
Basecamp
Journaux liées à cette note :
Alexandre m'a partagé le chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp publié en 2019.
Il sait que j'apprécie cette méthode — j'ai lu le livre vers 2021-2022 — et me l'a envoyé parce qu'il ne comprend pas bien comment je peux adhérer à cette méthode alors qu'elle semble aller à l'encontre de ce qu'on a pratiqué ensemble.
Tout d'abord, je commence par préciser que Shape Up semble mélanger les notions de issue tracker et Product Backlog (voir note "Confusion entre issue tracker et backlog, et comment gérer la masse d'issues").
Ensuite, la méthode ne dit pas "no backlog", mais "no backlog commun" :
Des listes décentralisées
On n'a pas à choisir entre un backlog encombrant et ne rien retenir du passé. Chacun peut continuer à suivre pitchs, bugs, demandes ou idées de son côté, sans liste centrale.
Le support peut maintenir une liste des demandes ou problèmes qui reviennent souvent. Le produit suit les idées qu'il espère pouvoir façonner dans un cycle futur. Les développeurs tiennent une liste de bugs qu'ils aimeraient corriger dès qu'ils en ont l'occasion. Il n'y a ni backlog unique ni liste centrale, et aucune de ces listes n'alimente directement le processus des paris.
Shape Up ne m'apparaît pas comme une méthode qui interdit de partager des listes d'issues entre sous-groupes — c'est visible quand le texte dit que « le produit suit les idées qu'il espère pouvoir façonner dans un cycle futur » et que « les développeurs tiennent une liste de bugs qu'ils aimeraient corriger dès qu'ils en ont l'occasion ».
Ce qui me semble central dans Shape Up, ce n'est probablement pas tant le rejet d'un issue tracker commun. À mon sens, le cœur de la méthode réside ici :
Quelques paris potentiels
Que fait-on à la place ? Avant chaque cycle de six semaines, on organise une table des paris (betting table) où les parties prenantes décident ce qu'elles vont faire dans le cycle suivant. À cette table, on examine les pitchs des six dernières semaines — ou ceux que quelqu'un a délibérément ressortis et défendus à nouveau.
Rien d'autre n'est sur la table. Pas de longue liste d'idées à passer en revue. Pas de temps perdu à entretenir un backlog d'anciennes idées.
Cela signifie que si une issue n'a pas de "sponsor", c'est-à-dire, personne qui la met en avant, alors elle ne sera jamais priorisée. Les pitchs sont examinés à la betting table, mais Shape Up n'a pas de process continu de revue des issues en tant que backlog.
C'est pour moi l'idée la plus importante de ce chapitre par rapport à Scrum "mainstream" et cela ne me perturbe pas, car dans ma pratique Scrum, comme je le disais dans une précédente note, une issue sans sponsor n'a pratiquement aucune chance d'être sélectionnée lors d'un Sprint Planning :
Le triage régulier des issues (fermer et prioriser) est un travail laborieux, extrêmement difficile à maintenir dans la durée dès lors qu'un issue tracker contient beaucoup d'issues. Si je peux témoigner d'une chose, c'est que je n'ai probablement jamais réussi à le faire, ni vu quelqu'un y parvenir.
Imaginons un bug remonté il y a 8 mois sur l'export PDF.
- Scénario Scrum classique : le bug traîne dans le backlog, priorité "moyenne". À chaque Sprint Planning, le Product Owner fait défiler la liste, le voit, se dit "pas critique cette fois", et le repousse. Le bug survit parce qu'il est dans le système, pas parce qu'il est défendu.
- Scénario Shape Up : le bug n'existe nulle part dans un backlog central. Si un développeur pense qu'il vaut la peine d'y consacrer un cycle, il doit le re-pitcher activement à la prochaine betting table. Si personne ne le fait, le bug disparaît du radar — pas par décision active de le fermer, mais par absence de sponsor.
Dans ma pratique de Scrum, j'intègre déjà un betting table lors du Sprint Planning, et seules les issues proposées au sprint par un sponsor sont étudiées, par conséquent, cela me semble assez proche de ce que propose Shape Up.
Je préfère Shape Up à Scrum sur ce point précis de la betting table : il me semble que cette approche est plus honnête et reflète probablement mieux ce qui se passe réellement sur le terrain.
Collecter les sujets dans un issue tracker pour ne pas se répéter
En essayant de répondre à une question d'un ami au sujet du chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp, j'ai cherché à mettre des mots sur les raisons qui me poussent à utiliser un issue tracker, une pratique que j'expérimente depuis plus de 15 ans. Cette note est le résultat de cette réflexion.
Pendant 5 ans, de 2018 à 2023, j'ai utilisé GitLab comme outil de issue tracker, en équipe, dans deux organisations différentes.
Avant d'aller plus loin, il me semble utile de montrer concrètement les types d'issue présentes dans ces trackers (voir aussi ces labels) :
- Bug — corriger un comportement qui ne correspond pas à ce qui est attendu
- Feature — implémenter une nouvelle fonctionnalité
- Enhancement — améliorer une capacité existante ; DoD : le comportement amélioré est mesurable ou observable
- Knowledge Gap — répondre à une question sans réponse accessible ; DoD : répondre à la question, indiquer comment trouver la réponse à cette question, si l'information n'était pas documentée, alors la documenter ou améliorer la documentation existante
- Spike — explorer une question technique ou une hypothèse incertaine dans un temps imparti ; DoD : du code est livré, une décision binaire est posée (concluante / non concluante) et documentée dans l'issue
- Enabler — préparer le terrain technique pour qu'une ou plusieurs issues futures soient implémentables en moins de 10h ; DoD : mergé sur main sans régression, les issues qu'il débloque sont identifiées
- User story développeur — exprimer un besoin d'infrastructure ou d'outillage interne sous forme de user story dont le "user" est un développeur ; DoD : code produit, environnement de développement amélioré, documentation ajoutée, etc.
- meta-spec-writing — décomposer un périmètre flou en issues actionnables ; DoD : les issues enfants sont créées, estimées et prêtes pour le sprint planning
- Sprint planning — préparer et documenter une session de sprint planning ; DoD : date, participants et issues candidates documentés avant la réunion, décisions prises et issues assignées documentées après
- Sprint retrospective — préparer et documenter une session de rétrospective ; DoD : date et sujets à aborder documentés avant la réunion, décisions et actions correctives documentées après, chaque action corrective génère une issue de suivi
Pourquoi je crée systématiquement une issue ?
Mon approche consiste à créer une issue dès qu'une idée, un bug ou un sujet émerge — même sans intention de le traiter immédiatement.
C'est un point qui me tient à cœur, parce qu'il m'agace profondément de voir les mêmes sujets resurgir sans cesse sans jamais être vraiment travaillés.
J'ai souvent observé dans les open spaces des conversations de 10-20 minutes autour d'un sujet où chacun y va de son opinion, de son intuition, de ses mises en garde et de ses objections, puis retourne à ses activités… pour recommencer le même débat deux jours plus tard. Tout ce qui a été dit est perdu et rarement approfondi.
Ces "conversations de couloir" récurrentes sont un symptôme classique de non-décision : personne ne bloque explicitement, personne n'avance vraiment — la discussion tourne en boucle, invisible et non tracée. Dans certains cas, elles dégénèrent en Stop Energy : les mêmes objections ressurgissent à chaque fois, épuisant le porteur de l'idée sans jamais produire de résolution.
Je préfère de loin créer l'issue avant toute conversation. À défaut, quand j'assiste à une discussion informelle qui tourne en rond, je la crée à chaud, y dépose les idées échangées, et la partage aux participants pour vérifier que j'ai bien retranscrit. La prochaine fois que le sujet resurgit, j'invite chacun à la lire et ajouter son commentaire ou voter "+1".
L'issue devient un espace formel où chacun peut argumenter et enrichir le fil à son rythme ; le Sprint Planning devient le moment de délibération légitime où l'équipe arbitre collectivement si l'issue doit être traitée dans le nouveau sprint ou non.
Cette rigueur n'est pas simple à tenir : quand l'équipe a l'habitude de tout régler à l'oral, créer une issue peut passer pour de la lourdeur bureaucratique. Je la tiens malgré tout, parce que le coût de la répétition me paraît plus élevé que celui du traçage. Surtout, à long terme, cela évite le brouillard organisationnel.
Cette utilisation d'un issue tracker s'inspire du monde du logiciel libre, où des issues peuvent rester ouvertes des années, voire des décennies, et servent de mémoire collective pour comprendre la complexité d'une demande, les trade-offs, les ressources disponibles.
Quand cette méthode est appliquée pendant plusieurs années dans une organisation, un issue tracker peut contenir des centaines voire des milliers d'issues ouvertes, mais ceci ne pose pas de problème car ces issues ne constituent pas un backlog.
Un backlog est une liste d'items extraits et sélectionnés de l'ensemble des issues de l'issue tracker — un sous-ensemble volontairement restreint et de meilleure qualité. Priorisée, maintenue à jour et régulièrement affiné, cette liste représente le travail potentiel sérieusement envisagé pour le produit. Lors du Sprint Planning, les parties prenantes — développeurs, produit et autres contributeurs concernés — discutent et arbitrent ensemble les priorités pour décider quels items intégreront le Sprint Backlog.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
2026-04-02 : étudier Beads comme source d'inspiration ou outil à intégrer.
Journal du jeudi 10 octobre 2024 à 16:39
En étudiant Loomio, #JaiDécouvert une fonctionnalité que je trouve très bien implémentée : "Démarrer la démo - Jouez avec un groupe exemple".
Cela crée automatiquement un groupe avec du "contexte" :
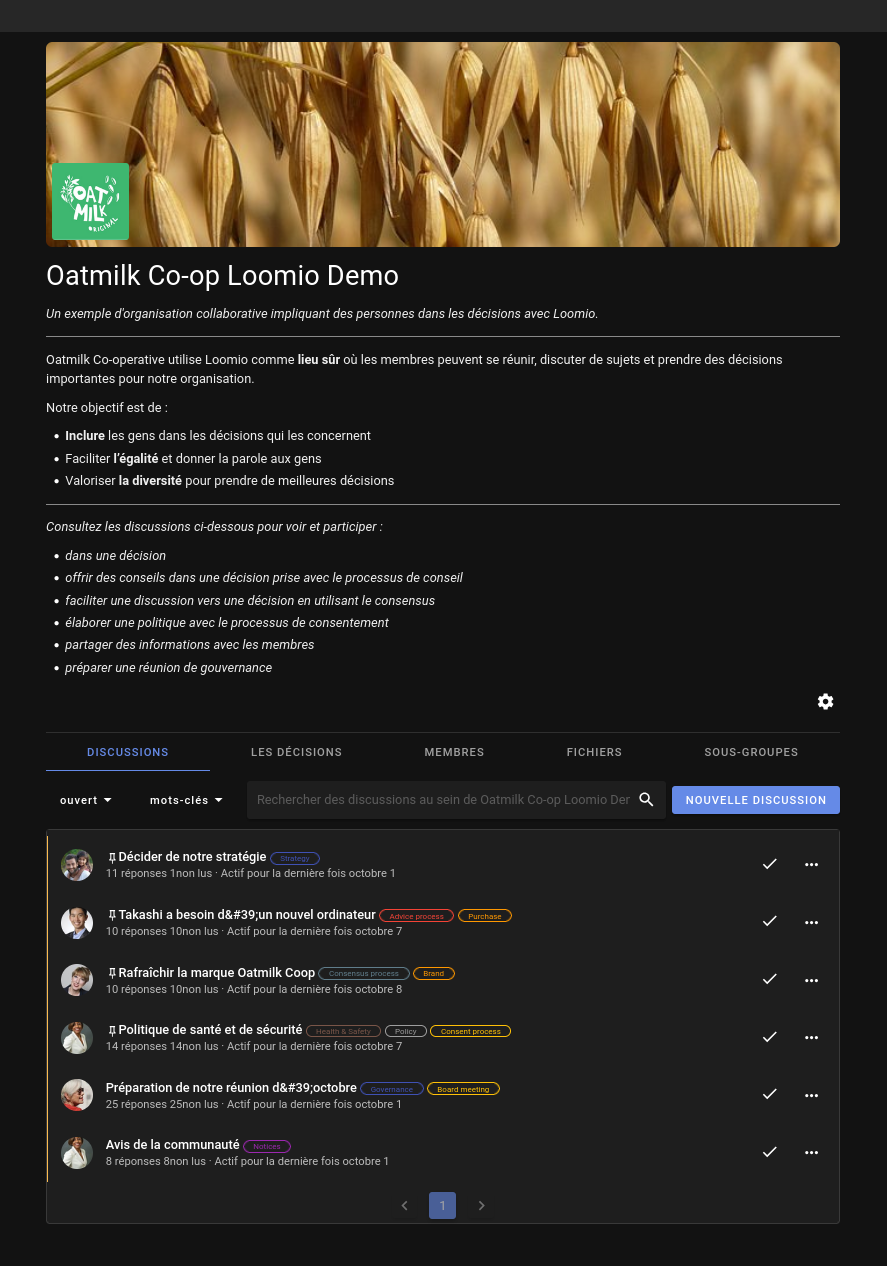
Avant cela, j'ai beaucoup aimé les "workspace" de type "sample" de Basecamp mais là, je trouve l'User experience encore meilleur. Je trouve l'entrée du menu très bien placée et très explicite.
Journal du mercredi 02 octobre 2024 à 09:55
#JaiDécouvert Kamal Proxy (from) « A minimal HTTP proxy for zero-downtime deployments » codé en Golang. Un projet Basecamp qui fonctionne avec kamal.
Cela attire ma curiosité, parce que la semaine dernière, je réfléchissais comment implémenter la fonctionnalité Skew Protection en self hosted, voir aussi 2023-07-04_1735.
Journal du mardi 10 septembre 2024 à 17:24
J'avais bien vu passer la news de sortie de Writebook, mais j'étais passé totalement à côté de la sortie du concept de Once.com de Basecamp.
Pour le moment, Once.com propose deux services de type SaaS without the aaS :
J'aime bien le concept de Finished software, cela me fait penser à Hare. J'aimerais utiliser davantage de logiciels qui ne nécessitent jamais de mises à jour, sauf pour les corrections de bugs.
Dans l'article Campfire is SaaS without the aaS, je lis :
It hasn’t even been a week since we started selling Campfire under the new ONCE model, but we’ve already sold more than quarter of a million dollars worth of this beautifully simple installable chat system.
Si c’est exact, 250 000 $ représentent 836 ventes, ce qui est vraiment impressionnant en moins d'une semaine !
Ce que j'apprécie particulièrement chez DHH, c'est son franc-parler et surtout son courage à aller à contre-courant. Par exemple, il défend le self-hosting, n’utilise pas TypeScript, et prône le SaaS without the aaS...
Obsidian ne souhaite jamais croitre au-delà de 12 personnes
#OnMaPartagé au sujet de Obsidian : https://x.com/kepano/status/1694731713686196526
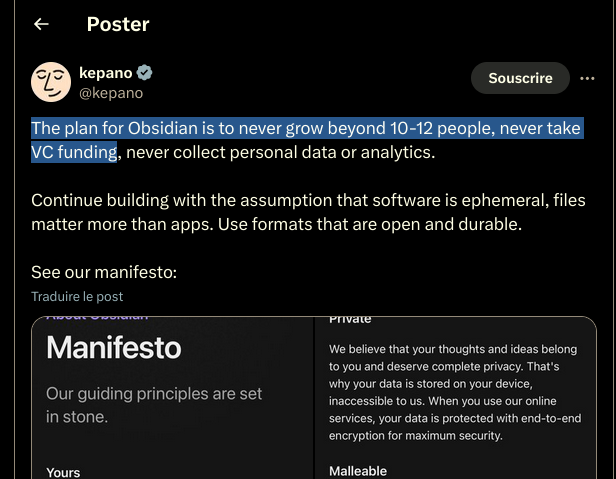
The plan for Obsidian is to never grow beyond 10-12 people, never take VC funding, never collect personal data or analytics.
#Jadore cela me fait penser à Basecamp.
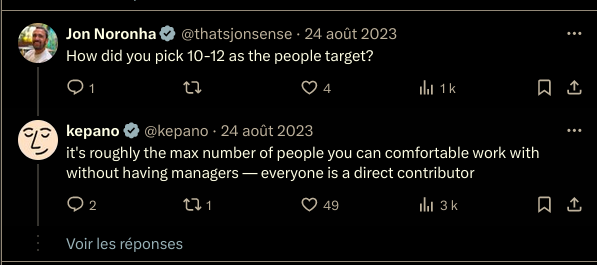
How did you pick 10-12 as the people target?
it's roughly the max number of people you can comfortable work with without having managers — everyone is a direct contributor
👍️👌
Though I don't get why you would never want to grow more than 10-12? If you could maintain everything else, wouldn't you want more people and ability to build things in parallel?
I have done it before and it's not as fun to me. For me the love is in the craft. I want to spend my time making things, not managing people. Obsidian has 0 meetings.
🙂