
Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
Journal du vendredi 17 mai 2024 à 12:57
#JeMeDemande combien me coûterait la réalisation du #POC suivant :
- Déploiement de llama.cpp sur une GPU Instances de Scaleway;
- 3h d'expérimentation;
- Shutdown de l'instance.
🤔.
Tarifs :
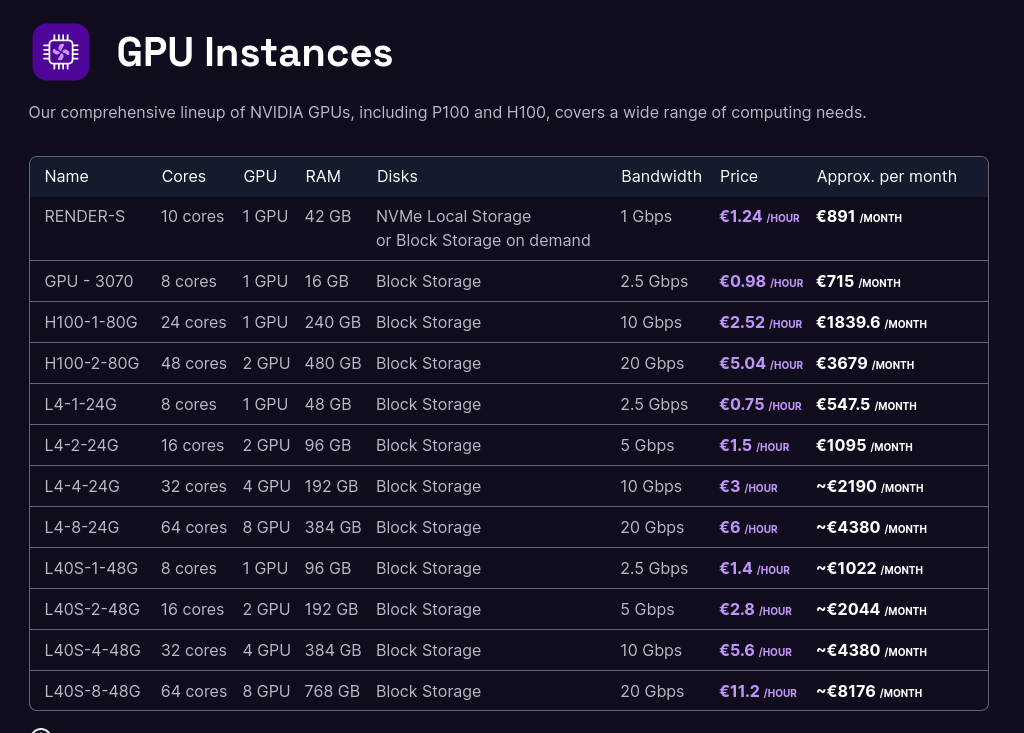
Dans un premier temps, j'aimerais me limiter aaux instances les moins chères :
- GPU-3070 à environ 1 € / heure
- L4-1-24G à 0.75 € / heure
- et peut-être RENDER-S à 1,24 € / heure
Tous ces prix sont hors taxe.
- L'instance GPU-3070 a seulement 16GB de Ram, #JeMeDemande si le résultat serait médiocre ou non.
- Je lis que l'instance L4-1-24G contient un GPU NVIDIA L4 Tensor Core GPU avec 24GB de Ram.
- Je lis que l'instance Render S contient un GPU Dedicated NVIDIA Tesla P100 16GB PCIe avec 42GB de Ram.
Au moment où j'écris ces lignes, Scaleway a du stock de ces trois types d'instances :
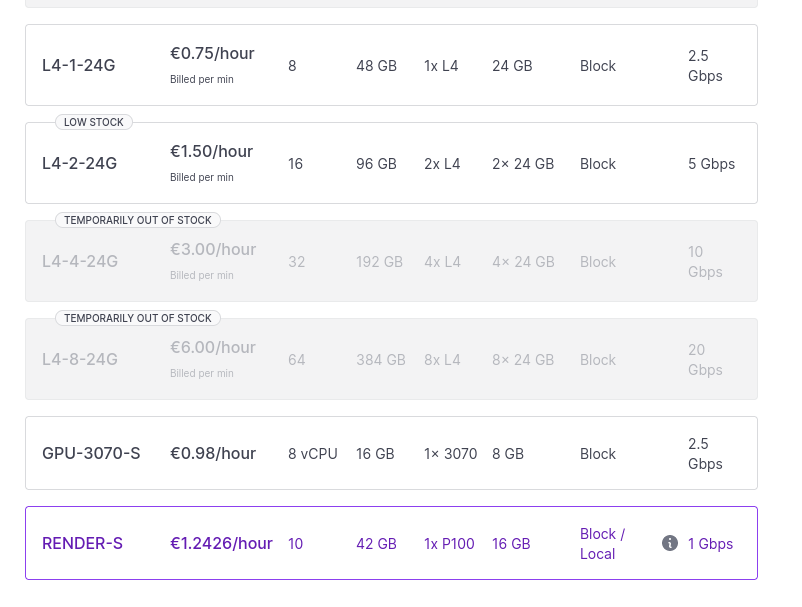
- #JeMeDemande comment je pourrais me préparer en amont pour installer rapidement sur le serveur un environnement pour faire mes tests.
- #JeMeDemande s'il existe des tutoriaux tout prêts pour faire ce type de tâches.
- #JeMeDemande combien de temps prendrait le déploiement.
Si je prends 2h pour l'installation + 3h pour faire des tests, cela ferait 5h au total.
J'ai cherché un peu partout, je n'ai pas trouvé de coût "caché" de setup de l'instance.
Le prix de cette expérience serait entre 4,5 € et 7,44 € TTC.
- #PremièreActionConcrète pour réaliser cette expérimentation : chercher s'il existe des tutoriaux d'installation de llama.cpp sur des instances GPU Scaleway.
- #JeMeDemande combien me coûterait l'achat de ce type de machine.
- #JeMeDemande à partir de combien d'heures d'utilisation l'achat serait plus rentable que la location.
- Si par exemple, j'utilise cette machine 3h par jour, je me demande à partir de quelle date cette machine serait rentabilisée et aussi, #JeMeDemande si cette machine ne serait totalement obsolète ou non à cette date 🤔.
Journaux liées à cette note :
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
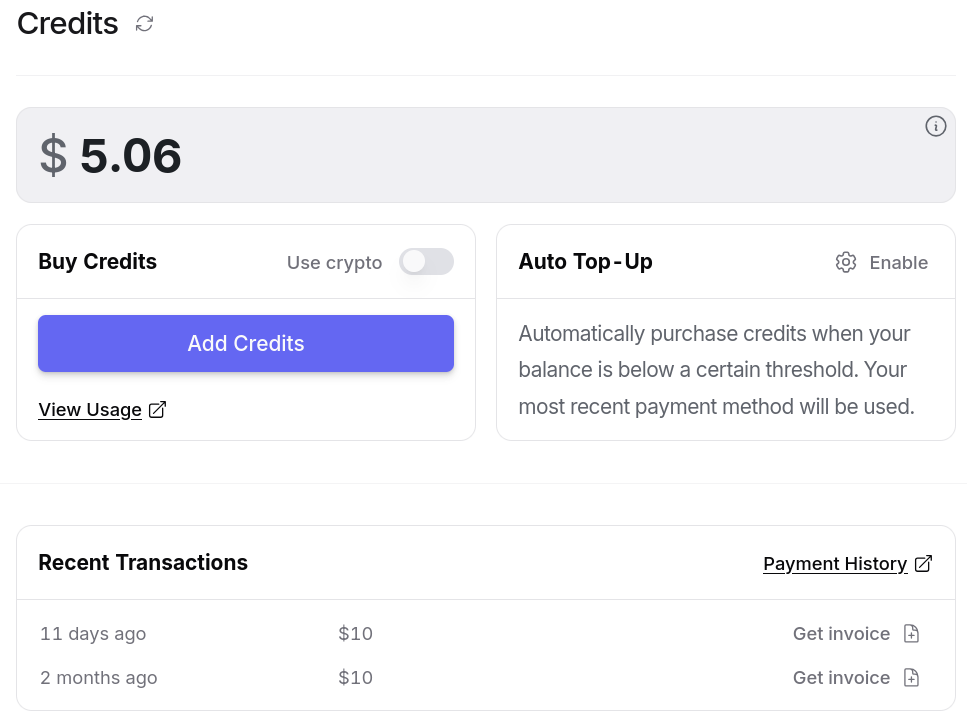
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
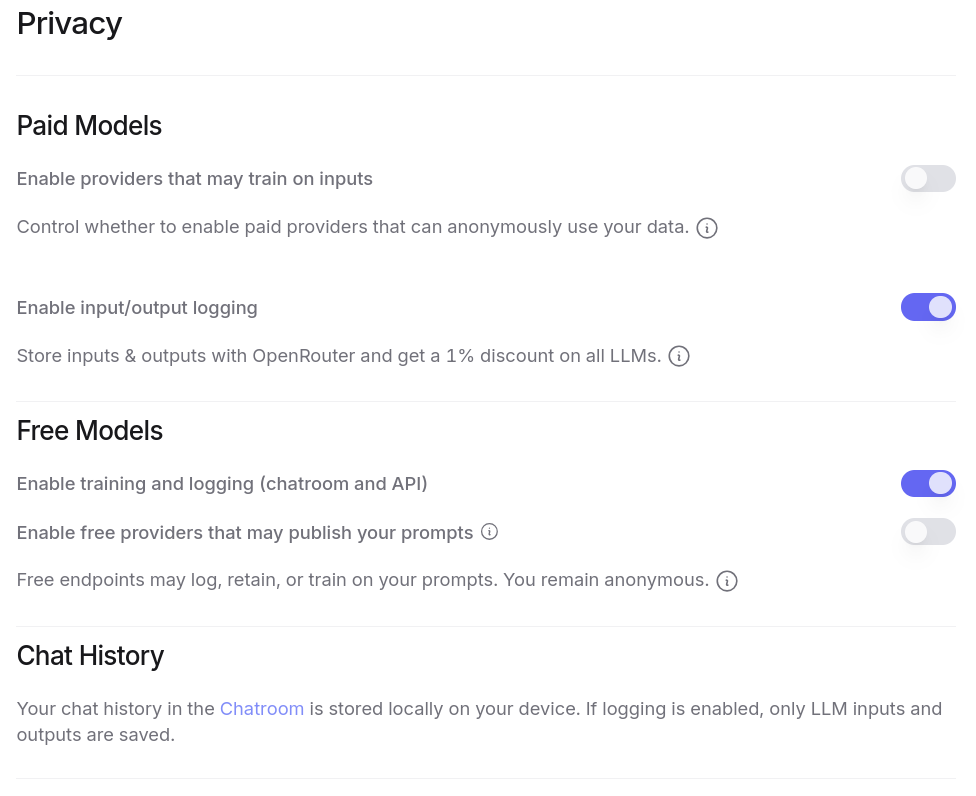
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
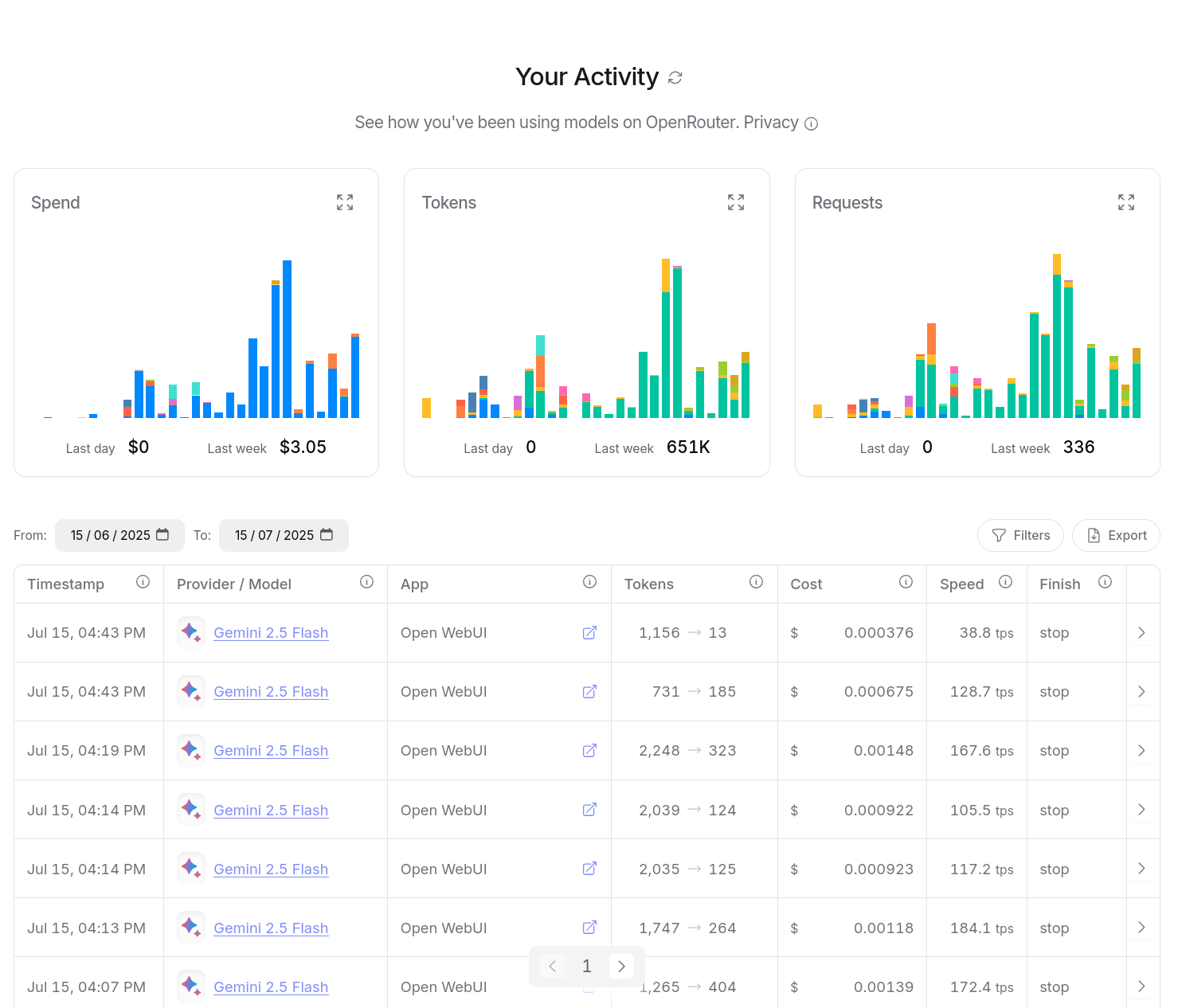
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Journal du mardi 23 juillet 2024 à 15:54
#JaiDécouvert que Scaleway a déployé en public beta une offre d'Managed Inference Service : Scaleway Managed Inference.
Added : Managed Inference is available in Public Beta
Managed Inference lets you deploy generative AI models and answer prompts from European end-consumers securely. Now available in public beta! (from)
C'est une alternative à Replicate.com.
Models now support longer and better conversations :
- All models on catalog now support conversations to their full context window (e.g Mixtral-8x7b up to 32K tokens, Llama3 up to 8k tokens).
- Llama3 70B is now available in FP8 quantization, INT8 is deprecated.
- Llama3 8b is now available in FP8 quantization, BF16 remains default.
L'offre est beaucoup moins large que celle de Replicate mais c'est un bon début 🙂.
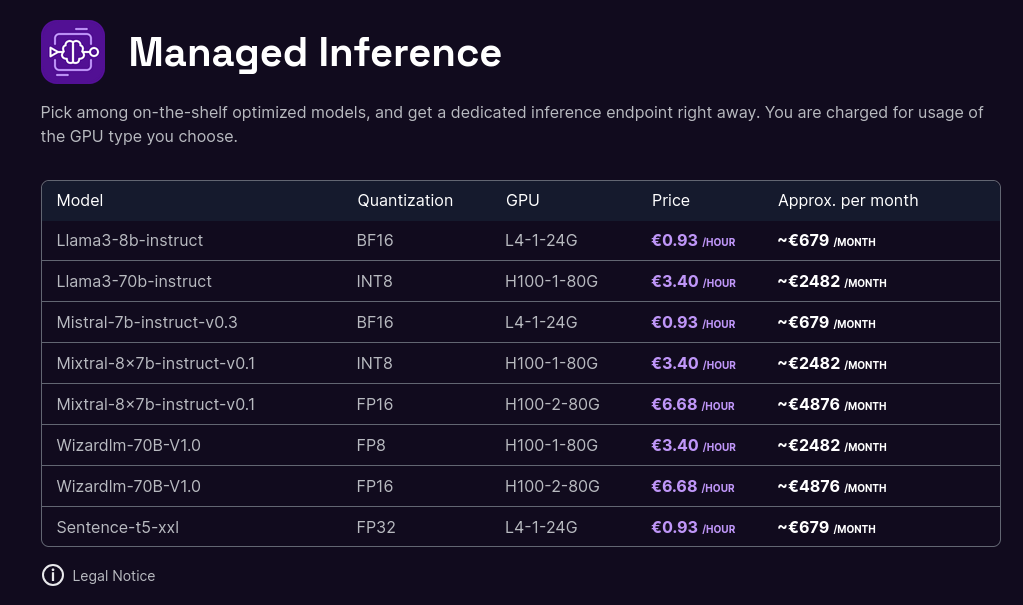
Tarif de l'offre de Scaleway :
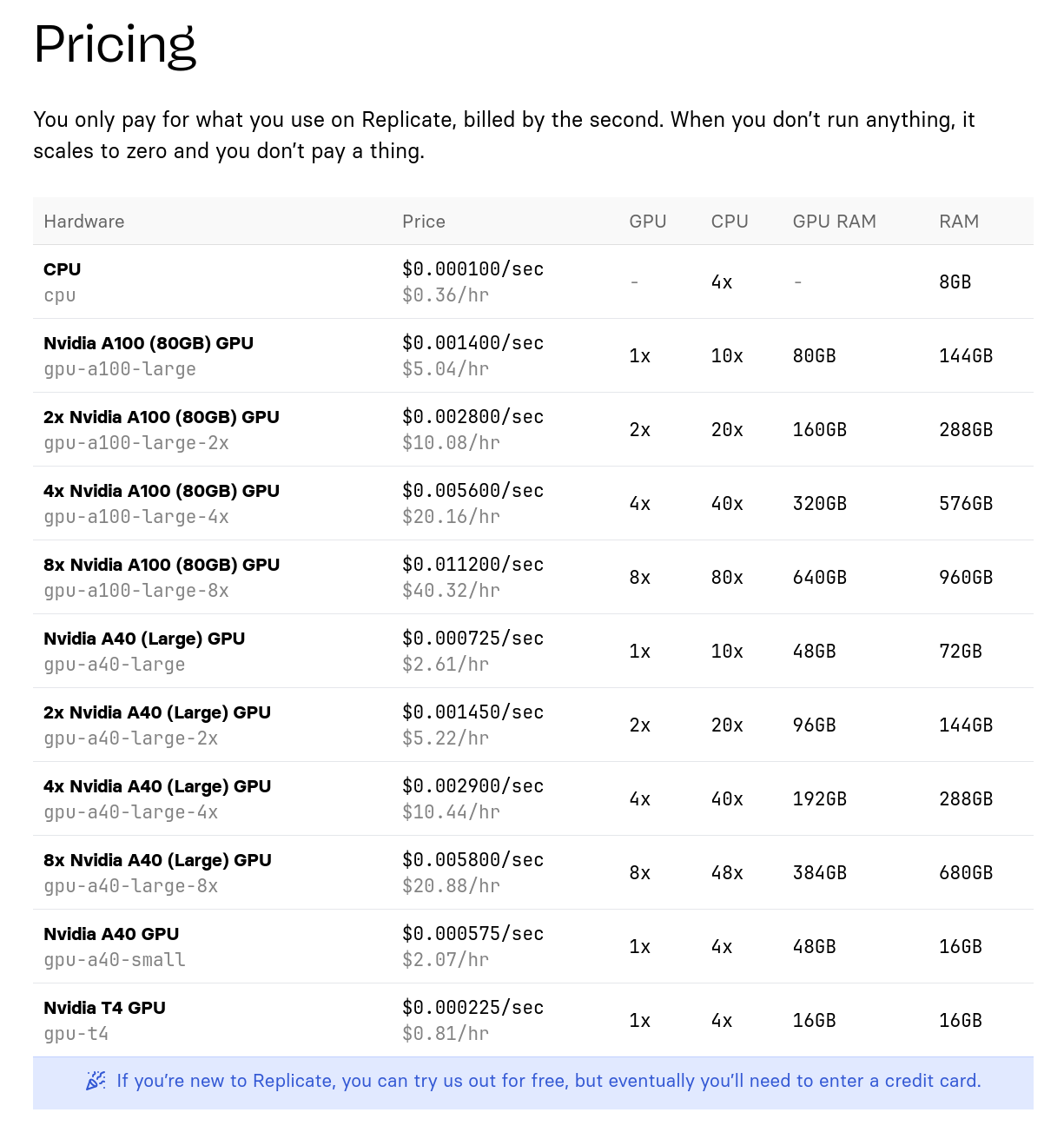
Tarif de l'offre de Replicate.com :
Bien que le matériel soit différent, j'essaie tout de même de faire une comparaison de prix :
- Scaleway : 0,93 € / heure pour une machine à 24Go de Ram GPU
- Replicate : 0,81 $ / heure pour une machine à 16GB de Ram GPU
Ensuite :
- Scaleway : 3,40 € / heure pour une machine à 80Go de Ram GPU
- Replicate : 5,04 € / heure pour une machine à 80Go de Ram GPU
Je précise, que je n'ai aucune idée si ma comparaison a du sens ou non.
Je n'ai pas creusé plus que cela le sujet.
Note en lien avec 2024-05-17_1257.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

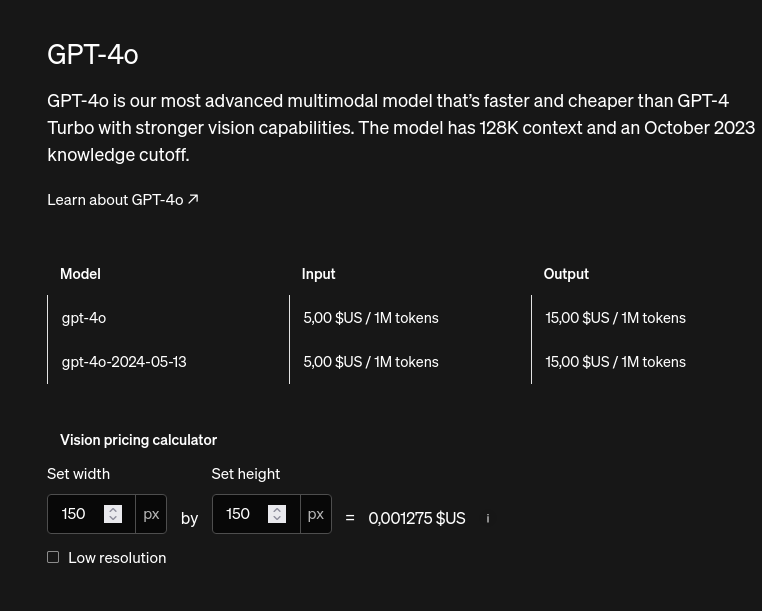
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.