
Ollama
https://github.com/ollama/ollama
Get up and running with Llama 3.1, Mistral, Gemma 2, and other large language models.
Ollama est un Inference Engine (comme LLama.cpp).
Journaux liées à cette note :
Alexandre m'a partagé le projet LocalAI (https://localai.io/).
Ce projet a été mentionné une fois sur Lobster dans un article intitulé Everything I’ve learned so far about running local LLMs, et quatre fois sur Hacker News (recherche pour "localai.io"), mais avec très peu de commentaires.
C’est sans doute pourquoi je n'ai jamais remarqué ce projet auparavant.
Pourtant, il ne s’agit pas d’un projet récent : son développement a débuté en mars 2023.
J'ai l'impression que LocalAI propose à la fois des interfaces web comme Open WebUI, mais qu'il est aussi une sorte de "wrapper" au-dessus de nombreux Inference Engines comme l'illustre cette longue liste.
Pour le moment, j'ai vraiment des difficultés à comprendre son positionnement dans l'écosystème.
LocalAI versus vLLM ou Ollama ? LocalAI versus Open WebUI ?, etc.
Je vais garder ce projet dans mon radar.
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
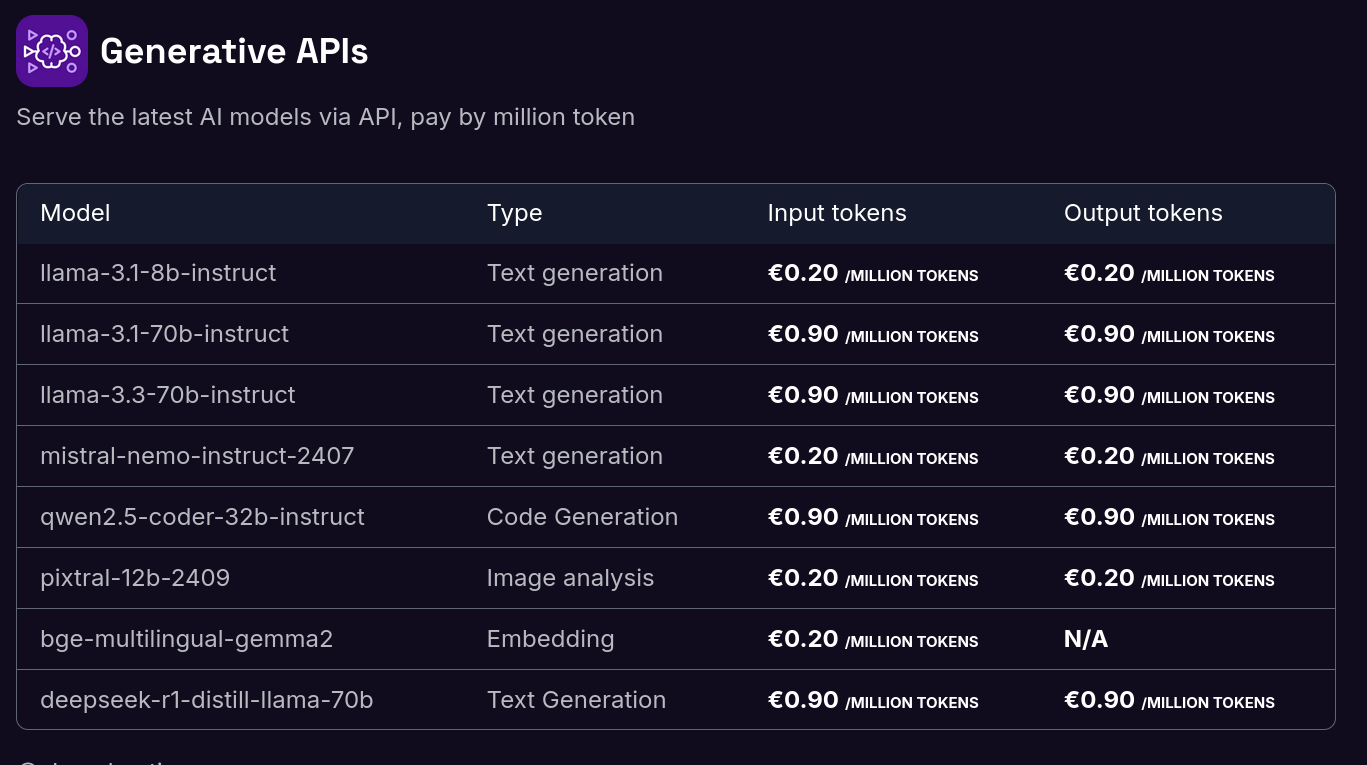
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
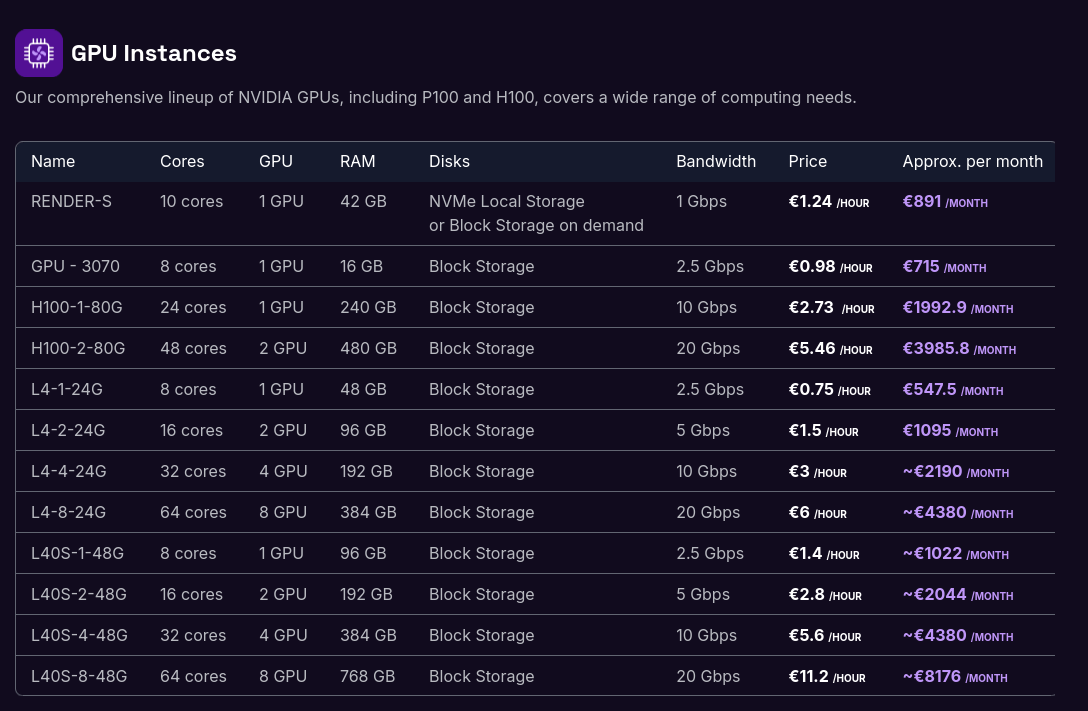
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
Journal du jeudi 19 septembre 2024 à 09:56
#OnMaPartagé ce repository pour déployer n8n avec Ollama.
Journal du dimanche 01 septembre 2024 à 10:42
Suite à des échanges avec Alexandre au sujet de la "position" et de l'usage de Ollama dans le domaine des LLM, j'ai pris un peu de temps pour essayer d'y voir plus clair.
#JaiLu ce thread Reddit : newbie confusion: LocalLM / AnythingLLM / llama.cpp / Lamafile / Ollama / openwebui All the same? : LocalLLM
Voici ma description d'Ollama. Ollama est un wrapper au-dessus de llama.cpp afin de rendre son utilisation davantage User Friendly. Ollama est écrit en Golang.
D'après :
Supported backends
- llama.cpp project founded by Georgi Gerganov
-- from
et la présence de llama.cpp directement dans le code source de Ollama
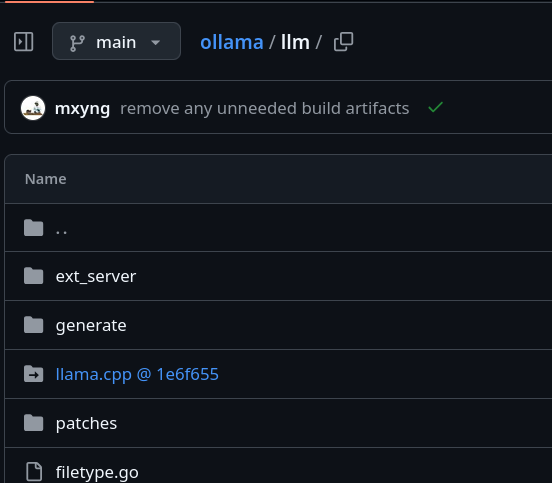
Je comprends que pour le moment, Ollama supporte uniquement le backend llama.cpp.
Conclusion : je pense qu'il est préférable d'utiliser Ollama plutôt que directement llama.cpp.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

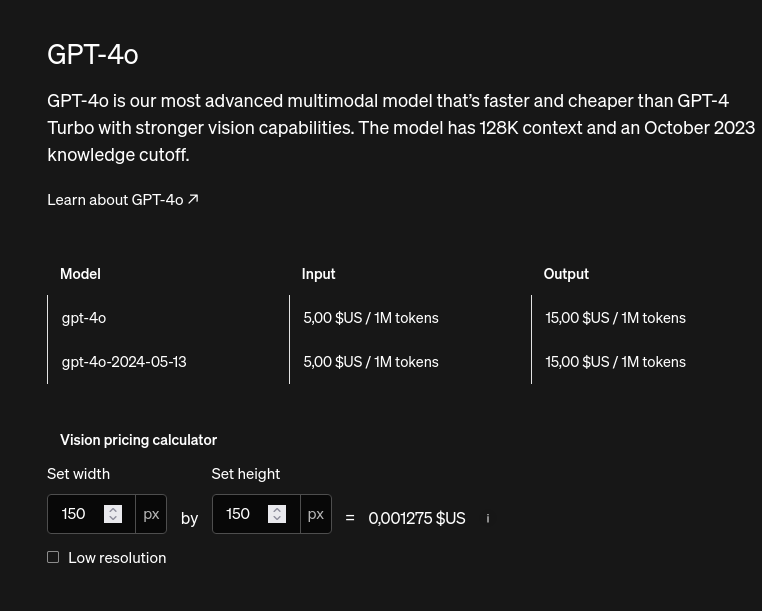
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.
Journal du dimanche 17 mars 2024 à 20:00
#JaiLu le billet de blog de Ollama nommé Ollama now supports AMD graphics cards .