
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (22 notes) :
Journal du lundi 17 mars 2025 à 16:50
Suite à une discusison avec un ami, j'ai les articles Chiffrement homomorphe (https://fr.wikipedia.org/wiki/Chiffrement_homomorphe) et Searchable symmetric encryption (https://en.wikipedia.org/wiki/Searchable_symmetric_encryption).
Journal du samedi 21 décembre 2024 à 16:10
Je viens d'améliorer l'implémentation du moteur de recherche de mon sklein-pkm-engine.
Voici un screencast de présentation du résultat :
Le commit de changement : https://github.com/stephane-klein/sklein-pkm-engine/commit/71210703fe626bd455b2ec7774167d9a637e4972
Je suis passé de :
query_string: {
query: queryString,
default_field: "content_html"
}
à ceci :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Les fonctionnalités de recherche d'Elasticsearch sont nombreuses. Pour les parcourir, je conseille ce point d'entrée de la documentation Search in Depth.
Même après avoir fini mon implémentation de la fonction recherche, je dois avouer que je tâtonne sur le sujet. Je suis loin de maitriser le sujet.
Au départ, après lecture de ce paragraphe :
If you don’t need to support a query syntax, consider using the
matchquery. If you need the features of a query syntax, use thesimple_query_stringquery, which is less strict.
J'ai fait un refactoring de query_string vers simple_query_string (lien vers la documentation).
Mon objectif était d'arriver à implémenter la fonctionnalité Query-Time Search-as-You-Type avec de la recherche floue (fuzzy).
J'ai commencé par essayer la syntax foobar~* mais j'ai appris qu'il n'était pas possible d'utiliser ~ (fuzzy) en couplé avec * 😔 (documentation vers la syntax). Sans doute pour de bonnes raisons, liées à des problèmes de performance.
J'ai ensuite découpé ma requête en 3 conditions :
baseQuery.body.query.bool.must.push({
bool: {
should: [
{
simple_query_string: {
query: queryString,
fields: ["content_html"],
boost: 3
}
},
{
simple_query_string: {
query: queryString.split(' ').map(word => (word.length >= 3) ? `${word}*` : undefined).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
},
{
simple_query_string: {
query: queryString.split(' ').map(
word => {
if (word.length >= 5) { return `${word}~2`; }
else if (word.length >= 3) { return `${word}~1`; }
else return undefined;
}
).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
}
],
minimum_should_match: 1
}
}
Cette implémentation fonctionne, mais je rencontrais des problèmes de performance aléatoires que je n'ai pas pris le temps d'essayer de comprendre la cause.
À force de tâtonnement, j'ai fini par choisir la solution basée sur multi_match (documentation de référence) :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Documentation de référence du paramètre fuzziness : Fuzzy query.
Documentation de la valeur AUTO : Common options - Fuzziness
Malheureusement, ici aussi, je ne peux pas utiliser fuzziness avec phrase_prefix :
The fuzziness parameter cannot be used with the phrase or phrase_prefix type.
En finissant cette note, je viens de découvrir cet exemple dans la documentation.
J'ai l'impression de comprendre qu'en utilisant le tokenizer ngram je pourrais faire des Fuzzy Search sans utiliser l'option fuzziness 🤔.
J'ai commencé l'implémentation dans la branche ngram-tokenizer mais je m'arrête là pour aujourd'hui. En tout, ce weekend, j'ai passé 4h30 sur ce sujet 😮.
J'espère tester cette implémentation d'ici à quelques jours.
Je souhaite aussi essayer prochainement de migrer de Elasticsearch vers OpenSearch.
Journal du mercredi 27 novembre 2024 à 14:37
J'utilise SearXNG depuis avril 2024. J'adore cet outil !
Depuis cette date, j'utilise l'instance https://searx.ox2.fr malheursement cette instance ne fonctionne plus depuis 4 jours.
Pour sélectionner une nouvelle instance, je suis partie de la liste officielle suivante : https://searx.space
Mes critères de sélection :
- Support IPv6
- Version la plus récente de SearXNG
- Proche de la France
- Utime proche de 100%
- Temps de réponse
Résultat de mon premier filtre :
- https://priv.au (DE)
- https://search.sapti.me (DE)
- https://search.projectsegfau.lt (DE)
- https://www.gruble.de (DE)
- https://searx.namejeff.xyz (Suisse)
J'ai fini par choisir l'instance https://priv.au parce qu'elle propose une extension Firefox de configuration automatique : https://addons.mozilla.org/en-US/firefox/addon/searxng-priv-au/.
Attention à bien supprimer l'ancienne extension Firefox SearXNG avant d'en installer une nouvelle afin de pouvoir utiliser la nouvelle instance SearXNG.
Journal du samedi 12 octobre 2024 à 12:20
#JaiDécouvert Orama (from) qui semble être une alternative à Algolia.
Journal du mercredi 02 octobre 2024 à 10:04
#JaiDécouvert Sourcebot (from) :
Sourcebot is an open-source code search tool that allows you to quickly search across many large codebases.
C'est une alternative à Sourcegraph.
Je suis ravi de voir qu'il existe de plus en plus d'alternatives communautaires à GitHub ou GitLab, comme Forgejo, Weblate, Woodpecker CI et maintenant Sourcebot.
Journal du samedi 17 août 2024 à 15:15
En lien avec Elasticsearch, #JaiDécouvert :
- https://github.com/searchkit/searchkit
- https://opensource.reactivesearch.io/
- https://github.com/appbaseio/dejavu/
qui sont plus ou moins des équivalents à InstantSearch (from).
Journal du samedi 17 août 2024 à 12:53
Ce matin, j'ai enfin pris le temps de parcourir attentivement la documentation d'Elasticsearch pour comparer ses fonctionnalités à celles de Meilisearch, Typesense et pg_search.
J'ai lu Text analysis overview de Elasticsearch.
Je note ici les étapes de l'Text analysis que j'ai des difficultés à retenir :
- Tokenization
- Token filtering (voir dans Anatomy of an analyzer)
- Normalization (search engine)
- Stemmer token filter (search engine)
- Character filters reference
- Customize text analysis
J'ai parcouru la liste des différents types des Built-in analyzer reference de Elasticsearch.
Je retiens le concept de stop analyzer.
#JeMeDemande l'usage du Keyword analyzer 🤔.
Je trouve le Pattern analyzer intéressant.
En lisant Fingerprint analyzer je découvre l'algorithme fingerprinting décrit dans la documentation de OpenRefine : https://openrefine.org/docs/technical-reference/clustering-in-depth#fingerprint. Je garde cela dans un coin de mon esprit, il se peut que cela me soit utile à l'avenir 🤔.
Je découvre que Elasticsearch (sans doute Lucene 🤔) propose beauoup de token filtering différent qui peuvent être combinés : Apostrophe, ASCII folding, CJK bigram, CJK width, Classic, Common grams, Conditional, Decimal digit, Delimited payload, Dictionary decompounder, Edge n-gram, Elision, Fingerprint, Flatten graph, Hunspell, Hyphenation decompounder, Keep types, Keep words, Keyword marker, Keyword repeat, KStem, Length, Limit token count, Lowercase, MinHash, Multiplexer, N-gram, Normalization, Pattern capture, Pattern replace, Phonetic, Porter stem, Predicate script, Remove duplicates, Reverse, Shingle, Snowball, Stemmer, Stemmer override, Stop, Synonym, Synonym graph, Trim, Truncate, Unique, Uppercase, Word delimiter, Word delimiter graph.
J'ai lu Stemmer token filter que je considère comme très important pour un moteur de recherche efficace.
#JaiDécouvert le support de Synonym graph token filter.
Je lis HTML strip character filter, fonctionnalité que je juge très utile.
Je lis qu'Elasticsearch propose de nombreuses méthodes de query, entre autres :
- Query DSL
- EQL search
- ES QL
- et même SQL
- Scripting
Tout cela est très riche !
J'ai lu Highlighting
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
Journal du samedi 17 août 2024 à 11:59
Je viens de comprendre que dans le domaine des full-text search engine les notions de Facets et Aggregations sont liées.
La fonctionnalité facets sont basés les fonctionnalités aggregations des full-text search engine.
Journal du mardi 09 juillet 2024 à 08:46
Dans le cadre de mon travail sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément, ma tentative d'utiliser pg_search pour y intégrer un moteur de recherche, j'ai creusé le sujet InstantSearch.
Typesense permet d'utiliser InstantSearch via un adaptateur :
At Typesense, we've built an adapter (opens new window) that lets you use the same Instantsearch widgets as is, but send the queries to Typesense instead. (from)
Ici j'ai découvert des alternatives à InstantSearch :
- typesense-minibar
- autocomplete (aussi créé par Algolia)
- docsearch (aussi créé par Algolia)
#JeMeDemande comment utiliser InstantSearch ou TypeSense-Minibar avec pg_search.
N'ayant pas trouvé de réponse, #JaiPublié How can I implement InstantSearch, Typesense-Minibar or Docsearch with pg_search?.
Journal du vendredi 24 mai 2024 à 16:05
#Jessaie d'utiliser l'instance https://searx.ox2.fr/ du meta moteur de recherche SearXNG.
Algorithm implémenté dans OpenRefine : https://openrefine.org/docs/technical-reference/clustering-in-depth#fingerprint
Notion de User Interface, qui correspond à la sélection rouge dans le screenshot ci-dessous :
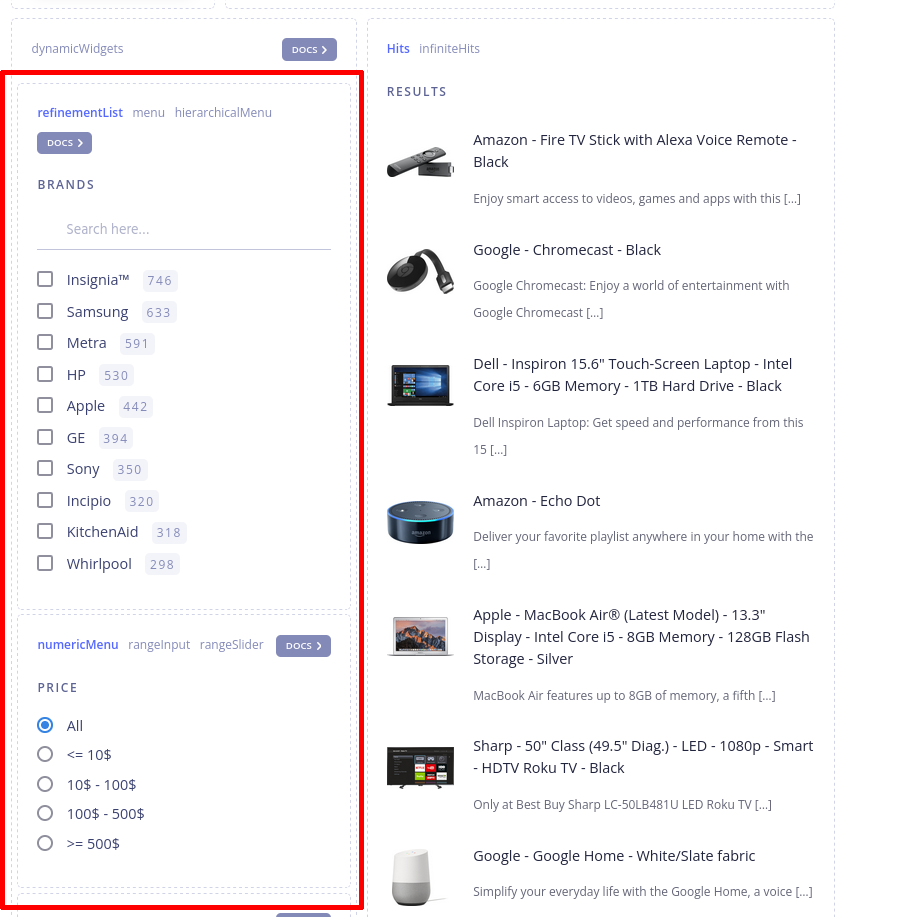
Voir aussi Aggregations (search engine).
Voir aussi Facets.
Sonic est un moteur de recherche open source implémenté Rust.
🦔 Fast, lightweight & schema-less search backend. An alternative to Elasticsearch that runs on a few MBs of RAM.
Dépôt GitHub : https://github.com/valeriansaliou/sonic
https://github.com/quickwit-oss/tantivy - Tantivy is a full-text search engine library inspired by Apache Lucene and written in Rust.
Utilisé par pg_search.
Dernière page.