
Scaleway
Article wikipedia : https://fr.wikipedia.org/wiki/Scaleway
Journaux liées à cette note :
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Setup Fedora CoreOS avec LUKS et Tang
Il y a quelques jours, dans ma note "Setup Fedora CoreOS avec LUKS et TPM", je disais :
Une solution pour traiter ce point faible est d'utiliser un pin éloigné physiquement du serveur qui l'utilise.
Le framework Clevis utilise le terme "pins" pour désigner les différents méthodes de déverrouillage d'un volume LUKS.
Origine du mot "pin" ?
Claude Sonnet 4.5 m'a expliqué que le terme "pin", qui se traduit par "goupille" en français, désigne la pièce mécanique qui bloque l'ouverture d'un cadenat.
Par exemple, dans un contexte self hosting dans un homelab, je peux héberger physiquement un serveur dans mon logement et le connecter à un pin sur un serveur Scaleway ou sur un serveur dans le homelab d'un ami.
Les pins distants, accessibles via réseau, sont appelés serveurs Network-Bound Disk Encryption.
Si le serveur Network-Bound Disk Encryption est configuré pour répondre uniquement aux requêtes provenant de l'IP de mon réseau homelab, en cas de vol du serveur, le voleur ne pourra pas récupérer le secret permettant de déchiffrer le volume LUKS.
Dans le playground install-coreos-iso-on-qemu-with-luks-and-tang, j'ai testé avec succès le déverrouillage d'un volume LUKS avec un serveur Network-Bound Disk Encryption nommé tang.
Pour être précis, dans la configuration de ce playground, deux pins sont obligatoires pour déverrouiller automatiquement le volume : un pin tang et un pin TPM2. Le nombre minimum de pins requis pour le déverrouillage est défini par le paramètre threshold.
clevis, qui permet de configurer les pins et de gérer la récupération de la passphrase à partir des pins, utilise l'algorithme Shamir's secret sharing (SSS) pour répartir le secret à plusieurs endroits.
Voici quelques scénarios de conditions de déverrouillage que clevis permet de configurer grâce à SSS :
- TPM2 ou Tang serveur 1
- TPM2 et Tang serveur 1
- Tang serveur 1 ou Tang serveur 2
- 2 parmi Tang serveur 1, Tang serveur 2, Tang serveur 3
- ...
Si les conditions ne sont pas remplies, systemd-ask-password demande à l'utilisateur de saisir sa passphrase au clavier.
Je n'ai pas trouvé d'image docker officielle de tang. Toutefois, j'ai trouvé ici l'image non officielle padhihomelab/tang (son dépôt GitHub : https://github.com/padhi-homelab/docker_tang).
Dans mon playground, je l'ai déployé dans ce docker-compose.yml.
J'ai trouvé la configuration butane de tang simple à définir (lien vers le fichier) :
luks:
- name: var
device: /dev/disk/by-partlabel/var
wipe_volume: true
key_file:
inline: password
clevis:
tpm2: true
tang:
- url: "http://10.0.2.2:1234"
# $ docker compose exec tang jose jwk thp -i /db/pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw.jwk
# pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw
thumbprint: dx9dNzgs-DeXg0SCBQW5rb7WQkSIN1B8MIgcO6WxJfI
threshold: 2 # TMP2 + Tang (or passphrase keyboard input)
La seule complexité que j'ai rencontrée est la méthode pour récupérer le paramètre thumbprint de l'instance tang.
Voici la méthode que j'ai utilisée :
$ docker compose exec tang jose jwk thp -i /db/pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw.jwk
pLWwUuLhqqFb-Mgf5iVkwuV4BehG9vzd2SXGMyGroNw
Autre difficulté, il faut ajouter les arguments kernel suivants pour activer l'accès réseau dès le début du process de boot afin de permettre à clevis d'accéder au serveur tang :
variant: fcos
version: 1.6.0
kernel_arguments:
should_exist:
- ip=dhcp
- rd.neednet=1
J'ai intégré au README.md du playground une section nommée "How to switch from 2 required ping to 1 or the opposite?", pour documenter comment modifier à chaud la configuration clevis.
Par exemple pour changer de serveur tang ou modifier le nombre de pins nécessaires pour déverrouiller la partition chiffrée.
Il est conseillé d'activer le pin TPM2 en complément de tang pour éviter ce type d'attaque décrit par Claude Sonnet 4.5 :
Imaginons un admin malveillant dans ton entreprise :
- Il a accès physique aux serveurs
- Il a accès au réseau (donc au serveur Tang)
- Il clone un disque pendant la nuit
- Il essaie de le monter sur sa propre machine pour extraire des données
Tang seul : ❌ Il réussit
TPM + Tang : ✅ Il échoue
À noter que l'instance tang ne contient pas la passphrase et ne voit jamais passer la passphrase via son API.
Voici les explications que m'a données Claude Sonnet 4.5 :
Tang ne stocke pas la passphrase secrète de chiffrement LUKS. C'est justement tout l'intérêt de cette solution !
Voici comment ça fonctionne :
Le principe de Tang + Clevis
- Génération de clé dérivée : Clevis (le client) contacte le serveur Tang et récupère sa clé publique
- Chiffrement avec la clé de Tang : Clevis utilise cette clé publique pour chiffrer la passphrase LUKS
- Stockage local : La passphrase chiffrée est stockée localement dans l'en-tête LUKS du disque (pas sur le serveur Tang)
- Déchiffrement au boot :
- La machine contacte Tang
- Tang utilise sa clé privée pour aider à déchiffrer
- La passphrase LUKS est reconstituée
- Le disque est déverrouillé
Ce que Tang sait et ne sait pas
- ❌ Tang ne connaît jamais votre passphrase LUKS
- ❌ Tang ne stocke rien concernant vos clés
- ✅ Tang fournit juste un service cryptographique (un oracle de déchiffrement)
- ✅ C'est un serveur sans état (stateless)
C'est du chiffrement asymétrique avec un mécanisme appelé "network-bound disk encryption" : le disque ne peut être déchiffré que si la machine peut contacter le serveur Tang sur le réseau.
Voici quelques ressources supplémentaires au sujet des techniques de déverrouillage automatique des volumes LUKS :
J'ai découvert ContainerLab, un projet qui permet de simuler des réseaux
Pendant mon travail d'étude pratique de IPv6, #JaiDécouvert le projet Containerlab :
Containerlab was meant to be a tool for provisioning networking labs built with containers. It is free, open and ubiquitous. No software apart from Docker is required! As with any lab environment it allows the users to validate features, topologies, perform interop testing, datapath testing, etc. It is also a perfect companion for your next demo. Deploy the lab fast, with all its configuration stored as a code -> destroy when done.
Projet qui a commencé en 2020 et semble principalement développé par un développeur de chez Nokia.
D'après ce que j'ai compris, Containerlab me permet de facilement créer des réseaux dans un simulateur.
Je me souviens que je cherchais ce type d'outil en 2018, quand je travaillais sur un projet baremetal as service chez Scaleway.
Voici un exemple de fichier créé par Claude.ai pour simuler un environnement composé de deux réseaux IPv6 connectés entre eux : 3 serveurs sur le premier réseau et 2 serveurs sur le second.
Je précise que je n'ai pas encore testé ce fichier. J'ignore donc s'il fonctionne correctement.
name: dual-network-ipv6-lab
topology:
nodes:
# Routeur avec IPv6
router:
kind: linux
image: alpine:latest
exec:
# Activer IPv6
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- sysctl -w net.ipv6.conf.all.forwarding=1
# Adresses IPv6 sur les interfaces
- ip -6 addr add 2001:db8:1::1/64 dev eth1
- ip -6 addr add 2001:db8:2::1/64 dev eth2
# IPv4 en parallèle (dual-stack)
- ip addr add 192.168.1.1/24 dev eth1
- ip addr add 192.168.2.1/24 dev eth2
- echo 1 > /proc/sys/net/ipv4/ip_forward
# Réseau A (2001:db8:1::/64)
vm-a1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::10/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.10/24 dev eth1
- ip route add default via 192.168.1.1
vm-a2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::11/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.11/24 dev eth1
- ip route add default via 192.168.1.1
vm-a3:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::12/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.12/24 dev eth1
- ip route add default via 192.168.1.1
# Réseau B (2001:db8:2::/64)
vm-b1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::10/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.10/24 dev eth1
- ip route add default via 192.168.2.1
vm-b2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::11/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.11/24 dev eth1
- ip route add default via 192.168.2.1
links:
# Réseau A
- endpoints: ["router:eth1", "vm-a1:eth1"]
- endpoints: ["router:eth1", "vm-a2:eth1"]
- endpoints: ["router:eth1", "vm-a3:eth1"]
# Réseau B
- endpoints: ["router:eth2", "vm-b1:eth1"]
- endpoints: ["router:eth2", "vm-b2:eth1"]
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Avril 2025, quelle est mon expérience Kubernetes ?
J'ai commencé à utiliser Kubernetes pour la première fois en janvier 2016. C'était dans un cadre professionnel, quand je travaillais chez Tech-Angels / Gemnasium.
Mes deux premiers projets étaient les suivants :
- Opérer et continuer à améliorer un cluster de 3 nodes basé sur OpenShift (surcouche Kubernetes de Red Hat) qui permettait d'héberger les services web de nos clients.
L'objectif était de fournir un service un peu comme Heroku, c'est-à-dire permettre un déploiement via un simple "git push".
Avec le recul, l'objectif ressemblait à ce que propose actuellement Clever Cloud. - Implémenter une version OnPremise de Gemnasium propulsée par Kubernetes.
En janvier 2016, Kubernetes était un projet très jeune, avec seulement 20 mois d'existence depuis la sortie de la première version 0.2.
L'écosystème était bien plus petit que maintenant. Par exemple, Helm n'était pas encore populaire.
J'ai commencé par installer la version 1.1 de Kubernetes avec les playbooks officiels Ansible.
Ce fut une expérience difficile, avec de nombreux crashs de clusters, tout particulièrement lors des montées en version.
L'expérience fut très enrichissante. Cela m'a permis de monter en compétence avec Docker, Kubernetes, Ceph…
J'ai ensuite utilisé Kubernetes de novembre 2018 à avril 2019, dans la team Kubernetes Kapsule de Scaleway.
La mission de cette équipe était de créer un produit qui permettait de déployer des clusters Kubernetes managés.
Je suis arrivé dans cette équipe 10 mois après le début du projet. J'ai contribué au projet pendant 5 mois, jusqu'au lancement du produit en production.
Cette fois encore, une partie du travail était de déployer des clusters Kubernetes from "scatch".
Expérience intéressante : j'ai appris à déployer des clusters Kubernetes via Kubernetes !
L'implémentation était inspirée de la méthode présentée dans cet article : Gardener - The Kubernetes Botanist.
Depuis avril 2019, je n'ai plus opéré de cluster Kubernetes. J'ai seulement continué à suivre de loin les actualités de cet écosystème. Je n'ai plus eu d'expérience pratique.
Maintenant que j'ai rejoint une mission dont le produit est déployé sur Kubernetes, je souhaite mettre à jour mes compétences pratiques dans ce domaine.
Voici quelques sujets sur lesquels je souhaite monter en compétence ces prochains mois :
- M'entrainement à utiliser et à créer des Helm Charts
- Déployer un ArgoCD pour apprendre à bien l'utiliser
- Jouer avec k3s
- Tester Postgres Operator
- Étudier et tester https://tilt.dev/
- kind (https://kind.sigs.k8s.io/)
- Grafana Tanka
- kustomize (https://github.com/kubernetes-sigs/kustomize)
Object Storage append-only backup playground
Pour un projet, je dois mettre en place un système de sauvegarde sécurisé (WORM).
Ici, "sécurisé" signifie :
- qui empêche la suppression accidentelle ou intentionnelle des données ;
- une protection contre les ransomwares.
Pour cela, j'ai décidé de sauvegarder ces données chez deux fournisseurs d'Object Storage :
Je viens de publier le playground append-only-backup-playground qui m'a permis de tester la configuration de bucket Backblaze et Scaleway.
Object Storage append-only backup playground
In this "playground" repository, I explore different methods to configure object storage services in append-only or write-once-read-many (WORM) mode.
J'ai testé deux méthodes qui interdisent la suppression des données :
1.La première, basée sur une clé d'accès avec des droits limités : l'interdiction de supprimer des fichiers. Si un attaquant parvient à s'infiltrer sur un serveur qui effectue des sauvegardes, la clé ne lui permettra pas d'effacer les anciennes sauvegardes.2.La seconde méthode plus stricte utilise la fonctionnalité object lock en modeGOVERNANCEouCOMPLIANCE.
Je vous recommande d'être vigilant avec le mode COMPLIANCE, car il vous sera impossible de supprimer les fichiers avant leur date de rétention, sauf si vous décidez de supprimer entièrement votre compte client !
Personnellement, je recommande d'utiliser la méthode 1 pour tous les environnements de développement.
En général, je pense que la méthode 1 est suffisante, même pour les environnements de production. Mais si les données sont vraiment critiques, alors je conseille le mode GOVERNANCE ou COMPLIANCE.
Le repository append-only-backup-playground contient 4 playgrounds :
- Pour tester la méthode
1:/scaleway/: configuration d'un bucket Scaleway Object Storage et une clé qui ne peut pas supprimer de fichier. L'option de versionning est activée./backblaze/: configuration d'un bucket Backblaze et une clé qui ne peut pas supprimer de fichier. L'option de versionning est activée.
- Pour tester la méthode
2:/scaleway-object-lock/: la même chose que/scaleway/avec en plus la configuration de object lock en modeGOVERNANCEavec une durée de rétention définie à 1 jour./backblaze-object-lock/: la même chose que/backblaze/avec en plus la configuration de object lock en modeGOVERNANCEavec une durée de rétention définie à 1 jour.
Journal du vendredi 17 janvier 2025 à 12:03
Suite de ma note 2025-01-15_1350.
Voici la réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Journal du vendredi 17 janvier 2025 à 11:58
#JeMeDemande s'il est possible d'installer des serveurs Scaleway Elastic Metal avec des images d'OS préalablement construites avec Packer 🤔.
Je viens de poser la question suivante : Is it possible to create Elastic Metal OS images with Packer and use it to create a Elastic Metal serveurs?
En français :
Bonjour,
Je sais qu'il est possible de créer des images d'OS avec Packer utilisables lors de la création d'instance Scaleway (voir https://www.scaleway.com/en/docs/tutorials/deploy-instances-packer-terraform/).
De la même manière, je me demande s'il est possible de créer des images d'OS avec Packer pour installer des serveurs Elastic Metal .
Question : est-il possible de créer des images Elastic Metal avec Packer et d'utiliser celle-ci pour créer des serveurs Elastic Metal ?
Si c'est impossible actuellement, pensez-vous qu'il soit possible de l'implémenter ? Ou alors, est-ce que des limitations techniques de Elastic Metal rendent impossible cette fonctionnalité ?
Bonne journée, Stéphane
Je viens d'envoyer cette demande au support de Scaleway.
Journal du mercredi 15 janvier 2025 à 13:50
Suite de la note 2025-01-14_2152 au sujet de Scaleway Domains and DNS.
Dans l'e-mail « External domain name validation » que j'ai reçu, je lis :
Alternative validation process (if your current registrar doesn't offer basic DNS service):
Please set your nameservers at your registrar to:
9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud
J'ai essayé cette méthode alternative pour le sous-domaine scw.stephane-klein.info :
Voici les DNS Records correspondants :
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
J'ai vérifié ma configuration :
$ dig NS scw.stephane-klein.info @ali.ns.cloudflare.com
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
J'ai attendu plus d'une heure et cette méthode de validation n'a toujours pas fonctionné.
Je pense que cela ne fonctionne pas 🤔.
Je vais créer un ticket de support Scaleway pour savoir si c'est un bug ou si j'ai mal compris comment cela fonctionne.
2025-01-17 : réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Conclusion : la documentation était imprécise, ce que j'ai essayé de réaliser ne peut pas fonctionner.
Journal du mardi 14 janvier 2025 à 21:52
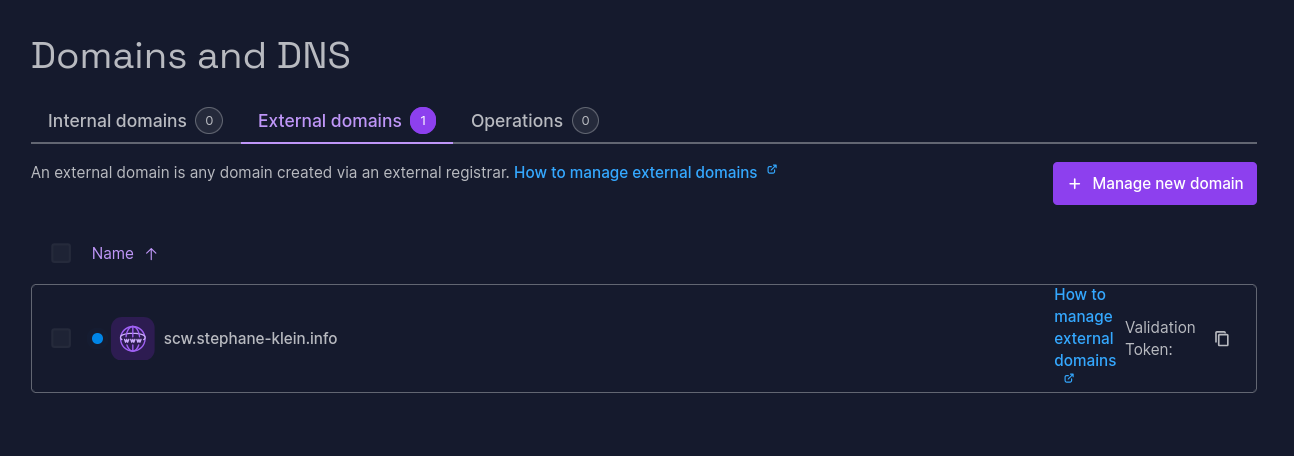
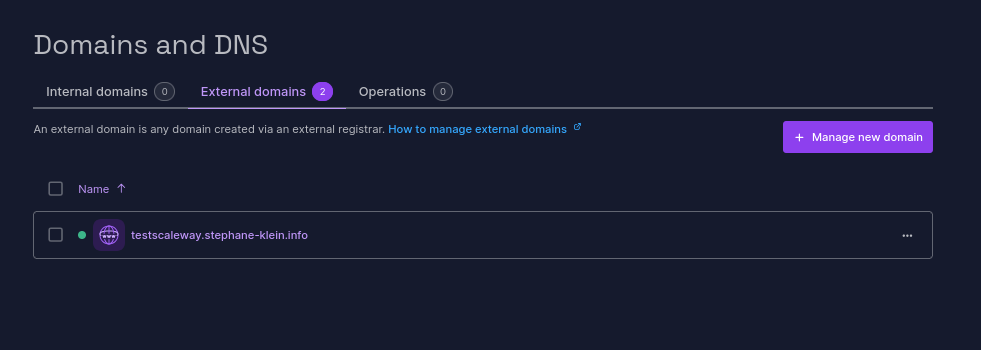
J'ai réalisé un test pour vérifier que la délégation DNS par le managed service de Scaleway nommé Domains and DNS (lien direct) fonctionne correctement pour un sous-domaine tel que testscaleway.stephane-klein.info.
Je commence par suivre les instructions du how to : How to add an external domain to Domains and DNS.
Sur la page https://console.scaleway.com/domains/internal/create :
Je sélectionne la dernière entrée « Manage as external ».
Ensuite :

J'ai ajouté le DNS Record suivant à mon serveur DNS géré par cloudflare :
_scaleway-challenge.testscaleway.stephane-klein.info. 1 IN TXT "dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Vérification :
$ dig TXT _scaleway-challenge.testscaleway.stephane-klein.info +short
"dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Je n'ai aucune idée de la fréquencede passage du job Scaleway qui effectue la vérification de l'entrée TXT :
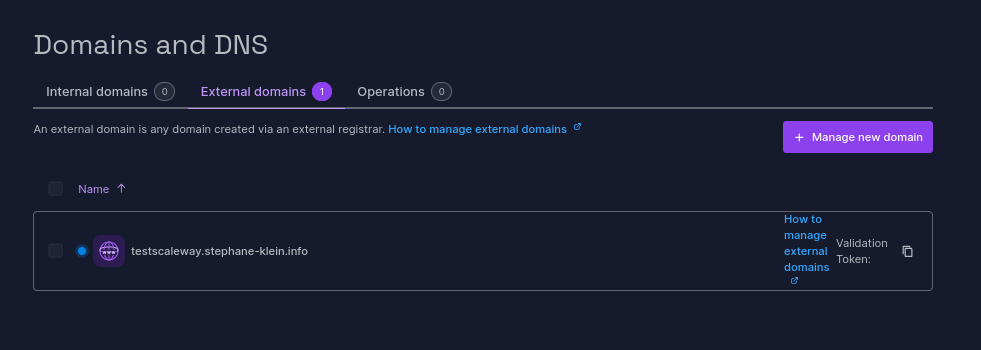
J'ai ajouté mon domaine à 22h22 et il a été validé à 22h54 :
Ensuite, j'ai ajouté les DNS Records suivants :
testscaleway.stephane-klein.info. 1 IN NS ns1.dom.scw.cloud.
testscaleway.stephane-klein.info. 1 IN NS ns0.dom.scw.cloud.
Vérification :
$ dig NS testscaleway.stephane-klein.info +short
ns0.dom.scw.cloud.
ns1.dom.scw.cloud.
Ensuite, j'ai configuré dans la console Scaleway, le DNS Record :
test1 3600 IN A 8.8.8.8
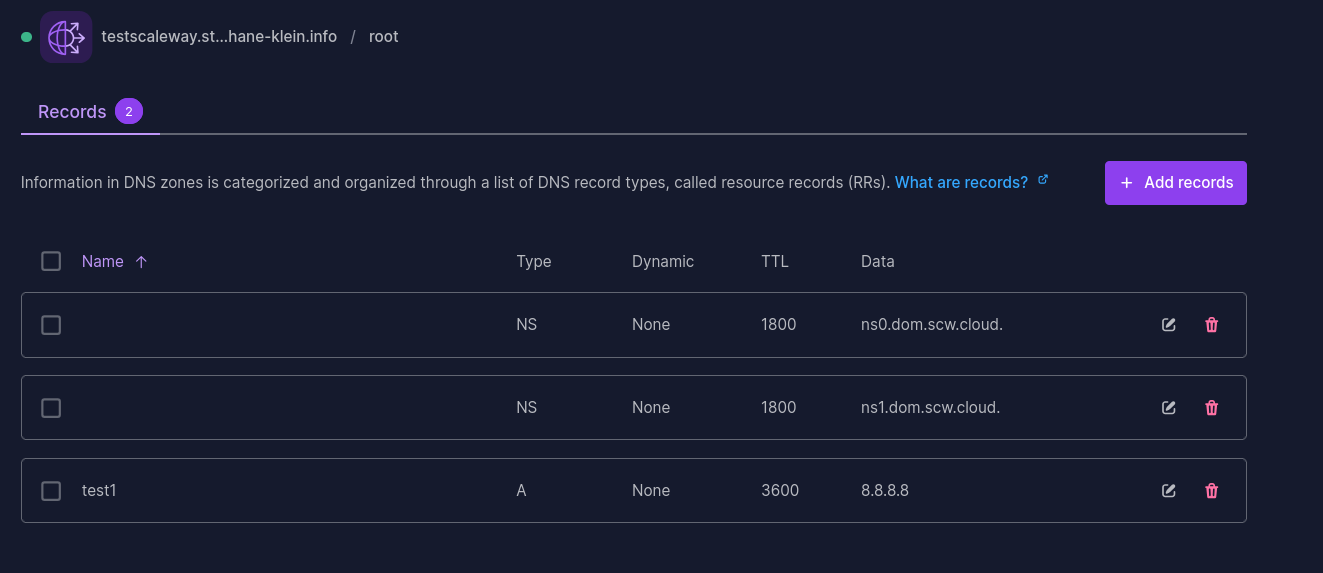
Vérification :
$ dig test1.testscaleway.stephane-klein.info +short
8.8.8.8
Conclusion : la réponse est oui, le managed service Scaleway Domains and DNS permet la délégation de sous-domaines 🙂.