryptiques aujourd'hui.
Historiquement, le champ Source0 pointe vers une archive (généralement un tar.gz), contenant les sources du projet. Pour des cas simples, comme ici avec le script Bash, Source0 peut directement référencer le fichier source.
J'ai aussi implémenté une variante bash-multifiles dans le playground, pour tester le packaging de plusieurs scripts accompagnés d'un fichier de documentation. J'y indique les fichiers via Source0:, Source1:, Source2:, puis je les copie dans %install avec %{SOURCE0}, %{SOURCE1}, %{SOURCE2}. Cela fonctionne correctement, bien qu'au-delà de trois ou quatre fichiers, je pense qu'il soit probablement plus pratique d'utiliser une archive.
Build local du package RPM
Le script /build.sh suivant permet de générer un package RPM :
#!/bin/bash
set -e
TOPDIR="$(pwd)/rpmbuild"
mkdir -p "$TOPDIR"/{BUILD,RPMS,SRPMS,SOURCES,SPECS}
echo "Copying source to SOURCES..."
cp hello-bash "$TOPDIR/SOURCES/"
echo "Building RPM..."
rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec
echo ""
echo "Build complete!"
echo "RPM: $TOPDIR/RPMS/noarch/"
Il commence par préparer la structure de dossier suivante :
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
├── SPECS
└── SRPMS
Ensuite les fichiers à packager sont copiés dans rpmbuild/SOURCES
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
Pour finir, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec génère à la fois le package SRPM (source RPM) et le RPM binaire. L'option -ba signifie "build all". Pour générer uniquement le SRPM, il faudrait utiliser -bs (build source). Ici, comme le package contient un script Bash, il est de type noarch :
/rpmbuild/
├── BUILD
├── RPMS
│ └── noarch
│ └── hello-bash-1.0.7-1.fc42.noarch.rpm
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
└── hello-bash-1.0.7-1.fc42.src.rpm
Publication sur Fedora COPR
Le playground contient un second script qui permet de publier le package sur Fedora COPR, ce qui permet de rendre accessible publiquement son package.
Voici comment cette méthode fonctionne. Tout d'abord, il faut créer un compte et un projet sur Fedora COPR. Dans le playground, j'ai implémenté le script init-copr-project.sh basé sur copr-cli, qui me permet d'automatiser la création du projet (paradigme GitOps).
$ copr-cli create "hello-bash" \
--description "A simple Hello World Bash script packaged as an RPM (auto-build on tags)" \
--chroot fedora-42-x86_64 \
--chroot fedora-43-x86_64 \
--chroot fedora-44-x86_64
Dans cet exemple, je demande à COPR de builder les packages du projet pour les distributions fedora-42-x86_64, fedora-43-x86_64, fedora-44-x86_64.
Après avoir configuré le projet COPR, je lance le script /build-copr.sh qui exécute :
copr-cli build "hello-bash" /rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
Le premier paramètre "hello-bash" est le nom du projet et le second est le package source SRPM préalablement construit localement par le script /build.sh.
Voici ce que donne l'exécution de ./build-copr.sh côté cli :
$ ./build-copr.sh
...
Build complete!
RPM: /home/stephane/git/github.com/stephane-klein/fedora-rpm-copr-playground/.worktree/bash/rpmbuild/RPMS/noarch/
Uploading package ./rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
|################################| 8.5 kB 47.1 kB/s eta 0:00:00
Build was added to hello-bash:
https://copr.fedorainfracloud.org/coprs/build/10252699
Created builds: 10252699
Watching build(s): (this may be safely interrupted)
08:59:15 Build 10252699: pending
08:59:45 Build 10252699: running
09:00:15 Build 10252699: starting
09:00:46 Build 10252699: running
Voici ce qui est visible sur l'interface web de COPR, https://copr.fedorainfracloud.org/coprs/stephaneklein/hello-bash/builds/ :
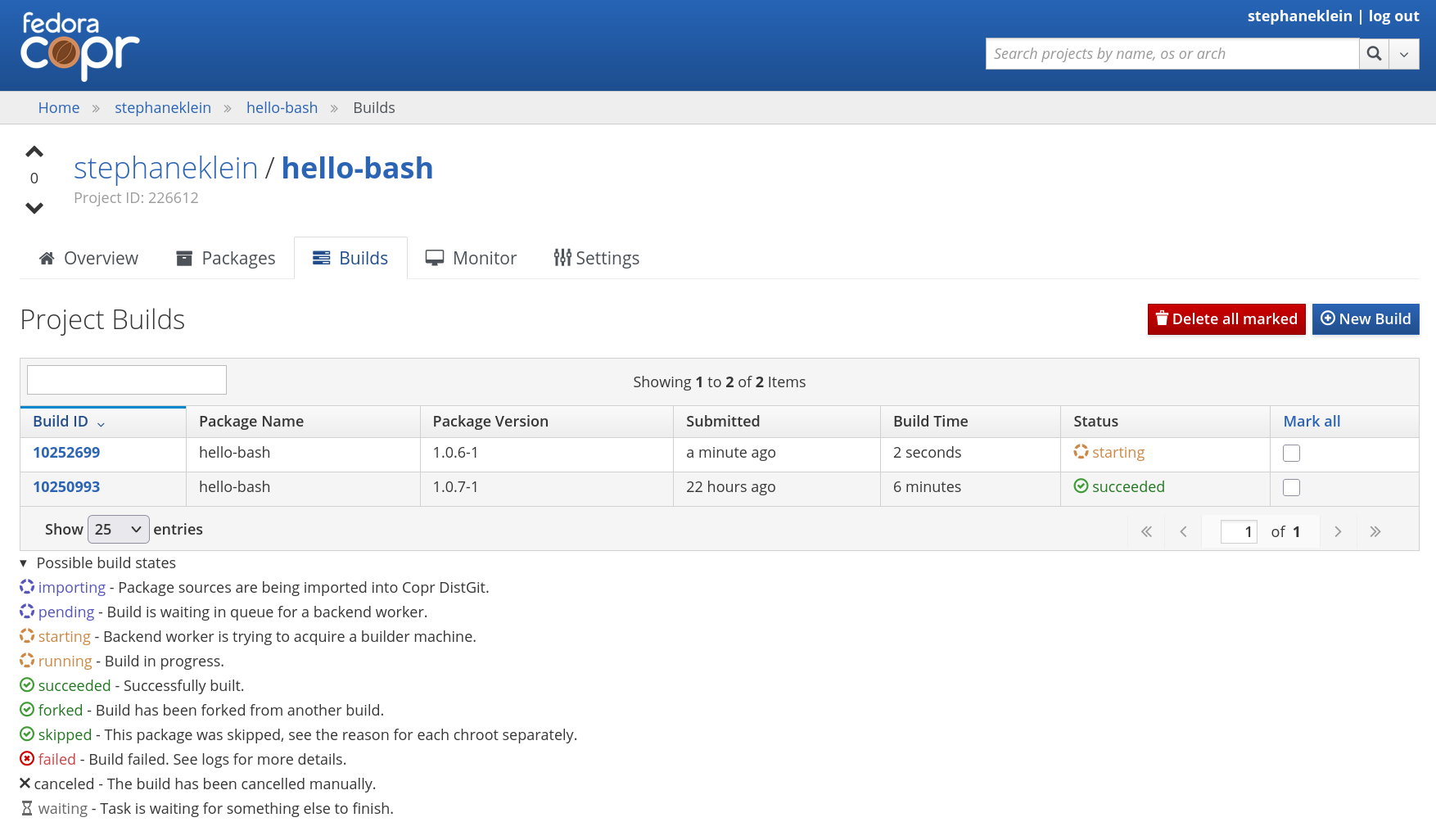
Une fois le build des packages terminé, il est facile d'installer le package avec les commandes suivantes :
$ sudo dnf copr enable -y stephaneklein/hello-bash
$ sudo dnf install -y hello-bash
$ hello-bash
Hello World
Automatisation GitOps avec COPR
Et pour finir, j'ai implémenté dans le playground l'automatisation complète de la compilation et publication des packages sur l'infrastructure COPR.
Pour cela, dans le script init-copr-project.sh j'ai déclaré l'URL du repository qui contient le code source :
...
copr-cli add-package-scm "$COPR_PROJECT" \
--name hello-bash \
--clone-url https://github.com/stephane-klein/fedora-rpm-copr-playground.git \
--commit bash \
--subdir . \
--spec rpm/hello-bash.spec \
--type git \
--method make_srpm \
--webhook-rebuild on
Le paramètre --commit bash permet de définir la branche Git à utiliser comme source.
Le paramètre --method make_srpm, qui permet à l'utilisateur d'utiliser un script personnalisé de génération du SRPM, à placer dans /.copr/Makefile à la racine du dépôt avec une cible srpm, exemple :
specfile = rpm/hello-bash.spec
.PHONY: srpm
srpm: $(specfile)
mkdir -p /tmp/copr-srpm-build
cp rpm/hello-bash.spec /tmp/copr-srpm-build/hello-bash.spec
cp -r . /tmp/copr-srpm-build/source/
cd /tmp/copr-srpm-build && \
rpmbuild -bs hello-bash.spec \
--define "_topdir /tmp/copr-srpm-build/rpmbuild" \
--define "dist .fc42" \
--define "_sourcedir /tmp/copr-srpm-build/source"
cp /tmp/copr-srpm-build/rpmbuild/SRPMS/*.src.rpm $(outdir)
Je ne souhaite pas détailler ici d'autres méthodes comme tito ou Packit, mais la méthode make_srpm est la plus flexible, elle permet de contrôler entièrement comment le SRPM est construit.
Une fois tout ceci configuré, il est possible de rebuild le package directement en cliquant sur le bouton "Rebuild" sur l'interface web de COPR :
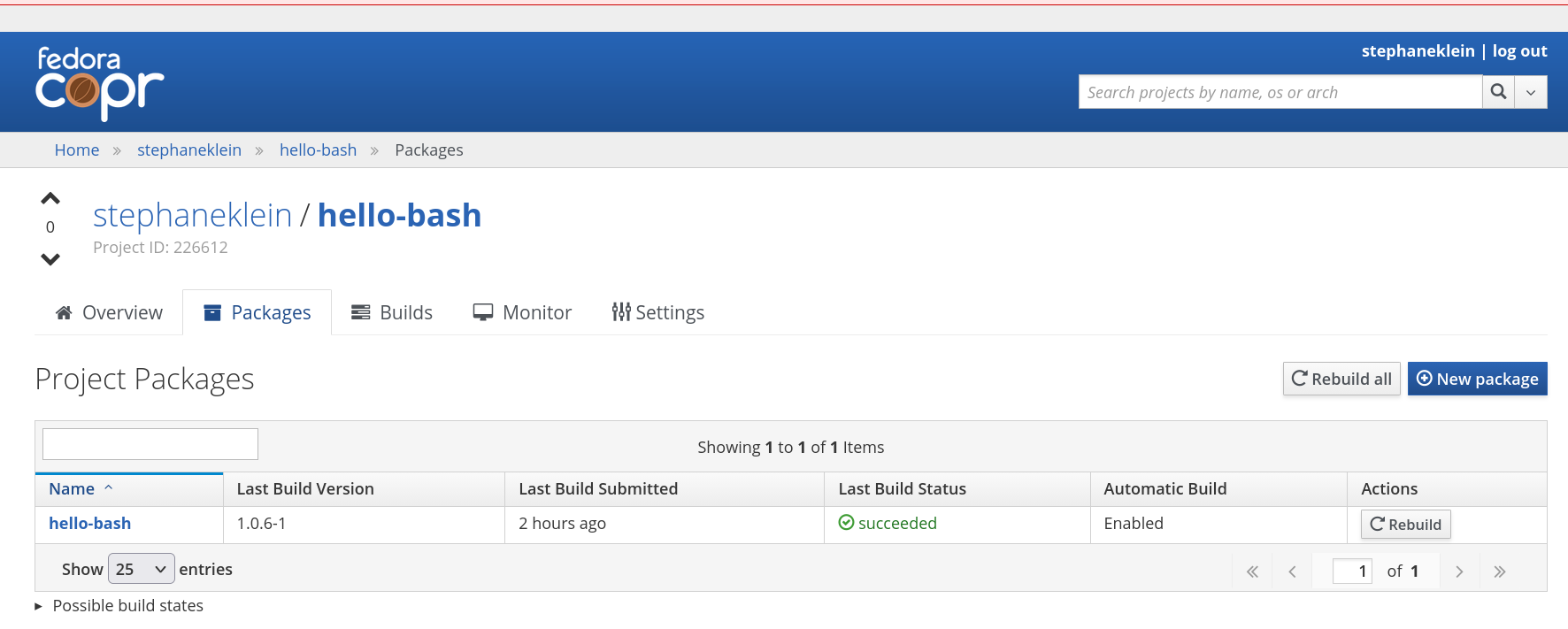
Dernière étape : j'ai implémenté un build automatique qui est déclenchée par un appel curl dans le job GitHub Actions /.github/workflows/trigger-copr-build.yml, dont voici le contenu :
name: Trigger Copr Build
on:
push:
tags:
- '*'
jobs:
trigger-copr-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Verify tag is on bash branch
run: |
if ! git branch -r --contains ${{ github.ref_name }} | grep -q "origin/bash"; then
echo "Tag ${{ github.ref_name }} is not on branch bash"
exit 1
fi
- name: Trigger Copr webhook
run: |
curl -X POST https://copr.fedorainfracloud.org/webhooks/custom/226325/3cf20247-820b-4050-bfb1-593b01a6996f/hello-bash/
Ce job est exécuté à chaque publication d'un nouveau Git tag, suivi d'une vérification que le tag provient bien de la branche bash.
Claude Sonnet 4.6 m'a suggéré l'existence d'une méthode de polling de dépôt Git intégrée à COPR, mais je n'ai trouvé aucune trace de celle-ci dans la documentation.
J'ai aussi essayé d'utiliser la méthode basée sur les webhooks GitHub de COPR, mais je n'ai pas réussi à la faire fonctionner. L'interface de GitHub m'indiquait à chaque fois une erreur dans la réponse des calls HTTP. C'est pour cela que j'ai fini par déclencher le webhook custom via un job GitHub Actions.
Package d'un projet en Golang
Le playground contient aussi le packaging d'une application en Golang, consultable dans la branche golang.
Voici le contenu du fichier /golang/rpm/hello-golang.spec :
Name: hello-golang
Version: 1.0.10
Release: 1%{?dist}
Summary: A simple Hello World Go application
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: %{name}-%{version}.tar.gz
BuildRequires: golang >= 1.21
%description
A simple "Hello World" Go application packaged as an RPM for Fedora COPR.
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
%install
mkdir -p %{buildroot}%{_bindir}
cp %{name} %{buildroot}%{_bindir}/
%files
%{_bindir}/%{name}
%changelog
* Fri Mar 20 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les principales différences avec la version pour Bash :
- Absence de
BuildArch: noarch - Présence de
BuildRequires: golang >= 1.21 - Et l'ajout des instructions suivantes :
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
Peu de changement au niveau du script /build-rpm-locally.sh, qui génère ces fichiers :
rpmbuild
├── BUILD
├── RPMS
│ └── x86_64
│ ├── hello-golang-1.0.10-1.fc42.x86_64.rpm
│ ├── hello-golang-debuginfo-1.0.10-1.fc42.x86_64.rpm
│ └── hello-golang-debugsource-1.0.10-1.fc42.x86_64.rpm
├── SOURCES
│ ├── hello-golang-1.0.10
│ │ ├── go.mod
│ │ └── main.go
│ └── hello-golang-1.0.10.tar.gz
├── SPECS
└── SRPMS
└── hello-golang-1.0.10-1.fc42.src.rpm
Cette fois, plus rien dans le dossier RPMS/noarch/, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-golang.spec build le package pour la distribution de la workstation du développeur.
Pour le reste, je n'ai pas identifié de différence majeure entre la version Bash et la version Golang
La suite… méthode Tito et Packit
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour stephane-klein/fedora-rpm-copr-playground pour les tester et ensuite publier une nouvelle note de compte rendu.
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows".
Première version de CoreOS Container Linux en 2013
La première version de CoreOS Container Linux sortie en 2013 utilisé la méthode A/B (seamless) system updates inspirée de manière transparente à Chrome OS :
Upgrading CoreOS is a bit different than the usual distros. Our update system is based on ChromeOS. The big difference is that we have two root partitions; lets call them root A and root B. Initially your system is booted into the root A partition and CoreOS begins talking to the update service to find out about new updates. If there is an update available it is downloaded and installed to root B.
D'après ce repository coreos/coreos-overlay, CoreOS Container Linux était basé sur les packages de Gentoo.
Première version d'Ignition en 2016
En avril 2016, l'équipe CoreOS a publié la première version de ignition, outil toujours utilisé en 2025 par Fedora CoreOS.
Ignition is a utility created to manipulate disks during the initramfs. This includes partitioning disks, formatting partitions, writing files (regular files, systemd units, etc.), and configuring users. On first boot, Ignition reads its configuration from a source of truth (remote URL, network metadata service, hypervisor bridge, etc.) and applies the configuration.
ignition est un système qui ressemble à cloud-init, mais qui est exécuté seulement une seule fois, lors du premier boot et est lancé en tout premier, avant même systemd.
Depuis 2019, les fichiers json ignition ne sont plus édités manuellement grâce à l'outil butane qui convertit des fichiers YAML butane en fichiers json ignition.
Voici la documentation de butane qui vous permet de voir les actions que peut effectuer ignition : https://coreos.github.io/butane/specs/.
À la différence de cloud-init, ignition fonctionne à un niveau plus bas. La spec Butane Fedora CoreOS v1.6.0 permet par exemple de configurer les partitions, le Raid, LUKS encryption…
Voici dans mon playground un exemple de son utilisation : atomic-os-playground/create-coreos-custom-iso.sh.
Note suivante : "2014-2018 approche alternative avec Atomic Project".
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
Une extension browser pour exporter ses threads Claude.ia et ChatGPT
Actuellement, et à ma connaissance, les APIs de Claude.ai et ChatGPT ne proposent pas de fonctionnalité d'export de l'historique des conversations de leur interface web de chat.
J'imagine deux approches pour réaliser cet export malgré tout : développer un script qui réalise une forme de Web Scraping ou intégrer cette fonctionnalité directement dans une extension navigateur plutôt que dans un script autonome. L'extension browser présente l'avantage de simplifier la gestion de l'authentification.
Après 30 minutes de recherche sur GitHub, du style "export chatgpt", j'ai trouvé claude-chatgpt-backup-extension. Cette extension permet l'export d'une ou plusieurs conversations Claude.ai et une conversation à la fois ChatGPT.
Je l'ai testée, elle fonctionne correctement 🙂.
Je viens de proposer cette Pull Request pour ajouter le support de l'export ChatGPT en mode bulk : Add bulk export feature for ChatGPT conversations.
Cette extension pourrait me servir de base de travail pour l'idée de projet "Aggregator - Backup Numeric Conversation System".
Voici les prochaines issues d'amélioration que j'imagine pour un fork de cette extension :
- Affichage conditionnel des boutons d'export Claude.ai uniquement quand l'utilisateur est connecté sur https://claude.ai/ (même principe pour ChatGPT).
- Afficher une barre de progression lors des bulk exportations.
- Proposer une option d'export au format YAML, sous une forme plus facile à lire pour les humains, avec moins d'informations techniques que le format JSON natif proposé actuellement.
- Tenter un refactoring pour simplifier la base de code actuelle.
- Développer une option permettant l'export vers des services Object Storage qui implémentent l'API S3.
- Créer un mock serveur API REST et permettre l'export des données vers ce serveur.
Journal du mercredi 11 décembre 2024 à 11:22
#JaiDécouvert ArchieML (https://archieml.org/) qui est un markup language créé en 2015 par Michael Strickland qui travaille chez The New York Times.
Mon premier sentiment a été « pourquoi ne pas utiliser du Markdown ».
Ensuite, en lisant la documentation, j'ai compris que ce markup language était utilisé pour renseigner des valeurs dans différents champs. Comme le dit la documentation, ArchieML est une alternative à JSON ou YAML.
En explorant la section « Why not YAML? Or JSON? », j'ai compris la philosophie fondamentale d'ArchieML : offrir un langage de balisage qui soit particulièrement tolérant aux erreurs de syntaxe, notamment concernant l'indentation.
Cette approche répond spécifiquement aux besoins des journalistes qui, contrairement aux développeurs, ne sont généralement pas familiers avec les conventions strictes d'indentation que l'on trouve dans d'autres langages de balisage.
Ensuite, je me suis demandé : « Pourquoi ne pas demander aux journalistes de saisir leur article dans une page d'édition web, qui présente différents champs bien distincts ? ».
Je pense que la réponse se trouve ici :
And finally, because we make extensive use of Google Documents's concurrent-editing features…
Tout comme j'aime travailler avec des documents "plain text", peut-être que les journalistes préfèrent finalement travailler sur de simples documents textes plutôt qu'une page web d'édition, pour des raisons de rapidité d'utilisation : copier-coller rapide, fonctionnalité de commentaire collaboratif de Google Docs…
Je découvre dans la section ressources différentes librairies d'intégration à Google Docs.
Je découvre aussi que ArchieML est utilisé par d'autres journaux :
- Quartz
- The Atlanta Journal-Constitution
- Fusion
- The Wall Street Journal
Au final, je n'ai pas d'opinion définitive au sujet de cette méthode d'édition d'article 🤔.
Journal du mercredi 11 septembre 2024 à 09:28
#JaiDécouvert NestedText (from).
Même en lisant la section Alternatives - YAML, je ne comprends pas encore précisément l'intérêt du projet. Je ne trouve pas YAML plus simple que NestedText.