
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (57 notes) :
net-tools est déprécié, je dois remplacer "lsof -i" par "ss -tlnp"
J'utilise habituellement lsof -i | grep "8080" pour identifier le processus qui écoute sur le port 8080.
Comme je le mentionnais dans 2025-07-04_1614, j'ai appris net-tools au début des années 2000 et j'ai gardé cette habitude depuis.
D'après Claude Sonnet 4.5, iproute2 est devenu le standard dans Debian, Ubuntu et Fedora vers 2013-2015. net-tools a été supprimé de l'installation par défaut entre 2017 et 2018.
lsof (pour LiSt Open Files) interroge /proc pour récupérer les informations. Cette implémentation, comme tous les outils net-tools, est ancienne et n'utilise pas l'API moderne Netlink.
En 2025, la méthode recommandée pour identifier les processus écoutant des ports est cette commande iproute2 (code source) :
$ ss -tlnp | grep 8080
-t: TCP sockets-l: Listening sockets uniquement-n: Affichage numérique (pas de résolution DNS)-p: Affiche les processus
J'ai écrit cette note et bridge-utils est déprécié, je dois remplacer "brctl" par "ip link" pour m'aider à adopter les commandes modernes iproute2.
Pour apprendre cette nouvelle commande, j'ai ajouté la carte-mémoire suivante dans Anki :
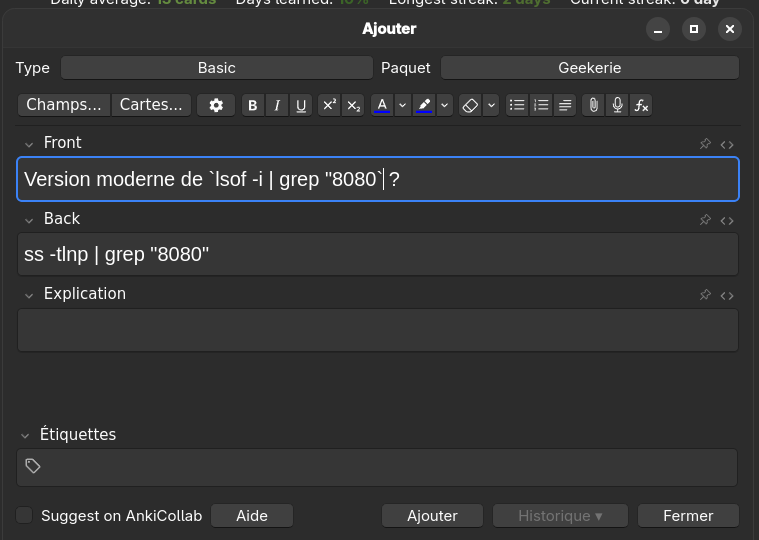
Mémento au sujet de QEMU et de sa configuration réseau
Note de type #mémento #mémo au sujet des fonctionnalités network de QEMU.
Pour bien comprendre le fonctionnement de la configuration network de QEMU, il est important de bien saisir deux concepts :
- les "virtual network device" (
-device) - les "network backend" (
-netdev)
There are two parts to networking within QEMU:
- the virtual network device that is provided to the guest (e.g. a PCI network card).
- the network backend that interacts with the emulated NIC (e.g. puts packets onto the host's network).
Voici toute la liste des network backend supportés par QEMU :
$ qemu-system-x86_64 -netdev help
Available netdev backend types:
socket
stream
dgram
hubport
tap
user
l2tpv3
bridge
af-xdp
vhost-user
vhost-vdpa
Dans cette note, je m'intéresse uniquement aux backend user, tap et bridge.
Le network backend user permet uniquement des accès sortant de la machine virtuelle vers Internet, mais pas l'inverse sans configurer un forwarding de port.
La configuration s'effectue via les options -netdev et -device :
$ qemu-system-x86_64 \
... \
-netdev user,id=n1 \ # configuration du network backend
-device e1000,netdev=n1 \ # virtual network device
...
La version 2.12 de QEMU (2018) propose une alternative plus simplifiée avec l'option -nic. Voici une exemple équivalent à la configuration ci-dessus :
$ qemu-system-x86_64 \
... \
-nic user,model=e1000
La version 2.12 de QEMU (2018) propose une alternative plus simplifiée avec l'option -nic. Voici un exemple équivalent à la configuration ci-dessus :
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute eth0
valid_lft 47067sec preferred_lft 47067sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86251sec preferred_lft 14251sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
En approfondissant mes recherches, j'ai appris que quand le network backend user est configuré, QEMU prend en charge nativement les fonctionnalités DHCP et NAT. Il répond aux requêtes DHCP de la VM démarrée et gère aussi le routage IP en mode NAT.
On peut voir ici deux adresses IPv6 attachées à l'interface eth0 :
fec0::5054:ff:fe12:3456/64fe80::5054:ff:fe12:3456/64
Une fois développées, ces deux adresses correspondent à :
fec0:0000:0000:0000:5054:00ff:fe12:3456fe80:0000:0000:0000:5054:00ff:fe12:3456
Après avoir regardé cette vidéo, je pense avoir compris que dans une IPv6, la moitié gauche représente systématiquement un réseau (ici fe80:0000:0000:0000), nommé aussi "network prefix" ou "routing prefix", tandis que la partie de droite (ici 5054:00ff:fe12:3456) correspond à une adresse d'interface.
La partie interface de ces deux adresses est identique : 5054:00ff:fe12:3456.
Cette adresse d'interface est générée par conversion EUI-64 de l'adresse MAC 52:54:00:12:34:56 => 5054:00ff:fe12:3456.
Exemple de génération d'une autre adresse IPv6 si j'ajoute une interface réseau supplémentaire à la machine virtuelle :
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:57 brd ff:ff:ff:ff:ff:ff
altname enp0s4
altname ens4
altname enx525400123457
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute eth1
valid_lft 86388sec preferred_lft 86388sec
inet6 fec0::5054:ff:fe12:3457/64 scope site dynamic noprefixroute
valid_lft 86389sec preferred_lft 14389sec
inet6 fe80::5054:ff:fe12:3457/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Ici on peut voir que la conversion EUI-64 de 52:54:00:12:34:57 donne 5054:ff:fe12:3457.
Par rapport au fonctionnement d'IPv4, je trouve que le mécanisme de génération automatique des adresses d'interface réseau d'IPv6 très bien conçu 👌.
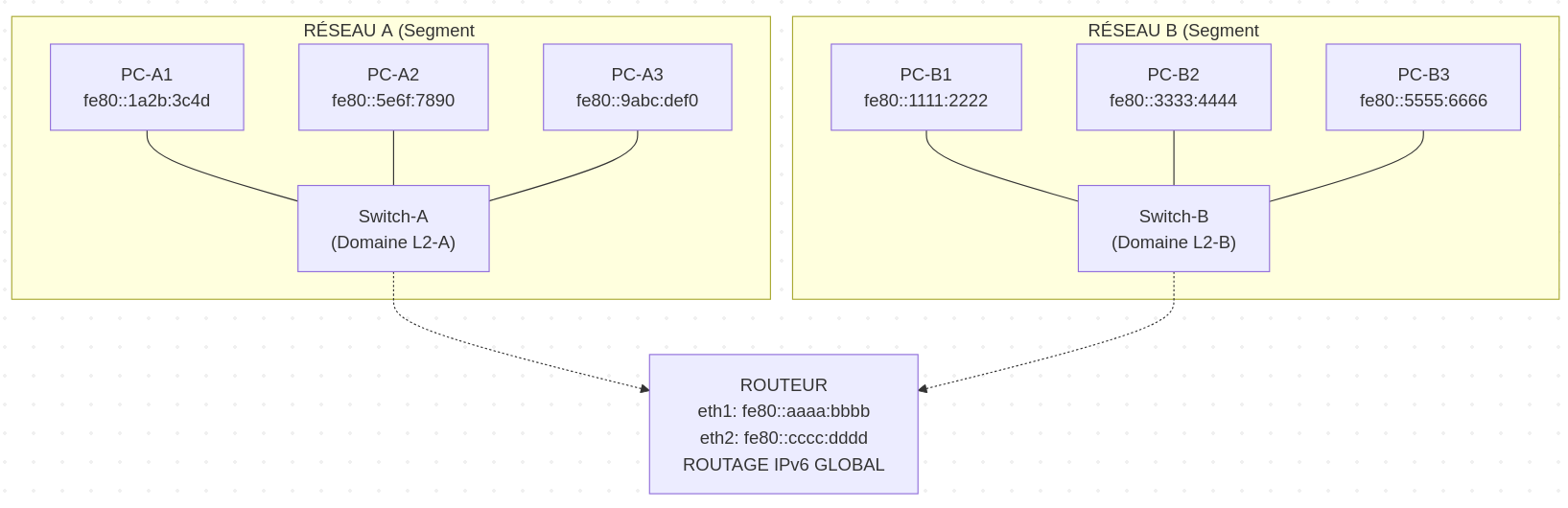
Je m'intéresse maintenant aux préfixes d'adresses IPv6 fec0::/10 et fe80::/10.
Le préfixe fe80::/10 est réservé aux adresses Link-Local. Ces adresses sont automatiquement configurées sur toutes les interfaces IPv6 actives et permettent une communication uniquement au sein du même segment réseau.
Exemple, dans le schéma ci-dessous, tous les serveurs présents sur le réseau A sont joignables via l'adresse Link-Local.
Cependant, les serveurs A n'ont pas la possibilité d'atteindre les serveurs B via Link-Local.
Journal du vendredi 19 septembre 2025 à 16:51
Dans ma note du 2025-07-24_2231 au sujet de Containerlab je disais :
Je viens de poster le message suivant l'espace de discussion GitHub de Containerlab : « Does Containerlab support the creation of topologies with multiple subnets? ».
J'espère que le créateur de Containerlab pourra me suggérer une solution à mon problème, car je n'ai pas réussi à l'identifier dans la documentation 🤷♂️.
Depuis, j'ai eu une réponse et j'ai réussi à fixer mon problème : https://github.com/srl-labs/containerlab/discussions/2718#discussioncomment-14457884
Voici le résultat : https://github.com/srl-labs/containerlab/discussions/2814
Je ne suis pas satisfait de cette simulation, car de mon point de vue les Linux bridge créé par Docker configure trop de chose automatiquement.
Par exemple, l'IP 2001:db8:a:1::1 est automatiquement créé et assigné au bridge network-a.
De plus, je ne suis pas satisfait de cette simulation parce que containerlab configure automatiquement des routes au niveau de l'hôte pour interconnecter les réseaux Docker network-a, network-b et network-c, alors que dans un environnement réel, cette connectivité serait gérée par les équipements réseau de la topologie.
J'envisage peut-être de tester Mininet pour effectuer des simulations IPv6.
Journal du jeudi 24 juillet 2025 à 22:31
Suite à ma note "J'ai découvert ContainerLab, un projet qui permet de simuler des réseaux", j'ai implémenté et publié containerlab-playground.
Mon but était d'utiliser Containerlab pour simuler deux réseaux IPv6 connectés entre eux : 3 serveurs sur le premier réseau et 2 serveurs sur le second.
Comme je l'observe fréquemment depuis quelques mois, Claude Sonnet 4 m'a produit une implémentation qui, en pratique, ne fonctionne pas (voir son contenu dans 2025-07-20_1241).
La note courante reprend principalement en français le contenu du README.md de mon playground .
Voici les instructions que j'ai exécutées pour installer Containerlab sous Fedora :
$ sudo dnf config-manager addrepo --set=baseurl="https://netdevops.fury.site/yum/" && \
$ echo "gpgcheck=0" | sudo tee -a /etc/yum.repos.d/netdevops.fury.site_yum_.repo
$ sudo dnf install containerlab
$ sudo usermod -aG clab_admins stephane && newgrp clab_admins
$ sudo semanage fcontext -a -t textrel_shlib_t $(which containerlab)
$ sudo restorecon $(which containerlab)
Voici les instructions que j'ai exécutées pour installer Containerlab sous Fedora :
$ sudo containerlab deploy
11:27:03 INFO Containerlab started version=0.69.0
11:27:03 INFO Parsing & checking topology file=network-a-b.clab.yaml
11:27:03 INFO Creating docker network name=net-custom IPv4 subnet="" IPv6 subnet=2001:db8:a::0/48 MTU=0
11:27:03 INFO Creating lab directory path=/home/stephane/git/github.com/stephane-klein/containerlab-playground/clab-network-a
11:27:04 INFO Creating container name=vm-b1
11:27:04 INFO Creating container name=vm-a1
11:27:04 INFO Creating container name=vm-a2
11:27:04 INFO Creating container name=vm-a3
11:27:04 INFO Adding host entries path=/etc/hosts
11:27:04 INFO Adding SSH config for nodes path=/etc/ssh/ssh_config.d/clab-network-a.conf
╭──────────────────────┬───────────────────┬─────────┬─────────────────╮
│ Name │ Kind/Image │ State │ IPv4/6 Address │
├──────────────────────┼───────────────────┼─────────┼─────────────────┤
│ clab-network-a-vm-a1 │ linux │ running │ 192.168.0.2 │
│ │ mitchv85/ohv-host │ │ 2001:db8:a:1::1 │
├──────────────────────┼───────────────────┼─────────┼─────────────────┤
│ clab-network-a-vm-a2 │ linux │ running │ 192.168.0.3 │
│ │ mitchv85/ohv-host │ │ 2001:db8:a:1::2 │
├──────────────────────┼───────────────────┼─────────┼─────────────────┤
│ clab-network-a-vm-a3 │ linux │ running │ 192.168.0.4 │
│ │ mitchv85/ohv-host │ │ 2001:db8:a:1::3 │
├──────────────────────┼───────────────────┼─────────┼─────────────────┤
│ clab-network-a-vm-b1 │ linux │ running │ 192.168.0.5 │
│ │ mitchv85/ohv-host │ │ 2001:db8:a:2::5 │
╰──────────────────────┴───────────────────┴─────────┴─────────────────╯
Globalement, j'ai trouvé l'expérience utilisateur de la cli Containerlab très agréable à utiliser :
$ containerlab help
deploy container based lab environments with a user-defined interconnections
USAGE
containerlab [command] [--flags]
COMMANDS
completion [bash|zsh|fish] Generate completion script
config [command] [--flags] Configure a lab
deploy [--flags] Deploy a lab
destroy [--flags] Destroy a lab
exec [--flags] Execute a command on one or multiple containers
generate [--flags] Generate a Clos topology file, based on provided flags
graph [--flags] Generate a topology graph
help [command] [--flags] Help about any command
inspect [command] [--flags] Inspect lab details
redeploy [--flags] Destroy and redeploy a lab
save [--flags] Save containers configuration
tools [command] Various tools your lab might need
version [command] Show containerlab version or upgrade
FLAGS
-d --debug Enable debug mode
-h --help Help for containerlab
--log-level Logging level; one of [trace, debug, info, warning, error, fatal] (info)
--name Lab name
-r --runtime Container runtime
--timeout Timeout for external API requests (e.g. container runtimes), e.g: 30s, 1m, 2m30s (2m0s)
-t --topo Path to the topology definition file, a directory containing one, 'stdin', or a URL
--vars Path to the topology template variables file
-v --version Version for containerlab
J'ai eu quelques difficultés à trouver une image Docker à utiliser qui fournit directement un serveur ssh :
vm-a1:
kind: linux
# image: alpine-ssh
# https://hub.docker.com/r/mitchv85/ohv-host
image: mitchv85/ohv-host
mgmt-ipv6: 2001:db8:a:1::1
Le déploiement de cette image permet de facilement se connecter à l'host en ssh:
$ ssh admin@clab-network-a-vm-a1
admin@vm-a1:~$ exit
Il est possible de facilement lancer une commande sur tous les hosts :
$ sudo containerlab exec -t network-a-b.clab.yaml --cmd 'ip addr'
11:29:52 INFO Parsing & checking topology file=network-a-b.clab.yaml
11:29:52 INFO Executed command node=clab-network-a-vm-a2 command="ip addr"
stdout=
│ 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
│ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
│ inet 127.0.0.1/8 scope host lo
│ valid_lft forever preferred_lft forever
│ inet6 ::1/128 scope host
│ valid_lft forever preferred_lft forever
│ 2: eth0@if192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
│ link/ether aa:86:42:84:81:de brd ff:ff:ff:ff:ff:ff link-netnsid 0
│ inet 192.168.0.3/20 brd 192.168.15.255 scope global eth0
│ valid_lft forever preferred_lft forever
│ inet6 2001:db8:a:1::2/48 scope global nodad
│ valid_lft forever preferred_lft forever
│ inet6 fe80::a886:42ff:fe84:81de/64 scope link
│ valid_lft forever preferred_lft forever
11:29:52 INFO Executed command node=clab-network-a-vm-a3 command="ip addr"
stdout=
│ 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
│ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
│ inet 127.0.0.1/8 scope host lo
│ valid_lft forever preferred_lft forever
│ inet6 ::1/128 scope host
│ valid_lft forever preferred_lft forever
│ 2: eth0@if193: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
│ link/ether b2:42:6c:2b:d0:9d brd ff:ff:ff:ff:ff:ff link-netnsid 0
│ inet 192.168.0.4/20 brd 192.168.15.255 scope global eth0
│ valid_lft forever preferred_lft forever
│ inet6 2001:db8:a:1::3/48 scope global nodad
│ valid_lft forever preferred_lft forever
│ inet6 fe80::b042:6cff:fe2b:d09d/64 scope link
│ valid_lft forever preferred_lft forever
11:29:52 INFO Executed command node=clab-network-a-vm-a1 command="ip addr"
stdout=
│ 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
│ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
│ inet 127.0.0.1/8 scope host lo
│ valid_lft forever preferred_lft forever
│ inet6 ::1/128 scope host
│ valid_lft forever preferred_lft forever
│ 2: eth0@if191: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
│ link/ether 26:9f:87:52:d6:1c brd ff:ff:ff:ff:ff:ff link-netnsid 0
│ inet 192.168.0.2/20 brd 192.168.15.255 scope global eth0
│ valid_lft forever preferred_lft forever
│ inet6 2001:db8:a:1::1/48 scope global nodad
│ valid_lft forever preferred_lft forever
│ inet6 fe80::249f:87ff:fe52:d61c/64 scope link
│ valid_lft forever preferred_lft forever
11:29:52 INFO Executed command node=clab-network-a-vm-b1 command="ip addr"
stdout=
│ 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
│ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
│ inet 127.0.0.1/8 scope host lo
│ valid_lft forever preferred_lft forever
│ inet6 ::1/128 scope host
│ valid_lft forever preferred_lft forever
│ 2: eth0@if194: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
│ link/ether e2:81:7b:c7:eb:64 brd ff:ff:ff:ff:ff:ff link-netnsid 0
│ inet 192.168.0.5/20 brd 192.168.15.255 scope global eth0
│ valid_lft forever preferred_lft forever
│ inet6 2001:db8:a:2::5/48 scope global nodad
│ valid_lft forever preferred_lft forever
│ inet6 fe80::e081:7bff:fec7:eb64/64 scope link
│ valid_lft forever preferred_lft forever
Ou alors sur un host en particulier :
$ sudo containerlab exec -t network-a-b.clab.yaml --label clab-node-name=vm-a1 --cmd 'ip addr'
11:02:44 INFO Parsing & checking topology file=network-a-b.clab.yaml
11:02:44 INFO Executed command node=clab-network-a-vm-a1 command="ip addr"
stdout=
│ 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
│ link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
│ inet 127.0.0.1/8 scope host lo
│ valid_lft forever preferred_lft forever
│ inet6 ::1/128 scope host
│ valid_lft forever preferred_lft forever
Par contre, je n'ai pas réussi à atteindre mon objectif 😟.
J'ai l'impression que pour le moment, Containerlab ne permet pas de créer plusieurs réseaux à partir d'un fichier topologie.
Je n'ai pas compris comment définir la longueur du prefix IPv6 des interfaces eth0 au niveau des nodes.
Pour le moment, tous les nodes appartiennent au même sous-réseau 2001:db8:a::0/48, alors que j'aimerais les séparer dans les deux sous-réseaux suivants :
2001:db8:a:12001:db8:a:2
# network-a-b.clab.yaml
...
topology:
nodes:
vm-a1:
kind: linux
# image: alpine-ssh
# https://hub.docker.com/r/mitchv85/ohv-host
image: mitchv85/ohv-host
mgmt-ipv6: 2001:db8:a:1::1
# <== ici je ne sais pas comment définir : 2001:db8:a:1::1/64
...
J'ai découvert l'issue suivante du principal développeur de Containerlab : « Multiple management networks ».
Je pense comprendre que ce que je cherche à faire n'est actuellement pas possible avec Containerlab.
Pour atteindre mon objectif, peut-être que je devrais plutôt m'orienter vers des alternatives mentionnées dans ce billet de blog : Open-source network simulation roundup 2024.
Je viens de poster le message suivant l'espace de discussion GitHub de Containerlab : « Does Containerlab support the creation of topologies with multiple subnets? ».
J'espère que le créateur de Containerlab pourra me suggérer une solution à mon problème, car je n'ai pas réussi à l'identifier dans la documentation 🤷♂️.
Voir la suite de cette note : 2025-09-19_1651.
J'ai découvert ContainerLab, un projet qui permet de simuler des réseaux
Pendant mon travail d'étude pratique de IPv6, #JaiDécouvert le projet Containerlab :
Containerlab was meant to be a tool for provisioning networking labs built with containers. It is free, open and ubiquitous. No software apart from Docker is required! As with any lab environment it allows the users to validate features, topologies, perform interop testing, datapath testing, etc. It is also a perfect companion for your next demo. Deploy the lab fast, with all its configuration stored as a code -> destroy when done.
Projet qui a commencé en 2020 et semble principalement développé par un développeur de chez Nokia.
D'après ce que j'ai compris, Containerlab me permet de facilement créer des réseaux dans un simulateur.
Je me souviens que je cherchais ce type d'outil en 2018, quand je travaillais sur un projet baremetal as service chez Scaleway.
Voici un exemple de fichier créé par Claude.ai pour simuler un environnement composé de deux réseaux IPv6 connectés entre eux : 3 serveurs sur le premier réseau et 2 serveurs sur le second.
Je précise que je n'ai pas encore testé ce fichier. J'ignore donc s'il fonctionne correctement.
name: dual-network-ipv6-lab
topology:
nodes:
# Routeur avec IPv6
router:
kind: linux
image: alpine:latest
exec:
# Activer IPv6
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- sysctl -w net.ipv6.conf.all.forwarding=1
# Adresses IPv6 sur les interfaces
- ip -6 addr add 2001:db8:1::1/64 dev eth1
- ip -6 addr add 2001:db8:2::1/64 dev eth2
# IPv4 en parallèle (dual-stack)
- ip addr add 192.168.1.1/24 dev eth1
- ip addr add 192.168.2.1/24 dev eth2
- echo 1 > /proc/sys/net/ipv4/ip_forward
# Réseau A (2001:db8:1::/64)
vm-a1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::10/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.10/24 dev eth1
- ip route add default via 192.168.1.1
vm-a2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::11/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.11/24 dev eth1
- ip route add default via 192.168.1.1
vm-a3:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::12/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.12/24 dev eth1
- ip route add default via 192.168.1.1
# Réseau B (2001:db8:2::/64)
vm-b1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::10/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.10/24 dev eth1
- ip route add default via 192.168.2.1
vm-b2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::11/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.11/24 dev eth1
- ip route add default via 192.168.2.1
links:
# Réseau A
- endpoints: ["router:eth1", "vm-a1:eth1"]
- endpoints: ["router:eth1", "vm-a2:eth1"]
- endpoints: ["router:eth1", "vm-a3:eth1"]
# Réseau B
- endpoints: ["router:eth2", "vm-b1:eth1"]
- endpoints: ["router:eth2", "vm-b2:eth1"]
bridge-utils est déprécié, je dois remplacer "brctl" par "ip link"
En étudiant IPv6 et Linux bridge, j'ai découvert que le projet bridge-utils est déprécié. À la place, il faut utiliser iproute2.
Ce qui signifie que je ne dois plus utiliser la commande brctl, chose que j'ignorais jusqu'à ce matin.
iproute2 remplace aussi le projet net-tools. Par exemple, les commandes suivantes sont aussi dépréciées :
ifconfigremplacé parip addretip linkrouteremplacé parip routearpremplacé parip neighbrctlremplacé parip linkiptunnelremplacé parip tunnelnameifremplacé parip link set nameipmaddrremplacé parip maddr
Au-delà des aspects techniques — iproute2 utilise Netlink plutôt que ioctl — l'expérience utilisateur me semble plus cohérente.
J'ai une préférence pour une commande unique ip accompagnée de sous-commandes plutôt que pour un ensemble de commandes disparates.
Cette logique de sous-commandes s'inscrit dans une tendance générale de l'écosystème Linux, et je pense que c'est une bonne direction.
Je pense notamment à systemctl, timedatectl, hostnamectl, localectl, loginctl, apt, etc.
Quand j'ai débuté sous Linux en 1999, j'ai été habitué à utiliser les commande ifup et ifdown qui sont en réalité des scripts bash qui appellent entre autre ifconfig.
Ces scripts ont été abandonnés par les distributions Linux qui sont passées à systemd et NetworkManager.
En simplifiant, l'équivalent des commandes suivantes avec NetworkManager :
$ ifconfig
$ ifup eth0
$ ifdown eth0
est :
$ nmcli device status
$ nmcli connection up <nom_de_connexion>
$ nmcli connection down <nom_de_connexion>
Contrairement à mon intuition initiale, NetworkManager n'est pas un simple "wrapper" de la commande ip d'iproute2.
En fait, nmcli fonctionne de manière totalement indépendante d'iproute2, il utilise l'interface Netlink comme l'illustre cet exemple de la commande nmcli device show :
nmcli device show
↓ (Method call via D-Bus)
org.freedesktop.NetworkManager.Device.GetProperties()
↓ (NetworkManager traite la requête)
nl_send_simple(sock, RTM_GETLINK, ...)
↓ (Socket netlink vers kernel)
Kernel: netlink_rcv() → rtnetlink_rcv()
↓ (Retour des données)
RTM_NEWLINK response
↓ (libnl parse la réponse)
NetworkManager met à jour ses structures
↓ (Réponse D-Bus)
nmcli formate et affiche les données
Autre différence, contrairement à iproute2, les changements effectués par NetworkManager sont automatiquement persistants et il peut réagir à des événements, tel que le branchement d'un câble réseau et la présence d'un réseau WiFi connu.
Les paramètres de configuration de NetworkManager se trouvent dans les fichiers suivants :
- Fichiers de configuration globale de NetworkManager :
# Fichier principal
/etc/NetworkManager/NetworkManager.conf
# Fichiers de configuration additionnels
/etc/NetworkManager/conf.d/*.conf
- Fichiers de configuration des connexions NetworkManager :
# Configurations système (root)
/etc/NetworkManager/system-connections/
# Configurations utilisateur
~/.config/NetworkManager/user-connections/
Comme souvent, Ubuntu propose un outil "maison", nommé netplan qui propose un autre format de configuration. Mais je préfère utiliser nmcli qui est plus complet et a l'avantage d'être la solution mainstream supportée par toutes les distributions Linux.
Journal du vendredi 04 juillet 2025 à 14:46
En étudiant IPv6 et Linux bridge, j'ai découvert que Netlink a été introduit pour remplacer ioctl et procfs.
Netlink permet à des programmes user-land de communiquer avec le kernel via une API asynchrone. C'est une technologie de type inter-process communication (IPC).
La partie "Net" de "Netlink" s'explique par l'histoire : au départ, Netlink servait exclusivement à iproute2 pour la configuration réseau.
L'usage de Netlink s'est ensuite généralisé à d'autres aspects du kernel.
Journal du mercredi 12 février 2025 à 11:41
En rédigeant la note 2025-02-12_1044, je me suis demandé quelle est la différence de performance entre un Unix Socket et un INET socket.
Durant mes recherches, j'ai découvert qu'Unix Socket est plus rapide que INET sockets. Je n'ai pas été surpris, j'avais cette intuition.
Toutefois, j'ai été surpris d'apprendre que le gain est non négligeable, de 30% à 50% de gains !
Exemple :
On my machine, Ryzen 3900X, Ubuntu 22,
A basic C++ TCP server app that only sends 64K packets, and a basic c++ receiver that pulls 100GB of these packets and copies them to it's internal buffer only, single-threaded:
- achieves
~30-33 GBit/secfor TCP connection (~4.0GB/sec) (not MBit)- and
~55-58GBit/secfor a socket connection, (~7.3 GB/sec)- and
~492Gbit/secfor in-process memcopy (~61GB /sec)
Conséquence : je vais essayer d'utiliser des Unix sockets autant que je peux.
Journal du mercredi 29 janvier 2025 à 22:22
En étudiant Pi-hole, je découvre le terme "DNS sinkhole" :
A DNS sinkhole, also known as a sinkhole server, Internet sinkhole, or Blackhole DNS is a Domain Name System (DNS) server that has been configured to hand out non-routable addresses for a certain set of domain names.
...
Another use is to block ad serving sites, either using a host's file-based sinkhole or by locally running a DNS server (e.g., using a Pi-hole). Local DNS servers effectively block ads for all devices on the network.
Journal du vendredi 24 janvier 2025 à 19:00
Dans l'article Wikipedia IPv6, j'ai découvert le terme addresse de Liaison Locale ou Link-Local, qui est utilisé pour communiquer avec des hôtes du réseau physique local.
Ces adresses commences par fe80::....
Certains préfixes d’adresses IPv6 jouent des rôles particuliers :
Description Terme anglais Détail Préfixe IPv6 Équivalent IPv4 Boucle Locale Node-local
LoopbackAdresse de bouclage, utilisée lorsqu'un hôte se parle à lui-même (ex : envoi de données entre 2 programmes sur cet hôte). ::1/128 127.0.0.0/8 (principalement 127.0.0.1) Liaison Locale Link-Local Envoi individuel sur liaison locale (RFC 4291). Obligatoire et indispensable au bon fonctionnement du protocole. fe80::/10 169.254.0.0/16 ... ... ... ... ...
Appliquer une configuration nftables avec un rollback automatique de sécurité
Voici une astuce pour appliquer une configuration nftables en toute sécurité, pour éviter tout risque d'être "enfermé dehors".
Je commence par m'assurer que le fichier de configuration ne contient pas d'erreur de syntaxe ou autre :
# nft -c -f /etc/nftables.conf
Sauvegarder la configuration actuelle :
# nft list ruleset > /root/nftables-backup.conf
Application de la configuration avec un rollback automatique exécuté après 200 secondes :
# (sleep 200 && nft -f /root/nftables-backup.conf) & sudo nft -f /etc/nftables.conf
Après cette commande, j'ai 200 secondes pour tester si j'ai toujours bien accès au serveur.
Si tout fonctionne bien, alors je peux exécuter la commande suivante pour désactiver le rollback :
# pkill -f "sleep 200"
Journal du dimanche 19 janvier 2025 à 11:24
#iteration Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram :
Être capable d'exposer sur Internet un port d'une VM.
Voici comment j'ai atteint cet objectif.
Pour faire ce test, j'ai installé un serveur http nginx sur une VM qui a l'IP 192.168.1.236.
Cette IP est attribuée par le DHCP installé sur mon routeur OpenWrt. Le serveur hôte Proxmox est configuré en mode bridge.
Ma Box Internet Bouygues sur 192.168.1.254 peut accéder directement à cette VM 192.168.1.236.
Pour exposer le serveur Proxmox sur Internet, j'ai configuré mon serveur Serveur NUC i3 gen 5 en tant que DMZ host.
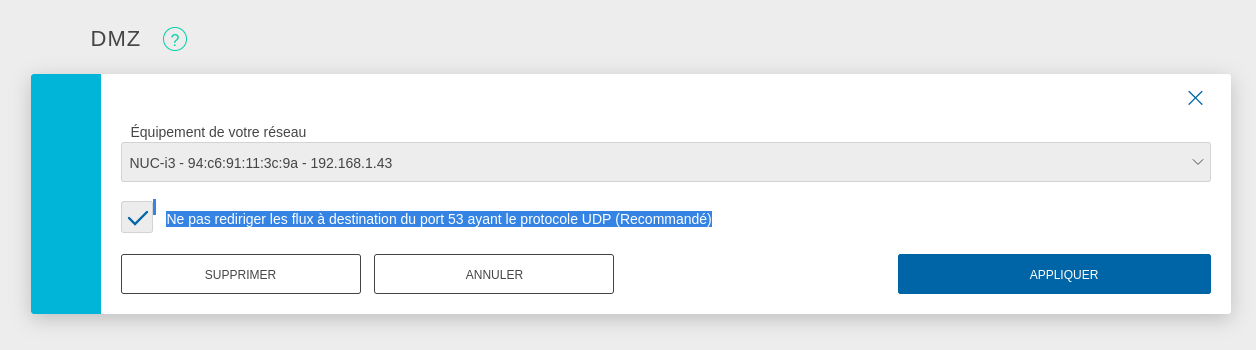
J'ai suivi la recommandation pour éviter une attaque du type : DNS amplification attacks
DNS amplification attacks involves an attacker sending a DNS name lookup request to one or more public DNS servers, spoofing the source IP address of the targeted victim.
Avec cette configuration, je peux accéder en ssh au Serveur NUC i3 gen 5 depuis Internet.
J'ai tout de suite décidé d'augmenter la sécurité du serveur ssh :
# cat <<'EOF' > /etc/ssh/sshd_config.d/sklein.conf
Protocol 2
PasswordAuthentication no
PubkeyAuthentication yes
AuthenticationMethods publickey
KbdInteractiveAuthentication no
X11Forwarding no
# systemctl restart ssh
J'ai ensuite configuré le firewall basé sur nftables pour mettre en place quelques règles de sécurité et mettre en place de redirection de port du serveur hôte Proxmox vers le port 80 de la VM 192.168.1.236.
nftables est installé par défaut sur Proxmox mais n'est pas activé. Je commence par activer nftables :
root@nuci3:~# systemctl enable nftables
root@nuci3:~# systemctl start nftables
Voici ma configuration /etc/nftables.conf, je me suis fortement inspiré des exemples présents dans ArchWiki : https://wiki.archlinux.org/title/Nftables#Server
# cat <<'EOF' > /etc/nftables.conf
flush ruleset;
table inet filter {
# Configuration from https://wiki.archlinux.org/title/Nftables#Server
set LANv4 {
type ipv4_addr
flags interval
elements = { 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 169.254.0.0/16 }
}
set LANv6 {
type ipv6_addr
flags interval
elements = { fd00::/8, fe80::/10 }
}
chain input {
type filter hook input priority filter; policy drop;
iif lo accept comment "Accept any localhost traffic"
ct state invalid drop comment "Drop invalid connections"
ct state established,related accept comment "Accept traffic originated from us"
meta l4proto ipv6-icmp accept comment "Accept ICMPv6"
meta l4proto icmp accept comment "Accept ICMP"
ip protocol igmp accept comment "Accept IGMP"
udp dport mdns ip6 daddr ff02::fb accept comment "Accept mDNS"
udp dport mdns ip daddr 224.0.0.251 accept comment "Accept mDNS"
ip saddr @LANv4 accept comment "Connections from private IP address ranges"
ip6 saddr @LANv6 accept comment "Connections from private IP address ranges"
tcp dport ssh accept comment "Accept SSH on port 22"
tcp dport 8006 accept comment "Accept Proxmox web console"
udp sport bootpc udp dport bootps ip saddr 0.0.0.0 ip daddr 255.255.255.255 accept comment "Accept DHCPDISCOVER (for DHCP-Proxy)"
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table nat {
chain prerouting {
type nat hook prerouting priority dstnat;
tcp dport 80 dnat to 192.168.1.236;
}
chain postrouting {
type nat hook postrouting priority srcnat;
masquerade
}
}
EOF
Pour appliquer en toute sécurité cette configuration, j'ai suivi la méthode indiquée dans : "Appliquer une configuration nftables avec un rollback automatique de sécurité".
Après cela, voici les tests que j'ai effectués :
- Depuis mon réseau local :
- Test d'accès au serveur Proxmox via ssh :
ssh root@192.168.1.43 - Test d'accès au serveur Proxmox via la console web : https://192.168.1.43:8006
- Test d'accès au service http dans la VM :
curl -I http://192.168.1.236
- Test d'accès au serveur Proxmox via ssh :
- Depuis Internet :
Voilà, tout fonctionne correctement 🙂.
Prochaines étapes :
- Être capable d'accéder depuis Internet via IPv6 à une VM
- Je souhaite arrive à effectuer un déploiement d'une Virtual instance via Terraform
Alternatives managées à ngrok Developer Preview
Dans la note 2024-12-31_1853, j'ai présenté sish-playground qui permet de self host sish.
Je souhaite maintenant lister des alternatives à ngrok qui proposent des services gérés.
Quand je parle d'alternative à ngrok, il est question uniquement de la fonctionnalité d'origine de ngrok en 2013 : exposer des serveurs web locaux (localhost) sur Internet via une URL publique. ngrok nomme désormais ce service "Developer Preview".
Offre managée de sish
Les développeurs de sish proposent un service managé à 2 € par mois.
Ce service permet l'utilisation de noms de domaine personnalisés : https://pico.sh/custom-domains#tunssh.
Test de la fonctionnalité "Developer Preview" de ngrok
J'ai commencé par créer un compte sur https://ngrok.com.
Ensuite, une fois connecté, la console web de ngrok m'invite à installer le client ngrok. Voici la méthode que j'ai suivie sur ma Fedora :
$ wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz -O ~/Downloads/ngrok-v3-stable-linux-amd64.tgz
$ sudo tar -xvzf ~/Downloads/ngrok-v3-stable-linux-amd64.tgz -C /usr/local/bin
$ ngrok --help
ngrok version 3.19.0
$ ngrok config add-authtoken 2r....RN
$ ngrok http http://localhost:8080
ngrok (Ctrl+C to quit)
👋 Goodbye tunnels, hello Agent Endpoints: https://ngrok.com/r/aep
Session Status online
Account Stéphane Klein (Plan: Free)
Version 3.19.0
Region Europe (eu)
Web Interface http://127.0.0.1:4040
Forwarding https://2990-2a04-cec0-107a-ea02-74d7-2487-cc11-f4d2.ngrok-free.app -> http://localhost:8080
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00
Cette fonctionnalité de ngrok est gratuite.
Toutefois, pour pouvoir utiliser un nom de domaine personnalisé, il est nécessaire de souscrire à l'offre "personal" à $8 par mois.
Test de la fonctionnalité Tunnel de Cloudflare
Pour exposer un service local sur Internet via une URL publique avec cloudflared, je pense qu'il faut suivre la documentation suivante : Create a locally-managed tunnel (CLI).
J'ai trouvé sur cette page, le package RPM pour installer cloudflared sous Fedora :
$ wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-x86_64.rpm -O /tmp/cloudflared-linux-x86_64.rpm
$ sudo rpm -i /tmp/cloudflared-linux-x86_64.rpm
$ cloudflared --version
cloudflared version 2024.12.2 (built 2024-12-19-1724 UTC)
Voici comment exposer un service local sur Internet via une URL publique avec cloudflared sans même créer un compte :
$ cloudflared tunnel --url http://localhost:8080
...
Requesting new quick Tunnel on trycloudflare.com...
Your quick Tunnel has been created! Visit it at (it may take some time to be reachable):
https://manufacturer-addressing-surgeon-tried.trycloudflare.com
Après cela, le service est exposé sur Internet sur l'URL suivante : https://manufacturer-addressing-surgeon-tried.trycloudflare.com.
Voici maintenant la méthode pour exposer un service sur un domaine spécifique.
Pour cela, il faut que le nom de domaine soit géré pour les serveurs DNS de cloudflare.
Au moment où j'écris cette note, c'est le cas pour mon domaine stephane-klein.info :
$ dig NS stephane-klein.info +short
ali.ns.cloudflare.com.
sri.ns.cloudflare.com.
Ensuite, il faut lancer :
$ cloudflared tunnel login
Cette commande ouvre un navigateur, ensuite il faut se connecter à cloudflare et sélectionner le nom de domaine à utiliser, dans mon cas j'ai sélectionné stephane-klein.info.
Ensuite, il faut créer un tunnel :
$ cloudflared tunnel create mytunnel
Tunnel credentials written to /home/stephane/.cloudflared/61b0e52f-13e3-4d57-b8da-6c28ff4e810b.json. …
La commande suivante, connecte le tunnel mytunnel au hostname mytunnel.stephane-klein.info :
$ cloudflared tunnel route dns mytunnel mytunnel.stephane-klein.info
2025-01-06T17:52:10Z INF Added CNAME mytunnel.stephane-klein.info which will route to this tunnel tunnelID=67db5943-1f16-4b4a-a307-e8ceeb01296c
Et, voici la commande pour exposer un service sur ce tunnel :
$ cloudflared tunnel --url http://localhost:8080 run mytunnel
Après cela, le service est exposé sur Internet sur l'URL suivante : https://mytunnel.stephane-klein.info.
Pour finir, voici comment détruire ce tunnel :
$ cloudflared tunnel delete mytunnel
J'ai essayé de trouver le prix de ce service, mais je n'ai pas trouvé. Je pense que ce service est gratuit, tout du moins jusqu'à un certain volume de transfert de données.
Journal du mercredi 27 novembre 2024 à 14:33
Un ami m'a partagé ce thread au sujet de l'IP fixe chez Bouygues qui semble indiquer que l'offre fibre de Bouygues ne propose pas d'IP fixe ?
En pratique, je constate que l'IP publique de ma fibre est fixe depuis plus d'un an : 176.142.86.141.
Voici, ci-dessous, les informations que j'ai trouvées à ce sujet.
Dans le document "Comparatif des offres en fibre optique des principaux opérateurs grand public en France, au 15 juillet 2024" du site lafibre.info, concernant la fibre de Bouygues, je lis :
- IPv4 fixe (dédiée ou mutualisée 8 064 ports.
- IPv4 dédiée gratuite sur demande.
- Plage IPv6 /60 fixe pour tous les clients
Dans le document "2024-07 ARCEP Baromètre ipv6 - partage ipv4" du site lafibre.info, je lis, concernant la fibre de Bouygues :
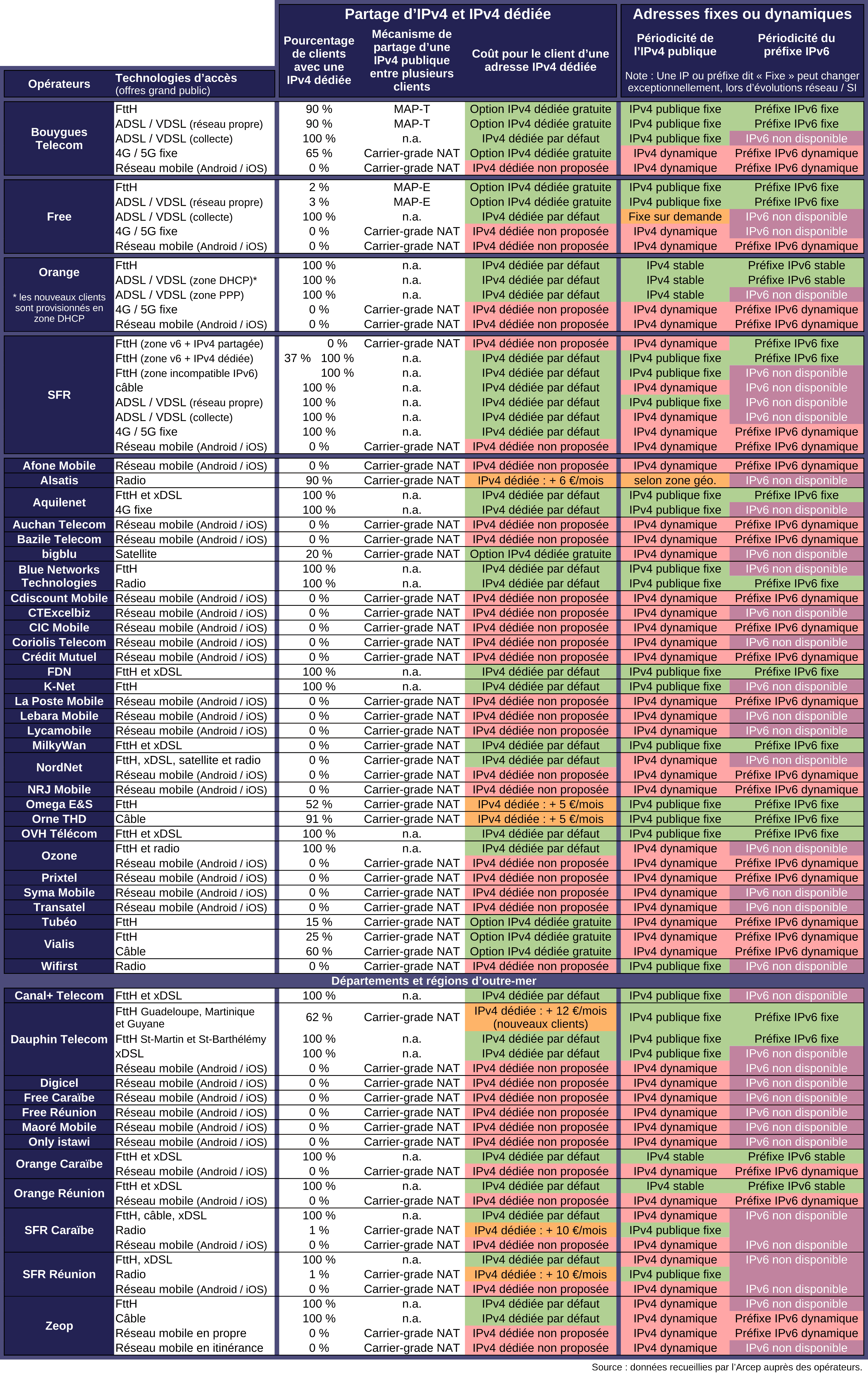{kind=link}
- Option IPv4 dédié gratuite.
- Pourcentage de clients avec une IPv4 dédiée : 90 %.
- Adresse fixes ou dynamiques (une IP ou prefixe dit « fixe » peut changer exceptionnelement, lors d'évolutions réseau / SI) :
- IPv4 publique fixe
- Préfixe IPv6 fixe
Voici mon interprétation : je pense que l'IP de l'offre fibre de Bouygues est fixe, mais peut exceptionnellement changer.
C'est ce que semble confirmer la personne membre du support technique de Bouygues dans le thread mentionné en début de cette note :
Journal du mardi 12 novembre 2024 à 13:26
#JaiDécouvert LibreSpeed que je vais utiliser à la place de https://fast.com/.
Il me propose une information supplémentaire à Fast.com : jitter.
Ma première mesure, en étant connecté en wifi :
- ping 17.0ms
- jitter : 120ms
La valeur jitter était anormalement élevée. J'ai relancé mon interface wifi radio 1 de mon Xiaomi Mi Router 4A Gigabit Edition sur un autre canal :
Maintenant, j'ai de bien meilleures performances :
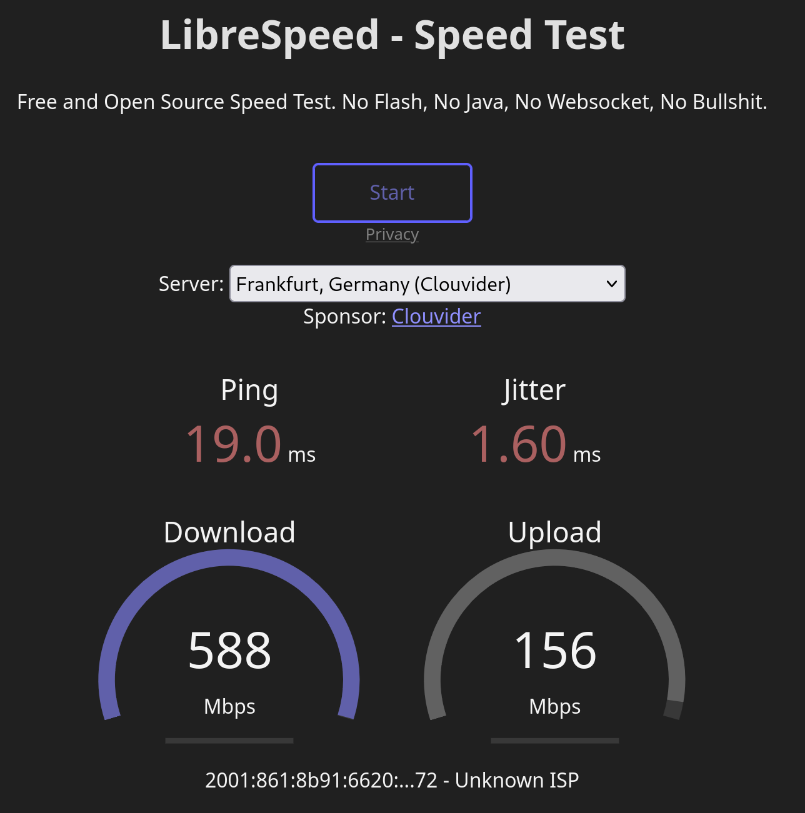
Voici le même test quand mon laptop est connecté en câble Ethernet :
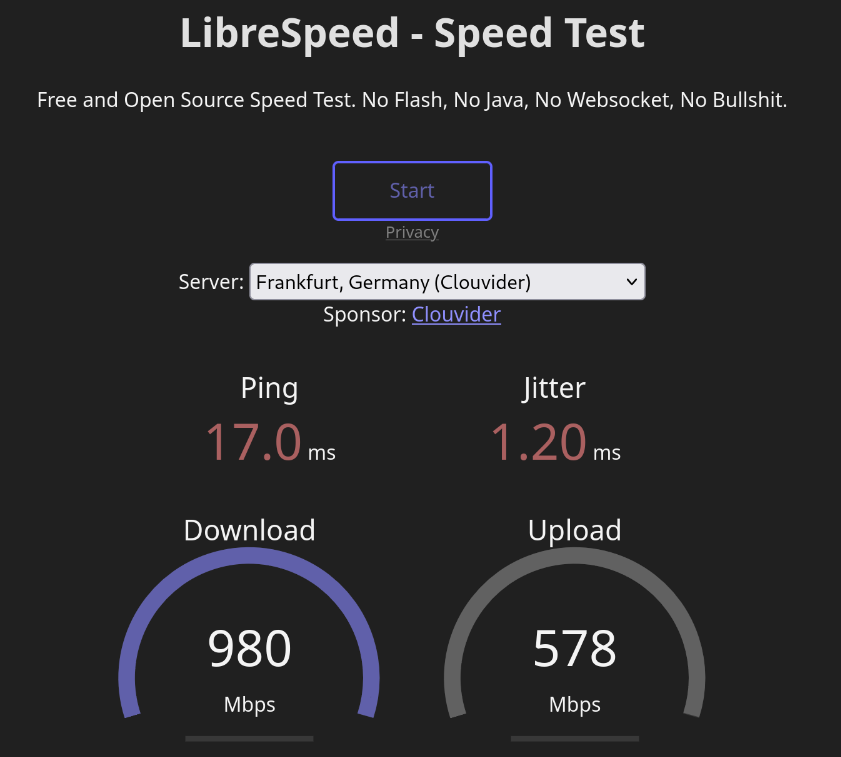
Les valeurs du ping et du jitter sont comparables, seul le débit est supérieur.
Journal du mardi 12 novembre 2024 à 11:56
#JaiDécouvert le projet "Falling-Sky project" qui propulse, par exemple, l'instance test-IPv6.com.
Résultat de http://test-ipv6.com/index.html.fr_FR quand je suis connecté à mon réseau domestique :
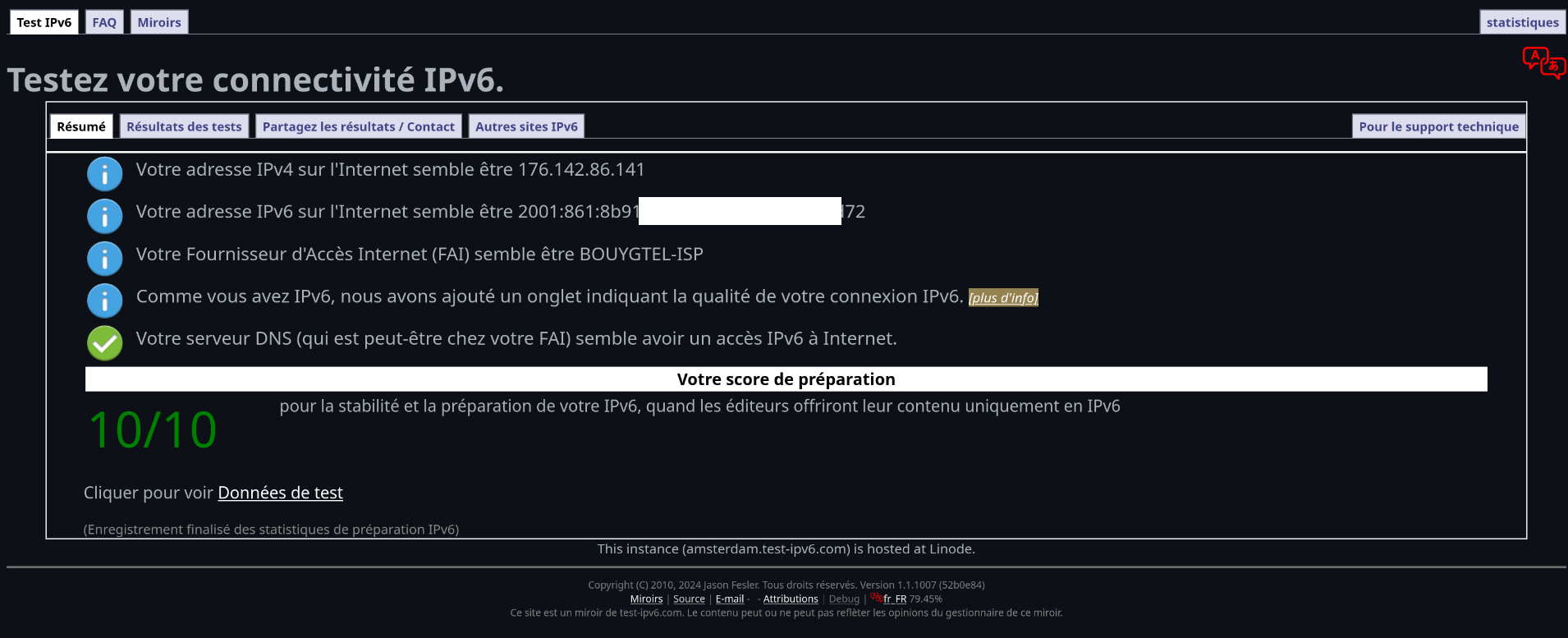
J'ai vérifié, tous mes devices ont bien une IPv6 spécifique.
Journal du dimanche 10 novembre 2024 à 10:19
#JaiDécouvert le thread TUTO - Remplacement BBox Fibre par Mikrotik (IPv4, IPv6 et TV/Replay).
#JaiDécouvert la section "remplacer-bbox" du forum lafibre.info.
J'ai étudié les connecteurs SFP+.
#JaiDécouvert le site https://hack-gpon.org
#JaiDécouvert les termes ONT (Optical Network Terminal), GPON (Gigabit Passive Optical Network), OLT (Optical Line Terminal), Fiber-optic splitter, PLOAM.
J'ai apprécié la lecture de ce schéma :
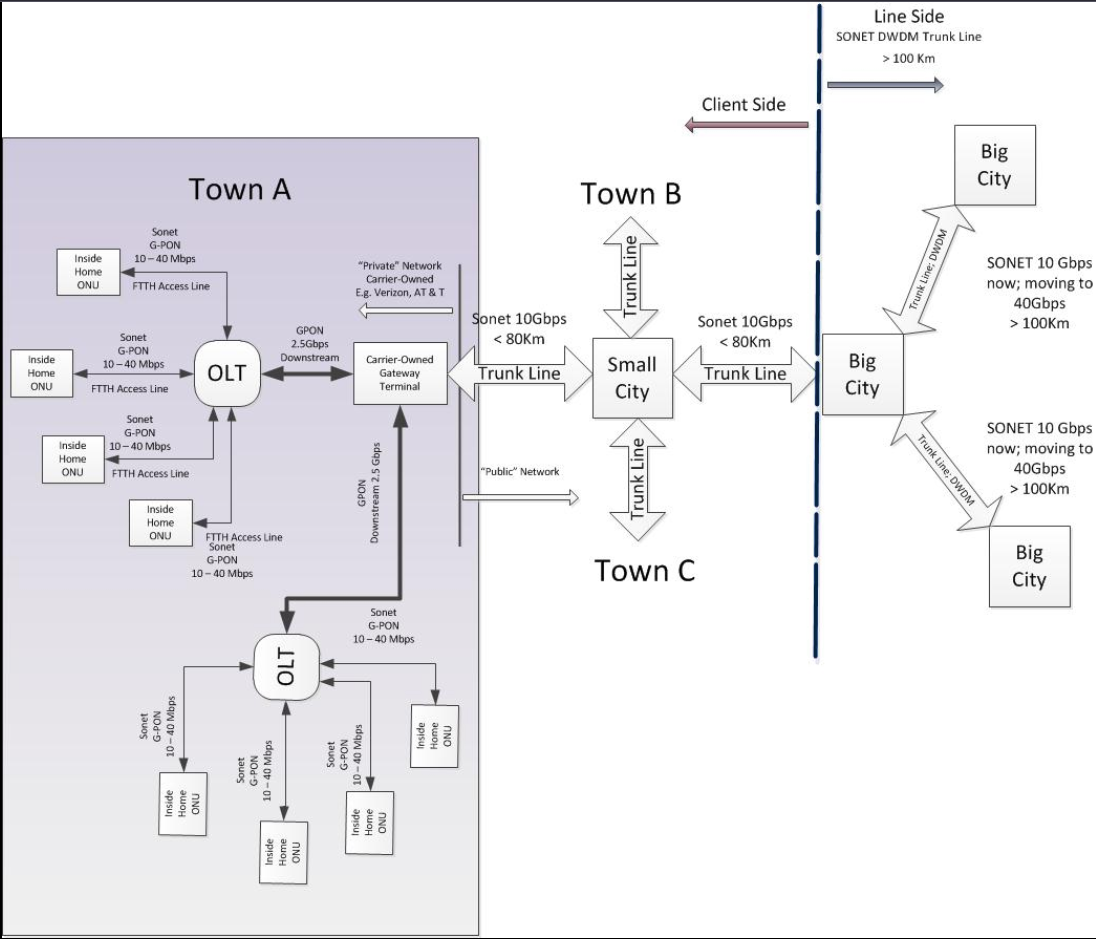
Bien que je pense que les débits ne sont pas à jour.
Voici le matériel listé dans TUTO - Remplacement BBox Fibre par Mikrotik (IPv4, IPv6 et TV/Replay) :
- Module ONU SFP GPON avec Mac à 70 € TTC
- Mikrotik CCR2116-12G-4S+ à 937 € 😮
- Mikrotik CRS310-1G-5S-4S+IN à 200 €
- TPLink TP-MC22L à 20 €
CRS310-1G-5S-4S+IN permet d'insérer 4 SFP+, je pense qu'il est possible d'utiliser soit ce routeur, soit le CCR2116-12G-4S+.
Afin de faciliter le paramétrage du module SFP GPON : 1x convertisseur de media (par exemple TPLink TP-MC22L)
J'ai des difficultés à comprendre, j'ai l'impression que l'article liste beaucoup de matériel redondant 🤔.
En étudiant le sujet, je suppose que la configuration matérielle minimale est : TP-MC22L à 20 € + Module ONU SFP GPON avec Mac à 70 € TTC.
Je compends que le ONT a besoin des paramètres suivants pour se connecter au réseau (GPON) Bouygues :
- Dans l'interface de la BBox, le SN du SFP commençant par SMB :
SMBA0000X000, qui semble être utilisé en tant qu'identifiant - Sur l'étiquette arrière de la BBox :
- L'adresse MAC :
48:29:FF:FF:FF:FF - L'IMEI :
123456789012345converti en0000123456789012345qui est utilisé en tant que "password"
- L'adresse MAC :
Ce commentaire liste le matériel suivant :
- Netgear GS724Tv4 - Smart Switch Ethernet 24 Ports RJ45 Gigabit (10/100/1000), Web Manageable Professionnel - switch RJ45 avec 2 Ports SFP 1 Gigabit, Bureau ou en Rack et Protection à Vie ProSafe à 256 €
- Mikrotik RB3011UiAS-RM à 175 €
Journal du samedi 09 novembre 2024 à 10:05
#JaiDécouvert la signification de iNIC (from).
Journal du mardi 05 novembre 2024 à 11:34
En explorant la console de Scaleway, je viens de tomber sur la fonctionnalité suivante :
Scaleway Domains and DNS provides advanced features for traffic management using your DNS zone. It allows you to redirect users based on their geolocation, the load on your different servers, and more.
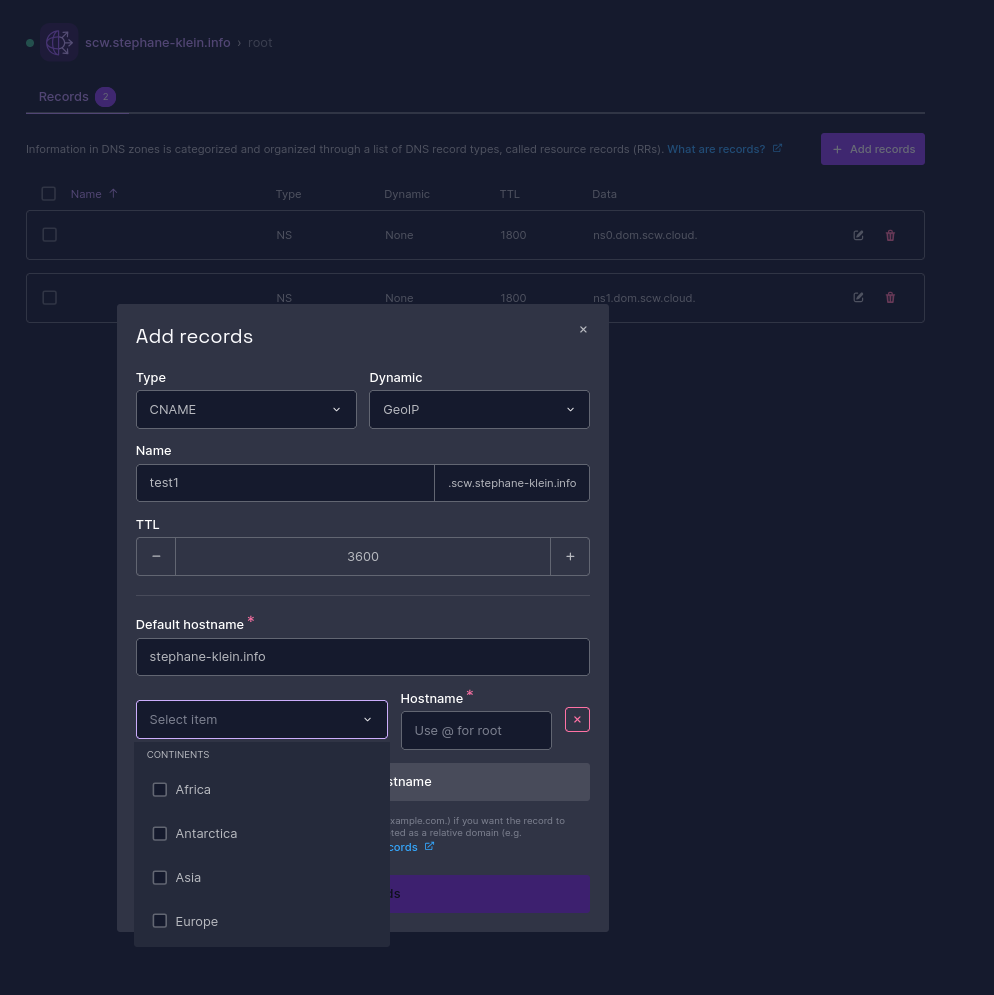
Je viens de réaliser que cela répond à une question que je me posais souvent entre 2000 et 2010 : comment les sites à portée mondiale parviennent-ils à répartir le trafic entre différents datacenters avec une URL unique, comme google.com ?
À l’époque, j’imaginais que ces acteurs utilisaient principalement le Round-robin DNS ou des algorithmes de répartition de charge avec HAProxy. mais je n'avais pas pensé à la possibilité que le serveur DNS puisse donner une réponse différente en fonction de l'IP de la personne qui fait la requête.
De plus, cette réponse peut dépendre de la localisation de l'IP (GeoIP).
Par exemple, depuis 2014, le serveur DNS Bind propose nativement la fonctionnalité "GeoIP Features".
J'ai lu aussi que les gros acteurs utilisent la méthode Anycast, mais cette méthode nécessite de gérer son propre Autonomous System.
Article Wikipedia : https://fr.wikipedia.org/wiki/GeoIP
Article Wikipedia : https://en.wikipedia.org/wiki/DNS_sinkhole
Article Wikipedia : https://fr.wikipedia.org/wiki/Zone_démilitarisée_(informatique)
Some router have a feature called DMZ host. This feature could designate one node (PC or other device with an IP address) as a DMZ host. The router's firewall exposes all ports on the DMZ host to the external network and hinders no inbound traffic from the outside going to the DMZ host. This is a less secure alternative to port forwarding, which only exposes a handful of ports.
Article Wikipedia : https://fr.wikipedia.org/wiki/Autonomous_System
Article Wikipedia https://fr.wikipedia.org/wiki/Anycast
Article Wikipedia : https://en.wikipedia.org/wiki/Pi-hole
Signifie : "Physical Layer Operations, Administration, and Maintenance".
ChatGPT me dit :
Le PLOAM fait partie du niveau physique (la couche physique) du réseau GPON et permet de surveiller, administrer, et maintenir la communication entre l'OLT et les ONT.
Fonctionnalités principales de PLOAM
- Authentification des ONT : Lorsqu'un ONT est ajouté au réseau, le processus PLOAM permet à l'OLT de vérifier et d'authentifier cet ONT avant qu'il puisse accéder au réseau, garantissant ainsi que seules les unités autorisées peuvent être connectées.
- Gestion de la performance : PLOAM assure la gestion de la qualité du service (QoS) en surveillant les performances du lien optique. Il permet à l'OLT d’ajuster les paramètres comme la puissance du signal pour garantir des connexions stables et fiables.
- Surveillance et maintenance : Le PLOAM est utilisé pour surveiller l'état des ONT et de la liaison optique. Par exemple, l'OLT peut recevoir des informations sur des erreurs ou des défaillances possibles. En cas de problème, PLOAM permet une intervention rapide pour rétablir la connectivité.
- Contrôle des erreurs et récupération : Il fournit des mécanismes pour détecter et corriger les erreurs au niveau de la couche physique, garantissant ainsi que les ONT et l'OLT restent synchronisés et fonctionnent correctement.
- Gestion des ressources : PLOAM peut être utilisé pour gérer les ressources du réseau, comme les canaux optiques et les plages de bande passante allouées à chaque ONT, afin de maintenir une performance optimale et éviter les interférences entre les utilisateurs.
Article Wikipedia : https://fr.wikipedia.org/wiki/Gigue_(informatique)
Article Wikipedia : https://fr.wikipedia.org/wiki/Nftables
Unique Local est un type d'adresse IPv6.
Voir section « Adresse IPv6 ».
Article Wikipedia : https://en.wikipedia.org/wiki/Network_bridge
Différence entre en Network bridge et un network switch :
En pratique : Un switch est essentiellement un "multi-port bridge". Le terme "bridge" est souvent réservé aux dispositifs simples ou aux implémentations logicielles (comme les bridges Linux).
Outil spécifique à Ubuntu à la place de NetworkManager.
Site officiel : https://netplan.io/
Linux bridge est un module du kernel Linux qui permet d'émuler des network switch par voie logicielle.
Documentation officielle actuelle semble être : https://docs.kernel.org/next/networking/bridge.html
L'ancienne documentation : https://wiki.linuxfoundation.org/networking/bridge
Code source : https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/net/bridge?h=v6.15.4
Pour gérer le module Linux bridge, il faut utiliser iproute2 ou NetworkManager. La commande brctl du projet déprécié bridge-utils ne doit plus être utilisée.
Article Wikipedia : https://fr.wikipedia.org/wiki/Network_address_translation
Article Wikipedia : https://en.wikipedia.org/wiki/IPv6_address#Address_formats
Vous êtes sur la première page | [ Page suivante (7) >> ]