
RAG
Papier de recherche qui invente le terme RAG : arXiv:2005.11401 - Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Article Wikipedia : https://en.wikipedia.org/wiki/Retrieval-augmented_generation
Journaux liées à cette note :
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals ou harnais (harness). Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
Journal du vendredi 03 janvier 2025 à 15:45
Dans ce thread Hacker News, #JaiDécouvert le RAG kotaemon (https://github.com/Cinnamon/kotaemon).
J'ai fait un simple test sur "Live Demo", j'ai trouvé le résultat très intéressant :
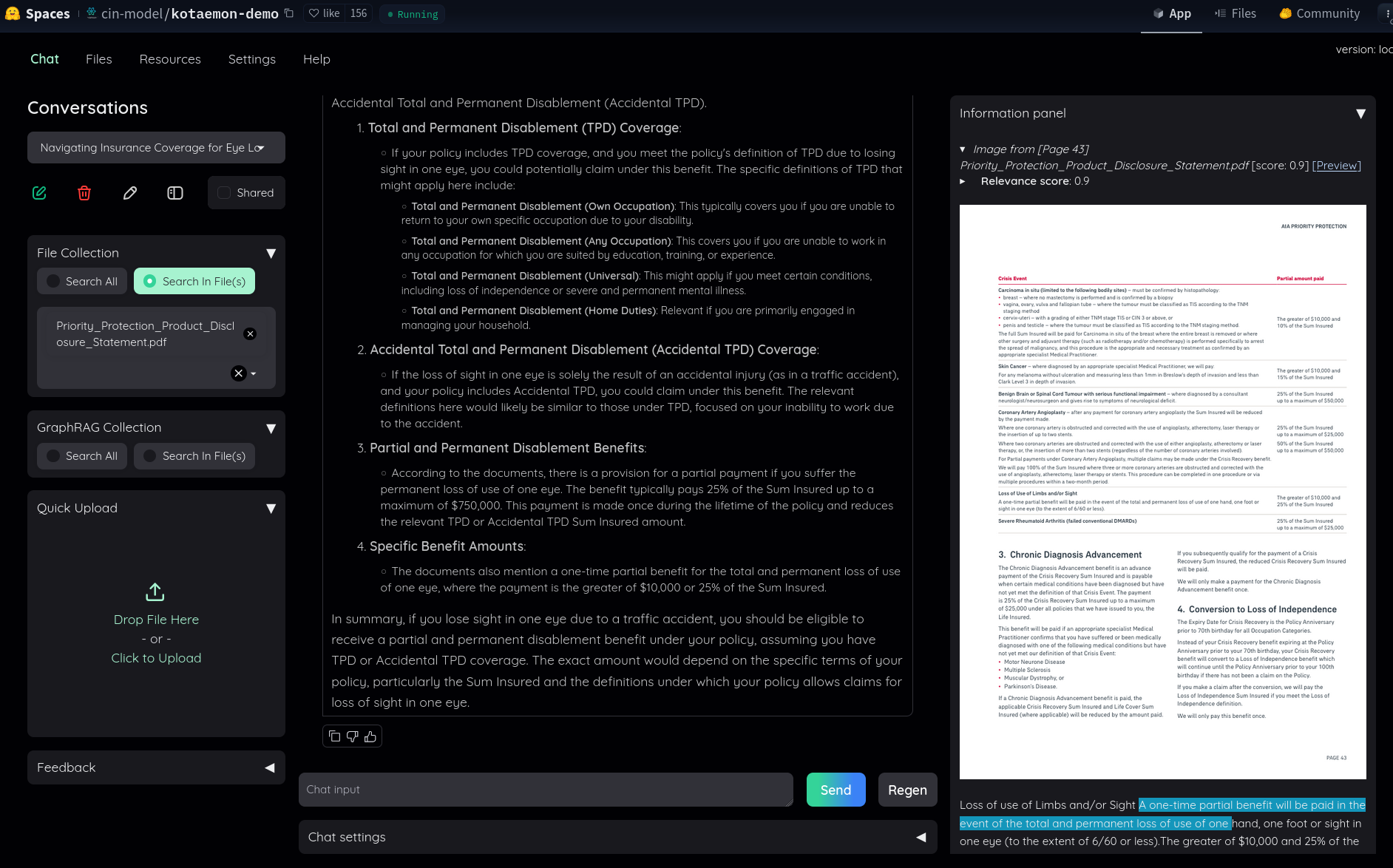
Dans le README, #JaiDécouvert GraphRAG (https://github.com/microsoft/graphrag), nano-graphrag (https://github.com/gusye1234/nano-graphrag) et LightRAG (https://github.com/HKUDS/LightRAG).
J'ai compris que kotaemon peut fonctionner avec nano-graphrag, LightRAG et GraphRAG et que nano-graphrag était recommandé.
J'ai lu :
Support for Various LLMs: Compatible with LLM API providers (OpenAI, AzureOpenAI, Cohere, etc.) and local LLMs (via
ollamaandllama-cpp-python).
J'ai l'impression que kotaemon est un outil de RAG complet, prêt à l'emploi, contrairement à llama_index qui se positionne davantage comme une bibliothèque de plus bas niveau.
Dans le Projet 20 - "Créer un POC d'un RAG", je pense commencer par tester kotaemon.
Journal du jeudi 26 décembre 2024 à 15:03
J'ai partagé Projet 20 - "Créer un POC d'un RAG" à un ami, il m'a dit « Pourquoi ne pas entraîner directement un modèle ? ».
Voici ma réponse sous forme de note.
Je tiens à préciser que je ne suis pas un expert du domaine.
Dans le manuscrit de l'épisode Augmenter ChatGPT avec le RAG de Science4All, je lis :
Quatre grandes catégories de solutions ont été proposées pour faire en sorte qu'un algorithme de langage apprenne une information.
Voici cette liste :
-
- le pré-entraînement, ou "pre-training" en anglais
-
- "peaufinage", qu'on appelle "fine-tuning" en anglais
Concernant le pre-training, je lis :
En pratique, ce pré-entraînement est toutefois très insuffisant pour que les algorithmes de langage soient capables de se comporter de manière satisfaisante.
Ensuite, je lis au sujet du fine-tuning :
Pour augmenter la fiabilité de l'algorithme, on peut alors effectuer un "peaufinage", qu'on appelle "fine-tuning" en anglais, et qui consiste typiquement à demander à des humains d'évaluer différentes réponses de l'algorithme.
...
Cependant, cette approche de peaufinage est coûteuse, à la fois en termes de ressources humaines et de ressources en calculs, et son efficacité est loin d'être suffisante pour une tâche aussi complexe que le langage.
Notez qu'on parle aussi de "peaufinage" pour la poursuite du pré-entraînement, mais cette fois sur des données proches du cas d'usage de l'algorithme. C'est typiquement le cas quand on part d'un algorithme open-weight comme Llama, et qu'on cherche à l'adapter aux contextes d'utilisation d'une entreprise particulière. Mais là encore, le coût de cette approche est important, et son efficacité est insuffisante.
Ensuite, au sujet du pré-prompting, je lis :
si cette approche est la plus efficace et la moins coûteuse, elle demeure encore très largement non-sécurisée ; et il faut s'attendre à ce que le chatbot déraille. Mais surtout, le pré-prompting est nécessairement limité car il ne peut pas être trop long.
Et, pour finir, je lis :
Je trouve que le paragraphe suivant donne une bonne explication du fonctionnement d'un RAG :
L'idée du RAG est la suivante : on va indexer tout un tas de documents qu'on souhaite enseigner à l'algorithme, et on va définir des méthodes pour lui permettre d'identifier, étant donné une requête d'un utilisateur, les bouts de documents qui sont les plus pertinents pour répondre à la requête de l'utilisateur. Ces bouts de documents sont ainsi "récupérés", et ils seront alors ajoutés à un preprompt fourni à l'algorithme, d'où "l'augmentation". Enfin, on va demander à l'algorithme de générer une réponse avec ce préprompt, d'où le nom de "Retrieval Augmented Generation". La boucle est bouclée !
Après lecture de ces informations, je pense qu'entrainer directement un modèle est une solution moins efficace qu'utiliser un RAG pour les objectifs décrits dans le Projet 20 - "Créer un POC d'un RAG".
Journal du mardi 13 août 2024 à 10:41
Deux amis m'ont partagé un thread Hacker News : Postgres.new: In-browser Postgres with an AI interface.
Je viens de prendre le temps de tester postgres.new.
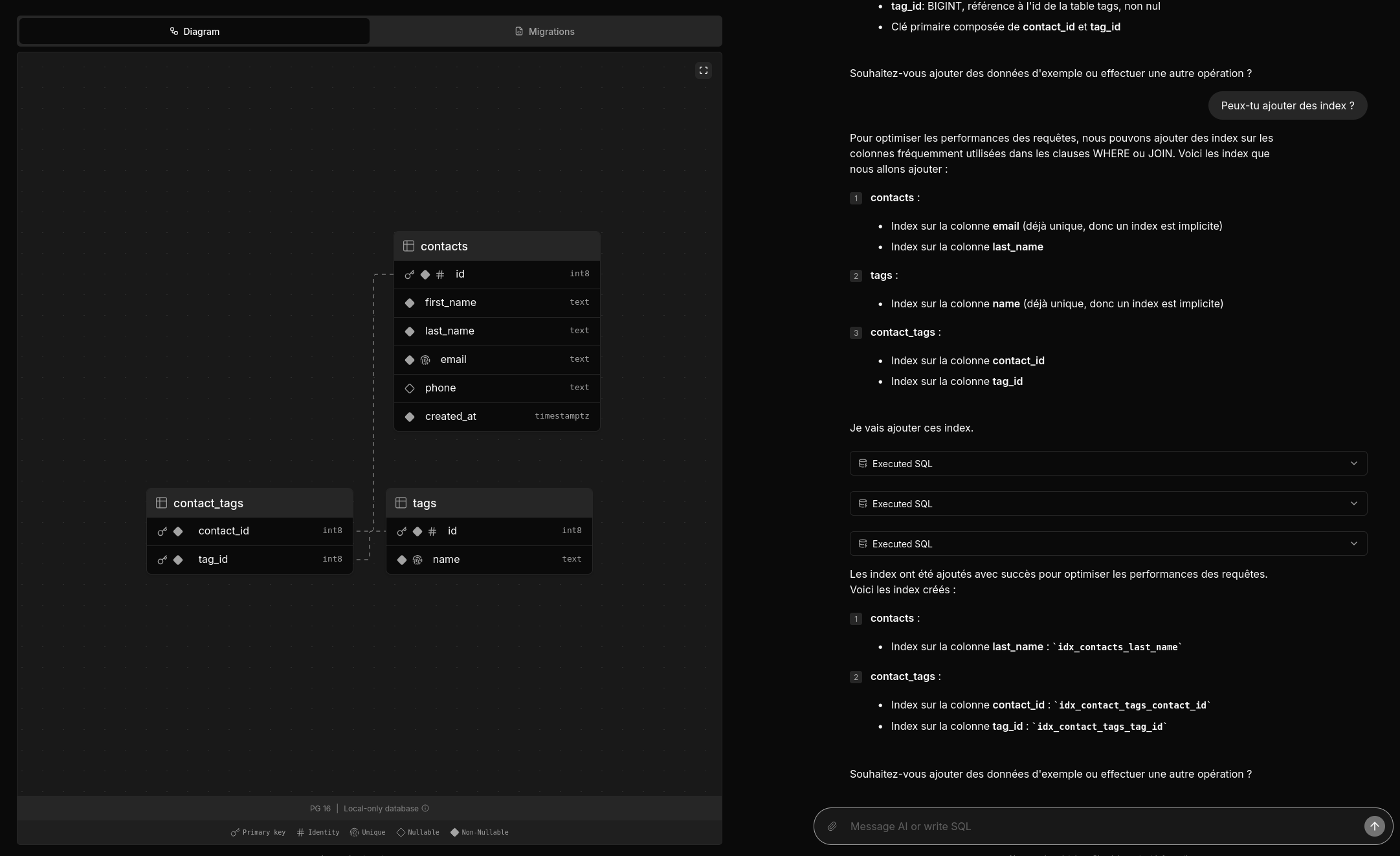
Voici une vidéo officielle : https://www.youtube.com/watch?v=ooWaPVvljlU
#Jadore ! Je trouve l'UX très bonne, j'aime l'onglet "Migrations", les explications données dans la colonne de droite.
Le projet est 100% Open source, voici le dépôt GitHub : https://github.com/supabase-community/postgres-new
Très beau travail !
Je me demande combien de temps ce projet a été implémenté 🤔.
1 mois et demi d'après la page contributors.
Mais je constate que le premier commit est plutôt conséquent, je pense que le projet était initialement intégré dans un mono repository.
Concernant l'implémentation, je lis :
All queries in postgres.new run directly in your browser. There’s no remote Postgres container or WebSocket proxy.
👍️
How is this possible? PGlite, a WASM version of PostgreSQL that can run directly in your browser. Every database that you create spins up a new instance of PGlite that exposes a fully-functional Postgres database. Data is stored in IndexedDB so that changes persist after refresh.
La partie LLM n'est pas mentionnée, #JeMeDemande comment elle est implémentée 🤔.
Je pense avoir trouvé ma réponse ici :
We pair PGlite with an LLM (currently GPT-4o) and give it full reign over the database with unrestricted permissions. (from)
Je lis :
RAG / pgvector: PGLite supports pgvector, so you can ask the LLM to create embeddings for RAG. The site uses transformers.js to create embeddings inside the browser.
Je n'ai pas tout compris 🤔.
#JaiDécouvert transformers.js.
J'ai lu ce commentaire :
It is a neat tech demo but it clearly shows the limits of AI:
- I got it to generate invalid SQL resulting in errors - it merely generates reasonable SQL, but in my case it generated to disjoint set of tables…. - In practice you have tot review all code - It can point you into the wrong direction. Novel systems often have something smart/abstract in there. This system creates mostly Straightforward simple systems. That’s not where the value is
All in all, it’s not worth it to me. Writing code myself is easier than having to review LLM code
Within our organization we have forbidden full LLM merge request because more often than not the code was suboptimal. And had sneaky bugs/mistakes.
I’m not saying these can’t be overcome. But not with current LLM design. They mostly generate stuff they have seen and are bad as truly new stuff.
Personnellement, cela ne me surprend pas et cela ne remet pas en question, à mes yeux, l'intérêt de cet outil.
Je pense l'utiliser pour concevoir une ébauche de base de données.
Je pense qu'il pourra me fournir de bonnes suggestions pour les noms de tables et de champs, et même inclure des champs auxquels je n'aurais peut-être pas pensé.
Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
Cette semaine, j'ai déjeuné avec un ami dont les connaissances dans le domaine du #MachineLearning et des #llm dépassent largement les miennes... J'en ai profité pour lui poser de nombreuses questions.
Voici ci-dessous quelques notes de ce que j'ai retenu de notre discussion.
Avertissement : Le contenu de cette note reflète les informations que j'ai reçues pendant cette conversation. Je n'ai pas vérifié l'exactitude de ces informations, et elles pourraient ne pas être entièrement correctes. Le contenu de cette note est donc à considérer comme approximatif. N'hésitez pas à me contacter à contact@stephane-klein.info si vous constatez des erreurs.
Histoire de Llama.cpp ?
Question : quelle est l'histoire de llama.cpp ? Comment ce projet se positionne dans l'écosystème ?
D'après ce que j'ai compris, début 2023, PyTorch était la solution "mainstream" (la seule ?) pour effectuer de l'inférence sur le modèle LLaMa — sortie en février 2023.
PyTorch — écrit en Python et C++ — est optimisée pour les GPU, plus précisément pour le framework CUDA.
PyTorch est n'est pas optimisé pour l'exécution sur CPU, ce n'est pas son objectif.
Georgi Gerganov a créé llama.cpp pour pouvoir effectuer de l'inférence sur le modèle LLaMa sur du CPU d'une manière optimisé. Contrairement à PyTorch, plus de Python et des optimisations pour Apple Silicon, utilisation des instructions AVX / AVX2 sur les CPU x86… Par la suite, « la boucle a été bouclée » avec l'ajout du support GPU en avril 2023.
À la question « Maintenant que llama.cpp a un support GPU, à quoi sert PyTorch ? », la réponse est : PyTorch permet beaucoup d'autres choses, comme entraîner des modèles…
Aperçu de l'historique du projet :
- 18 septembre 2022 : Georgi Gerganov commence la librairie ggml, sur laquelle seront construits llama.cpp et Whisper.cpp.
- 4 mars 2023 : Georgi Gerganov a publié le premier commit de llama.cpp.
- 10 mars 2023 : je crois que c'est le premier poste Twitter de publication de llama.cpp https://twitter.com/ggerganov/status/1634282694208114690.
- 13 mars 2023 : premier post à propos de LLama.cpp sur Hacker News qui fait zéro commentaire - Llama.cpp can run on Macs that have 64G of RAM (40GB of Free memory).
- 14 mars 2023 : second poste, toujours zéro commentaire - Run a GPT-3 style AI on your local machine, fully on premise.
- 31 mars 2023 : premier thread sur llama.cpp qui fait le buzz avec 414 commentaires - Llama.cpp 30B runs with only 6GB of RAM now.
- 12 avril 2023 : d'après ce que je comprends, voici la Merge Request d'ajout du support GPU à llama.cpp # Add GPU support to ggml (from).
- 6 juin 2023 : Georgi Gerganov lance sa société nommée https://ggml.ai (from) .
- 10 juillet 2023 : Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- 24 juillet 2023 : llama : add support for llama2.c models (from).
- 25 août 2023 : ajout du support ROCm (AMD).
Comment nommer Llama.cpp ?
Question : quel est le nom d'un outil comme llama.cpp ?
Réponse : Je n'ai pas eu de réponse univoque à cette question.
C'est un outil qui effectue des inférences sur un modèle.
Voici quelques idées de nom :
- Moteur d'inférence (Inference Engines) ;
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, #JaiDécidé d'utiliser le terme Inference Engines.
Autre projet comme Llama.cpp ?
Question : Existe-t-il un autre projet comme Llama.cpp
Oui, il existe d'autres projets, comme llm - Large Language Models for Everyone, in Rust. Article Hacker News publié le 14 mars 2023 sous le nom LLaMA-rs: a Rust port of llama.cpp for fast LLaMA inference on CPU.
Et aussi, https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from).
Le README de ce projet liste de nombreuses autres implémentations de Inference Engines.
Mais, à ce jour, llama.cpp semble être l'Inference Engines le plus complet et celui qui fait consensus.
GPU vs CPU
Question : Jai l'impression qu'il est possible de compiler des programmes généralistes sur GPU, dans ce cas, pourquoi ne pas remplacer les CPU par des GPU ? Pourquoi ne pas tout exécuter par des GPU ?
Mon ami n'a pas eu une réponse non équivoque à cette question. Il m'a répondu que l'intérêt du CPU reste sans doute sa faible consommation énergique par rapport au GPU.
Après ce déjeuner, j'ai fait des recherches et je suis tombé sur l'article Wikipedia nommé General-purpose computing on graphics processing units (je suis tombé dessus via l'article ROCm).
Cet article contient une section nommée GPU vs. CPU, mais qui ne répond pas à mes questions à ce sujet 🤷♂️.
ROCm ?
Question : J'ai du mal à comprendre ROCm, j'ai l'impression que cela apporte le support du framework CUDA sur AMD, c'est bien cela ?
Réponse : oui.
J'ai ensuite lu ici :
HIPIFY is a source-to-source compiling tool. It translates CUDA to HIP and reverse, either using a Clang-based tool, or a sed-like Perl script.
RAG ?
Question : comment setup facilement un RAG ?
Réponse : regarde llama_index.
#JaiDécouvert ensuite https://github.com/abetlen/llama-cpp-python
Simple Python bindings for @ggerganov's llama.cpp library. This package provides:
- Low-level access to C API via ctypes interface.
- High-level Python API for text completion
- OpenAI-like API
- LangChain compatibility
- LlamaIndex compatibility
- ...
dottextai / outlines
Il m'a partagé le projet https://github.com/outlines-dev/outlines alias dottxtai, pour le moment, je ne sais pas trop à quoi ça sert, mais je pense que c'est intéressant.
Embedding ?
Question : Thibault Neveu parle souvent d'embedding dans ses vidéos et j'ai du mal à comprendre concrètement ce que c'est, tu peux m'expliquer ?
Le vrai terme est Word embedding et d'après ce que j'ai compris, en simplifiant, je dirais que c'est le résultat d'une "sérialisation" de mots ou de textes.
#JaiDécouvert ensuite l'article Word Embeddings in NLP: An Introduction (from) que j'ai survolé. #JaimeraisUnJour prendre le temps de le lire avec attention.
Transformers ?
Question : et maintenant, peux-tu me vulgariser le concept de transformer ?
Réponse : non, je t'invite à lire l'article Natural Language Processing: the age of Transformers.
Entrainement décentralisé ?
Question : existe-t-il un système communautaire pour permettre de générer des modèles de manière décentralisée ?
Réponse - Oui, voici quelques liens :
- BigScience Research Workshop/
- Distributed Deep Learning in Open Collaborations
- Deep Learning over the Internet: Training Language Models Collaboratively
Au passage, j'ai ajouté https://huggingface.co/blog/ à mon agrégateur RSS (miniflux).
La suite…
Nous avons parlé de nombreux autres sujets sur cette thématique, mais j'ai décidé de m'arrêter là pour cette note et de la publier. Peut-être que je publierai la suite un autre jour 🤷♂️.
Journal du mercredi 22 mai 2024 à 12:45
On me demande où j'en suis dans mon expérience notes.sklein.xyz ?
Comment il est déployé ? Pour le moment, d'une manière très minimaliste et assez manuelle comme décrit ici : https://github.com/stephane-klein/obsidian-quartz-playground/tree/main/deployment
Aujourd'hui c'est toujours le cas. Quand je veux déployer je lance le script deployment/scripts/build-and-push.sh.
Je disais aussi :
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
Je ne suis toujours pas satisfait du rendu de notes.sklein.xyz mais je suis satisfait de l'expérience car j'arrive à produire et partager du contenu facilement.
Pour le moment, je pense que produire du contenu est plus important que de soigner le rendu. Le jour où j'aurai beaucoup de contenu, une amélioration de la forme, de la navigation et des fonctionnalités aura alors plus de valeur pour moi.
Je disais aussi :
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Suite à cela, j'ai créé Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et j'ai seulement travailé un tout petit peu sur cette expérience.
#JaimeraisUnJour un jour setup un RAG sur notes.sklein.xyz.
Est-ce que je suis satisfait du client Obsidian ? Je réponds que parfois oui, parfois non. Il m'agace par moments, et j'aimerais prendre le temps de "parfaitement configurer" Obsidian.nvim.
Journal du vendredi 17 mai 2024 à 11:57
Issue intéressante au sujet RAG LLM IA for documentation learning · Issue #25 · Its-Alex/backlog · GitHub.
Journal du vendredi 17 mai 2024 à 11:05
Dans l'article "Qu'est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?" je découvre l'acronyme Génération Augmentée de Récupération.
Je constate qu'il existe un paragraphe à ce sujet sur Wikipedia.
The initial phase utilizes dense embeddings to retrieve documents.
Je tombe encore une fois sur "embeddings", #JaimeraisUnJour prendre le temps de comprendre correctement cette notion.
Prenez l'exemple d'une ligue sportive qui souhaite que les fans et les médias puisse utiliser un chat pour accéder à ses données et obtenir des réponses à leurs questions sur les joueurs, les équipes, l'histoire et les règles du sport, ainsi que les statistiques et les classements actuels. Un LLM généralisé pourrait répondre à des questions sur l'histoire et les règles ou peut-être décrire le stade d'une équipe donnée. Il ne serait pas en mesure de discuter du jeu de la nuit dernière ou de fournir des informations actuelles sur la blessure d'un athlète, parce que le LLM n'aurait pas ces informations. Étant donné qu'un LLM a besoin d'une puissance de calcul importante pour se réentraîner, il n'est pas possible de maintenir le modèle à jour.
Le contenu de ce paragraphe m'intéresse beaucoup, parce que c'était un de mes objectifs lorsque j'ai écrit cette note en juin 2023.
Sans avoir fait de recherche, je pensais que la seule solution pour faire apprendre de nouvelles choses — injecter de nouvelle données — dans un modèle était de faire du fine-tuning.
En lisant ce paragraphe, je pense comprendre que le fine-tuning n'est pas la seule solution, ni même, j'ai l'impression, la "bonne" solution pour le use-case que j'aimerais mettre en pratique.
En plus du LLM assez statique, la ligue sportive possède ou peut accéder à de nombreuses autres sources d'information, y compris les bases de données, les entrepôts de données, les documents contenant les biographies des joueurs et les flux d'actualités détaillées concernant chaque jeu.
#JaimeraisUnJour implémenter un POC pour mettre cela en pratique.
Dans la RAG, cette grande quantité de données dynamiques est convertie dans un format commun et stockée dans une bibliothèque de connaissances accessible au système d'IA générative.
Les données de cette bibliothèque de connaissances sont ensuite traitées en représentations numériques à l'aide d'un type spécial d'algorithme appelé modèle de langage intégré et stockées dans une base de données vectorielle, qui peut être rapidement recherchée et utilisée pour récupérer les informations contextuelles correctes.
Intéressant.
Il est intéressant de noter que si le processus de formation du LLM généralisé est long et coûteux, c'est tout à fait l'inverse pour les mises à jour du modèle RAG. De nouvelles données peuvent être chargées dans le modèle de langage intégré et traduites en vecteurs de manière continue et incrémentielle. Les réponses de l'ensemble du système d'IA générative peuvent être renvoyées dans le modèle RAG, améliorant ses performances et sa précision, car il sait comment il a déjà répondu à une question similaire.
Ok, si je comprends bien, c'est la "kill feature" du RAG versus du fine-tuning.
bien que la mise en oeuvre de l'IA générative avec la RAG est plus coûteux que l'utilisation d'un LLM seul, il s'agit d'un meilleur investissement à long terme en raison du réentrainement fréquent du LLM
Ok.
Bilan de cette lecture, je dis merci à Alexandre de me l'avoir partagé, j'ai appris RAG et #JePense que c'est une technologie qui me sera très utile à l'avenir 👌.